#
这里提到的两个设计模式都是用于高并发系统(例如一个高性能的网络服务器)的。这里我只是简单地提一下:
1.半同步/半异步(half-sync/half-async):
在网上一份资料中引用了一本貌似很经典的书里的比喻:
”
许多餐厅使用 半同步/半异步 模式的变体。例如,餐厅常常雇佣一个领班负责迎接顾客,并在餐厅繁忙时留意给顾客安排桌位,
为等待就餐的顾客按序排队是必要的。领班由所有顾客“共享”,不能被任何特定顾客占用太多时间。当顾客在一张桌子入坐后,
有一个侍应生专门为这张桌子服务。
“
按照另一份似乎比较权威的文档的描述,要实现半同步/半异步模式,需要实现三层:异步层、同步层、队列层。因为很多操作
采用异步方式会比较有效率(例如高效率的网络模型似乎都采用异步IO),但是异步操作的复杂度比较高,不利于编程。而同步
操作相对之下编程要简单点。为了结合两者的优点,就提出了这个模式。而为了让异步层和同步层互相通信(模块间的通信),系
统需要加入一个通信队列。异步层将操作结果放入队列,同步层从队列里获取操作结果。
回过头来看看我之前写的那个select网络模型代码,个人认为基本上算是一个半同步半异步模式的简单例子:Buffer相当于通信
队列,网络底层将数据写入Buffer,上层再同步地从该队列里获取出数据。这样看来似乎也没什么难度。 = =
关于例子代码,直接引用iunknown给的:
//这就是一个典型的循环队列的定义,iget 是队列头,iput 是队列尾</STRONG>
int clifd[MAXNCLI], iget, iput;
int main( int argc, char * argv[] )
{
......
int listenfd = Tcp_listen( NULL, argv[ 1 ], &addrlen );
......
iget = iput = 0;
for( int i = 0; i < nthreads; i++ ) {
pthread_create( &tptr[i].thread_tid, NULL, &thread_main, (void*)i );
for( ; ; ) {
connfd = accept( listenfd, cliaddr,, &clilen );
clifd[ iput ] = connfd; // 接受到的连接句柄放入队列</STRONG>
if( ++iput == MAXNCLI ) iput = 0;
}
}
void * thread_main( void * arg )
{
for( ; ; ) {
while( iget == iput ) pthread_cond_wait( ...... );
connfd = clifd[ iget ]; // 从队列中获得连接句柄</STRONG>
if( ++iget == MAXNCLI ) iget = 0;
......
web_child( connfd );
close( connfd );
}
}
2.领导者/追随者(Leader/Followers):
同样,给出别人引用的比喻:
”
在日常生活中,领导者/追随者模式用于管理许多飞机场出租车候车台。在该用例中,出租车扮演“线程”角色,排在第一辆的出
租车成为领导者,剩下的出租车成为追随者。同样,到达出租车候车台的乘客构成了必须被多路分解给出租车的事件,一般以先进
先出排序。一般来说,如果任何出租车可以为任何顾客服务,该场景就主要相当于非绑定句柄/线程关联。然而,如果仅仅是某些
出租车可以为某些乘客服务,该场景就相当于绑定句柄/线程关联。
“
其实这个更简单,我记得<unix网络编程>中似乎提到过这个。总之有一种网络模型(connection-per-thread?)里,一个线程用于
accept连接。当接收到一个新的连接时,这个线程就转为connection thread,而这个线程后面的线程则上升为accept线程。这里,
accept线程就相当于领导者线程,而其他线程则属于追随者线程。
iunknown 的例子代码:
int listenfd;
int main( int argc, char * argv[] )
{
......
listenfd = Tcp_listen( NULL, argv[ 1 ], &addrlen );
......
for( int i = 0; i < nthreads; i++ ){
pthread_create( &tptr[i].thread_tid, NULL, &thread_main, (void*)i );
}
......
}
void * thread_main( void * arg )
{
for( ; ; ){
......
// 多个线程同时阻塞在这个 accept 调用上,依靠操作系统的队列</STRONG>
connfd = accept( listenfd, cliaddr, &clilen );
......
web_child( connfd );
close( connfd );
......
