|
|
|
发新文章 |
|
 | |

Foxit reader想在pdf文件中添加任意文字. Foxit reader -> menu -> Home -> Typewriter 如何在方框中打钩? (1) 方法一: qq拼音输入"对号",就有标准的对号,复制即可 (2) 方法二: Foxit reader -> menu -> Comment -> Pencil How to change the color of the 对号? 用Pencil写完,Select "Pencil" again. Select "对号". 右键, Properties -> Color 怎么添加签名? (1) 方法一: Foxit reader -> menu -> Comment -> Pencil (2) 方法二: Foxit reader -> menu -> PDF Sign -> Draw Signature,然后写的就应该保存了 How can we insert a picture? Foxit reader -> menu -> Home -> Image Annotation http://www.downxia.com/zixun/36037.html 你上次组会,讲ppt,用的什么pdf工具,右键会有pen出来?我看老师上课也这么用的我用的是我的笔记本,其他的目前还不太清楚,我猜老师应该也是用的surface. Zhengxia: 我没有用pdf工具,就是用的ppt放映的, 放映时候,右键会有一些选项,有pen,有激光器等等。See my webchat favourites on Sep 11, 2018. 我问Umich将machine learning的教授Scott: Do you use pdf or ppt when using the pen to write on this machine? He says ppt. ppt,右键, 指针选项 -> pen (笔);墨迹颜色(ink color); 橡皮擦(eraser) 如何设置Adobe professional每次打开pdf文件都是适合宽度?菜单:编辑->首选项,页面显示和辅助工具,均设置成总是使用页面布局方式:单页连续;总是使用缩放设置:适合宽度。(This is under the help of Fei Gao) 工具栏不见了,如何显示工具栏?菜单:视图->工具栏->显示工具栏 (View -> Toolbars -> Show toolbars) pdf文件如何旋转?用Adobe Acrobat即可:文档——页面——旋转——保存即可 pdf文件写东西:工具->打字机工具->打字机工具(写得很规范);工具->注释和标记->铅笔工具(就可以自己写字,包括打勾之类的)。How to change the color of the font? Google search "adobe professional pencil tools color" and find the link: https://forums.adobe.com/thread/494858. It says that "To change the color of the signature, right-click the Pencil tool in the Comment & Markup Toolbar. Then choose Tool Default Properties, and change the color in the Appearance tab." However, when I right-click or left-click the Pencil tool, there is nothing. Zhengxia gave the suggestion. Select the font. right-click -> Properties ->Color 第二点在ISCIDE 2013会议论文copyrightlncs.pdf中可以写的,就不知这样写出来,是否符合要求:打印出来签字再扫描 福昕阅读器: https://jingyan.baidu.com/article/e4511cf35ae8fb2b845eaff6.html Yuan Cao说有pdf转word的软件,word插入图片,再打印成pdf,她就是这么弄的。
在校稿时如何在指定位置插入文本:
http://wenku.baidu.com/view/beb7b00690c69ec3d5bb7508.html,该文件也已经保存到电脑,“关于PDF修改批注的用法.pdf”
【您正在pdf/A模式中查看本文档】 去除方法
问题:
有的pdf格式书或者文献,打开后,工具栏下有一行文字是“您正在pdf/A模式中查看本文档”,想添加书签却不能,请教诸位书友怎样才能改变此种模式,能如一般情况编辑书签。
回答:
请选择“编辑”>“首选项”(Windows)或“Acrobat”>“首选项”(Mac OS)。
在“种类”下选择“文档”。
在“使用 PDF/A 模式下查看文档”中选择选项: “从不”,“总是”或“仅用于 PDF/A 文档”。
通过再次改变本首选项设置,您可以切换 PDF/A 查看模式。
http://blog.163.com/ldhy01234@126/blog/static/1716529482010111391417570/
http://www.cappchem.com/Article2014/1122.html
Adobe Acrobat X如何变更语言?
核心提示:Adobe Acrobat X本来装的是中文版,后来不知道什么原因突然变成英文版了(如下图所示),或许是升级后导致的?那么如何调整回中文版呢?1.进入Edit菜单,点击Preferences下的Gen...
Adobe Acrobat X本来装的是中文版,
后来不知道什么原因突然变成英文版了(如下图所示),
或许是升级后导致的?

那么如何调整回中文版呢?
1.进入Edit菜单,点击Preferences下的General。

2.在弹出的Preferences对话框中,左侧选择International。
在右侧的Application Language中选择Same as the operating system。
该选项的意思是“与操作系统的语言相同”。
我们一般是用的简体中文版系统,因此Acrobat会自动切换成中文。

3.完成后,关闭Acrobat,再重新运行Acrobat后的界面图如下。
是不是已经回到中文版了呢?

