|
|
|
发新文章 |
|
 | |

身为IT专业,新软件出来,要去用,体会,才能发现问题。Picasa刚出现时,nannan wang讲他们实验室人都在用,体验。 这几天体会了下Picasa,功能确实很强大,将我的一张照片命名为小杰,连在长城、水立方的照片,其他人比如shuicheng yan教授的合影和 ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
http://www.pconline.com.cn/pcedu/soft/gj/photo/0909/1841482_all.html http://www.makeuseof.com/tag/how-to-use-facial-recognition-technology-in-picasa-web-albums/ Google的东西总能带给我们惊喜,从几年前的谷歌地球、Chrome浏览器到最近被炒得火热的Google OS,它的产品线几乎囊括了互联网的各个角落。而作为Google中唯一一款免费图片管理软件,Picasa一经面世便以其超酷的特效和方便好用的功能吸引了不少眼球。 | 软件名称: | Google Picasa | | 软件版本: | 3.5.0 Build 79.67 多国语言版 | | 软件大小: | 9462k | | 软件授权: | 免费 | | 适用平台: | Win9X WinNT Win2000 WinXP Win2003 | | 下载地址: | Google Picasa |
几天前这款小软件正式升级到了最新版3.5,其中“人脸识别”便成为了它的最大看点! 
图1 Picasa 3.5体验手记
一、 探秘“人脸识别” 简单来说,Picasa的“人脸识别”是通过一种复杂的算法,对照片人物进行判断,所有包含人脸的照片都将被自动归集并由用户统一命名。而这样做的最大好处,就是能够让我们随时利用右上角的搜索栏,快速查找某人照片,而且之后所有新入库的相片也都会按照这个规则,自动归类到相应位置,十分方便! 启动Picasa后,软件会自动搜索图片库,对所有包含人脸的照片进行分类。在此过程中,每一张被检测到的照片都会以大头贴的形式进行显示(相同的人物将被自动整理在一起),不过由于没有姓名,这些头像暂时都将被自动存放在一个“Unnamed people”(未命名人物)文件夹中,等待用户处理。 
图2 等待命名的照片“大头贴”
待照片分析完毕,我们便可以通过双击“Unknown Person”为该人物命名(可以输入中文哟),于是第一个人物标签便这样建立好了。有了人物标签后,日常查找就显得方便多了,只要将待搜索的人名(当然必须是已命名的名字)输入到顶端搜索框,片刻功夫,Picasa便会自动列示出对应结果,而且准确度极高。 
图3 为人物“命名”
也许有些朋友会感到奇怪,为什么这里显示的照片全都是“大头贴”呢?其实这只是Picasa的一项默认设置,目的是为了方便用户进行辨认。如果您不喜欢或者不习惯,完全可以通过搜索框下方的按钮自行切换,很简单的。 
图4 人物Tag使用演示
当然以上所说的只是一种理想情况,事实上在日常工作中,我们常常会遇到各种各样的问题。比如照片中出现了无关人员、人物照片被错误识别等等,而这时就需要我们对其进行一番小小的修正。 一般来说如果拍摄地属于景点,就很有可能在照片内包含进一些无关人员,对于这种情况最简单的一个方法,就是直接点击“叉号”忽略。而对于那些由于人物本身采用了夸张性表情(如“大笑”、“闭眼”)或者相片曝光而导致的未识别头像,则可以直接将其拖拽到正确标签下即可。不过此时Picasa会自动在这些面孔上打下问号,等待我们手工确认后才会真正识别。值得一提的是,Picasa的识别可是具有一定学习能力的,随着确认照片的增多,它的识别能力也会相应增强哟! 小提示:新加入的照片,即使能够正常识别(即自动放置到相应人物标签下),也会在头像上打上问号,提请用户最终确认,这样就可以保证新进入的照片100%准确,细节处考虑相当严谨。 
图5 无关人员直接点击“叉号”忽略

图6 可疑面孔将提交用户审核
除此之外Picasa 3.5还在右下角安排了一个“People”按钮,这到底又是做什么用的呢?其实聪明的网友大概已经在下图中找到一点眉目了,不错!这个面板的最大用途,就是自动找出与当前人物有过合影的人员。 