}
}
没什么技术含量,将select模型做简单的封装,同时提供服务器端和客户端所用的接口。功能实现上对数据的发送和接收
都做了缓存,搞得跟异步IO一样 = =#。
这个例子聊天服务器可以使用telnet登录,服务器直接将telnet发来的字符串转发给所有客户端。我稍微写了一个小的网络
模块,可以用于以后写网络程序的例子代码,也算是练习下网络库的设计。
系统总体类图如下:
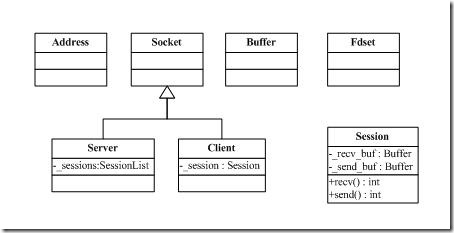
Address用于包装sockaddr_in结构体,目的就是让系统用起来更方便。
Buffer用于封装原始内存,主要目的是拿来做发送、接收数据缓冲。
Fdset差不多和FD_SET一样,只是这里自己写一个FD_SET,可以让连接数不受FD_SETSIZE的限制。
Socket封装了基本的SOCKET操作,包括创建、销毁套接字。
Session比较有意思,按我的意思,就是代表一个网络连接。对于服务器端,可能会有很多连接,每一个连接可以用一个
Session对象表示。而对于客户端,只有一个连接,那么就是一个Session对象。对于Session对象来说,可以进行数据的
发送和接收,因此这里Session有recv、send之类的接口。为了缓冲数据,所以Session对于读写分别有一个Buffer对象。
Server代表一个服务器,直接提供创建服务器的接口。同时使用一个unsigned long作为每一个连接的ID号。
Client代表一个客户端,可以直接用于连接服务器。
下载文件提供网络模块代码,以及三个例子程序。点击下载
Author : Kevin Lynx
从开始接触网络编程这个东西开始,我就不间断地阅读一些网络库(模块)的源代码,主要目的是为了获取别
人在这方面的经验,编程这东西,还是要多实践啊。
基本上,Etwork是一个很小巧的网络库。Etwork基于select模型,采用我之前说的技巧,理论上可以处理很
多连接(先不说效率)。
先看看下这个库的结构:
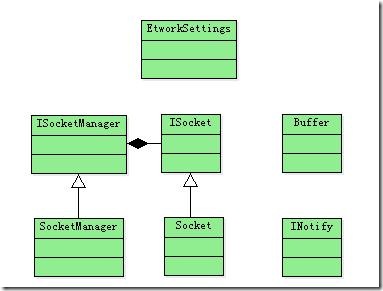
如同很多网络库一样,总会有一个类似于ISocketManager的类,用于管理所有网络连接(当用户服务器时)。
而ISocket则用于代表一个网络连接。在其他库中,ISocketManager对应的可能就是Server,而ISocket对应
的则是Session。
在接口设计上,尽管Etwork写了很多接口类(看看那些IClass),但是事实上它抽象得并不彻底。只是暴露给
客户端的代码很简洁,而库本身依然臃肿。不知道为什么,现在我比较喜欢纯C这种简洁的东西,对于OO以及
template,渐渐地有点心累。
在功能实现上,我以TCP服务器为例,CreateEtwork根据传来的参数建立服务器,在SocketManager::open中
是很常规的socket, bind, listen。当建立了服务器之后,需要在程序主循环里不断地轮询状态,这里主要
调用poll函数完成。
poll函数主体就是调用select。当select成功返回活动的套接字数量后,Etwork依次轮询读、写、错误fdset,
将保存的所有网络连接(就是那些ISocket对象)对应的套接字与fdset中当前的套接字做比较。大致逻辑为:
 fd_count = select( 0, readset, writeset, exceptset, &timeout );
fd_count = select( 0, readset, writeset, exceptset, &timeout );
for( each fd in readset )
if( fd is listening fd )
accept new connection
else
for( each socket in all connections )
if( fd == socket )
can read data on this socket
for( each fd in writeset )

for( each fd in exceptset )
没什么特别让人注意的地方(别觉得别人垃圾,耐心读别人的代码不是什么坏事)。每一次,当Etwork检测到
新的连接时,会创建新的ISocket对象,并关联对应的套接字,然后保存此对象到一个列表中。当poll结束
后,客户端程序通常会调用accept函数(Etwork中提供的接口),该函数主要是将poll中保存的新的ISocket
对象全部拷贝出去。
在接收、发送网络数据上,Etwork如同几乎所有的网络库(模块)一样,采用了缓冲机制。这里所说的缓冲机
制是,网络模块接收到网络数据时,将数据保存起来,客户端程序想获取数据时,实际上就是从这个缓冲中
直接取,而不是从网络上获取;同理,发送数据时,客户端程序将数据提供给网络模块,网络模块将数据保
存起来,网络模块会在另一个时候发送这个缓冲中的数据(对于异步IO的处理毕竟不一样)。
Etwork关于这个缓冲机制的相关代码,主要集中在Buffer这个类。与Buffer相关的是一个Message机制。Buffer
维护了一个Message的队列(deque)。一个Message实际上是一个非常简单的结构体:
struct Message

 {
{
 unsigned short offset_;
unsigned short offset_;
unsigned short size_;
 };
};
这其实是消息头,在消息头后全部是数据。在创建消息时(new_message),Etwork根据客户端提供的数据创建
足够大的缓存保存:
Message * m = (Message *)::operator new( size + sizeof( Message ) );
这其实是一个很危险的做法,但是从Etwokr的源码可以看出来,作者很喜欢玩弄这个技巧。与Buffer具体相
关的接口包括:get_data, put_data, get_message, put_message。Buffer内部维护的数据都是以Message
的形式组织。但是,对于外部而言,却依然是raw data,也就是诸如char*之类的数据。几个相关函数大致
上的操作为:获取指定尺寸的消息(可能包含多个消息),将一段数据加入Buffer并以消息的形式组织(可能会
创建多个消息),将一个消息以raw data的形式输出,将raw data以一个消息的形式加入到Buffer。
一般情况下,Etwork的poll操作,会将套接字上的数据接收并put_data到缓冲中;发送数据时则get_data。
