转自:https://my.oschina.net/caicloud/blog/829365
著作权归作者所有,转载请自觉标明出处,以示尊重!
大家好,我是徐超,从事 Kubernetes 开发已经两年多了。
今天,我从一个开发者的角度来讲一讲 client-go repository,以及怎么用 client-go 搭建 Controller。同时,也给大家讲一讲开发过程中遇到的坑,希望大家在开发的时候可以绕坑而行。
另外,我还会讲一下 Kubernetes 的 API,让 controller 功能变的更加强大。

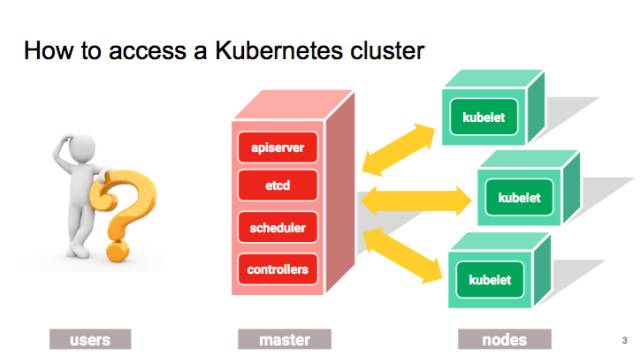
那我们现在先来讲,有哪些方法可以跟 APIserver 进行通讯。最常用的,可能就是 kubectl,以及官方支持的 UI,Kube Dashboard,这是 google 最近投入很多的一个项目。
开发过程中 debug 的时候可以直接去调用 k8s 的 Restful API,通过写脚本去实现 Controller。
但是,这些做法无论从效率还是可编程性来说都是不太令人满意的。
这也就是为什么我们要创建 client-go,我们其实就是把写 controller 所需的 clients,utilities 等都放到了 client-go 这个 repository 里面。大家如果需要写 controller 的话,可以在这里面找到所需要的工具。client-go 是 go 语言的 client,除了 go 语言之外,我们现在还支持 python 的 client,目前是 beta 版本。但是这个 python client 是我们直接从 open API spec 生成的,之后我们会继续生成 client Java 或者一些其它的语言。

我们先看一下 client library 的内容。它主要包括各种 clients:clientset、DynamicClient 和 RESTClient。还有帮助你写 Controller 时用到的 utilities:Workqueue 和 Informer。
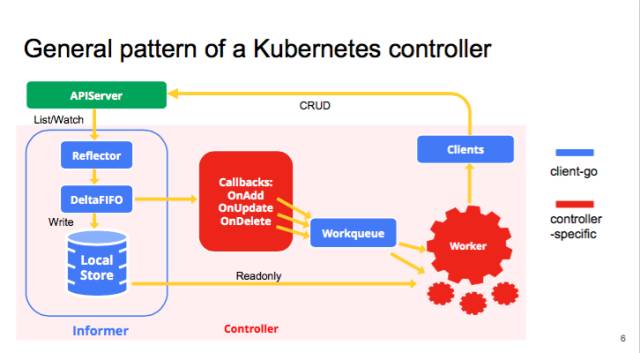
我们先看一下 kube-controller 的大致结构,典型的 controller 一般会有 1 个或者多个 informer,来跟踪某一个 resource,跟 APIserver 保持通讯,把最新的状态反映到本地的 cache 中。只要这些资源有变化,informal 会调用 callback。这些 callbacks 只是做一些非常简单的预处理,把不关心的的变化过滤掉,然后把关心的变更的 Object 放到 workqueue 里面。其实真正的 business logic 都是在 worker 里面, 一般 1 个 Controller 会启动很多 goroutines 跑 Workers,处理 workqueue 里的 items。它会计算用户想要达到的状态和当前的状态有多大的区别,然后通过 clients 向 APIserver 发送请求,来驱动这个集群向用户要求的状态演化。图里面蓝色的是 client-go 的原件,红色是自己写 controller 时填的代码。

