一、word页眉页脚概述
页眉页脚是word文档中每个页面里上、下页边距界定的用于存储和显示文本、图形的信息区。页眉页脚常用于word文档的打印修饰,内容可以包括文档当前页页码、文档页数、文档建立日期时间、文档作者、文档标题、文档路径和文件名、公司徽标、边框线、特制图形等文字或图形。在word文档中设置页眉页脚可以在文档的任何显示浏览视图下进行,但只有页面视图、文档打印预览和文档打印中可以显示页眉页脚,其它视图下均看不见页眉页脚;将设置了页眉页脚的word文档另保存为Web网页文件时,其页眉页脚将不仅不显示而且也不能打印输出,不过当把Web网页文件转换回word文档后又可以还原其页眉页脚;在word文档中设置页眉页脚可自始至终用同一个页眉页脚,也可在文档的不同部分用不同的页眉页脚。例如,可以在首页上使用与众不同的页眉页脚或者首页上不使用页眉和页脚,还可以在奇数页和偶数页上设置不同的页眉页脚,当然也可以在文档的不同部分设置使用不同的页眉页脚,但必须进行文档分节处理。word应用程序中的“页眉页脚”命令位于“视图”菜单中,执行“页眉页脚”命令进入页眉页脚编辑状态系统会自动显示“页眉页脚”工具栏。
二、奇偶页显示不同内容
在专业出版的书籍中,常常看到书籍中奇偶页的页眉会显示不同的内容,以方便用户在书籍中快速查找资料。而在Word 2000中,用户也可以很方便地在文档奇偶页的页眉中显示不同的内容。
打开需要设置页眉格式的Word文档,选择“文件”菜单中“页面设置”命令,打开“页面设置”对话框,接着单击“版式”选项卡,在“页眉和眉脚”选项区中将“奇偶页不同”复选框选中,最后单击“确定”按钮结束设置。
选择“视图”菜单中“页眉和页脚”命令,将视图切换到页眉和页脚视图方式。这时可以看到光标在奇数页页眉编辑区中闪烁,输入奇数页眉内容;单击“页眉和页脚”工具栏上的“显示下一项”按钮,将光标移到偶数页页眉编辑区,输入偶数页页眉内容。
三、在页眉中显示章编号及章标题内容
要想在Word文档中实现在页眉中显示该页所在章的章编号及章标题内容的功能,用户首先必须在文档中对章标题使用统一的章标题样式,并且对章标题使用多级符号进行自动编号,然后按照如下的方法进行操作。
选择“视图”菜单中“页眉和页脚”命令,将视图切换到页眉和页脚视图方式。
选择“插入”菜单中的“域”命令,打开“域”对话框。从“类别”列表框中选择“链接和引用”,然后从“域名”列表框中选择“StyleRef”域。
单击“选项”命令,打开“域选项”对话框,单击“域专用开关”选项卡,从“开关”列表框中选择“\n”开关,单击“添加到域”按钮,将开关选项添加到域代码框中。
单击“样式”选项卡,从“名称”列表框中找到章标题所使用的样式名称,如“标题1”样式名称,然后单击“添加到域”按钮。
单击“确定”按钮将设置的域插入到页眉中,这时可以看到在页眉中自动出现了该页所在章的章编号及章标题内容。
四、修改页眉中的划线格式
用户选择在文档中使用页眉后,在页眉中就会出现一条横贯页面的划线。如果你对系统设置的划线格式不满意的话,可以采用下面的方法进行修改。
方法1:选择“视图”菜单中“页眉和页脚”命令,将视图切换到页眉和页脚视图方式。将光标定位到页眉位置处,选择“格式”菜单中的“边框和底纹”命令,打开“边框和底纹”对话框,单击“边框”选项卡,在“边框”设置页面中可以看到页眉中使用的是宽度为“0.75磅”的单实线。
如果需要修改页眉中的划线格式,可在此对话框中对边框的线型、颜色、宽度等项目进行修改。例如将划线由单实线改为双实线时,首先在“线型”下拉列表中选择“双实线”,然后在预览区域中单击两次下线按钮,即可将线型更改成双实线。
如果你不想在页眉中使用划线,只需在“设置”中选择“无”边框格式即可。
方法2:在Word 2000中页眉中使用的划线格式是由“页眉”样式中的设置所决定的,如果你想永久改变在页眉中所使用划线的格式时,只要在“页眉”样式中对划线格式进行修改就可以了。
选择“格式”菜单中的“样式”命令,打开“样式”对话框。在“样式”列表框中选择“页眉”,然后单击“更改”按钮,打开“更改样式”对话窗口。
单击“格式”按钮,在弹出的菜单中选择“边框”选项,打开“边框和底纹”对话框,然后按照修改页眉中的划线格式方法1所介绍的操作方法修改页眉中的划线格式。修改结束后,单击“确定”按钮返回“更改样式”对话窗口。
将“添至模板”复框选中,将样式添至附于活动文档的模板,以便使修改后的“页眉”样式可用于基于该模板新建的文档。单击“确定”按钮返回“样式”对话框,单击“应用”按钮结束设置。
以后只要在文档中使用页眉,在页眉中就会自动应用经过修改后的划线格式。
五、在任意位置插入页码
一般情况下我们都是在Word文档页面的上方或者下方位置插入页码。其实在Word 2000中,只要你愿意,就可以在Word文档页面中的任意位置插入页码。例如可以在页面左右页边中插入页码。
选择“视图”菜单中“页眉和页脚”命令,将视图切换到页眉和页脚视图方式。单击“绘图”工具栏上的“文本框”按钮,然后拖动鼠标在文档中任意位置绘制一个文本框。
单击“页眉和页脚”工具栏上的“插入页码”按钮。这时在文本框中就出现了该页所在的页码。此外还可以在文本框中添加其他说明文字,为文本框设置边框和底纹效果等。
采用此方法设置的页码对该文档中所有的页面都有效。
六、 页眉页脚的使用技巧
