上一篇提到当访问的页表和页不在内存中时会触发
Page Fault 异常,操作系统需要在异常处理函数中分配内存页并设置好相应的分页表项。异常是一种中断类型,注册异常处理函数就是注册中断处理函数,中断处理函数注册在一个叫 IDT(Interrupt Descriptor Table) 的地方。
IDT
struct idt_entry
{
uint16_t offset_0;
uint16_t selector;
uint8_t zero;
uint8_t type_attr;
uint16_t offset_1;
};
其中 selector 是
GDT 的代码段选择器,offerset_0 和 offset_1 分别表示中断处理函数 offset 地址的 0~15bits 和 16~31bits ,type_attr 的结构如下:
7 0
+---+---+---+---+---+---+---+---+
| P | DPL | S | GateType |
+---+---+---+---+---+---+---+---+
P表示是否存在,DPL 表示描述符的最低调用权限,GateType 定义了中断类型,32 位的中断类型分别是:
Interrupt Gate 和 Trap Gate 相似,区别在前者执行中断处理函数前后会自动关闭和开启中断。
准备好 IDT ,设置好 IDTR 寄存器就把 IDT 都设置好了。IDTR 寄存器结构如下:
struct idtr
{
uint16_t limit;
struct idt_entry *base;
};
limit 是整个表的大小 -1 字节,base 指向 IDT 表,设置 IDTR 寄存器的指令是 lidt。
异常和硬件中断
PIC 分为 Master 和 Slave ,每个 PIC 都有一个命令端口和一个数据端口,通过这两个端口可以读写 PIC 的寄存器。每个 PIC 都可连 8 个输入设备,x86下 Slave 需要通过 line 2 连接到 Master 上才能响应输入设备,连接的输入设备有中断请求的时候会产生 IRQ(Interrupt Request),Master 产生 IRQ 0 ~ IRQ 7,Slave 产生 IRQ 8 ~ IRQ 15。保护模式下可以设定 PIC 产生的中断对应的 ISR 所在 IDT 中的 offset,通常设置为从 0x20 开始,到 0x2F 结束(0x0 到 0x1F 被异常占用)。
PIC 的端口号如下表:
PIC 产生的标准 IRQ 如下表:
PIC 初始化的时候,要设置 Master 和 Slave 通过 line 2 相连,同时设置好 IRQ 对应的 ISR 在 IDT 中的起始中断号。PIC 提供一个 IMR(Interrupt Mask Register) 寄存器来标识中断是否屏蔽,设置 bit 位会屏蔽对应的 IRQ。当 IMR 未设置,并且 CPU 的中断打开,如果有设备中断请求发生,那么 ISR 将会执行。ISR 执行完毕之后要通知 PIC 中断处理完成,需要向 PIC 的命令端口写入一个 EOI(End Of Interrupt) 命令(0x20),中断请求如果来自 Slave,那么需要先往 Slave 命令端口写入 EOI,再向 Master 命令端口写入 EOI。
Spurious IRQs
由于 CPU 与 PIC 之间的
竞争条件可能会产生 IRQ 7(Master 产生) 和 IRQ 15(Slave 产生) 的 Spurious IRQs。为了处理这种情况,我们要知道什么时候是无效的 IRQ,通过判断 IRR(Interrupt Request Register) 寄存器的值可以获知哪些 IRQ 发生了,这个寄存器的每个 bit 表示相应的 IRQ 是否发生。在 IRQ 7 和 IRQ 15 的 ISR 中先读取 IRR,然后判断对应的 bit 位是否被设置,如果没有设置,那么表示当前是一个 Spurious IRQ,不需要处理,也不需要写入 EOI,直接返回即可(如果是 Slave PIC 产生的,需要往 Master PIC 写入 EOI,由于 Master 不知道 Slave 产生的 IRQ 是不是 Spurious 的)。
PIT
现代操作系统都有抢占式多任务能力,通常是通过设置一个硬件 Timer,一个进程的执行时间到了之后切换成另一个进程执行,这个硬件 Timer 是
PIT(Programmable Interval Timer)。PIT 有多个 channel 和多种工作 mode,其中 channel 0 连接到 PIC 会产生 IRQ 0,mode 2 和 mode 3 是常用的工作模式。操作系统初始化的时候设置好 PIT,同时设置好 PIT 产生的 IRQ 0 的 ISR,在这个 ISR 中操作系统就可以执行多任务的调度。
中断处理结束
IDT 中设置的 ISR 返回时不能使用普通的函数返回指令 ret,需要使用一条特殊的返回指令 iret。在了解了这些之后,我们有了响应外部设备的能力,可以接入外部输入设备了,下一步接入键盘。
posted @
2015-05-05 10:03 airtrack 阅读(2567) |
评论 (0) |
编辑 收藏上一篇从 Bootloader 开始到内核载入使用的都是平坦内存,即所有地址对应实际的物理地址。现代操作系统都使用分页来管理内存,分页可以让每个进程都有完整的虚拟地址空间,进程间的虚拟地址空间相互隔离以提供页层级的保护。另外分页可以让物理内存少于虚拟地址空间,同时可以使用磁盘存储暂时未使用的内存页,提供更多的「内存」。
分页
分页通过 CPU 的 MMU(Memory Management Unit) 完成,MMU 通过当前的分页表完成虚拟地址到物理地址的转换。在 x86 下 MMU 通过两级分页表(也可以开启三级)完成地址转换,这两级分别是页目录(Page Directory)和页表(Page Table)。在 x86 下,由 cr3 寄存器存储页目录的地址(物理地址),页目录和页表都包含 1024 项,每项 4 字节,因此页目录和页表大小为 4KB ,按照 4KB 一页的话,刚好占用一页。
MMU 将虚拟地址转换成物理地址的方式是,取虚拟地址的 22~31bits 表示页目录的下标,获得页目录项定位到页表,再取 12~21bits 表示页表的下标,获得页表项定位到页,最后取 0~11bits 表示页偏移。页目录项和页表项的下标分别用 10bits 表示,刚好最大 1024 项,页内偏移用 12bits 表示,刚好 4KB。
页目录项结构如下:
其中 S 表示页大小是 4KB 还是 4MB,P 表示页表是否在内存中,如果在内存中,那么 12~31 bits 存储了 4KB 对齐的页表地址(同样是物理地址),其它 bit 的含义请参考
这里。
页表项结构如下:
同样的,P 表示此页是否在内存中,如果在内存中,12~31 bits 存储了页的地址。
我们知道了页目录和页表的结构,准备好页目录和页表,就可以开启分页了,开启分页只需把页目录地址放到 cr3 寄存器中,并把 cr0 的最高 bit 置 1。通过页目录项,我们可以发现页表不需要都存在内存当中,当访问一个虚拟地址,它对应的页表或者页不存在内存中时会触发
Page Fault 异常,我们可以在异常处理函数中完成页表或者页的分配,理论上开启分页只需要准备好页目录。
分页前后
准备好页目录页表,设置 cr3 和 cr0,开启了分页之后,内核的所有地址都变成了虚拟地址,所有的地址都要通过 MMU 映射到物理地址再访问内存。这一变化是需要小心注意的,开启分页前,访问的所有地址是物理地址,开启分页之后,所有的地址都变成了虚拟地址,因此,如果分页由内核来完成,那么内核就需要考虑到前后的变化,即有一部分代码运行在物理地址下,其它代码都运行在虚拟地址下;如果分页由 Bootloader 完成,那么 Bootloader 需要注意这个变化,并正确跳转到内核,让内核完整运行在虚拟地址下。
上一篇我把内核展开到从 0x100000 开始的物理内存中,编译链接内核的时候也把代码段的地址指定到 0x100000 的地址。开启分页之后,内核一般运行在高地址(比如 Linux 内核地址从 0x80000000 开始,Windows 从 0xC0000000 开始),而内核同样是展开到从 0x100000 开始的物理内存中。我选择把内核的虚拟地址链接到从 0xC0100000 开始,并把这个虚拟地址映射到 0x100000 的物理地址,开启分页之前运行的代码,凡是涉及到地址的操作,我都会把虚拟地址调整为物理地址再操作,开启分页之后,所有虚拟地址就可以正常运行了。
物理内存管理
操作系统采用分页方式管理内存,因此物理内存的管理也需按照页的方式管理,在 Page Fault 异常触发时,在异常处理函数中分配新的物理页并把它映射到分页表中。这里牵涉到空闲物理内存页的分配和释放,我们很容易想到一种直观的方法,把所有空闲内存页用链表串联起来,分配释放一页只需对链表进行操作。这种方式管理对进程的物理页分配简单有效,但是对内核本身使用的内存分配释放会导致内存利用率不高,因为这种方式管理的最大连续内存是一页,而内核中经常会分配大对象,连续多页的物理内存有更好的利用率。Linux 采用
