#
原文地址:http://codemacro.com/2012/07/18/start-to-write-tips/
回首上篇博客的发表时间,又2个月时间过去了。在我博客生涯的过去两三年里,总会有好几个月的时间没有编写任何文章。我觉得这真是一个不好的习惯。这个情况的产生,有很多原因。例如自己太懒、工作偶尔忙、自己偶尔处于混沌时期、自己偶尔怀疑人生,如是种种。但最大的原因还是,不敢写。
在刚出来工作那会,作为一个懵懂的青年,接触个什么新技术都内心激动骄傲,然后就特别有动力将所学记录下来,注意下言辞还能折腾个像那么回事的教程出来。后来慢慢地,我就觉得,这些东西太肤浅。先别说教人用个什么IDE,配置个什么数据库,就算你是学个新语言,好好研究下TCP,甚至还能折腾个IOCP框架,这些都还是他妈的特肤浅。你说任何一个有那么点经验和学习能力的程序员,谁花点时间整不出来这些?谁他妈要你在这里装逼卖萌,甚至贻笑大方。除此之外,我个人也觉得无聊了。
另一方面我觉得写博客还有个好处就是帮助自己记录技术,以便将来万一又需要曾经学习过的技术了,回头温习一下就好。但是后来慢慢地我又觉得,这也是没必要的事情。因为反正需要这个技术的时候,也花不了多少时间。
基于这些乱七八糟的原因,我虽然经常打开自己的博客,看看有没人评论啊,留言啊,但发表博客的频率始终上不去。
后来呢,在google reader上断断续续也看了些别的程序员的故事。例如有傻逼坚持1年每天一篇博客,后来竟然写了本书;例如有傻逼坚持每天翻译一篇英文文章。我琢磨着这些人该有多么大的毅力啊,就算是翻译文章,这从找文章筛选文章到最好发表出来这尼玛又该睡觉了啊亲。心生佩服之余,我觉得自己应该向这些傻逼们学习。作为一个已经没有那么多青年时光的青年,试想以后每天下班回家带娃的日子,而曾经竟碌碌无为地磨过每一个工作日耍过每一个工作日晚上,这是件比带娃更悲剧的事情。
所以,我也决定坚持干一件虽一日不用一次但也望每周那么几次的事情。我决定在博客上记录一些编程方面的技巧(tips),集中于某个小问题的解决、某个小功能的实现。这些技巧相比前文说的,就更肤浅了,肤浅到你一google出来的结果你都吓一跳的程度。但是我依然觉得这是有用的,就像我用rails做网站,每一个小功能我都得google一遍,然后积累于心,然后一段时间后忘掉。为了不忘掉,为了查阅起来简单,我决定记录下来。但是仅靠我自己的经验,是肯定无法做到频繁地更新的,所以,我决定上stackoverflow上随机找些问题/答案翻译出来。stackoverflow非常适合满足这种需求,我发现我google某个rails技巧时,基本是从stackoverflow上获取下来的。
这样,我的博客http://codemacro.com的rss输出可能会繁杂点,这对于某些人而言估计会起到恶心的效果。而我自己的博客可能也会变得不那么像个人博客。我也想过单独做个网站出来,但仔细想想还是制止自己少瞎折腾了。如有建议欢迎批评。
好,就这样,没了。
原文链接:http://codemacro.com/2012/05/10/tolua-api/
我们使用tolua++手工绑定c/c++接口到lua中,在绑定的接口实现里,就需要取出传入的参数。tolua++中提供了一系列tolua_toxxx函数,例如:
lua_Number tolua_tonumber(lua_State *L, int narg, lua_Number def)
const char *tolua_tostring(lua_State *L, int narg, const char *def)
这些函数都有一个def参数。乍一看,这些函数使用起来很简单。传入lua_State,传入参数在栈中的位置,然后再传一个失败后返回的默认值。
我重点要说的是这里这个失败,按正常程序员的理解,针对lua而言,什么情况下算失败呢?lua语言里函数参数支持不传,此时实参为nil,将nil转换为一个c类型必然失败;参数类型不正确算不算失败?你传一个user data,c里按数字来取,这也算失败。
这么简单的API还需要多纠结什么呢?然后我们浩浩荡荡地写了上百个接口,什么tolua_tostring/tolua_tonumber的使用少说也有500了吧?
然后有一天,服务器宕机了,空指针:
/* 失败返回"",还能省空指针的判断 */
const char *name = tolua_tostring(L, 1, "");
if (name[0] == '\0') { /* 空串总得判断吧 */
...
}
跟踪后发现,脚本里传入的是nil,这里的name取出来是NULL,而不是”“(的地址)。然后吐槽了一下这个API,辛苦地修改了所有类似代码,增加对空指针的判断。我没有多想。
故事继续,有一天服务器虽然没宕机,但功能不正常了:
float angle = (float) tolua_tonumber(L, 1, 2 * PI);
...
这个意思是,这个函数的参数1默认是2*PI,什么是默认?lua里某函数参数不传,或传nil就是使用默认。因为不传的话,这个实参本身就是nil。但,tolua_tonumber的行为不是这样的,它的实现真是偷懒:
TOLUA_API lua_Number tolua_tonumber (lua_State* L, int narg, lua_Number def)
{
return lua_gettop(L)<abs(narg) ? def : lua_tonumber(L,narg);
}
TOLUA_API const char* tolua_tostring (lua_State* L, int narg, const char* def)
{
return lua_gettop(L)<abs(narg) ? def : lua_tostring(L,narg);
}
意思是,只有当你不传的时候,它才返回默认值,否则就交给lua的API来管,而lua这些API是不支持应用层的默认参数的,对于lua_tonumber错误时就返回0,lua_tostring错误时就返回NULL。
这种其行为和其带来的common sense不一致的API设计,实在让人蛋疼。什么是common sense呢?就像一个UI库里的按钮,我们都知道有click事件,hover事件,UI库的文档甚至都不需要解释什么是click什么是hover,因为大家看到这个东西,就有了共识,无需废话,这就是common sense。就像tolua的这些API,非常普通,大家一看都期待在意外情况下你能返回def值。但它竟然不是。实在不行,你可以模仿lua的check系列函数的实现嘛:
LUALIB_API lua_Number luaL_checknumber (lua_State *L, int narg) {
lua_Number d = lua_tonumber(L, narg);
if (d == 0 && !lua_isnumber(L, narg)) /* avoid extra test when d is not 0 */
tag_error(L, narg, LUA_TNUMBER);
return d;
}
即,根本不用去检查栈问题,直接在lua_tonumber之后再做包装检查。何况,lua需要你去检查栈吗?当你访问了栈外的元素时,lua会自动返回一个全局常量luaO_nilobject:
static TValue *index2adr(lua_State *L, int idx) {
...
