#include<iconv.h>
#include <stdio.h>
#include<iconv.h>
using namespace std;
int utf8togb2312(const char *sourcebuf,size_t sourcelen,char *destbuf,size_t destlen) {
iconv_t cd;
if( (cd = iconv_open("gb2312","utf-8")) ==0 )
return -1;
memset(destbuf,0,destlen);
const char **source = &sourcebuf;
char **dest = &destbuf;
if(-1 == iconv(cd,source,&sourcelen,dest,&destlen))
return -1;
iconv_close(cd);
return 0;
}
int gb2312toutf8(const char *sourcebuf,size_t sourcelen,char *destbuf,size_t destlen) {
iconv_t cd; if( (cd = iconv_open("utf-8","gb2312")) ==0 )
return -1; memset(destbuf,0,destlen);
const char **source = &sourcebuf;
char **dest = &destbuf;
if(-1 == iconv(cd,source,&sourcelen,dest,&destlen))
return -1;
摘要: 转载自http://blog.csdn.net/u010984552/article/details/51887108为什么需要线程池目前的大多数网络服务器,包括Web服务器、Email服务器以及数据库服务器等都具有一个共同点,就是单位时间内必须处理数目巨大的连接请求,但处理时间却相对较短。 传 统多线程方案中我们采用的服务器模型则是一旦接受到请求之后,即创建一个新的线程,由该线程执行任...
阅读全文
摘自http://blog.csdn.net/hackbuteer1/article/details/7722667
在 各种计算机体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机 通信领 域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双字等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正 确的编/译码从而导致通信失败。目前在各种体系的计算机中通常采用的字节存储机制主要有两种:Big-Endian和Little-Endian,下面先从字节序说起。
一、什么是字节序
字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。其实大部分人在实际的开 发中都很少会直接和字节序打交道。唯有在跨平台以及网络程序中字节序才是一个应该被考虑的问题。
在所有的介绍字节序的文章中都会提到字 节序分为两类:Big-Endian和Little-Endian,引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
c) 网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
1.1 什么是高/低地址端
首先我们要知道C程序映像中内存的空间布局情况:在《C专 家编程》中或者《Unix环境高级编程》中有关于内存空间布局情况的说明,大致如下图:
----------------------- 最高内存地址 0xffffffff
栈底
栈
栈顶
-----------------------
NULL (空洞)
-----------------------
堆
-----------------------
未初始 化的数据
----------------------- 统称数据段
初始化的数据
-----------------------
正 文段(代码段)
----------------------- 最低内存地址 0x00000000
由图可以看出,再内存分布中,栈是向下增长的,而堆是向上增长的。
以上图为例如果我们在栈 上分配一个unsigned char buf[4],那么这个数组变量在栈上是如何布局的呢?看下图:
栈底 (高地址)
----------
buf[3]
buf[2]
buf[1]
buf[0]
----------
栈顶 (低地址)
其实,我们可以自己在编译器里面创建一个数组,然后分别输出数组种每个元素的地址,来验证一下。
1.2 什么是高/低字节
现在我们弄清了高/低地址,接着考虑高/低字节。有些文章中称低位字节为最低有效位,高位字节为最高有效位。如果我们有一个32位无符号整型0x12345678,那么高位是什么,低位又是什么呢? 其实很简单。在十进制中我们都说靠左边的是高位,靠右边的是低位,在其他进制也是如此。就拿 0x12345678来说,从高位到低位的字节依次是0x12、0x34、0x56和0x78。
