#
我一向是不太喜欢给一些东西强加上个名字。但为了随波逐流,我还是这样做了。
在我们的游戏开发中,通常会遇到两个模块之间的通信。 回调估计是最常用的方式了。 回调的设计思想很简单,就是两个对象相互注册,然后在需要的时候调用对方的函数。
如下:
这样,当A执行自己的某些动作的时候,就调用B的函数,这样B就会进行自己的更新或是一些处理。
但是,由于两个对象的直接回调,导致了许多不方便之处。特别是当A和B的功能需要扩展的时候。例如:现在A在执行过程中,需要调用B中其它的功能函数。这时候就不得不修改A和B的接口。然后大家都重新编译,连接,执行。
于是,我们就会想会不会有一种更好的方法来解决这一问题。 大家可以想想,WINDOWS中的通信机制:通过解析消息类型来进行处理。是的,消息回调的好处就是方便扩展。 当然我们这里要讲的不是像WINDOWS中那样的消息通信机制,对于我们来说,那种做法过繁琐。
假设现在是想让A通知B一些事情。那么,我们可以把B的void DoB();函数作一点点修改:
同理,当B要通知A的时候,也这样做就行了。
但是,这样也很麻烦,关键在于,如果现在写类A的人并不知道类B的人会怎么写,或者说,类B不知道什么时候要写。另外,如果我们强制类B要实现这样的接口,会有点不现实。
此时,我们决定使用一个中间对象来连接他们。
这就是我们传说中的监听器了。 在OGRE或是一些广泛采用面向对象思想的源程序中,随处可见这样的模式。
还是假设是A需要通知B一些事情。那么,可以在A中注册这个对象,然后调用它的方法就可以了。
而我们在实现B的时候,除了要实现B自己的东西以外,还需要将ICallBack派生并实现 void Do(int Msg)函数;
这样,双方便很自然地通了信。而写类A的人根本不需要理会类B的人会怎么写,也不用去管类B会是什么样的类名。只要告诉写类B的人,你需要实现这个Callback接口,并且对应的MsgID是干什么用的就OK了。
也许初初的一看,这是吃力不讨好的工作。毕竟一个写A的人,会去想那么多事情。 而一个写B的人,还要去实现一个Callback类。但是,从可扩展性,和降低耦合上来讲,的确会起不少的作用。
而上面的void Do(int MsgID);函数,可以做得更强大一点。
写成void Do(void* pData); 而这个pData怎么使用,就要看A和B通信的具体内容了。
我正尽力地试着把自己想要说的讲清楚,谢谢!
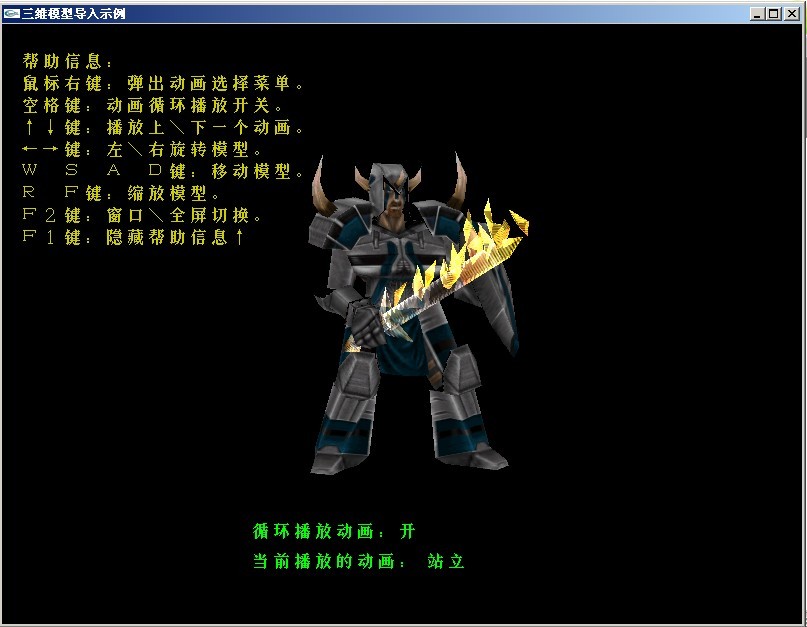
此次毕业设计的内容很简单,就是用OPENGL加载模型并显示出来就OK了。本想做骨骼动画,或是做个自己的软渲染器来渲染模型。看来只有毕业之后再做了。
此次演示用的是MD2文件格式。我会在毕业答辩后(估计6月份吧)给出源码。。
虽然示例并未做出什么高深的东西。但有兴趣的朋友可以拿来来看看。
另外,谁 能告诉我怎么上传附件哇,我还是没找到!
