#
Light Map是一个比较经典的技术,目前来说应该是一般游戏引擎中的标配,它很好的在一种拟全局光效果的质量和效率上做了中和。不过目前用的更多、质量更好的应该是Directional Light Map,它是原始LM的增强版,通过在预处理与实时还原中考量场景中表面的法向量进而增强效果。DLM的基本操作方法如下:
- 在采样点处把其半球空间中的辐射照度用某种方法进行采集并保存(比如离线的光线跟踪);
- 以某种方法存储额外的、与该辐射照度相关的法线信息到光照贴图中;
- 实时渲染中通过光照贴图对像素上的场景辐照度进行还原(结合光照信息与方向信息)。
目前常用的DLM实现方法主要有三种:
Radiosity Normal Maps
该方法最早是在Valve的Source引擎中用的一种模式,它的原理应该是一种拟信号压缩与重建的方法:
- 在采样点处选取三个正交的采样方向作为基方向,采样得到这些方向上的光照信息并保存(压缩);
- 实时渲染中通过三个方向及其上的光照值做为基函数,对实际表面法向上的光照值进行还原(重建)。
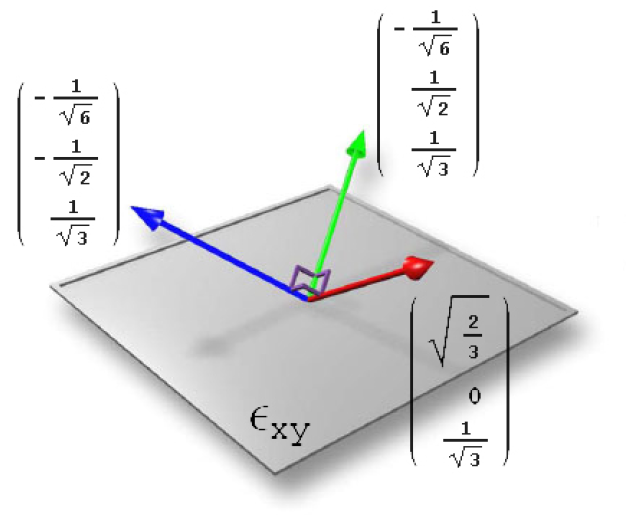
其中的三个基方向(表面法向所在的局部切空间,如下图示)分别为:
 ,
,  ,
, 
对应的还原计算为:

Valve的这种方法应该说还是很不错的,虽然数学理论依据不太充分,但至少看起来效果很不错,而且实现简单,效率较高。不过其也会出现一些问题,那就是当法线的方向与采样光照的主方向夹角较大(即与采样切平面的夹角较小时)容易出现一些不太正确的光照还原。
Dominant Directional Irradiance
该方法的原理可以是看作将采样点半球空间中的辐照信息处理为一个方向光(Directional Irradiance),这样在实时渲染中就可以使用反射模型进行快速还原;其中的Dominant axis就可以看作是指该平行光的方向。其操作如下:
- 外理采样点外部辐照信息为:方向光(方向:L,颜色:CL);
- 渲染中直接反射模型模型来还原 。
比如使用Lambert模型时对应的还原计算为:

另外,一般情况下也会使用方向贴图的空闲的Alpha通道来存储一个缩放因子,用其来控制该点上外部辐照度的方向性(即被dominant方向影响的力度)。当然,这里也可以使用其它更复杂的一些shading model来操作,不过Lambert已经足够了。该方法的计算量相对也比较小;存储空间也比较节省,只需要在传统LM的基础上再存储一张方向贴图就可以了(目前来说该方法较为流行,比如UE或Enlighten中就使用此方法)。
Spherical Harmonics
该方法与Radiosity Normal Map的方法类似(同样与Light Probe的原理类似),只不过这里使用了理论与数学依据更为充分的球谐函数来实现外部辐射照度信息的压缩与重建:
- 把光照函数使用球谐函数进行变换存储(压缩);
- 实时渲染中使用时直接利用SH重建进行还原即可(还原)。
这种方法比上述两种方法都更为高级,一般来说对于任意Normal上的照度信息都能正确还原,而且适应性较强,较为灵活;但同时有很大的缺点那就是存储空间较大(其LM中每个Pixel中存储的数据量相当于一个Light Probe对应的存储的内容),因而其应用范围就有所限制。
下述是LM与DLM的简单效果对比,差异还是相当明显的:


http://blog.csdn.net/bugrunner/article/details/7881819
这个东西很顺利,仅用了半小时就找到了方法,最应该感谢的还是Super TuxKart(简称STK,下面就都用这三字母了). 如果不明白STK,同时又对它感兴趣的童鞋,可以访问这里
http://supertuxkart.sourceforge.net/
由于墙的原因,需要各位搭梯子。
上周末,在弄换装的时候,发现irrlicht引擎本身是不支持硬件蒙皮的,多少令人有些失望。 心里就一直寻思着怎么扩展一下,将它弄出来。
值得说明的是STK对irrlicht引擎的用法是很简单的,基本上可以说是裸用,并未在irrlicht接口上做修改。 而是对外进行了一些必要的扩展。
当然,STK也对外开放了一个irrlicht.dll,说是修改了其中的BUG。 但直接使用irrlicht是可以的。
废话不多说,来说说如何不修改irrlicht一行代码,通过外部扩展来实现硬件骨骼动画吧
首先,能够使我们不修改irrlicht代码的原因,是因为ISkinnedMesh提供了一个setHardwareSkinning接口,默认为false.
虽然这个接口的说明是"(This feature is not implemented in irrlicht yet)”,但并不代表,设置与不设置无差别。
查看代码可以发现,当你设置了这个为true以后,irrlicht就完全不管你的动画了。 意思就是,要是你非要让我干我不干不了的事,那就只有您另请高明了。
irrlicht连CPU计算都不会参与。 这正好让我们有机可乘,完全用GPU接管。
而要让一个顶点参与骨骼计算,那骨骼索引则是少不了的。所以,我们需要想办法让顶点数据能够将骨骼索引代入SHADER中。
在STK中用了一种巧妙的方法, 就是使用了顶点的颜色数据, 虽然这样一来,顶点颜色就用不了了。 但在模型渲染时,顶点颜色很少被使用到的。 也就是说,顶点颜色在STK的动画模型中,被用作了骨骼索引。
初始化骨骼索引的方法很简单,用下面的代码遍历即可。
设:我们有一个骨骼动画模型是 ISkinnedMesh* pSkinnedMesh = …
那么:初始化代码如下
for(u32 i = 0;i < pSkinnedMesh ->getMeshBuffers().size();++i)
{
for(u32 g = 0;g < pSkinnedMesh ->getMeshBuffers()[i]->getVertexCount();++g)
{
pSkinnedMesh ->getMeshBuffers()[i]->getVertex(g)->Color = video::SColor(0,0,0,0);
}
}
//初始化完毕以后,就是需要真正的索引赋值了,通过以下代码可以完成
const core::array<scene::ISkinnedMesh::SJoint*>& joints = pSkinnedMesh ->getAllJoints();
for(u32 i = 0;i < joints.size();++i)
{
const core::array<scene::ISkinnedMesh::SWeight>& weights = joints[i]->Weights;
for(u32 j = 0;j < weights.size();++j)
{
int buffId = weights[j].buffer_id;
int vertexId = pSkinedMesh->getAllJoints()[i]->Weights[j].vertex_id;
video::SColor* vColor = &pSkinedMesh->getMeshBuffers()[buffId]->getVertex(vertexId)->Color;
if(vColor->getRed() == 0)
vColor->setRed(i + 1);
else if(vColor->getGreen() == 0)
vColor->setGreen(i + 1);
else if(vColor->getBlue() == 0)
vColor->setBlue(i + 1);
else if(vColor->getAlpha() == 0)
vColor->setAlpha(i + 1);
}
}
//经过以上两个步骤,顶点数据改造完成。 值得注意的是, 在这里, 索引 0 是被认为是无效的
然后,我们来创建一个SHADER作为渲染。
假设 我们将这个pSkinnedMesh绑定了到了一个IAnimatedSceneNode* node 上。
那,我们为这个结点创建一个材质 在创建材质前,我们需要准备一个SHADER回调。 SHADER回调就像下面一样就可以了。
class HWSkinCallBack:public video::IShaderConstantSetCallBack
{
scene::IAnimatedMeshSceneNode* m_pNode;
public:
HWSkinCallBack(scene::IAnimatedMeshSceneNode* node):m_pNode(node)
{
}
virtual void OnSetConstants(video::IMaterialRendererServices* services,
s32 userData)
{
scene::ISkinnedMesh* mesh = (scene::ISkinnedMesh*)m_pNode->getMesh();
f32 joints_data[55 * 16];
int copyIncrement = 0;
const core::array<scene::ISkinnedMesh::SJoint*> joints = mesh->getAllJoints();
for(u32 i = 0;i < joints.size();++i)
{
core::matrix4 joint_vertex_pull(core::matrix4::EM4CONST_NOTHING);
joint_vertex_pull.setbyproduct(joints[i]->GlobalAnimatedMatrix, joints[i]->GlobalInversedMatrix);
f32* pointer = joints_data + copyIncrement;
for(int i = 0;i < 16;++i)
*pointer++ = joint_vertex_pull[i];
copyIncrement += 16;
}
services->setVertexShaderConstant("JointTransform", joints_data, mesh->getAllJoints().size() * 16);
}
};
好了,现在我们来创建一个材质
s32 hwskm = gpu->addHighLevelShaderMaterialFromFiles(
"../../skinning.vert","main",video::EVST_VS_2_0,
"","main",video::EPST_PS_2_0,&hwc,video::EMT_SOLID);
//用新创建出来的材质赋值给这个结点
node->setMaterialType((video::E_MATERIAL_TYPE)hwskm );
//到此,设置完毕。
//最后,就是skinning.vert本身的内容了。 贴出来即可,没有太多技巧,就是一个普通的蒙皮。
// skinning.vert
#define MAX_JOINT_NUM 36
#define MAX_LIGHT_NUM 8
uniform mat4 JointTransform[MAX_JOINT_NUM];
void main()
{
int index;
vec4 ecPos;
vec3 normal;
vec3 light_dir;
float n_dot_l;
float dist;
mat4 ModelTransform = gl_ModelViewProjectionMatrix;
index = int(gl_Color.r * 255.99);
mat4 vertTran = JointTransform[index - 1];
index = int(gl_Color.g * 255.99);
if(index > 0)
vertTran += JointTransform[index - 1];
index = int(gl_Color.b * 255.99);
if(index > 0)
vertTran += JointTransform[index - 1];
index = int(gl_Color.a * 255.99);
if(index > 0)
vertTran += JointTransform[index - 1];
ecPos = gl_ModelViewMatrix * vertTran * gl_Vertex;
normal = normalize(gl_NormalMatrix * mat3(vertTran) * gl_Normal);
gl_FrontColor = vec4(0,0,0,0);
for(int i = 0;i < MAX_LIGHT_NUM;i++)
{
light_dir = vec3(gl_LightSource[i].position-ecPos);
n_dot_l = max(dot(normal, normalize(light_dir)), 0.0);
dist = length(light_dir);
n_dot_l *= 1.0 / (gl_LightSource[0].constantAttenuation + gl_LightSource[0].linearAttenuation * dist);
gl_FrontColor += gl_LightSource[i].diffuse * n_dot_l;
}
gl_FrontColor = clamp(gl_FrontColor,0.3,1.0);
ModelTransform *= vertTran;
gl_Position = ModelTransform * gl_Vertex;
gl_TexCoord[0] = gl_MultiTexCoord0;
gl_TexCoord[1] = gl_MultiTexCoord1;
/*
// Reflections.
vec3 r = reflect( ecPos.xyz , normal );
float m = 2.0 * sqrt( r.x*r.x + r.y*r.y + (r.z+1.0)*(r.z+1.0) );
gl_TexCoord[1].s = r.x/m + 0.5;
gl_TexCoord[1].t = r.y/m + 0.5;
*/
}
//注:这是GLSL 2.0, 在用IRR做测试的时候,要选GL驱动方式。
还是上个图吧,不上图感觉没有真像。 虽然图看不出来什么动作