if (o >= L->top) return cast(TValue*, luaO_nilobject);
}
另,程序悲剧也来源于臆想。
原文链接:http://codemacro.com/2012/04/25/game-server-info-2/
上一篇谈了一些关键技术的实现方案。本篇描述一些遇到的问题。
一
在策划制作完了几个职业后(主要是技能制作),大概去年年底公司内部进行了一次混战测试。30个角色在一个场景进行混战,测试结果从技术上来说非常不理想。首先是客户端和服务器都巨卡无比。服务器CPU一直是满负载状态。而客户端又频繁宕机。
我们关注的主要问题,是服务器CPU满负载问题。最开始,我通过日志初步定位为网络模块问题,因为逻辑线程表现不是那么差。然后考虑到技能过程中的特效、动作都是通过服务器消息驱动,并且本身特效和动作就比一般网游复杂,通过逐一屏蔽这一部分功能,最终确认确为网络模块导致。然后团队决定从两方面努力:重写网络模块,改善性能;改善技能实现机制,将表现类逻辑移到客户端。
至于网络模块,在后来才发现,虽然网络流量过高,但导致网络线程CPU满的原因竟然是网络模块自身的流量限制导致。而技能实现机制的改善,考虑到改动的成本,最终使用了一种RPC机制,让服务器脚本可以调用客户端脚本,并且支持传入复杂参数。然后策划通过一些关键数据在客户端计算出特效、动作之类。
此外,程序将更多的技能属性广播给客户端,一个客户端上保存了周围角色的技能数据,从而可以进行更多的客户端逻辑。这一块具体的修改当然还是策划在做(我们的脚本策划基本就是半个程序员)。后经测试,效果改善显著。
二
在策划制作了一个PVP竞技副本后,服务器在10V10测试过程中又表现出CPU负载较高的情况。这个问题到目前为止依然存在,只不过情况略微不同。
首先是触发器生命周期的问题。触发器自身包含最大触发次数、存留时间等需求,即当触发一定次数,或超过存留时间后,需要由程序自动删除;另一方面,触发器可以是定时器类型,而定时器也决定了触发器的生命周期。这一块代码写的非常糟糕,大概就是管理职责划分不清,导致出现对象自己删除自己,而删除后还在依赖自己做逻辑。
但这样的逻辑,最多就是导致野指针的出现。不过,这种混乱的代码,也更容易导致BUG。例如,在某种情况下触发器得不到自动删除了。但这个BUG并不是直接暴露的,直接暴露的,是CPU满了。我们的怪物AI在脚本中是通过定时器类触发器驱动的,每次AI帧完了后就注册一个触发器,以驱动下一次AI帧。由于这个BUG导致触发器没有被删除,从而导致服务器上触发器的数量急剧增加。但,这也就导致内存增长吧?
另一个巧合的原因在于,在当时的版本中,触发器是保存一个表里的,即定时器类触发器、属性类触发器、移动类触发器等都在一个表里。每次任意触发器事件发生时,例如属性改变,都会遍历这个表,检查其是否触发。
基于以上原因,悲剧就发生了。在这个怪物的AI脚本里,有行代码设置了怪物的属性。这会导致程序遍历该怪物的所有触发器。而这个怪物的触发器数量一直在增长。然后就出现了在很多游戏帧里出现过长的遍历操作,CPU就上去了。
找到这个问题了几乎花了我一天的时间。因为脚本代码不是我写的,触发器的最初版本也不是我写的。通过逐一排除可能的代码,最终竟然发现是一行毫不起眼的属性改变导致。这个问题的查找流程,反映了将大量逻辑放在脚本中的不便之处:查起问题来实在吃力不讨好。
修复了这个BUG后,我又对触发器管理做了简单的优化。将触发器列表改成二级表,将触发器按照类型保存成几个列表。每次触发事件时,找出对应类型的表遍历。
改进
除了修改触发器的维护数据结构外,程序还实现了一套性能统计机制,大概就是统计某个函数在一段时间内的执行时间情况。最初这套机制仅用于程序,但考虑到脚本代码在整个项目中的比例,又决定将其应用到脚本中。
这个统计需要在函数进入退出时做一些事情,C++中可以通过类对象的构建和析构完成,但lua中没有类似机制。最初,我使用了lua的调试库来捕获函数进入/退出事件,但后来又害怕这种方式本身存在效率消耗,就取消了。我们使用lua的方式,不仅仅是全局函数,还包括函数对象。而函数对象是没有名字标示的,这对于日志记录不是什么好事。为了解决这个问题,我只好对部分功能做了封装,并让策划显示填入函数对于的字符串标示。
除此之外,因为触发器是一种重要的敏感资源,我又加入了一个专门的触发器统计模块,分别统计触发器的类型数量、游戏对象拥有的触发器数量等。
END
到目前为止,导致服务器CPU负载过高,一般都是由BUG导致。这些BUG通常会造成一个过长的列表,然后有针对这个列表的遍历操作,从而导致CPU负载过高。更重要的,我们使用了这么多的脚本去开发这个游戏,如何找到一个更有效合理的监测方法,如何让程序框架更稳定,则是接下来更困难而又必须去面对的事情。
原文链接:http://codemacro.com/2012/04/23/game-server-info-1/
我们的逻辑服务器(Game Server,以下简称GS)主要逻辑大概是从去年夏天开始写的。因为很多基础模块,包括整体结构沿用了上个项目的代码,所以算不上从头开始做。转眼又快一年,我觉得回头总结下对于经验的积累太有必要。
整体架构
GS的架构很大程度取决于游戏的功能需求,当然更受限于上个项目的基础架构。基础架构包括场景、对象的关系管理,消息广播等。
需求
这一回,程序员其实已经不需要太过关心需求。因为我们决定大量使用脚本。到目前为止整个项目主要还是集中在技能开发上。而这个使用脚本的度,就是技能全部由策划使用脚本制作,程序员不会去编写某个具体技能,也不会提供某种配置方式去让策划通过配置来开发技能。这真是一个好消息,不管对于程序员而言,还是对于策划而言。但后来,我觉得对于这一点还是带来了很多问题。
实现
基于以上需求,程序员所做的就是开发框架,制定功能实现方案。脚本为了与整个游戏框架交互,我们制定了“触发器“这个概念,大概就是一种事件系统。