客户端要从缓冲中获取数据时,就调用get_message;发送数据时就put_message。
Etwork中还有一个比较有趣的东西:marshaller。这个东西主要就是提供将C++中各种数据类型的变量进行字
节编码,也就是将int long struct之类的东西转换为unsigned char,从而方便直接往网络上发送。
基本上,Buffer和marshaller可以说是一个网络库(模块)的必要部件,你可以在不同的网络库中看到类似的
东西。
Etwork在网络事件的处理上,除了上面的轮询外,还支持回调机制。这主要是通过INotify,以及给各个ISocket
注册Notify对象实现。没什么难度,基本上就是observer模式的简单实现。
其他东西就没什么好说的了,纵观一下,Etwork实现得还是比较典型的,可以作为开发网络库的一个简单例子。
Author : Kevin Lynx
前言:
在很多比较各种网络模型的文章中,但凡提到select模型时,都会说select受限于轮询的套接字数量,这个
数量也就是系统头文件中定义的FD_SETSIZE值(例如64)。但事实上这个算不上真的限制。
C语言的偏方:
在C语言的世界里存在一个关于结构体的偏门技巧,例如:
typedef struct _str_type
{
int _len;
char _s[1];
}str_type;
str_type用于保存字符串(我只是举例,事实上这个结构体没什么用处),乍看上去str_type只能保存长度为
1的字符串('\0')。但是,通过写下如下的代码,你将突破这个限制:
int str_len = 5;
str_type *s = (str_type*) malloc( sizeof( str_type ) + str_len - 1 );
//
free( s );
这个技巧原理很简单,因为_s恰好在结构体尾部,所以可以为其分配一段连续的空间,只要注意指针的使用,
这个就算不上代码上的罪恶。但是这个技巧有个限制,str_type定义的变量必须是被分配在堆上,否则会破
坏堆栈。另外,需要动态增长的成员需要位于结构体的末尾。最后,一个忠告就是,这个是C语言里的技巧,
如果你的结构体包含了C++的东西,这个技巧将不再安全(<Inside the C++ object model>)。
其实select也可以这样做:
事实上,因为select涉及到的fd_set是一个完全满足上述要求的结构体:
winsock2.h :
typedef struct fd_set {

 u_int fd_count; /**//* how many are SET? */
u_int fd_count; /**//* how many are SET? */
SOCKET fd_array[FD_SETSIZE]; /**//* an array of SOCKETs */
} fd_set;
但是,如果使用了以上技巧来增加fd_array的数量(也就是保存的套接字数量),那么关于fd_set的那些宏可
能就无法使用了,例如FD_SET。
winsock2.h :
#define FD_SET(fd, set) do { \
u_int __i; \
for (__i = 0; __i < ((fd_set FAR *)(set))->fd_count; __i++) { \
if (((fd_set FAR *)(set))->fd_array[__i] == (fd)) { \
break; \
 } \
} \
} \
if (__i == ((fd_set FAR *)(set))->fd_count) { \
if (((fd_set FAR *)(set))->fd_count < FD_SETSIZE) { \
((fd_set FAR *)(set))->fd_array[__i] = (fd); \
((fd_set FAR *)(set))->fd_count++; \
} \
} \
} while(0)
有点让人眼花缭乱,我鼓励你仔细看,其实很简单。这里有个小技巧,就是他把这些代码放到一个do...while(0)
里,为什么要这样做,我觉得应该是防止名字污染,也就是防止那个__i变量与你的代码相冲突。可以看出,
FD_SET会将fd_count与FD_SETSIZE相比较,这里主要是防止往fd_array的非法位置写数据。
因为这个宏原理不过如此,所以我们完全可以自己写一个新的版本。例如:
#define MY_FD_SET( fd, set, size ) do { \
unsigned int i = 0; \
for( i = 0; i < ((fd_set*) set)->fd_count; ++ i ) { \
if( ((fd_set*)set)->fd_array[i] == (fd) ) { \
break; \
} \
} \
if( i == ((fd_set*)set)->fd_count ) { \
if( ((fd_set*)set)->fd_count < (size) ) { \
((fd_set*)set)->fd_array[i] = (fd); \
((fd_set*)set)->fd_count ++; \
} \
} \
} while( 0 )
没什么变化,只是为FD_SET加入一个fd_array的长度参数,宏体也只是将FD_SETSIZE换成这个长度参数。
于是,现在你可以写下这样的代码:
unsigned int count = 100;
fd_set *read_set = (fd_set*) malloc( sizeof( fd_set ) + sizeof(SOCKET) * (count - FD_SETSIZE ) );
SOCKET s = socket( AF_INET, SOCK_STREAM, 0 );
//
MY_FD_SET( s, read_set, count );
//
free( read_set );
closesocket( s );
小提下select模型:
这里我不会具体讲select模型,我只稍微提一下。一个典型的select轮询模型为:
int r = select( 0, &read_set, 0, 0, &timeout );
if( r < 0 )
{
// select error
}
if( r > 0 )
{
for( each sockets )
{
if( FD_ISSET( now_socket, &read_set ) )
{
// this socket can read data
}
}
}
