财务应该及早进入产品开发流程,贯穿到企业愿景,使命,产品规划,产品开发及产品生命周期管理全过程
IPD成本控制主要针对两个目标:
1、 降低开发成本
2、 降低产品本身的结构成本
研发人员常犯的成本错误:
1、 只关注物料成本,不关注设计成本和维护成本,出现物料成本虽然降低,但是带来的设计难度、设计成本增加
2、 不采购外来成熟组件,自行开发,导致产品不稳定带来的维护成本增加
3、 对公司内部成本高的优选器件不采用,忽略量产后带来的采购成本下降
控制综合成本的手段:
1、 通过需求与规划,区分基本需求、竞争需求、可有可无的需求,避免过度开发
2、 通过产品化共享,减少低水平重复开发
3、 通过技术分类,识别核心技术、关键技术、通用技术和一般技术,核心技术和关键技术自主开发,通用技术和一般技术外包,以降低开发成本
4、 在设计中控制成本:确定目标成本,设计中采用多方案选择,减少新模块,控制质量成本,加强可靠性设计,由高手负责设计
5、 在开发与制造中进行成本过程控制:保证资源
产品经理必须掌握的财务成本知识:
1、 了解财务基本专业知识,定期看部门财务报表,分析部门的内部核算表
2、 理解核算原则,学会用比例定岗
3、 了解公司和部门的固定成本变动,学会控制成本
4、 知识计算部门内部的盈亏平衡点
5、 知道怎么做预算,并亲自做预算和审核下级预算及费用
6、 关注项目回款,明白影响现金流的原因
7、 熟悉公司财务制度,并提出改进措施,使其简洁有效
posted @
2012-12-14 10:57 胡满超 阅读(427) |
评论 (0) |
编辑 收藏新产品开发的前三单客户也是产品开发的一部分,必须由公司高级别的人员完成,而不是一味地交给客户经理去销售
产品命名及商标管理:
1、 产品命令应将技术语言转换为了市场语言
2、 命名突出卖点
3、 命名保持统一品牌形象
4、 命名不要使用方言,俚语
产品宴会的FFAB策略:
Feature:技术卖点
Function:功能卖点
Advantage:产品的优点
Benefits:对客户的好处
1、 如果客户熟悉技术,突出介绍Function、Feature;不熟悉技术,突出介绍Advantage、Benefits
2、 客户经理(销售)应该掌握,Benefits、Advantage、Function
3、 市场经理应该掌握,Benefits、Advantage、Function、Feature
4、 技术经理应熟悉技术实现路径
5、 严格区别Advantage、Benefits
产品定价:
1、 要利润,定高价
2、 要规模,定低价
3、 阻拦对手,定更低价
4、 把价格隐藏在服务中
产品定价步骤:
1、 明确竞争对手产品
2、 分析竞争对手产品定价
3、 进行比较定价分析$APPEALS
4、 对产品进行成本分析,根据配置不同进行成本分析
5、 根据战略价值及KPI定价
6、 细化并验证定价策略
按价格承受力把客户分类:
1、 战略客户:样板用户,带动其他客户消费
2、 利润客户:接受的价格给公司带来的利润大于机会利润
3、 非利润客户:接受的价格给公司带来的利润小于机会利润
4、 大客户:订单较多
5、 价值客户:战略+利润+大客户
定价避免以下情况:
1、 避免大客户是非利润客户
2、 避免非利润的战略客户太多
3、 避免将战略客户等同于价值客户
客户满意度聚焦利润客户,价值客户的满意度必须达到100%,非战略非利润客户的满意度不要超过50%
新产品推广:
一个资料库六个子库:案例库,问题库,产品资料库,市场资料库,需求库,竞争对手资料库
销售工具包:内部销售工具包,给客户资料包
五种手段:公司展厅,展览会,样板点,研讨交流会,广告/网站/软性文章
公司高层,产品经理,市场经理,客户经理都要进行客户关系的维护和开拓
产品经理和系统级工程师更要对技术型的客户进行维护和开拓
产品销售工具:产品一纸禅、售前胶片、案例分析、销售指导书
通过规范的资料培训销售人员,营造产品大量进入市场的条件
posted @
2012-12-11 09:10 胡满超 阅读(391) |
评论 (0) |
编辑 收藏常见的质量管理问题原因:
1、 QA没有在设计时介入
2、 QA工作不独立,影响测试结果
3、 做评审没有评审要素,评审人没有绩效考核,走过场
4、 新手做设计,高手救火
5、 未建立公共模块共享开发的研发模式
6、 引入不成熟的技术
7、 在设计时,未进行多方案预备
构建质量体系六个要素:
1、 一套流程:将质量管理体系融入研发流程
2、 两个原则:业务决策评审与技术质量评审分离、建立产品货架
3、 三个职位:系统级工程师,主审人,PQA
4、 四个分离:规划与系统设计分离,设计与实现分离,实现与测试分离,测试与验证分离
5、 五种手段:规划与CBB共享、评审、测试和验证、任职资格与活动匹配、缺陷归零管理
6、 六个评审点
技术评审:关注技术评估
决策评审:关注财务、资源投入、计划
posted @
2012-12-06 16:19 胡满超 阅读(337) |
评论 (0) |
编辑 收藏技术分类:核心技术,关键技术,一般技术,通用技术
核心技术:需要进行发展规划,进行立体开发,知识产权保护
技术外包进行严格评审,避免核心技术,关键技术外包
核心技术,关键技术:纵向发展人员
一般技术,通用技术:横向发展人员,可以外包
核心技术特点:独有性,竞争性,可拦截性,不可替代性,可管理可保护,产生价值
技术并不是越多越好,而是核心技术和关键技术越多越好
技术开发五个阶段:立项,开发,验证,发布,成果货架化管理
对技术管理考核:结果要宽松,过程要严格
共用基础模块CBB:在不同产品、系统之间共用的零部件,模块,技术,设计成果
货架:将不同层次的产品统一管理
货架产品:成熟度达到一定程度的CBB
平台:一系列货架产品在层级上的集合
平台形成的两条路:
1、 根据需求形成平台规划:平台很难规划
2、 总结与沉淀:做3个定制项目进行一次CBB分析
技术预研和平台开发人员级别要高,需要高手开发
预研团队和技术开发,产品开发团队应该合理流动,以实现技术成果的产品化
鼓励和激励平台开发措施:
1、 通过任职资格牵引
2、 平台进行内部定价
3、 可以对非竞争的客户进行外部销售
4、 对平台开发给予战略补贴和特别激励
posted @
2012-12-04 09:38 胡满超 阅读(478) |
评论 (0) |
编辑 收藏项目分级:
A级项目:公司级重点关注和管理项目
B级项目:产品线重点关注和管理的项目
C级项目:产品经理或项目经理自己管理的项目
项目排序要素:市场吸引力、竞争地位、财务评估
单项目主体:项目经理
多项目主体:项目管理部
项目开发四个阶段:阶段,步骤,任务,活动
三个计划:
1、 一级计划:解决全流程、全要素协同
2、 二级计划:全流程协同下的各部门协同
3、 三级计划:指导更小模块或个人具体执行任务计划
提高计划准备度和完成率三要素:需求管理,关键资源及时到位,项目经理的能力
计划制订需要分阶段,分级进行,避免追求一次成型
posted @
2012-11-26 10:44 胡满超 阅读(396) |
评论 (0) |
编辑 收藏研发工作四类流程:
1、 技术开发流程:预研、应用技术开发V版本
2、 平台开发流程:共享模块开发V版本
3、 产品开发流程:每向细分市场R版本
4、 定制项目开发流程:在产品和平台基础上针对某一客户的定制M版本
产品开发活动四个步骤:阶段,步骤,任务,活动
概念阶段:验证市场需求,确立产品是否可以立项
计划阶段:确立总体方案,资源投入,确保工艺、结构方案、设计方案同步,避免重复开发
发布阶段:寻找样板客户,准备商标、命令、市场指导书、产品实验局、初步定价策略;销售工具包、售前胶片、销售指导书、产品的配置、商业械设计、产品的成功安全分析,销售培训,发布计划
产品开发流程六个阶段:概念、计划、产品开发、验证、生命周期管理
四个决策评审点:概念决策、计划决策、发布决策、生命周期决策
六个技术评审点:产品包需求评审、系统规格评审、概要设计评审、详细设计评审、样机评审、小批量评审
