我曾经写过一篇《谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词》(以下简称《谈谈Unicode编码》),在网上流传较广,我也收到不少朋友的反馈。本文探讨《谈谈Unicode编码》中未介绍或介绍较少的代码页、Surrogates等问题,补充一些Unicode资料,顺带介绍一下我最近编写的一个Unicode工具:UniToy。本文虽然是前文的补充,但在写作上尽量做到独立成篇。
标题中的“浅谈”是对自己的要求,我希望文字能尽量浅显易懂。但本文还是假设读者知道字节、16进制,了解《谈谈Unicode编码》中介绍过的字节序和Unicode的基本概念。
0 UniToy
UniToy是我编写的一个小工具。通过UniToy,我们可以全方位、多角度地查看Unicode,了解Unicode和语言、代码页的关系,完成一些文字编码的相关工作。本文的一些内容是通过UniToy演示的。大家可以从我的网站(www.fmddlmyy.cn)下载UniToy的演示版本。1 文字的显示
1.1 发生了什么?
我们首先以Windows为例来看看文字显示过程中发生了什么。用记事本打开一个文本文件,可以看到文件包含的文字:
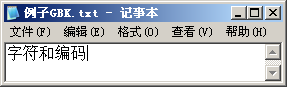
如果我们用UltraEdit或Hex Workshop查看这个文件的16进制数据,可以看到:
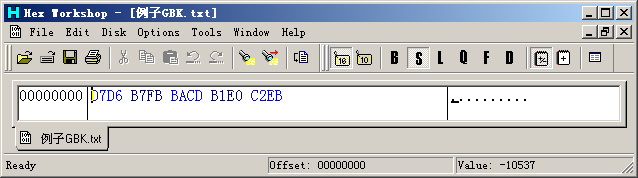
我们看到:文件“例子GBK.txt”有10个字节,依次是“D7 D6 B7 FB BA CD B1 E0 C2 EB”,这就是记事本从文件中读到的内容。记事本是用来打开文本文件的,所以它会调用Windows的文本显示函数将读到的数据作为文本显示。Windows首先将文本数据转换到它内部使用的编码格式:Unicode,然后按照文本的Unicode去字体文件中查找字体图像,最后将图像显示到窗口上。 总结一下前面的分析,文字的显示应该是这样的:
- 步骤1:文字首先以某种编码保存在文件中。
- 步骤2:Windows将文件中的文字编码映射到Unicode。
- 步骤3:Windows按照Unicode在字体文件中查找字体图像,画到窗口上。
所谓编码就是用数字表示字符,例如用D7D6表示“字”。当然,编码还意味着约定,即大家都认可。从《谈谈Unicode编码》中,我们知道Unicode也是一种文字编码,它的特殊性在于它是由国际组织设计,可以容纳全世界所有语言文字。而我们平常使用的文字编码通常是针对一个区域的语言、文字设计,只支持特定的语言文字。例如:在上面的例子中,文件“例子GBK.txt”采用的就是GBK编码。
如果上述3个步骤中任何一步发生了错误,文字就不能被正确显示,例如:
在Unicode被广泛使用前,有多少种语言、文字,就可能有多少种文字编码方案。一种文字也可能有多种编码方案。那么我们怎么确定文本数据采用了什么编码?
1.2 采用了哪种编码?
按照惯例,文本文件中的数据都是文本编码,那么它怎么表明自己的编码格式?在记事本的“打开”对话框上:
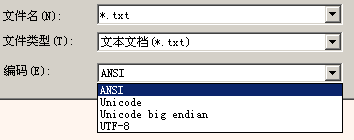
我们可以看到记事本支持4种编码格式:ANSI、Unicode、Unicode big endian、UTF-8。如果读者看过《谈谈Unicode编码》,对Unicode、Unicode big endian、UTF-8应该不会陌生,其实它们更准确的名称应该是UTF-16LE(Little Endian)、UTF-16BE(Big Endian)和UTF-8,它们是基于Unicode的不同编码方案。
在《谈谈Unicode编码》中介绍过,Windows通过在文本文件开头增加一些特殊字节(BOM)来区分上述3种编码,并将没有BOM的文本数据按照ANSI代码页处理。那么什么是代码页,什么是ANSI代码页?