图7 自动搜索合影人员
http://productforums.google.com/forum/#!topic/gmail-zh-cn/xO9ru5F6mck 我的笔记本也这样,用谷歌浏览器不能正常显示,用ie浏览器是可以正常显示星标的,不知是什么原因引起的。20121022在uts将谷歌浏览器包括所有插件都卸载后,现在谷歌浏览器能正常显示星标。20131224在niu group,戴尔台式机用谷歌浏览器和goagent能正常显示星标。20140320在niu group,台式机google site能编辑,但T420笔记本不能编辑。将笔记本google浏览器删除,包括配置数据后,重新安装最新版google浏览器,星标能正常显示了(过几天又不正常显示了,不纠结这个问题了),但google site还是不能编辑。 20141208在niu group,台式机和x240s经过安装最新版goagent,星标能正常显示了,google site能编辑。
http://www.guao.hk/posts/5-cool-picasa-features.html 我是一个有点反复无常的Picasa用户(桌面的picasa软件,不是指网上相册的那个picasaweb)。每一次我重新开始使用picasa时,都会意识到这是一款多么伟大的软件,它真的应该一直停留在我的电脑里面,一直停留在每一个用户的电脑里面。 Google出了很多好的软件和系统,而Picasa是其中尤其优秀的一款产品。如果你是个硬盘里面保存和很多照片和图片,时不时也要浏览和编辑一下下的用户,那Picasa真的应该作为你默认的图片编辑工具。除了简单的欣赏照片以外,Picasa提供了很多很多的特性,使图片的浏览、编辑更加的方便、易用和有趣! 这里介绍5个功能,都是我认为很好,而且会频繁使用到的。 方便的调整图片为适合的尺寸我习惯于把我很多漂亮的照片放在一起做成一张相片 。但是很多别的图片编辑软件没办法把照片的尺寸调整的刚刚好。哪怕指定了准确的尺寸进行调整,那些图片看上去也会偏大或者偏小。然后我们就不得不把多余的切下来或者空出一块难看的空白…… 使用Picasa就没有这些问题,调整图片尺寸的时候,它会变得刚刚好。 在图片编辑窗口点击”打印”按钮,会显示出各种尺寸的选项。 
用户还可以点击“边界和文本选项”(”Border and Text”)添加边框来给图片添加边框和文字描述。还可以选择希望显示多少分图片的拷贝并把它们放到同一个页面内(取决于尺寸)。最后,选择你希望的尺寸并打印,非常简单吧? 
嵌入你的照片在HTML页面内如果你想要把照片放到网页内,但是对自己HTML的编程水平不太自信的话,用picasa处理是非常方便的。甚至比使用Web Album Generatr创建相册还要容易。 选择你想要放到页面内的照片,然后点击菜单“目录”—“导出为HTML页面”,弹出如图若干选项: 
选择相应的选项,然后弹出窗口,要求你选择一个页面的类型,如下图: 
确认后,Picasa很快生成相应的页面,并在浏览器中显示。如果觉得满意,在浏览器中,用“文件”—“网页另存为…”就可以保存下来了。 
直接把照片发布到Blogger里
现在,我又开始重新使用Blogger了……当我想要发送我的照片到Blog上时,这个功能是非常有用的。 双击希望Picasa中希望发布的照片, 点击下方的”BlogThis”按钮。弹出窗口要求登录Blogger(如果你还没设置登陆的话)。 使用Google帐户登录以后,填写关于尺寸的参数,然后再敲一些描述照片的文字(这些文字会显示在照片边上),然后点击“发布”,图片就马上出现在你的Blog页面里啦,非常方便吧!
把照片做成拼贴画,然后做成桌面的墙纸!
Picasa 可以非常容易的帮助你制作照片拼贴效果,超酷! 很简单,首选选中要拼贴的照片,点击“制作”-“图片拼贴”,你的这些图片就被picasa随机的生成了拼贴效果。当然,你还可以通过调整选项来尝试不同的拼贴效果。 一旦完成拼贴,下面就有个选项,可以直接使生成的图片成为桌面墙纸。 
这样的效果会让你的女朋友兴奋的跳起来的! 制作幻灯片的视频,配上音乐,并上传到YouTube!