Buddy memory allocation 方式管理物理内存,使用 Slab/Slub 管理内核对象的分配释放。
我的实现也采用 Buddy 方式管理物理内存,把空闲内存页用多层级的 Buddy 方式管理,分别是 order 0 ~ order 10,表示 2^order 页连续内存页块,即 order 0 管理单页的空闲内存块,order 10 管理连续 1024 页的空闲内存块。分配内存时,算出最佳的 order,在相应的 order 层级里分配一块内存块,如果当前 order 中没有可用的空闲内存块,就向 order + 1 层级中借一块,并把借来的空闲内存块平分成 2 块 order 层级的空闲内存块,其中一块当作分配结果返回,另一块放入到 order 层级中待以后分配使用。当第 order 块的内存使用完释放时,把这块释放的内存块放入 order 层级时,判断与它相连的同样大小的内存块是否在 order 层级中,如果存在,把它和它的 Buddy 合并成一个 order + 1 的内存块放入到 order + 1的层级中。
内存管理器初始化之前
在内存管理初始化之前,内核没有动态内存分配能力,因此很多时候我们需要使用静态全局变量。内存管理器初始化时,可能会使用到动态内存分配,这就出现鸡与蛋的问题,为了解决这个问题,通常会实现一个简单的 Boot Allocator 用在内存管理器初始化之前分配动态内存。我的实现是从内核展开的末尾位置开始建立一个只分配不释放的 Boot Allocator,等到内存管理器初始化完成之后,Boot Allocator 的使命便完成了。
另外还有一个问题,我们管理物理内存,需要知道安装了多少物理内存,因此我们要探测安装了多少物理内存,
这里介绍了几种探测方法,我使用的是 BIOS 的 INT 0x15, EAX = 0xE820 函数,它由 Bootloader 调用完成,最后通过参数把它传递给操作系统内核。
posted @
2015-04-27 12:53 airtrack 阅读(3422) |
评论 (0) |
编辑 收藏2014年的最后一个星期用Rust写了一个Tunnel,代码放在
GitHub上。主要原因是VPN在12月开始极不稳定,其次是VPN用起来不爽,每次下东西都要关VPN,而用ssh -D时偶尔又会断开,最后干脆自己写一个(其实年初就想写,因为买了VPN就不想折腾了)。
编译和使用
现代语言一般都自带编译工具,不用折腾make cmake等东西,Rust官方提供了
Cargo,所以编译很简单,安装好Cargo,然后到源码目录下Cargo build就完成了。
编译完成得到两个可执行文件,分别是:client, server,server启动在服务器上,client启动在本机并绑定到地址127.0.0.1:1080,浏览器由代理插件通过SOCKS v5协议连接这个地址即可。
Tunnel逻辑结构
下面是逻辑图:
Client和Server之间通过一条TCP链接相连,客户端每收到一个TCP请求就开一个port处理,同时在Server上有一个port与之对应,这样就在Client和Server之间建立了一个会话层,这个TCP链接的数据全部都在对应的port里传输。
Tunnel本身跟SOCKS v5不相关,为了让浏览器代理能连上,Client提供了SOCKS v5中最简单的NO AUTHENTICATION TCP方法,即无用户名和密码的TCP代理。
Client和Server之间传输的数据都加了密,加密算法是Blowfish,工作模式是
Counter Mode,client和server启动时的参数Key即加密算法的Key。
Rust的使用感受
以前虽有关注Rust,却从没用Rust写过代码,主要是还未发布1.0,语法不稳定,最近1.0快有眉目了,可以用来写写小东西了。因为有Haskell的基础,所以上手Rust对我来说没什么难度。
Rust提供了ADT(Algebraic Data Type), Pattern Matching, Traits,语法表达能力很强,同时也提供了macro,可自定扩展语法,进一步加强了语法表达能力。自动内存管理也让程序更安全,不过由此也带来一些语法表达能力的削弱,比如需要在函数返回的时候自动调用socket.close_read,通常可以定义一个struct,并让这个struct impl trait Drop,在结构体销毁的时候调用socket.close_read,又因为socket.close_read需要mut的socket引用,而mut的引用只能borrow一次,所以这个struct一旦borrow了socket的mut引用,之后再调用这个socket的mut函数就会报错,一个workaround的方法就是struct保存socket的一份拷贝(socket本身通过引用计数管理),虽然可行,但是总感觉有些重了,仅仅为写起来方便的一个问题引入了一次引用计数对象的拷贝。同时也会产生一个警告,由于那个struct的对象没有被使用过。
Rust编译器报错信息很详细友好,运行时依赖小,Tunnel编译出来的的client和server都可以在其它机器上直接运行。其它方面主要是API文档跟不上,最新文档上有的函数,编译器编译可能报错,函数已经不存在了(刚刚去看了看最新的文档,std::io变成了std::old_io)。库方面,虽然Cargo仓库里有一些第三方库,但是总体数量还不多。
posted @
2015-02-03 21:03 airtrack 阅读(3493) |
评论 (0) |
编辑 收藏Bootloader
我们知道计算机启动是从BIOS开始,再由BIOS决定从哪个设备启动以及启动顺序,比如先从DVD启动再从硬盘启动等。计算机启动后,BIOS根据配置找到启动设备,并读取这个设备的第0个扇区,把这个扇区的内容加载到0x7c00,之后让CPU从0x7c00开始执行,这时BIOS已经交出了计算机的控制权,由被加载的扇区程序接管计算机。
这第一个扇区的程序就叫Boot,它一般做一些准备工作,把操作系统内核加载进内存,并把控制权交给内核。由于Boot只能有一个扇区大小,即512字节,它所能做的工作很有限,因此它有可能不直接加载内核,而是加载一个叫Loader的程序,再由Loader加载内核。因为Loader不是BIOS直接加载的,所以它可以突破512字节的程序大小限制(在实模式下理论上可以达到1M)。如果Boot没有加载Loader而直接加载内核,我们可以把它叫做Bootloader。
Bootloader加载内核就要读取文件,在实模式下可以用BIOS的INT 13h中断。内核文件放在哪里,怎么查找读取,这里牵涉到文件系统,Bootloader要从硬盘(软盘)的文件系统中查找内核文件,因此Bootloader需要解析文件系统的能力。GRUB是一个专业的Bootloader,它对这些提供了很好的支持。
对于一个Toy操作系统来说,可以简单处理,把内核文件放到Bootloader之后,即从软盘的第1个扇区开始,这样我们可以不需要支持文件系统,直接读取扇区数据加载到内存即可。
实模式到保护模式
我们知道Intel x86系列CPU有实模式和保护模式,实模式从8086开始就有,保护模式从80386开始引入。为了兼容,Intel x86系列CPU都支持实模式。现代操作系统都是运行在保护模式下(Intel x86系列CPU)。计算机启动时,默认的工作模式是实模式,为了让内核能运行在保护模式下,Bootloader需要从实模式切换到保护模式,切换步骤如下:
- 准备好GDT(Global Descriptor Table)
- 关中断
- 加载GDT到GDTR寄存器
- 开启A20,让CPU寻址大于1M
- 开启CPU的保护模式,即把cr0寄存器第一个bit置1
- 跳转到保护模式代码
GDT是Intel CPU保护模式运行的核心数据结构,所有保护模式操作的数据都从GDT表开始查找,
这里有GDT的详细介绍。
GDT中的每一个表项由8字节表示,如下图:
其中Access Byte和Flags如下图:
GDTR是一个6字节的寄存器,有4字节表示GDT表的基地址,2字节表示GDT表的大小,即最大65536(实际值是65535,16位最大值是65535),每个表项8字节,那么GDT表最多可以有8192项。
实模式的寻址总线是20bits,为了让寻址超过1M,需要开启A20,可以通过以下指令开启:
in al, 0x92
or al, 2
out 0x92, al
把上述步骤完成之后,我们就进入保护模式了。在保护模式下我们要使用GDT通过GDT Selector完成,它是GDT表项相对于起始地址的偏移,因此它的值一般是0x0 0x8 0x10 0x18等。
ELF文件
Bootloader程序是原始可执行文件,如果程序由汇编写成,汇编编译器编译生成的文件就是原始可执行文件,也可以使用C语言编写,编译成可执行文件之后通过objcopy转换成原始可执行文件,
