|
|
Stool - Easily switch VPN server for Mac 发布
主要功能:
1.方便管理大量VPN服务器和账户
2.批量检测VPN服务器速度
3.方便的切换VPN连接,并自动监测VPN连接状态.
4.支持L2TP和PPTP.
完全免费,欢迎大家使用.
下一步:计划加入状态栏支持.
截图:
weak table是什么意思,建议不要看中文翻译的,我以前看了半天还是没懂啥子意思. lua 手册原文是这样解释的: A weak table is a table whose elements are weak references. A weak reference is ignored by the garbage collector. In other words, if the only references to an object are weak references, then the garbage collector will collect this object. A weak table can have weak keys, weak values, or both. A table with weak keys allows the collection of its keys, but prevents the collection of its values. A table with both weak keys and weak values allows the collection of both keys and values. In any case, if either the key or the value is collected, the whole pair is removed from the table. The weakness of a table is controlled by the __mode field of its metatable. If the __mode field is a string containing the character 'k', the keys in the table are weak. If __mode contains 'v', the values in the table are weak. After you use a table as a metatable, you should not change the value of its __mode field. Otherwise, the weak behavior of the tables controlled by this metatable is undefined. 在lua中,像table,userdata,function这些类型的值都是引用传递,通过引用计数来判断是否收掉对象,而弱引用(weak reference)会被垃圾回收器忽略.weak table就是它的元素是弱引用的,一个元素(键值对)可能键是弱引用,也可能值是弱引用的,也可能都是弱引用, 这个特性是通过弱表的metatable的__mode的值来设置的,特别有意思的是,当弱表中一个键值对,它的键或值关联(引用/指向)的那个对象被垃圾回收器回收的时候,这个键值对会从弱表中被自动删除掉.这是个很重要的特点. 那么弱表到底有什么用呢? 在lua的wiki中有一篇使用userdata的例子 ,其中就很巧妙的用到了弱表,原文地址 http://lua-users.org/wiki/CppBindingWithLunar
这篇文章介绍了如何通过userdata绑定c++对象到脚本中 fulluserdata能够设置metatable,也就能模拟出对象的效果出来,对一个C++的类的对象实例来说,push到脚本中,一般是创建了一个userdata,文章中用弱表避免了同一个对象实例(指针) push到脚本中,多次创建userdata的问题. 换句话来说,如果C++对象的生存周期是靠lua的垃圾回收来控制的话(userdata被回收时,调用元表的__gc方法,__gc方法中析构c++对象),一个C++对象只能有一个唯一的userdata. 在userdata的metatable中创建一个值是弱引用的弱表,用C++对象指针做键,每次push c++对象的时候,就去用指针值查弱表,如果有,就push那个userdata,没有就创建, 同时,当userdata是被弱引用的,当被垃圾回收掉的时候,弱表中它所在的键值对自动被销毁了.
最近做了个DEMO,飞机追飞机的. 利用AOI模块产生的enterAOI,LeaveAOI事件 触发NPC追随玩家 顺便也测试下服务器实体的欧拉角计算 先运行RegionApp.exe 然后再运行ClientDemo WSAD 前后左右 J上K下 客户端做的很简单..., 支持多开... 下载DEMO
最近在优化游戏服务器的AOI(area of interest)部分,位置有关的游戏实体一般都有一个视野或关心的范围,