http://blog.sina.com.cn/s/blog_631a4cc401019gqx.html 今年的low rank显然比去年要火一些。 1.Robust Visual Domain Adaptation with Low-Rank Reconstruction (PDF) I-Hong Jhuo, Dong Liu, Shih-Fu Chang, Der-Tsai Lee 这篇文章是做多视角的物体识别的。一般认为不同视角的物体分布在相同的低维流型上,但是 本文认为如果噪声过大本质上并不在一个流行上面。所以将低秩的约束加在变换系数上了。 也可以说这篇文章是在domain adaption上面加了low rank的约束。 2.Sparse Representation for Face Recognition based on Discriminative Low-Rank Dictionary Learning Long Ma, Chunheng Wang, Baihua Xiao, Wen Zhou 这篇文章可以说在判别词典上面加上low rank的约束,也可以说在low rank上面加上了判别词典 的信息。对目标函数的解法套用了别人的方法。实验做得很充分。 以下是今年CVPR中关于low rank的一些文章,感兴趣的可以看一看: A Unified Approach to Salient Object Detection via Low Rank Matrix Recovery (PDF) Xiaohui Shen, Ying Wu Practical Low-Rank Matrix Approximation under Robust \(L_{1}\)-Norm Yinqiang Zheng, Guangcan LIU, Shigeki Sugimoto, Shuicheng YAN, Masatoshi Okutomi Automatic Mitral Leaflet Tracking in Echocardiography by Outlier Detection in the Low-rank Representation Xiaowei Zhou, Weichuan Yu Robust Late Fusion with Multi-Task Low Rank Minimization (PDF) Guangnan Ye, Dong Liu, I-Hong Jhuo, Shih-Fu Chang Non-Negative Low Rank and Sparse Graph for Semi-Supervised Learning Liansheng Zhuang, Haoyuan Gao, Zhouchen Lin, Yi Ma, Nenghai Yu Low-Rank Matrix Recovery with Structural Incoherence for Robust Face Recognition Chih-Fan Chen, Chia-Po Wei, Yu-Chiang Frank Wang
http://en.wikipedia.org/wiki/Taylor_series
Taylor series in several variables The Taylor series may also be generalized to functions of more than one variable with 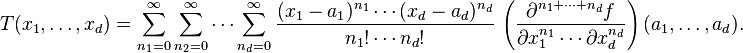
For example, for a function that depends on two variables, x and y, the Taylor series to second order about the point (a, b) is: ![\begin{align} f(x,y) & \approx f(a,b) +(x-a)\, f_x(a,b) +(y-b)\, f_y(a,b) \\ & {}\quad + \frac{1}{2!}\left[ (x-a)^2\,f_{xx}(a,b) + 2(x-a)(y-b)\,f_{xy}(a,b) +(y-b)^2\, f_{yy}(a,b) \right], \end{align}](http://upload.wikimedia.org/math/5/5/8/5587e7367ecb9029926201c9747966b2.png)
where the subscripts denote the respective partial derivatives. A second-order Taylor series expansion of a scalar-valued function of more than one variable can be written compactly as 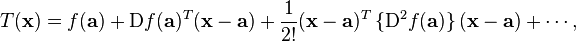
where 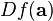 is the gradient of is the gradient of 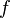 evaluated at evaluated at 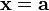 and and  is the Hessian matrix. Applying the multi-index notation the Taylor series for several variables becomes is the Hessian matrix. Applying the multi-index notation the Taylor series for several variables becomes 
which is to be understood as a still more abbreviated multi-index version of the first equation of this paragraph, again in full analogy to the single variable case. [edit]Example Second-order Taylor series approximation (in gray) of a function  around origin. Compute a second-order Taylor series expansion around point  of a function of a function 
Firstly, we compute all partial derivatives we need 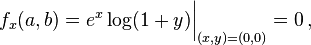

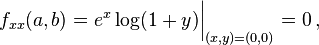


The Taylor series is ![\begin{align} T(x,y) = f(a,b) & +(x-a)\, f_x(a,b) +(y-b)\, f_y(a,b) \\ &+\frac{1}{2!}\left[ (x-a)^2\,f_{xx}(a,b) + 2(x-a)(y-b)\,f_{xy}(a,b) +(y-b)^2\, f_{yy}(a,b) \right]+ \cdots\,,\end{align}](http://upload.wikimedia.org/math/d/a/d/dad3055d4695f7e70e10c5e403a92112.png)
which in this case becomes ![\begin{align}T(x,y) &= 0 + 0(x-0) + 1(y-0) + \frac{1}{2}\Big[ 0(x-0)^2 + 2(x-0)(y-0) + (-1)(y-0)^2 \Big] + \cdots \\ &= y + xy - \frac{y^2}{2} + \cdots. \end{align}](http://upload.wikimedia.org/math/f/e/2/fe2770b7f29c8d32af5ca24d26b9cd99.png)
Since log(1 + y) is analytic in |y| < 1, we have 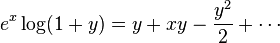
for |y| < 1.