(1)、页眉页脚中横线格式的设置;①、横线格式设置;启动进入word页眉页脚编辑状态,默认情况下页眉文字、图形的下方都有一根水平实心细线(其属性为:边框、单实底线、0.75磅、边框间距1磅)。该线既可以删除取消也可以重新设置线条格式,它们都可以在页眉页脚编辑状态下通过调用“格式”菜单下的“边框和底纹”命令进入“边框和底纹”设置对话框,选择“边框”标签选项卡下的不同选项来完成;去掉页眉中的实心水平线的方法有;方法一、在“边框和底纹”对话框的“边框”标签选项卡下,选定“无边框”且设置应用范围为“段落”,单击“确定”按钮即可;方法二、在“边框和底纹”对话框的“边框”标签选项卡下,选定“方框”、“阴影”、“三维”或“自定义”之一,设置“颜色”为白色,选择作用范围为“段落”,单击“确定”。;方法三、在“页眉页脚”编辑状态下,选定页眉中包括段尾符在内的文字及图形,然后删除,关闭“页眉页脚”编辑返回word编辑状态即可;设置水平线格式的方法:在“边框和底纹”对话框的“边框”标签选项卡下,选定“自定义”——选择“线型”、 “颜色”和“宽度”——设置应用范围为“段落”,单击“确定;②、页眉线下文字的设置方法;页眉文字通常都位于实心水平线上方,称为线上文字。那么要实现线下文字该怎么办呢?其实很简单,只要在页眉的“边框和底纹”对话框中“边框”标签下将“自定义”边框的边框线设置成上边框类型并选择“作用范围”为“段落”,单击“确定”。页脚中一上、下线边框添加方法类似;
(2)、任意位置上页眉页脚对象设置; word页眉页脚通常位于文档页面的上、下页边距处,但这不是一成不变的。事实上,我们可将各种页眉页脚对象通过添加文本框的方式放置到文档中的任意位置处,也可以采用绘制图形、绘制自选图形的方式添加页眉页脚对象。对文本框对象和图形对象又都可以设置阴影效果和三维效果。
七、页眉页脚的特殊应用
(1)、手动制作word稿纸;众所周知,在word中要采用稿纸方式,一般是必须安装“稿纸向导”并通过在执行“文件”菜单下的“新建”,选择新建对话框中的“其它文档”标签下的“稿纸向导”,一步一步往下设置直到完成,即可建立起统一格式的word稿纸方式文档。那么,未安装word应用程序的“稿纸向导”是不是就不能制作稿纸方式文档了呢?回答当然是否定的。事实上word的稿纸向导,不外乎是一系列word命令的集合而已。通过仔细揣摩,我们发现了word的稿纸方式的方框格子,类似于word的页眉页脚的功能——设置一次以后新建页中自动添加且在当前文档编辑状态下无法选定……。沿此思路,我们找到了手动调word命令制作稿纸方式文档的方法——进入“页眉页脚”编辑状态,用绘图工具画出稿纸方式的方框格子,并作“页面设置”下的“文档网格”设置。具体方法如下;新建一个空白文档,执行“视图”菜单下的“页眉页脚”命令,进入页眉页脚编辑状态,启用显示文档文字(单击页眉页脚工具栏上的“显示/隐藏文档文字”按钮),用绘图工具栏上的“矩形”按钮绘制一个存放一个汉字大小的方框格子于文档区最左边(方框连长均为0.75cm),选定方格并按下Ctrl键向右拖曳复制方格使其相邻边框线完全重叠,依此复制成每行20个方格(也可复制到5个方格时,按下Shift同时选定5个方格,松开Shift键,再按下Ctrl向右拖曳,同样使得相邻方格边框重叠复制);同时选定第一行上的20个方框后将组合成一个整体,再按下Ctrl键向下复制成间隔等距的20行,又同时选定这20行方格再组合,最后画出一个大外框并设置线型为稍粗一点的线;至此,稿纸样式制作完成,但还需要设置页面中的“文档网格”格式为:每行20个字,每页20行。它是通过“文件”菜单下的“页面设置”来完成的;要制作个性化的word稿纸,也可用以上方法实现。如:设置稿纸方格线型、宽度、颜色,不同的行字符数和页行数等等。若想将已编辑存盘的word文档转为稿纸方式文档,可以在打开文档的条件下直接手动制作word稿纸来完成;
(2)、制作丰富多彩的word水印水印本质上是页眉页脚中的特殊对象——艺术字对象。只是用word应用程序窗口“格式”菜单的“背景”——“水印”制作的水印可以通过水印对话框修改、修饰和删除水印,而在页眉页脚编辑状态下插入的艺术字、文本框和图形图片水印是跟“水印”对话框不相关联的。诚然,用“水印”命令制作的水印,也可在页眉页脚编辑状态下选定、复制、编辑修改和删除;①、制作铺满页面的水印;用word“格式”菜单下的“水印”命令制作的水印,只有一个;即使你重复使用多次“水印”命令,它也只能不断地覆盖生成水印,最终只保留最后一次制作的水印。要想实现“水印”铺满页面,可以通过进入“页眉页脚”编辑状态,选定“水印”然后进行拖曳复制或复制——粘贴——移动来完成。只要是由“水印”命令制作的水印,不管你复制生成了多少个它们都与“水印”命令对话框关联,所以可以使用它修改和删除水印。不过一次只能操作一个水印对象;②、制作文字水印;在页眉页脚编辑状态下,插入文本框到word文档的文本区域内,输入文本——设置字符格式——隐藏文本框的边框;③、添加图形图片水印;在页眉页脚编辑状态下,插入文本框,置插入点I型指针于文本框内,插入图形或图片。绘制图形可以设置阴影或三维效果
posted @
2009-03-16 13:19 Benson 阅读(568) |
评论 (0) |
编辑 收藏1 从const int i 说起
有了const修饰的ic 我们不称它为变量,而称符号常量,代表着20这个数。这就是const 的作用。ic是不能在它处重新赋新值了。
认识了const 作用之后,另外,我们还要知道格式的写法。有两种:const int ic=20;与int const ic=20;。它们是完全相同的。这一点我们是要清楚。总之,你务必要记住const 与int哪个写前都不影响语义。有了这个概念后,我们来看这两个家伙:const int * pi与int const * pi ,按你的逻辑看,它们的语义有不同吗?呵呵,你只要记住一点,int 与const 哪个放前哪个放后都是一样的,就好比const int ic;与int const ic;一样。也就是说,它们是相同的。
好了,我们现在已经搞定一个“双包胎”的问题。那么int * const pi与前两个式子又有什么不同呢?我下面就来具体分析它们的格式与语义吧!