高/低地址端和高/低字节都弄清了。我们再来回顾 一下Big-Endian和Little-Endian的定义,并用图示说明两种字节序:
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下图:
栈底 (高地址)
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
栈顶 (低地址)
Little-Endian: 低地址存放低位,如下图:
栈底 (高地址)
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
栈 顶 (低地址)
二、各种Endian
2.1 Big-Endian
计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最重要字节(MSB)存放在最低端的地址 上。采用这种机制的处理器有IBM3700系列、PDP-10、Mortolora微处理器系列和绝大多数的RISC处理器。
+----------+
| 0x34 |<-- 0x00000021
+----------+
| 0x12 |<-- 0x00000020
+----------+
图 1:双字节数0x1234以Big-Endian的方式存在起始地址0x00000020中
在Big-Endian中,对于bit序列 中的序号编排方式如下(以双字节数0x8B8A为例):
bit 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+----------------------------------------+
图 2:Big-Endian的bit序列编码方式
2.2 Little-Endian
计算机体系结构中 一种描述多字节存储顺序的术语,在这种机制中最不重要字节(LSB)存放在最低端的地址上。采用这种机制的处理器有PDP-11、VAX、Intel系列微处理器和一些网络通信设备。该术语除了描述多字节存储顺序外还常常用来描述一个字节中各个比特的排放次序。
+----------+
| 0x12 |<-- 0x00000021
+----------+
| 0x34 |<-- 0x00000020
+----------+
图3:双字节数0x1234以Little-Endian的方式存在起始地址0x00000020中
在 Little-Endian中,对于bit序列中的序号编排和Big-Endian刚好相反,其方式如下(以双字节数0x8B8A为例):
bit 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+-----------------------------------------+
图 4:Little-Endian的bit序列编码方式
注意:通常我们说的主机序(Host Order)就是遵循Little-Endian规则。所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序 (Little-Endian)和网络序(Big-Endian)的转换。
采用 Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。 32bit宽的数0x12345678在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 0x4000 0x4001 0x4002 0x4003
存放内容 0x78 0x56 0x34 0x12
而在Big- endian模式CPU内存中的存放方式则为:
内存地址 0x4000 0x4001 0x4002 0x4003
存放内容 0x12 0x34 0x56 0x78
具体的区别如下:

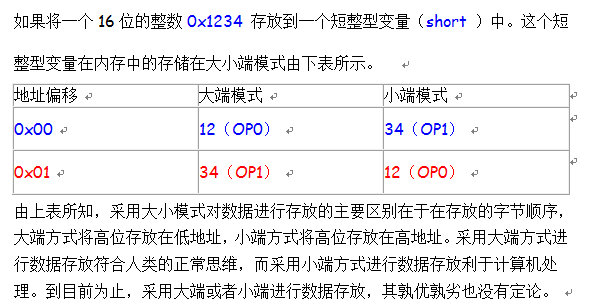
三、Big-Endian和Little-Endian优缺点
Big-Endian优点:靠首先提取高位字节,你总是可以由看看在偏移位置为0的字节来确定这个数字是 正数还是负数。你不必知道这个数值有多长,或者你也不必过一些字节来看这个数值是否含有符号位。这个数值是以它们被打印出来的顺序存放的,所以从二进制到十进制的函数特别有效。因而,对于不同要求的机器,在设计存取方式时就会不同。
Little-Endian优点:提取一个,两个,四个或者更长字节数据的汇编指令以与其他所有格式相同的方式进行:首先在偏移地址为0的地方提取最低位的字节,因为地址偏移和字节数是一对一的关系,多重精度的数学函数就相对地容易写了。
如果你增加数字的值,你可能在左边增加数字(高位非指数函数需要更多的数字)。 因此, 经常需要增加两位数字并移动存储器里所有Big-endian顺序的数字,把所有数向右移,这会增加计算机的工作量。不过,使用Little- Endian的存储器中不重要的字节可以存在它原来的位置,新的数可以存在它的右边的高位地址里。这就意味着计算机中的某些计算可以变得更加简单和快速。
四、请写一个C函数,若处理器是Big_endian的,则返回0;若是Little_endian的,则返回1。
- int checkCPU(void)
- {
- union
- {
- int a;
- char b;
- }c;