2 代码页和字符集
2.1 Windows的代码页
2.1.1 代码页
代码页(Code Page)是个古老的专业术语,据说是IBM公司首先使用的。代码页和字符集的含义基本相同,代码页规定了适用于特定地区的字符集合,和这些字符的编码。可以将代码页理解为字符和字节数据的映射表。
Windows为自己支持的代码页都编了一个号码。例如代码页936就是简体中文 GBK,代码页950就是繁体中文 Big5。代码页的概念比较简单,就是一个字符编码方案。但要说清楚Windows的ANSI代码页,就要从Windows的区域(Locale)说起了。
2.1.2 区域和ANSI代码页
微软为了适应世界上不同地区用户的文化背景和生活习惯,在Windows中设计了区域(Locale)设置的功能。Local是指特定于某个国家或地区的一组设定,包括代码页,数字、货币、时间和日期的格式等。在Windows内部,其实有两个Locale设置:系统Locale和用户Locale。系统Locale决定代码页,用户Locale决定数字、货币、时间和日期的格式。我们可以在控制面板的“区域和语言选项”中设置系统Locale和用户Locale:
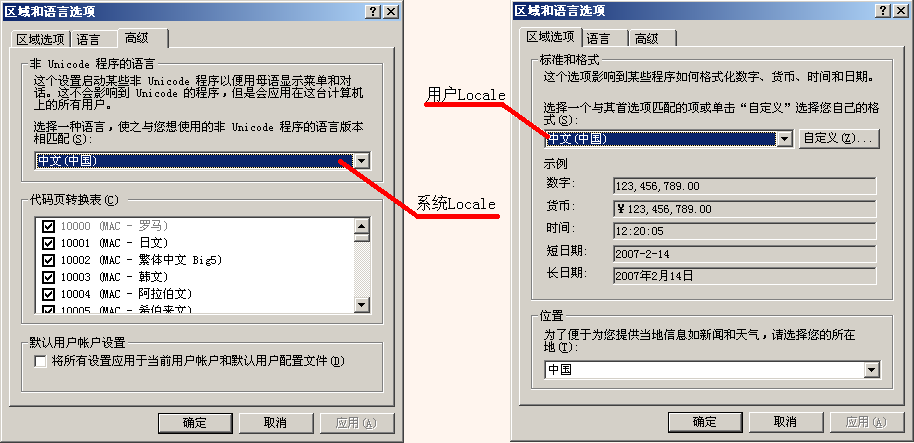
每个Locale都有一个对应的代码页。Locale和代码页的对应关系,大家可以参阅我的另一篇文章《谈谈Windows程序中的字符编码》的附录1。系统Locale对应的代码页被作为Windows的默认代码页。在没有文本编码信息时,Windows按照默认代码页的编码方案解释文本数据。这个默认代码页通常被称作ANSI代码页(ACP)。
ANSI代码页还有一层意思,就是微软自己定义的代码页。在历史上,IBM的个人计算机和微软公司的操作系统曾经是PC的标准配置。微软公司将IBM公司定义的代码页称作OEM代码页,在IBM公司的代码页基础上作了些增补后,作为自己的代码页,并冠以ANSI的字样。我们在“区域和语言选项”高级页面的代码页转换表中看到的包含ANSI字样的代码页都是微软自己定义的代码页。例如:
- 874 (ANSI/OEM - 泰文)
- 932 (ANSI/OEM - 日文 Shift-JIS)
- 936 (ANSI/OEM - 简体中文 GBK)
- 949 (ANSI/OEM - 韩文)
- 950 (ANSI/OEM - 繁体中文 Big5)
- 1250 (ANSI - 中欧)
- 1251 (ANSI - 西里尔文)
- 1252 (ANSI - 拉丁文 I)
- 1253 (ANSI - 希腊文)
- 1254 (ANSI - 土耳其文)
- 1255 (ANSI - 希伯来文)
- 1256 (ANSI - 阿拉伯文)
- 1257 (ANSI - 波罗的海文)
- 1258 (ANSI/OEM - 越南)
在UniToy中,我们可以按照代码页编码顺序查看这些代码页的字符和编码:
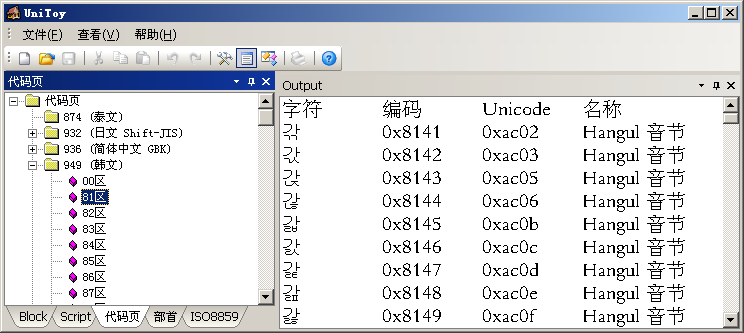