2 const int * pi的语义
我先来说说const int * pi是什么作用。看下面的例子:
int i1=30;
int i2=40;
const int * pi=&i1;
pi=&i2; //4.注意这里,pi可以在任意时候重新赋值一个新内存地址
i2=80; //5.想想看:这里能用*pi=80;来代替吗?当然不能
printf( “%d”, *pi ) ; //6.输出是80
语义分析:
看出来了没有啊,pi的值是可以被修改的。即它可以重新指向另一个地址的,但是,不能通过*pi来修改i2的值。这个规则符合我们前面所讲的逻辑吗?当然符合了!
首先const 修饰的是整个*pi(注意,我写的是*pi而不是pi)。所以*pi是常量,是不能被赋值的(虽然pi所指的i2是变量,不是常量)。
其次,pi前并没有用const 修饰,所以pi是指针变量,能被赋值重新指向另一内存地址的。你可能会疑问:那我又如何用const 来修饰pi呢?其实,你注意到int * const pi中const 的位置就大概可以明白了。请记住,通过格式看语义。
3 再看int * const pi
确实,int * const pi与前面的int const * pi会很容易给混淆的。注意:前面一句的const 是写在pi前和*号后的,而不是写在*pi前的。很显然,它是修饰限定pi的。我先让你看例子:
int i1=30;
int i2=40;
int * const pi=&i1;
//pi=&i2; 4.注意这里,pi不能再这样重新赋值了,即不能再指向另一个新地址。
//所以我已经注释了它。
i1=80; //5.想想看:这里能用*pi=80;来代替吗?可以,这里可以通过*pi修改i1的值。
//请自行与前面一个例子比较。
printf( “%d”, *pi ) ; //6.输出是80
语义分析:
看了这段代码,你明白了什么?有没有发现pi值是不能重新赋值修改了。它只能永远指向初始化时的内存地址了。相反,这次你可以通过*pi来修改i1的值了。与前一个例子对照一下吧!看以下的两点分析
1). pi因为有了const 的修饰,所以只是一个指针常量:也就是说pi值是不可修改的(即pi不可以重新指向i2这个变量了)(看第4行)。
2). 整个*pi的前面没有const 的修饰。也就是说,*pi是变量而不是常量,所以我们可以通过*pi来修改它所指内存i1的值(看5行的注释)
总之一句话,这次的pi是一个指向int变量类型数据的指针常量。
我最后总结两句:
1).如果const 修饰在*pi前则不能改的是*pi而不是指pi。
2).如果const 是直接写在pi前则pi不能改。
3.补充三种情况。
这里,我再补充以下三种情况。其实只要上面的语义搞清楚了,这三种情况也就已经被包含了。不过作为三种具体的形式,我还是简单提一下吧!
情况一:int * pi指针指向const int i常量的情况
const int i1=40;
int *pi;
pi=&i1;//这样可以吗?不行,VC下是编译错。
//const int 类型的i1的地址是不能赋值给指向int 类型地址的指针pi的。否则pi岂不是能修改i1的值了吗!
pi=(int* ) &i1; // 这样可以吗?强制类型转换可是C所支持的。
//VC下编译通过,但是仍不能通过*pi=80来修改i1的值。去试试吧!看看具体的怎样。
情况二:const int * pi指针指向const int i1的情况
const int i1=40;
const int * pi;
pi=&i1;//两个类型相同,可以这样赋值。很显然,i1的值无论是通过pi还是i1都不能修改的。
情况三:用const int * const pi申明的指针
int i
const int * const pi=&i;//你能想象pi能够作什么操作吗?pi值不能改,也不能通过pi修改i的值。因为不管是*pi还是pi都是const的。
posted @
2008-12-13 11:46 Benson 阅读(488) |
评论 (0) |
编辑 收藏
熵的概念最先在1864年首先由鲁道夫·克劳修斯提出,并应用在热力学中。后来在1948年由克劳德·艾尔伍德·香农第一次引入到信息论中来。
熵在信息论的定义如下:
如果有一个系统S内存在多个事件S = {E1,...,En}, 每个事件的概率分布 P = {p1, ..., pn},则每个事件本身的信息为
Ie = − log2pi
(对数以2为底,单位是比特(bit))
Ie = − lnpi
(对数以e为底,单位是纳特/nats)
如英语有26个字母,假如每个字母在文章中出现次数平均的话,每个字母的信息量为
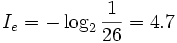
而汉字常用的有2500个,假如每个汉字在文章中出现次数平均的话,每个汉字的信息量为
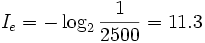
整个系统的平均信息量为
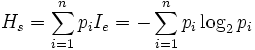
这个平均信息量就是信息熵。因为和热力学中描述热力学熵的玻耳兹曼公式形式一样,所以也称为“熵”。
如果两个系统具有同样大的信息量,如一篇用不同文字写的同一文章,由于是所有元素信息量的加和,那么中文文章应用的汉字就比英文文章使用的字母要少。所以汉字印刷的文章要比其他应用总体数量少的字母印刷的文章要短。即使一个汉字占用两个字母的空间,汉字印刷的文章也要比英文字母印刷的用纸少。实际上每个字母和每个汉字在文章中出现的次数并不平均,因此实际数值并不如同上述,但上述计算是一个总体概念。使用书写单元越多的文字,每个单元所包含的信息量越大。
- 熵均大于等于零,即,
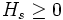 。
。
- 设N是系统S内的事件总数,则熵
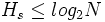 。当且仅当p1=p2=...=pn时,等号成立,此时系统S的熵最大。
。当且仅当p1=p2=...=pn时,等号成立,此时系统S的熵最大。
- 联合熵:
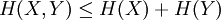 ,当且仅当X,Y在统计学上相互独立时等号成立。
,当且仅当X,Y在统计学上相互独立时等号成立。
- 条件熵:
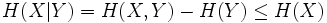 ,当且仅当X,Y在统计学上相互独立时等号成立。
,当且仅当X,Y在统计学上相互独立时等号成立。
posted @
2008-11-22 20:22 Benson 阅读(478) |
评论 (0) |
编辑 收藏
对操作系统而言,在进程Terminate之后回收进程占用的全部资源是最基本的要求.在一个程序结束(无论是怎么结束的)时,它所占用的内存会全部被释放.也就是说,如果windows的设计是正确的,那么所谓"被浪费的是硬盘上的空间"这种情况是绝对不可能出现的.如果出现,那么就是windows的一个特大bug.而windows是否真的有这个问题,第一,没有类似的报告.第二,我们也看不到windows的源代码.有兴趣的可以去看看Linux的代码,是如何管理内存的.