这篇文章介绍了用C语言写Bootloader。
那么内核文件是什么格式的呢?跟Bootloader一样的当然可以。内核一般使用C语言编写,每次编译链接完成之后调用objcopy是可以的。我们也可以支持通用的可执行文件格式,ELF(Executable and Linkable Format)即是一种通用的格式,它的
维基百科。
ELF文件有两种视图(View),链接视图和执行视图,如下图:
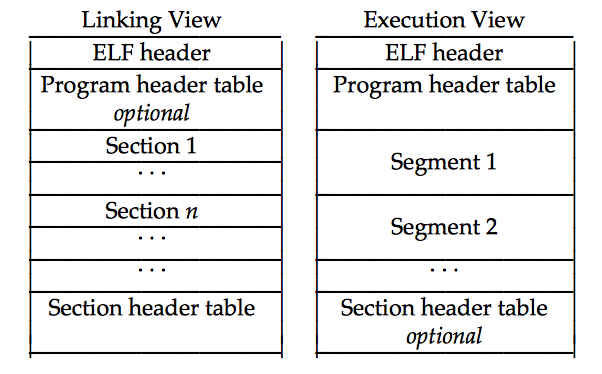
链接视图通过Section Header Table描述,执行视图通过Program Header Table描述。Section Header Table描述了所有Section的信息,包括所在的文件偏移和大小等;Program Header Table描述了所有Segment的信息,即Text Segment, Data Segment和BSS Segment,每个Segment中包含了一个或多个Section。
对于加载可执行文件,我们只需关注执行视图,即解析ELF文件,遍历Program Header Table中的每一项,把每个Program Header描述的Segment加载到对应的虚拟地址即可,然后从ELF header中取出Entry的地址,跳转过去就开始执行了。对于ELF格式的内核文件来说,这个工作就需要由Bootloader完成。Bootloader支持ELF内核文件加载之后,用C语言编写的内核编译完成之后就不需要objcopy了。
为什么写操作系统
首先是兴趣,在现在这个时代,写操作系统几乎没有实用价值,只能是一个Toy,在写一个Toy OS时,可以学习掌握很多知识,并把这些知识贯穿实用起来。操作系统是一个复杂的系统,牵涉到的东西很多,我相信写操作系统可以帮助理解现代操作系统及其它底层知识。我目前才刚开始写,代码放在
Github上。
posted @
2014-10-30 19:13 airtrack 阅读(3351) |
评论 (1) |
编辑 收藏
去年花了两三个星期的业余时间实现了基于DFA的正则引擎(
一 二),时间一晃就过去一年,工作繁忙,兴趣面广,前途未卜什么的耗费太多精力,最近两三个月抽了点时间写了基于NFA的正则引擎,代码放在
Github。
正则引擎常见的实现方法
正则的常见实现方式有三种:DFA、Backtracking、NFA:
- DFA是三种实现中效率最高的,不过缺点也明显,一是DFA的构造复杂耗时,二是DFA支持的正则语法有限。在早期正则被发明出来时,只有concatenation、alternation、Kleene star,即"ab" "a|b" "a*",DFA可以轻松搞定。随着计算机的发展,正则像所有其它语言一样发展出各种新的语法,很多语法在DFA中难以实现,比如capture、backreference(capture倒是有论文描述可以在DFA中实现)。
- Backtracking是三种实现中效率最低的,功能确是最强的,它可以实现所有后面新加的语法,因此,大多数正则引擎实现都采用此方法。因为它是回溯的,所以在某些情况下会出现指数复杂度,这篇文章有详细的描述。
- NFA(Thompson NFA)有相对DFA来说的构造简单,并兼有接近DFA的效率,并且在面对Backtracking出现指数复杂度时的正则表达式保持良好的性能。
NFA-based的实现
这里描述的NFA是指Thompson NFA。Thompson NFA实现的核心是对于正则表达式多个可能的匹配并发的向前匹配,此过程是在模拟DFA运行。比如对于正则表达式"abab|abbb"匹配字符串"abbb":
- Backtracking的匹配过程是取正则的第一个子表达式"abab"匹配,前两个字符匹配成功,匹配第三个字符的时候失败,这时引擎回溯选择第二个子表达式"abbb"匹配,最终匹配成功。
- Thompson NFA是同时取两个子表达式"abab"和"abbb"匹配,前两个字符匹配时,两个子表达式都能匹配成功,当匹配第三个字符时,子表达式"abab"匹配失败,因此丢弃,"abbb"匹配成功接着匹配,最终匹配成功。
上面是一个简单的例子,没有出现"*" "+" "{m,n}"这种复杂的metacharacters,在处理这种repeat的metacharacter时Thompson NFA优势更加明显。
在实际复杂的正则表达式中,NFA构造是必然会产生一堆epsilon边,这在
第二篇文章中有描述。上面描述Thompson NFA实际是在模拟DFA运行,在每个字符匹配完成之后需要跳过epsilon边得到后面要匹配的并发的状态集合,这样持续的并发匹配下去,当字符串匹配完成时只要有一个达到了接受状态,就是匹配成功,若这个集合为空,那表示匹配失败。
在我的实现中,构造了一组状态和由这组状态加epsilon边集合构造的有向图,每个状态有自己的状态类型,分为两种:
- 一种是匹配状态类型,即用来匹配字符的状态,若字符匹配成功,则进入下一个状态;
- 一种是操作状态类型,即不匹配字符的状态,在每个字符匹配结束之后若到达这些状态,则会进行相应的操作,比如repeat状态,记录匹配计数,并判断匹配计数是否完成再决定是否进入的下面的状态。
repeat是一种会分化的状态,达到最小匹配次数时,可以接着往下走,也可以继续重复匹配repeat的子正则表达式,这样就分化成两条线了,并且每条线都带有自己的状态数据,因此,我的实现中引入的thread来表示一条匹配线,里面有状态数据。
Match和Search
状态构造完成了之后,就要开始匹配了。匹配有两种,一种是match,即一个正则表达式能否完整匹配一个字符串,若完整匹配则匹配成功;另一种是search,要在一个字符串中或者一块buffer中查找每个满足的匹配。这里就有个问题,从第一个字符开始匹配,匹配了几个字符之后发现匹配失败了怎么办呢?回退到第二个字符重新匹配?我们知道对于普通的字符串查找,有KMP算法可以保证不回退字符(其实KMP算法的预处理就是构造DFA),或者有Boyer-Moore算法尽量回退少的字符个数。对于正则这种复杂的匹配该怎么办呢?从上面的Thompson NFA的描述可以知道匹配过程是多条线并发匹配,因此可以构造一个始终产生一条新线的状态,若匹配在前面的线失败被丢弃之后,后面的新线始终可以补上,这样查找的过程就不再需要回退字符了。
我的实现中,状态构造完成后是这样的:
// |-----|--------|---------------|-----|-------------|
// | any | repeat | capture begin |  | capture end |
| capture end |
// |-----|--------|---------------|-----|-------------|
用repeat-any来产生新的匹配线。若在match模式下,则从第三个状态开始匹配,不会产生新的匹配线,一旦匹配过程失败了就失败了。
结语
正则表达式语法一直在扩展,新的语法有些很难在DFA和NFA中实现,而在Backtracking中的实现又是以牺牲性能为代价。因此有些正则表达式实现会结合多种实现方式,判断正则表达式的类型选择不同的引擎,比如普通字符串加上一些简单的正则语法采用DFA引擎匹配,或者只有普通字符串的匹配可以用Boyer-Moore算法,毕竟Boyer-Moore算法在普通文本查找中要优于KMP算法:),对于复杂的正则表达式采用Backtracking,甚至有些正则引擎使用JIT来加速。
posted @
2014-09-15 19:04 airtrack 阅读(3182) |
评论 (0) |
编辑 收藏
GC的分类
通常情况下GC分为两种,分别是:扫描GC(Tracing GC)和引用计数GC(Reference counting GC)。其中扫描GC是比较常用的GC实现方法,其原理是:把正在使用的对象找出来,然后把未被使用的对象释放。而引用计数GC则是对每个对象都添加一个计数器,引用增加一个计数器就加一,引用减少一个计数器就减一,当计数器减至零时,把对象回收释放。引用计数GC跟C++中的shared_ptr类似,自然也会存在循环引用问题。
扫描GC(Tracing GC)是广泛使用的GC方法,最简单的实现方式是mark-sweep,即扫描所有存活的对象并mark,然后遍历整个GC对象列表,把所有标记过的对象清除标记,把未标记过的对象释放。如果GC使用的是mark-sweep方法,程序运行一段时间后触发了GC,每次GC的时候会把当前程序中的所有对象都扫描一次,然后释放未使用的对象。这对于分配GC对象少的程序来说没有什么问题,当程序中存在大量分配GC对象时,每次启动GC扫描所有对象的代价是很高的,又因为GC的过程通常是stop-the-world,所以高代价的GC会导致整个程序卡顿一段时间。对于这个问题,解决方法有增量GC(Incremental GC)和分代GC(Generational GC)。