我们来仔细看一下各种 clients。
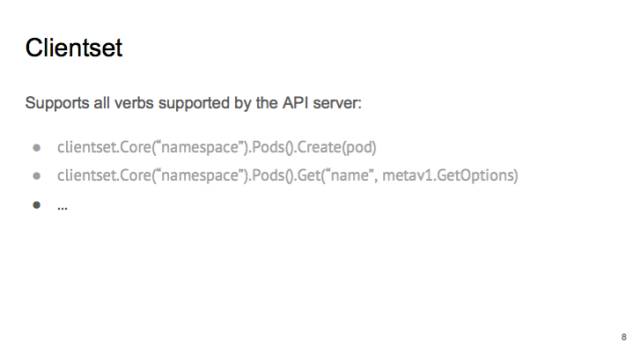
先讲最常见的 Clientset,它是 k8s 中出镜率最高的 client,用法比较简单。先选 group,比如 core,再选具体的 resource,比如 pod 或者 job,最后在把动词(create、get)填上。
clientset 的使用分两种情况:集群内和集群外。
集群内:将 controller 容器化后以 pod 的形式在集群里跑,只需调用 rest.InClusterConfig(),默认的 service accoutns 就可以访问 apiserver 的所有资源。
集群外,比如在本地,可以使用与 kubectl 一样的 kube-config 来配置 clients。如果是在云上,比如 gke,还需要 import Auth Plugin。
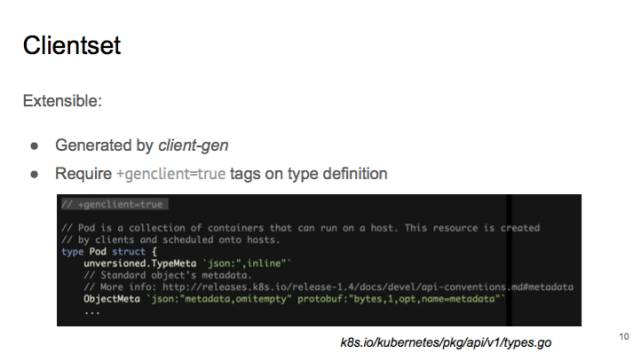
clientset 是用 client-gen 生成的。如果你打开 pkg/api/v1/tyeps.go,在 pod 的定义上有一行注释,叫做“+genclient=true”,这句话的意思是,需要为这个 type 生成一个 client,如果之后要做自己的 API type 拓展,也可以通过这样的方式来生成对应的 clients。

Clientset 的动词很多细微的地方比较烧脑,我来帮助大家理解一下。
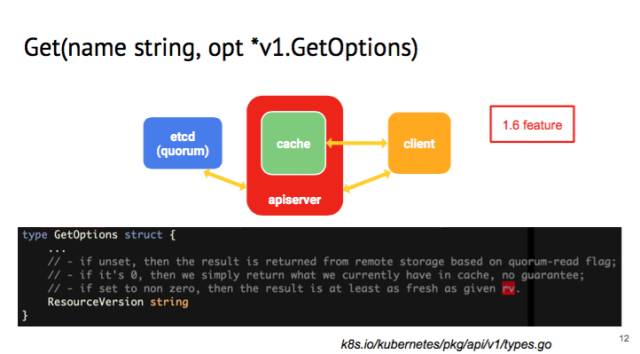
我们先来说 Get 的 GetOptions,这是 1.6 的 feature,如果在里面看 client 的 get 的话,有一个 field,叫做 resource version。
resourece version 是 kubernetes 里面一个 logical clock,用作 optimistic concurrency。如果没有设置 resourceversion,api-server 收到请求后会从 etcd 读出最新的值。但设为 0 的话,APIserver 就会从 local 的 cache 里面把值读取出来,cache 的值可能会有一定的延迟。这样可以减轻 APIserver 和 etcd 后端的压力。现在是用得比较多的是 kubelet,经常要 get node status,但是不需要最新的 node status,如果集群很大,就能够省不少 cpu/memory 的开销。如果 resource version 设成非常大的值,get request 会在 api-server 挂起,没有响应的话会 time-out。
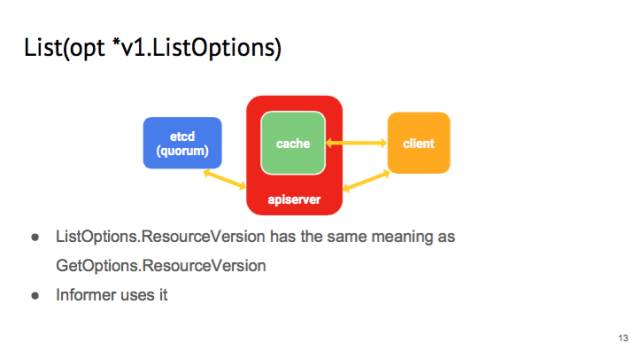
同样的,在 list 这个操作的时候,你可以提供一个 listOption,这个 listOption 里面也有 resource version,和 get 里的意义一样。我们在写 informer 的时候会用到。因为每一个 controller 在启动的时候,会向 api-server 发送 list 请求,如果每一个 request 都是从 etcd 里读取过来的话,这个开销非常大,所以 list 会从 api-server 的 cache 读取。
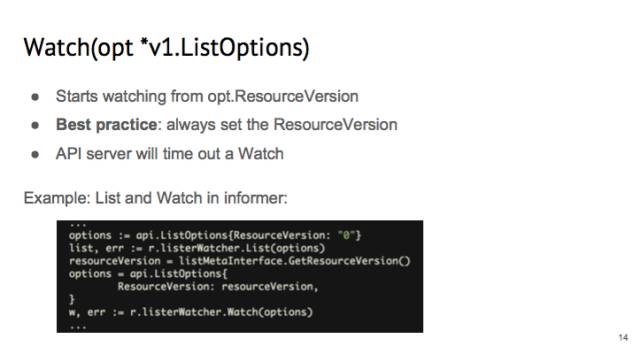
在 watch 里面也有一个 listOption,里面 resrouce version 的意义不一样。在 watch 的时候,apiserver 会从这个 resuorce version 开始所有的变化。这里的 best practice 设置成:永远要设置 resource version。因为如果不设置,那么 APIserver 就会从 cache 里随便的一个时间点开始推送,令 controller 的行为不好预测。
我们看 informer 是怎么使用 list 进行 watch 的。在 informer 里面,我们一般都是先 list,把 resource version 设为 0,API Server 就可以从 cache 里面给我 list。List 完之后,把 list 的 resource version 取出来,并且设置为 watch 的 listOption,这样就可以保证 informer 拿到的 events 是连续的。
另外要注意的是,watch 不是一劳永逸的,apiserver 会 timeout 一个 watchrequest 的,默认值是 5~10 分钟。这时你需要重新 watch。