终于找到了两篇让人易懂的文章,这两篇结合着看,很容易看清计算过程,没有想象中的那么复杂
这是一篇老外的:http://www.terathon.com/code/tangent.html
这是另一个大哥的:http://jingli83.blog.sohu.com/94746672.html
两篇结合看,方显其效!
有了这两篇的理解后,再去看其它的关于切线空间的文章,就不会再摸不着东南西北了!
SSAO全称“Screen-Space Ambient Occlusion” (屏幕空间环境光遮蔽)。其最先运用于 Crysis(孤岛危机) 游戏中,通过GPU的 shader实现
SSAO通过采样象素周围的信息,并进行简单的深度值对比来计算物体身上环境光照无法到达的范围,从而可以近似地表现出物体身上在环境光照下产生的轮廓阴影。可以利用“逐象素场景深度计算”技术计算得出的深度值直接参与运算。
现在的效果确实错误还比较大,应该先进行简单的空间划分(或类似处理)然后计算。
不过个人认为这种方法只是近似地模拟,效果并不正确,但确实能增强场景的层次感,让画面更细腻,让场景细节更加明显。
不同于显卡驱动中普通的AO选项,burnout的SSAO是全动态的,无需预处理,无loading时间,无需消耗内存,不使用CPU,全由GPU处理,对GPU有较大的消耗
SSAO默认是关闭的,可以在游戏视频选项中打开
评测
在7950GT下跑,加了ssao后,下降了15%。而且,显卡性能越低,下降的越厉害。效率消耗主要是在于要多渲染一遍场景到深度以及之后进行的ssao处理。这遍可以进行优化,如果物体的纹理不带alpha,则可以把他们都合在一批或几批渲染。至于深度图的尺寸 ,我采用了与窗口一样的尺寸,这样精度高。也可以采用低分辨率,但效果会有锯齿,还需要进行模糊处理才比较自然。当然,如果本来就用了延迟渲染技术,本来就有深度图了,那就可以直接拿来用了。
与PRT对比
PRT用于静态场景确实是个比较好的方案,毕竟可以预计算。但是对于动态的场景,还需要动态更新。另外,PRT的质量依赖于网格的细分程度,要是模型太简,则效果也糟糕。
因此 ,PRT对于虚拟现实项目里的高楼大厦等场景(这些模型都是很精简的)来说,就显得不合适了
目前已发行的游戏中,运用SSAO的游戏有
Crysis(孤岛危机)
Burnout(TM) Paradise The Ultimate Box(火爆狂飙5天堂)
帝国:全面战争
另外,星际争霸2的开发也运用到了SSAO
什么是SSAO?