这个触发器系统,简单来说,就是提供一种“关心“、”通知“的交互方式,也就是一般意义上的事件机制。例如,脚本中告诉程序它关心某个对象的移动,那么当程序中该对象产生移动时,就通知脚本。脚本中可以关心很多东西,包括对象属性,其关心的方式包括属性值改变、变大、变小,各种变化形式;对象开始移动,移动停止;对象碰撞,这个会单独谈谈;定时器等。
除了触发器系统外,还有个较大的系统是游戏对象的属性系统。对象的属性必然是游戏逻辑中策划最关心最容易改动的模块。既然我们程序的大方向是尽可能地不关心策划需求,所以对象属性在设计上就不可能去编写某个具体属性,更不会编写这个属性相关的逻辑功能。简单来说,程序为每个对象维护一个key-value表,也就是属性名、属性值表。该表的内容由脚本填入,脚本享有存取权限。然后脚本中就可以围绕某个属性来编写功能,而程序仅起存储作用。
第三,怪物AI模块。AI模块的设计在开发周期上靠后。同样,程序不会去编写某类AI的实现。程序提供了另一种简单的事件系统,这个系统其实就是一个调用脚本的方案。当关于某个怪物发生了某个事件时,程序调用脚本,传入事件类型和事件参数。这个事件分为两类:程序类和脚本类。脚本类程序不需关心,仅提供事件触发API。程序类事件非常有限:怪物创建、出生、删除。
除了以上三块之外,还有很多零散的脚本交互。例如游戏对象属性初始化,角色进入游戏,角色进入场景等。这些都无关痛痒。
接下来谈一些关键模块的实现。
定时器
整个GS的很多逻辑模块都基于这个定时器来实现。这个定时器接收逻辑模块的注册,在主循环中传入系统时间,定时器模块检查哪些定时器实例超时,然后触发调用之。这个主循环以每帧5ms的速率运行,也即帧率1000/5。
这个定时器是基于操作系统的时间。随着帧率的不同,它在触发逻辑功能时,就必然不精确。游戏客户端(包括单机游戏)在帧率这块的实现上,一般逻辑功能的计算都会考虑到一个dt(也就是一帧的时间差),例如移动更新,一般都是x = last_x + speed * dt。但,我们这里并没有这样做。我们的几乎所有逻辑功能,都没有考虑这个时间差。
例如,我们的移动模块注册了一个固定时间值的定时器,假设是200ms。理想情况下,定时器模块每200ms回调移动模块更新坐标。但现实情况肯定是大于200ms的更新频率,悲剧的是,移动模块每次更新坐标都更新一个固定偏移。这显然是不够精确的。
更悲剧的是,定时器的实现中,还可能出现跳过一些更新帧。例如,理论情况下,定时器会在系统时间点t1/t2/t3/t4分别回调某个逻辑模块。某一帧里,定时器大概在t1回调了某逻辑模块,而当该帧耗时严重时,下一帧定时器模块在计算时,其时间值为t,而t大于t4,此时定时器模块跳过t2/t3。相当于该逻辑模块少了2次更新。这对于移动模块而言,相当于某个对象本来在1秒的时间里该走5格,但实际情况却走了1格。
当然,当游戏帧率无法保证时,逻辑模块运行不理想也是情有可原的。但,不理想并不包含BUG。而我觉得,这里面是可能出现BUG的。如何改善这块,目前为止我也没什么方案。
移动
有很多更上层的模块依赖移动。我们的移动采用了一种分别模拟的实现。客户端将复杂的移动路径拆分为一条一条的线段,然后每个线段请求服务器移动。然后服务器上使用定时器来模拟在该线段上的移动。因为服务器上的阻挡是二维格子,这样服务器的模拟也很简单。当然,这个模块在具体实现上复杂很多,这里不细谈。
碰撞检测
我们的技能要求有碰撞检测,这主要包括对象与对象之间的碰撞。在最早的实现中,当脚本关心某个对象的碰撞情况时,程序就为该对象注册定时器,然后周期触发检测与周围对象的距离关系,这个周期低于100ms。这个实现很简单,维护起来也就很简单。但它是有问题的。因为它基于了一个不精确的定时器,和一个不精确的移动模块。
首先,这个检测是基于对象的当前坐标。前面分析过在帧率掉到移动更新帧都掉帧的情况下,服务器的对象坐标和理论情况差距会很大,而客户端基本上是接近正确情况的,这个时候做的距离检测,就不可能正确。另一方面,就算移动精确了,这个碰撞检测还是会带来BUG。例如现在检测到了碰撞,触发了脚本,脚本中注册了关心离开的事件。但不幸的是,在这个定时器开始检测前,这两个对象已经经历了碰撞、离开、再碰撞的过程,而定时器开始检测的时候,因为它基于了当前的对象坐标,它依然看到的是两个对象处于碰撞状态。
最开始,我们直觉这样的实现是费时的,是不精确的。然后有了第二种实现。这个实现基于了移动的实现。因为对象的移动是基于直线的(服务器上)。我们就在对象开始移动时,根据移动方向、速度预测两个对象会在未来的某个时间点发生碰撞。当然,对于频繁的小距离移动而言,这个预测从直觉上来说也是费时的。然后实现代码写了出来,一看,挺复杂,维护难度不小。如果效果好这个维护成本也就算了,但是,它依然是不精确的。因为,它也依赖了这个定时器。
例如,在某个对象开始移动时,我们预测到在200ms会与对象B发生碰撞。然后注册了一个200ms的定时器。但定时器不会精确地在未来200ms触发,随着帧率的下降,400ms触发都有可能。即便不考虑帧率下降的情况,它还是有问题。前面说过,我们游戏帧保证每帧至少5ms,本来这是一个限帧手段,目的当然是避免busy-loop。这导致定时器最多出现5ms的延迟。如果策划使用这个碰撞检测去做飞行道具的实现,例如一个快速飞出去的火球,当这个飞行速度很快的时候,这5ms相对于这个预测碰撞时间就不再是个小数目。真悲剧。
技能
虽然具体的技能不是程序写的,但正如把几乎所有具体逻辑交给策划写带来的悲剧一样:这事不是你干的,但你得负责它的性能。所以有必要谈谈技能的实现。
技能的实现里,只有一个技能使用入口,程序只需要在客户端发出使用技能的消息时,调用这个入口脚本函数。然后脚本中会通过注册一些触发器来驱动整个技能运作。程序员一直希望策划能把技能用一个统一的、具体的框架统一起来,所谓的变动都是基于这个框架来变的。但策划也一直坚持,他们心目中的技能是无法统一的。