If λ1 and λ2 are two arbitrary nonnegative real numbers such that λ1 + λ2 = 1 then convexity of  implies implies  [这就是凸函数的定义] [这就是凸函数的定义]
This can be easily generalized: if λ1, λ2, ..., λn are nonnegative real numbers such that λ1 + ... + λn = 1, then 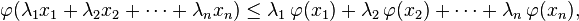
例如-log(x)是凸函数
两个电脑的同步更新。问题:长期使用台式机,笔记本不用也没联网。笔记本联网之前最好将所有文件都删除,不删应该也没关系,肯定是保留的最近的操作,比如台式机已经删除了,笔记本也会将它他删除(其实可以做个实验)。
微软快盘skydrive可以在任何地方使用,没有限制。本机和网络同步。问题:本机和网络同步得快吗,有没有时差(比如我在本机更新一个文件的名字,多久在云端能够更新)?打开这个软件有什么显示? 灵活:可以上载任何大小不超过300 MB 的照片和文件 更新时发现,文件名中含有中文冒号的都无法更新,在windows中本来文件名含有英文冒号就是不合法的 金山快盘
(3)WORD或者LATEX插入PDF格式图片?将ppt转化成pdf的两种方式(一、打印成pdf;二、另存为pdf(我的论文PACFS的流程图,graphs中间的线像是一段一段的,采用方式二就没有问题(This is under the help of Yong Luo) )),工具->高级编辑->裁剪工具 (东大正版pdf, 编辑->编辑文本和图像->裁剪页面),选中,注意此时调整大小,只能拉角落的角,确定,就会打印出新的pdf文件出来。工具->选择和缩放->快照工具(东大正版pdf, 编辑->拍快照),选中复制到word就可以了。Latex中直接插入pdf格式图片就可以了,当然也可以将pdf存成eps格式,再插入eps格式的图片,方法:打开pdf文件,另存为eps即可。一般情况这样就可以了。如果存成eps,有部分被截怎么解决?解决方法:将pdf另存为png,不要另存为jpg,png是无损的,再用Zhibing Hong给我的以下三句matlab命令将png转成eps格式即可。a = imread('SystemDiagram.png');imshow(a); saveas(gcf,'SystemDiagram.eps', 'psc2')。这种存的是矢量图(Yong Luo)。
2012/11/11 Latex插入图片(我自己画的pdf图片(投CVPR 2013的),如果转成eps图片,就会产生问题:发现有一些被截断了(以前也遇到过,或者被翻转之类,而且用转换成png再转化为eps,仍然不能解决)。于是想到还是插入pdf图片),头文件只要\usepackage{graphicx}即可
注意1:要插入pdf图片,所有图片都要求是pdf图片,不能是eps图片。编译方式1:WinEdt 6.0和7.0都有PDFTeXify直接能生成pdf文件(Yong Luo都用的这一种方式)。编译方式2:PDFLaTeX->BibTex-> PDFLaTeX-> PDFLaTeX; 注意此时不能再点div2pdf,直接到文件夹看生成的pdf文件即可(nannan wang的版本就不能点击div2pdf)。问题:WinEdt 6.0和7.0都有PDFTeXify直接能生成pdf文件,这和PDFLaTeX->BibTex-> PDFLaTeX-> PDFLaTeX这样编译有什么区别?答:Yong Luo都用的第一种方式。编译方式3:Mingming Cheng老师的latex基金模板,要安装texlive,安装完成后WinEdit 7就会出现XeLaTeX,运行XeLaTeX即可,不能运行PDFLaTeX,他说XeLaTeX相对PDFLaTeX的优点就是支持中文比较好。texlive不能删,否则XeLaTeX就没了。因为我首次运行发现引用参考文献的地方,显示的是问号,问他是不是首次运行时要先运行XeLaTeX,再运行BibTeX,再运行XeLaTeX?是不是只要参考文献改过了,都要这样运行一次?他说应该是,参考文献改过了,应该不要再编译参考文献了。怎么将“Figure”换成“图”?他的是自动就是“图”。我自己上网找到解决方案:https://zhidao.baidu.com/question/247603925.html,加\renewcommand\figurename{图} 即可.