内存泄漏是指这样一种情况:按照设计,程序在完成一个任务之后应当不会占用更多的内存,但事实是占用变多了.引起内存泄漏的基本原因,就是在new以后没有delete(malloc以后没有free).java有垃圾回收机制,但显然,这是以牺牲性能为代价的,对响应要求高的环境下,这恐怕是通不过的.
另外,操作系统是不能自动回收进程占用的内存,除非进程显式的通知操作系统放弃某块空间,操作系统并不负责检查进程中每一部分的使用情况(它也不能负责,操作系统是不会知道进程中有些什么变量的).java的回收是进程本身的一种自动检查功能,和操作系统完全无关.
posted @
2008-11-21 23:33 Benson 阅读(543) |
评论 (0) |
编辑 收藏
回调函数是应用程序提供给Windows系统DLL或其它DLL调用的函数,一般用于截获消息、获取系统信息或处理异步事件。应用程序把回调函数的地址指针告诉DLL,而DLL在适当的时候会调用该函数。回调函数必须遵守事先规定好的参数格式和传递方式,否则DLL一调用它就会引起程序或系统的崩溃。通常情况下,回调函数采用标准WindowsAPI的调用方式,即__stdcall,当然,DLL编制者可以自己定义调用方式,但客户程序也必须遵守相同的规定。在__stdcall方式下,函数的参数按从右到左的顺序压入堆栈,除了明确指明是指针或引用外,参数都按值传递,函数返回之前自己负责把参数从堆栈中弹出。
理解回调函数!
程序在调用一个函数(function)时(通常指api).相当于程序(program)呼叫(Call)了一个函数(function)关系表示如下:
call(调用)
program --------------------→ dll
程序在调用一个函数时,将自己的函数的地址作为参数传递给程序调用的函数时(那么这个自己的函数称回调函数).需要回调函数的 DLL 函数往往是一些必须重复执行某些操作的函数.关系表示如下:
call(调用)
program --------------------→ dll
↑ ¦
¦_______________________________¦
callback(回调)
当你调用的函数在传递返回值给回调函数时,你就可以利用回调函数来处理或完成一定的操作。至于如何定义自己的回调函数,跟具体使用的API函数有关,很多不同类别的回调函数有各种各样的参数,有关这些参数的描述一般在帮助中有说明回调函数的参数和返回值等.其实简单说回调函数就是你所写的函数满足一定条件后,被DLL调用!
也有这样的说法(比较容易理解):
回调函数就好像是一个中断处理函数,系统在符合你设定的条件时自动调用。为此,你需要做三件事:
1. 声明;
2. 定义;
3. 设置触发条件,就是在你的函数中把你的回调函数名称转化为地址作为一个参数,以便于DLL调用。
posted @
2008-11-21 20:42 Benson 阅读(663) |
评论 (0) |
编辑 收藏SQL 里面最常用的命令是 SELECT 语句,用于检索数据。语法是:
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
[ INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table ]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT [ ALL ] } select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ FOR UPDATE [ OF class_name [, ...] ] ]
[ LIMIT { count | ALL } [ { OFFSET | , } start ]]
现在我们将通过不同的例子演示 SELECT 语句复杂的语法。用于这些例子的表在 供应商和部件数据库 里定义。
这里是一些使用 SELECT 语句的简单例子:
Example 1-4. 带有条件的简单查询
要从表 PART 里面把字段 PRICE 大于 10 的所有记录找出来, 我们写出下面查询:
SELECT * FROM PART
WHERE PRICE > 10;
然后得到表:
PNO | PNAME | PRICE
-----+---------+--------
3 | Bolt | 15
4 | Cam | 25
在 SELECT语句里使用 "*" 将检索出表中的所有属性。 如果我们只希望从表 PART 中检索出属性 PNAME 和 PRICE, 我们使用下面的语句:
SELECT PNAME, PRICE
FROM PART
WHERE PRICE > 10;
这回我们的结果是:
PNAME | PRICE
--------+--------
Bolt | 15
Cam | 25
请注意
SQL 的 SELECT 语句对应关系演算里面的 "projection" (映射),而不是 "selection"(选择)(参阅
关系演算 获取详细信息)。
WHERE 子句里的条件也可以用关键字 OR,AND,和 NOT 逻辑地连接起来:
SELECT PNAME, PRICE
FROM PART
WHERE PNAME = 'Bolt' AND
(PRICE = 0 OR PRICE <= 15);
这样将生成下面的结果:
PNAME | PRICE
--------+--------
Bolt | 15
目标列表和 WHERE 子句里可以使用算术操作。例如, 如果我们想知道如果我们买两个部件的话要多少钱, 我们可以用下面的查询:
SELECT PNAME, PRICE * 2 AS DOUBLE
FROM PART
WHERE PRICE * 2 < 50;
这样我们得到:
PNAME | DOUBLE
--------+---------
Screw | 20
Nut | 16
Bolt | 30
请注意在关键字 AS 后面的 DOUBLE 是第二个列的新名字。 这个技巧可以用于目标列表里的每个元素, 给它们赋予一个在结果列中显示的新的标题。 这个新的标题通常称为别名。这个别名不能在该查询的其他地方使用。
