http://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650325637&idx=1&sn=e3b66513e2ad39513d3637443e91995a&chksm=f235a58fc5422c99b2000599486858d0cc46af88eea1015b536205c995927a282490e92b3e60&mpshare=1&scene=1&srcid=1104m9Edzx1ubd7UlBlGBPaX#rd
国际人工智能联合会议( International Joint Conference on Artificial Intelligence,IJCAI )是聚集人工智能领域研究者和从业者的盛会,也是人工智能领域中最主要的学术会议之一。1969 年到 2015 年,该大会在每个奇数年举办,现已举办了 24 届。随着近几年来人工智能领域的研究和应用的持续升温,从 2016 年开始,IJCAI 大会将变成每年举办一次的年度盛会;今年是该大会第一次在偶数年举办。第 25 届 IJCAI 大会于 7 月 9 日- 15 日在纽约举办。本届会议的举办地在繁华喧嚣的纽约时代广场附近,正映衬了人工智能领域几年来的火热氛围。此次大会包括7场特邀演讲、4场获奖演讲、551篇同行评议论文的presentation,41场workshop、37堂tutorial、22个demo等。深度学习成为了IJCAI 2016的关键词之一,以深度学习为主题的论文报告session共计有3个。本期我们从中选择了两篇深度学习领域的相关论文进行选读,组织了相关领域的博士研究生,介绍论文的主要思想,并对论文的贡献进行点评。Makeup Like a Superstar Deep Localized Makeup Transfer Network在人脸分割的应用中,美妆是一个受众较广的问题。给出一张素颜正面照,如果能够给出其最适合的化妆风格并将其渲染到这张素颜脸上,可以让女孩子们更方便地找到适合的风格。中科院信工所刘偲博士等人的论文所解决的问题就是完成一个功能更完善的人脸自动美妆应用,不仅能够给素颜的图片上妆,而且可以为用户推荐最适合的妆容,达到更高的用户满意度。文章采用端到端的方法完成风格推荐、五官提取、妆容迁移这三个步骤,同时在损失函数中还考虑平滑性与脸部对称性的约束,最终达到了state-of-the-art效果,本文方法的整体框架如下:核心方法:首先风格推荐,是从已上妆人脸数据库中挑选与当前素颜人脸最相近的图片。具体方法是选取与当前人脸特征的欧氏距离最小者作为推荐结果,该特征即网络输出的feature map。然后是五官提取。五官提取是采用全卷积网络做图像分割实现face parsing,而已上妆数据库还要多一个眼影的部分,对于素颜图片则没有眼影部分的问题,因此要根据眉眼特征点定位给出眼影区域。由于妆容分割的部分相对于背景更重要,网络输出loss选择的是加权交叉熵,权重为使验证集上F1 score最大的权重值。另一方面,数据库中的脸都为正面,具有对称性,因此加上了对称性的先验约束,具体方法为在输出每个像素点的类别概率预测值后,将这个值与它的对称点再取均值作为最终输出:最后是妆容迁移。本文中的妆容包括粉底(对应面部),唇彩(对应双唇),眼影(对应双眼)。眼影的迁移比较特殊,因为它不是直接改变双眼的部分,文章针对此设计了一个loss意指给需要的人脸上妆后眼影部分与推荐的带妆人脸眼影的特征的L2 Norm (该特征为从五官提取部分用到的FCN第一层卷积特征conv1-1)。类似的,对面部、上唇与下唇的loss: 不同的是它计算了conv1-1,conv2-1, conv3-1, conv4-1, conv5-1层特征的相似度。最后给出的使这个loss最小的A(即最终给出的妆后人脸)满足以下条件:其中Rl、Rr表示左眼右眼眼影的loss,Rf表示脸部粉底的loss,Rup、Rlow表示上唇下唇唇彩的loss,Rs表示结构的loss(计算公式与眼影loss相同,但Sb、Sr中元素值都为1)。