财务角色:
概念阶段:产品的定价分析和成本分析
计划阶段:核算综合成本
开发阶段:监控成本
发布阶段:明确价格策略
生命周期阶段:进行价格的核准和调整价格
生产、维护、服务人员:在方案设计阶段参与进来,提出可维护、可安装、可测试、可生产需求,使方案设计一步到位。
采购角色:
概念阶段:参与供应商认证
计划阶段:完成元器件认证,明确提前采购的风险
产品生命周期阶段:关注器件的产能情况,提前预警
企业执行产品开发流程失败原因分析:
1、 为流程而流程,只有研发参与
2、 没有建立市场管理流程,没有好的市场经理,产品开发没有良好的输入,推行产品开发流程困难
3、 没有培养起来系统级工程师或团队进行总体方案设计,没有打通设计时的所有环节,流程流于形式
4、 评审过于关注技术,在市场和财务成功方面考虑较少
5、 过多关注流程执行的完整性,没有结合自身情况,分步推进
6、 配套支撑流程和体系建设跟不上,如项目管理流程、绩效管理流程、任职资格体系建设,落地的支撑人员配套跟不上
7、 没有固化或形成时,过早进行IT化,僵化了流程
posted @
2012-11-19 15:32 胡满超 阅读(303) |
评论 (0) |
编辑 收藏研发与销售矛盾重重:需要建立市场体系,销售与市场分离
市场体系:分析客户需求,进行产品规划,培训渠道及客户经理,立足核心产品设计
市场体系:让产品好卖,营
销售体系:将产品卖好,销
需求管理四个步骤:需求收集,需求分析与分类,需求分发,需求实现及验证
需求管理体系目的:让每个人在日常活动中,将需求进行收集并通过分析和分发,以确保非金属人员面向市场进行开发
需求管理体系原则:落后了,找对手;平行了,建市场;领先了,做标准。
要建立好的市场体系,必须建立鼓励研发人员进入营销体系的机制。
为了保证快速地反映市场,规划必须每三个月更新一次。
需求分类:
A类:新产品开发需求
B类:产品设计规格更改需求
C类:详细设计路径更改需求
D类:生产订单需求
E类:CBB和平台开发需求
F类:技术开发需求
G类:市场调研,需要继续求证
进入一个客户群三要素:
1、 市场吸引力:市场规模,市场成长性,战略价值
2、 竞争地位:是否有能力进入,市场份额、产品优势、成本优势、渠道能力
3、 财务回报:收入增长率,现金流贡献、研发投入产出比
确定新产品的需求的方法:
1、 重新进行新产品开发
2、 对老产品进行改进
外部需求:客户的要求、功能需求、规格需求、可靠性需求
内部需求:产品化需求(可生产、可安装、可维护、可测试、可验证),技术需求
需求完成包括四类人员:客户经理、市场经理、产品经理、技术经理
需求产出的四份文档:
1、 客户需求规格说明书
2、 产品包需求说明书
3、 需求的分解分配
4、 技术规格说明书
将产品规格转变为技术需求:FFAB
Benefits:对客户的好处
Advantage:产品的优点
Function:功能模块的卖点
Feature:实现功能模块的技术特性
业界常用的$APPEALS模型:$价格、A可获得性、P包装、P功能性能、E易用、A保证、L生命周期成本、S社会接受程度

posted @
2012-11-16 13:37 胡满超 阅读(348) |
评论 (0) |
编辑 收藏企业战略规划制定:一个从公司愿景,到经营计划,到各产品线的愿景,及业务计划,再到产品平台以及核心技术需求,并落实到资源规划以及各种激励机制的配套保证的总体流程
战略规划分三个层次:
1、 顶层设计,战略研究层
2、 业务层,产品线战略规划层
3、 支撑层,资源配置管理改进层
产品战略的W型八个步骤
技术型企业组织绩效指标:
1、 生存类能力指标:财务指标,交付指标,
2、 可持续发展能力指标:新业务占收入的比重,核心技术和平台带来的收入占比
3、 核心竞争能力指标:公共模块共享率,人员结构合理性及任职资料提升率,引导客户需求与规划能力
产品线的核心考核指标是组织绩效:对市场成功和财务成功负责
个人绩效:只能产品线有利润,组织绩效成功,才有意义
企业增加利润的路径:
1、 进入新市场
2、 开发新业务
3、 改变商业模式
4、 降低成本:研发的首要目的是提高老产品的利润,其次是开发新产品,新技术
5、 提高价格
企业新业务分类:
1、 聚焦发展,70%
2、 必须突破的业务,20%
3、 布局式业务,10%
笔记原书:
http://www.amazon.cn/%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86-%E6%9E%84%E5%BB%BA%E4%B8%96%E7%95%8C%E4%B8%80%E6%B5%81%E7%9A%84%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86%E4%BD%93%E7%B3%BB-%E5%91%A8%E8%BE%89/dp/B006THMWQS/ref=pd_sim_b_3

posted @
2012-11-13 09:54 胡满超 阅读(341) |
评论 (0) |
编辑 收藏IPD介绍
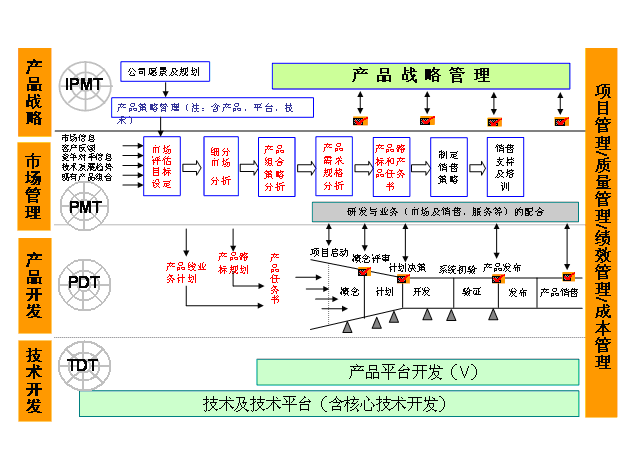
研发的六种产出模式:
1、 基础研究,发明和标准
2、 应用开发,将非成熟的应用技术变成成熟的技术
3、 项目开发,一次性的定制
4、 产品开发,内部共享模块与产品,外部销售的产品,可批量,可重复,可复制生产
5、 解决方案,以产品为核心,为客户做的跨产品或跨领域集成方案
6、 服务和运营,服务、运营、维护获取收益
产品开发货架层次:器件、组件、部件、单机、整机、子系统、系统
产品分类:
1、 内部共享产品:器件、组件、部件
2、 面向细分客户群的产品:部件、单机、整机、子系统(能力强的公司)
3、 解决方案级产品:子系统、系统
技术型企业的商业模式:经营技术、经营产品、经营解决方案、经营客户和服务
技术型企业的商业模式发展和演变五个阶段:
1、 劳动密集型加工
2、 项目生存型
3、 产品扩展型
4、 运营客户型
5、 集成产业链型
产品开发方式:
1、 先开发技术,然后做通用产品,再销售
技术开发->产品开发->形成产品->销售渠道->通用客户需求
缺点:容易被细分市场产品替代,技术一旦落后没有后续产出
2、 客户需求,寻找技术,完成定制
客户需求->营销渠道->确定交付->投入开发->技术突破
缺点:技术开发有风险;一个个项目做,企业很难做大;质量不易保证;人员没有专业发展通道,容易流失;项目越多,管理越难
集成产品开发:
1、 产品开发与技术开发、平台开发分离;
2、 技术和平台开发先行,解决技术突破;
3、 产品开发按细分客户群需求
集成产品开发和技术开发特点:
1、 产品开发:强调基于市场需求和共享平台,对市场和财务的成功负责
2、 技术开发:自己掌握业界成熟的技术,做成货架,供产品开发时共享,以缩短产品开发周期
集成产品开发三种产品形态:
1、 产品大版本V:平台版本
2、 细分客户群版本R:交付给用客户产品,四要素:客户及竞争需求、功能与技术需求、时间、成本
3、 客户定制版本M:在R版本的基础上针对具体客户的个性化版本
产品开发四个范畴:技术开发、市场开发、生产和服务开发、资料包开发
产品开发的步骤:
1、 先进行市场开发,细分客户群,寻找卖点和商业模式,寻找市场和财务成功的要素;
2、 根据产品需求进行分解与分配,进行技术开发
3、 根据技术要求进行产品的可生产性,可安装性,可测试性,可验证性,可服务性开发
4、 根据产品大量进入市场,进行技术资料包,服务资料包和销售工具的开发
企业研发管理发展的五个阶段:
1、 单项目单产品阶段:以项目为核心
2、 多产品、共享产品和货架平台阶段:以产品为核心
3、 以共享为核心面向客户需求阶段:以客户为核心
4、 以产业链为核心的关注利润阶段:以利润为核心
5、 持续改进阶段
集成产品开发管理思想:
1、 产品开发是一项投资
2、 必须强调基于市场的创新
3、 执行技术开发与产品开发分离
4、 对技术进行分类管理,强调核心技术,关键技术的自主开发