当其他实体进出某个实体的这个范围的时候,就会触发leaveAOI或enterAOI事件,并维护一份AOI 实体列表。
我们来考虑最简单的实现,假设区域R中有1000个Entity,当某个entity位置发生变化时,需要计算entity的AOI事件和列表,伪代码如下:
function onEntityMove(who)
for entity in entities do
if who <> entity then
计算who和entity之间的距离
如果who移动前entity在who的AOI范围内,且现在在范围外
触发who.onLeaveAOI(entity)
如果who移动前entity在who的AOI范围外,且现在在范围内
触发who.onEnterAOI(entity)
如果who移动前在 entity的AOI范围内,且现在在范围外
触发entity.onLeaveAOI(who)
如果who移动前在 entity的AOI范围外,且现在在 范围内
触发entity.onEntityAOI(who)
end
end
end
每次一个实体移动一次位置就要遍历1000个实体来计算,这 样做显然不行,效率太低了,
那么就需要引入场景管理,将区域R分成n个格子,每个格子维护一个实体链表,entity移动时,只遍历它所在的格子和周围的8个格子的实体链表,
再优化下,可以加入AOI圆和格子的碰撞检查,9个格子中再去掉没有相交的格子。。。等等
也有用四叉树来进行场景管理的。
还有些方案更简单,直接是画格子,按以实体为中心的九个格子进行位置广播, 实体从一个格子移动到另外的格子时触发事体。。好处是计算量简单,缺点是带宽占用大
我上面的方案都试过了,效率和带宽占用都不理想,最近终于弄出一个新的方案,现在的AOI计算量是我们服务器以前计算量的1/40-1/80,由于涉及到公司的保密制度,不便细说,上几个测试的抓图:
机器配置:win7 ,T5870 inter双核2G,2G内存
20个entity 随机运动计算一次所有entity AOI的时间在0.02毫秒左右:

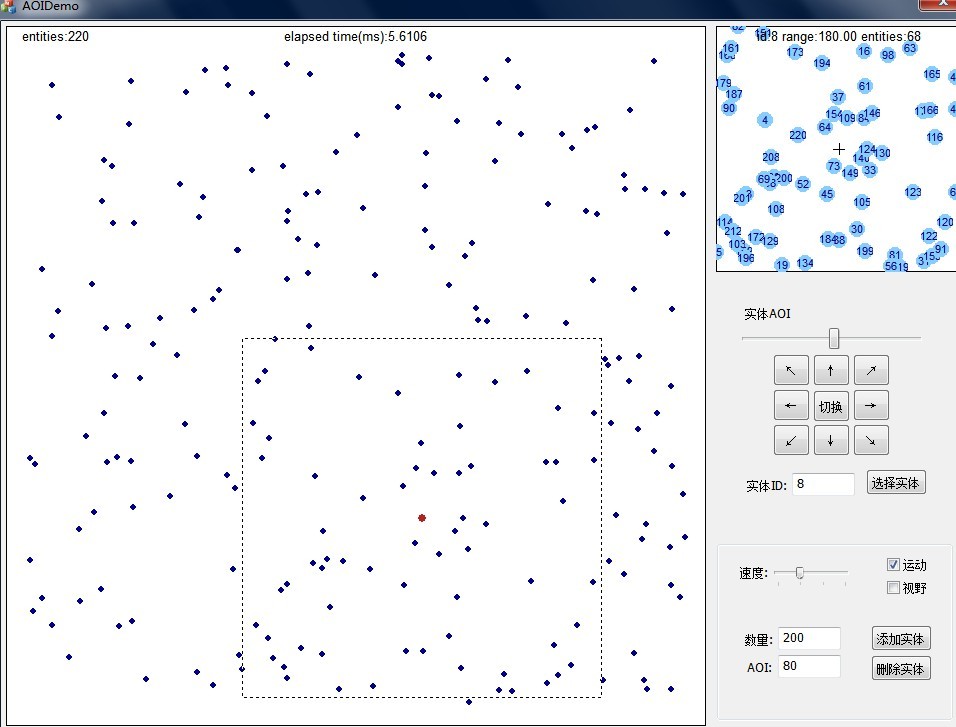
220个实体,选择的实体AOI范围里有68个实体:
4000个实体,选择的实体的AOI区域里有465个实体
 AOIDemo.exe 下载
AOIDemo.exe 下载
SOA:Service-oriented architecture 最近在做游戏服务器引擎,查了不少有关SOA的设计方面的资料。发现JAVA世界有相当多的技术标准。 其中比较好的是OSGi ( http://www.osgi.org/About/WhatIsOSGi),OSGi技术是面向Java的动态模型系统。OSGi服务平台向Java提供服务,这些服务使Java成为软件集成和软件开发的首选环境。Java提供在多个平台支持产品的可移植性。OSGi技术提供允许应用程序使用精炼、可重用和可协作的组件构建的标准化原语。这些组件能够组装进一个应用和部署中。 参考它的思路,结合C++语言的特点,我将一个服务器基础框架设计成了这样一种:  一个服务器应用,由多个组件组成,组件物理上可以是动态库,也可以是EXE里一段实际的代码,每个组件可以向ApplicationFramework注册多个服务(比如日志服务,网络服务等)。 ApplicationFramework启动时,通过配置文件,动态加载和启动组件,读取服务的可配置属性。Framework触发IComponentActivator的OnStart() 和OnStop()事件,在Start事件中,可以注册组件自己的服务,也可以加入一个服务监听器来监听关心的服务的注册,注销等事件。 我随便画了几个大概的接口: 
替换^M字符
在Linux下使用vi来查看一些在Windows下创建的文本文件,有时会发现在行尾有一些“^M”。有几种方法可以处理。
1.使用dos2unix命令。一般的分发版本中都带有这个小工具(如果没有可以根据下面的连接去下载),使用起来很方便:
$ dos2unix myfile.txt
上面的命令会去掉行尾的^M。
2.使用vi的替换功能。启动vi,进入命令模式,输入以下命令:
:%s/^M$//g # 去掉行尾的^M。
:%s/^M//g # 去掉所有的^M。
:%s/^M/[ctrl-v]+[enter]/g # 将^M替换成回车。
:%s/^M/\r/g # 将^M替换成回车。
3.使用sed命令。和vi的用法相似:
$ sed -e ‘s/^M/\n/g’ myfile.txt
注意:这里的“^M”要使用“CTRL-V CTRL-M”生成,而不是直接键入“^M”。
转自:http://hi.baidu.com/mofeis/blog/item/23c7b2fb92dc97234e4aea6d.html
编辑~/.vimrc 加入以下代码
1 autocmd BufNewFile *.[ch],*.hpp,*.cpp exec ":call SetTitle()"
2
3 "加入注释
4 func SetComment()