增量GC(Incremental GC)会把整个GC过程分成很多步(phase),每步的执行可以存在一定间隔运行程序本身,这就尽量把stop-the-world的时间变短,使得程序不会因为GC而导致延迟太大。Lua默认采用的是这种实现方法,Lua 5.2中也引入了分代GC作为备选GC方法。
分代GC(Generational GC)把对象分成几代(Generation),通常把GC分为两种:Minor GC和Major GC。刚刚分配出来的对象属于最年轻的一代,在一次GC过后把年轻代中存活的对象上升到年老的一代中。把只扫描年轻一代的对象以减少扫描对象数量的GC过程称为Minor GC,只有在特定情况下才会启动完整的Major GC。分代GC是基于在大多数程序中新创建的对象同时也是最快变成无效的对象的经验设计的,对年轻代对象GC时,可以释放大多数无效对象,存活下来的对象一般存活时间也会更长,因此把它们上升到下一代中以减少最这些对象的扫描。
对于GC内存的管理,有移动和非移动之分。移动的就是把一次GC过后存活的对象compact到一起,使GC管理的内存保持连续,这里增加了一个移动对象的开销,不过它也同样带来不少好处:分配释放对象快和更快的序列遍历(在CPU cache中及在同一个Virtual memory page中)。正因为它会把对象compact到一起,对象的地址就会发生变化,这也就导致一个明显的缺点,不能使用指针引用GC对象。
其它高级GC方法,比如.NET的background GC,几乎不需要stop-the-world就可以在GC线程中完成GC,这种高科技的GC对于我这种初级人士基本属于不可想象。
初级分代GC设计
了解了基本的GC方法之后,我为
luna第二版实现了一个初级的分代GC,把对象分成三代:GCGen0,GCGen1,GCGen2:
GCGen0是最年轻的一代,默认所有对象都是分配在这代中。
GCGen1是年老的一代,在一次GC过后GCGen0代存活的对象会移动到这一代中。
GCGen2是最老的一代,一般情况下用于存放编译时分配的会长期存在的对象,比如函数及字符串常量。
由于我在很多地方直接引用了GC对象的指针,为了简单起见,我没有在GC之后移动对象,而是对每个对象单独分配释放内存。每个对象都有Generation标记和GC标记以及一个用于指向跟自己属于同代的GC对象的指针。
Minor GC对GCGen0代对象mark-sweep,并把存活的对象移动到GCGen1代中。既然需要mark,自然需要对所有GCGen0代存活的对象标记,这通过对root对象的遍历完成,root是指所有对象的引用入口,比如程序的栈和全局表。对于Minor GC的root对象遍历最简单的方法是跟Major GC的root遍历完全一致,不过这样的遍历对于本来就是为了减少遍历对象的Minor GC来说似乎不合,所以通常只对某一小块root遍历,比如只对栈上的对象遍历,然后再把存活的对象保留不存活的对象释放。
Minor GC的root遍历存在一个问题:假设只把栈上的对象作为root遍历,会存在一些从GCGen0代分配出来的对象没有被栈上的对象引用,而被全局表中的某个对象引用,或者其它某个非GCGen0对象引用了,这样对GCGen0代sweep的时候可能会把这个存活的对象当做无效对象而释放掉,这种操作自然也就会导致整个程序crash。于是为了控制root遍历的范围,又要解决这个问题,对非GCGen0对象引用GCGen0对象的时候,需要把这个非GCGen0的对象也加入到root遍历列表中去。这时引入了barrier,对于非GCGen0对象引用GCGen0对象时,把这个非GCGen0的对象放到barrier列表中。
Major GC是一个完整的GC,它遍历所有的root并mark,并把所有的无效的对象都sweep释放。
GC启动的时机
GC什么时候启动是一个需要仔细考虑的问题,由于我实现的GC并没有自己管理内存(Lua也没有自己管理内存,所有内存分配都通过realloc),所以我把GCGen0代和GCGen1代的对象数量作为启动时机的衡量指标,当GCGen0和GCGen1的对象数量大于它们的阈值时,分别启动Minor GC和Major GC。我觉得对象的数量比起内存占用大小(各种复杂的GC对象导致内存占用很难精确的统计,Lua的内存统计也不够精确)更能反映GC时间的长短,如果两者结合也许会更好。
通过判断GC对象个数超过阈值时启动GC,同时需要在GC之后自动调整阈值大小。比如某些程序很快的达到GCGen0的阈值并在Minor GC之后有超过一半的对象还是存活的,这时需要把阈值调大,以减少GC启动的次数,这个阈值也不能无限扩大,这不仅会导致一段时间内内存占用一直上升,也会导致一旦触发GC所需扫描的对象数量太多,GC耗时太长,程序运行的延时增加。
结语
为了减少stop-the-world的时间,引入的各种方法都会让GC实现难度加大。GC是一个复杂的东西,网上所能找到的资料文章似乎不太多,而有关GC的书,目前只发现
《The Garbage Collection Handbook》(我还没有看过),而这本书既没有pdf也没有kindle版,只能在美国Amazon上买纸质书。另外一个参考资料就是各个语言的实现源码了。
posted @
2013-11-17 22:20 airtrack 阅读(2631) |
评论 (1) |
编辑 收藏 离上一篇已经有近两个月的时间了,这段时间事情烦(多),导致没心情写,现在争取补上。
生成epsilon-NFA
epsilon-NFA是包含epsilon边(空边)的NFA,把简单正则表达式转换成epsilon-NFA的方法如下:
正则表达式:”ab” 对应的epsilon-NFA是:

正则表达式:”a|b”对应的epsilon-NFA是:

正则表达式:”a*” 对应的epsilon-NFA是:

这是最基本的3种正则表达式的NFA表示,其中a*在实际的正则表达式实现中通常生成的epsilon-NFA不是这样的,因为有下面这些正则表达式存在:
a{m} 重复a,m次
a{m,n} 重复a,m到n次
a{m,} 重复a,至少m次
a+ 重复a,至少1次
a? 重复a,0次或1次
所以对于a*表示重复至少0次的实现可以跟上面这些正则表达式采用相同方法的实现。
按照这些生成规则就可以把正则表达式转换成epsilon-NFA,我代码中即把这些生成规则实现成一个AST的visitor。
epsilon-NFA subset construction to DFA
在生成了epsilon-NFA之后,通常会有很多epsilon的边存在,也会有很多无用的state存在,所以通常需要把epsilon边消除并合并state,这个过程采用的算法是subset construction,如下:
subset construction:
start_subset <- epsilon_extend(start_state) // 把start_state通过epsilon扩展得到起始subset
subsets <- { start_subset } // 初始化subsets
work_list <- subsets // 初始化work_list
while (!work_list.empty())
{
subset <- work_list.pop_front()
for edge in epsilon-NFA // 取出NFA中的每条边
{
next_subset <- delta(subset, edge) // 对subset中的每个state通过edge所到达的state的epsilon边扩展得到next_subset
if (!subsets.exist(next_subset)) // 如果next_subset不存在于subsets中,则把这个next_subset加入到work_list中
work_list.push_back(next_subset)
map[subset, edge] = next_subset // 构建subset到next_subset的边映射
subsets.merge({next_subset}) // 把next_subset合并到subsets
}
}
delta:
next_subset <- { } // 初始化next_subset为空集合
for state in subset
{
// 取出next_state并将它通过epsilon边扩展得到的subset合并到next_subset中
next_state <- map[state, edge]
if (next_state)
next_subset.merge(epsilon_extend(next_state))
}
这里面使用了epsilon_extend,它是把一个state的所有epsilon边能到达的state构成一个集合,比如上面正则表达式a*对应的epsilon-NFA中的所有state的epsilon_extend是:
epsilon_extend(1) –> { 1 }
epsilon_extend(2) –> { 1, 2, 4 }
epsilon_extend(3) –> { 1, 3, 4 }
epsilon_extend(4) –> { 4 }
对于一个epsilon-NFA来说,每个state的epsilon_extend是固定的,因此可以对epsilon-NFA中的每个state都求出epsilon_extend并保存下来,算法如下:
epsilon_extend_construct:
work_list <- { }
// 为每个state初始化epsilon_extend集合
for state in epsilon-NFA
{
epsilon_extend(state) <- { state }
work_list.push_back(state)
}
while (!work_list.empty())
{
state <- work_list.pop_front()
state_epsilon_extend <- epsilon_extend(state)
// 把state通过epsilon所能到达的state的epsilon_extend
// 合并到当前state的epsilon_extend
for next_state in map[state, epsilon]
state_epsilon_extend.merge(epsilon_extend(next_state))
// 如果当前state的epsilon_extend变化了之后
// 把所有通过边epsilon到达state的pre_state都加入到work_list中
if (state_epsilon_extend.has_changed())
{
for pre_state in epsilon_pre(state)
work_list.push_back(state)
}
}
epsilon-NFA通过subset construction构造成完之后,并把构造的subsets中的subset转换成DFA中的state,再把NFA中除epsilon边之外的所有边都转换成DFA的边,这样就把DFA构造完成。
DFA minimization
从NFA构造完成DFA之后,这时的状态数量一般不是最少的,为了减少最终生成的状态机的状态数量,通常会对DFA的state进行最小化构造,这个算法具体如下:
minimization:
// 把所有state划分成accept的state集合和非accept的state集合
state_sets <- { {accept_state(DFA)}, {non_accept_state(DFA)} }
do
{
work_list <- state_sets
old_state_sets_size <- state_sets.size()
state_sets <- { }
for state_set in work_list
{
split_success <- false
for edge in DFA
{
// 如果edge可以把state_set拆分成两个subset,那就把新拆分出来的
// 两个subset合并到state_sets里面,并break继续work_list中取出下一个
// state_set拆分
subset1, subset2, split_success <- split(state_set, edge)
if (split_success)
{
state_sets.merge({subset1, subset2})
break
}
}
if (!split_success)
state_sets.merge({state_set})
}
} while (old_state_sets_size != state_sets.size())
这里面的split是把一个state_set按edge划分成两个subset,即对于state_set中的每一个state都通过这条边edge到达的state属于不同的state_set时就把state_set拆分成两个subset。首先把第一个state划分到subset1中,从第二个state开始通过边edge到达的state所属的state_set和第一个state通过边edge到达的state所属的state_set为同一个的时候,把这个state划分到subset1中,否则划分到subset2中。
这个算法就这样依次把最初的两个state_set(accept的state组成的set和非accept的state组成的set)划分到不能再划分为止,此时就把能合并的state都合并到了同一个state_set中,这时只需要把每个state_set转换成最终状态机中的state,即可完成DFA的最小化构造并转换成状态机。得到状态机之后,就可以使用状态机进行字符匹配了。
posted @
2013-09-01 23:25 airtrack 阅读(1786) |
评论 (0) |
编辑 收藏 实现正则表达式的想法很早就有,各种原因导致没有做,最近花了点时间先实现了几个简单的正则语法,分别是concatenation、alternation和closure,其他语法及metacharacter等有时间了有想法了之后再扩展。
这三种基本的语法分别是对应这样的:
concatenation: abc 表示匹配字符串abc
alternation: abc|def 表示匹配字符串abc或者def
closure: a* 表示匹配零个到多个a构成的字符串
我们知道正则表达式最终需要转换成自动机才能用来匹配字符串,我实现的正则通过如下几个步骤把正则表达式转换成自动机:
正则表达式->Parse成AST->生成边(字符)集合->生成NFA->NFA subset construction->转换成DFA->DFA minimization
最后用DFA minimization之后构造的自动机来匹配字符串。
正则语法的分析
一个正则表达式写出来,要让这个正则表达式匹配字符串等操作之前,我们先需要从正则表达式中提取需要的信息并在正则语法错误的时候提示错误,这个过程自然少不了parser。一个parser通常是从一个lexer里面获取一个token,而正则表达式的token都是字符,那么lexer不需要做任何的分词操作,只需要简单的把字符返回给parser即可。
那三种基本的正则语法对应的BNF为:
re ::= alter
re_base ::= char | char_range | '(' re ')'
alter ::= alter_base alter_end
alter_base ::= concat
alter_end ::= '|' alter_base alter_end | epsilon
concat ::= concat_base concat_end
concat_base ::= re_base | closure
concat_end ::= concat_base concat_end | epsilon
closure ::= re_base '*'
这个parser分析了正则表达式之后产生AST,AST的node类型为:
class ASTNode
{
public:
ACCEPT_VISITOR() = 0;
virtual ~ASTNode() { }
};
class CharNode : public ASTNode
{
public:
explicit CharNode(int c) : c_(c) { }
ACCEPT_VISITOR();
int c_;
};
class CharRangeNode : public ASTNode
{
public:
struct Range
{
int first_;
int last_;
explicit Range(int first = 0, int last = 0)
: first_(first), last_(last)
{
}
};
CharRangeNode() { }
void AddRange(int first, int last)
{
ranges_.push_back(Range(first, last));
}
void AddChar(int c)
{
chars_.push_back(c);
}
ACCEPT_VISITOR();
std::vector<Range> ranges_;
std::vector<int> chars_;
};
class ConcatenationNode : public ASTNode
{
public:
void AddNode(std::unique_ptr<ASTNode> node)
{
nodes_.push_back(std::move(node));
}
ACCEPT_VISITOR();
std::vector<std::unique_ptr<ASTNode>> nodes_;