5、 跨部分的协同开发,实现全流程全要素(市场、研发、生产、采购、财务协同)的管理
6、 强调CBB和平台建设,强调技术共享
7、 执行异步开发
8、 根据产品的不同层次和技术开发执行不同的结构化开发流程
9、 强调市场和财务成功、核心竞争力的提升是研发绩效考核的重要因素
要实现IPD要以产品线(产品)为核心进行四大重组:财务重组、市场重组、产品重组、组织与流程重组
笔记原书:
http://www.amazon.cn/%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86-%E6%9E%84%E5%BB%BA%E4%B8%96%E7%95%8C%E4%B8%80%E6%B5%81%E7%9A%84%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86%E4%BD%93%E7%B3%BB-%E5%91%A8%E8%BE%89/dp/B006THMWQS/ref=pd_sim_b_3
posted @
2012-11-11 21:42 胡满超 阅读(710) |
评论 (0) |
编辑 收藏IPD集成产品开发管理思想强调:
1、 产品开发是一项投资
2、 必须强调基于市场的创新
3、 执行技术开发与产品开发分离
4、 对技术进行分类管理,强调核心技术,关键技术的自主开发
5、 跨部分的协同开发,实现全流程全要素(市场、研发、生产、采购、财务协同)的管理
6、 强调CBB和平台建设,强调技术共享
7、 执行异步开发
8、 根据产品的不同层次和技术开发执行不同的结构化开发流程
9、 强调市场和财务成功、核心竞争力的提升是研发绩效考核的重要因素
除了IPD的流程之外,华为人结合了华为实践IPD过程的经验与教训,及一些成功的管理实践,做了完整的总结与升华,阅读之后感觉茅塞顿开。
介绍两本书:
http://www.amazon.cn/gp/product/B001ULBY6W 与
与http://www.amazon.cn/%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86-%E6%9E%84%E5%BB%BA%E4%B8%96%E7%95%8C%E4%B8%80%E6%B5%81%E7%9A%84%E4%BA%A7%E5%93%81%E7%A0%94%E5%8F%91%E7%AE%A1%E7%90%86%E4%BD%93%E7%B3%BB-%E5%91%A8%E8%BE%89/dp/B006THMWQS/ref=pd_sim_b_3
我将陆续把自己写的一些笔记与大家分享。
posted @
2012-11-10 14:20 胡满超 阅读(1787) |
评论 (1) |
编辑 收藏总结网上订票系统常见的问题如下:
1、 高峰时段无法登陆,提示在线用户过多
2、 订单提交成功之后,支付环节出了问题,浏览器意外退出,后再登陆,发现登陆不上,无法在规定时间内完成支付,购票失败
3、 订单提交反馈时间过长,热门线路需要等待20分钟甚至更长时间,才能得到反馈
4、 验证码输入总是错误,无法完成验证码验证环节,无法登陆
5、 逢用户高峰,网站反应速度较慢
6、 对多浏览器支持不好,没有IOS,Android应用入口
以上问题多数都是用户体验的问题,用户体验的问题即有票源稀少的原因,更多的是对订票系统使用过程中系统登陆困难,反应迟钝,订单结果反馈太慢,意外退出等问题难以忍受。
本人并非订票系统设计人员,但是通用对订票系统外在的表现大胆猜测一下订票系统的设计。
常见问题原因分析:
问题1,高峰时段无法登陆,提示在线用户过多;
问题4,验证码输入总是错误,无法完成验证码验证环节,无法登陆
无法登陆的问题,其原因显然是前端用于处理WEB连接服务器太少或网络带宽不足所至,为了不让更多的用户一起连接服务器导致服务器较慢,只好拒绝一些用户的登陆请求。使同时在线人数保持在一个上限以内。
验证码输入总是错误的问题,原因也是用于处理WEB连接服务器太少所至,为了防止一些客户端使用“恶意”软件,不断自动登陆的情况,验证码需求由客户端向服务器提交一个验证请求,可以由于服务器响应实在太慢,以至于整个响应速度居然超过了验证码的有效时间。
常见问题:
问题2:订单提交成功之后,支付环节出了问题,浏览器意外退出,后再登陆,发现登陆不上,无法在规定时间内完成支付,购票失败
问题3:订单提交反馈时间过长,热门线路需要等待20分钟甚至更长时间,才能得到反馈
问题5:逢用户高峰,网站反应速度较慢
问题2是一个系统的BUG,但是可以通过一些设计来解决这个问题。
问题3,问题5,可能是由于WEB服务器与逻辑处理服务器在同一台机器上,而导致服务器CPU分配了过多的时间与资源在处理用户请求,在执行逻辑时执行缓慢。
如果数据库也在同一台服务器上,那问题可能更加严重。当然我相信,不在一台服务器上的可能性比较大。
总结以上问题,其解决方案建议如下:
1、 准备更多前端WEB服务器,解决WEB前端的问题没有别的办法,只能加服务器,或者每个省市放一群单独的服务器,根据用户量进行增加,直到响应流畅为止。
2、 可以考虑把逻辑服务器单独分离出来,与WEB服务器分开,WEB服务器只处理WEB请求,逻辑服务器单独运行
3、 把数据库服务器单独分离,并且把火车票票量数据库与用户订票信息数据库放到不同的机器上,由于大量的订票请求会访问火车票票量数据库,并且会有大量订票数据添加到用户订票信息数据库中,在处理添加的逻辑占用了大量的数据库资源,会导致整个系统变慢。如果放到同一台机器上,必然导致响应变慢。把不同性质的数据,放到不同机器、不同的数据系统中,可以合理的分流系统访问量,使系统响应加快,横向扩展更具有弹性。
4、 把支付订票费用放到一个单独的网站进行,订单提交成功后锁票,之后根据订单号可以在另外一个单独的网站上进行单独支付,支付时只要提供订票号就可以,这样做有很多好处:1. 避免了由于支付失败而导致退出浏览器,却由于在线人数过多无法登陆导致订票失败的情况,2. 电话订票也可以在此支付,在火车站机自动售票机器上取票,这样支付方便,也解决了异地付款取票的问题 3. 单独支付会在一定程度上给订票网站减轻访问与处理压力
5、 提供快递火车票服务进行创收,支付成功的火车票可以进行快递,这样即方便订票人也可以给铁道部创收
6、 网站可以根据用户订票信息做一些有针对性网站广告,如旅游、酒店广告等进行创收
7、 开发出更多的手机终端软件,扩大订票系统使用的覆盖面
8、 支持更多的浏览器,而不仅仅是IE
由于本人水平有限,欢迎各个高手批评指正,希望这篇文章能够抛砖引玉,大家一起讨论。
网上的其他类似文章:
http://cloud.it168.com/a2012/0130/1304/000001304533.shtml
posted @
2012-10-15 17:09 胡满超 阅读(2758) |
评论 (7) |
编辑 收藏转自:http://book.douban.com/annotation/19461092/