我们不能直接设置ANSI代码页,只能通过选择系统Locale,间接改变当前的ANSI代码页。微软定义的Locale只使用自己定义的代码页。所以,我们虽然可以通过“区域和语言选项”中的代码页转换表安装很多代码页,但只能将微软的代码页作为系统默认代码页。
2.1.3 代码页转换表
在Windows 2000以后,Windows统一采用UTF-16作为内部字符编码。现在,安装一个代码页就是安装一张代码页转换表。通过代码页转换表,Windows既可以将代码页的编码转换到UTF-16,也可以将UTF-16转换到代码页的编码。代码页转换表的具体实现可以是一个以nls为后缀的数据文件,也可以是一个提供转换函数的动态链接库。有的代码页是不需要安装的。例如:Windows将UTF-7和UTF-8分别作为代码页65000和代码页65001。UTF-7、UTF-8和UTF-16都是基于Unicode的编码方案。它们之间可以通过简单的算法直接转换,不需要安装代码页转换表。
在安装过一个代码页后,Windows就知道怎样将该代码页的文本转换到Unicode文本,也知道怎样将Unicode文本转换成该代码页的文本。例如:UniToy有导入和导出功能。所谓导入功能就是将任一代码页的文本文件转换到Unicode文本;导出功能就是将Unicode文本转换到任一指定的代码页。这里所说的代码页就是指系统已安装的代码页:
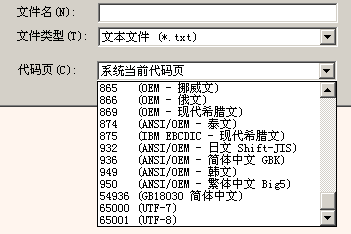
其实,如果全世界人民在计算机刚发明时就统一采用Unicode作为字符编码,那么代码页就没有存在的必要了。可惜在Unicode被发明前,世界各国人民都发明并使用了各种字符编码方案。所以,Windows必须通过代码页支持已经被广泛使用的字符编码。从这种意义看,代码页主要是为了兼容现有的数据、程序和习惯而存在的。
2.1.4 SBCS、DBCS和MBCS
SBCS、DBCS和MBCS分别是单字节字符集、双字节字符集和多字节字符集的缩写。SBCS、DBCS和MBCS的最大编码长度分别是1字节、两字节和大于两字节(例如4或5字节)。例如:代码页1252 (ANSI-拉丁文 I)是单字节字符集;代码页936 (ANSI/OEM-简体中文 GBK)是双字节字符集;代码页54936 (GB18030 简体中文)是多字节字符集。
单字节字符集中的字符都用一个字节表示。显然,SBCS最多只能容纳256个字符。
双字节字符集的字符用一个或两个字节表示。那么我们从文本数据中读到一个字节时,怎么判断它是单字节字符,还是双字节字符的首字符?答案是通过字节所处范围来判断。例如:在GBK编码中,单字节字符的范围是0x00-0x80,双字节字符首字节的范围是0x81到0xFE。我们顺序读取字节数据,如果读到的字节在0x81到0xFE内,那么这个字节就是双字节字符的首字节。GBK定义双字节字符的尾字节范围是0x40到0x7E和0x80到0xFE。