20250312 Xiaofeng Cong: TexWorks中编译顺序是XeLaTex->BibTex->XeLaTex->XeLaTex
注意2:此时只能点击PDFLaTeX 编译,不能点击LaTeX编译,否则会有问题:cannot determine size of graphic (怎样在latex中插入jpg图片? 必须用pdf LaTeX 编译)
有eps图片,编译方式LaTeX->BibTex-> LaTeX-> LaTeX->div2pdf,有时如果eps不显示,可能是点dvi2pdf没用;先点dvi2ps再dvi2pdf。编译方式:LaTex:编译论文文件;BibTex编译参考文献;再两次LaTex(是规定的)(Tianyi告诉Fangjun Wu:ctrl+shift+X等同于LaTex+BibTex+LaTex+LaTex,分四步,能看出是参考文献错误还是文中有错误)。
nannan wang讲pdf图片唯一的问题,质量不太高,他和Yong Luo现在都是插入pdf图片。Matlab生成的图片可以直接保存为pdf格式,例如我准备投CVPR 13的Yale结果图,发现问题:见我的文件Yale.pdf,NN的结果在matlab看效果是方块的,但到pdf是竖线。matlab画出图后,不保存为pdf,按打印,属性,在Adobe PDF设置,默认设置,编辑,选择图像,将彩色图像,“缩减像素采样”选择“关”,再确定,打印成pdf,这样就没有问题了。这是首次的方式,以后每次打印时将默认设置改为standard(1)即可 (This is with Fei Gao's help.) 双栏模式插入单栏图片:\begin{figure*},这种是因为图像比较大,必须单栏才能显示出来,如果图像很小就用 \begin{figure}即可; 如何让图片或者表格置顶?\begin{figure}[t], nannan wang says [t]就是实现置顶的功能
Please note the differences between \usepackage{subfig} and \usepackage{subfigure}. These two can not be used together in my talk: "talk\2017\I\1\Jie Gui_3\Multi-view".
(4)LATEX中如何插入网址?(我的教材P379)
使用以下方式即可:\usepackage{url}
\url{http://www.ri.cmu.edu/projects/project_418.html}
【这种方式在我的SRDA正则化参数估计杂志论文中已经能够正确编译】
Latex参考文献中含有网址,对应的*.bib文件要如何编辑?
https://blog.csdn.net/techfield/article/details/19933589用到这个包: \usepackage{url} 然后在你的.bib文件里写上 @Misc{timmurphy.org, howpublished = {[EB/OL]}, note = {\url{http://timmurphy.org/2009/07/22/line-spacing-in-latex-documents/} Accessed April 4, 2010}, title = {Line Spacing in LaTeX documents}, author = {Murphy, Timothy I} } 我在引用https://cacm.acm.org/news/244720-yann-lecun-yoshuabengio- self-supervised-learning-is-key-to-human-levelintelligence/ fulltext时将\url删除了,如果加上没法自动换行
我觉得有如下两种方式:方式一:@article{zhu2005semi,
title={Semi-supervised learning literature survey, \url{http://www.cs.wisc.edu/~jerryzhu/pub/ssl_survey.pdf}},
author={Zhu, X.},
year={2005},
publisher={Citeseer}
}也可以用url={http://www.cs.wisc.edu/~jerryzhu/pub/ssl_survey.pdf} ,但这样有可能:编译没问题,但在最后参考文献中,这一项显示不出来问题:要不要使用宏包\usepackage{hyperref} 方式二:
\bibitem{url} National Center for Biotechnology Information, \url{http://www.ncbi.nlm.nih.gov}问题:要显示网址中的~,使用\~{}吗?审稿人说我的网址显示不对,我在latex用的是https://www.cs.toronto.edu/\~{}kriz/cifar.html
Tongliang回答:usepackage{hyperref},在文中使用\url{https://www.cs.toronto.edu/~kriz/cifar.html}
继续产生问题:伪代码中凡是有引用的,都加了红色的框。网址,图表的序号都加了框,这怎么解决呢?