半个月前在豆瓣上看到了一本新书《数学之美》,评价很高。而因为在半年前看了《什么是数学》就对数学产生浓厚兴趣,但苦于水平不足的我便立马买了一本,希望能对数学多一些了解,并认真阅读起来。 令我意外并欣喜的是,这本书里边的数学内容并不晦涩难懂,而且作者为了讲述数学之美而搭配的一些工程实例都是和我学习并感兴趣的模式识别,目标分类相关算法相关联的。这让我觉得捡到了意外的宝藏。 书中每一个章节都或多或少是作者亲身经历过的,比如世界级教授的小故事,或者Google的搜索引擎原理,又或者是Google的云计算等。作者用其行云流水般的语言将各个知识点像讲故事一样有趣的叙述出来。 这本书着实让我印象深刻,所以我把笔记分享出来,希望更多和我学习研究领域一样的人会喜欢并亲自阅读这本书,并能支持作者。毕竟国内这种书实在是太少了,也希望能有更多领域内的大牛能再写出一些这种书籍来让我们共同提高。1. 因为需要传播信息量的增加,不同的声音并不能完全表达信息,语言便产生了。2. 当文字增加到没有人能完全记住所有文字时,聚类和归类就开始了。例如日代表太阳或者代表一天。3. 聚类会带来歧义性,但上下文可以消除歧义。信息冗余是信息安全的保障。例如罗塞塔石碑上同一信息重复三次。4. 最短编码原理即常用信息短编码,生僻信息长编码。5. 因为文字只是信息的载体而非信息本身,所以翻译是可以实现的。6. 2012,其实是玛雅文明采用二十进制,即四百年是一个太阳纪,而2012年恰巧是当前太阳纪的最后一年,2013年是新的太阳纪的开始,故被误传为世界末日。7. 字母可以看为是一维编码,而汉字可以看为二维编码。8. 基于统计的自然语言处理方法,在数学模型上和通信是相通的,甚至是相同的。9. 让计算机处理自然语言的基本问题就是为自然语言这种上下文相关的特性建立数学模型,即统计语言模型(Statistical Language Modal)。10. 根据大数定理(Law of Large Numbers),只要统计量足够,相对频度就等于概率。11. 二元模型。对于p(w1,w2,…,wn)=p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|w1,w2,…,wn-1)的展开问题,因为p(w3|w1,w2)难计算,p(wn|w1,w2,…,wn-1)更难计算,马尔科夫给出了一个偷懒但是颇为有效的方法,也就是每当遇到这种情况时,就假设任意wi出现的概率只与它前面的wi-1有关,即p(s)=p(w1)p(w2|w1)p(w3|w2)…p(wi|wi-1)…p(wn|wn-1)。现在这个概率就变的简单了。对应的语言模型为2元模型(Bigram Model)。12. *N元模型。wi只与前一个wi-1有关近似的过头了,所以N-1阶马尔科夫假设为p(wi|w1,w2,…,wi-1)=p(wi|wi-N+1,wi-N+2,…,wi-1),对应的语言模型成为N元模型(N-Gram Model)。一元模型就是上下文无关模型,实际应用中更多实用的是三元模型。Google的罗塞塔翻译系统和语言搜索系统实用的是四元模型,存储于500台以上的Google服务器中。13. *卡兹退避法(Katz backoff),对于频率超过一定阈值的词,它们的概率估计就是它们在语料库中的相对频度,对于频率小于这个阈值的词,它们的概率估计就小于他们的相对频度,出现次数越少,频率下调越多。对于未看见的词,也给予一个比较小的概率(即下调得到的频率总和),这样所有词的概率估计都平滑了。这就是卡兹退避法(Katz backoff)。14. 训练数据通常是越多越好,通过平滑过渡的方法可以解决零概率和很小概率的问题,毕竟在数据量多的时候概率模型的参数可以估计的比较准确。15. 利用统计语言模型进行分词,即最好的分词方法应该保证分完词后这个句子出现的概率最大。根据不同应用,汉语分词的颗粒度大小应该不同。16. 符合马尔科夫假设(各个状态st的概率分布只与它前一个状态st-1有关)的随即过程即成为马尔科夫过程,也称为马尔科夫链。17. 隐含马尔科夫模型是马尔科夫链的扩展,任意时刻t的状态st是不可见的,所以观察者没法通过观察到一个状态序列s1,s2,s3,…,sT来推测转移概率等参数。但是隐马尔科夫模型在每个时刻t会输出一个符号ot,而且ot和st相关且仅和ot相关。这个被称为独立输出假设。其中隐含的状态s1,s2,s3,…是一个典型的马尔科夫链。18. 隐含马尔科夫模型是机器学习主要工具之一,和几乎所有机器学习的模型工具一样,它需要一个训练算法(鲍姆-韦尔奇算法)和使用时的解码算法(维特比算法)。掌握了这两类算法,就基本上可以使用隐含马尔科夫模型这个工具了。19. 鲍姆-韦尔奇算法(Baum-Welch Algorithm),首先找到一组能够产生输出序列O的模型参数,这个初始模型成为Mtheta0,需要在此基础上找到一个更好的模型,假定不但可以算出这个模型产生O的概率P(O|Mtheta0),而且能够找到这个模型产生O的所有可能的路径以及这些路径的概率。并算出一组新的模型参数theta1,从Mtheta0到Mtheta1的过程称为一次迭代。接下来从Mtheta1出发寻找更好的模型Mtheta2,并一直找下去,直到模型的质量没有明显提高为止。这样一直估计(Expectation)新的模型参数,使得输出的概率达到最大化(Maximization)的过程被称为期望值最大化(Expectation-Maximization)简称EM过程。EM过程能保证一定能收敛到一个局部最优点,但不能保证找到全局最优点。因此,在一些自然语言处理的应用中,这种无监督的鲍姆-韦尔奇算法训练处的模型比有监督的训练得到的模型效果略差。20. 熵,信息熵的定义为H(X)=-SumP(x)logP(x),变量的不确定性越大,熵也越大。21. 一个事物内部会存在随机性,也就是不确定性,假定为U,而从外部消除这个不确定性唯一的办法是引入信息I,而需要引入的信息量取决于这个不确定性的大小,即I>U才行。当I<U时,这些信息可以消除一部分不确定性,U'=U-I。反之,如果没有信息,任何公示或者数字的游戏都无法排除不确定性。22. 信息的作用在于消除不确定性。23. 互信息,对两个随机事件相关性的量化度量,即随机事件X的不确定性或者说熵H(X),在知道随机事件Y条件下的不确定性,或者说条件熵H(X|Y)之间的差异,即I(X;Y)=H(X)-H(X|Y)。所谓两个事件相关性的量化度量,即在了解了其中一个Y的前提下,对消除另一个X不确定性所提供的信息量。24. 相对熵(Kullback-Leibler Divergence)也叫交叉熵,对两个完全相同的函数,他们的相对熵为零;相对熵越大,两个函数差异越大,反之,相对熵越小,两个函数差异越小;对于概率分布或者概率密度函数,如果取值均大于零,相对熵可以度量两个随机分布的差异性。25. 弗里德里克·贾里尼克(Frederek Jelinek)是自然语言处理真谛的先驱者。26. 技术分为术和道两种,具体的做事方法是术,做事的原理和原则是道。术会从独门绝技到普及再到落伍,追求术的人会很辛苦,只有掌握了道的本质和精髓才能永远游刃有余。27. 真理在形式上从来是简单的,而不是复杂和含混的。28. 搜索引擎不过是一张大表,表的每一行对应一个关键字,而每一个关键字后面跟着一组数字,是包含该关键词的文献序号。但当索引变的非常大的时候,这些索引需要通过分布式的方式存储到不同的服务器上。29. 网络爬虫(Web Crawlers),图论的遍历算法和搜索引擎的关系。互联网虽然复杂,但是说穿了其实就是一张大图……可以把每一个网页当做一个节点,把那些超链接当做连接网页的弧。有了超链接,可以从任何一个网页出发,用图的遍历算法,自动访问到每一个网页并且把他们存储起来。完成这个功能的程序叫网络爬虫。30. 哥尼斯堡七桥,如果一个图能从一个顶点出发,每条边不重复的遍历一遍回到这个顶点,那么每一个顶点的度必须为偶数。31. 构建网络爬虫的工程要点:1.用BFS(广度优先搜索)还是DFS(深度优先搜索),一般是先下载完一个网站,再进入下一个网站,即BFS的成分多一些。2.页面的分析和URL的提取,如果有些网页明明存在,但搜索引擎并没有收录,可能的原因之一是网络爬虫中的解析程序没能成功解析网页中不规范的脚本程序。3.记录哪些网页已经下载过的URL表,可以用哈希表。最终,好的方法一般都采用了这样两个技术:首先明确每台下载服务器的分工,也就是在调度时,一看到某个URL就知道要交给哪台服务器去下载,这样就避免了很多服务器对同一个URL做出是否需要下载的判断。然后,在明确分工的基础上,判断URL是否下载就可以批处理了,比如每次向哈希表(一组独立的服务器)发送一大批询问,或者每次更新一大批哈希表的内容,这样通信的次数就大大减少了。32. PageRank衡量网页质量的核心思想,在互联网上,如果一个网页被很多其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。同时,对于来自不同网页的链接区别对待,因为网页排名高的那些网页的链接更可靠,于是要给这些链接比较大的权重。