- c.a = 1;
- return (c.b == 1);
- }
说明:
1 在c中,联合体(共用体)的数据成员都是从低地址开始存放。
2 若是小端模式,由低地址到高地址c.a存放为0x01 00 00 00,c.b被赋值为0x01;
————————————————————————————
地址 0x00000000 0x00000001 0x00000002 0x00000003
c.a 01 00 00 00
c.b 01 00
————————————————————————————
3 若是大端模式,由低地址到高地址c.a存放为0x00 00 00 01,c.b被赋值为0x0;
————————————————————————————
地址 0x00000000 0x00000001 0x00000002 0x00000003
c.a 00 00 00 01
c.b 00 00
————————————————————————————
4 根据c.b的值的情况就可以判断cpu的模式了。
举例,一个16进制数是 0x11 22 33,其存放的位置是
地址0x3000 中存放11
地址0x3001 中存放22
地址0x3002 中存放33
连起来就写成地址0x3000-0x3002中存放了数据0x112233
而这种存放和表示方式,正好符合大端。
另外一个比较好理解的写法如下:
- bool checkCPU() // 如果是大端模式,返回真
- {
- short int test = 0x1234;
-
- if( *((char *)&test) == 0x12) // 低地址存放高字节数据
- return true;
- else
- return false;
- }
-
- int main(void)
- {
- if( !checkCPU())
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
-
- return 0;
- }
- int main(void)
- {
- short int a = 0x1234;
- char *p = (char *)&a;
-
- if( *p == 0x34)
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
-
- return 0;
- }
-
- int main(void)
- {
- short int a = 0x1234;
- char x0 , x1;
-
- x0 = ((char *)&a)[0];
- x1 = ((char *)&a)[1];
-
- if( x0 == 0x34)
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
-
- return 0;
- }
摘要: C++ 虚函数表解析 陈皓http://blog.csdn.net/haoel 前言 C++中的虚函数的作用主要是实现了多态的机制。关于多态,简而言之就是用父类型别的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数。这种技术可以让父类的指针有“多种形态”,这是一种泛型技术。所谓泛型技术,说白了就是试图使用不变...
阅读全文
首先看看如下一个声明:
int* ( *( *fun )( int* ) )[10];
这是一个会让初学者感到头晕目眩、感到恐惧的函数指针声明。在熟练掌握C/C++的声明语法之前,不学习一定的规则,想理解好这类复杂声明是比较困难的。
C/C++所有复杂的声明结构,都是由各种声明嵌套构成的。如何解读复杂指针声明?右左法则是一个很著名、很有效的方法。不过,右左法则其实并不是C/C++标准里面的内容,它是从C/C++标准的声明规定中归纳出来的方法。C/C++标准的声明规则,是用来解决如何创建声明的,而右左法则是用来解决如何辩识一个声明的,从嵌套的角度看,两者可以说是一个相反的过程。右左法则的英文原文是这样说的:
The right-left rule: Start reading the declaration from the innermost parentheses, go right, and then go left. When you encounter parentheses, the direction should be reversed. Once everything in the parentheses has been parsed, jump out of it. Continue till the whole declaration has been parsed.
这段英文的翻译如下:
右左法则:首先从最里面的圆括号看起,然后往右看,再往左看。每当遇到圆括号时,就应该掉转阅读方向。一旦解析完圆括号里面所有的东西,就跳出圆括号。重复这个过程直到整个声明解析完毕。
笔者要对这个法则进行一个小小的修正,应该是从未定义的标识符开始阅读,而不是从括号读起,之所以是未定义的标识符,是因为一个声明里面可能有多个标识符,但未定义的标识符只会有一个。
现在通过一些例子来讨论右左法则的应用,先从最简单的开始,逐步加深:
int (*func)(int *p);