我们的技能确实很复杂。一个技能的整个过程中,服务器可能会和客户端发生多次消息交互。在最初的实现中,服务器甚至会控制客户端的技能特效、释放动作等各种细节;甚至于服务器会在这个过程中依赖客户端的若干次输入。
下一篇我将谈谈一些遇到的问题。
原文链接http://codemacro.com/2012/04/20/blog-on-github/
最开始知道Github Page,是通过codertrace上的某些注册用户,他们的BLOG就建立在Github Page上,并且清一色的干净整洁(简陋),这看起来很酷。
Github提供了很多很合coder口味的东西,例如Gist,也包括这里提到的Page。Page并不是特用于建立博客的产品,它仅提供静态页面的显示。它最酷的地方,是通过Git的方式来让你管理这些静态页面。通过建立一个repository,并使用markdown语法来编写文章,然后通过Git来管理这些文章,你就可以自动将其发布出去。
当然,要搭建一个像样点的博客,使用Github Page还不太方便。这里可以使用Jekyll。Jekyll是一个静态网页生成器,它可以将你的markdown文件自动输出为对应的网页。而Github Page也支持Jekyll。
为了更方便地搭建博客,我还使用了Jekyll-bootstrap。jekyll-bootstrap其实就是一些模板文件,提供了一些博客所需的特殊功能,例如评论,访问统计。
基于以上,我就可以像在Github上做项目一样,编写markdown文章,然后git push即可。可以使用jekyll --server在本地开启一个WEB SERVER,然后编写文章时,可以在本地预览。
Github Page还支持custom domain,如你所见,我将我的域名codemacro.com绑定到了Github Page所提供的IP,而不再是我的VPS。你可以通过kevinlynx.github.com或者codemacro.com访问这个博客。
当然实际情况并没有那么简单,例如并没有太多的theme可供选择,虽然jekyll-bootstrap提供了一些,但还是太少。虽然,你甚至可以fork别人的jekyll博客,使用别人定制的theme,但,这对于一个不想过于折腾的人说,门槛也过高了点。
jekyll-bootstrap使用了twitter的bootstrap css引擎,但我并不懂这个,所以,我也只能定制些基本的页面样式。
1年前我编写了ext-blog,并且在我的VPS上开启了codemacro.com这个博客。本来,它是一个ext-blog很好的演示例子,但维护这个博客给我带来诸多不便。例如,每次发布文章我都需要使用更早前用lisp写的cl-writer,我为什么就不愿意去做更多的包装来让cl-writer更好用?这真是一个垃圾软件,虽然它是我写的。另一方面,codemacro.com使用的主题,虽然是我抄的,但依然太丑,并且恶心。
更别说那个消耗我VPS所有内存的lisp解释器,以及那恶心的两位数字乘法的验证码---你能想象别人得有多强烈的留言欲望,才愿意开一个计算器?
说说codertrace.com。我其实写了篇关于codertrace.com的总结,但没有作为博客发布。做这个事情的结果,简单总结来说就是瞎JB折腾没有任何结果。我真的是个苦逼双子男,我每次做件事情都需要巨大的毅力才能让自己专注下去。
整个过程中,收到了些网友的邮件,看到了些评论,虽然不多。邮件/评论中有建议的,也有单纯的交流的,也有单纯鼓励的。我想说的是,thanks guys。
Anyway, try Github Page, save your VPS money :D.
简介
因为写 ext-blog 的原因,慢慢喜欢上github_ 。然后突然有一天产生了一个想法:如果可以把自己的博客_ 和 github主页 集中到一块展示给别人,会不会是一种很方便的自我简介方式?然后我就动手写了 codertrace.com 。
所以, codertrace.com 这个网站的作用就是用来集中让程序员炫耀的。它通过RSS抓取,将你的博客,github主页,或其他有RSS输出的信息集中到一块展示给别人。这些信息通常就可以代表一个程序员。
如果你是程序员,也不妨试试。

技术信息
不知道哪个王八蛋说的,程序员每一年得学一门新语言。我2010年末接触了Lisp,然后莫名其妙地写了 ext-blog ,又莫名其妙地在2011年末接触了Ruby。因为大学期间太痴迷C++,我勤奋努力,几乎通晓这门语言的各种细节;后来又稍微实践了下编译原理。在这若干年间,断断续续也接触过其他脚本类语言,我甚至在android上用java写过几个 小应用 。基于这些积累,我发现我可以很快上手Ruby,然后再上手Rails,然后就有了 codertrace.com (当然还做过一些小的 APP )
所以, codertrace.com 就是一个Ruby on Rails的应用。当我用这货来做WEB的时候,我才发现曾经用Lisp写博客是多么geek。这种感觉就像你在用汇编写一个GUI程序一样。我的意思是,ruby/rails的世界里有太多现成的东西,但lisp的世界里没有。
而且,ruby是一个很爽的语言。我太喜欢它的closure语法,简洁,不需要加其他关键字就可以构造(例如其他语言map(function (item) xxxx end),或者map(lambda (item) xxx ))。但我不喜欢在使用的地方通过yield去调用---这就像一个hack。我更不喜欢ruby用proc去封装closure。好吧,这其实是我自我分裂,为什么我要把ruby看成一个函数式语言?
