从实现装饰者模式中思考C++指针和引用的选择
最近在看设计模式的内容,偶然间手痒就写了一个“装饰者”模式的一个实例。该实例来源于风雪涟漪的博客,我对它做了简化。作为一个经典的设计模式,本身并没有太多要说的内容。但是在我尝试使用C++去实现这个模式的实例的时候,出现了一些看似无关紧要但是却引人深思的问题。
首先,我想简单介绍一下这个实例的含义。实例的目的是希望通过装饰器类对已有的蛋糕类进行装饰补充,于是按照装饰者模式的设计结构,有类似图1的设计结构。
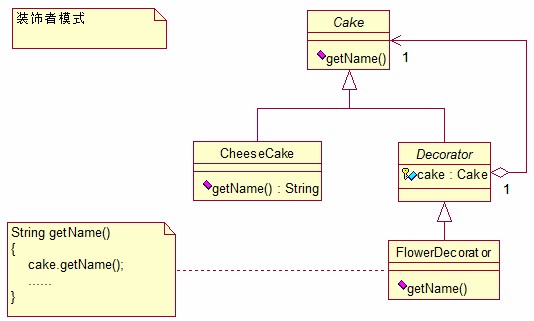
图1 装饰者模式
蛋糕类和装饰器类都继承于一个公共的基类,该基类声明了一些公共接口。这里简单的使用getName来返回当前蛋糕的名称,而装饰器类可以对该蛋糕的名称进行修改补充。具体的蛋糕类都有自己的名称,比如CheeseCake返回的是“奶油蛋糕”。如果使用了装饰器类对该类进行装饰的话,返回的名字就发生了的变化,比如“装饰了花的奶油蛋糕”,这正是装饰器类的功能。实现这个功能的关键在于装饰器公共基类Decorator,它包含了一个Cake类型的成员cake。在定义装饰器的时候我们可以传递给装饰器一个已经建立好的蛋糕对象,比如CheeseCake对象。由于CheeseCake是Cake的子类,因此该对象可以被cake成员记录下来。由于具体的装饰器继承于装饰器基类Decorator,因此保护乘员cake可以被看到,又因为装饰器本身也是继承与Cake的,因此也拥有getName的接口,这样在装饰器类内用getName调用cake的getName接口并添加额外的操作就能完成装饰的目的。另外,装饰器本身也是Cake的子类,因此装饰后的装饰器类对象同时也是一个具体的蛋糕对象,它可以被再次装饰!这样装饰器类反映在我们脑海里的情境就是一个原本的蛋糕对象外边包裹了一层层装饰器对象。
以上的说明如果还不够清楚的话,下边展示具体的实现代码。这里就需要考虑cake成员的类型问题,一般使用指针类型可能更符合C++的编程习惯。因为使用对象不仅消耗空间,还在每次构造对象的时候进行对象的复制,这都不是我们愿意看到的。当然,使用引用或许更合理,因为按照平常的经验,很多使用C++指针的地方都可以用引用代替,有人甚至建议多使用引用少使用指针(当然我也承认C++引用也有很多好处~)。不过,当你读完本文或许你就不大这么认为了。首先,我们用Cake*pCake实现这个装饰器类内的成员,先具体了解一下这个代码的具体内容。
按 Ctrl+C 复制代码
按 Ctrl+C 复制代码
从代码中不难看出程序的输出结构应该是“装饰过花的装饰过花的奶油蛋糕”,事实也的确如此!从装饰器的使用格式来看FlowerDecorator(&FlowerDecorator(&CheeseCake()))倒也不至于十分麻烦。但是刚才讨论过,如果能使用引用代替会许会更“舒服”,至少不用传递参数之前还要使用&获取一下地址了~
既然如此,我们把成员修改为引用格式的:
#pragma once
#include <iostream>
using namespace std;
//Cake公共基类,提供装饰者和被装饰物的统一接口
class Cake
{
public:
virtual string getName()const=0;
};
//一个具体的蛋糕
class CheeseCake:public Cake
{
public:
virtual string getName()const
{
return string("奶油蛋糕");
}
};
//一个装饰者基类
class Decorator:public Cake
{
protected:
Cake &pCake;
public:
Decorator(Cake&pc):pCake(pc){}
};
//一个具体的装饰器
class FlowerDecorator:public Decorator
{
public:
FlowerDecorator(Cake&pc):Decorator(pc){}
virtual string getName()const
{
string decName="装饰过花的";
decName+=pCake.getName();
return decName;
}
};
int main()
{
cout<<
FlowerDecorator(
FlowerDecorator(
CheeseCake()
))
.getName().c_str()
<<endl;
return 0;
}
修改后的代码看起来的确更“顺眼了”。因为调用的时候我们不用再写那个看着别扭的取地址运算符了,然后我们满怀欣喜的执行了程序,输出结果为:“装饰过花的奶油蛋糕”!你我的第一反应八成是觉得忘了多修饰一次了,但是我们认真的检查代码,发现的确一切都是符合逻辑的……
上边做了这么多铺垫就是为了引出这个奇怪的问题,我其实也被该问题困惑了很久。稍有编程经验的人都会跟踪调试这些构造函数的执行过程,结果发现FlowerDecorator只被执行了一次,因此少输出一次“装饰过花的”不足为奇。但是你我肯定好奇为什么会少输出一次呢?