首先找到那个未定义的标识符,就是func,它的外面有一对圆括号,而且左边是一个*号,这说明func是一个指针,然后跳出这个圆括号,先看右边,也是一个圆括号,这说明(*func)是一个函数,而func是一个指向这类函数的指针,就是一个函数指针,这类函数具有int*类型的形参,返回值类型是int。
int (*func)(int *p, int (*f)(int*));
func被一对括号包含,且左边有一个*号,说明func是一个指针,跳出括号,右边也有个括号,那么func是一个指向函数的指针,这类函数具有int *和int (*)(int*)这样的形参,返回值为int类型。再来看一看func的形参int (*f)(int*),类似前面的解释,f也是一个函数指针,指向的函数具有int*类型的形参,返回值为int。
int (*func[5])(int *p);
func右边是一个[]运算符,说明func是一个具有5个元素的数组,func的左边有一个*,说明func的元素是指针,要注意这里的*不是修饰func的,而是修饰func[5]的,原因是[]运算符优先级比*高,func先跟[]结合,因此*修饰的是func[5]。跳出这个括号,看右边,也是一对圆括号,说明func数组的元素是函数类型的指针,它所指向的函数具有int*类型的形参,返回值类型为int。
int (*(*func)[5])(int *p);
func被一个圆括号包含,左边又有一个*,那么func是一个指针,跳出括号,右边是一个[]运算符号,说明func是一个指向数组的指针,现在往左看,左边有一个*号,说明这个数组的元素是指针,再跳出括号,右边又有一个括号,说明这个数组的元素是指向函数的指针。总结一下,就是:func是一个指向数组的指针,这个数组的元素是函数指针,这些指针指向具有int*形参,返回值为int类型的函数。
int (*(*func)(int *p))[5];
func是一个函数指针,这类函数具有int*类型的形参,返回值是指向数组的指针,所指向的数组的元素是具有5个int元素的数组。
要注意有些复杂指针声明是非法的,例如:
int func(void) [5];
func是一个返回值为具有5个int元素的数组的函数。但C语言的函数返回值不能为数组,这是因为如果允许函数返回值为数组,那么接收这个数组的内容的东西,也必须是一个数组,但C/C++语言的数组名是一个不可修改的左值,它不能直接被另一个数组的内容修改,因此函数返回值不能为数组。
int func[5](void);
func是一个具有5个元素的数组,这个数组的元素都是函数。这也是非法的,因为数组的元素必须是对象,但函数不是对象,不能作为数组的元素。
实际编程当中,需要声明一个复杂指针时,如果把整个声明写成上面所示这些形式,将对可读性带来一定的损害,应该用typedef来对声明逐层分解,增强可读性。
typedef是一种声明,但它声明的不是变量,也没有创建新类型,而是某种类型的别名。typedef有很大的用途,对一个复杂声明进行分解以增强可读性是其作用之一。例如对于声明:
int (*(*func)(int *p))[5];
可以这样分解:
typedef int (*PARA)[5];
typedef PARA (*func)(int *);
这样就容易看得多了。
typedef的另一个作用,是作为基于对象编程的高层抽象手段。在ADT中,它可以用来在C/C++和现实世界的物件间建立关联,将这些物件抽象成C/C++的类型系统。在设计ADT的时候,我们常常声明某个指针的别名,例如:
typedef struct node * list;
从ADT的角度看,这个声明是再自然不过的事情,可以用list来定义一个列表。但从C/C++语法的角度来看,它其实是不符合C/C++声明语法的逻辑的,它暴力地将指针声明符从指针声明器中分离出来,这会造成一些异于人们阅读习惯的现象,考虑下面代码:
const struct node *p1;
typedef struct node *list;
const list p2;
p1类型是const struct node*,那么p2呢?如果你以为就是把list简单“代入”p2,然后得出p2类型也是const struct node*的结果,就大错特错了。p2的类型其实是struct node * const p2,那个const限定的是p2,不是node。造成这一奇异现象的原因是指针声明器被分割,标准中规定:
6.7.5.1 Pointer declarators
Semantics
If in the declaration ‘‘T D1’’, D1 has the form
* type-qualifier-listopt D
and the type specified for ident in the declaration ‘‘T D’’ is
‘‘derived-declarator-type-list T’’
then the type specified for ident is
‘‘derived-declarator-type-list type-qualifier-list pointer to T’’
For each type qualifier in the list, ident is a so-qualified pointer.