33. TF-IDF(Term Frequency / Inverse Document Frequency) ,关键词频率-逆文本频率值,其中,TF为某个网页上出现关键词的频率,IDF为假定一个关键词w在Dw个网页中出现过,那么Dw越大,w的权重越小,反之亦然,公式为log(D/Dw)。1.一个词预测主题的能力越强,权重越大,反之,权重越小。2.停止词的权重为零。34. 动态规划(Dynamic Programming)的原理,将一个寻找全程最优的问题分解成一个个寻找局部最优的小问题。35. 一个好的算法应该像轻武器中最有名的AK-47冲锋枪那样:简单、有效、可靠性好而且容易读懂(易操作)而不应该故弄玄虚。选择简单方案可以容易解释每个步骤和方法背后的道理,这样不仅便于出问题时的查错,也容易找到今后改进的目标。36. 在实际的分类中,可以先进行奇异值分解(得到分类结果略显粗糙但能较快得到结果),在粗分类结果的基础上,利用计算向量余弦的方法(对范围内的分类做两两计算),在粗分类结果的基础上,进行几次迭代,得到比较精确的结果。37. 奇异值分解(Singular Value Decomposition),在需要用一个大矩阵A来描述成千上万文章和几十上百万词的关联性时,计算量非常大,可以将A奇异值分解为X、B和Y三个矩阵,Amn=Xmm*Bmn*Ynn,X表示词和词类的相关性,Y表示文本和主题的相关性,B表示词类和主题的相关性,其中B对角线上的元素很多值相对其他的非常小,或者为零,可以省略。对关联矩阵A进行一次奇异值分解,就可以同时完成近义词分类和文章的分类,同时能得到每个主题和每个词义类之间的相关性,这个结果非常漂亮。38. 信息指纹。如果能够找到一种函数,将5000亿网址随即地映射到128位二进制,也就是16字节的整数空间,就称这16字节的随机数做该网址的信息指纹。信息指纹可以理解为将一段信息映射到一个多维二进制空间中的一个点,只要这个随即函数做的好,那么不同信息对应的点不会重合,因此这个二进制的数字就变成了原来信息所具有的独一无二的指纹。39. 判断两个集合是否相同,最笨的方法是这个集合中的元素一一比较,复杂度O(squareN),稍好的是将元素排序后顺序比较,复杂度O(NlogN),最完美的方法是计算这两个集合的指纹,然后直接进行比较,计算复杂度O(N)。40. 伪随机数产生器算法(Pseudo-Random Number Generator,PRNG),这是产生信息指纹的关键算法,通过他可以将任意长的整数转换成特定长度的伪随机数。最早的PRNG是将一个数的平方掐头去尾取中间,当然这种方法不是很随即,现在常用的是梅森旋转算法(Mersenne Twister)。41. 在互联网上加密要使用基于加密的伪随机数产生器(Cryptography Secure Pseudo-Random Number Generator,CSPRNG),常用的算法有MD5或者SHA-1等标准,可以将不定长的信息变成定长的128位或者160位二进制随机数。42. 最大熵模型(Maximum Entropy)的原理就是保留全部的不确定性,将风险降到最小。最大熵原理指出,需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小。I.Csiszar证明,对任何一组不自相矛盾的信息,这个最大熵模型不仅存在,而且是唯一的,此外,他们都有同一个非常简单的形式-指数函数。43. 通用迭代算法(Generalized Iterative Scaling,GIS)是最原始的最大熵模型的训练方法。1.假定第零次迭代的初始模型为等概率的均匀分布。2.用第N次迭代的模型来估算每种信息特征在训练数据中的分布。如果超过了实际的,就把相应的模型参数变小,反之变大。3.重复步骤2直至收敛。这是一种典型的期望值最大化(Expectation Maximization,EM)算法。IIS(Improved Iterative Scaling)比GIS缩短了一到两个数量级。44. 布隆过滤器实际上是一个很长的二进制向量和一系列随机映射的函数。45. 贝叶斯网络从数学的层面讲是一个加权的有向图,是马尔科夫链的扩展,而从知识论的层面看,贝叶斯网络克服了马尔科夫那种机械的线性的约束,它可以把任何有关联的事件统一到它的框架下面。在网络中,假定马尔科夫假设成立,即每一个状态只与和它直接相连的状态有关,而和他间接相连的状态没有直接关系,那么它就是贝叶斯网络。在网络中每个节点概率的计算,都可以用贝叶斯公式来进行,贝叶斯网络也因此得名。由于网络的每个弧都有一个可信度,贝叶斯网络也被称作信念网络(Belief Networks)。46. 条件随机场是计算联合概率分布的有效模型。在一个隐含马尔科夫模型中,以x1,x2,...,xn表示观测值序列,以y1,y2,...,yn表示隐含的状态序列,那么xi只取决于产生它们的状态yi,和前后的状态yi-1和yi+1都无关。显然很多应用里观察值xi可能和前后的状态都有关,如果把xi和yi-1,yi,yi+1都考虑进来,这样的模型就是条件随机场。它是一种特殊的概率图模型(Probablistic Graph Model),它的特殊性在于,变量之间要遵守马尔科夫假设,即每个状态的转移概率只取决于相邻的状态,这一点和另一种概率图模型贝叶斯网络相同,它们的不同之处在于条件随机场是无向图,而贝叶斯网络是有向图。47. 维特比算法(Viterbi Algoritm)是一个特殊但应用最广的动态规划算法,利用动态规划,可以解决任何一个图中的最短路径问题。它之所以重要,是因为凡是使用隐含马尔科夫模型描述的问题都可以用它来解码。1.从点S出发,对于第一个状态x1的各个节点,不妨假定有n1个,计算出S到他们的距离d(S,x1i),其中x1i代表任意状态1的节点。因为只有一步,所以这些距离都是S到他们各自的最短距离。2.对于第二个状态x2的所有节点,要计算出从S到他们的最短距离。d(S,x2i)=min_I=1,n1_d(S,x1j)+d(x1j,x2i),由于j有n1种可能性,需要一一计算,然后找到最小值。这样对于第二个状态的每个节点,需要n1次乘法计算。假定这个状态有n2个节点,把S这些节点的距离都算一遍,就有O(n1*n2)次运算。3.按照上述方法从第二个状态走到第三个状态一直走到最后一个状态,这样就得到整个网络从头到尾的最短路径。48. 扩频传输(Spread-Spectrum Transmission)和固定频率的传输相比,有三点明显的好处:1.抗干扰能力强。2.信号能量非常低,很难获取。3.扩频传输利用带宽更充分。49. Google针对云计算给出的解决工具是MapReduce,其根本原理就是计算机算法上常见的分治算法(Divide-and-Conquer)。将一个大任务拆分成小的子任务,并完成子任务的计算,这个过程叫Map,将中间结果合并成最终结果,这个过程叫Reduce。50. 逻辑回归模型(Logistic Regression)是将一个事件出现的概率适应到一条逻辑曲线(Logistic Curve)上。典型的逻辑回归函数:f(z)=e`z/e`z+1=1/1+e`-z。逻辑曲线是一条S型曲线,其特点是开始变化快,逐渐减慢,最后饱和。逻辑自回归的好处是它的变量范围从负无穷到正无穷,而值域范围限制在0-1之间。因为值域的范围在0-1之间,这样逻辑回归函数就可以和一个概率分别联系起来了。因为自变量范围在负无穷到正无穷之间,它就可以把信号组合起来,不论组合成多大或者多小的值,最后依然能得到一个概率分布。51. 期望最大化算法(Expectation Maximization Algorithm),根据现有的模型,计算各个观测数据输入到模型中的计算结果,这个过程称为期望值计算过程(Expectation),或E过程;接下来,重新计算模型参数,以最大化期望值,这个过程称为最大化的过程(Maximization),或M过程。这一类算法都称为EM算法,比如隐含马尔科夫模型的训练方法Baum-Welch算法,以及最大熵模型的训练方法GIS算法。