人脸妆容的平滑性可以通过以下公式进行进一步约束:本文用end-to-end深度卷积神经网络学习出妆前妆后面部特征部位的对应关系,并进行妆容的迁移,流程较为简单,在考虑了人脸结构对称性和平滑性约束后达到了理想的效果,部分实验结果如下:Feature Learning based Deep Supervised Hashing with Pairwise Labels在信息检索中,哈希学习算法将图像/文本/视频等复杂数据表示成一串紧致的二值编码(只由0/1或者±1构成的特征向量),从而实现时间、空间高效的最近邻搜索。在哈希学习算法中,给定一个训练集,目标是学到一组映射函数,使得训练集中的数据经过映射后,相似的样本被映射到相似的二值编码(二值编码的相似性用Hamming距离度量)。南京大学李武军组的这篇文章中,作者提出了一种使用pairwise label进行哈希学习的方法。通常的图像标签指示的可能是图像中的物体属于哪个类别,或者图像所描绘的场景属于哪个类别,而这里的pairwise label则是基于一对图像定义的,指示的是这一对图像是否相似(通常可以根据这一对图像是否属于同一类别定义它们是否相似)。具体来说,对于一个数据库中的第i,j两幅图像,sij=1代表这两个图像相似,sij=0代表这两个图像不相似。具体到这篇文章,作者使用了上图所示的网络结构,网络的输入为成对的图像,以及相应的pairwise label。该网络结构中包含了共享权值的两路子网络(这种结构被称为Siamese Network),每路子网络处理一对图像中的一张。在网络的后端,根据得到的样本的二值编码和pairwise label,作者设计了损失函数来指导网络的训练。具体来说,理想情况下,网络前端的输出应该是只由±1构成的二值向量,在这种情况下,两个样本的二值编码向量的内积事实上是等价于Hamming距离的。基于这个事实,作者提出了如下的损失函数,希望用样本二值编码之间的相似性(内积)去拟合pairwise label(logistic regression):
在实际中,如果想让网络前端输出为只由±1构成的二值向量,则需要在网络中插入量化操作(如sign函数)。但是,因为量化函数在定义域上要么导数为0,要么不可导,因此在训练网络的时候无法使用基于梯度的算法,因此作者提出将网络前端的输出进行松弛,不再要求输出是二值的,转而通过在损失函数中增加一个正则项的方法,对网络输出进行约束:
其中U表示松弛后的“二值编码”,其余定义与J1相同。
在训练的时候,J2中的第一项可以直接根据图像对的标签和Ui计算得到,第二项需要对Ui进行量化得到bi后再计算。利用上述损失函数训练好网络后,当查询样本出现时,只需要将图像通过网络,并对最后一个全连接层的输出进行量化,即可得到样本的二值编码。
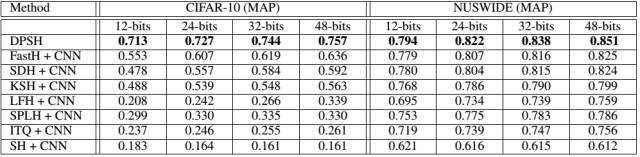
本文中的部分实验结果如下,文章提出的方法取得了state-of-the-art的性能,即使和使用了CNN特征作为输入的一些非深度哈希方法相比,在性能上也有比较显著的优势:
总体来说,本文提出的方法通过联合学习图像特征和哈希函数,在图像检索任务上取得了显著的性能提升。但是由于文中使用的pairwise label在描述一对样本的时候只有相似、不相似两种可能,相对比较粗糙,因此不可避免地限制了本文方法的适用场合。作者在后续的工作中可能会考虑使用更加灵活的监督信息形式来扩展方法的通用性。
该文章属于“深度学习大讲堂”原创,如需要转载,请联系loveholicguoguo。朱鹏飞,天津大学机器学习与数据挖掘实验室副教授,硕士生导师。分别于2009和2011年在哈尔滨工业大学能源科学与工程学院获得学士和硕士学位,2015年于香港理工大学电子计算学系获得博士学位。目前,在机器学习与计算机视觉国际顶级会议和期刊上发表论文20余篇,包括AAAI、IJCAI、ICCV、ECCV以及IEEE Transactions on Information Forensics and Security等。