从HL2开始,众多游戏公司开始对于如何表现“间接光照”进行研究,这些昙花一现的技术有:
运用于HL2的radiosity Normal Maps技术,效果比较垃圾
运用于Stalker的GI(?)技术,算法不好,开销巨大。
初期Crytek准备运用在Crysis上的Photon Mapping(光子映射)技术,开销同样比较垃圾,被抛弃。
随后Crytek又准备运用在Crysis上的Real-Time Ambient Map(实时环境光照贴图,简称RAM),这个是与之前Stalker使用的技术比较类似的,也是最接近SSAO的一个技术。
不过Crytek不愧为“间接光照”研究上的先锋,其技术员对于RAM进行了改进,新的算法成为了如今的SSAO
SSAO开与关的区别所在
SSAO(Screen-Space Ambient Occlusion)是一个纯粹的渲染技术,或者说,是一个算法。虽然从上文知道是为了实现“间接光照”的效果,不过从技术上讲,就是一个对于AO(Ambient Occlusion环境光吸收,也就是NV 185.20驱动加入的那个,一个渲染技术,我们可以在Maya等3D软件中可以见到)的一个逼近函数,并且以此为据进行实时渲染。
SSAO比起185.20驱动中AO的优点:
与场景复杂性无关
无数据预处理,无loading时间,无系统内存分配
动态渲染
每个像素工作方式始终一致
无CPU占用,完全通过GPU执行
与流行显卡的管线整合相当容易
缺点也是有的:
由于采样全部在可见点上进行的,对于不可见点的遮挡影响会有错误的估算。
颗粒感比较重,需要与动态模糊紧密配合才能取得较好效果。
SSAO屏幕空间环境光遮蔽的运作方式
其实了解了AO环境光遮蔽的原理,SSAO(屏幕空间环境光遮蔽)已经可以融会贯通,SSAO通过采样像素周围的信息,并进行简单的深度值对比来计算物体身上环境光照无法到达的范围,从而可以近似地表现出物体身上在环境光照下产生的轮廓阴影。
具体的运作方式上,SSAO会利用GPU计算出指定像素的空间坐标,然后以此坐标为基点,在周围选择数个采样点进行采样,然后将采样点的空间坐标投影回屏幕坐标,对深度缓冲进行采样,最后得到采样点的深度值,再进行后续计算,最终得到一个遮挡值。

SSAO实现了较好的全局光照效果
SSAO屏幕空间环境光遮蔽实现了较好的全局光照效果
因为是基于指定空间的全局计算模式,因此SSAO实现效果的优劣取决于算法,包括空间的指定范围和采样点的选取等等。需要指明的是,不同游戏(引擎)在SSAO的细节算法方面可能不尽相同,另外SSAO还会结合其它光照技术共同达成游戏画面的渲染,所以SSAO在很多游戏中不会有专门的开关选项,其最终的表现结果可能是与其它技术共同作用的结果。
转自:
http://www.abc188.com/info/html/wangzhanyunying/jianzhanjingyan/20080417/71683.html
文档简介: 提高3D图像程式的性能是个很大的课题。图像程式的优化大致能够分成两大任务,一是要有好的场景管理程式,能快速剔除不可见多边形,并根据对象距相机远近选择合适的细节(LOD);二是要有好的渲染程式,能快速渲染送入渲染管线的可见多边形。 我们知道,使用
文档简介:
提高3D图像程式的性能是个很大的课题。图像程式的优化大致能够分成两大任务,一是要有好的场景管理程式,能快速剔除不可见多边形,并根据对象距相机远近选择合适的细节(LOD);二是要有好的渲染程式,能快速渲染送入渲染管线的可见多边形。
我们知道,使用OpenGL或Direct3D渲染图像时,首先要配置渲染状态,渲染状态用于控制渲染器的渲染行为。应用程式能够通过改变渲染状态来控制OpenGL或Direct3D的渲染行为。比如配置Vertex/Fragment Program、绑定纹理、打开深度测试、配置雾效等。
改变渲染状态对于显卡而言是比较耗时的操作,而假如能合理管理渲染状态,避免多余的状态转换,将明显提升图像程式性能。这篇文章将讨论渲染状态的管理。
文档目录:
基本思想
实际问题
渲染脚本
文档内容:
基本思想
我们考虑一个典型的游戏场景,包含人、动物、植物、建筑、交通工具、武器等。稍微分析一下就会发现,实际上场景里很多对象的渲染状态是相同的,比如任何的人和动物的渲染状态一般都相同,任何的植物渲染状态也相同,同样建筑、交通工具、武器也是如此。我们能够把具备相同的渲染状态的对象归为一组,然后分组渲染,对每组对象只需要在渲染前配置一次渲染状态,并且还能够保存当前的渲染状态,配置渲染状态时只需改变和当前状态不相同的状态。这样能够大大减少多余的状态转换。下面的代码段演示了这种方法:
// 渲染状态组链表,由场景管理程式填充
RenderStateGroupList groupList;
// 当前渲染状态
RenderState curState;
……
// 遍历链表中的每个组
RenderStateGroup *group = groupList.GetFirst();
while ( group != NULL )
{
// 配置该组的渲染状态
RenderState *state = group->GetRenderState();
state->ApplyRenderState( curState );
