这一节关注根据key定位到数据进行删除的整个流程。
先来看这个过程的流程图,其实很简单,包括以下几个按部就班的步骤:

a) 首先,根据key查找对应的记录,这个在上一节已经完整的介绍过了,当时也提到,查找操作是后续进行删除和插入新数据时的基础。
如果没有找到记录,说明原来就没有,那么就不必继续下去了。
假设现在找到了所要删除的数据,接着以下几步:
b) 将该记录的magic number置为0xb0,第一节讲解hash数据库概述的时候提到过,每条记录的头部信息中有两种不同magic number,根据这个判断一条记录是否被删除了,现在将这个magic number置为0xb0就是表示这条记录已经被删除了。
c) 将这条被删除的记录插入到free pool数组中的合适位置,这是下一节的重点,这里先知道这个操作就好。
d) 上一节提到过,同一个bucket index是以二叉树形式组织在一起的,虽然不是平衡的二叉树,但是删除了一个数据之后会破坏二叉树的性质,所以需要在二叉树中找到合适的记录来替换删除这条记录之后剩下的位置。
熟悉数据结构与算法的都知道,一个排序二叉树如果按照中序遍历的话,那么是有序的。所以要在删除一个记录之后仍然保持排序二叉树的有序性,是删除操作的重点,下面就是TC中删除一个记录时的调整算法:
if rec.left is not null and rec.right is null
child = rec.left
else if rec.left is null and rec.right is not null
child = rec.right
else if rec.left is null and rec.right is null
child = null
else
child = rec.left
right = rec.right
rec.right = child
while (rec.right is not null)
rec = rec.right
rec.right = right
replace rec's original place with child
也可以从下图中来理解当删除一个记录时,它的左右子节点都不为空时的处理:
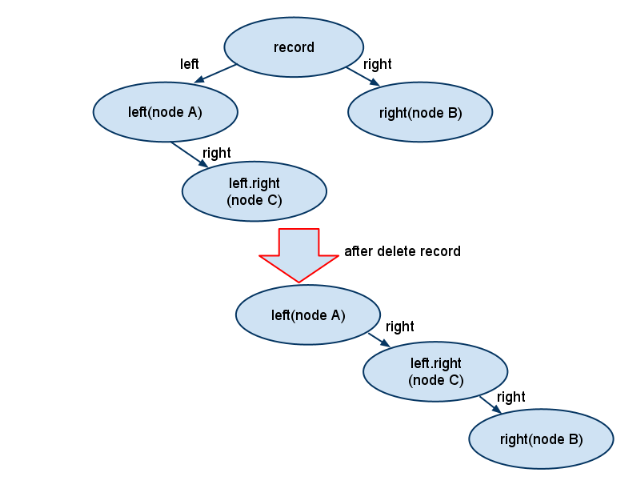
从图中可以看出,当所要删除的节点左右子节点都不为空时,会去寻找左子树中的最右边的子节点,然后将待删除记录的右子树变成这个最右子节点的右子树。
需要注意到的是,经典的数据结构算法中,当在排序二叉树中删除一个节点之后,所做的调整与上面的流程有所不同,虽然也是找到的原记录的左子树的最右节点,但是是将这个最右节点直接替换掉原来记录的位置,也就是如下图:
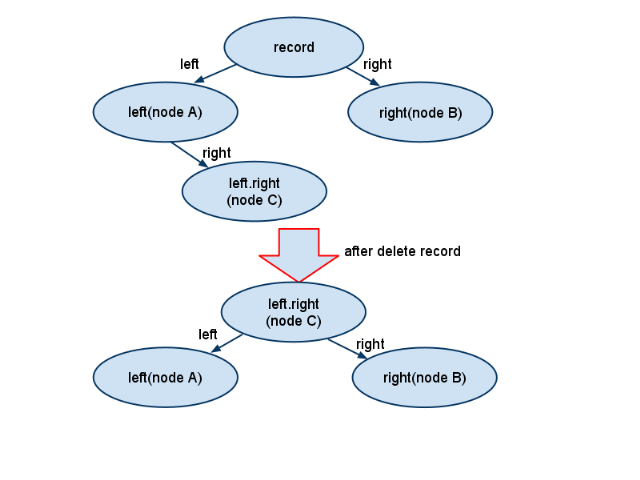
所以,这里出现了一个新的问题,TC中的调整算法是有可能导致删除记录之后二叉树不平衡的,那么为什么不选用第二种方法呢?
我的理解是:
1) 如前一节所述,TC中的二叉树本来就不是必然平衡的,所以TC中的这种调整算法有可能会有“负负得正”的结果。
2)第二种经典的做法中,需要的调整包括:a)将最右子节点从原来的父节点上删除 b)最右子节点要替换原记录的位置,那么要将原记录的左右子树分别赋值变为最右子节点的左右子树。上面的这个调整,每次调整都是需要修改节点的,而每次修改都会有对磁盘的I/O操作。
而第一种做法呢,仅需要一次修改操作-----将原记录的右子树变成最右子节点的右子树即可。
综合这几个因素,TC选择了I/O较少的做法。
我不清楚我的理解是否合理,欢迎补充。
e)删除了记录,也跳整了树的结构之后,最后的工作就是更新数据库文件header的信息---因为当前记录少了一条。
最后分析一下整个删除操作的最坏复杂度,还是以1G的bucket对16G的数据库文件记录为例:
1)首先查找元素,前面一节说了,需要O(4)次磁盘I/O+O(1)读取内存
2)接着置所删除记录的magic number,一次磁盘I/O
3)将删除插入到合适的free pool位置,这个下一节会提到,是在内存中进行的。
4)调整树结构,在所删除记录左右子树都存在的情况下,首先要找到最右子节点,这又是一个O(4)的磁盘I/O操作,最后将原记录的右子树赋值给最右子节点,又是一次磁盘I/O。不过,上面这个推断与前面是有矛盾的,假如在第一步查找中已经需要O(4)的代价才能定位到所删除元素了,那么最后的这个调整根本没有必要了。