GPU 的硬件架构
这里我们会简单介绍,NVIDIA 目前支持 CUDA 的 GPU,其在执行 CUDA 程序的部份(基本上就是其 shader 单元)的架构。这里的数据是综合 NVIDIA 所公布的信息,以及 NVIDIA 在各个研讨会、学校课程等所提供的数据,因此有可能会有不正确的地方。主要的数据源包括 NVIDIA 的 CUDA Programming Guide 1.1、NVIDIA 在 Supercomputing '07 介绍 CUDA 的 session,以及 UIUC 的 CUDA 课程。
目前 NVIDIA 推出的显示芯片,支持 CUDA 的是 G80 系列的显示芯片。其中 G80 显示芯片支持 CUDA 1.0 版,而 G84、G86、G92、G94、G96 则支援 CUDA 1.1 版。基本上,除了最早的 GeForce 8800 Ultra/GTX 及 320MB/640MB 版本的 GeForce 8800GTS、Tesla 等显卡是 CUDA 1.0 版之外,其它 GeForce 8 系列及 9 系列显卡都支持 CUDA 1.1。详细情形可以参考 CUDA Programming Guide 1.1 的 Appendix A。
所有目前支持 CUDA 的 NVIDIA 显示芯片,其 shader 部份都是由多个 multiprocessors 组成。每个 multiprocessor 里包含了八个 stream processors, 其组成是四个四个一组,也就是说实际上可以看成是有两组 4D 的 SIMD 处理器。此外,每个 multiprocessor 还具有 8192 个寄存器,16KB 的 share memory,以及 texture cache 和 constant cache。大致上如下图所示:
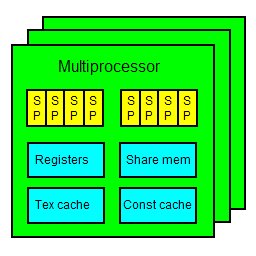
详细的 multiprocessor 信息,都可以透过 CUDA 的 cudaGetDeviceProperties() 函式或 cuDeviceGetProperties() 函式取得。不过,目前还没有办法直接取得一个显示芯片中有多少 multiprocessor 的信息。
在 CUDA 中,大部份基本的运算动作,都可以由 stream processor 进行。每个 stream processor 都包含一个 FMA(fused-multiply-add)单元,可以进行一个乘法和一个加法。比较复杂的运算则会需要比较长的时间。
在执行 CUDA 程序的时候,每个 stream processor 就是对应一个 thread。每个 multiprocessor 则对应一个 block。从之前的文章中,可以注意到一个 block 经常有很多个 thread(例如 256 个),远超过一个 multiprocessor 所有的 stream processor 数目。这又是怎么回事呢?
实际上,虽然一个 multiprocessor 只有八个 stream processor,但是由于 stream processor 进行各种运算都有 latency,更不用提内存存取的 latency,因此 CUDA 在执行程序的时候,是以 warp 为单位。目前的 CUDA 装置,一个 warp 里面有 32 个 threads,分成两组 16 threads 的 half-warp。由于 stream processor 的运算至少有 4 cycles 的 latency,因此对一个 4D 的 stream processors 来说,一次至少执行 16 个 threads(即 half-warp)才能有效隐藏各种运算的 latency。
由于 multiprocessor 中并没有太多别的内存,因此每个 thread 的状态都是直接保存在 multiprocessor 的寄存器中。所以,如果一个 multiprocessor 同时有愈多的 thread 要执行,就会需要愈多的寄存器空间。例如,假设一个 block 里面有 256 个 threads,每个 thread 用到 20 个寄存器,那么总共就需要 256x20 = 5,120 个寄存器才能保存每个 thread 的状态。
目前 CUDA 装置中每个 multiprocessor 有 8,192 个寄存器,因此,如果每个 thread 使用到 16 个寄存器,那就表示一个 multiprocessor 同时最多只能维持 512 个 thread 的执行。如果同时进行的 thread 数目超过这个数字,那么就会需要把一部份的数据储存在显卡内存中,就会降低执行的效率了。
编者注:在NVIDIA GT200中的Register File大小增加了一倍,在FP32下可用的register file为16K,FP64下是8K。
目前 CUDA 装置中,每个 multiprocessor 有 16KB 的 shared memory。Shared memory 分成 16 个 bank。如果同时每个 thread 是存取不同的 bank,就不会产生任何问题,存取 shared memory 的速度和存取寄存器相同。不过,如果同时有两个(或更多个) threads 存取同一个 bank 的数据,就会发生 bank conflict,这些 threads 就必须照顺序去存取,而无法同时存取 shared memory 了。