GB18030是多字节字符集,它的字符可以用一个、两个或四个字节表示。这时我们又如何判断一个字节是属于单字节字符,双字节字符,还是四字节字符?GB18030与GBK是兼容的,它利用了GBK双字节字符尾字节的未使用码位。GB18030的四字节字符的第一字节的范围也是0x81到0xFE,第二字节的范围是0x30-0x39。通过第二字节所处范围就可以区分双字节字符和四字节字符。GB18030定义四字节字符的第三字节范围是0x81到0xFE,第四字节范围是0x30-0x39。
2.2 代码页实例
2.2.1 实例一:GB18030代码页
1.1节的“错误2”中演示了一个全被显示成'?'的文件。这个文件的数据是:
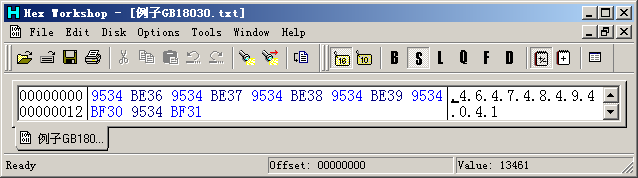
其实,这是一个包含了6个四字节字符的GB18030编码的文件。记事本按照GBK显示这些数据,而GB18030的四字节字符编码在GBK中是未定义的。Windows根据首字节范围判断出12个双字节字符,然后因为找不到匹配的转换而将其映射到默认字符'?'。使用UniToy按照GB18030代码页导入这个文件,就可以看到:
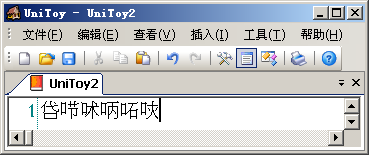
这个GB18030编码的文件是用UniToy创建的,编辑Unicode文本,然后导出到GB18030编码格式。
2.2.2 实例二:GBK和Big5的转换
综合使用UniToy的导入、导出功能就可以在任意两个代码页之间转换文本。其实,由于各代码页支持的字符范围不同,我们一般不会直接在代码页间转换文本。例如将以下GBK编码的文本:
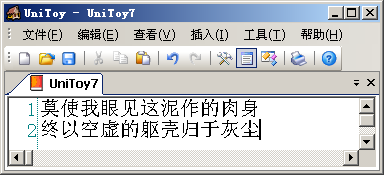
直接转换到Big5编码,就会看到:
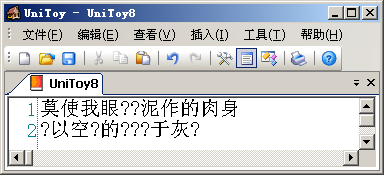
变成'?'的字符都是Big5编码不支持的简化字。在从Unicode转换到Big5编码时,由于Big5编码不支持这些字符,Windows就用默认字符'?'代替。在UniToy中,我们可以先将简体字转换到繁体字,然后再导出到Big5编码,就可以正常显示:
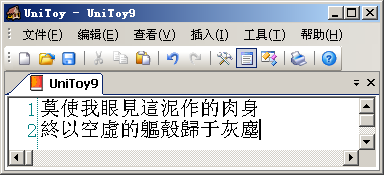
同理,将Big5编码的文本转换到GBK编码的步骤应该是:
- 将Big5编码的文本导入到Unicode文本;
- 将繁体的Unicode文本转换简体的Unicode文本;
- 将简体的Unicode文本导出到GBK文本。
2.3 互联网的字符集
2.3.1 字符集
互联网上的信息缤纷多彩,但文本依然是最重要的信息载体。html文件通过标记表明自己使用的字符集。例如:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
或者:
<meta http-equiv="charset" content="iso-8859-1">
那么我们可以使用哪些字符集(charset)呢?在IETF(互联网工程任务组)的网页上维护着一份可以在互联网上使用的字符集的清单:CHARACTER SETS。如果有新的字符集被登记,IETF会更新这份文档。