周六的时候我参加了一个婚礼,新郎和新娘的朋友们制作了一段幻灯片送给他们,里面有两人不同时期的照片,并在婚礼上面播放。但是他们笔记本中的软件突然死掉了。幸好有picasa!我们来看看Picasa是如何轻易的就做出了幻灯效果,而且配上音乐的! 当然,Picasa只能简单的做出用照片形成的幻灯效果,我们不能指望它去参加奥斯卡奖的评选:)。但是,如果你只是希望用一种方式去展示你的照片并配上音乐(不配音乐当然也可以),那这个方法还是非常方便并适合的。 把所有要加入幻灯的照片保存到一个目录下,然后Picasa在每个目录的顶部就有“制作视频演示”的按钮。点击,并调整显示顺序(如果把名字按照显示的顺序来命名,如picture1.jpg,picture2.jpg…,那就更简单了)。 
在界面的左面,也有一些选项可以添加音乐。在“音轨”栏目,点击“载入”,找到你计算机本地的音频文件,就可以了。在下面,可以选择“转场样式”,用来调整图片在幻灯中切换的方式。你还可以通过调整选项来使照片渐入渐出、推进推出、缩放或者左右移动等等。 在主窗口里,点击播放,就可以看到幻灯片的效果。也可以全屏来看最大最清晰的效果。最后,当你对幻灯片满意的时候,可以直接点击“YouTube”按钮上传到YouTube上,这样其余人就可以一起分享你的幻灯片了! 下面还列出了一些介绍Picasa特性和功能的文章:
第一、matlab能不用循环尽量不用循环
% % Nannan wang says that in matlab, cycling(循环) is time-consuming. % % 能不用循环就不用循环 % % The easiest example to illustrate this idea 已知两个矩阵A,B,求所有元素对应相乘之和 思路一:用两重循环实现 思路二:点乘后的矩阵用C表示,sum(C(:)),思路二更好,没用循环
第二、预先分配存储空间
tic; a=zeros(1000,10000); for i=1:1000 a(i,:)=randperm(10000); end toc;
20130111在我的笔记本测试,需要时间1.115140 seconds;如果将a=zeros(1000,10000)注释,在我的笔记本测试,需要时间19.308252 seconds
参考文献:
见我的matlab教材P54
On the group meeting of Oct 3, 2018, Jiaqi shows his bar. I asked that why his variance is very small. He said that he uses the standard error (https://en.wikipedia.org/wiki/Standard_error), which is standard derivation divided by the square root of the number of trials. According to the notes of my undergraduate course probability:
(1) D(ax+b) = a*a*D(x),
(2) the second line of "中心极限定理". x bar is seen as a random variable,
we have std(x bar) = std(x)/sqrt(n).
I ask Jiaqi which tool he uses to draw his figure. He says he uses python, bar of matplotlib. https://matplotlib.org/api/_as_gen/matplotlib.pyplot.bar.html. The mean of the errors and standard error should be computed first and then be used as the input of xerr and yerr.
I check my TNNLS 2017 paper and I find that I show the std. Maybe next time I can show the standard error.