Tongliang回答:在usepackage{hyperref}后面加上\hypersetup{ bookmarks=true, % show bookmarks bar? unicode=false, % non-Latin characters in Acrobat’s bookmarks pdftoolbar=true, % show Acrobat’s toolbar? pdfmenubar=true, % show Acrobat’s menu? pdffitwindow=false, % window fit to page when opened pdfstartview={FitH}, % fits the width of the page to the window pdftitle={My title}, % title pdfauthor={Author}, % author pdfsubject={Subject}, % subject of the document pdfcreator={Creator}, % creator of the document pdfproducer={Producer}, % producer of the document pdfkeywords={keyword1, key2, key3}, % list of keywords pdfnewwindow=true, % links in new PDF window colorlinks=true, % false: boxed links; true: colored links linkcolor=black, % color of internal links (change box color with linkbordercolor) citecolor=black, % color of links to bibliography filecolor=black, % color of file links urlcolor=black % color of external links } 即可,以上语句来自https://en.wikibooks.org/wiki/LaTeX/Hyperlinks,就最后五行修改了。我的论文SDHR就是这么处理的 我的latex中文简历V1版本,20170301咨询Yong Luo第二页脚注显示有问题。 他找到方案:把这个去掉就好了\usepackage{hyperref},这个包可能跟模板有冲突,会导致分页不正常。 产生新的问题:但删掉之后,有网址出现的地方就编译通不过了,怎么使得网址出现的地方和我原来效果一样呢? 他也没有办法解决,我想到的是用\url{}代替\href{},\usepackage{url},将V2版本发给他,感觉还行
(5)LATEX中,在输入有中文的情况下如何两端对齐?
以下例子可能是偶然情况,需要时再看教材4.2.7节。代码一:,cbscmvOptimizeAlpha有参数lambda\_a可能就对应这两个正则化参数;代码二:,cbscmvOptimizeAlpha有参数lambda\_a可能就对应这两个正则化参数 .区别仅仅在于最前面中文还是英文逗号,中文就能自动两端对齐,像IEEE模板一样,长单词在截断处加-,不会硬放在一行。
(6) Naive: Also note the existence of \i and \j, which produce dotless versions of “i” and “j” (viz., “i” and “j”). These are useful when the accent is supposed to replace the dot. For example, “na\"{\i}ve” produces a correct “naïve”, while “na\"{i}ve” would yield the rather odd-looking “naïve”. (“na\"{i}ve” does work in encodings other than OT1, however.) (http://hevea.inria.fr/examples/sym.html )
参考文献多个作者只显示一个?
试试: Joe Gui and others 这种方式 如何设置成IEEE或者ACM的参考文献样式? https://www.sharelatex.com/learn/Bibtex_bibliography_styles
(末尾) LATEX插入参考文献完整攻略
Latex中插入参考文献遇到的问题: 在模板中,将最近的bib文件拷贝至当前目录,加上以下两句即可\bibliographystyle{ieeetr} %plain\bibliography{a}如果模板有bibitem方式的参考文献,必须注释。如果文中没有加任何参考文献引用,直接编译是会出错的, 2012-09-18晚为这个问题很长时间都没搞定。回去想可能是在文中加一篇引用就能解决,确实是这个原因。以上就是Latex插入参考文献完整的步骤 。
Latex中参考文献如何设定专有名词大写
将所有参考文献写在bib file 中,然后在latex调用来生成参考文献,一般生成的参考文献的格式是:除了文章名字的第一个字母为大写外,其他均为小写。但是有些专有名词是需要全部大写或者部分大写的,要实现这样的功能就需要在bib file 中把需要显示为大写的字母用{}括起来。
例如:要实现 OFDMA network, 那么在bib file中,要写成 {OFDMA} network;
要实现 Nash bargaining solution, 那么在bib file 中要写成 {N}ash bargaining solution.
Latex插入会议参考文献时 BOOKTITLE统一采用以下方式:看了很多,感觉Ran He CVPR2012的方式最好
booktitle={Conference on Computer Vision and Pattern Recognition};注意不能是{International Conference on Computer Vision and Pattern Recognition}
booktitle={International Conference on Computer Vision},
booktitle={European Conference on Computer Vision}, booktitle={Neural Information Processing Systems},
booktitle={International Conference on Machine Learning},
booktitle={International Joint Conference on Artificial Intelligence},
booktitle={AAAI Conference on Artificial Intelligence},这就是AAAI会议
booktitle={ACM SIGKDD Conference on Knowledge Discovery and Data Mining},这就是KDD会议 注意这两个数据挖掘会议简称
booktitle={IEEE International Conference on Data Mining} ,booktitle={SIAM International Conference on Data Mining}, mingming gong说UAI references用数字标没有问题, http://auai.org/uai2017/proceedings/papers/289.pdf,
http://auai.org/uai2017/proceedings/papers/11.pdf, 这两个最终接受的论文都是用数字标的, 他特地研究过。
不一定用那个,真的无所谓.Asymmetric LSH是NIPS最佳论文奖,参考文献19就写的In KDD, 5写的In SDM, 20写的In NIPS。关键格式一致就可以。 书的引用方式:Top 10 algorithms in data mining的第83个文献,该文应该是非常标准的方式。 Vapnik V (1995) The nature of statistical learning theory. Springer, New York 对应的Latex方式: @book{vapnik2000nature,
title={The nature of statistical learning theory},
author={Vapnik, Vladimir},
year={2000},
publisher={Springer, New York }
}
对于没有正式卷号期号的怎么写bib文件?
