本文挡描述的是
Logiscope——Audit中函数作用域常用度量元的具体含义。
对每个度量元的解释分为以下几部分:
首先是该度量元的原文名称,后面是该度量元的代号,跟在后面的是Audit质量模型为该度量元设的参考值(用中括号括起。当然,对于这个范围值,我们可以对它进行修改),再往下就是对该度量元含义的具体解释。
下面分别介绍函数作用域中各个度量元
的具体含义
。注意,下面讨论的所有问题都是站在一个函数的角度上的,这一点对于我们理解这些度量元很重要。
度量元名称:函数的圈复杂度。
解释说明:
函数圈复杂度的计算方法为:将函数流程图中各节点(开始和结束结点除外)的引出边的数量减去一后的值相加,最后再在这个和的基础上加一。可见,当一个函数中条件判断的地方越多时,它的
ct_vg
就会越大。
如果该值过大,会增大函数的复杂性,影响我们对函数的理解。
度量元名称:函数中非结构化语句的数量。
解释说明:
非结构化语句包括:
goto
语句、在循环中使用的
break
、
continue
语句。
该度量元是为了使程序编写符合结构化的要求。
度量元的名称:函数中定义的变量的数量。
解释说明:
在函数体内部定义的变量的数量。函数中局部变量定义的过多,会增大代码的复杂性,影响对函数的理解。
度量元的名称:函数参数的数量。
解释说明:
函数的参数过多,会使函数易于受外部(其他部分的代码)变化的影响,从而影响维护工作。
函数的参数过多也会增大测试的工作量。
度量元的名称:函数中调用其它函数的数量。
解释说明:
在函数体中调用其它函数的数量,对同一函数的多次调用计为一次。
该值过大,首先是会使函数易于受外部(其他部分的代码)变化的影响,从而增加维护工作的工作量。
其次,该值过大,也会增加阅读程序的人在理解程序上的困难。
度量元的名称:函数出口的数量。
解释说明:
也就是函数体中退出点的数量。
在一个函数中存在一个以上的出口会增加函数出错的可能性,建议单出口。
度量元的名称:函数中使用其它类的数据成员的数量。
解释说明:
所谓函数中使用的其它类的数据成员的数量,也就是在函数体中对外部类(与该函数所属的类不是同一个类)的数据成员的使用数量,对同一数据成员的多次使用计为一次。
这个度量元的用意也很好理解,就是为了尽量减少函数与其它类的耦合关系。
度量元的名称:函数中执行路径的数量。
解释说明:
函数中执行路径过多,会极大的增大测试的工作量。
度量元的名称:函数中的可执行语句数
.
解释说明:
函数中的可执行语句数过多,意味着函数的功能可能不单一,同时也会增加函数的复杂性。
度量元的名称:语句平均承载的信息量。
解释说明:
该度量元计算在一个函数中,平均每个可执行语句所包含的操作符和操作数的数量。
该度量元的计算公式为:
AVGS = (N1 + N2) / (lc_stat )
其中:
N1
是该函数中的操作符的数量
,
N2
是该函数中的操作数的数量
,
lc_stat
是函数中可执行语句的数量
.
如果平均每个可执行语句所包含的操作符和操作数的数量较多时,也就是说当程序语句比较长时,会增大阅读者理解程序的难度。应该将较长的语句分解为几个较短的语句,以此来降低程序的复杂性。
度量元的名称:词汇频率。
解释说明:
该度量元表示的是在一个函数中,相同的操作符和操作数出现的频率。
该度量元的计算公式为:
VOCF = (N1+N2) / (n1+n2)
其中:
N1
是该函数中的操作符的数量,包括重复出现的;
N2
是该函数中的操作数的数量,包括重复出现的;
n1
是该函数中不同的操作符的数量
,
n2
是该函数中不同的操作数的数量
,
当一个函数
VOCF
的值较高时,说明在这个函数中可能包含重复的或类似的语句。如果确实是这种情况,建议将这些反复使用的语句分离出来,写成一个单独的函数,从而增加了程序的简明、清晰程度,也为以后修改这个函数带来了方便。
度量元的名称:函数的注释比率。
解释说明:
函数中的注释块的数量与函数中的可执行语句的数量之比。
该度量元的计算公式为:
COMF = (lc_bcom + lc_bcob) / (lc_stat )
其中:
lc_bcom
是函数体中注释块的数量
,
lc_bcob
是函数体前注释块的数量(值只能为
0
或
1
)
,
lc_stat
是函数中可执行语句的数量
.