这个函数的意思是:
ERRORBAR(X,Y,L,U),X是自变量,Y是因变量,L是Y的变动下限,U是Y的变动上限
errorbar(X,Y,E) X是自变量,Y是因变量,E是Y的变动绝对差值。 我自己写的例子:
X=[1 2 3];
Y= [ 0.2 0.4 0.2];
L=[0.1 0.03 0.03];U=[0.1 0.3 0.2];
E= [0.1 0.3 0.2];
figure;
hold on;%一定要有这一句,否则有问题
bar(X,Y);
errorbar(X,Y,E,'Marker','none','LineStyle','none');
figure;
hold on;%一定要有这一句,否则有问题
errorbar(X,Y,E);%以下注释的两句用这一句就可以了
%plot(X,Y);
%errorbar(X,Y,E,'Marker','none','LineStyle','none'); figure;
hold on;%一定要有这一句,否则有问题
bar(X,Y);
errorbar(X,Y,L,U);%,'Marker','none','LineStyle','none'不能省
说明:必须使用hold on,bar是画柱状图, errorbar是花竖线--------------------------------------------------------------------以下可不看----------------------------------------------------------------------------
example1:
x = 1:10;
y = sin(x);
e = std(y)*ones(size(x));
errorbar(x,y,e)

example2: % 生成示例数据x=1:10;y=cumsum(randn(1,10));lower = y - (rand(1,10));upper = y + (rand(1,10));% 由于errorbar函数使用相对差值在图形上绘图,所以% 需要将绝对差值转变为相对差值。L = y - lower;U = upper -y;% 绘图时需要设定 hold on% 柱状图clf;figure(1);hold on;bar(x,y);% 此处需要隐藏折线errorbar(x,y,L,U,'Marker','none','LineStyle','none');% 折线图figure(2);hold('on');plot( x, y);errorbar( x, y, L, U); Reference: http://blog.sina.com.cn/s/blog_61010ebe0100l9c9.html http://bio-spring.info/wp/?p=85
http://blog.163.com/symphony_sol/blog/static/30279623200751841822500/
两种不同的随机数算法
seed是matlab4的,matlab5及以后用的是state
seed 现在也是有的,
实际上现在用的随机数是伪随机数,由一定的规则产生
比如z_{k+1}=f(z_{k}),z_{k}即为我们得到的随机数,
比如之前得到的随机数是0.5, 再用randn命令得到的随机数是0.6
那么如果下次得到随机数0.5,那么之后的随机数还是0.6
seed是产生这个随机数的种子,也就是初始值z_{0},seed不同,得到的随机数列也不同,
取定了seed之后,随机数列也就确定了,只不过这个数列非常大,看起来就象是随机产生的,
举例:
seed=x1
得到随机数列 y1,....ym
seed=x2
得到随机数列 z1,.....zn
关于state:指定随机数的状态,
我的理解是类似于指定了这个随机数列数组的下标
比如:randn('state',100)
然后产生一个随机数为 r0
然后中间再产生了若干随机数
然后再键入命令randn('state',100)
这时再产生的随机数还是r0
http://blog.sina.com.cn/s/blog_6c00b0e30100rmyy.html
(2)RANDN产生伪随机数的语法:
发生器的状态决定所产生数的序号。
S = RANDN('state') 是一个二元向量,包括标准发生器的状态;
RANDN('state',S):设置发生器的状态为S(即标准状态);
RANDN('state',0):设置发生器的初始状态;
RANDN('state',J):J为整数,设置发生器到J阶状态;
(3)MATlAB 4.X应用一个单独的种子来产生随机数:
RANDN('seed',0) and RANDN('seed',J)作用与RANDN('state',0)和RANDN('state',J)一样,但使用Matlab 4.x随机数发生器。
RANDN('seed'):返回MATlAB 4.X发生器的当前种子。 |
以上部分是转自其他网友的分析。下面是我对这randn或rand的理解。
例如:randn('state',0);,表明选定了一个初状态,再定义随机数列x=randn(1,100),x的值会确定下来,不会每运行一次而产生不同的随机数。
例如: "E:\other\matlab 2007a\work\function\rand_"
a1 =2 3 1
b1 = 4 1 3 2
c1 = 1 3 4 5 2 重新运行还是这个结果
do_exp_MNIST_SSH_BRE_ITQ中半监督hashingSSH 重新跑一次,除了Training time和Test Time还是这个结果,因为有rand('seed',0);
rand('seed',0)和randn('state',0): do_exp_MNIST_SSH_BRE_ITQ中CCA-ITQ加randn('state',0)重新跑一次,除了Training time和Test Time还是这个结果,rand('state',0)不行,因为ITQ函数中用的randn不是rand
20160120谷歌搜索:randperm seed,找一个连接https://www.mathworks.com/matlabcentral/newsreader/view_thread/171653,有如下语句:If we initialize rand with some seed (say
rand('seed',1)) then the result of randperm(n) is always same after the initialization.