Shared memory 是以 4 bytes 为单位分成 banks。因此,假设以下的数据:
__shared__ int data[128];
那么,data[0] 是 bank 0、data[1] 是 bank 1、data[2] 是 bank 2、…、data[15] 是 bank 15,而 data[16] 又回到 bank 0。由于 warp 在执行时是以 half-warp 的方式执行,因此分属于不同的 half warp 的 threads,不会造成 bank conflict。
因此,如果程序在存取 shared memory 的时候,使用以下的方式:
int number = data[base + tid];
那就不会有任何 bank conflict,可以达到最高的效率。但是,如果是以下的方式:
int number = data[base + 4 * tid];
那么,thread 0 和 thread 4 就会存取到同一个 bank,thread 1 和 thread 5 也是同样,这样就会造成 bank conflict。在这个例子中,一个 half warp 的 16 个 threads 会有四个 threads 存取同一个 bank,因此存取 share memory 的速度会变成原来的 1/4。
一个重要的例外是,当多个 thread 存取到同一个 shared memory 的地址时,shared memory 可以将这个地址的 32 bits 数据「广播」到所有读取的 threads,因此不会造成 bank conflict。例如:
int number = data[3];
这样不会造成 bank conflict,因为所有的 thread 都读取同一个地址的数据。
很多时候 shared memory 的 bank conflict 可以透过修改数据存放的方式来解决。例如,以下的程序:
data[tid] = global_data[tid];
...
int number = data[16 * tid];
会造成严重的 bank conflict,为了避免这个问题,可以把数据的排列方式稍加修改,把存取方式改成:
int row = tid / 16;
int column = tid % 16;
data[row * 17 + column] = global_data[tid];
...
int number = data[17 * tid];
这样就不会造成 bank conflict 了。
编者注:share memory在NVIDIA的文档中其实还有不同的叫法,例如PDC(Parallel Data Cache)、PBSM(per-block share memory)。
由于 multiprocessor 并没有对 global memory 做 cache(如果每个 multiprocessor 都有自己的 global memory cache,将会需要 cache coherence protocol,会大幅增加 cache 的复杂度),所以 global memory 存取的 latency 非常的长。除此之外,前面的文章中也提到过 global memory 的存取,要尽可能的连续。这是因为 DRAM 存取的特性所造成的结果。
更精确的说,global memory 的存取,需要是 "coalesced"。所谓的 coalesced,是表示除了连续之外,而且它开始的地址,必须是每个 thread 所存取的大小的 16 倍。例如,如果每个 thread 都读取 32 bits 的数据,那么第一个 thread 读取的地址,必须是 16*4 = 64 bytes 的倍数。
如果有一部份的 thread 没有读取内存,并不会影响到其它的 thread 速行 coalesced 的存取。例如:
if(tid != 3) {
int number = data[tid];
}
虽然 thread 3 并没有读取数据,但是由于其它的 thread 仍符合 coalesced 的条件(假设 data 的地址是 64 bytes 的倍数),这样的内存读取仍会符合 coalesced 的条件。
在目前的 CUDA 1.1 装置中,每个 thread 一次读取的内存数据量,可以是 32 bits、64 bits、或 128 bits。不过,32 bits 的效率是最好的。64 bits 的效率会稍差,而一次读取 128 bits 的效率则比一次读取 32 bits 要显著来得低(但仍比 non-coalesced 的存取要好)。
如果每个 thread 一次存取的数据并不是 32 bits、64 bits、或 128 bits,那就无法符合 coalesced 的条件。例如,以下的程序:
struct vec3d { float x, y, z; };
...