这个度量元能反映出程序的开发者是否对程序进行了认真的注释。如果函数的注释写的比较充分,那么在我们进行测试工作和维护工作需要理解程序代码时是非常有用的。
这个度量元检测的是注释块的数量,而不是注释行的数量,这种注释量的计算方法我认为更科学。
度量元的名称:函数中具有嵌套的控制结构的最大的嵌套层数再加一。
解释说明:
该度量元的计算公式为:
其中:
ct_nest
:函数中控制结构嵌套的最大嵌套层数。
函数中具有嵌套的控制结构的最大的嵌套层数再加一。该值越大,说明函数越复杂,越难于理解。
度量元的名称:
扇入
解释说明:
该度量元的计算公式为:
其中:
ic_usedp
是函数参数的个数;
ic_varpi
是函数对本类中数据成员的使用次数。
这个度量元反映的是函数需要输入的数据量。
如果函数需要输入的数据过多,那么阅读者对函数进行理解时会变的困难,并且外部变化对函数的影响也会较大。
度量元的名称:
扇出
解释说明:
该度量元的计算公式为:
其中:
ic_paradd
是传址参数的个数;
ic_varpe
是函数对外部类数据成员的使用次数。
这个度量元反映的是函数的输出数据量。如果函数输出的数据量过多,那么对这个函数进行理解分析时会很困难。同时,函数输出的数据量越大,这样的函数对系统的影响也会越大,所以应该加以限制。
度量元的名称:
被调用次数
解释说明:
该项度量元表示的是:调用了该函数的函数的个数。
一个函数,调用它的函数越多,则对该函数的可靠性要求的越高,它一旦发生问题,引发的后果就越严重。系统中这样的函数越多,出现问题的可能性就越大,所以应该加以限制。
度量元的名称:调用层次数
解释说明:
该项度量元表示的是:在该函数的调用关系图中,函数调用关系的层次数。
比如图
2-1
的这个的函数调用关系图中,函数
Fun2( )
的
cg_levels
的值为
3
。
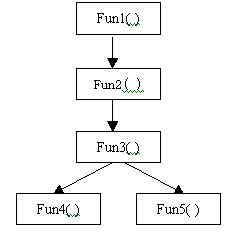 图 2-1 函数调用关系图
图 2-1 函数调用关系图
度量元的名称:每层平均函数个数
解释说明:
该项度量元表示的是:在该函数的调用关系图中,平均每一层上的函数个数。
比如图
2-1
的函数调用关系图中,函数
Fun2( )
的
cg_hiercpx
的值为
4 / 3 = 1.3
。
度量元的名称:函数平均调用数量
解释说明:
该项度量元表示的是:在函数的调用关系图中,每个函数的平均调用数量。
比如图
2-1
的函数调用关系图中,函数
Fun2( )
的
cg_strucpx
的值为
3 / 4 = 0.75
。
度量元的名称:调用路径数量
解释说明:
该项度量元表示的是:在该函数的调用关系图中,从该函数到每个叶子函数的不同路径数量之和。
比如图
2-1
的函数调用关系图中,函数
Fun2( )
的
IND_CALLS
的值为
2
。
度量元的名称:函数调用关系的易测性
解释说明:
该项度量元表示的是:对该函数的函数调用关系进行测试时的工作量。