说一下这个 update,client 里面有两种 update:Update 和 UpdateStatus。
他们的区别是,如果你 Update 一个 pod,那么你对 status 的修改会被 API server overwrite 掉。UptateStatus 则相反。
k8s 有 OptimisticConcurrency 机制,如果有两个 client 都在 update 同一个,会 fail。所以写代码时一般会把 update 写到 loop 里,直到 api-server 返回 200,ok 时才确定 update 成功。
另外,使用 get+update 有一个 bug:假设 cluster 的 pod 有一个新的 field,如果你使用一个旧的 client,它不知道这个新的 field,那么 get 到的 pod 是没有这个新的 field 的,再 update 的时候,这个新的 field 会被覆盖掉。
可能会在 1.7 的时候把这个 bug 处理掉。
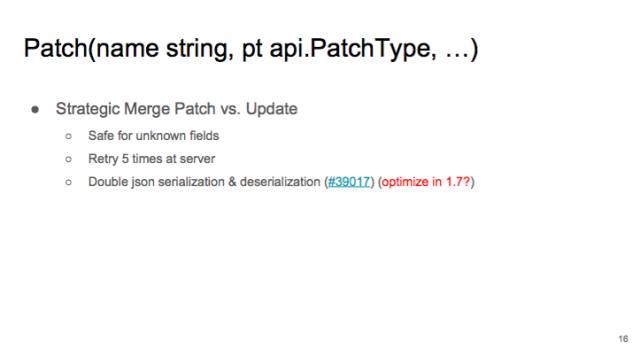
跟 update 相对应的就是 patch。Update 像拆迁队,只会把整个 object 推倒重做。Patch 则像手术刀,可以做精细操作,可以精确修改一个 object 的 field。
patch 如果有 conflicts,会在 apiserver 重试 5 次。除非有用户 patch 同一个 field,否则一般 client 会一次 patch 成功。当然 patch 有性能问题,因为要在 API serve 做 Json serialiation 和 deserialization。我们估计会在 1.7 的时候优化。如果不关心性能,我们还是推荐用 patch。
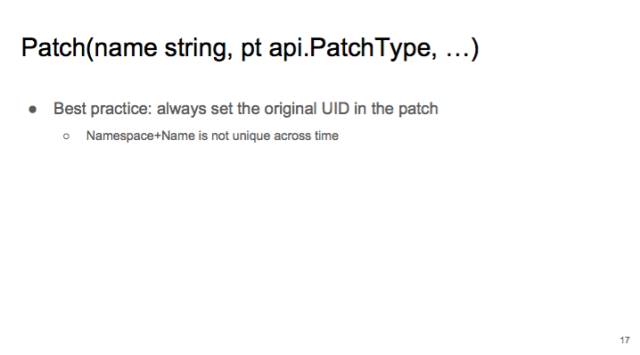
提醒一下:你在做 Patch 的时候,最佳实践是把 original 的 UID 填在 patch 里。因为 API server 的 key-value store 是以“namespace + name”作为 key 的。在任意一个时间,这个组合都是唯一的。但是如果把时间这条轴加进来的话,比如你有一个 pod,删除后过了一会儿,又在同一个 namespace 下建了同名的 pod,但是把所有的 spec 都改掉了,那么 controller 旧的 patch 可能会被应用到这个新建的 pod 上,这样就会有 bug 了。如果在 patch 里加入 uid 的话,一旦发生刚才所说的情况,apiserver 会以为你是要修改 uid,这个是不允许的,所以这个 patch 就会 fail 掉,防止了 bug。
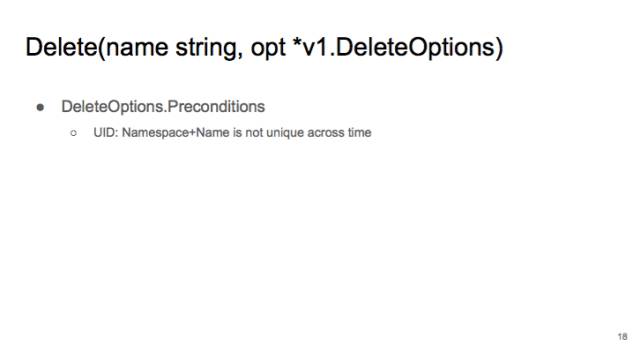
Delete Option,有一个选项叫 precondition,它有一个 uid 选项。也是为了防止 namespace+name 的组合在时间轴上不唯一。
当时,我们发现 K8S 的 CI tests 经常会莫名其妙的 fail 掉。最后我发现是因为刚 create 的 pod 跟之前已经被删除的 pod 重名,但是 kubelet 不知道,就把新的 pod 给误删除了。所以我们 delete 的时候,这个 precondition 的 UID 请勿删除。