仿照tongliang主页写法:@article{gui2016Re,
title={Representative Vector Machines: A unified framework for classical classifiers},
author={Gui, Jie and Liu, Tongliang and Tao, Dacheng and Sun, Zhenan and Tan, Tieniu},
journal={IEEE Transactions on Cybernetics},
doi={10.1109/TCYB.2015.2457234}
} ----------------------------------------以下内容不必再看------------------------------------
注意不要加简称CVPR 11之类,看Deng Cai Graph Regularized Nonnegative Matrix(TPAMI)第四十六个文献,patch alignment的第十八个文献都没有加会议简称,
Yangqingjia CVPR 2012和Jianchao Yang CVPR 2009格式都是In CVPR
@INPROCEEDINGS{CHZH07,
Author = {Deng Cai and Xiaofei He and Wei Vivian Zhang and Jiawei Han},
TITLE = {Regularized Locality Preserving Indexing via Spectral Regression},
BOOKTITLE = {Proceedings of the 16th ACM Conference on information and knowledge management},
YEAR = {2007},
pages = {741--750},}
@INPROCEEDINGS{HCN05b,
AUTHOR = {Xiaofei He and Deng Cai and Partha Niyogi},
TITLE = {Tensor Subspace Analysis},
BOOKTITLE = {Advances in Neural Information Processing Systems 18},
YEAR = {2005}, }
booktitle={Proceedings of 2011 IEEE Conference on Computer Vision and Pattern Recognition}
booktitle={Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition}
The differences are 24th and 2011. I asked Professor Ran He on msn on 20120327 and he said that both are OK.
nannan wang(20120827): 标准就是统一就行。会议最后不要用Proceedings,年份一般也不写,单独写,有简称CVPR、NIPS都有,没有都没有。
booktitle={IEEE Conference on Computer Vision and Pattern Recognition}
如何排序并压缩连续的引用,产生如[2,4-8] 形式的引用? [zhaofeng he]
如果你在Latex 中使用\cite{a,b,c,d,e,f} 则Latex 不会对条目进行排序,因此,可能会产生象[6,2,5,8,4,7] 这样很难看的排版效果。大多数人都希望对引用的条目进行排序,并且对连续的条目使用压缩的表示方式,即用[2,4-8] 表示上面的例子。使用cite 宏包可以解决这个问题。另一种方法是使用宏包natbib 并指定选项numbers 和sort&compress ,可以得到一样的效果。如果使用BibTEX 则必须使用natbib所带的数字式参考文献风格(plainnat.bst 和unsrtnat.bst)。
在使用 hyperref 宏包来生成超链接的时候会有点问题。cite 宏包会完全失效,产生没有排序和压缩的引用。而 natbib 则可以得到排序但没有压缩的引用效果。如果你想得到排序而且压缩的效果,可以在加入natbib 宏包后再使用宏包 hypernat。
参考文献:Ctex FAQ-P.26
- 方法1:具体例子如下:\usepackage[sort&compress,square,numbers]{natbib}, 则可以得到排序但没有压缩的引用效果,但再使用\usepackage{hypernat},编译出现错误:
'hypernat.sty' not found的错误。请chong wang帮忙,也没能解决。 方法2:\usepackage[compress]{cite} [见我的Latex教材P367]。 以后就用这个方法
在gmailstore里的“Latex学习记录”,20160826已经整理,绝不再看,但gmailstore里删不掉,本机的该文件已删
以SVM为例,参数C和sigma的选择叫Model selection。求w和b叫Model/Parameter estimation
http://en.wikipedia.org/wiki/Gradient_descent http://zh.wikipedia.org/wiki/%E6%9C%80%E9%80%9F%E4%B8%8B%E9%99%8D%E6%B3%95
Gradient descent is based on the observation that if the multivariable function  is defined and differentiable in a neighborhood of a point is defined and differentiable in a neighborhood of a point  , then decreases fastest if one goes from in the direction of the negative gradient of , then decreases fastest if one goes from in the direction of the negative gradient of  at , at ,  为啥步长要变化?Tianyi的解释很好:如果步长过大,可能使得函数值上升,故要减小步长 (下面这个图片是在纸上画好,然后scan的)。 Andrew NG的coursera课程Machine learning的 II. Linear Regression with One Variable的 Gradient descent Intuition中的解释很好,比如在下图在右侧的点,则梯度是正数, 是负数,即使当前的a减小