脚本语言真是太酷了。
服务器信息
我很穷。不管你信不信,我真的舍不得花1000RMB买个VPS来架设 codertrace.com 。目前, codertrace.com 架设在 heroku.com ,而且还使用的是免费服务。免费服务竟然只有5M数据库。 codertrace.com 后台为了异步抓取用户提供的RSS,还使用了一个单独的进程(delayed_job ruby gem)。这也不是免费的。
但ruby的世界里有太多现成的东西了,甚至有很多现成的库解决这里的两个问题:heroku_external_db,这个gem可以让codertrace使用heroku以外的数据库,然后我就在我的VPS上搭了个mysql,这下流量和网站响应速度悲剧了啊,你想你请求个页面,这个页面直接涉及到若干条数据库查询。而这些查询的请求和回应竟然是通过internet网络传输的。
workless,这个gem可以在有异步任务时,例如codertrace上读取RSS,就会自动开启这个worker进程,然后heroku开始计费,当没有任务时,它又自动关闭这个进程。虽然省了美元,但再一次让网站的响应速度打了折扣。
为了实现自定义域名,我需要将 codertrace.com 指向 heroku.com 提供的IP。但也许你会同我一样愤怒,因为它提供的几个IP都被GFW墙了!所以,目前的实现方案是,我将 codertrace.com 指向了我博客对应的VPS,然后在VPS上使用nginx反向代理到 heroku.com 提供的IP。即使如此,我最近甚至发现 codertrace.com 竟然神奇般地会域名解析错误,难道godaddy的name server也要被GFW和谐??
故事
作为一个宅男,在工作的若干年中,若干个假期我都用来打游戏,或者写程序。
所以,当这个成为习惯的时候, codertrace.com ,就顺理成章地消费了我今年的春节假期。我发现一个人窝在租的小房子里写代码是件很爽的事情。在当前这个社会环境下,你可以专注地去干件喜欢的事情,还不用处理各种生活琐事,真是太爽了。
但为什么我平时得不到这种感觉?因为,我,是一个没钱的程序员。我和我老婆租在一个标间里。在这样狭小的空间里,多个人就是多几倍干扰。这太残酷了。
末了
曾经我以为我很牛逼,曾经我以为程序员很牛逼。后来我慢慢发现自己很垃圾。我没有写出来过牛逼的程序,大概也没能力写。还记得那个程序员的故事吗?就是有个傻逼也以为程序员很牛逼,但不幸在一家非IT公司的IT部门工作,他的程序员同事的工作就是每周填个excel表格。他后来很绝望,因为他没有为世界贡献过任何代码。后来,这货丢下一切,坐上去某地的飞机走了。
| Author: |
Kevin Lynx |
|---|
| Date: |
9.29.2011 |
|---|
| Contact: |
kevinlynx at gmail dot com |
|---|
本文描述如何使用Lisp工具集搭建一个完整的个人博客站点。一个搭建好的例子站点可以参看我的个人博客:http://codemacro.com。
要搭建一个独立博客,需要两方面的支持。一是博客软件,二是根据选择的博客软件取得必须的“硬件“。例如我这里使用的是Lisp工具集,就需要一个可以完全控制的服务器,所以这里我需要一个VPS。当然,购买一个合适的域名也是必须的。以下将针对这些内容做描述。
获取VPS及域名
VPS提供商国内国外都有很多。我选择的是 rapidxen ,128M内存,1年70来美元,算是国外比较便宜的,速度上还过得去。
购买了VPS后,可以进入后台管理页面安装VPS操作系统。同样,因为我使用的是Lisp,我选择安装了Debian 6.0 squeeze (minimal)64位。实际上我更倾向于32位,因为我的PC系统就是32位,方便测试。安装系统非常简单,基本随意设置下即可。值得注意的是,除了修改root密码外,最好修改下ssh端口,具体设置方法可以另行搜索。此外,因为后面我会使用nginx作为HTTP前端服务器,为了方便安装nginx,最好更新下软件源列表,编辑etc/apt/source.list:
deb http://ftp.us.debian.org/debian squeeze main
deb http://packages.dotdeb.org stable all
deb-src http://packages.dotdeb.org stable all
deb http://php53.dotdeb.org stable all
deb-src http://php53.dotdeb.org stable all
购买VPS最主要的,就是获取到一个独立IP,如图:
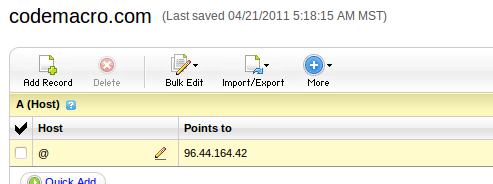
然后可以去购买域名。同样,也有很多域名服务商。这里我选择的是 godaddy ,我选择的域名codemacro.com一年11美元。购买了域名后,就需要将域名和VPS IP关联起来。详细设置也可以另行搜索。这里简要提下:在成功登入godaddy后,选择My Account,进入自己的域名,选择DNS Manager,然后添加域名映射即可,如图:
通过以上设置后,你购买的域名就成功指向你购买的VPS地址了。可以通过ping来观察是否指向成功。
使用Lisp构建博客系统
要在VPS上安装软件,首先需要SSH上你的VPS,例如:ssh -p 1234 root@codemacro.com。
这里使用的软件集包括:
实际上,可以完全使用Lisp作为Web服务器,但我担心效率问题(对个人博客而言完全没这回事),所以使用了nginx作为Web服务器前端,将hunchentoot放在后面。
安装nginx
在设置好debian软件源后,安装非常简单:
apt-get install nginx
安装完后,因为要将HTTP请求转发给Lisp服务器,所以需要修改下配置:
vi /etc/nginx/sites-avaiable/default
将/请求派发给Lisp服务器(假设监听于8000端口):
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
然后可以启动nginx了:
nginx
这个时候通过浏览器访问,会得到503 bad gateway的错误提示,因为hunchentoot还没开启。
安装Lisp相关软件
SBCL 同样可以通过apt直接安装:
apt-get instal sbcl
装好SBCL后,就可以进一步安装 quicklisp 。可以完全遵守quicklisp官方给的安装方法进行安装。大概就是先获取quicklisp.lisp文件,然后在SBCL中载入,根据提示即可。这里不再赘述。