__global__ void func(struct vec3d* data, float* output)
{
output[tid] = data[tid].x * data[tid].x +
data[tid].y * data[tid].y +
data[tid].z * data[tid].z;
}
并不是 coalesced 的读取,因为 vec3d 的大小是 12 bytes,而非 4 bytes、8 bytes、或 16 bytes。要解决这个问题,可以使用 __align(n)__ 的指示,例如:
struct __align__(16) vec3d { float x, y, z; };
这会让 compiler 在 vec3d 后面加上一个空的 4 bytes,以补齐 16 bytes。另一个方法,是把数据结构转换成三个连续的数组,例如:
__global__ void func(float* x, float* y, float* z, float* output)
{
output[tid] = x[tid] * x[tid] + y[tid] * y[tid] +
z[tid] * z[tid];
}
如果因为其它原因使数据结构无法这样调整,也可以考虑利用 shared memory 在 GPU 上做结构的调整。例如:
__global__ void func(struct vec3d* data, float* output)
{
__shared__ float temp[THREAD_NUM * 3];
const float* fdata = (float*) data;
temp[tid] = fdata[tid];
temp[tid + THREAD_NUM] = fdata[tid + THREAD_NUM];
temp[tid + THREAD_NUM*2] = fdata[tid + THREAD_NUM*2];
__syncthreads();
output[tid] = temp[tid*3] * temp[tid*3] +
temp[tid*3+1] * temp[tid*3+1] +
temp[tid*3+2] * temp[tid*3+2];
}
在上面的例子中,我们先用连续的方式,把数据从 global memory 读到 shared memory。由于 shared memory 不需要担心存取顺序(但要注意 bank conflict 问题,参照前一节),所以可以避开 non-coalesced 读取的问题。
CUDA 支援 texture。在 CUDA 的 kernel 程序中,可以利用显示芯片的 texture 单元,读取 texture 的数据。使用 texture 和 global memory 最大的差别在于 texture 只能读取,不能写入,而且显示芯片上有一定大小的 texture cache。因此,读取 texture 的时候,不需要符合 coalesced 的规则,也可以达到不错的效率。此外,读取 texture 时,也可以利用显示芯片中的 texture filtering 功能(例如 bilinear filtering),也可以快速转换数据型态,例如可以直接将 32 bits RGBA 的数据转换成四个 32 bits 浮点数。
显示芯片上的 texture cache 是针对一般绘图应用所设计,因此它仍最适合有区块性质的存取动作,而非随机的存取。因此,同一个 warp 中的各个 thread 最好是读取地址相近的数据,才能达到最高的效率。
对于已经能符合 coalesced 规则的数据,使用 global memory 通常会比使用 texture 要来得快。
Stream processor 里的运算单元,基本上是一个浮点数的 fused multiply-add 单元,也就是说它可以进行一次乘法和一次加法,如下所示:
a = b * c + d;
compiler 会自动把适当的加法和乘法运算,结合成一个 fmad 指令。
除了浮点数的加法及乘法之外,整数的加法、位运算、比较、取最小值、取最大值、及以型态的转换(浮点数转整数或整数转浮点数)都是可以全速进行的。整数的乘法则无法全速进行,但 24 bits 的乘法则可以。在 CUDA 中可以利用内建的 __mul24 和 __umul24 函式来进行 24 bits 的整数乘法。
浮点数的除法是利用先取倒数,再相乘的方式计算,因此精确度并不能达到 IEEE 754 的规范(最大误差为 2 ulp)。内建的 __fdividef(x,y) 提供更快速的除法,和一般的除法有相同的精确度,但是在 2216 < y < 2218 时会得到错误的结果。
此外 CUDA 还提供了一些精确度较低的内部函数,包括 __expf、__logf、__sinf、__cosf、__powf 等等。这些函式的速度较快,但精确度不如标准的函式。详细的数据可以参考 CUDA Programming Guide 1.1 的 Appendix B。
在 CUDA 中,GPU 不能直接存取主内存,只能存取显卡上的显示内存。因此,会需要将数据从主内存先复制到显卡内存中,进行运算后,再将结果从显卡内存中复制到主内存中。这些复制的动作会限于 PCI Express 的速度。使用 PCI Express x16 时,PCI Express 1.0 可以提供双向各 4GB/s 的带宽,而 PCI Express 2.0 则可提供 8GB/s 的带宽。当然这都是理论值。
从一般的内存复制数据到显卡内存的时候,由于一般的内存可能随时会被操作系统搬动,因此 CUDA 会先将数据复制到一块内部的内存中,才能利用 DMA 将数据复制到显卡内存中。如果想要避免这个重复的复制动作,可以使用 cudaMallocHost 函式,在主内存中取得一块 page locked 的内存。不过,如果要求太大量的 page locked 的内存,将会影响到操作系统对内存的管理,可能会减低系统的效率。
原文地址