为了说明它真的在动,不得不上第二张。

在此,十分感谢Super Tux Kart. 提供了一个学习和扩展irrlicht的榜样.
看了看时间,已经3点过了,突然想写点什么,却又不知从何说起。
那就从今天这个用irrlicht做天龙八部的模型换装说起吧。
也不知道是为什么,最近又捣鼓起了OGRE和irrlicht. 并且,总想用irrlicht实现一些OGRE中的东西。
当然,这不是商业项目,也没有商业目的,纯属蛋疼而已。
一切行动的由来,都来自于vczh那天晚上的举动。
记得有一天晚上在群里聊天,大伙就称赞各位菊苣是多么的厉害。
最后vc发了一个自己的桌面截图说:让你们看看菊苣是如何练成的(这不是原话,和话的字眼有出入,在此不想负任何责任,如果真有想看的,去翻群的聊天记录)
那天晚上,我想了很久。想想自己自从转做页游以后,是如何虚渡光阴的。
终于忍不住了,翻开了自己的移动硬盘,看看自己曾经做过的小东西。90%是建好工程就没理了。
这才明白,我花在思考上的时间远远大于了行动。 于是,我决定改变自己,找回那个真的我。
3D游戏是我的真爱, 真爱到就算画面差一点,只要是3D,我也会很喜欢。
于是,我觉得自己还是应该接着先前的路走下去。 什么服务器,什么 AS3. 都是浮云, 不喜欢就是不喜欢。
私下又开始研究irrlicht了。
猛地一发现,自己是多么的搞笑, 从09年到11年,一直在做引擎开发, 也翻过irrlicht和ogre无数遍。 却从来就没有写完过一个完整的DEMO。
连功能测试用例都没有写过。突然觉得之前的一些设计似乎有些脱离了实际。没有真正使用过,又怎知如何是好,如何是坏呢?
这一次是真的玩irrlicht了, 中间也纠结过是不是OGRE更适合。 但在目前这个时间有限的空间下,我更愿意玩irrlicht.小巧,轻便。 当然,意味着更多东西要自己实现。 不过对于一个代码控来说,也反而更自得其乐。 正好可以在短路的时候,去参考一下其它引擎,用来扩充irrlicht.
我要做的不是把irrlicht整得牛B,而是想自己弄弄,加上移动平台的崛起,我觉得irrlicht更加适合吧。 据说gameloft也有使用(仅是据说)。
可能很多兄弟会说我这讲的东西,其实就是一坨屎了。 不过,我觉得再坏的评论,也表示一种关注。 批评好过于无视啊~~~~
----------------------------------------------------------下面说说我遇上的纠结------------------------------------------------
纠结1:换装需要场景节点配合
在irrlicht中,并没有提供普通引擎中的submesh或者bodypart这种东西,用于直接支持换装。 在irrlicht中,如果想要换装,最直接的方法就是依赖于场景结点
比如,在我的示例中,可以更换头发,帽子,衣服,护腕,靴子,面容。 那就需要7个场景节点,1个作为根节点,用于控制整个角色的世界坐标,平移,缩放,旋转等属性。另外6个场景节点则分别绑有各个部件的模型
贴一下我的角色类的代码,行数不多
class CCharactor
{
IrrlichtDevice* m_pDevice;
IAnimatedMeshSceneNode* m_pBodyParts[eCBPT_Num];
ISceneNode* m_pRoot;
public:
CCharactor(IrrlichtDevice* pDevice)
:m_pDevice(pDevice)
{
memset(m_pBodyParts,0,sizeof(m_pBodyParts));
m_pRoot = pDevice->getSceneManager()->addEmptySceneNode(NULL,12345);
}
void changeBodyPart(ECharactorBodyPartType ePartType,stringw& meshPath,stringw& metrialPath)
{
ISceneManager* smgr = m_pDevice->getSceneManager();
IAnimatedMeshSceneNode* pBpNode = m_pBodyParts[ePartType];
IAnimatedMesh* pMesh = smgr->getMesh(meshPath.c_str());
if(pMesh==NULL)
return;
if(pBpNode==NULL)
{
pBpNode = smgr->addAnimatedMeshSceneNode(pMesh,m_pRoot);
m_pBodyParts[ePartType] = pBpNode;
}
else
{
pBpNode->setMesh(pMesh);
}
ITexture* pTexture = m_pDevice->getVideoDriver()->getTexture(metrialPath.c_str());
if(pTexture)
pBpNode->setMaterialTexture(0,pTexture);
}
};
//然后,我用了一个结构体来构建部件信息
struct SBodyPartInfo
{
stringw Desc;
ECharactorBodyPartType Type;
stringw MeshPath;
stringw MeterialPath;
};
纠结2:共享骨骼
首先,irrlicht 1.8中对OGRE模型的格式支持在代码中,最高只看到了1.40版本的解析,更高的就会被无视。 天龙八部的模型有几个是1.30的,而用于换装和主角的,都是1.40的。 可能是解析不全的原因,导致1.40的骨骼动画无法正常播放。 这个问题整了几个小时,没有解决,明天继续
其次,多个模型共享骨骼只能通过场景节点的useAnimationFrom来完成,并且传入的是一个Mesh参数。这点让人蛋疼, 天龙八部的角色动作是分开了的,不同的攻击动作是一个skeleton文件。 想要实现共享,有点麻烦。
纠结3:模型文件格式
irrlicht不像OGRE那样有一个强大且成熟的模型文件格式,虽然提供了.irr格式,但仅是用于irrEdit的场景信息输出。先看一张图

这张图是irrlicht samples中的MeshViewer的提示框内容。 上面列出了可以支持的模型文件类型。 大家可以看看,又有多少模型格式是可以直接拿来放到项目上用的呢? mdl和ms3d可以考虑,dae的话,我在开源游戏0 A.D. 中见到使用过。 其它的话,就完全不熟悉了。 OGRE的 .mesh支持也不完全。 难道真要自己整一个。
我能想到的,就是选一个插件完整和模型和动画格式都比较好的作为与美术工具交互的格式。 自己再写一个工具,转换成自己的格式。
纠结4:硬件蒙皮
我以为像NIKO那样的技术狂,怎么会放掉这一个特性。 很高兴地在场景节点上发现了硬件蒙皮的函数接口。但一看注释,把我咽着了。
//! (This feature is not implemented in irrlicht yet)
virtual bool setHardwareSkinning(bool on);
其它地方,还没有去整,就先不发表言论了。 继续着这个很傻B,很天真的捣鼓之路。
上个图,纪念一下我的irrlicht产物。
布衣