安装好quicklisp后,就可以使用它安装很多Lisp软件/库了。quicklisp在安装一个Lisp库时,会自动下载并安装依赖库,就像apt-get一样。因为ext-blog并未收入到quicklisp的软件列表里,所以ext-blog需要手动安装。首先,在本地(非VPS上)获取ext-blog源码:
git clone git://github.com/kevinlynx/klprj.git
上面的git是我个人存东西用的,暂时没将ext-blog单独放置。进入到ext-blog目录。该目录下有几个方便的脚本可以用于博客管理。首先将ext-blog打包并上传到VPS上,例如:
./upload-dist.sh root@codemacro.com 1234 /home/test
该脚本会调用make-dist.sh将ext-blog全部源码打包,然后使用scp拷贝该文件及update-blog.sh到VPS指定的目录里(这里是/home/test),然后ssh上VPS。期间会两次输入VPS系统的密码。然后以下操作将在VPS上完成。
首先进入到刚才拷贝文件的目录:
cd /home/test
解压ext-blog.tar.gz:
tar xvf ext-blog.tar.gz
然后ext-blog被解压到/home/test/dist目录。进入此目录运行SBCL:
cd dist
sbcl
ext-blog目录下dep.lisp会使用quicklisp安装依赖库,进入SBCL后,载入该文件即可安装所有依赖库,这可能需要一点时间:
(load "dep.lisp")
在没有其他问题下,可以暂时退出SBCL完成一些其他准备工作。
ext-blog在最近的版本中加入了验证码生成功能,这需要一个pcf字体文件。因为字体文件一般较大,所以upload-dist.sh脚本并没有将该字体文件打包,所以这里需要手动复制,同样在本地的ext-blog目录下:
scp -P 1234 data/wenquanyi_12ptb.pcf root@codemacro.com:/home/test/dist/data/
另外,因为需要将Lisp解释器放置在系统后台执行,避免关掉SSH会话后终止SBCL进程,所以这里需要个工具gnu screen。可以使用apt-get来安装:
apt-get install screen
然后,一切就OK了。在VPS上可以使用ext-blog目录下的run-blog.sh来运行这个博客(首先确定VPS上的nginx开启):
./run-blog.sh
该脚本会使用screen在后台开启一个SBCL进程,并自动载入ext-blog,然后在8000端口上开启HTTP服务。这个启动过程可能会使用几十秒的时间,直接ctrl+z退出screen,这并不终止SBCL。一段时间后便可在浏览器里测试。
设置博客
如果一切正常,此时通过浏览器访问你的站点时,会被重定向到一个博客初始化页面,如下:
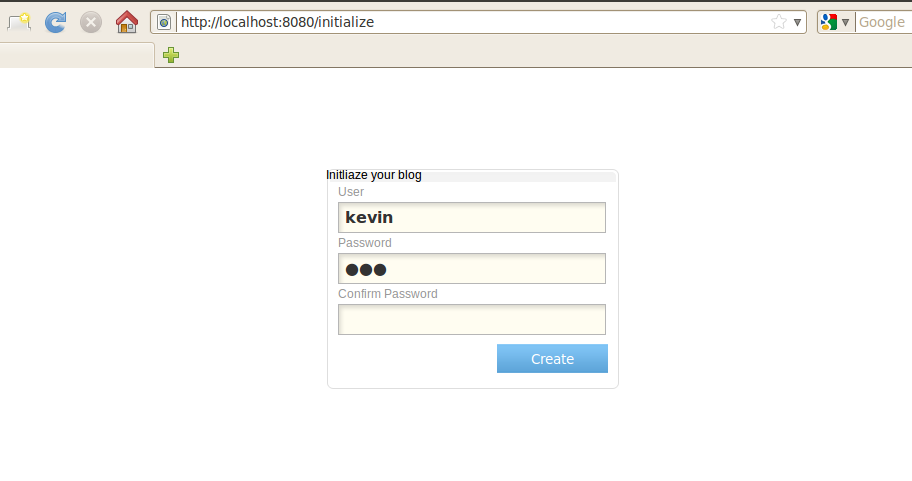
上图中我是在本机测试的,所以域名是localhost,希望不至于产生误解。初始化仅需输入用户名和密码即可,以后可通过该用户名和密码进入博客后台管理页面。完成这一步后,就可以进入博客后台管理页面做更多的设置,例如博客标题等。
ext-blog的管理页面使用了emlog博客系统的CSS及其他资源,因此有同学觉得管理页面很面熟就不奇怪了。ext-blog提供在线编辑博客功能,同时也支持简单的metaweblog API,因此可以使用一些博客客户端来发表文章(仅测过我自己写的博客客户端cl-writer)。
最后
本文描述较为粗略,主要是很多细节我自己也记不清。如有问题可以发邮件给我。
4月份的时候基于nuclblog写过一个简单的博客系统,但是因为写得丑,代码耦合度高,又有很多硬编码。当然nuclblog本身就写得不怎么样,所以6月分的时候就用Lisp写了新版的ext-blog。支持自定义主题,套个马甲上去像模像样。
ext-blog是一个使用Common Lisp编写的博客系统。基于之前基于nuclblog修改的经验,新的ext-blog最大程度地将博客本身的逻辑与前台渲染分离开,并且添加了对主题 (theme)的支持。制作新的主题可以随便找一个WordPress的主题,然后将php代码翻译成Lisp代码即可。
ext-blog底层代码非常少,其实基本的博客系统功能本来就不多。大部分功能都是在6月初完成。那个时候公司每天加班,下班回去后还写点Lisp代码。后来越整越累,就实在没那完善它的心情,一拖就拖到7月底,功能都还不算完善(至少还得加个rss导出吧?)。
关于主题开发
ext-blog主要有几个页面派发,对每个页面都派发给具体的主题模块,让其完成渲染。编写一个主题本质上就是生成html页面。在Lisp的世界中有很多库可以生成html。ext-blog的主题也不限制你使用哪一个html生成库。目前我自己移植的2个WordPress主题,使用的都是google的closure-template的Lisp移植版本,即cl-closure-template。closure-template会从模板产生出 Lisp函数,这一点是比同类库中的html-template方便一点。当然,作为一个模板语言,内置判断、循环则是必须的。
关于网络框架
世界上很多流行的语言都有流行的Web开发框架。Lisp方面,我最开始选用的是Weblocks,我甚至用它为公司写了个简单的订餐系统(这让一个程序员颇有自豪感)。但终究觉得Weblocks太难用,复杂,但没有实际功能。我甚至阅读了它80%的源代码,但依然获取不到如何更好使用它的思想。然后恰好我看了些Rails例子,虽然我不懂Ruby语言(依然可以看到很多语言特性有Lisp的影子),但看懂例子还不是大问题。后来我决定自己写个 Web框架,因为其实我主要需要的就是一个url派发(route),就像Rails那样。我甚至为此做了些详细设计,结果后来不幸发现Lisp里已经有一个类似的框架了,这就是Restas。ext-blog基于Restas。
关于后台管理
后台管理这东西其实可要可不要。就算没有后台管理,也可以通过增强RPC来实现。但并不是每个人都是Lisper,相信想了解ext-blog的人很大一部分都是想学习Lisp的人。综合来看,拥有一个后台管理功能,提供更友好的操作界面,也是非常有必要的。但我确实不擅长做前台美化的工作。幸运地是我将渲染和逻辑分离开了,后台管理也算是主题的一种。然后,我抄了emlog博客系统的后台管理,如前所说,也就是把php代码(虽然我也不懂php)翻译成lisp代码。
关于开源
ext-blog是完全有理由发布到common-lisp.net上的,甚至还可以加入到quicklisp的库列表里。但前提是排除尽可能多的 bug,写一系列英文文档,以及最重要的,对其进行长期维护。不幸的是我目前没有这个时间和精力。所以,只能暂时在这里发布下了。