轮询write时也差不多。在Etwork(一个超小型的基本用于练习网络编程的网络库,google yourself)中,作者
的轮询方式则有所不同:
// read_set, write_set为采用了上文所述技巧的fd_set类型的指针
int r = select( 0, read_set, write_set, 0, &timeout );
// error handling
for( int i = 0; i < read_set->fd_count; ++ i )
{
// 轮询所有socket,这里直接采用read_set->fd_array[i] == now_socket判断,而不是FD_ISSET
}
for( int i = 0; i < write_set->fd_count; ++ i )
{
// 轮询所有socket,检查其whether can write,判断方式同上
}
两种方式的效率从代码上看去似乎都差不多,关键在于,FD_ISSET干了什么?这个宏实际上使用了__WSAFDIsSet
函数,而__WSAFDIsSet做了什么则不知道。也许它会依赖于FD_SETSIZE宏,那么这在我们这里将是不安全的,
所以相比之下,如果我们使用了这个突破FD_SETSIZE的偏方手段,那么也许第二种方式要好些。
相关下载(5.21.2008)
随便写了一个改进的select模型的echo服务器,放上源码。
Author : Kevin Lynx
主要部分,四次握手:
断开连接其实从我的角度看不区分客户端和服务器端,任何一方都可以调用close(or closesocket)之类
的函数开始主动终止一个连接。这里先暂时说正常情况。当调用close函数断开一个连接时,主动断开的
一方发送FIN(finish报文给对方。有了之前的经验,我想你应该明白我说的FIN报文时什么东西。也就是
一个设置了FIN标志位的报文段。FIN报文也可能附加用户数据,如果这一方还有数据要发送时,将数据附
加到这个FIN报文时完全正常的。之后你会看到,这种附加报文还会有很多,例如ACK报文。我们所要把握
的原则是,TCP肯定会力所能及地达到最大效率,所以你能够想到的优化方法,我想TCP都会想到。
当被动关闭的一方收到FIN报文时,它会发送ACK确认报文(对于ACK这个东西你应该很熟悉了)。这里有个
东西要注意,因为TCP是双工的,也就是说,你可以想象一对TCP连接上有两条数据通路。当发送FIN报文
时,意思是说,发送FIN的一端就不能发送数据,也就是关闭了其中一条数据通路。被动关闭的一端发送
了ACK后,应用层通常就会检测到这个连接即将断开,然后被动断开的应用层调用close关闭连接。
我可以告诉你,一旦当你调用close(or closesocket),这一端就会发送FIN报文。也就是说,现在被动
关闭的一端也发送FIN给主动关闭端。有时候,被动关闭端会将ACK和FIN两个报文合在一起发送。主动
关闭端收到FIN后也发送ACK,然后整个连接关闭(事实上还没完全关闭,只是关闭需要交换的报文发送
完毕),四次握手完成。如你所见,因为被动关闭端可能会将ACK和FIN合到一起发送,所以这也算不上
严格的四次握手---四个报文段。
在前面的文章中,我一直没提TCP的状态转换。在这里我还是在犹豫是不是该将那张四处通用的图拿出来,
不过,这里我只给出断开连接时的状态转换图,摘自<The TCP/IP Guide>:
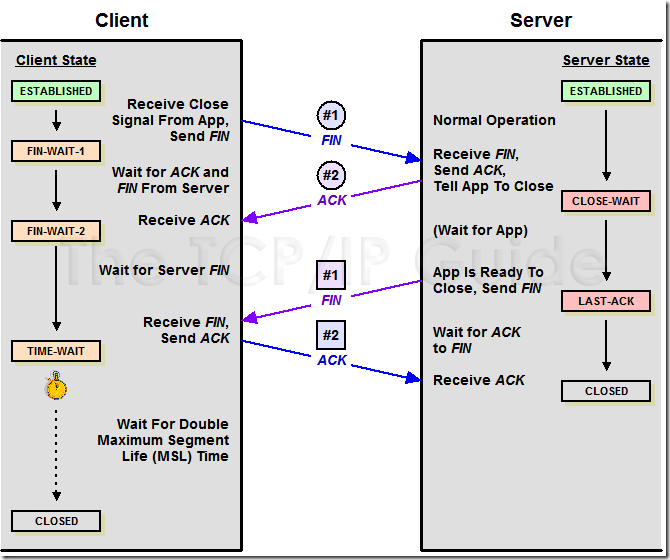
给出一个正常关闭时的windump信息:
14:00:38.819856 IP cd-zhangmin.1748 > 220.181.37.55.80: F 1:1(0) ack 1 win 65535
14:00:38.863989 IP 220.181.37.55.80 > cd-zhangmin.1748: F 1:1(0) ack 2 win 2920
14:00:38.864412 IP cd-zhangmin.1748 > 220.181.37.55.80: . ack 2 win 65535
补充细节:
关于以上的四次握手,我补充下细节:
1. 默认情况下(不改变socket选项),当你调用close( or closesocket,以下说close不再重复)时,如果
发送缓冲中还有数据,TCP会继续把数据发送完。
2. 发送了FIN只是表示这端不能继续发送数据(应用层不能再调用send发送),但是还可以接收数据。
3. 应用层如何知道对端关闭?通常,在最简单的阻塞模型中,当你调用recv时,如果返回0,则表示对端
关闭。在这个时候通常的做法就是也调用close,那么TCP层就发送FIN,继续完成四次握手。如果你不调用
close,那么对端就会处于FIN_WAIT_2状态,而本端则会处于CLOSE_WAIT状态。这个可以写代码试试。
4. 在很多时候,TCP连接的断开都会由TCP层自动进行,例如你CTRL+C终止你的程序,TCP连接依然会正常关
闭,你可以写代码试试。
特别的TIME_WAIT状态:
从以上TCP连接关闭的状态转换图可以看出,主动关闭的一方在发送完对对方FIN报文的确认(ACK)报文后,
会进入TIME_WAIT状态。TIME_WAIT状态也称为2MSL状态。
什么是2MSL?MSL即Maximum Segment Lifetime,也就是报文最大生存时间,引用<TCP/IP详解>中的话:“
它(MSL)是任何报文段被丢弃前在网络内的最长时间。”那么,2MSL也就是这个时间的2倍。其实我觉得没
必要把这个MSL的确切含义搞明白,你所需要明白的是,当TCP连接完成四个报文段的交换时,主动关闭的
一方将继续等待一定时间(2-4分钟),即使两端的应用程序结束。你可以写代码试试,然后用netstat查看下。
为什么需要2MSL?根据<TCP/IP详解>和<The TCP/IP Guide>中的说法,有两个原因:
其一,保证发送的ACK会成功发送到对方,如何保证?我觉得可能是通过超时计时器发送。这个就很难用
代码演示了。
其二,报文可能会被混淆,意思是说,其他时候的连接可能会被当作本次的连接。直接引用<The TCP/IP Guide>
的说法:The second is to provide a “buffering period” between the end of this connection
and any subsequent ones. If not for this period, it is possible that packets from different
connections could be mixed, creating confusion.