再次再次的检查代码、调试、跟踪,或许你会像发现新大陆一样发现了一个隐藏的问题:第二次构造FlowerDecorator时调用的是复制构造函数,而不是定义好的构造函数(虽然子类FlowerDecorator是Cake的子类,但是编译器会自动最佳匹配函数参数类型)!由于复制构造函数值原模原样的拷贝出一个对象,所以只能完成一次装饰器装饰。非常完美的解释!因此我们可以自己重写复制构造函数来完成我们的装饰功能,这里先忽略原本的对象复制功能了。编译器为我们生成的复制构造函数应该是:
FlowerDecorator(const FlowerDecorator&pc):Decorator(pc.pCake){}
而我们应该将参数看作一个Cake对象进行装饰,因此修改为:
FlowerDecorator(const FlowerDecorator&pc):Decorator(const_cast<FlowerDecorator&>(pc)){}
同样,由于构造函数初始化了基类,所以基类的复制构造也需要重写:
Decorator(const Decorator&pc):pCake(const_cast<Decorator&>(pc)){}
即使传递的参数是FlowerDecorator对象和Cake与Decorator不是一个类型,但是编译器或许默认的匹配继承层次最近的类型!然后我们按照这样要求重写了代码,执行了程序,在期待结果的那一刻看到的是“装饰过花的奶油蛋糕”……或许此时的你都会感到灰心,但是你还是依然的坚强的按下了F5单步跟踪,结果你发现拷贝构造函数并没有被调用!难道以上的假设都错了吗?我可以确定的告诉读者,我们以上的假设都是正确的。
最终我也是没有办法,去StackOverFlow上求助,综合回答者的讨论,我终于把问题的原因锁定了——编译器优化!我觉得用一个最简单的例子来说明这个问题再合适不过了:
class A
{
public:
A(int)
{
cout<<"构造\n";
}
A(const A&)
{
cout<<"拷贝\n";
}
};
int main()
{
A(0);
cout<<"------------------------\n";
A(A(0));
cout<<"------------------------\n";
A(A(A(0)));
cout<<"------------------------\n";
A(A(A(A(0))));
cout<<"------------------------\n";
A(A(A(A(A(0)))));
cout<<"------------------------\n";
return 0;
}
这个简单的例子结果或许大家都很明白,但是你亲自测试一下就可能要怀疑自己的判断能力了,程序输出:
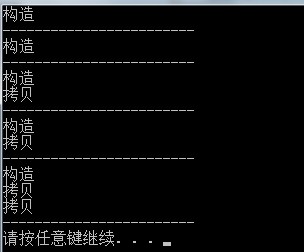
是不是有点世界观被颠覆的感觉?需要声明一下,这个是Visual Studio 2010下的测试结果,因为这个程序的输出的确和编译器相关!为了确认我用gcc-4.4.3测试了该段代码,输出结果为:
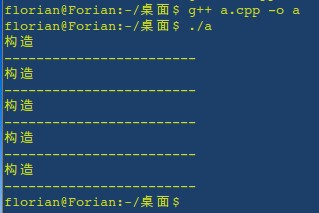
看来,还是gcc优化的比较彻底。因此我们可以得出结论,类似这种无名对象的构造(有名的是按照规矩来的),调用多少次构造函数要看编译器的“脾气”了。到这里,不知道你对引用参数的感觉如何?
讨论到这,或许有人说和本来要讨论的话题离得太远了。其实并不是,佛家说:“今日之果皆来自昨日之因”,一切的一切都是由于我们使用了本以为毫无悬念的引用导致的!如果使用指针就不可能发生和拷贝构造函数冲突的问题,也不会导致编译器优化的问题!回视本文刚开始举的例子和该文的主题,或许我们应该清楚有时候的确要好好区分一下指针和引用的差别了,当然本文也是从一个实践的例子中去发现和挖掘这一点。