// 该渲染状态组的对象链表
RenderableObjectList *objList = group->GetRenderableObjectList();
// 遍历对象链表的每个对象
RenderableObject *obj = objList->GetFirst();
while ( obj != NULL )
{
// 渲染对象
obj->Render();
obj = objList->GetNext();
}
group = groupList.GetNext();
}
其中RenderState类的ApplyRenderState方法形如:
void RenderState::ApplyRenderState( RenderState &curState )
{
// 深度测试
if ( depthTest != curState.depthTest )
{
SetDepthTest( depthTest );
curState.depthTest = depthTest;
}
// Alpha测试
if ( alphaTest != curState.alphaTest )
{
SetAlphaTest( alphaTest );
curState.alphaTest = alphaTest;
}
// 其他渲染状态
……
}
这些分组的渲染状态一般被称为Material或Shader。这里Material不同于OpenGL和Direct3D里面用于光照的材质,Shader也不同于OpenGL里面的Vertex/Fragment Program和Direct3D里面的Vertex/Pixel Shader。而是指封装了的显卡渲染图像需要的状态(也包括了OpenGL和Direct3D原来的Material和Shader)。
从字面上看,Material(材质)更侧重于对象表面外观属性的描述,而Shader(这个词实在不好用中文表示)则有用程式控制对象表面外观的含义。由于显卡可编程管线的引入,渲染状态中包含了Vertex/Fragment Program,这些小程式能够控制物体的渲染,所以我觉得将封装的渲染状态称为Shader更合适。这篇文章也将称之为Shader。
上面的代码段只是简单的演示了渲染状态管理的基本思路,实际上渲染状态的管理需要考虑很多问题。
渲染状态管理的问题
消耗时间问题
改变渲染状态时,不同的状态消耗的时间并不相同,甚至在不同条件下改变渲染状态消耗的时间也不相同。比如绑定纹理是个很耗时的操作,而当纹理已在显卡的纹理缓存中时,速度就会很快。而且随着硬件和软件的发展,一些很耗时的渲染状态的消耗时间可能会有减少。因此并没有一个准确的消耗时间的数据。
虽然消耗时间无法量化,情况不同消耗的时间也不相同,但一般来说下面这些状态转换是比较消耗时间的:
Vertex/Fragment Program模式和固定管线模式的转换(FF,Fixed Function Pipeline)
Vertex/Fragment Program本身程式的转换
改变Vertex/Fragment Program常量
纹理转换
顶点和索引缓存(Vertex & Index Buffers)转换
有时需要根据消耗时间的多少来做折衷,下面将会碰到这种情况。
渲染状态分类
实际场景中,往往会出现这样的情况,一类对象其他渲染状态都相同,只是纹理和顶点、索引数据不同。比如场景中的人,只是身材、长相、服装等不同,也就是说只有纹理、顶点、索引数据不同,而其他如Vertex/Fragment Program、深度测试等渲染状态都相同。相反,一般不会存在纹理和顶点、索引数据相同,而其他渲染状态不同的情况。我们能够把纹理、顶点、索引数据不归入到Shader中,这样场景中任何的人都能够用一个Shader来渲染,然后在这个Shader下对纹理进行分组排序,相同纹理的人放在一起渲染。
多道渲染(Multipass Rendering)
有些比较复杂的图像效果,在低档显卡上需要渲染多次,每次渲染一种效果,然后用GL_BLEND合成为最终效果。这种方法叫多道渲染Multipass Rendering,渲染一次就是个pass。比如做逐像素凹凸光照,需要计算环境光、漫射光凹凸效果、高光凹凸效果,在NV20显卡上只需要1个pass,而在NV10显卡上则需要3个pass。Shader应该支持多道渲染,即一个Shader应该分别包含每个pass的渲染状态。
不同的pass往往渲染状态和纹理都不同,而顶点、索引数据是相同的。这带来一个问题:是以对象为单位渲染,一次渲染一个对象的任何pass,然后渲染下一个对象;还是以pass为单位渲染,第一次渲染任何对象的第一个pass,第二次渲染任何对象的第二个pass。下面的程式段演示了这两种方式:
以对象为单位渲染
// 渲染状态组链表,由场景管理程式填充
ShaderGroupList groupList;
……
// 遍历链表中的每个组
ShaderGroup *group = groupList.GetFirst();
while ( group != NULL )
{
Shader *shader = group->GetShader();