指针的声明器由指针声明符*、可选的类型限定词type-qualifier-listopt和标识符D组成,这三者在逻辑上是一个整体,构成一个完整的指针声明器。这也是多个变量同列定义时指针声明符必须紧跟标识符的原因,例如:
int *p, q, *k;
p和k都是指针,但q不是,这是因为*p、*k是一个整体指针声明器,以表示声明的是一个指针。编译器会把指针声明符左边的类型包括其限定词作为指针指向的实体的类型,右边的限定词限定被声明的标识符。但现在typedef struct node *list硬生生把*从整个指针声明器中分离出来,编译器找不到*,会认为const list p2中的const是限定p2的,正因如此,p2的类型是node * const而不是const node*。
虽然typedef struct node* list不符合声明语法的逻辑,但基于typedef在ADT中的重要作用以及信息隐藏的要求,我们应该让用户这样使用list A,而不是list *A,因此在ADT的设计中仍应使用上述typedef语法,但需要注意其带来的不利影响。
摘要: 值得推荐的C/C++框架和库【本文系外部转贴,原文地址:http://coolshell.info/c/c++/2014/12/13/c-open-project.htm】留作存档下次造轮子前先看看现有的轮子吧值得学习的C语言开源项目- 1. Webbench Webbench是一个在linux下使用的非常简单的网站压测工具。它使用fork()模拟多个客户端同时访问我们设定的URL,测试...
阅读全文
摘要: Eric S. Raymond<esr@thyrsus.com>目录1. 谁该阅读这篇文章2. 我为什么写这篇文章3.对齐要求4.填充5.结构体对齐及填充6.结构体重排序7.难以处理的标量的情况8.可读性和缓存局部性9.其他封装的技术10.工具11.证明及例外12.版本履历 1. 谁该阅读这篇文章本文是关于削减C语言程序内存占用空间的一项技术——为了减...
阅读全文
STL使用模板生成,当我们使用模板的时候,每一个EXE,和DLL都在编译器产生了自己的代码,导致模板所使用的静态成员不同步,所以出现数据传递的各种问题,下面是详细解释。
原因分析:
一句话-----如果任何STL类使用了静态变量(无论是直接还是间接使用),那么就不要再写出跨执行单元访问它的代码。 除非你能够确定两个动态库使用的都是同样的STL实现,比如都使用VC同一版本的STL,编译选项也一样。强烈建议,不要在动态库接口中传递STL容器!!
STL不一定不能在DLL间传递,但你必须彻底搞懂它的内部实现,并懂得为何会出问题。
微软的解释:
http://support.microsoft.com/default.aspx?scid=kb%3ben-us%3b172396
微软给的解决办法:
http://support.microsoft.com/default.aspx?scid=kb%3ben-us%3b168958
1、微软的解释:
大部分C++标准库里提供的类直接或间接地使用了静态变量。由于这些类是通过模板扩展而来的,因此每个可执行映像(通常是.dll或.exe文件)就会存在一份只属于自己的、给定类的静态数据成员。当一个需要访问这些静态成员的类方法执行时,它使用的是“这个方法的代码当前所在的那份可执行映像”里的静态成员变量。由于两份可执行映像各自的静态数据成员并未同步,这个行为就可能导致访问违例,或者数据看起来似乎丢失或被破坏了。
可能不太好懂,我举个例子:假如类A<T>有个静态变量m_s,那么当1.exe使用了2.dll中提供的某个A<int>对象时,由于模板扩展机制,1.exe和2.dll中会分别存在自己的一份类静态变量A<int>.m_s。
这样,假如1.exe中从2.dll中取得了一个的类A<int>的实例对象a,那么当在1.exe中直接访问a.m_s时,其实访问的是 1.exe中的对应拷贝(正确情况应该是访问了2.dll中的a.m_s)。这样就可能导致非法访问、应当改变的数据没有改变、不应改变的数据被错误地更改等异常情形。
原文:
Most classes in the Standard C++ Libraries use static data members directly or indirectly. Since these classes are generated through template instantiation, each executable image (usually with DLL or EXE file name extensions) will contain its own copy of the static data member for a given class. When a method of the class that requires the static data member is executed, it uses the static data member in the executable image in which the method code resides. Since the static data members in the executable images are not in sync, this action could result in an access violation or data may appear to be lost or corrupted.