};
class AlternationNode : public ASTNode
{
public:
void AddNode(std::unique_ptr<ASTNode> node)
{
nodes_.push_back(std::move(node));
}
ACCEPT_VISITOR();
std::vector<std::unique_ptr<ASTNode>> nodes_;
};
class ClosureNode : public ASTNode
{
public:
explicit ClosureNode(std::unique_ptr<ASTNode> node)
: node_(std::move(node))
{
}
ACCEPT_VISITOR();
std::unique_ptr<ASTNode> node_;
};
其中ASTNode作为AST的基类,并提供接口实现Visitor模式访问ASTNode类型。
字符(边)集的构造
AST构造好了之后,需要把AST转换成NFA。语法中有[a-zA-Z0-9]这种字符区间表示法,我们可以用最简单原始的方法转换,就是把区间中的每个字符都转化成相应的一条边(NFA中的边),这样一来会导致字符区间越大,对应边的数量会越多,使得对应的NFA也越大。因此,我们需要构造区间字符集合来减少边的数量。
比如正则表达式是:a[x-z]|[a-z]*e
那么我们希望对应的字符集合是这样:[a-a] [b-d] [e-e] [f-w] [x-z]
这需要构造一个字符集,每次插入一个区间的时候,把新插入的区间与已存在的区间进行分割,初始时已存在的区间集为空,那么正则表达式a[x-z]|[a-z]*e的划分步骤如下:
已存在区间集合{},插入[a-a],得到{[a-a]}
已存在区间集合{[a-a]},插入[x-z],得到{[a-a], [x-z]}
已存在区间集合{[a-a], [x-z]},插入[a-z],得到{[a-a], [b-w], [x-z]}
已存在区间集合{[a-a], [b-w], [x-z]},插入[e-e],得到{[a-a], [b-d], [e-e], [f-w], [x-z]}
这个区间构造完成了之后,还需要在后面转换成NFA边的时候,根据字符区间查询出在这个集合中,由哪几个区间构成,比如:
查询区间[a-a],得到[a-a]
查询区间[x-z],得到[x-z]
查询区间[a-z],得到区间[a-a] [b-d] [e-e] [f-w] [x-z]
在转换成NFA时,集合中的每个区间都对应一条边,这样相对于每个字符对应一条边,边的数量不会太多。
有了这么一个集合构造的类之后,把正则的AST中的字符信息提取出来构造出这么个集合即可,这样只需要写个visitor就完成了:
class EdgeSetConstructorVisitor : public Visitor
{
public:
explicit EdgeSetConstructorVisitor(EdgeSet *edge_set)
: edge_set_(edge_set)
{
}
EdgeSetConstructorVisitor(const EdgeSetConstructorVisitor &) = delete;
void operator = (const EdgeSetConstructorVisitor &) = delete;
VISIT_NODE(CharNode);
VISIT_NODE(CharRangeNode);
VISIT_NODE(ConcatenationNode);
VISIT_NODE(AlternationNode);
VISIT_NODE(ClosureNode);
private:
EdgeSet *edge_set_;
};
边集合构造完成之后,下一步就是生成NFA了。
posted @
2013-07-05 13:30 airtrack 阅读(4411) |
评论 (3) |
编辑 收藏最近几个月利用上下班的时间在学习Haskell,Haskell有不少让人开阔思路的东西,也有不少看起来很美好,用起来不错,但是读起来费劲的东西。Haskell的语法学的差不多了之后,用Haskell写了一个简单的C++代码行统计工具,写过几个版本,留下了两个,一个是直接用模式匹配写的,一个是山寨了一个极简的parse combinator,然后用这个山寨的parse combinator写了一个版本,代码估计写的都比较烂,以后进阶学习之后有时间再改。这个统计工具并不是完整的处理C++的语法,也没对在字符串和宏定义里面的"//" "/*" "*/"做处理,因此对某些C++程序统计代码行,可能不完全正确,但是基本可以用。
data, type, newtype
Haskell里面用data来定义数据类型,它可以是这样:
data Mode = ReadMode | WriteMode
data Some = Some Int String
data Thing = { a :: Int, b :: String }
data Func a b = { func :: a -> b }
第一行定义了一个Mode,包含ReadMode和WriteMode;
第二行定义了一个普通数据类型Some,包含一个Int数据和一个String数据;
第三行定义了一个普通数据类型Thing,包含类型为Int的a和类型为String的b;
第四行定义了一个符合数据类型Func,里面有个函数类型为(a -> b)的数据func。
第一种相当于C++中的enum class,第二种第三种相当于普通的struct数据,第二种和第三种的区别是第二种不能直接取到Int和String的数据,第三种可以通过a,b取到数据,第四种相当于C++的template class(struct),第四种写成这样来定义具体的数据类型:
type IntStringFunc = data Func Int String
type在这里定义了一个别名IntStringFunc类型,包含了一个函数类型是Int -> String的func的数据,这里的type相当于C++ 11的using别名,因为它还可以这样写:
type IntBFunc b = data Func Int b
在C++ 11中,using包含了typedef的功能,也支持了template class的类型typedef,如下:
template <typename T, typename P>
class SomeType;
template <typename T>
using SomeTypeInt = SomeType<T, int>;
newtype定义的数据类型跟type类型,不过type定义的纯粹是别名,别名类型跟原始类型是一致的,而newtype则定义的是一个wrapper,是一种新的数据类型,所以是newtype。newtype定义的类型是编译时期的wrapper,Haskell保证没有运行时期的开销,newtype定义的跟data类似:
newtype NewType a b = NewType { func :: a -> b }
模式匹配
上面说道data定义的第二种数据类型,包含Int和String的数据,但是不能直接取到这两个数据,所以我们需要定义两个函数来取其中的数据:
some = Some 0 "test" -- 定义一个数据,类型为Some
-- 定义两个函数用于获取Some的数据
getSomeInt Some i _ = i
getSomeString Some _ s = s
getSomeInt some -- 0
getSomeString some -- "test"
这里的getSomeInt和getSomeString函数都是采用模式匹配来实现,模式匹配就是把数据的结构直接写在代码中来匹配,然后取出想要使用的数据即可。
Haskell里常用的Maybe数据类型是这样定义的:
data Maybe a = Nothing
| Just a
如果要取用Maybe里面的值,我们通常使用模式匹配来获取数据,如下:
useMaybe maybe =
case maybe of
Nothing -> … -- Maybe的值是空
Just a -> … -- 直接使用a即可
useMaybe (Just 1)
下面调用useMaybe的函数体内取到的a的值就是1。
Haskell里的内置数据类型list,比如[1, 2, 3, 4],使用:可以把新的元素添加到list头部,即:
0 : [1, 2, 3, 4] -- [0, 1, 2, 3, 4]
这样的特性同样可以简单的套用在模式匹配上面,如下:
useList [] =
useList (x:xs) = … -- x是list里面的第一个元素,xs是list的尾部
模式匹配可以很直观的匹配数据的原始表示方式,并可以取出其中有用的值做其他操作,它是一个简单直观有效的操作数据的方式,甚至可以在嵌套很深的tuple数据里面直接取出想要的数据,而不用像C++那样调用tuple::get之类的函数来取出其中的值,比如:
getTupleValue (_, _, _, (_, _, (x:xs))) = … -- 取得x和xs数据
Visitor模式和C++ template
王垠说设计模式中值得一提的模式不多,其中之一的visitor模式是在模拟模式匹配。visitor模式通常是访问获取某个继承类层次构成的一个树形结构中的某个节点的具体类型,并对这种具体类型做某些操作,而模式匹配是可以从复杂的数据结构中直接取出想要的数据。
C++的template meta-programming也可以看成是一种模式匹配,C++里面著名的Factorial求值是这样的:
template <int N>
struct Factorial
{
enum { value = N * Factorial<N - 1>::value };
};
template <>
struct Factorial<0>
{
enum { value = 1 };
};
int v = Factorial<10>::value;
而这段代码如果用Haskell写是这样的:
factorial 0 = 1
factorial n = n * factorial (n - 1)
v = factorial 10
C++中的模板参数就是用来做模式匹配的,每特化一种类型就可以匹配某种类型,然后对那种匹配的类型做相应的操作。C++的template meta-programming是编译时期(编译器运行期)的行为,所以它只能操作类型以及编译时期能够确定的值,而模式匹配是程序本身的运行期的行为。
Currying
Haskell的Currying是一个很有用的特性,但是我觉得这个特性滥用的话,也会让程序代码的可读性降低不少。所谓Currying就是可以向一个多参数的函数传递比它所需的参数个数更少的参数后返回生成的一个新函数接受剩余的参数的函数。Haskell里的函数默认都是curried的,所以Haskell里面的函数可以随意currying,比如:
add :: Int -> (Int -> Int) -- 一般写成 Int -> Int -> Int
add a b = a + b
addOne :: Int -> Int
addOne = add 1
addOne 2 -- result: 3
Currying的实现是使用的单参数的lambda构成的闭包(closure),add可以看成是接受一个Int参数返回一个函数,这个函数的类型是Int -> Int。
Partial application
Currying是一个从左到右部分传参数的一个过程,也就是不会出现参数a还没给,就给了具体的参数b的情况。如果确定要先给参数b,那么它是Partial application,如下:
addTwo a = add a 2
addTwo 1 -- result: 3
(+ 2) 1 -- result: 3
(+ 2)这种类似的用法可能会作为参数传递给另外一个函数。Partial application是一种更宽泛的概念,上面的Currying是一种Partial application。
正如王垠所说的,如果一个函数接受了多个参数,但是这个函数在实际调用中被Currying了很多次,那最后生成的那个函数它到底接受几个参数是不能很直观的看明白的,比如:
func a b c d e f = …
do1 = func 1
do2 = do1 2
do3 = do2 3
do4 = do3 4
do5 = do4 5
那当我们看到do5函数的时候,我们是很难判断do5到底接受几个参数,尤其是do5跟前面几个doN函数不在同一个地方定义,很有可能do5只是传递给某个函数的参数,当然如果给每个函数都加上函数类型声明会清晰许多。当Currying碰到了flip之后,那代码的可读性会降低更多,所以我觉得Currying是一个很有用的特性,但是如果被滥用的话,那代码的可读性会是一个问题。
C++: function + bind
C++中的function + bind其实是一种Partial application实现,比如:
int Func(int a, int b, int c);
std::function<int (int, int)> f1 = std::bind(Func, 1, std::placeholders::_1, std::placeholders::_2);
std::function<int (int)> f2 = std::bind(f1, std::placeholders::_1, 3);
f2(2); // Func(1, 2, 3);
我觉得C++的function + bind会比Currying的可读性要好一些,毕竟我们可以完整看到f1和f2的函数类型,知道参数类型及个数和返回值,是有利于代码的可读性的,当然这里完全可以不写出f1和f2的类型,采用auto,我们同样可以从调用函数bind的placeholder的个数得知bind之后的function的参数个数,这样我们可以不用看到函数Func的声明,就知道需要传几个参数。function + bind跟Currying一样会影响代码的可读性,如果嵌套的层次越多,可读性就越差,所以使用这些特性的时候不要过度。
typeclass
Haskell用typeclass来表示一个concept,它是一组抽象函数的集合,一个满足某个typeclass的数据类型,它就可以跟其他使用这个typeclass的函数或者数据类型组合使用。typeclass一般这么定义:
class Monad m where
(>>=) :: m a -> (a -> m b) -> m b
(>>) :: m a -> m b -> m b
return :: a -> m a
fail :: String -> m a
它定义了一个叫Monad的typeclass,这个typeclass的concept里有四个函数,分别是(>>=), (>>), return和fail,m是一个带类型参数的数据类型。我们上面知道了Maybe是一个带类型参数的data类型,它定义如下:
data Maybe a = Nothing
| Just a
既然Maybe是一个带类型参数的data,那它就满足Monad typeclass中m的需求,因此可以把Maybe定义成Monad,如下:
instance Monad Maybe where
(>>=) maybeA f =
case maybeA of
Nothing -> Nothing
Just a -> f a
(>>) maybeA maybeB = maybeA >>= (\_ -> maybeB)
return = Just
fail = error
这里(\_ -> maybeB)定义了一个lambda,参数 _ 紧接 \,-> 后面则是函数体。函数(>>)和fail是可以作为默认实现放到class Monad的定义里面,而instance Monad的时候只需要实现(>>=)和return即可。
class Monad m where
(>>=) :: m a -> (a -> m b) -> m b
(>>) :: m a -> m b -> m b
(>>) ma mb = ma >>= (\_ -> mb)
return :: a -> m a
fail :: String -> m a
fail = error
对于内置list类型[a],也是带有一个类型参数a,因此,我们同样可以把[] instance成为class Monad,如下:
instance Monad [] where
(>>=) (x:xs) f = (f x) ++ (xs >>= f)
(>>=) [] _ = []
return a = [a]
函数(>>)和fail我们保留默认的实现即可。
Monad
上面实现的定义的typeclass就是Haskell著名的Monad,它是组合其他操作的一个基础typeclass,是与no pure交互的一个重要媒介。一般情况下Monad有两种,一种是数据wrapper,一种是action的wrapper。上面定义的Maybe Monad和list Monad都是数据类型的wrapper,它们实现了Monad定义的接口函数,我们还可以将其它data instance成Monad,只需要遵循了Monad的接口即可。
我们知道Haskell的函数都是pure的,没有任何状态的函数,但是与现实世界交互必然需要影响或修改某种状态,并且会需要顺序执行某些操作以完成交互。我们把action操作封装在一个data里面,并让它instance Monad,为了让前一个action的结果值作为某种状态往下传递,Monad的(>>=)就是为了这个目的而存在的,(>>=) 函数的类型是 m a -> (a -> m b) -> m b,它的意思就是执行封装在m a这个数据里面的action,然后把这个action的结果值做为参数传递给(>>=)的第二个参数(a -> m b),第二个参数是一个函数,这函数可以取用第一个参数的结果,再返回一个m b的数据,m b的数据也是一个action的封装,这样当一连串的(>>=)放到一起的时候,就可以把一个状态值作为action的参数和结果值往下传递。