TIME_WAIT状态所带来的影响:
当某个连接的一端处于TIME_WAIT状态时,该连接将不能再被使用。事实上,对于我们比较有现实意义的
是,这个端口将不能再被使用。某个端口处于TIME_WAIT状态(其实应该是这个连接)时,这意味着这个TCP
连接并没有断开(完全断开),那么,如果你bind这个端口,就会失败。
对于服务器而言,如果服务器突然crash掉了,那么它将无法再2MSL内重新启动,因为bind会失败。解决这
个问题的一个方法就是设置socket的SO_REUSEADDR选项。这个选项意味着你可以重用一个地址。
对于TIME_WAIT的插曲:
当建立一个TCP连接时,服务器端会继续用原有端口监听,同时用这个端口与客户端通信。而客户端默认情况
下会使用一个随机端口与服务器端的监听端口通信。有时候,为了服务器端的安全性,我们需要对客户端进行
验证,即限定某个IP某个特定端口的客户端。客户端可以使用bind来使用特定的端口。
对于服务器端,当设置了SO_REUSEADDR选项时,它可以在2MSL内启动并listen成功。但是对于客户端,当使
用bind并设置SO_REUSEADDR时,如果在2MSL内启动,虽然bind会成功,但是在windows平台上connect会失败。
而在linux上则不存在这个问题。(我的实验平台:winxp, ubuntu7.10)
要解决windows平台的这个问题,可以设置SO_LINGER选项。SO_LINGER选项决定调用close时,TCP的行为。
SO_LINGER涉及到linger结构体,如果设置结构体中l_onoff为非0,l_linger为0,那么调用close时TCP连接
会立刻断开,TCP不会将发送缓冲中未发送的数据发送,而是立即发送一个RST报文给对方,这个时候TCP连
接就不会进入TIME_WAIT状态。
如你所见,这样做虽然解决了问题,但是并不安全。通过以上方式设置SO_LINGER状态,等同于设置SO_DONTLINGER
状态。
断开连接时的意外:
这个算不上断开连接时的意外,当TCP连接发生一些物理上的意外情况时,例如网线断开,linux上的TCP实现
会依然认为该连接有效,而windows则会在一定时间后返回错误信息。
这似乎可以通过设置SO_KEEPALIVE选项来解决,不过不知道这个选项是否对于所有平台都有效。
总结:
个人感觉,越写越烂。接下来会讲到TCP的数据发送,这会涉及到滑动窗口各种定时器之类的东西。我真诚
希望各位能够多提意见。对于TCP连接的断开,我们只要清楚:
1. 在默认情况下,调用close时TCP会继续将数据发送完毕;
2. TIME_WAIT状态会导致的问题;
3. 连接意外断开时可能会出现的问题。
4. maybe more...
可能我这个人比较怀旧,对什么东西都想做个记录,方便日后回忆。可能很多认识我的朋友都是通过GameRes那个作品专
区。我对于当年那种疯狂编程的干劲很是自豪,现在差了很多,以前帮别人做小学生系列游戏外包的时候,可以12小时出
个弱智的小游戏,那些日子一度被我称为’12小时编程挑战赛‘,只是自己跟自己比赛。
每一次发布在GameRes(排除早期的那些垃圾玩意),在写简介时我都要把自己开发用的时间写上,可是脾气好的sea_bug
每次都给我删掉了。我自己汇总一下:
1. 最让我自豪的一个游戏引擎,耗尽了我当时所有的设计能力。我努力把它做得很具扩展性,可是忽略了功能性。现在基本不维护了,可能是用户群太少了。我想我还是没做好吧:
edge2d google code page
托sea_bug的忙搞了个论坛,冷清得让我心寒:http://bbs.gameres.com/showforum.asp?forumid=91
2. PacShooter3d:
http://data.gameres.com/showmessage.asp?TopicID=90655
不知道怎么的被人放到一个网站上了:http://noyes.cn/Software.Asp?id=9667
源代码下载。
3. Space Demon demo
当初看到dophi写的俄罗斯方块营造的那种感觉觉得很不错,于是决定认真地做个游戏出来。结果后来做的东西让我很失望。这是一个在代码上过度设计的东西。我虽然对这个游戏不满意,但是我对代码还基本满意。后来这个游戏的代码被我游戏学院的一个朋友拿给金山的一个主程(在他们学校教书?)看,还得到了表扬。;D
这个游戏我是直接开源了的:http://www.gameres.com/showmessage.asp?TopicID=73123
4. Crazy Eggs Clone
<Crazy Eggs>是小林子他们工作室做的东西,属于casual games,拿到国外去卖的。我当时也觉得casual games市场不错,还找了个美工,大谈特谈,吹嘘了很多,最终在写策划案的时候失败了。我当时心也懒了,最终失败。
同样是在GameRes上:http://www.gameres.com/showmessage.asp?TopicID=72351
源代码下载。
后来我为了宣传edge2d,特地把这个游戏移植到我的引擎上。我从来很自豪自己代码的模块性,所以移植起来很容易。除了edge2d版本,我还做了HGE版本,不过HGE版本是做给别人的外包:
edge2d版本下载
5. Brick Shooter Jr
这个游戏也是我翻版别人的,用的别人的美术+音乐资源,自己重写代码。后来网上有个人又用我的资源翻作了个,做的比我好。
http://data.gameres.com/showmessage.asp?TopicID=65654
源代码下载
6. Feeding Frenzy
Popcap的经典游戏,我做的垃圾东西,不提其他的了:
http://data.gameres.com/showmessage.asp?TopicID=62796
源代码下载
7.是男人就下一百层