Delete 从 1.4 开始有一个 field 叫做 OrphanDependents。如果设为 true 或者 unset 的话,当 delete()返回的时候,这个 object 可能会在继续存在一会儿,虽然最终还是会被删掉。另外,这个时候,如果你把 OrphanDependents 设置成 true 或者不设置的话,要删除的 Dependents 是不会被删除的。如果设成 false,只要 delete()返回了,这个 object 就肯定已经在 apiserver 上被删掉了,除非你另外设置了 finalizer。并且 garbage collector 会在背景里面慢慢删除 dependents。


现在讲一下另外一种 client,叫做 dynamic client。
dynamic client 用法比较灵活。因为你可以任意设置要操作的 resource。它的 return value,不是一个 structure,而是 map[string]interface{}。如果一个 controller 需要控制所有 API,比如 namespace controller 或者 garbage collector,那就用 dynamic client。使用时可以先通过 discovery,发现有哪些 API,再通过使用 dynamic client access 所有的 api。dynamic client 也支持 third party resources。
dynamic client 的缺点是它只支持 JSON 一种序列化。而 JSON 的效率远远低于 proto buf。


现在我们讲一下 rest client。
Rest Client 是 client 和 dynamic client 的基础。属于比较底层的,跟 dynamic client 一样,你可以使用它操作各种 resource。支持 Do() 和 DoRaw。
相比 dynamic client,支持 protobuf 和 json。效率会比较高。
但是问题就是,如果你要 access third party resource,需要自己写反序列化,不能直接 decode 到 type。在 demo 里会进行演示。
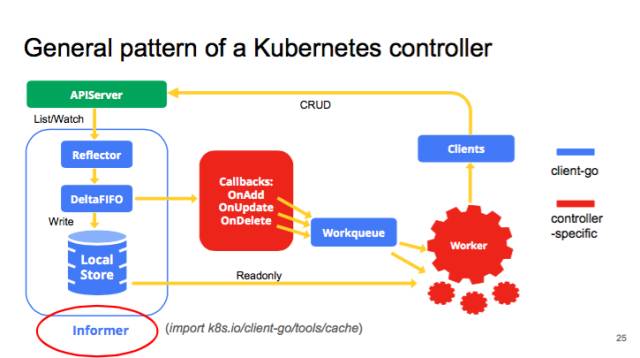
现在我们讲 informer,它的 input 其实就两个,一是要 list function 和 watch function,二是你要给 informer 提供一些 callback。informer 跑起来后,它会维护 localstore。你之后就可以直接访问 localstore,而不用跟 APIserver 通讯。提高一些 performance。
使用 informer 的好处一个是性能比较好,还有一个是可靠性。如果有 network partition,informer 后会从断点开始继续 watch,它不会错过任何 event 的。
Informer 也有一些 best practice,第一点,在 controller run 之前,最好等这些 informer 都 sync 了(初始化)。这样做,一是可以避免 controller 初始化时的 churn:比如 replica set controller 要 watch replica set 和 pod,如果不 sync 就开始 run,controller 会以为现在没有任何 pod,会创建很多不必要的 pod,之后还要删除。二来就是会避免很多很诡异的 bug。我在写 garbage collector 的时候就遇到过不少。
另外 informer 提供的 localcache 是 read-only 的。如果要修改,先用 DeepCopy 拷贝出来,否则可能有 read-write race。并且你的 cache 可能是和其他 controller 共享的,修改 cache 会影响其他 controller。