下面的例子显示了 SQL 里是如何实现连接的。
要在共同的属性上连接三个表 SUPPLIER,PART 和 SELLS, 我们通常使用下面的语句:
SELECT S.SNAME, P.PNAME
FROM SUPPLIER S, PART P, SELLS SE
WHERE S.SNO = SE.SNO AND
P.PNO = SE.PNO;
而我们得到的结果是:
SNAME | PNAME
-------+-------
Smith | Screw
Smith | Nut
Jones | Cam
Adams | Screw
Adams | Bolt
Blake | Nut
Blake | Bolt
Blake | Cam
在 FROM 子句里,我们为每个关系使用了一个别名, 因为在这些关系间有着公共的命名属性(SNO 和 PNO)。 现在我们可以区分不同表的公共命名属性, 只需要简单的用每个关系的别名加上个点做前缀就行了。 联合是用与 一个内部联接 里显示的同样的方法计算的。首先算出笛卡儿积 SUPPLIER × PART × SELLS 。然后选出那些满足 WHERE 子句里给出的条件的记录 (也就是说,公共命名属性的值必须相等)。 最后我们映射出除 S.SNAME 和 P.PNAME 外的所有属性。
另外一个进行连接的方法是使用下面这样的 SQL JOIN 语法:
select sname, pname from supplier
JOIN sells USING (sno)
JOIN part USING (pno);
giving again:
sname | pname
-------+-------
Smith | Screw
Adams | Screw
Smith | Nut
Blake | Nut
Adams | Bolt
Blake | Bolt
Jones | Cam
Blake | Cam
(8 rows)
一个用 JOIN 语法创建的连接表,是一个出现在 FROM 子句里的, 在任何 WHERE,GROUP BY 或 HAVING 子句之前的表引用列表项. 其它表引用,包括表名字或者其它 JOIN 子句,如果用逗号分隔的话, 可以包含在 FROM 子句里. 连接生成的表逻辑上和任何其它在 FROM 子句里列出的表都一样.
SQL JOIN 有两种主要类型,CROSS JOIN (无条件连接) 和条件连接.条件连接还可以根据声明的 连接条件(ON,USING,或 NATURAL)和它 应用的方式(INNER 或 OUTER 连接)进一步细分.
连接类型
- CROSS JOIN
-
{ T1 } CROSS JOIN { T2 }
一个交叉连接(cross join)接收两个分别有 N 行和 M 行 的表 T1 和 T2,然后返回一个包含交叉乘积 NxM 条记录的 连接表. 对于 T1 的每行 R1,T2 的每行 R2 都与 R1 连接生成 连接的表行 JR,JR 包含所有 R1 和 R2 的字段. CROSS JOIN 实际上就是一个 INNER JOIN ON TRUE.
- 条件 JOIN
-
{ T1 } [ NATURAL ] [ INNER | { LEFT | RIGHT | FULL } [ OUTER ] ] JOIN { T2 } { ON search condition | USING ( join column list ) }
一个条件 JOIN 必须通过提供一个(并且只能有一个) NATURAL,ON,或者 USING 这样的关键字来声明它的 连接条件. ON 子句 接受一个 search condition, 它与一个 WHERE 子句相同.USING 子句接受一个用逗号分隔的 字段名列表,连接表中必须都有这些字段, 并且用那些字段连接这些表,生成的连接表包含每个共有字段 和两个表的所有其它字段. NATURAL 是 USING 子句的缩写,它列出两个表中所有公共 的字段名字.使用 USING 和 NATURAL 的副作用是 每个连接的字段都只有一份拷贝出现在结果表中 (与前面定义的关系演算的 JOIN 相比较).
-
[ INNER ] JOIN
-
对于 T1 的每行 R1,连接成的表在 T2 里都有一行满 足与 R1 一起的连接条件.
对于所有 JOIN 而言,INNER 和 OUTER 都是可选的.INNER 是缺省. LEFT,RIGHT,和 FULL 只用于 OUTER JOIN.
-
LEFT [ OUTER ] JOIN
-
首先,执行一次 INNER JOIN. 然后,如果 T1 里有一行对任何 T2 的行都不满足 连接条件,那么返回一个连接行,该行的 T2 的字段 为 null.
小技巧: 连接成的表无条件地包含 T1 里的所有行.
-
RIGHT [ OUTER ] JOIN
-
首先,执行一次 INNER JOIN. 然后,如果 T2 里有一行对任何 T1 的行都不满足 连接条件,那么返回一个连接行,该行的 T1 的字段 为 null.
小技巧: 连接成的表无条件地包含 T2 里的所有行.
-
FULL [ OUTER ] JOIN
-
首先,执行一次 INNER JOIN. 然后,如果 T1 里有一行对任何 T2 的行都不满足 连接条件,那么返回一个连接行,该行的 T1 的字段 为 null. 同样,如果 T2 里有一行对任何 T1 的行都不满足 连接条件,那么返回一个连接行,该行的 T2 的字段 为 null.
小技巧: 连接成的表无条件地拥有来自 T1 的每 一行和来自 T2 的每一行.
所有 类型的 JOIN 都可以链接在一起或者嵌套在一起, 这时 T1 和 T2 都可以是连接生成的表.我们可以使用圆括弧控制 JOIN 的顺序,如果我们不主动控制,那么连接顺序是从左到右.
SQL 提供以一些聚集操作符(如, AVG,COUNT,SUM,MIN,MAX),这些聚集操作符以一个表达式为参数。 只要是满足 WHERE 子句的行,就会计算这个表达式, 然后聚集操作符对这个输入数值的集合进行计算. 通常,一个聚集对整个 SELECT 语句计算的结果是 生成一个结果.但如果在一个查询里面声明了分组, 那么数据库将对每个组进行一次独立的计算,并且 聚集结果是按照各个组出现的(见下节).