超级古老的东西,这个东西当初还和上海一家广告公司合作过。我签署了长这么大的第一份合同,结果后来一分钱没捞到。他们公司现在也不做这个了。和我合作的产品经理现在貌似在搞棋牌。
http://data.gameres.com/showmessage.asp?TopicID=54475
源代码下载
8. 所谓的雷电,一个我最早做的东西,现在你开baidu搜索 kevin lynx,出来最多的链接就是<雷电kevinlynx版>,别信那
些,全是流氓软件。
http://data.gameres.com/showmessage.asp?TopicID=54474
源代码下载
其他还给别人做了一些外包,在此特别感谢哆啦G梦老大,给我找了很多工作。他这个人四处跳巢,还给我说了几次工作。
只是我还想暂时留在成都,所以都拒绝了。那些外包做的都比较垃圾,做到后来基本有个小游戏框架了。版权问题可能不
能发布出来吧。
Author : Kevin Lynx
准备:
在这里本文将遵循上一篇文章的风格,只提TCP协议中的要点,这样我觉得可以更容易地掌握TCP。或者
根本谈不上掌握,对于这种纯理论的东西,即使你现在掌握了再多的细节,一段时间后也会淡忘。
在以后各种细节中,因为我们会涉及到分析一些TCP中的数据报,因此一个协议包截获工具必不可少。在
<TCP/IP详解>中一直使用tcpdump。这里因为我的系统是windows,所以只好使用windows平台的tcpdump,
也就是WinDump。在使用WinDump之前,你需要安装该程序使用的库WinpCap。
关于WinDump的具体用法你可以从网上其他地方获取,这里我只稍微提一下。要让WinDump开始监听数据,
首先需要确定让其监听哪一个网络设备(或者说是网络接口)。你可以:
windump -D
获取当前机器上的网络接口。然后使用:
windump -i 2
开始对网络接口2的数据监听。windump如同tcpdump(其实就是tcpdump)一样支持过滤表达式,windump
将会根据你提供的过滤表达式过滤不需要的网络数据包,例如:
windump -i 2 port 4000
那么windump只会显示端口号为4000的网络数据。
序号和确认号:
要讲解TCP的建立过程,也就是那个所谓的三次握手,就会涉及到序号和确认号这两个东西。翻书到TCP
的报文头,有两个很重要的域(都是32位)就是序号域和确认号域。可能有些同学会对TCP那个报文头有所
疑惑(能看懂我在讲什么的会产生这样的疑惑么?),这里我可以告诉你,你可以假想TCP的报文头就是个
C语言结构体(假想而已,去翻翻bsd对TCP的实现,肯定没这么简单),那么大致上,所谓的TCP报文头就是:
typedef struct _tcp_header
{
/**//// 16位源端口号
unsigned short src_port;
/**//// 16位目的端口号
unsigned short dst_port;
/**//// 32位序号
unsigned long seq_num;
/**//// 32位确认号
unsigned long ack_num;
/**//// 16位标志位[4位首部长度,保留6位,ACK、SYN之类的标志位]
unsigned short flag;
/**//// 16位窗口大小
unsigned short win_size;
/**//// 16位校验和
short crc_sum;
/**//// 16位紧急指针
short ptr;
/**//// 可选选项
/// how to implement this ?
} tcp_header;
那么,这个序号和确认号是什么?TCP报文为每一个字节都设置一个序号,觉得很奇怪?这里并不是为每一
字节附加一个序号(那会是多么可笑的编程手法?),而是为一个TCP报文附加一个序号,这个序号表示报文
中数据的第一个字节的序号,而其他数据则是根据离第一个数据的偏移来决定序号的,例如,现在有数据:
abcd。如果这段数据的序号为1200,那么a的序号就是1200,b的序号就是1201。而TCP发送的下一个数据包
的序号就会是上一个数据包最后一个字节的序号加一。例如efghi是abcd的下一个数据包,那么它的序号就
是1204。通过这种看似简单的方法,TCP就实现了为每一个字节设置序号的功能(终于明白为什么书上要告诉
我们‘为每一个字节设置一个序号’了吧?)。注意,设置序号是一种可以让TCP成为’可靠协议‘的手段。
TCP中各种乱七八糟的东西都是有目的的,大部分目的还是为了’可靠‘两个字。别把TCP看高深了,如果
让你来设计一个网络协议,目的需要告诉你是’可靠的‘,你就会明白为什么会产生那些乱七八糟的东西了。
接着看,确认号是什么?因为TCP会对接收到的数据包进行确认,发送确认数据包时,就会设置这个确认号,
确认号通常表示接收方希望接收到的下一段报文的序号。例如某一次接收方收到序号为1200的4字节数举报,
那么它发送确认报文给发送方时,就会设置确认号为1204。
大部分书上在讲确认号和序号时,都会说确认号是序号加一。这其实有点误解人,所以我才在这里废话了
半天(高手宽容下:D)。
开始三次握手:
如果你还不会简单的tcp socket编程,我建议你先去学学,这就好比你不会C++基本语法,就别去研究vtable
之类。
三次握手开始于客户端试图连接服务器端。当你调用诸如connect的函数时,正常情况下就会开始三次握手。
随便在网上找张三次握手的图:

如前文所述,三次握手也就是产生了三个数据包。客户端主动连接,发送SYN被设置了的报文(注意序号和
确认号,因为这里不包含用户数据,所以序号和确认号就是加一减一的关系)。服务器端收到该报文时,正
常情况下就发送SYN和ACK被设置了的报文作为确认,以及告诉客户端:我想打开我这边的连接(双工)。客户
端于是再对服务器端的SYN进行确认,于是再发送ACK报文。然后连接建立完毕。对于阻塞式socket而言,你
的connect可能就返回成功给你。
在进行了铺天盖地的罗利巴索的基础概念的讲解后,看看这个连接建立的过程,是不是简单得几近无聊?