换了身盔甲

换了帽子和靴子

PS:头发没有纹理,所以是白的。
今天在查看EPOLLET和EPOLLLT的细节的时候,发现一篇文章。 但不知文中说的是否有道理,望各位大大给个明确的答复。
游戏服务器,我们用的是ET方式。
平时大家使用 epoll 时都知道其事件触发模式有默认的 level-trigger 模式和通过 EPOLLET 启用的 edge-trigger 模式两种。从 epoll 发展历史来看,它刚诞生时只有 edge-trigger 模式,后来因容易产生 race-cond 且不易被开发者理解,又增加了 level-trigger 模式并作为默认处理方式。
二者的差异在于 level-trigger 模式下只要某个 fd 处于 readable/writable 状态,无论什么时候进行 epoll_wait 都会返回该 fd;而 edge-trigger 模式下只有某个 fd 从 unreadable 变为 readable 或从 unwritable 变为 writable 时,epoll_wait 才会返回该 fd。
通常的误区是:level-trigger 模式在 epoll 池中存在大量 fd 时效率要显著低于 edge-trigger 模式。
但从 kernel 代码来看,edge-trigger/level-trigger 模式的处理逻辑几乎完全相同,差别仅在于 level-trigger 模式在 event 发生时不会将其从 ready list 中移除,略为增大了 event 处理过程中 kernel space 中记录数据的大小。
然而,edge-trigger 模式一定要配合 user app 中的 ready list 结构,以便收集已出现 event 的 fd,再通过 round-robin 方式挨个处理,以此避免通信数据量很大时出现忙于处理热点 fd 而导致非热点 fd 饿死的现象。统观 kernel 和 user space,由于 user app 中 ready list 的实现千奇百怪,不一定都经过仔细的推敲优化,因此 edge-trigger 的总内存开销往往还大于 level-trigger 的开销。
一般号称 edge-trigger 模式的优势在于能够减少 epoll 相关系统调用,这话不假,但 user app 里可不是只有 epoll 相关系统调用吧?为了绕过饿死问题,edge-trigger 模式的 user app 要自行进行 read/write 循环处理,这其中增加的系统调用和减少的 epoll 系统调用加起来,有谁能说一定就能明显地快起来呢?
实际上,epoll_wait 的效率是 O(ready fd num) 级别的,因此 edge-trigger 模式的真正优势在于减少了每次 epoll_wait 可能需要返回的 fd 数量,在并发 event 数量极多的情况下能加快 epoll_wait 的处理速度,但别忘了这只是针对 epoll 体系自己而言的提升,与此同时 user app 需要增加复杂的逻辑、花费更多的 cpu/mem 与其配合工作,总体性能收益究竟如何?只有实际测量才知道,无法一概而论。不过,为了降低处理逻辑复杂度,常用的事件处理库大部分都选择了 level-trigger 模式(如 libevent、boost::asio等)
结论:
• epoll 的 edge-trigger 和 level-trigger 模式处理逻辑差异极小,性能测试结果表明常规应用场景 中二者性能差异可以忽略。
• 使用 edge-trigger 的 user app 比使用 level-trigger 的逻辑复杂,出错概率更高。
• edge-trigger 和 level-trigger 的性能差异主要在于 epoll_wait 系统调用的处理速度,是否是 user app 的性能瓶颈需要视应用场景而定,不可一概而论。
欢迎就此话题进行深入调研、讨论!
参考资料:
• linux kernel source:fs/eventpoll.c
• “Comparing and Evaluating epoll, select, and poll Event
Mechanisms”:http://bcr2.uwaterloo.ca/~brecht/papers/getpaper.php?file=ols-2004.pdf
• “Edge-triggered interfaces are too difficult?”:http://lwn.net/Articles/25137/
By QingWu
ID Tech 5 中"Megatexture"针对地形的D3D9
基本实现原理
姚勇
H3D
2007-8
本文对ID SOFTWARE 使用的"megatexture"技术,针对地表贴图应用的D3D9 的硬件实
现,做了概要式的介绍。并对技术的实现,优化,扩展,和实用性进行了刨析。转载请注名
作者和H3D。
一,综述
ID TECH5是PC 3D游戏之父和DOOM之父John Carmack最新推出的一项新的游戏制作
技术。核心内容为一种命名为"Megatexture"的动态贴图管理技术。实际上是一种动态卸载和
装载渲染资源的技术统称。Idsoftware DOOM3引擎的lighting/shadow/shader方案统一以后,
同UNREAL3一样,面对次世代游戏对资源的无穷尽需求,需要尽快建立起一种实际工程技术
方案,加快构建3D虚拟现实的生产。

图片来源:Quake Wars
这个技术最主要方向就是要把VR3D建造从有限的显卡内存中释放出来。把美术从繁重
的贴图重用绘制中解脱出来。因为VR3D主要资源消耗都在贴图上,所以这个技术主要针对
texture。同时geometry也可以作为动态资源。一旦rendering相关资源作为动态流进行管理,
所带来的另一个好处就是可以让VR世界变为动态的。随时改变texture/geometry。
总得来讲,ID这项针对工程应用技术主要致力于解决:1-3DVR资源需求的爆炸增长和
有限显卡显存的矛盾;2-美术资源需求的爆炸增长,以及生产力低、成本高昂的矛盾
在ID TECH5演示中,实时演算播放了一个细节非常丰富的室外地形,同时结合了一个
小型的室内场景。所有模型和贴图制作,按照Carmack介绍,只让几个美术花了4天时间。
就制作出20G的游戏美术资源。而游戏引擎负责把几十G的资源动态装载到显卡进行渲染。
本文就以下几个问题做初步讲述:1,综述地形渲染以及贴图技术;2,Clipmap介绍;
3,基于D3D9的解决方案描述;4,优化和扩展;5,方案可行性
1-1
,
Mega
Texture
Megatexture 的具体实现,在DOOM3 中的地形绘制已经加入。具体实现细节简单描述
如下:
DOOM3 的地形贴图最大支持32768x32768 。即5.46 G。在DOOM3 中,以128x128
大小的块进行储存便于快速读取。以最大2048x2048 的clipmap 尺寸进行处理。其实可以计
算出在D3D9 标准的显卡上,normalmap+6 clipmap stack 的最大理论支持贴图数据大小为
(2048 * 2^6 )^2 *4= 68T bytes. 这个大小针对现在的PC 硬盘是绰绰有余的。
DOOM3 使用这张全局metatexture 纹理渲染地形,不使用LOD,GEOM-MORPHING。
1-2
,
传统
地形贴图渲染
当使用Tiling 方式绘制贴图,等于把贴图图素(texel)密度成倍扩大。以重复纹理信息量
的代价保证在一定分辨率下屏幕上贴图的精细程度。在绘制大范围地形时,使用不Tiling 的
全局贴图无法表现贴地处的地表细节。所以使用一些可以重复(Tiling)的不规则图案的贴图
来进行模拟。
1-2-1
Tiling
地形贴图
由于地形贴图尺寸很大,所以无法使用全局贴图。而是把多层Tiling 的纹理使用alpha
通道互相融合起来。诸如WOW[1],天堂2 等大型室外地形渲染多采用此技术。此技术在每
一层Tiling 贴图依然用到了一张全局alpha 贴图。以及一张全地形唯一的静态光影贴图。在
multitexture 中根据显卡的multitexture 处理单元数量,进行multi-pass 和multitexture 的混合
渲染。
比如,混合绿草,土路,野花的一块室外地形,需要至少3 层地表贴图。分别是一块
256x256 的草贴图,128x128 的土路贴图,和128x128 的野花贴图。每层纹理使用Tiling 模
式进行绘制,在绘制的同时,每层纹理带有一张ALPHA 灰度图(第一层不用)。用来表明
本层纹理在融合中所占的比重。把3 张地表贴图,2 张ALPHA 贴图,以及一张LIGHTMAP
贴图混合起来,就有如下地表效果。可以看出土路和草地之间的均匀过渡。

