原文地址:http://hi.baidu.com/zzpppork/blog/item/c1c79cfadbfe0a6e034f5683.html
在向量空间模型中,文本泛指各种机器可读的记录。用D(Document)表示,特征项(Term,用t表示)是指出现在文档D中且能够代表该文档内容的基本语言单位,主要是由词或者短语构成,文本可以用特征项集表示为D(T1,T2,…,Tn),其中Tk是特征项,1<=k<=N。例如一篇文档中有a、b、c、d四个特征项,那么这篇文档就可以表示为D(a,b,c,d)。对含有n个特征项的文本而言,通常会给每个特征项赋予一定的权重表示其重要程度。即D=D(T1,W1;T2,W2;…,Tn,Wn),简记为D=D(W1,W2,…,Wn),我们把它叫做文本D的向量表示。其中Wk是Tk的权重,1<=k<=N。在上面那个例子中,假设a、b、c、d的权重分别为30,20,20,10,那么该文本的向量表示为D(30,20,20,10)。在向量空间模型中,两个文本D1和D2之间的内容相关度Sim(D1,D2)常用向量之间夹角的余弦值表示,公式为:
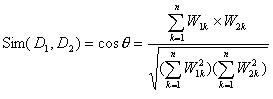
其中,W1k、W2k分别表示文本D1和D2第K个特征项的权值,1<=k<=N。
在自动归类中,我们可以利用类似的方法来计算待归类文档和某类目的相关度。例如文本D1的特征项为a,b,c,d,权值分别为30,20,20,10,类目C1的特征项为a,c,d,e,权值分别为40,30,20,10,则D1的向量表示为D1(30,20,20,10,0),C1的向量表示为C1(40,0,30,20,10),则根据上式计算出来的文本D1与类目C1相关度是0.86
那个相关度0.86是怎么算出来的?
是这样的,抛开你的前面的赘述
在数学当中,n维向量是 V{v1, v2, v3, ..., vn}
他的模: |v| = sqrt ( v1*v1 + v2*v2 + ... + vn*vn )
两个向量的点击 m*n = n1*m1 + n2*m2 + ...... + nn*mn
相似度 = (m*n) /(|m|*|n|)
物理意义就是两个向量的空间夹角的余弦数值
对于你的例子
d1*c1 = 30*40 + 20*0 + 20*30 + 10*20 + 0*10 = 2000
|d1| = sqrt(30*30 +20*20 + 20*20 + 10*10 + 0*0) = sqrt(1800)
|c1| = sqrt(40*40 + 0*0 + 30*30 + 20*20 + 10*10) = sqrt(3000)
相似度 = d1*c1/(|d1|*|c1|)= 2000/sqrt(1800*3000)= 0.86066
应用的具体参考地址:
http://www.cnblogs.com/TtTiCk/archive/2007/08/04/842819.html
posted on 2010-06-07 13:52
漂漂 阅读(788)
评论(0) 编辑 收藏 引用