我们来实际点,写个最简单的客户端代码:
sockaddr_in addr;
memset( &addr, 0, sizeof( addr ) );
addr.sin_family = AF_INET;
addr.sin_port = htons( 80 );
/**//// 220.181.37.55 addr.sin_addr.s_addr = inet_addr( "220.181.37.55" );
printf( "%s : connecting to server.\n", _str_time() );
int err = connect( s, (sockaddr*) &addr, sizeof( addr ) );
主要就是connect。运行程序前我们运行windump:
windump -i 2 host 220.181.37.55
00:38:22.979229 IP noname.domain.4397 > 220.181.37.55.80: S 2523219966:2523219966(0) win 65535 <mss 1460,nop,nop,sackOK>
00:38:23.024254 IP 220.181.37.55.80 > noname.domain.4397: S 1277008647:1277008647(0) ack 2523219967 win 2920 <mss 1440,nop,nop,sackOK>
00:38:23.024338 IP noname.domain.4397 > 220.181.37.55.80: . ack 1 win 65535
如何分析windump的结果,建议参看<tcp/ip详解>中对于tcpdump的描述。
建立连接的附加信息:
虽然SYN、ACK之类的报文没有用户数据,但是TCP还是附加了其他信息。最为重要的就是附加的MSS值。这个
可以被协商的MSS值基本上就只在建立连接时协商。如以上数据表示,MSS为1460字节。
连接的意外:
连接的意外我大致分为两种情况(也许还有更多情况):目的主机不可达、目的主机并没有在指定端口监听。
当目的主机不可达时,也就是说,SYN报文段根本无法到达对方(如果你的机器根本没插网线,你就不可达),
那么TCP收不到任何回复报文。这个时候,你会看到TCP中的定时器机制出现了。TCP对发出的SYN报文进行
计时,当在指定时间内没有得到回复报文时,TCP就会重传刚才的SYN报文。通常,各种不同的TCP实现对于
这个超时值都不同,但是据我观察,重传次数基本上都是3次。例如,我连接一个不可达的主机:
12:39:50.560690 IP cd-zhangmin.1573 > 220.181.37.55.1024: S 3117975575:3117975575(0) win 65535 <mss 1460,nop,nop,sackOK>
12:39:53.538734 IP cd-zhangmin.1573 > 220.181.37.55.1024: S 3117975575:3117975575(0) win 65535 <mss 1460,nop,nop,sackOK>
12:39:59.663726 IP cd-zhangmin.1573 > 220.181.37.55.1024: S 3117975575:3117975575(0) win 65535 <mss 1460,nop,nop,sackOK>
发出了三个序号一样的SYN报文,但是没有得到一个回复报文(废话)。每一个SYN报文之间的间隔时间都是
有规律的,在windows上是3秒6秒9秒12秒。上面的数据你看不到12秒这个数据,因为这是第三个报文发出的
时间和connect返回错误信息时的时间之差。另一方面,如果连接同一个网络,这个间隔时间又不同。例如
直接连局域网,间隔时间就差不多为500ms。
(我强烈建议你能运行windump去试验这里提到的每一个现象,如果你在ubuntu下使用tcpdump,记住sudo :D)
出现意外的第二种情况是如果主机数据包可达,但是试图连接的端口根本没有监听,那么发送SYN报文的这
方会收到RST被设置的报文(connect也会返回相应的信息给你),例如:
13:37:22.202532 IP cd-zhangmin.1658 > 7AURORA-CCTEST.7100: S 2417354281:2417354281(0) win 65535 <mss 1460,nop,nop,sackOK>
13:37:22.202627 IP 7AURORA-CCTEST.7100 > cd-zhangmin.1658: R 0:0(0) ack 2417354282 win 0
13:37:22.711415 IP cd-zhangmin.1658 > 7AURORA-CCTEST.7100: S 2417354281:2417354281(0) win 65535 <mss 1460,nop,nop,sackOK>
13:37:22.711498 IP 7AURORA-CCTEST.7100 > cd-zhangmin.1658: R 0:0(0) ack 1 win 0
13:37:23.367733 IP cd-zhangmin.1658 > 7AURORA-CCTEST.7100: S 2417354281:2417354281(0) win 65535 <mss 1460,nop,nop,sackOK>
13:37:23.367826 IP 7AURORA-CCTEST.7100 > cd-zhangmin.1658: R 0:0(0) ack 1 win 0
可以看出,7AURORA-CCTEST.7100返回了RST报文给我,但是我这边根本不在乎这个报文,继续发送SYN报文。
三次过后connect就返回了。(数据反映的事实是这样)
关于listen:
TCP服务器端会维护一个新连接的队列。当新连接上的客户端三次握手完成时,就会将其放入这个队列。这个队
列的大小是通过listen设置的。当这个队列满时,如果有新的客户端试图连接(发送SYN),服务器端丢弃报文,
同时不做任何回复。
总结:
TCP连接的建立的相关要点就是这些(or more?)。正常情况下就是三次握手,非正常情况下就是SYN三次超时,
以及收到RST报文却被忽略。
Author : Kevin Lynx
TCP是TCP/IP协议簇中传输层上的一种网络协议,它是一种面向连接的、可靠的协议。为了提供这种可靠性,
TCP实现了各种有效的机制、算法。为了从一种宏观的角度去了解这个协议,这里先大致地提一下与之相关
的概念。
1. 什么是‘面向连接的’?
引用<TCP/IP协议详解>中的概念:
面向连接意味着两个使用TCP的应用(通常是一个客户和一个服务器)在彼此交换数据之前必须先建立
一个TCP连接。
2. 什么是‘三次握手’?
在建立TCP连接之前,两个使用TCP的应用需要交换三次网络数据。这三个数据包的来往也就是所谓的‘
三次握手’。
3. 报文段segment
我们说TCP是流式的网络协议,那是因为,应用程序可以一直往TCP写数据,无论你是逐byte,还是write
a chunk,TCP对应用传给它的数据进行缓冲,直到缓冲数据达到一定尺寸才发送。可以看出,对于应用
而言,TCP就像是stream的。但事实上,在TCP层,数据还是以块为单位的。这个块也就是所谓的报文段
segment。
4. 什么是MTU?