图片来源:H3D
如果进行优化,4 层ALPHA 可以混合称为一张贴图。Lightmap 一张。那么也至少需要
2 张全局贴图进行地表绘制。
1-2-2
全局地表纹理混合Tiling
细节贴图[2]
在更大广度的地形渲染,有时候需要一种更加快速的方法。在FAR CRY 引擎中,使用
了这个技术。简单描述为,使用一张全局地表纹理,渲染地表所有植被和光影信息。在离视
点近的范围内,使用一张表现当地地表细节的贴图,以Tiling 方式进行融合叠加。这样在细
节度上,以Tiling 方式的贴图以高细节图素纹理,掩盖了下面那一层全局贴图的粗糙颗粒。
总的来讲,分层Tiling Alpha 混合地表贴图,和全局地表混合Tiling 细节贴图,两种方
法都是靠贴图的Tiling 来增大视点附近贴图图素的密度。防止比屏幕分辨率小的2 图素之间
进行线性差值。影响真实感。
二,Clip
maps
基本介绍
针对受显卡显存制约,无法使用大尺寸贴图进行绘制,1998年SGI公司发表了一篇名为
<The Clipmap: A Virtual Mipmap>[3]的论文。论文里详细阐述了一种以有限硬件性
能,来实现相对无限大贴图的渲染。论文是一整套硬件与软件结合的方案。它可以实现以一
平方米一个图素,用单一贴图进行整个地球表面的渲染。并且结合硬件数据传输带宽,以及
相应优化方法,鲁棒的保证以任意速度漫游时保持在60Hz(针速率)。下面先对此技术做一定
简要介绍。在第三节给出基于D3D9硬件的解决方案思路。下图为Clipmap实现的美国国家地
图实时漫游的一小部分。美国约塞米蒂国家公园(Yosemite National Park)南部的一半。整个
美国使用一张170G的贴图。在显卡中的clipmap贴图缓存为16M。这个贴图内存用量在今天
的PC硬件上是完全可以实现的。

图片来源:<The Clipmap: A Virtual Mipmap>
2-1
,
Mipmap
工作原理及其分析
我们先从mipmap[4]工作原理分析开始。如图:

图片来源:<The Clipmap: A Virtual Mipmap>
Mipmap 的工作原理是,把一张贴图按照2 的倍数进行缩小。直到1X1。把缩小的图都
储存起来。在渲染时,根据一个象素(pixel,注意pixel 和texel 区别。Pixel 是屏幕上一个点。
Texel 是贴图上一个图素)离眼睛位置的距离,来判断从一个合适的图层中取出texel 颜色赋
给象素。D3D 和OGL 都有想对应的API 控制接口。如下图

图片来源:<The Clipmap: A Virtual Mipmap>
通过观察mipmap 工作原理我们可以发现,硬件总是根据眼睛到目标的距离,来选取最
适合当前屏幕象素分辨率的图层。假设有一张32768x32768 mipmap 贴图。当前屏幕分辨率
为1024×1024。眼睛距离物体比较近时,mipmap 最大也只可能从1024×1024 的mipmap
图层选取texel。再次,当使用三线性过滤(trilinear)时,最大也只访问到2048x2048 的图层选
取texel,来和1024x1024 图层中的图素进行线性插值。
这样一个基本事实告诉我们,在使用任何尺寸贴图渲染任意距离的物体时,贴图采样只
会用到不大于屏幕分辨率2 倍的mipmap 层。根据这个事实,我们可以创建clipmap 对大尺
寸贴图进行渲染时的优化。
2-2
,
Clipmap
原理
2-2-1
Clipmap
构建
在原始clipmap 论文中,clipmap 在显卡内存中的构建如图:

图片来源:<The Clipmap: A Virtual Mipmap>
Clipmap Pyramid(clipmap 棱椎)是我们PC 显卡中常见的mipmap 形式。Clipmap Stack
是不同于mipmap 实现的地方。横线绘制的棱锥代表完整贴图的mipmap 形式。但是在显存
中,大于clipmap Pyramid 最高层尺寸的贴图,都以clipmap pyramid 尺寸存放,但是相应的,
clipmap stack 中的贴图代表的原始贴图面积,一层比一层小。比如clipmap pyramid 最大
2048x2048。在之上一层,mipmap 表达是4096x4094 图素。在clipmap stack 中,还是储存
2048x2048 大小的贴图。显然此代表的就是mipmap 尺寸4096 的一半边长,即原始面积的
1/4大小。依次推上去,每层都是下层代表面积的1/4。Clipmap pyramid最大边长即为Clip
size
。
Clipmap 贴图的中心点,在整张贴图的位置坐标,我们称为ClipCenter
。ClipCenter 由
当前摄像机在整个世界中的相对位置来决定。
实际中,目前D3D9 级别的PC 显卡硬件并不支持这种储存形式的mipmap。具体实现
方法将在第三章讲解。
2-2-2
渲染Clipmap
在渲染中,针对一个Pixel,根据当前Pixel,找到相应的clipmap 层,如果处于clipmap
pyramid,直接按照mipmap 传统方式采样取图素。如果处于clipmap stack,则把贴图坐标根
据当前clipmap stack 代表整体面积的比例,进行缩放,得到对应位置图素。这样就可以正确
渲染屏幕上的任意物体。如下图:

图片来源:<The Clipmap: A Virtual Mipmap>
把CLIPMAP 所有图层绘制出来,从正上方看,就是象北京二环内,二环,三环,四环
为分割。绘制中心区域的贴图分辨率最大,但是代表的面积最小。绘制最外围四环之外的贴
图分辨率最小。是因为到了clipmap pyramid 层,一层就代表一张全局贴图。但是分辨率已
经被缩小了很多倍。而分辨率最大的clipmap stack 顶层,由于尺寸必须保持clipmap pyramid
的最大尺寸,所以所代表的面积就小了很多。这种折中正是由于基于绘制屏幕上的任何物体
都不可能使用大于屏幕分辨率的贴图尺寸,所以在显存中只提供刚刚满足绘制在一针内,从
一个视点看过去的所有场景(地形)分辨率的贴图内容。
2-2-3
clima
p
LOD
计算以及每层贴图坐标计算
给定一个根据ClipCenter换算过的贴图坐标,下面需要计算出在屏幕上的一个物体的象
素,从clipmap中选取一层,索引贴图图素。由mipmap LOD(LOD数在本文用俗称层数描述)
计算公式得知,clipmap LOD计算和mipmap一样。并且可以保证任意pixel计算出来的climap
层必然落在clipmap stack中。一般PC 3D显卡硬件计算都采用Heckbe算法。简单描述如下:
LOD = log2[f(x, y)]; f(x,y)为屏幕x,y轴方向贴图坐标变化率的最大值。贴图坐标变
化率计算由屏幕象素X,Y坐标分别递进一个象素单位的变化投影到贴图坐标系得出。具体描
述参考[5]。
2-3
,存储效率
Clipmap由于采用clipmap stack和clipmap pyramid结合的方式,使用clipsize为2^m的
clipmap,把一张2^n边长贴图容量从(4n+1 - 1)/3 字节下降为4m(n - m + 4/3) - 1/3 字
节。更具体的数据如下:
类型/边长512 1024 4096 32768 67108864
Full Mipmap 682KB 2.7MB 42.7MB 2.7GB 10923TB
512 Clipmap 682KB 1.1MB 2.2MB 3.7MB 9.1MB
1024 Clipmap 682KB 2.7MB 6.7MB 12.7MB 34.7MB
2048 Clipmap 682KB 2.7MB 18.7MB 42.7MB 131.7MB
可见clipmap极大降低了显卡内存对渲染超大容量贴图的要求。目前D3D9的主流显卡从
128M到256M不等。在1024的Clipsize下,几乎所有显卡都可以满足要求。
2-4
,绘制整个地球表面的方案
--
虚拟
clipmap
(简述)
当绘制国家或者星球表面这样规模的实时渲染时,整张贴图尺寸为2^26 的平方。这样
一来,需要在显卡硬件内部计算的工作,诸如贴图坐标换算等都难以在精度为IEEE 32
FLOAT 下正确进行。
在原有clipmap 基础上,在U,V 方向加入一个坐标偏移向量。在clipmap stack 的纵向方
向,加入一个偏移数值。形成如下图解构:

图片来源:<The Clipmap: A Virtual Mipmap>
系统只要能够保证从图中的3 种情况中正确寻址,就能够保证超大贴图的clipmap 渲染。
三,基于D3D9
的简化实现
从之前对Clipmap 的描述中可以看出。现代D3D9 显卡具备了渲染clipmap 的大部分功
能。唯一欠缺的是clipmap stack 的模拟。因为clipmap pyramid 就是一张标准的mipmap 贴
图。所以D3D9 只要能够把clipmap stack 模拟出来,使用shader model3 可以很容易的实现
clipmap。
3-1
,
Multitexture
我们利用显卡硬件的multitexture 模拟clipstack。这是D3D9 简化实现的最基本思想。
PC 显卡支持clip pyramid。在pixel shader 中,如果想利用clipmap stack,就必须有某种途径
让pixel shader 使用除了clip pyramid 之外的贴图。自然我们想到了使用multitexture。D3D9
标准显卡应该支持最少8 层纹理单元(不支持的硬件很快会绝迹,所以可以不考虑)。假设
我们不使用法线贴图进行凹凸象素光照。
使用第8 层装载clip pyramid,使用2048x2048 32bit DDS 贴图。从第一层到第七层我们
都可以使用clip stack 贴图。这样,分别装载4096, 8192, 16384,32768,65536,131072,262144 边
长mipmap 的clipmap。每一层占用2048x2048*4*/4*1.33 /1024 /1024 = 5.32Mb 。这样一共8
层贴图总共43MB 贴图显存,可以容纳一张274TB 的贴图。当我们使用每层1024×1024
贴图时,使用12MB 显存就可以模拟68TB 的贴图。显然对于游戏来讲绰绰有余。注意这
里只是简化计算,没有把trilinear 考虑进去。
3-2
,
Toroidal addressing
在第四章我们将考虑优化和动态管理clipmap。我们知道用MULTITEXTURE 模拟的
clipmap 只是当前视角观察的贴图用量。当摄像机移动时,clipmap 的贴图组必须同时更新。
除了最底层clipmap pyramid 贴图不用更新,其他几张clipmap stack 贴图必须根据摄像机移
动,改变ClipCenter 位置。然后从磁盘上把clipcenter 周围的贴图调入。这涉及到显存写入
问题。可以想见当所有clipmap stack 贴图同时频繁装载总共十几MB 容量的内存,对于磁
盘IO 和显存带宽都是极大考验。所以针对clipmap 更新特点,在贴图寻址方面采用wrap 循
环寻址。然后对贴图的更新采用如下方式:


图片来源:NVSDK
3-
3,
p
ixel
shader
实现思想概要
由于有了第二章climpa 渲染的大概描述,以及前两节关于clipmap stack 和贴图寻址方
式,我们利用shader model 3 的pixel shader 功能可以直接实现具体算法。描述如下:
1,计算mipmap LOD。
2,计算光照
3,假如应该采样clipmap pyramid,直接采样,混合光照,完成
4,假如应该采样clipmap stack 贴图,重新计算贴图坐标
5,根据mipamapLOD 选择相应的stack 贴图。采样,混合光照,完成
首先,计算mipmap LOD。这里可以采用三线性插值。
例如:
PSOut PS_Trilinear(PSIn input)
{
PSOut output;
float2 dx = ddx( input.texCoord * g_TextureSize.x );
float2 dy = ddy( input.texCoord * g_TextureSize.y );
float d = max( sqrt( dot( dx.x, dx.x ) + dot( dx.y, dx.y ) ) , sqrt( dot( dy.x, dy.x ) +
dot( dy.y, dy.y ) ) );
// 计算出
float mipLevel = log2( d );
float blendGlobal = saturate(g_StackDepth - mipLevel);
float4 color0 = PyramidTexture.Sample( samplerLinear, input.texCoord );
If (blendGlobal)//如果使用了全局clipmap pyrimad,及早退出
{
output.color = color0;
}
Else
{//使用了clipmap stack 贴图,计算贴图坐标,然后动态分支判断应该采样第几层
贴图
// This fractional part defines the factor used for blending
// between two neighbour stack layers
float blendLayers = modf(mipLevel, mipLevel);
blendLayers = saturate(blendLayers);
int nextMipLevel = mipLevel + 1;
nextMipLevel = clamp( nextMipLevel, 0, g_StackDepth - 1 );
mipLevel = clamp( mipLevel, 0, g_StackDepth - 1 );
// Here we need to perform proper scaling for input texture coordinates.
// For each layer we multiply input coordinates by g_ScaleFactor / pow( 2,
layer ).
// We add 0.5 to result, because our stack center with coordinates (0.5, 0.5)
// starts from corner with coordinates (0, 0) of the original image.
float2 clipTexCoord = input.texCoord / pow( 2, mipLevel );
clipTexCoord *= g_ScaleFactor;
//只是简单的双线性采样
if (mipLevel==0)
{
//use clipStackTexture0.Sample(...)
}
If (mipLevel ==1)
{
//use clipStackTexture1.Sample(...)
}
}
Return output;
}
3-
4,
D3D10 的实现【
7】
D3D10 引入了一种叫Texture Array 的功能。可以在pixel shader 中直接利用一个整
数下标来寻找所需要的贴图,然后进行采样。思路同上,只不过不用动态分支,直接进行数
组索引后采样。

图片来源:NVSDK
图中绿色部分就是texture array。
四,一些优化和扩展
Clipmap 在显存中的存在,只是应对某一个固定摄像机位置和角度的场景贴图需求。当
摄像机移动时,必须对clipmap 贴图进行更新。具体更新方法第三章已经提过。但是,在摄
像机每一针运动都使用磁盘IO 和阻塞渲染管道的内存搬运,是不具实用性的。所以在实用
中,必须对clipmap 动态更新进行高度优化。这也是此技术的核心所在。
同时,对clipmap 的一些扩展是为了增强游戏的表现力。以下4-6 到4-9 的扩展方面没
有进行任何实际论文和实例支持,只是一种对现有技术扩充的预想和估计。希望专家给与更
深入的建议。
4-1
,动态
clipmap
管理
Clipmap 的动态管理,必须满足几个条件。1,摄像机移动时的平滑实时渲染;2,不能
对摄像机的移动速度和位置有所限制;3,动态装载更新应该是外部不可见,自动进行的。
4-2
,
2
级
cache
由一般异步动态装载卸载应用技术得知,在大数据量进行从磁盘到内存的交换时,必须
有足够的缓冲。由于磁盘到内存,内存到显存的带宽大不一样,磁盘到内存比内存到显存慢
得比较多。所以,对于从硬盘到显卡内存的缓冲,需要存在至少2 步CACHE。
第一步,从磁盘到主内存的缓冲。对clipmap stack 贴图周边的图素,必须预先读入一些
到主存CACHE 中来。并且这个动作应该在整个游戏期间保持不停顿。预先读入的数据根据
玩家移动方向做一定预测。
在模拟星球表面的海量贴图库中进行更新,同时还要考虑不同磁盘阵列相应速度等等。
所以磁盘到主存的缓冲策略非常重要。
第二步,从主存装入内存,每次更新每个clipmap stack 贴图周边的半圈贴图内容。