经过如下语句测试,没有任何问题:
rand('seed',1); a = randperm(10); i=2; rand('seed',i); b = randperm(20); rand('seed',1); c = randperm(10); i=2; rand('seed',i); d = randperm(20); sum(a==c) sum(b==d)
dispfor i = 1:10 disp(i) end display%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% display(['Show the value of i and j...']);%即可以输出字符串
for i=1:2
for j=1:2 display(['--------i=', num2str(i), ' j=', num2str(j), '------------']);
end
end 见我的matlab教材P20
Definition (classification context)For classification tasks, the terms true positives, true negatives, false positives, and false negatives (see also Type I and type II errors) compare the results of the classifier under test with trusted external judgments. The terms positive and negative refer to the classifier's prediction (sometimes known as the observation), and the terms true and false refer to whether that prediction corresponds to the external judgment (sometimes known as the expectation). This is illustrated by the table below: | actual class
(expectation) |
|---|
|
|---|
predicted class
(observation) | tp
(true positive)
Correct result | fp
(false positive)
Unexpected result |
|---|
fn
(false negative)
Missing result | tn
(true negative)
Correct absence of result |
Precision and recall are then defined as:[4] 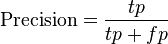 [通俗理解:预测出来100个正例,事实只有30个,precesion就是0.3] [通俗理解:预测出来100个正例,事实只有30个,precesion就是0.3]
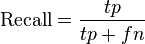 [通俗理解:总共200个正例,事实只有40个,recall就是0.2] [通俗理解:总共200个正例,事实只有40个,recall就是0.2]
Recall in this context is also referred to as the True Positive Rate or Sensitivity, and precision is also referred to as Positive predictive value (PPV); other related measures used in classification include True Negative Rate and Accuracy:.[4] True Negative Rate is also called Specificity. 

A measure that combines precision and recall is the harmonic mean of precision and recall, the traditional F-measure or balanced F-score: 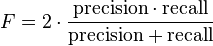
Reference
http://en.wikipedia.org/wiki/Precision_and_recall
Compressed labeling on distilled labelsets for multi-label learning公式85和86,这是对应multi-label的precision和 recall。(例如第i个样本的实际标记是 1 0 0;预测标记是1 1 0;该样本对应的值是1/2,与单label的意义很好对应,物理意义很好理解)
)
liblinear学习记录: 在本机:matlab 2007a\work\SVM\liblinear-1.96\matlab
定位到\liblinear-1.96\windows后,在win 64电脑上,train和predict是能直接使用的,不需要再编译
------------------------------------------------------Jianchao Yang的CVPR09-ScSPM公布的代码------------------------------------------------------------------------------------------------------------Yong Luo传给我的SVM------------------------------------------------------利用Yong Luo传给我的SVM,在电脑文件夹E:\other\matlab 2007a\work\SVM\SVM\,不用编译。 用testSVMnew还是testSVMold?最好用new。testSVMnew中又有kernelSVM文件夹,是什么作用? kernelSVM就是输入是kernel。在服务器运行SVM工具包,有问题Undefined function 'loqo' for input arguments of type 'double'.,是不是要编译的原因?是的,如果是64位机的linux系统,要拷贝这个文件loqo.mexa64,如果是32位机的windows系统,要拷贝这个文件loqo.mexw32 ,w和a的区别分别是windows和linux。Yong Luo 没将编译的程序发给我,如果需要也可以找他拷贝
--------------------------------------------------------------------------------------------------------------------------------------
E:\other\matlab 2007a\work\SVM\SVM\testSVMnew中的testSVM能直接运行
'nin' = NIN number of input dimensions,即输入数据的维数(已经得到Yong Luo确认,并且程序已经通过运行)
'nout' = 1 number of output dimensions
'kernel' = KERNEL kernel functi
'kernelpar' = KERNELPAR parameters for the kernel function,针对线性核,这个参数不起作用,高斯核就会有作用
C一般要调整吗?主要调整这个,就是惩罚因子
我自己的tag程序svmplot就有问题,什么原因?svmplot是两维的才能plot,高维的无法plot,直接将这一句注释即可
--------------------------------------------------------------------------------------------------------------------------------------
E:\other\matlab 2007a\work\SVM\SVM\testSVMnew\kernelSVM中的testkernelSVM( )能直接运行该函数里面调用kernelSVM,C=10代表什么?
kernelSVMfwd即是测试,注释中有其输出Y1的含义,Y1(i) is equivalent to the distance of point X(i,:) from the separating hyperplane. -------------------------------------------------------------------采用新的svm工具基于以下原因------------------------------------------------------------------------------
在uts服务器上编译libsvm时出现下面错误
Warning: You are using gcc version "4.4.6". The version
currently supported with MEX is "4.3.4".
