“CUDA 是 NVIDIA 的 GPGPU 模型,它使用 C 语言为基础,可以直接以大多数人熟悉的 C 语言,写出在显示芯片上执行的程序,而不需要去学习特定的显示芯片的指令或是特殊的结构。”
CUDA是什么?能吃吗?
编者注:NVIDIA的GeFoce 8800GTX发布后,它的通用计算架构CUDA经过一年多的推广后,现在已经在有相当多的论文发表,在商业应用软件等方面也初步出现了视频编解码、金融、地质勘探、科学计算等领域的产品,是时候让我们对其作更深一步的了解。为了让大家更容易了解CUDA,我们征得Hotball的本人同意,发表他最近 亲自撰写的本文。这篇文章的特点是深入浅出,也包含了hotball本人编写一些简单CUDA程序的亲身体验,对于希望了解CUDA的读者来说是非常不错 的入门文章,PCINLIFE对本文的发表没有作任何的删减,主要是把一些台湾的词汇转换成大陆的词汇以及作了若干"编者注"的注释。
现代的显示芯片已经具有高度的可程序化能力,由于显示芯片通常具有相当高的内存带宽,以及大量的执行单元,因此开始有利用显示芯片来帮助进行一些计算工作的想法,即 GPGPU。CUDA 即是 NVIDIA 的 GPGPU 模型。
NVIDIA 的新一代显示芯片,包括 GeForce 8 系列及更新的显示芯片都支持 CUDA。NVIDIA 免费提供 CUDA 的开发工具(包括 Windows 版本和 Linux 版本)、程序范例、文件等等,可以在 CUDA Zone 下载。
使用显示芯片来进行运算工作,和使用 CPU 相比,主要有几个好处:
- 显示芯片通常具有更大的内存带宽。例如,NVIDIA 的 GeForce 8800GTX 具有超过 50GB/s 的内存带宽,而目前高阶 CPU 的内存带宽则在 10GB/s 左右。
- 显示芯片具有更大量的执行单元。例如 GeForce 8800GTX 具有 128 个 "stream processors",频率为 1.35GHz。CPU 频率通常较高,但是执行单元的数目则要少得多。
- 和高阶 CPU 相比,显卡的价格较为低廉。例如目前一张 GeForce 8800GT 包括 512MB 内存的价格,和一颗 2.4GHz 四核心 CPU 的价格相若。
当然,使用显示芯片也有它的一些缺点:
- 显示芯片的运算单元数量很多,因此对于不能高度并行化的工作,所能带来的帮助就不大。
- 显示芯片目前通常只支持 32 bits 浮点数,且多半不能完全支持 IEEE 754 规格, 有些运算的精确度可能较低。目前许多显示芯片并没有分开的整数运算单元,因此整数运算的效率较差。
- 显示芯片通常不具有分支预测等复杂的流程控制单元,因此对于具有高度分支的程序,效率会比较差。
- 目前 GPGPU 的程序模型仍不成熟,也还没有公认的标准。例如 NVIDIA 和 AMD/ATI 就有各自不同的程序模型。
整体来说,显示芯片的性质类似 stream processor,适合一次进行大量相同的工作。CPU 则比较有弹性,能同时进行变化较多的工作。
CUDA 是 NVIDIA 的 GPGPU 模型,它使用 C 语言为基础,可以直接以大多数人熟悉的 C 语言,写出在显示芯片上执行的程序,而不需要去学习特定的显示芯片的指令或是特殊的结构。
在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 "kernel"。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
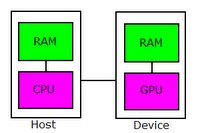
由于 CPU 存取显卡内存时只能透过 PCI Express 接口,因此速度较慢(PCI Express x16 的理论带宽是双向各 4GB/s),因此不能太常进行这类动作,以免降低效率。
在 CUDA 架构下,显示芯片执行时的最小单位是 thread。数个 thread 可以组成一个 block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。
每一个 block 所能包含的 thread 数目是有限的。不过,执行相同程序的 block,可以组成 grid。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
Grid、block 和 thread 的关系,如下图所示:
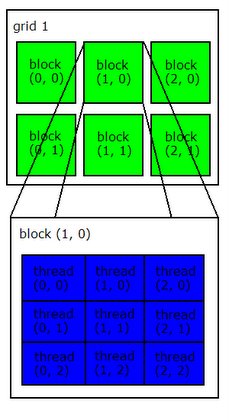
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个 thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。这些不同的内存的差别,会在之后讨论。
由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般 CPU 是不同的。主要的特点包括:
- 内存存取 latency 的问题:CPU 通常使用 cache 来减少存取主内存的次数,以避免内存 latency 影响到执行效率。显示芯片则多半没有 cache(或很小),而利用并行化执行的方式来隐藏内存的 latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个 thread,依此类推)。
- 分支指令的问题:CPU 通常利用分支预测等方式来减少分支指令造成的 pipeline bubble。显示芯片则多半使用类似处理内存 latency 的方式。不过,通常显示芯片处理分支的效率会比较差。
因此,最适合利用 CUDA 处理的问题,是可以大量并行化的问题,才能有效隐藏内存的 latency,并有效利用显示芯片上的大量执行单元。使用 CUDA 时,同时有上千个 thread 在执行是很正常的。因此,如果不能大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。