图片来源:<The Clipmap: A Virtual Mipmap>
棕色区域是每次更新的内容。
4-3
,
多线程
IO
控制
在主循环中对贴图进行磁盘IO,解压,然后写入clipmap stack 贴图缓存,会同时阻碍
CPU 和GPU 的工作流水线。使得处理器停滞,影响效率。所以,对磁盘到主存的读取IO,
解压工作,可以放在另外一个线程中进行。写入贴图显存的工作由于本身会阻断D3D9 级别
显卡的流水线。但是,可以利用一些策略延缓一次性装入所有CLIPMAP STACK 贴图的并
发。这将在4-6 讲解。
4-1 中提到的摄像机平滑移动渲染,主要是指对clipmap stack 贴图更新的步骤一定要
短,不能极大幅度影响主渲染循环的执行。在固定带宽内,对clipmap stack 贴图边带更新的
数据量并不很大。基本可以保持一个平滑渲染的过程。
在WINDOWS 系统,使用无缓冲的异步IO 模式是最适合此应用的。且文件以硬盘簇大
小的整数倍放置,读取效率最快。
4-4
,
使用
MaxTextureLOD
在4-1 中提到,摄像机以任意速度移动,都不能影响渲染的平滑。我们采用如下策略。
1,当摄像机以设计速度移动时,clipmap 正常更新。
2,当摄像机超过设计速度,clipmap 更新速度无法赶上摄像机移动速度。则自动调整
max texture LOD。Max texture LOD 的意义是clipmap 工作在最高clipmap stack 的贴图层数。
这个参数同时影响clipmap upload 和渲染pixel shader 中stack 选取。降低最高细节stack 意
味着降低climap update 的负荷。
3 当出现极端情况时,所有clip stack 更新都赶不上camera 移动,则只使用clipmap
pyramid 贴图进行渲染。虽然图象贴图分辨率急剧下降,但是保证了camera 以任意速度漫游。
4-5
,对地形几何渲染扩展
--geometry
clipmap
参考GPU GEMS2 的geometry clipmap 介绍文章【6】。简单描述为:使用clipmap 进行
顶点生成。把高度图做为clipmap 进行更新,然后做为vertex texture 的源。用以生成地形网
格。这么做的好处是,地形网格削减被放入了climap 的LOD 过程中。而不用CPU 做任何
额外计算工作。并且支持相对无限大地形。动态地形改变。
4-6
,
double
clipmap
buffer
,无效边带
4-3 指出,使用多线程把磁盘IO 和解压缩,可以促进CPU 和GUP 协同工作。在对磁
盘文件进行预读取时有着极大好处。在对JPEG 进行分块读取和REALTIME 解压缩时,可
以在多核系统上获得额外的负载减轻。
Clipmap 原先的设计,存在一个叫无效边带的技术。它可以使得SGI 硬件底层一边渲染
一边进行边带的贴图更新。等于是主存到显存的第0 级CACHE。PC 和有的CONSOLE 显
卡不具备这样的功能。对于写入显存操作,都是把一张贴图显存LOCK 住,进行写入。在
这个期间此贴图无法进行渲染。但是受此启发,我们可以把CACHE 的粒度放为每层
CLIPMAP STACK 贴图。结合多线程与DOULBE BUFFER 思想,方法如下:
1,在需要创建clipmap stack 贴图时,对每层贴图创建一个BACK BUFFER。
2,在渲染CLIPMAP 同时,多线程进行另外一组stack texture 的更新。虽然可以预知假
如写入一张贴图要阻断整个GPU 工作管道的话,但是由于多线程把一组stack texture 按顺
序更新。所以避免了在主循环并发一次性更新整个stack texture array。如果显卡可以同时渲
染和写入back buffer 的话,则效率应该会提高。
3,每针渲染完毕,调换STACK BACK BUFFER 到前台。
这个方法DOULBE 了CLIPMAP 占用内存。但是在多核环境下,尤其显卡支持渲染时
并发写入贴图显存功能的话,CLIPMAP 更新效率会大大提高。内存的使用,前面进行过计
算,适合游戏的贴图,采用1024 大小的DDS CLIPMAP,显存占用不大。
4-7
,支持非
2
的
N
次方全局贴图
在游戏中,一个全局的世界如果只能是2 的N 次方大小,会极大限制美术工作。如果
是正方形世界,贴图只能是4G,16G,64G(都乘1.33)这个数量级别。考虑引入MxN 大小
的贴图。M 和N 都不是2 的幂。
我们在之上取任意一点P,k<Px<M-k, k<Py<N-k, k=2^q(q=1,2,...),k 为接近分辨率的一
个2 的幂整数。围绕P 建立一个边长为k 的正方形。以k 正方形为基础,创建clipmap。这
个clipmap 代表在P 点绘制需要的贴图内容。
随着摄像机移动,原先不用更新的clipmap pyramid 也需要根据ClipCenter 移动进行更
新。保持贴图棱锥还是以2 的幂进行更新。换句话说,除了clipmap stack 贴图更新,clipmap
pyramid 贴图以及其mipmap 层,都需要更新。
这样一来,我们就可以用clipmap 进行任意长宽世界贴图的渲染。
4-8
,
支持法线贴图进行象素级别光照
在ID TECH5 演示中,地表都具有凹凸贴图象素光照。在这里无法给出确切的实现方法。
只是尝试列出可能的实现方案。希望更进一步的探讨。
法线贴图同样使用一张全局贴图。
1, multipass 方法。使用第二张clipmap 装载法线贴图。
2, 在更新diffuse color clipmap 时,利用3 张clipmap stack 贴图的ALPHA 通道,
装载法线贴图的z,y,z。或者只装载x,y(在pixel shader 计算z)。然后在pixel shader
重组,进行光照计算。2 层stack clipmap 代表一层normalmap。我们只在近距离使用
normalmap,远处就用一个RGB(0.5,0.5,1)的蓝色象素代替。在超出clipmap stack 视野区
域使用mipmap 的trilinear 插值。
3, 使用clipmap 其中的一层或者两层装载法线贴图,因为远距离地形景物不需要象素
级别的光照。所以直接对近景进行象素光照即可。凹凸象素光照消失的地方使用一些三线性
插值,平滑过渡。
4-9
非地形应用
Clipmap 主要用于大规模地形渲染的贴图调度。在此基础上,对非地形场景的渲染,应
用clipmap 也称为可能。Clipmap 实际是对贴图数据库进行了一种线性组织和查找。可以根
据简单的x,y 坐标以及u.v 贴图坐标定位所需要贴图在clipmap texture database 的位置。地形
应用的天然方便之处在于,地形网格的空间位置本身就说明了其贴图纹理在clipmap texture
