2. 解压至本地硬盘,我解压在D:/boost_1_46_1下。
3. 编译得到bjam.exe. 进入VS2008的Command Prompt,(一定要是这个,不能是cmd)转目录至D:/boost_1_46_1/tools/build/v2,然后执行批处理bootstrap.bat后,得到bjam.exe, 将其拷至Boost根目录下(即:D:/boost_1_46_1)
4. 利用bjam.exe编译得到Boost的lib文件。将VS2008的Command Prompt的执行目录转至D:/boost_1_46_1,然后输入:bjam --toolset=msvc-9.0 --build-type=complete stage 后开始编译,大概20分钟后,编译完成。生成的库文件位于D:/boost_1_46_1/stage/lib下。
/////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
Boost库是一个可移植、提供源代码的C++库,作为标准库的后备,是C++标准化进程的发动机之一。 Boost库由C++标准委员会库工作组成员发起,其中有些内容有望成为下一代C++标准库内容。在C++社区中影响甚大,是不折不扣的“准”标准库。 Boost由于其对跨平台的强调,对标准C++的强调,与编写平台无关。大部分boost库功能的使用只需包括相应头文件即可,少数(如正则表达式库,文件系统库等)需要链接库。但Boost中也有很多是实验性质的东西,在实际的开发中实用需要谨慎。boost 在一些播放软件和音效中指增强,比如Bass Boost,低音增强。
1.下载最新版的BOOST库,当前最新版为1.46.1(2011-3-12发布),下载链接地址:http://sourceforge.net/projects/boost/files/boost/1.46.1/
2.解压到硬盘上,其目录构造为
boost_1_46_1/ ................................boost根目录
index.htm ..................... www.boost.org 网站首页
boost/ ..............................所有的Boost头文件
lib/ .................................预编译的二进制库
libs/ ......................库的Tests, .cpps, docs等等
index.html .............................库文档开始处
algorithm/
any/
array/
…more libraries…
status/ .........................Boost-wide test suite
tools/ ...........实用工具, e.g. bjam, quickbook, bcp
more/ .......................................一些文档
doc/ ...............................所有库文档的一部分
3.打开根目录下的index.html,在上面的“Getting Started”有介绍怎么开始使用Boost的,大部分的Boost库只需要包含头文件即可,少部分需要编译链接。以下是必须编译的Boost库:
* Boost.Filesystem
* Boost.GraphParallel
* Boost.IOStreams
* Boost.MPI
* Boost.ProgramOptions
* Boost.Python
* Boost.Regex
* Boost.Serialization
* Boost.Signals
* Boost.System
* Boost.Thread
* Boost.Wave
另外,一些库可以是可选择编译的:
* Boost.DateTime (只有当你需要使用它的to_string/from_string或者serialization features, or if you're targeting Visual C++ 6.x or Borland.
* Boost.Graph (只有当你倾向解析 GraphViz 文件)
* Boost.Math (the TR1 and C99 cmath functions)
* Boost.Random (当你需要使用random_device的时候)
* Boost.Test (can be used in “header-only” or “separately compiled” mode)
4.下面开始一个无需编译Boost,直接使用头文件的示例:
①打开Visual Studio 2008,新建Visual C++工程,基于Win32控制台程序,工程名为example,确定之后,在弹出的对话框中“应用程序设置”打钩上“控制台应用程序”和“空项目”,点“完成”;
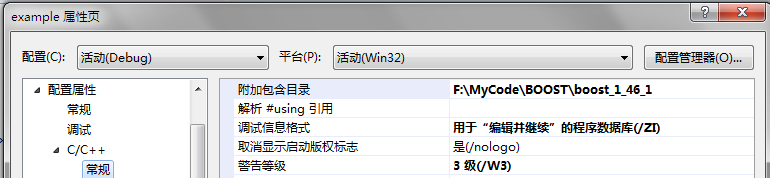
②在“解决方案资源管理器”右击example工程,选择“属性”→“C/C++”→“常规”→“附加包含目录”,输入刚才解压Boost的目录,比如“F:/MyCode/BOOST/boost_1_46_1”,如下图所示:
③右击example工程下的“源文件”→“添加”→“新建项”→左边的“代码”→选中右边的“C++文件(.cpp)”,文件名为example,点“添加”,输入以下代码:
#include <boost/lambda/lambda.hpp>
#include <iostream>
#include <iterator>
#include <algorithm>
int main()
{
using namespace boost::lambda;
typedef std::istream_iterator<int> in;
std::for_each(
in(std::cin), in(), std::cout << (_1 * 3) << " " );
}
④点击菜单栏上“生成”→“生成解决方案”,正常的话会编译通过,按F5可看结果,结果如下图所示:

这个example代码的功能是从标准输入中读取一系列整型,然后使用boost::lambda使之每个数乘以3,再把结果写进标准输出。
5.若是需要用到那些必须得编译链接的库,那么就得组建编译Boost库了。官方文档上介绍说可以使用安装版,或者自己编译源代码,特别介绍推荐在Microsoft Visual Studio开发环境下使用安装版,因为安装版可以直接下载,并且带有预编译好的库,节省自己编译源代码的麻烦。在这里,因为我使用的是Visual Studio 2008,故欲试试使用安装版。安装版是boostpro网站制作的,安装版不是跟官方的Boost同步的,会比较晚一些时间才会发布出来。当前最新版BoostPro 1.46.1 Installer (197K .exe),下载地址:http://www.boostpro.com/download/
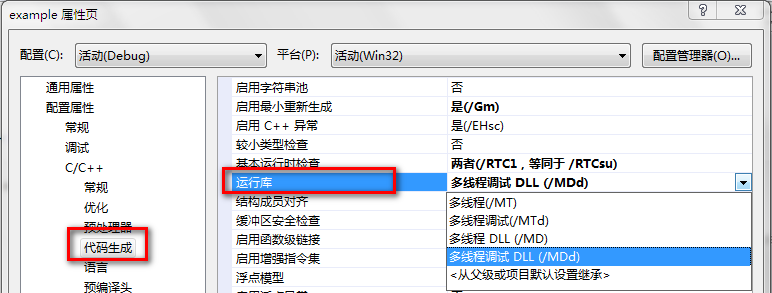
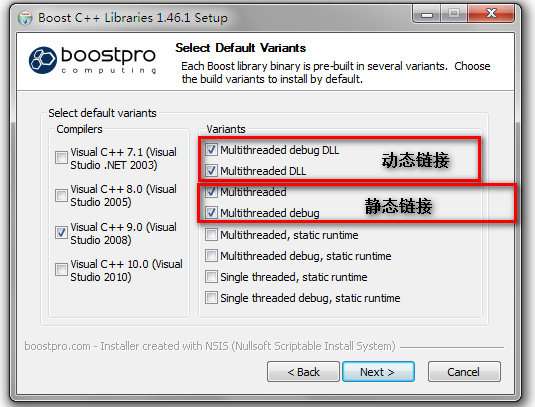
5.1运行安装版,一路“I Agree”,注意会连接网络,必须放行。之后会弹出选择下载Boost C++库1.46.1的镜像地址,默认就好,继续“Next”,弹出选择默认的编译类型,在左侧选择“Visual C++ 9”,在右侧选择类型,我们一般所用到的运行库比较多使用多线程,可以在上面的example工程看属性,如下图所示:
为此,我们只需选择上面四个选项,再根据动态链接和静态链接需求进行选择,如下图所示:
接下去就是选择组件安装,没啥问题就默认了,下一步选择路径,接着就开始下载了,如下图所示:
因为是连接网络下载,所以得一段比较长的时间,下载完之后就会自动安装好,在设定的目录下就有个lib文件夹,里面就是编译好的库。
5.2现在让我们测试一下那些需要链接才能使用的库:
①打开上面建立的example工程,将其cpp文件代码改为如下:
#include <boost/regex.hpp>
#include <iostream>
#include <string>
int main()
{
std::string line;
boost::regex pat( "^Subject: (Re: |Aw: )*(.*)" );
while (std::cin)
{
std::getline(std::cin, line);
boost::smatch matches;
if (boost::regex_match(line, matches, pat))
std::cout << matches[2] << std::endl;
}
}
此时,若是生成解决方案的话,就会提示 fatal error LNK1104: 无法打开文件“libboost_regex-vc90-mt-gd-1_46_1.lib”
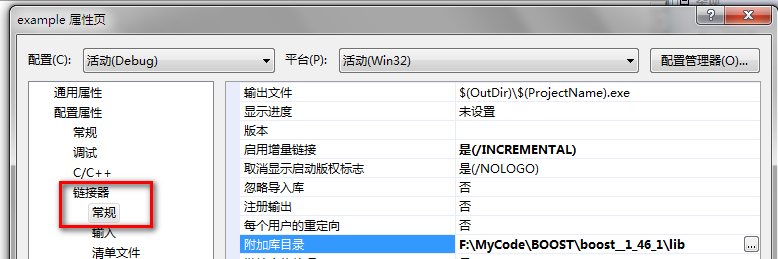
②右键example解决方案,选择“属性”→“配置属性”→“链接器”→“附加库目录”,添加安装版下载好的lib库文件夹路径,如下图所示:
③在菜单栏“生成”下拉选择“生成解决方案”,无警告无错误通过。将下面文字保存成文本文档,文件名为jayne.txt,内容如下:
To: George Shmidlap
From: Rita Marlowe
Subject: Will Success Spoil Rock Hunter?
---
See subject.
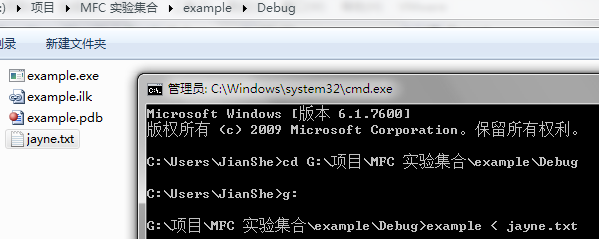
然后保存到工程目录的Debug文件夹下。接着Win+R输入CMD进入控制台,cd 转到此Debug目录下,输入example < jayne.txt命令,如下图所示:
回车之后,文本文档里面Subject主题的内容就会被正则匹配出来,如下图所示:

也可以不进入CMD控制台,直接在example解决方案右键“属性”→“调试”→“命令参数”,输入< jayne.txt ,按“确定”,直接Ctrl+F5运行程序,结果如下图所示:
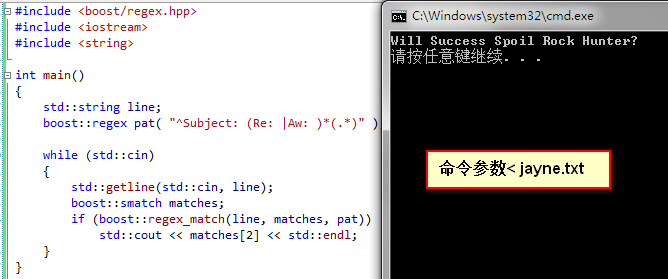
6.最后总结,Visual Studio环境的话可以直接下载安装版的,省去麻烦的编译过程,但是不带帮助文档,这点得自己再从官方网站下载了,目前有汉化Boost文档,还有一些不错的中文站点,列举如下:
boost文档汉化:http://code.google.com/p/boost-doc-zh/
在线汉化版文档:http://www.cppprog.com/boost_doc/