1、保证资源的分配/删除操作对等并处于同一个执行单元;
比如,可以把这些操作(包括构造/析构函数、某些容器自动扩容{这个需要特别注意}时的内存再分配等)隐藏到接口函数里面。换句话说:尽量不要直接从dll中输出stl对象;如果一定要输出,给它加上一层包装,然后输出这个包装接口而不是原始接口。
2、保证所有的执行单元使用同样版本的STL运行库。
比如,全部使用release库或debug库,否则两个执行单元扩展出来的STL类的内存布局就可能会不一样。
只要记住关键就是:如果任何STL类使用了静态变量(无论是直接还是间接使用),那么就不要再写出跨执行单元访问它的代码。
解决方法:
1. 一个可以考虑的方案
比如有两个动态库L1和L2,L2需要修改L1中的一个map,那么我在L1中设置如下接口
int modify_map(int key, int new_value);
如果需要指定“某一个map”,则可以考虑实现一种类似于句柄的方式,比如可以传递一个DWORD
不过这个DWORD放的是一个地址
那么modify_map就可以这样实现:
int modify_map(DWORD map_handle, int key, int new_value)
{
std::map<int, int>& themap = *(std::map<int, int>*)map_handle;
themap[key] = new_value;
}
map_handle的值也首先由L1“告诉”L2:
DWORD get_map_handle();
L2可以这样调用:
DWORD h = get_map_handle();
modify_map(h, 1, 2);
2. 加入一个额外的层,就可以解决问题。所以,你需要将你的Map包装在dll内部,而不是让它出现在接口当中。动态库的接口越简单越好,不好去传太过复杂的东东是至理名言:)
在动态连接库开发中要特别注意内存的分配与释放问题,稍不注意,极可能造成内存泄漏,从而访问出错。例如在某DLL中存在这样一段代码:
extent "C" __declspec(dllexport)
void ExtractFileName( const std::string& path //!< Input path and filename.
, std::string& fname //!< Extracted filename with extension.
)
{
std::string::size_type startPos = path.find_last_of('\\');
fname.assign(path.begin() startPos 1, path.end() );
}
在DLL中使用STL对象std::string,并且在其中改变std::string的内容,即发生了内存的重分配问题,若在EXE中调用该函数会出现内存访问问题。主要是:因为DLL和EXE的内存分配方式不同,DLL中的分配的内存不能在EXE中正确释放掉。
解决这一问题的途径如下:
一般情况下:构建DLL必须遵循谁分配就由谁释放的原则,例如COM的解决方案(利用引用计数),对象的创建(QueryInterface)与释放均在COM组件内部完成。在纯C 环境下,可以很容易的实现类似方案。
在应用STL的情况下,很难使用上述方案来解决,因此必须另辟蹊径,途径有二:
1、自己写内存分配器替代STL中的默认分配器。
2、使用STLport替代系统的标准库。
其实,上述问题在VC7及以后版本中,已得到解决,注意DLL工程和调用的工程一定要使用多线程DLL库,就不会发生内存访问问题。
一个很奇怪的问题:DLL中使用std::string作为参数结果出错
这段时间,在工程中将一些功能封装成动态库,需要使用动态库接口的时候.使用了STL的一些类型作为参数.
比方string,vector,list.但是在使用接口的时候.- class exportClass
- {
- bool dll_funcation(string &str);
- };
当我在使用这个库的时候.这样写代码:- string str="":
- exportClass tmp;
- tmp.dll_function(str);
一点一点取掉这个函数的代码.最后就剩下
str="qadasdasdasdsafsafas";
还是出错误.
如果改成很短的字符串,就不会出错误.