posted @
2012-09-18 15:04 胡满超 阅读(452) |
评论 (0) |
编辑 收藏posted @
2012-09-07 13:15 胡满超 阅读(349) |
评论 (0) |
编辑 收藏在Windows平台做开发肯定会接触到UI程序的编写,以MFC的UI开发为例,可以开发单文档,多文档,对话框等形式的应用。写一个UI程序容易,写好却不是一件简单的事情。在整个代码结构的清晰性与可维护性方面需要多加注意。写好UI程序需求注意以下几点:
1、围绕数据编程与不是围绕UI编程
当我们拿到需求最先接触到的就是UI的设计,也许是美工画的,也许是设计草图。工程师在具体设计的时候容易受UI的影响,或者干脆从UI开始编程。
这是一个错误的编程习惯,无论UI如何展现与交互,最终都应该围绕数据编程。拿到需求后,应该先思考和推敲数据的设计与流转,UI不过就是数据的一种展现形式而已。
2、做好UI与逻辑的解耦
UI的编程会涉及到许多控件的操作,消息的处理,不知不觉,一个UI类的代码会越写越大,以至于一段时间以后,浏览和梳理都会变得不太方便。
在UI类里,除了与UI本身的操作有关的代码以外,任何逻辑代码都应该与此解耦,并根据具体情况进行封装调用。如果一个控件关联了太多数据操作,应该把这些操作封装到控件的继承类中,把一类代码进行集中管理和维护。
上述问题,在程序写作的初期还不太明显,随着代码逐渐膨胀,会越会越让人难以忍受。
3、数据单向依赖,单向更新
UI围绕的数据进行展现与更新,在这个过程中,所以对数据的操作应该进行封装,而不是散落在UI程序在各个角落,数据的更新、获取和UI传递消息时,应该单向操作,如果出现循环处理的情况,在以后维护调试的BUG的过程中会变得比较困难,导致维护效率下降。
posted @
2012-08-31 17:00 胡满超 阅读(1041) |
评论 (0) |
编辑 收藏posted @
2012-03-23 17:16 胡满超 阅读(6057) |
评论 (1) |
编辑 收藏在 Windows x64 上共有2种查看方式。一种用于 32-bit 应用程序,另一种用于 x64 应用程序。默认情况下,32-bit 应用程序运行在 x64 系统的 WOW64 模式下时,只允许使用 32-bit 查看方式。使用
SetRegView 64 将允许安装程序在 x64 中访问注册表键值。恢复访问32位注册表使用
SetRegView 32。
它将影响
DeleteRegKey,
DeleteRegValue,
EnumRegKey,
EnumRegValue,
ReadRegDWORD,
ReadRegStr,
WriteRegBin,
WriteRegDWORD,
WriteRegStr 和
WriteRegExpandStr。
posted @
2012-03-09 10:29 胡满超 阅读(1573) |
评论 (0) |
编辑 收藏转自:http://www.ibm.com/developerworks/cn/linux/l-cn-valgrind/
Valgrind 概述
体系结构
Valgrind是一套Linux下,开放源代码(GPL V2)的仿真调试工具的集合。Valgrind由内核(core)以及基于内核的其他调试工具组成。内核类似于一个框架(framework),它模拟了 一个CPU环境,并提供服务给其他工具;而其他工具则类似于插件 (plug-in),利用内核提供的服务完成各种特定的内存调试任务。Valgrind的体系结构如下图所示:
图 1 Valgrind 体系结构
Valgrind包括如下一些工具:
- Memcheck。这是valgrind应用最广泛的工具,一个重量级的内存检查器,能够发现开发中绝大多数内存错误使用情况,比如:使用未初始化的内存,使用已经释放了的内存,内存访问越界等。这也是本文将重点介绍的部分。
- Callgrind。它主要用来检查程序中函数调用过程中出现的问题。
- Cachegrind。它主要用来检查程序中缓存使用出现的问题。
- Helgrind。它主要用来检查多线程程序中出现的竞争问题。
- Massif。它主要用来检查程序中堆栈使用中出现的问题。
- Extension。可以利用core提供的功能,自己编写特定的内存调试工具。
Linux 程序内存空间布局
要发现Linux下的内存问题,首先一定要知道在Linux下,内存是如何被分配的?下图展示了一个典型的Linux C程序内存空间布局:
图 2: 典型内存空间布局
一个典型的Linux C程序内存空间由如下几部分组成:
- 代码段(.text)。这里存放的是CPU要执行的指令。代码段是可共享的,相同的代码在内存中只会有一个拷贝,同时这个段是只读的,防止程序由于错误而修改自身的指令。
- 初始化数据段(.data)。这里存放的是程序中需要明确赋初始值的变量,例如位于所有函数之外的全局变量:int val=100。需要强调的是,以上两段都是位于程序的可执行文件中,内核在调用exec函数启动该程序时从源程序文件中读入。
- 未初始化数据段(.bss)。位于这一段中的数据,内核在执行该程序前,将其初始化为0或者null。例如出现在任何函数之外的全局变量:int sum;
- 堆(Heap)。这个段用于在程序中进行动态内存申请,例如经常用到的malloc,new系列函数就是从这个段中申请内存。
- 栈(Stack)。函数中的局部变量以及在函数调用过程中产生的临时变量都保存在此段中。
内存检查原理
Memcheck检测内存问题的原理如下图所示:
图 3 内存检查原理
Memcheck 能够检测出内存问题,关键在于其建立了两个全局表。
- Valid-Value 表:
对于进程的整个地址空间中的每一个字节(byte),都有与之对应的 8 个 bits;对于 CPU 的每个寄存器,也有一个与之对应的 bit 向量。这些 bits 负责记录该字节或者寄存器值是否具有有效的、已初始化的值。
- Valid-Address 表
对于进程整个地址空间中的每一个字节(byte),还有与之对应的 1 个 bit,负责记录该地址是否能够被读写。
检测原理:
- 当要读写内存中某个字节时,首先检查这个字节对应的 A bit。如果该A bit显示该位置是无效位置,memcheck 则报告读写错误。
- 内核(core)类似于一个虚拟的 CPU 环境,这样当内存中的某个字节被加载到真实的 CPU 中时,该字节对应的 V bit 也被加载到虚拟的 CPU 环境中。一旦寄存器中的值,被用来产生内存地址,或者该值能够影响程序输出,则 memcheck 会检查对应的V bits,如果该值尚未初始化,则会报告使用未初始化内存错误。
回页首
Valgrind 使用
第一步:准备好程序
为了使valgrind发现的错误更精确,如能够定位到源代码行,建议在编译时加上-g参数,编译优化选项请选择O0,虽然这会降低程序的执行效率。
这里用到的示例程序文件名为:sample.c(如下所示),选用的编译器为gcc。
生成可执行程序 gcc –g –O0 sample.c –o sample
清单 1
第二步:在valgrind下,运行可执行程序。
利用valgrind调试内存问题,不需要重新编译源程序,它的输入就是二进制的可执行程序。调用Valgrind的通用格式是:valgrind [valgrind-options] your-prog [your-prog-options]
Valgrind 的参数分为两类,一类是 core 的参数,它对所有的工具都适用;另外一类就是具体某个工具如 memcheck 的参数。Valgrind 默认的工具就是 memcheck,也可以通过“--tool=tool name”指定其他的工具。Valgrind 提供了大量的参数满足你特定的调试需求,具体可参考其用户手册。
这个例子将使用 memcheck,于是可以输入命令入下:valgrind <Path>/sample.