5 call setline(1,"/*===============================================================")
6 call append(line("."), "* Copyright (C) ".strftime("%Y")." All rights reserved.")
7 call append(line(".")+1, "* ")
8 call append(line(".")+2, "* 文件名称:".expand("%:t"))
9 call append(line(".")+3, "* 创 建 者:蒋浩")
10 call append(line(".")+4, "* 创建日期:".strftime("%Y年%m月%d日"))
11 call append(line(".")+5, "* 描 述:")
12 call append(line(".")+6, "*")
13 call append(line(".")+7, "* 更新日志:")
14 call append(line(".")+8, "*")
15 call append(line(".")+9, "================================================================*/")
16 endfunc
17
18 "定义函数SetTitle,自动插入文件头
19 func SetTitle()
20 call SetComment()
21 if expand("%:e") == 'hpp'
22 call append(line(".")+10, "#ifndef _".toupper(expand("%:t:r"))."_H")
23 call append(line(".")+11, "#define _".toupper(expand("%:t:r"))."_H")
24 call append(line(".")+12, "#ifdef __cplusplus")
25 call append(line(".")+13, "extern \"C\"")
26 call append(line(".")+14, "{")
27 call append(line(".")+15, "#endif")
28 call append(line(".")+16, "")
29 call append(line(".")+17, "#ifdef __cplusplus")
30 call append(line(".")+18, "}")
31 call append(line(".")+19, "#endif")
32 call append(line(".")+20, "#endif //".toupper(expand("%:t:r"))."_H")
33 elseif expand("%:e") == 'h'
34 call append(line(".")+10, "#pragma once")
35 elseif &filetype == 'c'
36 call append(line(".")+10,"#include \"".expand("%:t:r").".h\"")
37 elseif &filetype == 'cpp'
38 call append(line(".")+10, "#include \"".expand("%:t:r").".h\"")
39 endif
40 endfunc
41
一个典型的游戏服务器设计中,一般都是用的多线程,服务器中一般运行两类线程,N个SOCKET IO线程,1个逻辑线程,
IO线程接受客户端发来的信息,通过消息队列发送给逻辑线程处理后,再发送消息给客户端,发送消息这里一般是IO线程处理实际发送。
其实我认为,如果逻辑线程都是消耗的CPU运算资源的话,服务器完全采用单线程的方式来做。
首先,我们看IO处理,基本就是数据入队、出队,send、recv操作,作为服务器的SOCKET处理一般都是异步SOCKET,也就是说,send、recv操作只是将信息copy到socket底层的发送接收缓冲区去了,不存在IO堵塞的问题。
然后,我们再来看逻辑处理,前面已经说了,采用单线程的前提是逻辑处理只是消耗CPU运算资源,那么,不管你开几个线程,对单核的CPU来说,它的处理速度就是这么多,并不会因为你线程开的越多,就处理的越快。
因此我们可不可以这样说呢,在单核机器上,只消耗CPU运算的服务,多线程并不比单线程能提高多少效率。
接下来,我们再讨论下多核的情况,你肯定要想,我这台服务器是4个双核CPU,就只跑一个单线程的服务器不是亏死了,多线程多好,我开8个线程,就能很好的利用我的机器啦。是啊,我也觉得这样很好,不过在LINUX、UNIX下,对线程的支持并不像WINDOWS下那么好,LINUX、UNIX下一般都是用LWP(轻量级进程)的方式来支持多线程程序的,Linux内核只提供了轻量进程的支持,限制了更高效的线程模型的实现,但Linux着重优化了进程的调度开销,一定程度上也弥补了这一缺陷。同时,滥用多线程也会造成不必要的上下文切换,不必要的同步机制的引入(如pthread_mutex),让程序频繁的在内核和用户间频繁切换。另外,从开发角度来看,单线程开发比多线程环境开发更不容易出错和更加健壮。