要围观效果的请移步至我的独立博客:http://codemacro.com。关于ext-blog更正式的介绍请移步此篇:http://codemacro.com/view/8。
ps,之前订阅我独立博客的TX麻烦更换下rss地址:http://codemacro.com/feed,而博客主页也最好换成http://codemacro.com。
MMO游戏对象属性设计
| Author: |
Kevin Lynx |
|---|
| Date: |
5.2.2011 |
|---|
一般的MMORPG中,游戏对象主要包括怪物和玩家。这两类对象在经过游戏性方面的不断“进化”后,其属性数量及与之相关的逻辑往往会变得很巨大。如何将这一块做得既不损失效率,又能保证结构的灵活、清晰、可维护?本文将提供一种简单的结构。
原始结构
最原始的结构,极有可能为这样:
Player: +---------------+
| property-1 |
+---------------+
| property-2 |
+---------------+
| ... |
+---------------+
| operator-1 |
+---------------+
| operator-2 |
+---------------+
| ... |
+---------------+
也就是,一个对象为一个C++类,然后里面直接塞满了各种属性名,然后是针对这个属性的逻辑操作(函数)。其结果就是Player成为巨类。针对这个情况,一直以来我觉得可以使用一种简单的方法来拆分这个类。冠以官腔,称之为Entity-Component-based Desgin。产生这种想法和我的个人技术积累有一定关系,见下文。
Policy-based Design
Policy-based Design,基于决策的设计。这个概念来源于<Modern C++ Design>。虽然这本书讲述的是针对C++模板的使用及设计技巧。但这种思想依然被我潜意识般地用在其他地方。Policy大致来说就是一个小的组件(Component)。它努力不依赖于其他东西,它可能就是个简单的类,它拥有极少的数据结构,及针对这些数据的极少操作接口。举例而言,玩家MP的自动回复功能,就可封装为一个Policy。将许多Policy组合起来,就可完成一个复杂的功能。
这种思想还可指导很多程序结构方面的设计。例如在做功能的接口拆分时,就将每个函数设计得足够小,小到单纯地完成一个功能。一个功能的入口函数,就将之前实现的小函数全部组合起来,然后共同完成功能点。
当然,<Modern C++ Design>里的Policy在表现形式上有所不同。但其核心思想相同,主要体现在 组合 特点上。
Entity-Component-based Design
Entity-Component-based Design按照google到的文章,严格来说算是与OOP完全不同的软件设计方法。不过在这里它将按照我的意思重新被解释。
如果说Policy-based Design极大可能地影响着我们平时的细节编码,那么Entity-Component则是直接对游戏对象的结构设计做直接的说明。 一个游戏对象就是一个Entity。 Entity拥有很少的属性,也许仅包含一个全局标示的ID。 一个Component则是Entity的某个行为、或者说某个组成部分。 其实说白了,以玩家为例,一个玩家对象就是一个Entity,而一个MP的自动回复功能就可被包装为一个Component。这个Component可能包含若干与该功能相关的数据,例如回复时间间隔,每次的回复量等。我们往玩家对象这个Entity添加各种Component,也就是给玩家添加各种逻辑功能。
但是,Component之间可能会涉及到交互,玩家对象之外的模块可能也会与玩家内的某个Component交互。子功能点的拆分,不得不涉及到更多的胶水代码,这也算一种代价。
游戏对象属性设计
这份属性结构设计,基本就是参考了上面提到的设计思想。整个系统有如下组件:
Entity: +-------------------+
| property-table |
+-------------------+
| component-table |
+-------------------+
Property: +-------------------+
| observer-list |
+-------------------+
Component: +--------------------+
| logic-related data |
+--------------------+
| logic-related func |
+--------------------+
意即,所有Entity都包含一个属性表和组件表。这里的属性表并非硬编码的属性数据成员集合,而是一个key-value形式的表。Property包含一个观察者列表,其实就是一系列回调函数,但是这些观察者本质上也是组件,后面会提到。Component正如上文描述,仅包含Component本身实现的功能所需要的数据和函数。整个结构大致的代码如下:
class Entity {
private:
GUID id;
std::map<std::string, IComponent*> components;
std::map<std::string, Property*> properties;
};
class Property {
private:
std::string name;
Value val;
std::vector<IComponent*> observers;
};
class IComponent {
public:
virtual bool Operate (const Args &args) { return false; }
virtual void OnNotify (const Property &property, const Args &args) {}
protected:
std::string name;
Entity *entity;
};
属性本身是抽象的,这完全是因为我们将属性统一地放在了一个表里。从而又导致属性的值也需要继续阅读
多重继承和void*的糗事
| Author: | Kevin Lynx |
|---|
| Date: | 4.30.2011 |
|---|
C++为了兼容C,导致了不少语言阴暗面。Bjarne Stroustrup在<D&E>一书里也常为此表现出无奈。另一方面,强制转换也是C++的一大诟病。但是,因为我们的应用环境总是那么“不
纯”,所以也就常常导致各种问题。