database 中的位置。
根据此思想,如果能够在场景中固定几何物体信息中标致好所在clipmap 数据库中的位
置。并且有效组织场景中的几何体贴图存放位置也和其世界空间位置相关。这样就能在几何
体与clipmap 之间建立起一种联系。随着摄像机的移动,clipmap 贴图不断更新,相应场景
中的物体就被赋上材质。当视角远离物体,此物体贴图不再被使用,从显存中清除。这样就
实现了非地形的海量几何物体贴图的clipmap 管理。
此思想只是停留在思考阶段。需要在今后的工作中实践。
五,是否值得
5-1
,地形渲染精度和容量
我们来计算一下实际游戏大概需要的贴图容量。
假设地形,高度图的一个象素代表一个格子。一个格子代表现实一米。屏幕分辨率
r=1024x1024。人眼离地面最低距离d=1 米。FOV=90。离地面最近距离为人眼直视下方。根
据透视关系,可以推算出在屏幕上2 米的格子将会撑满整个屏幕。
一张非TILING 的贴图,平铺在地下,我们可以计算出,如果需要屏幕的一个象素恰好
被一个贴图图素覆盖(mipmapLOD=0)。则需要2x2 的格子贴一张1024 非TILING 的贴图。
对于一个格子贴512 象素才不会被filter 进行插值模糊。这个贴图细节度是非常惊人的。
按这个计算, 要一张全局RGB24BIT 贴图贴满1 平方公里的区域, 就需要
1024*1024*512*512*3*1.33 字节= 1Tb 的RGB 贴图。粗略估计JPEG 大概为40-50G 之间。
但是1T 的海量贴图相当于一张1024x1024 图的26 万倍,这基本不太可能由美术手工完成。
而且,一公里的距离根本不足以表现大型世界。假设人站在512,512 的坐标,500 米的直
线距离,景物远远没有达到人眼视界之外。人眼在晴天看远处山脉可以有十几公里的视界。
就算在远处不用精细的贴图,但是人既然能够移动过去,那么必然要制作这么大范围的全局
贴图。利用512 象素代表一米显然是不现实的。
如果我们认为不需要那么高的精度。观察WOW,粗略估计可以接受的精度为,128-256
象素代表一米(WOW 基本为256)。我们计算人眼离地1 米时一个图素覆盖4 个象素插值的
情况:128*128*1024*1024*3*1.33 = 65G. JPEG 估计3G。4 平方公里就是48G。
对于付出如此巨大代价,在一平方公里之内,让美术进行了相当于一万六千多张
1024x1024 地图的手绘,实时渲染进行非常复杂的CACHE 和多线程异步操作,得到的效果
只是4 个象素模糊一个图素的图形细节。而且如果游戏想承载4 平方公里的地域,基本就已
经超出目前CONSOLE 和PC 能够接受一个游戏容量的范围。即便是蓝光,也快到达了极限。
而4 平方公里对次世代游戏来说,简直是九牛一毛。有很多游戏(CRYSIS)对于表现几十
平方公里都已经非常得心应手。数量也在几个G 之内。所以单纯使用clipmap 实现连续大型
地形渲染,以目前硬件容量,还是比较吃力。需要其他优化手段配合。
接下来计算贴图更新速度需求。假设人类行走1.5 米/秒.如果按照斜前方行走。1 米128
图素。Clipmap 为1024。Clipmap stack 为6 层。在一秒人类行走经过的地域,以1024 为边
界,正方形边带图素个数大约为1.5/sqrt(2) *128* 1024 * 2 = 2172Kb。1 秒钟需要更新的
图素内存为6x2172x3 = 39096Kb 。大约40MB。假设30Hz 刷新,一针里更新的数据为
39096/30 = 1.3Mb。一针一MB 的数据流量,也是非常客观。
5-2
,对传统地形渲染方法进行
STREAMING
5-1 节对使用全局贴图进行大范围渲染的数量和最小贴图传输量做了估计。接下来我们
看一下,应用clipmap 思想,传统地形渲染方法是否有可扩展的空间。
在1-2-1 和1-2-2 使用tiling 的两种地形渲染方法中,都提到要应用至少1-2 张全局地
表纹理贴图。在使用全局贴图绘制过程中,完全可以借鉴clipmap 的技术。把全局alpha 和
lightmap,或者全局diffuse 颜色图放入clipmap 管理。由于其他图层都是靠tiling 实现。理
论上可以实现贴图密度无限制,贴图大小无限制的全面解决方案。而制作全局diffuse 颜色
图和制作clipmap 全局图一样。Alpha map 靠手工绘制。Lightmap 可以自动生成。并不会比
只使用一张全局地形贴图麻烦多少。
六,结论
Clipmap 极大的释放了显存限制,把应用对贴图细节的无限增长需求转化为对clipmap
实时更新的技术解决方案。此应用不仅可以用于大规模地形渲染,也可以应用与大型场景中
固定几何物体的贴图管理。
Clipmap 可以做为一种空间和贴图数据库的对应管理系统。并且在象素级别进行LOD。
结合geometry clipmap 的应用,可以相对提高虚拟现实制作的生产力。
同时Clipmap 的更新成为了一个新的瓶颈。在PC 硬件架构上,需要极大精力进行更新
的优化。
另外,在对次世代游戏质量和渲染精度的标准下,对clipmap 采用全局世界纹理的可行
性做了分析,并提出了质疑。同时结合传统地形渲染方法,给出了与clipmap 相结合的可能
性。
来信请给puzzy4d@yahoo.com.cn,欢迎讨论。
索引
【1】WORLD OF WOLFCRAFT,http://www.wowchina.com, Blizzard,2004
【2】Far Cry, http://www.crytek.com/, Crytek,2007
【3】<The Clipmap: A Virtual Mipmap>,Christopher C. Tanner, Christopher J. Migdal, and Michael
T. Jones,Silicon Graphics Computer Systems,1998
【4】EWINS Jp,WALLER MD,WHITE M,et a1.MIP—Map Level Selection for Texture
Mapping[J].IEEE TRANSACTIONS ON VISUAIAZATION AND COMPUTE R GRAPHICS,
1998,4(4)
【5】Mipmap 映射技术中d 值计算方法的探讨,韩慧健,徐振中,张诚洁,计算机应用,第
24 卷第12 期,2004
【6 】Terrain Rendering Using GPU-Based Geometry Clipmaps,<GPU GEMS 2>,
Hoope,NVIDIA,2005
【7】NVIDIA, SDK10,clipmaps
http://wenku.baidu.com/view/d20b147e5acfa1c7aa00cc42.html