在游戏服务器架构中,为了提高玩家在线人数,实现负载均衡,现在一般都是采用分布式的多进程服务器集群的方式,我们来看看服务器集群中,每个服务进程是采用多线程的方式还是单线程的方式好呢?我觉得,对于有慢速IO访问的需求的应用进程,多线程肯定比单线程好,最典型的情况就是数据库访问这块,完全可以采用N个DB线程,一个逻辑线程的架构,而对只是消耗CPU运算资源的应用进程,尽量单线程就行了,如果觉得单线程负载不行的话,完全可以分成多个进程来跑。。
以上只是我自己的一些看法,表达有限,欢迎指正。。。
boost里的program_options提供程序员一种方便的命令行和配置文件进行程序选项设置的方法。 其文档例子中有如下代码:
1 using namespace boost::program_options;
2 //声明需要的选项
3 options_description desc("Allowed options");
4 desc.add_options()
5 ("help,h", "produce help message")
6 ("person,p", value<string>()->default_value("world"), "who");
看第4到6行,是不是感觉很怪?这种方式体现了函数式编程中最大的特点:函数是一类值,引用资料来说, 所谓“函数是一类值(First Class Value)”指的是函数和值是同等的概念,一个函数可以作为另外一个函数的参数,也可以作为值使用。如果函数可以作为一类值使用,那么我们就可以写出一些函数,使得这些函数接受其它函数作为参数并返回另外一个函数。比如定义了f和g两个函数,用compose(f,g)的风格就可以生成另外一个函数,使得这个函数执行f(g(x))的操作,则可称compose为高阶函数(Higher-order Function)。
program_options里的这种方式是怎么实现的呢?通过分析boost的源代码,我们自己来写个类似的实现看看: test.h
1 #pragma once
2
3 #include <iostream>
4 using namespace std;
5
6 class Test;
7
8 class Test_easy_init
9 {
10 public:
11 Test_easy_init(Test* owner):m_owner(owner){}
12
13 Test_easy_init & operator () (const char* name);
14 Test_easy_init & operator () (const char* name,int id);
15 private:
16 Test* m_owner;
17 };
18
19
20 class Test
21 {
22 public:
23 void add(const char* name);
24 void add(const char* name,int id);
25
26 Test_easy_init add_some();
27
28 };
test.cpp
1 #include "test.h"
2
3 Test_easy_init & Test_easy_init::operator () (const char* name,int id)
4 {
5
6 m_owner->add(name,id);
7 return *this;
8 }
9
10
11 Test_easy_init & Test_easy_init::operator () (const char* name)
12 {
13
14 m_owner->add(name);
15 return *this;
16 }
17
18 Test_easy_init Test::add_some()
19 {
20 return Test_easy_init(this);
21 }
22
23
24 void Test::add(const char* name)
25 {
26 cout<<"add:"<<name<<endl;
27 }
28
29 void Test::add(const char* name,int id)
30 {
31 cout<<"add:"<<name<<"-"<<id<<endl;
32 }
使用方式:
1 Test t1;
2
3 t1.add_some()
4 ("hello",1)
5 ("no id")
6 ("hello2",2);
是不是很有意思。add_some()方法返回一个Test_easy_init类的对象,Test_easy_init类重载了操作符(),操作符()方法返回Test_easy_init类对象自身的引用。。
|