Example 1-5. 聚集
果我们想知道表 PART 里面所有部件的平均价格,我们可以使用下面查询:
SELECT AVG(PRICE) AS AVG_PRICE
FROM PART;
结果是:
AVG_PRICE
-----------
14.5
如果我们想知道在表 PART 里面存储了多少部件,我们可以使用语句:
SELECT COUNT(PNO)
FROM PART;
得到:
COUNT
-------
4
SQL 允许我们把一个表里面的记录分成组。 然后上面描述的聚集操作符可以应用于这些组上 (也就是说,聚集操作符的值不再是对所有声明的列的值进行操作, 而是对一个组的所有值进行操作。这样聚集函数是为每个组独立地进行计算的。)
对记录的分组是通过关键字 GROUP BY 实现的,GROUP BY 后面跟着一个定义组的构成的属性列表。 如果我们使用语句 GROUP BY A1, ⃛, Ak 我们就把关系分成了组,这样当且仅当两条记录在所有属性 A1, ⃛, Ak 上达成一致,它们才是同一组的。
Example 1-6. 聚集
如果我们想知道每个供应商销售多少个部件,我们可以这样写查询:
SELECT S.SNO, S.SNAME, COUNT(SE.PNO)
FROM SUPPLIER S, SELLS SE
WHERE S.SNO = SE.SNO
GROUP BY S.SNO, S.SNAME;
得到:
SNO | SNAME | COUNT
-----+-------+-------
1 | Smith | 2
2 | Jones | 1
3 | Adams | 2
4 | Blake | 3
然后我们看一看发生了什么事情。首先生成表 SUPPLIER 和 SELLS 的连接:
S.SNO | S.SNAME | SE.PNO
-------+---------+--------
1 | Smith | 1
1 | Smith | 2
2 | Jones | 4
3 | Adams | 1
3 | Adams | 3
4 | Blake | 2
4 | Blake | 3
4 | Blake | 4
然后我们把那些属性 S.SNO 和 S.SNAME 相同的记录放在组中:
S.SNO | S.SNAME | SE.PNO
-------+---------+--------
1 | Smith | 1
| 2
--------------------------
2 | Jones | 4
--------------------------
3 | Adams | 1
| 3
--------------------------
4 | Blake | 2
| 3
| 4
在我们的例子里,我们有四个组并且现在我们可以对每个组应用聚集操作符 COUNT,生成上面给出的查询的最终结果。
请注意如果要让一个使用 GROUP BY 和聚集操作符的查询的结果有意义, 那么用于分组的属性也必须出现在目标列表中。 所有没有在 GROUP BY 子句里面出现的属性都只能通过使用聚集函数来选择。 否则就不会有唯一的数值与其它字段关联.
还要注意的是在聚集上聚集是没有意义的,比如,AVG(MAX(sno)), 因为 SELECT 只做一个回合的分组和聚集.你可以获得这样的结果, 方法是使用临时表或者在 FROM 子句中使用一个子 SELECT 做第一个层次的聚集.
HAVING 子句运做起来非常象 WHERE 子句, 只用于对那些满足 HAVING 子句里面给出的条件的组进行计算。 其实,WHERE 在分组和聚集之前过滤掉我们不需要的输入行, 而 HAVING 在 GROUP 之后那些不需要的组. 因此,WHERE 无法使用一个聚集函数的结果. 而另一方面,我们也没有理由写一个不涉及聚集函数的 HAVING. 如果你的条件不包含聚集,那么你也可以把它写在 WHERE 里面, 这样就可以避免对那些你准备抛弃的行进行的聚集运算.
Example 1-7. Having
如果我们想知道那些销售超过一个部件的供应商,使用下面查询:
SELECT S.SNO, S.SNAME, COUNT(SE.PNO)
FROM SUPPLIER S, SELLS SE
WHERE S.SNO = SE.SNO
GROUP BY S.SNO, S.SNAME
HAVING COUNT(SE.PNO) > 1;
and get:
SNO | SNAME | COUNT
-----+-------+-------
1 | Smith | 2
3 | Adams | 2
4 | Blake | 3
在 WHERE 和 HAVING 子句里,允许在任何要产生数值的地方使用子查询 (子选择)。 这种情况下,该值必须首先来自对子查询的计算。子查询的使用扩展了 SQL 的表达能力。
Example 1-8. 子查询
如果我们想知道所有比名为 'Screw' 的部件贵的部件,我们可以用下面的查询:
SELECT *
FROM PART
WHERE PRICE > (SELECT PRICE FROM PART
WHERE PNAME='Screw');
结果是:
PNO | PNAME | PRICE
-----+---------+--------
3 | Bolt | 15
4 | Cam | 25
当我们检查上面的查询时会发现出现了两次 SELECT 关键字。 第一个在查询的开头 - 我们将称之为外层 SELECT - 而另一个在 WHERE 子句里面,成为一个嵌入的查询 - 我们将称之为内层 SELECT。 对外层 SELECT 的每条记录都必须先计算内层 SELECT。在完成所有计算之后, 我们得知名为 'Screw' 部件的记录的价格, 然后我们就可以检查那些价格更贵的记录了。 (实际上,在本例中,内层查询只需要执行一次, 因为它不依赖于外层查询高等状态.)
如果我们想知道那些不销售任何部件的供应商 (比如说,我们想把这些供应商从数据库中删除),我们用:
SELECT *
FROM SUPPLIER S
WHERE NOT EXISTS
(SELECT * FROM SELLS SE
WHERE SE.SNO = S.SNO);
在我们的例子里,结果列将是空的,因为每个供应商至少销售一个部件。 请注意我们在 WHERE 子句的内层 SELECT 里使用了来自外层 SELECT 的 S.SNO。 正如前面所说的,子查询为每个外层查询计算一次,也就是说, S.SNO 的值总是从外层 SELECT 的实际记录中取得的。
一种有些特别的子查询的用法是把它们放在 FROM 子句里. 这个特性很有用,因为这样的子查询可以输出多列和多行, 而在表达式里使用的子查询必须生成一个结果. FROM 里的子查询还可以让我们获得多于一个回合的分组/聚集特性, 而不需要求助于临时表.
Example 1-9. FROM 里面的子查询
如果我们想知道在所有我们的供应商中的最高平均部件价格的那家, 我们不能用 MAX(AVG(PRICE)),但我们可以这么写:
SELECT MAX(subtable.avgprice)
FROM (SELECT AVG(P.PRICE) AS avgprice
FROM SUPPLIER S, PART P, SELLS SE
WHERE S.SNO = SE.SNO AND
P.PNO = SE.PNO
GROUP BY S.SNO) subtable;
这个子查询为每个供应商返回一行(因为它的 GROUP BY) 然后我们在外层查询对所有行进行聚集.