For a list of currently supported compilers see:
http://www.mathworks.com/support/compilers/current_release/
不能编译通过,与Yong Luo discuss,因为这是大家共用的服务器,可能不能为了个人安装。想用matlab自带的svm函数,发现在测试时只能输入测试样本,不能输入核。故在服务器上先用Yong Luo提供的svm工具。
Caltech101是属于image categorization数据库,见Linear Spatial Pyramid Matching using Sparse Coding for Image Classification(CVPR09-ScSPM)摘要写了: In a number of image categorization experiments, 其标题是Image Classification。Mingming Gong讲image/object Classification/categorization 四个是一样的概念.
我自己到谷歌上搜索:object categorization COIL,发现A novel color-context descriptor and its applications (ICME 2009)摘要最后一句: Experiments validate the discriminant power of the proposed descriptor in object categorization on COIL- 100 database and pedestrian identification in surveillance videos.故Deng Cai主页的COIL是属于object categorization的
中文名称:图像检索
英文名称:image retrieval 定义:在图像集合中查找具有指定特征或包含指定内容的图像的技术。Yong Luo said比如线性化特征抽取方法,应该是用训练集学习一个投影矩阵,然后应用到测试集上来相互query,训练集丢掉,相当于离线学习了一个投影矩阵
Reference
http://baike.baidu.com/view/63486.htm
Learning a Maximum Margin Subspace for Image Retrieval
Dong Xu's Phd thesis Section 7
Cooperative Sparse Representation Semi-supervised Image Annotation --------------------------------------------------------------------------------------------------------------------------------------------------- 图像分类是测试样本的预测label和实际的label比较得准确率。图像标注本质也是分类,是测试样本预测出来的tag和实际的tag做比较得准确率,看voc 07的训练tag,是5011*804的矩阵,也就是总共804个tag,如果该样本有这个tag,则该位置的tag是1否则是0.一个图像可以有多个tag,image annotation本质也是multi-label的问题。是不是所有样本的tag确实只有804个,其实有更多,将一些频率比较低的去掉了。Yong Luo讲在测试时有这样的情况,测试样本没有tag,这时没法算准确率,就将这个测试样本去掉。 --------------------------------------------------------------------------------------------------------------------------------------------------------- image annotation就是image classification. 见Cooperative Sparse Representation Semi-supervised Image Annotation. VI节A节第三段:with the annotations from a set of total 20 keywords.This is discussing with Weifeng Liu and Yong Luo. Sparse Unsupervised Dimensionality Reduction for Multiple View Data该文IV节E节 2)就用的Image Classification and Annotation.该文用三个数据集,MIML仅有类别没有tag,后两个仅有tag没有类别,论文说了分别81和100个tag,故MIML是测试样本的预测label和实际的label比较得准确率,后两个库是是测试样本的预测tag和实际的tag比较得准确率。Yong Luo讲没有人在voc上做image annotation,因为其tag没有太多的语义信息,比如pascal07_dictionary的804个tag中还有2003,voc的tag只能作为特征。 Yong Luo:另外还有三个做annotation的数据库Corel 5K,IAPR TC-12,ESP GAME. Annotation是给图像加标注,阿秋TIP fig 3. Tian Xia MSE实验第三节是Video annotation, Tian Xia写了,和image retrival做法一样。这三个数据库Yong Luo 建议不要按照ML-KNN的五个指标来进行比较。Image annotation就按照annotation的指标,TagProp Discriminative Metric Learning (ICCV 2009)Table 3的P、R和N+。这三个指标的定义该文讲了,该文参考文献17 A. Makadia, V. Pavlovic, and S. Kumar. A new baseline for image annotation. In ECCV, 2008也讲了。 整个领域基本都是分类或者回归问题,少部分是回归,比如是年龄回归(age regression)。mingming gong said that介于两者之间的还有一个是ordinal regression = ranking(值是离散的,还有大小)
|