例1:Toward the Optimization of Normalized Graph Laplacian(TNN 2011)的Fig. 1. Normalized graph Laplacian learning algorithm是很好的梯度下降法的例子.只要看Fig1,其他不必看。Fig1陶Shuning老师课件 非线性优化第六页第四个ppt,对应教材P124,关键直线搜索策略,应用 非线性优化第四页第四个ppt,步长加倍或减倍。只要目标减少就到下一个搜索点,并且步长加倍;否则停留在原点,将步长减倍。 例2: Distance Metric Learning for Large Margin Nearest Neighbor Classification(JLMR),目标函数就是公式14,是矩阵M的二次型,展开后就会发现,关于M是线性的,故是凸的。对M求导的结果,附录公式18和19之间的公式中没有M 我自己额外的思考:如果是凸函数,对自变量求偏导为0,然后将自变量求出来不就行了嘛,为啥还要梯度下降?上述例二是不行的,因为对M求导后与M无关了。和tianyi讨论,正因为求导为0 没有解析解采用梯度下降,有解析解就结束了
http://blog.csdn.net/yudingjun0611/article/details/8147046
1. 梯度下降法
梯度下降法的原理可以参考:斯坦福机器学习第一讲。
我实验所用的数据是100个二维点。
如果梯度下降算法不能正常运行,考虑使用更小的步长(也就是学习率),这里需要注意两点:
1)对于足够小的, 能保证在每一步都减小;
2)但是如果太小,梯度下降算法收敛的会很慢;
总结:
1)如果太小,就会收敛很慢;
2)如果太大,就不能保证每一次迭代都减小,也就不能保证收敛;
如何选择-经验的方法:
..., 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1...
约3倍于前一个数。
matlab源码:
- function [theta0,theta1]=Gradient_descent(X,Y);
- theta0=0;
- theta1=0;
- t0=0;
- t1=0;
- while(1)
- for i=1:1:100 %100个点
- t0=t0+(theta0+theta1*X(i,1)-Y(i,1))*1;
- t1=t1+(theta0+theta1*X(i,1)-Y(i,1))*X(i,1);
- end
- old_theta0=theta0;
- old_theta1=theta1;
- theta0=theta0-0.000001*t0 %0.000001表示学习率
- theta1=theta1-0.000001*t1
- t0=0;
- t1=0;
- if(sqrt((old_theta0-theta0)^2+(old_theta1-theta1)^2)<0.000001) % 这里是判断收敛的条件,当然可以有其他方法来做
- break;
- end
- end
2. 随机梯度下降法
随机梯度下降法适用于样本点数量非常庞大的情况,算法使得总体向着梯度下降快的方向下降。
matlab源码:
- function [theta0,theta1]=Gradient_descent_rand(X,Y);
- theta0=0;
- theta1=0;
- t0=theta0;
- t1=theta1;
- for i=1:1:100
- t0=theta0-0.01*(theta0+theta1*X(i,1)-Y(i,1))*1
- t1=theta1-0.01*(theta0+theta1*X(i,1)-Y(i,1))*X(i,1)
- theta0=t0
- theta1=t1
- end
An Efficient Projection for l1,∞ Regularization该文提供代码,在Readme文件中说To run the projection in Matlab, you first need to compile the mexfile:
$ mex -output projL1Inf mex-projL1Inf.c
Then, from Matlab, test the projection by running the script "runprojection", (1)在我笔记本电脑,打开matlab,打开该程序所在的文件夹,在matlab命令行输入mex -setup, matlab输出:Would you like mex to locate installed compilers [y]/n? 手动输入:y , matlab输出: Select a compiler: 手动输入:1, matlab输出: Are these correct [y]/n? 手动输入:y 。 手动输入: mex -output projL1Inf mex-projL1Inf.c ,可能是因为我的笔记本电脑没装VC,有错误。在我本机要能运行,关键就是生成 projL1Inf.mexw32这个文件就可以了,在Mingming Gong电脑上生成,拷贝到我的电脑就可以了。 Mingming电脑装VC了,但还是不能编译,他讲可能原因是这个c语言代码本来就是在linux下写的,在windows上跑不了,naiyang也这么说。 20121023, after Mingming Gong saw my blog, he found the solution to produce the file projL1Inf.mexw32. 