第三个要注意的地方就是,informer 传递给 callbacks 的 object 不一定是你所期待的 type。比如 informer 追踪所有 pod,返回的 Object 可能不是 pod,而是 DeletedFinalStateUnknown。所以在处理 delete 的时候,除了要处理原来跟踪的 object,还要处理 DeletedFinalStateUnknown。
最后要讲一下的就是,informer 的 resyncoption。它只是周期性地把所有的 local cache 的东西重新放到 FIFO 里。并不是说把 APIserver 上所有的最新状态都重新 list 一遍。这个 option 大家一般都是不会用到的,可以放心大胆地把这个 resync period 设成 0。
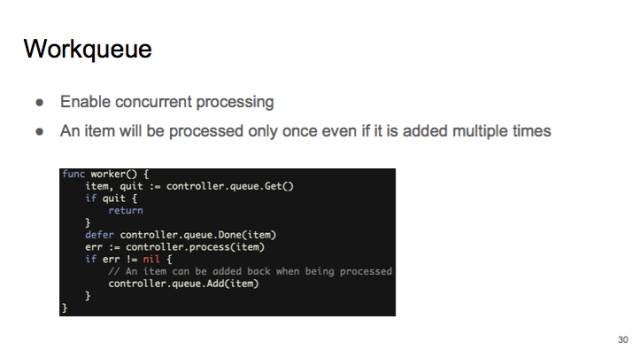
最后再讲一下这个 workqueue。
其实主要是为了可以 concurrent processing,可以并行地让 Callbacks 把状态加到 workqueue 里,然后起一大堆的 worker。
workqueue 提供的一个保障就是,如果是同一个object,比如同一个 pod,被多次加到 workqueue 里,在 dequeue 时,它只会出现一次。防止会有同一个 object 被多个 worker 同时处理。

另外 workqueue 还有一些非常有用的 feature。比如说 rate limited: 如果你从 workqueue 里面拿出一个 object,处理时发生了错误,重新放回了 workqueue。这时,workqueue 保证这个 object 不会被立刻重新处理,防止 hot loop。
另外的一个 feature 就是提供 prometheus 监控。你可以实时监控 queue 的长度,延迟等。你可以监控 queue 的处理速度是否跟得上。

现在我给大家做一个 demo(https://github.com/caesarxuchao/servicelookup)。通过 k8s 的 api 用户是没办法很快通过 pod 的名字找到对应的 service 的。当然你可以找到这个 pod 的 label,然后去跟 selector 进行比较而确定 service,但做这种逆向查询是非常费时间的。
所以我这里就是写了这样一种 controller,watch 所有的 endpoints 和 pods,来做比对,找到 pod 服务的 service。

我先启动两个 informer,1 个 informer 是追踪所有 pods 的变化,另一个追踪所有 endpoints 变化。

给 informer 注册 callback,来把 pod 和 endpoint 的变化放到 workqueue。

然后启动许多 worker,从 workquue 里拿出 pod 和 endpoint 做比对。
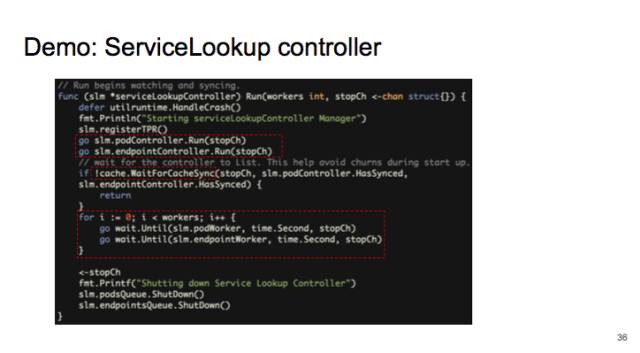
运行时,先启动两个 informer,等它们 sync,最后启动 worker。
Demo 的代码在 github 上,https://github.com/caesarxuchao/servicelookup。
视频链接:http://v.qq.com/iframe/player.html?vid=c03641vzw2m&width=670&height=502.5&auto=0
posted on 2017-01-23 17:06
思月行云 阅读(552)
评论(0) 编辑 收藏 引用 所属分类:
Docker\K8s