第三步:分析 valgrind 的输出信息。
以下是运行上述命令后的输出。
清单 2
- 左边显示类似行号的数字(32372)表示的是 Process ID。
- 最上面的红色方框表示的是 valgrind 的版本信息。
- 中间的红色方框表示 valgrind 通过运行被测试程序,发现的内存问题。通过阅读这些信息,可以发现:
- 这是一个对内存的非法写操作,非法写操作的内存是4 bytes。
- 发生错误时的函数堆栈,以及具体的源代码行号。
- 非法写操作的具体地址空间。
- 最下面的红色方框是对发现的内存问题和内存泄露问题的总结。内存泄露的大小(40 bytes)也能够被检测出来。
示例程序显然有两个问题,一是fun函数中动态申请的堆内存没有释放;二是对堆内存的访问越界。这两个问题均被valgrind发现。
回页首
利用Memcheck发现常见的内存问题
在Linux平台开发应用程序时,最常遇见的问题就是错误的使用内存,我们总结了常见了内存错误使用情况,并说明了如何用valgrind将其检测出来。
使用未初始化的内存
问题分析:
对于位于程序中不同段的变量,其初始值是不同的,全局变量和静态变量初始值为0,而局部变量和动态申请的变量,其初始值为随机值。如果程序使用了为随机值的变量,那么程序的行为就变得不可预期。
下面的程序就是一种常见的,使用了未初始化的变量的情况。数组a是局部变量,其初始值为随机值,而在初始化时并没有给其所有数组成员初始化,如此在接下来使用这个数组时就潜在有内存问题。
清单 3
结果分析:
假设这个文件名为:badloop.c,生成的可执行程序为badloop。用memcheck对其进行测试,输出如下。
清单 4
输出结果显示,在该程序第11行中,程序的跳转依赖于一个未初始化的变量。准确的发现了上述程序中存在的问题。
内存读写越界
问题分析:
这种情况是指:访问了你不应该/没有权限访问的内存地址空间,比如访问数组时越界;对动态内存访问时超出了申请的内存大小范围。下面的程序就是一个 典型的数组越界问题。pt是一个局部数组变量,其大小为4,p初始指向pt数组的起始地址,但在对p循环叠加后,p超出了pt数组的范围,如果此时再对p 进行写操作,那么后果将不可预期。
清单 5
结果分析:
假设这个文件名为badacc.cpp,生成的可执行程序为badacc,用memcheck对其进行测试,输出如下。
清单 6
输出结果显示,在该程序的第15行,进行了非法的写操作;在第16行,进行了非法读操作。准确地发现了上述问题。
内存覆盖
问题分析:
C 语言的强大和可怕之处在于其可以直接操作内存,C 标准库中提供了大量这样的函数,比如 strcpy, strncpy, memcpy, strcat 等,这些函数有一个共同的特点就是需要设置源地址 (src),和目标地址(dst),src 和 dst 指向的地址不能发生重叠,否则结果将不可预期。
下面就是一个 src 和 dst 发生重叠的例子。在 15 与 17 行中,src 和 dst 所指向的地址相差 20,但指定的拷贝长度却是 21,这样就会把之前的拷贝值覆盖。第 24 行程序类似,src(x+20) 与 dst(x) 所指向的地址相差 20,但 dst 的长度却为 21,这样也会发生内存覆盖。
清单 7
结果分析:
假设这个文件名为 badlap.cpp,生成的可执行程序为 badlap,用 memcheck 对其进行测试,输出如下。
清单 8
输出结果显示上述程序中第15,17,24行,源地址和目标地址设置出现重叠。准确的发现了上述问题。
动态内存管理错误
问题分析:
常见的内存分配方式分三种:静态存储,栈上分配,堆上分配。全局变量属于静态存储,它们是在编译时就被分配了存储空间,函数内的局部变量属于栈上分 配,而最灵活的内存使用方式当属堆上分配,也叫做内存动态分配了。常用的内存动态分配函数包括:malloc, alloc, realloc, new等,动态释放函数包括free, delete。
一旦成功申请了动态内存,我们就需要自己对其进行内存管理,而这又是最容易犯错误的。下面的一段程序,就包括了内存动态管理中常见的错误。
清单 9
常见的内存动态管理错误包括:
由于 C++ 兼容 C,而 C 与 C++ 的内存申请和释放函数是不同的,因此在 C++ 程序中,就有两套动态内存管理函数。一条不变的规则就是采用 C 方式申请的内存就用 C 方式释放;用 C++ 方式申请的内存,用 C++ 方式释放。也就是用 malloc/alloc/realloc 方式申请的内存,用 free 释放;用 new 方式申请的内存用 delete 释放。在上述程序中,用 malloc 方式申请了内存却用 delete 来释放,虽然这在很多情况下不会有问题,但这绝对是潜在的问题。
申请了多少内存,在使用完成后就要释放多少。如果没有释放,或者少释放了就是内存泄露;多释放了也会产生问题。上述程序中,指针p和pt指向的是同一块内存,却被先后释放两次。
本质上说,系统会在堆上维护一个动态内存链表,如果被释放,就意味着该块内存可以继续被分配给其他部分,如果内存被释放后再访问,就可能覆盖其他部分的信息,这是一种严重的错误,上述程序第16行中就在释放后仍然写这块内存。
结果分析:
假设这个文件名为badmac.cpp,生成的可执行程序为badmac,用memcheck对其进行测试,输出如下。
清单 10
输出结果显示,第14行分配和释放函数不一致;第16行发生非法写操作,也就是往释放后的内存地址写值;第17行释放内存函数无效。准确地发现了上述三个问题。
内存泄露
问题描述:
内存泄露(Memory leak)指的是,在程序中动态申请的内存,在使用完后既没有释放,又无法被程序的其他部分访问。内存泄露是在开发大型程序中最令人头疼的问题,以至于有 人说,内存泄露是无法避免的。其实不然,防止内存泄露要从良好的编程习惯做起,另外重要的一点就是要加强单元测试(Unit Test),而memcheck就是这样一款优秀的工具。
下面是一个比较典型的内存泄露案例。main函数调用了mk函数生成树结点,可是在调用完成之后,却没有相应的函数:nodefr释放内存,这样内存中的这个树结构就无法被其他部分访问,造成了内存泄露。
在一个单独的函数中,每个人的内存泄露意识都是比较强的。但很多情况下,我们都会对malloc/free 或new/delete做一些包装,以符合我们特定的需要,无法做到在一个函数中既使用又释放。这个例子也说明了内存泄露最容易发生的地方:即两个部分的 接口部分,一个函数申请内存,一个函数释放内存。并且这些函数由不同的人开发、使用,这样造成内存泄露的可能性就比较大了。这需要养成良好的单元测试习 惯,将内存泄露消灭在初始阶段。
清单 11 清单 11.2
清单 11.2 清单 11.3
清单 11.3
结果分析:
假设上述文件名位tree.h, tree.cpp, badleak.cpp,生成的可执行程序为badleak,用memcheck对其进行测试,输出如下。
清单 12
该示例程序是生成一棵树的过程,每个树节点的大小为12(考虑内存对齐),共8个节点。从上述输出可以看出,所有的内存泄露都被发现。 Memcheck将内存泄露分为两种,一种是可能的内存泄露(Possibly lost),另外一种是确定的内存泄露(Definitely lost)。Possibly lost 是指仍然存在某个指针能够访问某块内存,但该指针指向的已经不是该内存首地址。Definitely lost 是指已经不能够访问这块内存。而Definitely lost又分为两种:直接的(direct)和间接的(indirect)。直接和间接的区别就是,直接是没有任何指针指向该内存,间接是指指向该内存的 指针都位于内存泄露处。在上述的例子中,根节点是directly lost,而其他节点是indirectly lost。
回页首
总结
本文介绍了valgrind的体系结构,并重点介绍了其应用最广泛的工具:memcheck。阐述了memcheck发现内存问题的基本原理,基本 使用方法,以及利用memcheck如何发现目前开发中最广泛的五大类内存问题。在项目中尽早的发现内存问题,能够极大地提高开发效率,valgrind 就是能够帮助你实现这一目标的出色工具。
参考资料
关于作者
杨经,他的技术兴趣包括自动化测试与linux系统管理。目前是IBM中国系统与技术实验室(CSTL)的软件工程师,从事中小型企业(SME)服务器的测试工作,可以通过cdlyangj@cn.ibm.com与他联系。
posted @
2011-12-30 14:24 胡满超 阅读(329) |
评论 (0) |
编辑 收藏
新建一个DEF文件(右键Project->Add->New Item->.def)
加入
EXPORTS
fn_function @ 1
重新编译就OK了
参考链接:
http://blog.csdn.net/cglover/article/details/1621685
posted @
2011-11-21 17:45 胡满超 阅读(973) |
评论 (0) |
编辑 收藏
Set objshell = CreateObject("wscript.shell")
strDomainDnsName = LCase(objshell.ExpandEnvironmentStrings("%USERDNSDOMAIN%"))
If strDomainDnsName = "%USERDNSDOMAIN%" Then
WScript.Echo "workgroup"
Else
WScript.Echo "Domain"
End if
本文出自 “okhelper” 博客,请务必保留此出处http://okhelper.blog.51cto.com/313500/197249
注意:下面的链接提供了7种方法
http://www.robvanderwoude.com/vbstech_network_names_domain.php
| Environment Variable |
|---|
| VBScript Code: |
Set wshShell = WScript.CreateObject( "WScript.Shell" )
strUserDomain = wshShell.ExpandEnvironmentStrings( "%USERDOMAIN%" )
WScript.Echo "User Domain: " & strUserDomain |
| Requirements: |
| Windows version: | NT 4, 2000, XP, Server 2003, Vista or Server 2008 |
| Network: | Stand-alone, workgroup, NT domain, or AD |
| Client software: | N/A |
| Script Engine: | WSH |