只要将mex-projL1Inf.c后缀改为mex-projL1Inf.cpp,projL1Inf.c后缀改为projL1Inf.cpp,mex-projL1Inf.cpp第39行改为#include "projL1Inf.cpp",只要修改这三点就可以在windows下编译,我已经从他那里拷贝了 projL1Inf.mexw32 。从我本机还是不能编译,因为本机没装VC。 原因:*.cpp是支持C和C++的;*.c只支持C,故//不支持。在Linux下C和C++是两个编译器(在linux下c是用gcc编译,C++使用g++编译),在windows下,C和C++是可以同时用VC编译的。 20130629在NLPR的54服务器用mex -output projL1Inf mex-projL1Inf.cpp成功编译生成文件projL1Inf.mexw64,不知为什么用mex -setup一步一步来不行。 (2)在uts cluster,按照上面输入的命令,有错误和警告 (Mingming said that the warning does not matter)
Warning: You are using gcc version "4.4.6". The version
currently supported with MEX is "4.3.4". 错误:projL1Inf.c:248: error: expected expression before '/' token
projL1Inf.c:250: error: expected expression before '/' token
projL1Inf.c:252: error: expected expression before '/' token 打开projL1Inf.c ,将这三行的注释//,均换成/* * / 这样的作用,就是生成 projL1Inf.mexa64这个文件.如果用命令mex mex-projL1Inf.c,就是生成 mex-projL1Inf.mexa64 (已经实践,将原始 projL1Inf.mexa64 删除,用命令mex mex-projL1Inf.c,就是生成 mex-projL1Inf.mexa64, 再将这个文件改名为projL1Inf.mexa64,再运行runprojection 还是可以的)
20121208在uts服务器编译libsvm-mat-2.9-1,编译有问题,根据提示,将所有文件*.c都变成*.cpp,还有问题g++: svm.obj: No such file or directory,上网搜索解决方案http://blog.csdn.net/kit_147/article/details/7417734,将文件svm.obj改为svm.o,编译就没有问题了,但用程序测试还有问题,提示 "-largeArrayDims"的问题,make.m开始注释:% add -largeArrayDims on 64-bit machines,问mingming gong怎么add?将makefile中的mex...修改为mex...-largeArrayDims即可。例如
mex -O -c svm.cpp
mex -O -c svm_model_matlab.c 修改为
mex -O -c svm.cpp -largeArrayDims
mex -O -c svm_model_matlab.c -largeArrayDims (This is with Mingming Gong's help) 20150710在跑FastHash提示错误:binaryTreeTrain1.mexw64不是有效的w32应用程序,感到费解,这是64位机,怎么会提示这个错误。Jian Liang讲重新编译下就行了,他就在matlab窗口敲入mex binaryTreeTrain1.cpp,再敲入mex forestInds.cpp就可以了
http://blog.csdn.net/flyingworm_eley/article/details/6517853 Newton-Raphson算法在统计中广泛应用于求解MLE的参数估计。 对应的单变量如下图: 
多元函数算法: 
Example:(implemented in R) #定义函数f(x) f=function(x){
1/x+1/(1-x)
} #定义f_d1为一阶导函数 f_d1=function(x){
-1/x^2+1/(x-1)^2
} #定义f_d2为二阶导函数 f_d2=function(x){
2/x^3-2/(x-1)^3
} #NR算法
NR=function(time,init){
X=NULL
D1=NULL #储存Xi一阶导函数值
D2=NULL #储存Xi二阶导函数值
count=0 X[1]=init
l=seq(0.02,0.98,0.0002)
plot(l,f(l),pch='.')
points(X[1],f(X[1]),pch=2,col=1) for (i in 2:time){
D1[i-1]=f_d1(X[i-1])
D2[i-1]=f_d2(X[i-1])
X[i]=X[i-1]-1/(D2[i-1])*(D1[i-1]) #NR算法迭代式
if (abs(D1[i-1])<0.05)break
points(X[i],f(X[i]),pch=2,col=i)
count=count+1
}
return(list(x=X,Deriviative_1=D,deriviative2=D2,count))
}
o=NR(30,0.9)
结果如下图:图中不同颜色的三角形表示i次迭代产生的估计值Xi 
o=NR(30,0.9) #另取函数f(x) f=function(x){
return(exp(3.5*cos(x))+4*sin(x))
} f_d1=function(x){
return(-3.5*exp(3.5*cos(x))*sin(x)+4*cos(x))
} f_d2=function(x){
return(-4*sin(x)+3.5^2*exp(3.5*cos(x))*(sin(x))^2-3.5*exp(3.5*cos(x))*cos(x))
} 得到结果如下: 
Reference from: Kevin Quinn Assistant Professor Univ Washington
|