简单浏览一下,2006年12月7日的版本列出了253个字符集。其中也包括微软的CP1250 ~ CP1258,在这里它们不会被称作什么ANSI代码页,而是被简单地称作windows-1250、windows-1251等。其实在Unicode被广泛使用前,除了中日韩等大字符集,世界上,特别是西方使用最广泛的字符集应该是ISO 8859系列字符集。
2.3.2 ISO 8859系列字符集
ISO 8859系列字符集是欧洲计算机制造商协会(ECMA)在上世纪80年代中期设计,并被国际标准化(ISO)组织采纳为国际标准。ISO 8859系列字符集目前有15个字符集,包括:
- ISO 8859-1 大部分的西欧语系,例如英文、法文、西班牙文和德文等(Latin-1)
- ISO 8859-2 大部分的中欧和东欧语系,例如捷克文、波兰文和匈牙利文等(Latin-2)
- ISO 8859-3 欧洲东南部和其它各种文字(Latin-3)
- ISO 8859-4 斯堪的那维亚和波罗的海语系(Latin-4)
- ISO 8859-5 拉丁文与斯拉夫文(俄文、保加利亚文等)
- ISO 8859-6 拉丁文与阿拉伯文
- ISO 8859-7 拉丁文与希腊文
- ISO 8859-8 拉丁文与希伯来文
- ISO 8859-9 为土耳其文修正的Latin-1(Latin-5)
- ISO 8859-10 拉普人、北欧与爱斯基摩人的文字(Latin-6)
- ISO 8859-11 拉丁文与泰文
- ISO 8859-13 波罗的海周边语系,例如拉脱维亚文等(Latin-7)
- ISO 8859-14 凯尔特文,例如盖尔文、威尔士文等(Latin-8)
- ISO 8859-15 改进的Latin-1,增加遗漏的法文、芬兰文字符和欧元符号(Latin-9)
- ISO 8859-16 罗马尼亚文(Latin-10)
其中缺少的编号12据说是为了预留给天城体梵文字母(Deva-nagari)的。印地文和尼泊尔文都使用了这种在七世纪形成的字母表。由于印度定义了自己的编码ISCII(Indian Script Code for Information Interchange),所以这个编号就未被使用。ISO 8859系列字符集都是单字节字符集,即只使用0x00-0xFF对字符编码。
大家都知道ASCII吧,那么大家知道ANSI X3.4和ISO 646吗?在1968年发布的ANSI X3.4和1972年发布的ISO 646就是ASCII编码,只不过是不同组织发布的。绝大多数字符集都与ASCII编码保持兼容,ISO 8859系列字符集也不例外,它们的0x00-0x7f都与ASCII码保持一致,各字符集的不同之处在于如何利用0x80-0xff的码位。使用UniToy可以查看ISO 8859系列所有字符集的编码,例如:
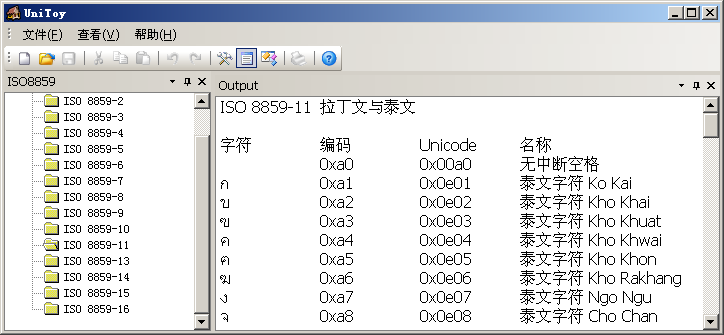
通过这些演示,大家是不是觉得代码页和字符集都是很简单、朴实的东西呢?好,在进入Unicode的话题前,让我们先看一个很深奥的概念。