MTU即最大传输单元(Maximum Transmission Unit,MTU)是指一种通信协议的某一层上面所能通过的
大数据报大小(以字节为单位)。我个人目前的理解认为,MTU是一个网络在硬件层次上所允许的最大
数据包大小,例如以太网大概是1500字节。
5. 什么是MSS?
MSS即最大报文段大小(Maximum Segment Size),它是指TCP中一个报文段上附加的用户数据的最大大小。
这里稍微说下应用层发送某个数据包时整个TCP/IP协议栈的操作过程:应用层将自己的用户数据传给TCP
层(传输层),TCP在这些数据前添加自己的协议头(简单地理解为附加一些数据),然后将数据交给
IP层(网络层),IP层附加自己的协议头,以此类推。
虽然MSS意思是最大报文段大小,但事实上它是排除了协议头的用户数据。
6. MTU and MSS ?
可以简单地给你一个这样的公示:mss = mtu - tcp_header_size - ip_header_size。
而通常,IP协议附加的协议头大小和TCP的协议头大小都是20字节,所以通常的MSS为1460字节。
注意,这里说的数字并不见得正确,因为MSS是可以被协商的。各种协议头也可能被添加附加数据,但是
他们的关系是这样的。
7. 什么是窗口大小?
找本TCP的书看下TCP数据包的包头(本文多次使用数据包、报文的概念,我这里说的都是一样的),你会
发现那个16位的窗口大小。
窗口这个域对于整个TCP协议都很重要。简单地说,窗口大小是指接收端的接收缓存的大小。上面说了,应用
在发数据的时候,TCP会缓存这些数据,稍后发送。接收数据时也一样,TCP接收数据并缓存起来,直到应用
调用recv之类的函数取数据时,TCP才将这些缓存数据清除。
TCP发送端会根据TCP接收端那个接收缓存大小决定发送多少数据(如何知道这个缓存大小?稍后给概念)。
这样,TCP接收端的接收缓存才不至于缓冲溢出。
8. 提供可靠性的方法之一:ACK确认?
这里还不敢提序号、确认号、延时ACK等乱七八糟的东西。我只能告诉你,当TCP发送某些数据给TCP接收方
时,TCP接收方会发回一个确认报文。TCP发送方收到这个确认报文后,就可以确认刚才发送的数据包成功到达。
为什么这个确认报文叫ACK确认(貌似是我临时给的概念:D)?再翻到TCP包头结构那张图,ACK是TCP包头中
的1bit标志位,如同SYN、PSH、RST之类的标志一样,这些标志都有一个专有的用途。当ACK标志位被设置为1
时,我就称其为ACK确认标志,因为ACK就是用于确认报文段的。
在上面所说的窗口大小中,我提到,发送方如何知道接收方的接收缓存大小呢?这也是通过确认报文段实现:
当接收方接收到数据后,发送ACK确认数据包给发送方,就设置包头中的窗口域。
9. 提供可靠性的方法之二:各种定时器
TCP中会设置很多计时器,这些定时器大多用于超时重传(老半天得不到回应,所以重传数据)。
10.什么是全双工?
全双工就是你可以同时在一个TCP连接上进行数据的发送和接收。这种双工特性也促使了关闭TCP连接时的四次
握手。
11.TODO : more concepts...
这里我尽量简单地介绍一些TCP中的概念,希望可以让你有概括性的了解。预计下一节我会讲讲建立TCP连接的相关细节。
除了Stevens的<TCP/IP详解>,我推荐<The TCP/IP Guide>,据说是另一部TCP的权威之作。
预计新项目会选择lua或python之一作为游戏的脚本语言。以前草草地接触过这两门语言,对于语法,以及嵌入进C/C++程序都有点感性上的认识。可能是受《UNIX编程艺术》中KISS原则的影响,现在总喜欢简洁的东西。所以我个人比较偏向于使用lua。
这两天翻了下网络上的资料,在lua的wiki上看到一篇比较lua和python的文章,草草地翻译出要点:
Python:
1. 扩展库很多,资料很多
2. 数值计算比较强大,支持多维数组,而lua没有数组类型
3. 本身带的c类型(?)支持处理动态链接库,不需要进行C封装(C扩展)
4. 远程调试器,似乎lua扩展工具支持
5. 自然语言似的语法
6. 对于string和list的支持,lua可以通过扩展库实现
7. 对unicode的支持
8. 空格敏感(代码不忽略空格),这其实可以使python的代码风格看起来更好一点
9. 内建位操作,lua可以通过扩展库支持
10.语言本身对错误的处理要好些,可以有效减少程序错误
11.初级文档比lua多
12.对面向对象支持更好
Lua:
1. 比python小巧很多(包括编译出来的运行时库)
2. 占用更小的内存
3. 解释器速度更快
4. 比python更容易集成到C语言中
5. 对于对象不使用引用计数(引用计数会导致更多的问题?)
6. lua早期定位于一种配置语言(作为配置文件),因此比起python来更容易配置数据
7. 语言更漂亮(nice)、简单(simple)、强大(powerful)。
8. lua支持多线程,每个线程可以配置独立的解释器,因此lua更适合于集成进多线程程序
9. 对空格不敏感,不用担心编辑器会将tab替换成空格
Useful Comments:
1. Everything is an object allocated on the heap in Python, including numbers. (So 123+456 creates a new heap object).
2. lua对于coroutine的支持更适用于嵌入进游戏,虽然python也有,但是并没有包含进核心模块
3.Python was a language better suited to Game AI
本来想去找点对于python的正面资料(嵌入进游戏这方面),但是居然没找到。客观地说如果单独用python做应用,python还是很有优势。现在心意已决,应该向leader推荐lua。
ps,希望能补充以上两种语言的特点。