从Monad的函数(>>)的实现我们可以看到,它把m a的action的结果值丢弃直接返回了m b,当一连串的(>>)放到一起的时候,其实就是让一组action顺序执行。通过(>>=)和(>>),可以把一组Monad action data组合起来。
IO Monad
IO Monad是一个把IO action封装的data,我们可以使用IO Monad与外界进行输入输出交互,下面是一个"hello world":
helloWorld = do
putStr "hello "
putStrLn "world"
这里do语法糖其实就是用的Monad来实现,展开之后是这样:
helloWorld =
(putStr "hello ") >>
(putStrLn "world")
由(>>)函数确定(putStr "hello ")和(putStrLn "world")需要是同一个Monad类型,我们可以查询到putStr和putStrLn的类型是String -> IO (),那么(putStr "hello ")和(putStrLn "world")的类型都是IO (),helloWorld函数把两个IO ()的action数据顺序组合起来生成一个新的IO (),当这个helloWorld IO action被执行的时候,它会依次执行封装在它里面的IO action。我们可以把helloWorld IO action放到Main函数里面然后编译执行,也可以直接在ghci里面执行。
我们可以自己定义某种data再instance Monad,这样可以构成一组data combination,可以实现任意的action combine。我山寨的极简的parse combinator的数据类型定义如下:
newtype Parser a = Parser {
runP :: State (ByteString, Context) a
} deriving (Monad, MonadState (ByteString, Context))
这里Parser带一个类型参数a,deriving (Monad, MonadState (ByteString, Context))表示编译器自动instance Monad和instance MonadState (ByteString, Context)。有了这个Parser之后,可以写出简单的几个combinator,然后使用这几个combinator组合成更加复杂的,组合的过程就是利用了Monad的组合能力。当所需的combinator都实现了好了之后,可以最终实现一个Parser a来分析整个C++文件:
file = repeatP $ spaceLine <||> normalLine
file就把分析整个C++文件所需的操作都combine到了一起,有了这个分析整个文件的Parser a之后,需要把它跑起来,那就需要定义下面这个函数:
runParse :: Parser a -> ByteString -> (a, (ByteString, Context))
runParse p b = runState (runP p) $ (b, emptyContext)
这个函数接受一个Parser a和一个文件内容ByteString作为参数,把整个Parser a封装的action用于分析文件内容,再产生一个分析结果。
这里的file,它是一个一个小的combinator构成的,每个combinator是一个action加上它所需数据构成一个“闭包”再存放到Parser a的data里面,其实可以认为实现了Monad的数据类型是一个“闭包”的载体。在其它语言里,我们可以使用闭包来实现combinator,我记得两年半前,我使用lua的闭包实现了一组游戏副本内容玩法操作的combinator,这些闭包自由组合在一起之后就能完成一个副本中所需的玩法操作。
Monad transformer
一种Monad类型只能封装和组合一种action操作,而与外界交互的时候,很多时候一种Monad类型是不够的,为了让多种Monad类型组合在一起,就需要定义Monad transformer,它跟Monad一样也是一个数据类型,不同的是它接受至少两种类型参数,其中一种就是Monad的类型,这样就可以把某个Monad类型嵌套在它里面。
newtype StateT s m a = StateT {
runStateT :: s -> m (a, s)
}
这里StateT就是一个Monad transformer,它允许嵌套一个Monad m类型,它是typeclass MonadState的一个instance,MonadState如下:
class Monad m => MonadState s m | m -> s where
get :: m s
put :: s -> m ()
为了让Monad transformer可以嵌套进StateT,其它类型的Monad transformer就需要instance MonadState,而StateT Monad transformer为了可以嵌套在其它Monad transformer中,就需要对其它Monad transformer抽象出来的typeclass instance,符合这种规则的Monad transformer就可以相互之间嵌套了,嵌套的层次可以任意深,这样构造出来的Monad里面有个Monad transformer stack,而这个新构造出来的Monad就可以使用多种Monad的action操作组合在一起了。
Monad transformer会带来一个问题,如果想定义一个新的Monad transformer,需要先抽象出这个Monad transformer的typeclass,就像MonadState typeclass一样,然后把其它Monad transformer都instance这个新抽象出来的typeclass,这样才能让这个新的Monad transformer嵌套在其它的Monad transformer之中,接着,为了让其它Monad transformer能够嵌套在新的Monad transformer之中,需要把新的Monad transformer instance其它Monad transformer抽象的typeclass。
我觉得其实Haskell为什么会有Monad和Monad transformer的存在,是因为Haskell是一个纯函数式语言,它本身没有顺序执行语句的能力,为了能让Haskell拥有修改外部状态并能够顺序执行语句的能力,引入了Monad,又为了让多种action的Monad能够组合到一起,由于Monad是一个data type,它不能简单的组合到一起,因为类型不一致,为了让它们组合到一起,又引入了更一般化的Monad transformer,让这些Monad transformer嵌套在一起构成一个stack,才能将这些不同类型的Monad组合。
Lazy evaluation
Haskell里面使用的是惰性求值方式,王垠说Haskell的惰性求值是一个很严重的问题。我目前也觉得惰性求值是一种负担,因为惰性求值,会使得程序很容易就出现space leak,我写的那两个版本的统计C++代码行工具都有这个问题,因为它是惰性求值,所以它会把整个目录的数据全部取出来构造存放到内存中,最后再进行求值,这就自然导致统计大量C++代码文件的目录时,占用内存会很高(几百M上G),也许当我进一步学习之后,我能够避免这种space leak,但这对于一个初学Haskell的人是一个不小的负担,因为随便写一个小程序都有可能耗用几百M的内存,而用其他语言实现的话,内存很容易很自然的控制在几M之内。(看完优化章节,只对程序修改了几行代码就让内存使用降到可以接受的程度,看来Lazy evaluation的问题没之前想像的那么严重。)
posted @
2013-04-30 20:41 airtrack 阅读(5501) |
评论 (0) |
编辑 收藏
摘要: 这篇文章是我两年多前写给同事看的,当时不少同事对编码了解甚少,直到现在发现还是很多人对编码了解甚少,所以我就把这篇文章发出来让大家参考一下,希望对一些人有帮助,不过这篇文章是当时花了3个小时左右写的,错误在所难免。字符编码历史计算机,发明在20世纪中期西方国家。计算机内部使用二进制作为表示任何东西的基础,为了能够在计算机中使用整数、浮点数等都要对其进行编码,只是这个编码是在硬件层的(CPU指令),...
阅读全文
posted @
2012-12-23 13:44 airtrack 阅读(4523) |
评论 (0) |
编辑 收藏