这些操作符分别计算两个子查询产生的元组的联合,相交和集合理论里的相异。
Example 1-10. Union, Intersect, Except
下面的例子是 UNION 的例子:
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNAME = 'Jones'
UNION
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNAME = 'Adams';
产生结果:
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
3 | Adams | Vienna
下面是相交( INTERSECT)的例子:
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO > 1
INTERSECT
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO < 3;
产生结果:
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
两个查询都会返回的元组是那条 SNO=2 的
最后是一个 EXCEPT 的例子:
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO > 1
EXCEPT
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO > 3;
结果是:
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
3 | Adams | Vienna
posted @
2008-11-21 17:00 Benson 阅读(1056) |
评论 (0) |
编辑 收藏/****strlen.c - contains strlen() routine
*
* Copyright (c) 1985-1997, Microsoft Corporation. All rights reserved.
*
*Purpose:
* strlen returns the length of a null-terminated string,
* not including the null byte itself.
*
*******************************************************************************/
#include <cruntime.h>
#include <string.h>
#ifdef _MSC_VER
#pragma function(strlen)
#endif /* _MSC_VER */
/****strlen - return the length of a null-terminated string
*
*Purpose:
* Finds the length in bytes of the given string, not including
* the final null character.
*
*Entry:
* const char * str - string whose length is to be computed
*
*Exit:
* length of the string "str", exclusive of the final null byte
*
*Exceptions:
*
*******************************************************************************/
size_t __cdecl strlen (
const char * str
)
{
const char *eos = str;
while( *eos++ );
return( (int)(eos - str - 1) );
}
posted @
2008-11-21 12:39 Benson 阅读(641) |
评论 (0) |
编辑 收藏
 /**//****strcat.c - contains strcat() and strcpy()
/**//****strcat.c - contains strcat() and strcpy()
 *
*
* Copyright (c) 1985-1997, Microsoft Corporation. All rights reserved.
*
*Purpose:
* Strcpy() copies one string onto another.
*
* Strcat() concatenates (appends) a copy of the source string to the
* end of the destination string, returning the destination string.
*
 *******************************************************************************/
*******************************************************************************/

#include <cruntime.h>
#include <string.h>
#ifndef _MBSCAT
#ifdef _MSC_VER
#pragma function(strcat,strcpy)
#endif /* _MSC_VER */
#endif /* _MBSCAT */
/**//****char *strcat(dst, src) - concatenate (append) one string to another
*
*Purpose:
* Concatenates src onto the end of dest. Assumes enough
* space in dest.
*
*Entry:
* char *dst - string to which "src" is to be appended
* const char *src - string to be appended to the end of "dst"
*
*Exit:
* The address of "dst"
*
*Exceptions:
*
*******************************************************************************/
char * __cdecl strcat (
char * dst,
const char * src
)
 {
{
char * cp = dst;
while( *cp )

 cp++; /**//* find end of dst */
cp++; /**//* find end of dst */
while( *cp++ = *src++ ) ; /**//* Copy src to end of dst */
return( dst ); /**//* return dst */
}
/**//****char *strcpy(dst, src) - copy one string over another
*
*Purpose:
* Copies the string src into the spot specified by
* dest; assumes enough room.
*
*Entry:
* char * dst - string over which "src" is to be copied
* const char * src - string to be copied over "dst"
*
*Exit:
* The address of "dst"
*
*Exceptions:
*******************************************************************************/
char * __cdecl strcpy(char * dst, const char * src)
{
char * cp = dst;
while( *cp++ = *src++ ); /**//* Copy src over dst */
return( dst );
}posted @
2008-11-21 12:34 Benson 阅读(1766) |
评论 (0) |
编辑 收藏
/**//****strcmp.c - routine to compare two strings (for equal, less, or greater)
*
* Copyright (c) 1985-1997, Microsoft Corporation. All rights reserved.
*
*Purpose:
* Compares two string, determining their lexical order.
*
*******************************************************************************/
#include <cruntime.h>
#include <string.h>
#ifdef _MSC_VER
#pragma function(strcmp)
#endif /* _MSC_VER */
/**//***
*strcmp - compare two strings, returning less than, equal to, or greater than
*
*Purpose:
* STRCMP compares two strings and returns an integer
* to indicate whether the first is less than the second, the two are
* equal, or whether the first is greater than the second.
*
* Comparison is done byte by byte on an UNSIGNED basis, which is to
* say that Null (0) is less than any other character (1-255).