在这个时候,只能尝试认为是字符串的空间太小
最终我修改成这样,错误消失了.希望错误真的是这个引起的- string str="":
- str.resize(1000);
- exportClass tmp;
- tmp.dll_function(str);
|
今天写程序的时候要给一个模块的dll传递一个参数,由于参数数量是可变的,因此设计成了vector<string>类型,但调试过程中发现在exe中的参数传递到dll中的函数后,vector变成空的,改成传引用类型后,vector竟然变得很大,并且是无意义的参数。
对于这个问题,两种办法:
1.传递vector指针
2.传递const vector<TYPE>。
究其原因:
是因为vector在exe和dll之间传递的时候,由于在dll内可能对vector插入数据,而这段内存是在dll里面分配的,exe无法知道如何释放内存,从而导致问题。而改成const类型后,编译器便知道dll里不会改变vector,从而不会出错。
或者可以说这是"cross-DLL problem."(This problem crops up when an object is created using new in one dynamically linked library (DLL) but is deleted in a different DLL)的一种吧。
对于STL,在DLL中使用的时候,往往存在这些问题,在网络上搜集了下,这些都是要平时使用STL的时候注意的。
***************************************************************************************************************
引用http://www.hellocpp.net/Articles/Article/714.aspx
当template 遭遇到dynamic link 时候, 很多时候却是一场恶梦.
现在来说说一部分我已经碰到过的问题. 问题主要集中在内存分配上.
1>
拿STL来说, 自己写模板的时候,很难免就用到stl. stl的代码都在头文件里. 那么表示着内存分配的代码.只有包含了它的cpp 编译的时候才会被决定是使用什么样的内存分配代码. 考虑一下: 当你声明了一个vector<> . 并把这个vector<>交给一个 dll里的代码来用. 用完后, 在你的程序里被释放了. 那么如果你 在dll里往vector里insert了一些东西. 那么这个时候insert 发生的内存分配的代码是属于dll的. 你不知道这个dll的内存分配是什么. 是分配在哪里的. 而这个时候.释放那促的动作却不在dll里.....同时. 你甚至无法保证编译dll的那个家伙使用的stl版本和你是完全一样的..>
如此说来, 程序crash掉是天经地义的....
对策: 千万别别把你的stl 容器,模板容器在 dll 间传来传去 . 记住string也是....
2>
你在dll的某个类里声明了一个vector之类的容器. 而没有显式的写这个类的构造和析构函数. 那么问题又来了.
你这个类肯定有操作这vector的函数. 那么这些函数会让vecoter<>生成代码. 这些代码在这个dll里都是一致的. 但是别忘了.你没有写析构函数...... 如果这个时候, 别人在外面声明了一个这样的类.然后调用这个类的函数操作了这个vector( 当然使用者并不知道什么时候操作了vector) . 它用完了这个类以后. 类被释放掉了. 编译器很负责的为它生成了一份析构函数的代码...... 听好了.这份代码并不是在 dll里 ... . 事情于是又和1>里的一样了.... crash ......(可能还会伴随着迷茫.....)
对策: 记得dll里每个类,哪怕式构造析构函数式空的. 也要写到cpp里去. 什么都不写也式很糟糕的.....同时,更要把任何和内存操作有关的函数写到 .cpp 里...
3>
以上两个问题似乎都是比较容易的-----只要把代码都写到cpp里去, 不要用stl容器传来传去就可以了.
那么第三个问题就要麻烦的多.
如果你自己写了一个模板, 这个模板用了stl 容器..........
这个时候你该怎么办呢?
显然你无法把和内存分配相关的函数都写到.cpp里去 . template的代码都必须放到header file里.....
对策: 解决这个问题的基本做法是做一个stl 内存分配器 , 强制把这个模板里和内存分配相关的放到一个.cpp里去.这个时候编译这个cpp就会把内存分配代码固定在一个地方: 要么是dll. 要么是exe里...
模板+动态链接库的使用问题还很多. 要千万留心这个陷阱遍地的东西啊
***************************************************************************************************************************
微软关于这类问题的解释:
You may experience an access violation when you access an STL object through a pointer or reference in a different DLL or EXE
http://support.microsoft.com/default.aspx?scid=KB;en-us;q172396
How to export an instantiation of a Standard Template Library (STL) class and a class that contains a data member that is an STL object
http://support.microsoft.com/default.aspx?scid=KB;en-us;q168958
总结:
字符串参数用char*,Vector用char**,
动态内存要牢记谁申请谁释放的原则。