| Summarized: | Works in Windows NT 4 or later, *.vbs with CSCRIPT.EXE or WSCRIPT.EXE only.
Doesn't work in Windows 95, 98 or ME, nor in Internet Explorer (HTAs). |
| |
| [Back to the top of this page] |
| |
| WshNetwork |
| VBScript Code: |
Set wshNetwork = WScript.CreateObject( "WScript.Network" )
strUserDomain = wshNetwork.UserDomain
WScript.Echo "User Domain: " & strUserDomain |
| Requirements: |
| Windows version: | Windows 98, ME, NT 4, 2000, XP, Server 2003, Vista, Server 2008 |
| Network: | Stand-alone, workgroup, NT domain, or AD |
| Client software: | Windows Script 5.6 for Windows 98, ME, and NT 4 (no longer available for download?) |
| Script Engine: | WSH |
| Summarized: | Works in Windows 98 or later, *.vbs with CSCRIPT.EXE or WSCRIPT.EXE only.
Doesn't work in Windows 95, nor in Internet Explorer (HTAs). |
| |
| [Back to the top of this page] |
| |
| ADSI (WinNTSystemInfo) |
| VBScript Code: |
Set objSysInfo = CreateObject( "WinNTSystemInfo" )
strUserDomain = objSysInfo.DomainName
WScript.Echo "User Domain: " & strUserDomain |
| Requirements: |
| Windows version: | 2000, XP, Server 2003, Vista or Server 2008 (95, 98, ME, NT 4 with Active Directory client extension) |
| Network: | Stand-alone, workgroup, NT domain, or AD |
| Client software: | Active Directory client extension for Windows 95, 98, ME or NT 4 |
| Script Engine: | any |
| Summarized: | Can work in any Windows version, but Active Directory client extension is required for Windows 95, 98, ME or NT 4.
Can be used in *.vbs with CSCRIPT.EXE or WSCRIPT.EXE, as well as in HTAs. |
| |
| [Back to the top of this page] |
| |
| ADSI (ADSystemInfo) |
| VBScript Code: |
Set objSysInfo = CreateObject( "ADSystemInfo" )
strUserDomain = objSysInfo.DomainName
WScript.Echo "User Domain: " & strUserDomain |
| Requirements: |
| Windows version: | 2000, XP, Server 2003, Vista or Server 2008 (95, 98, ME, NT 4 with Active Directory client extension) |
| Network: | Only AD domain members |
| Client software: | Active Directory client extension for Windows 95, 98, ME or NT 4 |
| Script Engine: | any |
| Summarized: | For AD domain members only.
Can work in any Windows version, but Active Directory client extension is required for Windows 95, 98, ME or NT 4 SP4.
Can be used in *.vbs with CSCRIPT.EXE or WSCRIPT.EXE, as well as in HTAs.
Doesn't work on stand-alones, workgroup members or members of NT domains. |
| |
| [Back to the top of this page] |
| |
| WMI (Win32_ComputerSystem) |
| VBScript Code: |
Set objWMISvc = GetObject( "winmgmts:\\.\root\cimv2" )
Set colItems = objWMISvc.ExecQuery( "Select * from Win32_ComputerSystem", , 48 )
For Each objItem in colItems
strComputerDomain = objItem.Domain
If objItem.PartOfDomain Then
WScript.Echo "Computer Domain: " & strComputerDomain
Else
WScript.Echo "Workgroup: " & strComputerDomain
End If
Next |
| Requirements: |
| Windows version: | XP, Server 2003, Vista or Server 2008 |
| Network: | Stand-alone, workgroup, NT domain, or AD |
| Client software: | N/A |
| Script Engine: | any |
| Summarized: | Works in Windows XP and later.
Can be used in *.vbs with CSCRIPT.EXE or WSCRIPT.EXE, as well as in HTAs. |
| |
| [Back to the top of this page] |
| |
| WMI (Win32_NTDomain) |
| VBScript Code: |
Set objWMISvc = GetObject( "winmgmts:\\.\root\cimv2" )
Set colItems = objWMISvc.ExecQuery( "Select * from Win32_NTDomain", , 48 )
For Each objItem in colItems
strComputerDomain = objItem.DomainName
WScript.Echo "Computer Domain: " & strComputerDomain
Next |
| Requirements: |
| Windows version: | XP, Server 2003, Vista or Server 2008 |
| Network: | NT domain, or AD |
| Client software: | N/A |
| Script Engine: | any |
| Summarized: | Will work only on AD or NT domain members running Windows XP or later.
Can be used in *.vbs with CSCRIPT.EXE or WSCRIPT.EXE, as well as in HTAs.
Doesn't work in Windows 95, 98, ME, NT 4, or 2000.
Doesn't work on stand-alones or workgroup members. |
| |
| [Back to the top of this page] |
| |
| System Scripting Runtime |
| VBScript Code: |
Set objIP = CreateObject( "SScripting.IPNetwork" )
strComputerDomain = objIP.Domain
WScript.Echo "Computer Domain: " & strComputerDomain |
| Requirements: |
| Windows version: | any |
| Network: | TCP/IP |
| Client software: | System Scripting Runtime |
| Script Engine: | any |
| Summarized: | Works in any Windows version with System Scripting Runtime is installed, with any script engine. |
posted @
2011-09-26 10:09 胡满超 阅读(756) |
评论 (0) |
编辑 收藏
摘要: 转自:http://www.cnblogs.com/k-eckel/articles/188489.html深入分析MFC文档视图结构(项目实践) k_eckel:http://www.mscenter.edu.cn/blog/k_eckel 文档视图结构(Document/View Architecture)是MFC的精髓...
阅读全文
posted @
2011-08-03 11:13 胡满超 阅读(1512) |
评论 (0) |
编辑 收藏