*
*Entry:
* const char * src - string for left-hand side of comparison
* const char * dst - string for right-hand side of comparison
*
*Exit:
* returns -1 if src < dst
* returns 0 if src == dst
* returns +1 if src > dst
*
*Exceptions:
*
*******************************************************************************/
int __cdecl strcmp (
const char * src,
const char * dst
)
{
int ret = 0 ;
while( ! (ret = *(unsigned char *)src - *(unsigned char *)dst) && *dst)
++src, ++dst;
if ( ret < 0 )
ret = -1 ;
else if ( ret > 0 )
ret = 1 ;
return( ret );
}
posted @
2008-11-21 12:29 Benson 阅读(1043) |
评论 (0) |
编辑 收藏
数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。
设计范式是不是很难懂呢?非也,大学教材上给我们一堆数学公式我们当然看不懂,也记不住。所以我们很多人就根本不按照范式来设计数据库。
实质上,设计范式用很形象、很简洁的话语就能说清楚,道明白。本文将对范式进行通俗地说明,并以笔者曾经设计的一个简单论坛的数据库为例来讲解怎样将这些范式应用于实际工程。
范式说明
第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
例如,如下的数据库表是符合第一范式的:
而这样的数据库表是不符合第一范式的:
| 字段1 |
字段2 |
字段3 |
字段4 |
| |
|
字段3.1 |
字段3.2 |
|
很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
第二范式(2NF):数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。
假定选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),关键字为组合关键字(学号, 课程名称),因为存在如下决定关系:
(学号, 课程名称) → (姓名, 年龄, 成绩, 学分)
这个数据库表不满足第二范式,因为存在如下决定关系:
(课程名称) → (学分)
(学号) → (姓名, 年龄)
即存在组合关键字中的字段决定非关键字的情况。
由于不符合2NF,这个选课关系表会存在如下问题:
(1) 数据冗余:
同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。
(2) 更新异常:
若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
(3) 插入异常:
假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据库。
(4) 删除异常:
假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
把选课关系表SelectCourse改为如下三个表:
学生:Student(学号, 姓名, 年龄);
课程:Course(课程名称, 学分);
选课关系:SelectCourse(学号, 课程名称, 成绩)。
这样的数据库表是符合第二范式的,消除了数据冗余、更新异常、插入异常和删除异常。
另外,所有单关键字的数据库表都符合第二范式,因为不可能存在组合关键字。
第三范式(3NF):在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系:
关键字段 → 非关键字段x → 非关键字段y
假定学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号) → (姓名, 年龄, 所在学院, 学院地点, 学院电话)
这个数据库是符合2NF的,但是不符合3NF,因为存在如下决定关系:
(学号) → (所在学院) → (学院地点, 学院电话)
即存在非关键字段"学院地点"、"学院电话"对关键字段"学号"的传递函数依赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况,读者可自行分析得知。
把学生关系表分为如下两个表:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 地点, 电话)。
这样的数据库表是符合第三范式的,消除了数据冗余、更新异常、插入异常和删除异常。
鲍依斯-科得范式(BCNF):在第三范式的基础上,数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符合第三范式。
假设仓库管理关系表为StorehouseManage(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。它会出现如下异常情况:
(1) 删除异常:
当仓库被清空后,所有"存储物品ID"和"数量"信息被删除的同时,"仓库ID"和"管理员ID"信息也被删除了。
(2) 插入异常:
当仓库没有存储任何物品时,无法给仓库分配管理员。
(3) 更新异常:
如果仓库换了管理员,则表中所有行的管理员ID都要修改。
把仓库管理关系表分解为二个关系表:
仓库管理:StorehouseManage(仓库ID, 管理员ID);
仓库:Storehouse(仓库ID, 存储物品ID, 数量)。
这样的数据库表是符合BCNF范式的,消除了删除异常、插入异常和更新异常。
范式应用
我们来逐步搞定一个论坛的数据库,有如下信息:
(1) 用户:用户名,email,主页,电话,联系地址
(2) 帖子:发帖标题,发帖内容,回复标题,回复内容
第一次我们将数据库设计为仅仅存在表:
| 用户名 |
email |
主页 |
电话 |
联系地址 |
发帖标题 |
发帖内容 |
回复标题 |
回复内容 |
这个数据库表符合第一范式,但是没有任何一组候选关键字能决定数据库表的整行,唯一的关键字段用户名也不能完全决定整个元组。我们需要增加"发帖ID"、"回复ID"字段,即将表修改为:
| 用户名 |
email |
主页 |
电话 |
联系地址 |
发帖ID |
发帖标题 |
发帖内容 |
回复ID |
回复标题 |
回复内容 |
这样数据表中的关键字(用户名,发帖ID,回复ID)能决定整行:
(用户名,发帖ID,回复ID) → (email,主页,电话,联系地址,发帖标题,发帖内容,回复标题,回复内容)
但是,这样的设计不符合第二范式,因为存在如下决定关系:
(用户名) → (email,主页,电话,联系地址)
(发帖ID) → (发帖标题,发帖内容)
(回复ID) → (回复标题,回复内容)
即非关键字段部分函数依赖于候选关键字段,很明显,这个设计会导致大量的数据冗余和操作异常。
我们将数据库表分解为(带下划线的为关键字):
(1) 用户信息:用户名,email,主页,电话,联系地址
(2) 帖子信息:发帖ID,标题,内容
(3) 回复信息:回复ID,标题,内容
(4) 发贴:用户名,发帖ID
(5) 回复:发帖ID,回复ID
这样的设计是满足第1、2、3范式和BCNF范式要求的,但是这样的设计是不是最好的呢?
不一定。
观察可知,第4项"发帖"中的"用户名"和"发帖ID"之间是1:N的关系,因此我们可以把"发帖"合并到第2项的"帖子信息"中;第5项"回复"中的"发帖ID"和"回复ID"之间也是1:N的关系,因此我们可以把"回复"合并到第3项的"回复信息"中。这样可以一定量地减少数据冗余,新的设计为:
(1) 用户信息:用户名,email,主页,电话,联系地址
(2) 帖子信息:用户名,发帖ID,标题,内容
(3) 回复信息:发帖ID,回复ID,标题,内容
数据库表1显然满足所有范式的要求;
数据库表2中存在非关键字段"标题"、"内容"对关键字段"发帖ID"的部分函数依赖,即不满足第二范式的要求,但是这一设计并不会导致数据冗余和操作异常;
数据库表3中也存在非关键字段"标题"、"内容"对关键字段"回复ID"的部分函数依赖,也不满足第二范式的要求,但是与数据库表2相似,这一设计也不会导致数据冗余和操作异常。
由此可以看出,并不一定要强行满足范式的要求,对于1:N关系,当1的一边合并到N的那边后,N的那边就不再满足第二范式了,但是这种设计反而比较好!
对于M:N的关系,不能将M一边或N一边合并到另一边去,这样会导致不符合范式要求,同时导致操作异常和数据冗余。
对于1:1的关系,我们可以将左边的1或者右边的1合并到另一边去,设计导致不符合范式要求,但是并不会导致操作异常和数据冗余。
结论
满足范式要求的数据库设计是结构清晰的,同时可避免数据冗余和操作异常。这并意味着不符合范式要求的设计一定是错误的,在数据库表中存在1:1或1:N关系这种较特殊的情况下,合并导致的不符合范式要求反而是合理的。
在我们设计数据库的时候,一定要时刻考虑范式的要求。
posted @
2008-11-21 11:09 Benson 阅读(365) |
评论 (0) |
编辑 收藏