本文即描述了一个关于强制转换带来的问题。这个问题几年前我曾遇到过(<多线程下vc2003,vc2005对虚函数表处理的BUG?>),当时没来得及深究。深究C++的某些语法,实在是件辛苦事。所以,这里也不提过于诡异的用法。
问题
考虑下面非常普通的多重继承代码:
class Left {
public:
virtual void ldisplay () {
printf ("Left::ldisplay\n");
}
};
class Right {
public:
virtual void rdisplay () {
printf ("Right::rdisplay\n");
}
};
class Bottom : public Left, public Right {
public:
virtual void ldisplay () {
printf ("Bottom::ldisplay\n");
}
};
这样子的代码在我们的项目中很容易就会出现,例如:
class BaseObject;
class EventListener;
class Player : public BaseObject, public EventListener
别紧张,我当然不会告诉你这样的代码是有安全隐患的。但它们确实在某些时候会出现隐患。在我们的C++项目中,也极有可能会与一些纯C模块打交道。在C语言里,极有肯能出现以
下的代码:
typedef void (*allocator) (void *u);
void set_allocator (allocator alloc, void *u);
之所以使用回调函数,是出于对模块的通用性的考虑。而在调用回调函数时,也通常会预留一个user data的指针,用于让应用层自由地传递数据。
以上关于多重继承和void*的使用中,都属于很常规的用法。但是当它们遇到一起时,事情就悲剧了。考虑下面的代码:
Bottom *bobj = new Bottom(); // we HAVE a bottom object
Right *robj = bobj; // robj point to bobj?
robj->rdisplay(); // display what ?
void *vobj = bobj; // we have a VOID* pointer
robj = (Right*) vobj; // convert it back
robj->rdisplay(); // display what?
这里的输出结果是什么呢?:
Right::rdisplay
Bottom::ldisplay // !!!!
由void*转回来的robj调用rdisplay时,却调用了莫名其妙的Bottom::ldisplay!
多重继承类的内存布局
类对象的内存布局,并不属于C++标准。这里仅以vs2005为例。上面例子中,Bottom类的内存布局大概如下:
+-------------+
| Left_vptr |
+-------------+
| Left data |
+-------------+
| Right_vptr |
+-------------+
| Right data |
+-------------+
| Bottom data |
+-------------+
与单继承不同的是,多重继承的类里,可能会包含多个vptr。当一个Bottom对象被构造好时,其内部的两个vptr也被正确初始化,其指向的vtable分别为:
Left_vptr ---> +---------------------+
| 0: Bottom::ldisplay |
+---------------------+
Right_vptr ---> +---------------------+
| 0: Right::rdisplay |
+---------------------+
转换的内幕
类体系间的转换
隐式转换相比强制转换而言,一定算是优美的代码。考虑如下代码的输出:
Bottom *bobj = new Bottom();
printf ("%p\n", bobj);
Right *robj = bobj;
printf ("%p\n", robj);
其输出结果可能为:
003B5DA0
003B5DA4
结论就是,Right *robj = bobj;时,编译器返回了bobj的一个偏移地址。 从语言角度看,就是这个转换,返回了bobj中Right*的那一部分的起始地址。但编译器并不总是在bobj上加一个偏移,例如:
bobj = NULL;
Right *robj = bobj;
编译器不会傻到给你一个0x00000004的地址,这简直比NULL更无理。
void*转换
编译器当然有理由做上面的偏移转换。那是因为在编译阶段,编译器就知道bobj和Right之间的关系。这个偏移量甚至不需要在运行期间动态计算,或是从某个地方取。如果你看过上面代码对应的汇编指令,直接就是:
add eax, 4 ; 直接加 sizeof(Left),记住,Right在Left之后
void*就没那么幸运了。void*和Bottom没有任何关系,所以:
void *vobj = bobj; // vobj的地址和bobj完全相同
然后当你将vobj转换到一个Right*使用时:
robj = (Right*) vobj; // 没有偏移转换,robj == vobj == bobj
robj->rdisplay();
robj指向的是Bottom的起始地址,天啊,在我们学习C++时,我们可以说Bottom就是一个Left,也是一个Right,所谓的is kind of。但这里的悲剧在于,按照上面的逻辑,我们在使用Right时,其实应该使用Bottom里Right那一部分。 但现在这个转换,却让robj指向了Bottom里Left那一部分。
当调用 robj->rdisplay 时,编译器当然按照Right的内存布局,生成一个虚函数的调用指令,大概就是:
mov vptr, robj->[0] ;; vptr在robj起始地址处
mov eax, vptr[0] ;; rdisplay在vtable中位于第一个
mov ecx, robj
call eax
总而言之, robj->rdisplay 就是使用偏移0处的值作为vptr,然后使用vptr指向的vtable中第一个函数作为调用。
但,robj正指向bobj的起始地址,这个地址是放置Left_vptr的地方。这个过程,使用了Left_ptr,而Left_ptr指向的vtable中,第一个函数是什么呢?:
Left_vptr ---> +---------------------+
| 0: Bottom::ldisplay |
+---------------------+
正是Bottom::ldisplay!到这里,整个问题的原因就被梳理出来了。
;;END;;