RenderableObjectList *objList = group->GetRenderableObjectList();
// 遍历相同Shader的每个对象
RenderableObject *obj = objList->GetFirst();
while ( obj != NULL )
{
// 获取shader的pass数
int iNumPasses = shader->GetPassNum();
for ( int i = 0; i < iNumPasses; i )
{
// 配置shader第i个pass的渲染状态
shader->ApplyPass( i );
// 渲染对象
obj->Render();
}
obj = objList->GetNext();
}
group = groupList->GetNext();
}
以pass为单位渲染
// 渲染状态组链表,由场景管理程式填充
ShaderGroupList groupList;
……
for ( int i = 0; i < MAX_PASSES_NUM; i )
{
// 遍历链表中的每个组
ShaderGroup *group = groupList.GetFirst();
while ( group != NULL )
{
Shader *shader = group->GetShader();
int iNumPasses = shader->GetPassNum();
// 假如shader的pass数小于循环次数,跳过此shader
if( i >= iNumPasses )
{
group = groupList->GetNext();
continue;
}
// 配置shader第i个pass的渲染状态
shader->ApplyPass( i );
RenderableObjectList *objList =
group->GetRenderableObjectList();
// 遍历相同Shader的每个对象
RenderableObject *obj = objList->GetFirst();
while ( obj != NULL )
{
obj->Render();
obj = objList->GetNext();
}
group = groupList->GetNext();
}
}
这两种方式各有什么优缺点呢?
以对象为单位渲染,渲染一个对象的第一个pass后,马上紧接着渲染这个对象的第二个pass,而每个pass的顶点和索引数据是相同的,因此第一个pass将顶点和索引数据送入显卡后,显卡Cache中已有了这个对象顶点和索引数据,后续pass不必重新将顶点和索引数据拷到显卡,因此速度会很快。而问题是每个pass的渲染状态都不同,这使得实际上每次渲染都要配置新的渲染状态,会产生大量的多余渲染状态转换。
以pass为单位渲染则正好相反,以Shader分组,相同Shader的对象一起渲染,能够只在这组开始时配置一次渲染状态,相比以对象为单位,大大减少了渲染状态转换。可是每次渲染的对象不同,因此每次都要将对象的顶点和索引数据拷贝到显卡,会消耗不少时间。
可见想减少渲染状态转换就要频繁拷贝顶点索引数据,而想减少拷贝顶点索引数据又不得不增加渲染状态转换。鱼和熊掌不可兼得 :-(
由于硬件条件和场景数据的情况比较复杂,具体哪种方法效率较高并没有定式,两种方法都有人使用,具体选用那种方法需要在实际环境测试后才能知道。
多光源问题
待续……
阴影问题
待续……
渲染脚本
现在很多图像程式都会自己定义一种脚本文档来描述Shader。
比如较早的OGRE(Object-oriented Graphics Rendering Engine,面向对象图像渲染引擎)的Material脚本,Quake3的Shader脚本,连同刚问世不久的Direct3D的Effect File,nVIDIA的CgFX脚本(文档格式和Direct3D Effect File兼容),ATI RenderMonkey使用的xml格式的脚本。OGRE Material和Quake3 Shader这两种脚本比较有历史了,不支持可编程渲染管线。而后面三种比较新的脚本都支持可编程渲染管线。
脚本 特性 范例
OGRE Material 封装各种渲染状态,不支持可编程渲染管线 >>>>
Quake3 Shader 封装渲染状态,支持一些特效,不支持可编程渲染管线 >>>>
Direct3D Effect File 封装渲染状态,支持multipass,支持可编程渲染管线 >>>>
nVIDIA CgFX脚本 封装渲染状态,支持multipass,支持可编程渲染管线 >>>>
ATI RenderMonkey脚本 封装渲染状态,支持multipass,支持可编程渲染管线 >>>>
使用脚本来控制渲染有很多好处:
能够很方便的修改一个物体的外观而不需重新编写或编译程式
能够用外围工具以所见即所得的方式来创建、修改脚本文档(类似ATI RenderMonkey的工作方式),便于美工、关卡设计人员设定对象外观,建立外围工具和图像引擎的联系
能够在渲染时将相同外观属性及渲染状态的对象(也就是Shader相同的对象)归为一组,然后分组渲染,对每组对象只需要在渲染前配置一次渲染状态,大大减少了多余的状态转换