3 字符编码模型
程序员经常会面对复杂的问题,而降低复杂性的最简单的方法就是分而治之。Peter Constable在他的文章"Character set encoding basics Understanding character set encodings and legacy encodings"中描述了字符编码的四层模型。我觉得这种说法确实可以更清晰地展现字符编码中发生的事情,所以在这里也介绍一下。
3.1 字符的范围(Abstract character repertoire)
设计字符编码的第一层就是确定字符的范围,即要支持哪些字符。有些编码方案的字符范围是固定的,例如ASCII、ISO 8859 系列。有些编码方案的字符范围是开放的,例如Unicode的字符范围就是世界上所有的字符。
3.2 用数字表示字符(Coded character set)
设计字符编码的第二层是将字符和数字对应起来。可以将这个层次理解成数学家(即从数学角度)看到的字符编码。数学家看到的字符编码是一个正整数。例如在Unicode中:汉字“字”对应的数字是23383。汉字“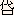 ”对应的数字是134192。
”对应的数字是134192。
在写html文件时,可以通过输入"字"来插入字符“字”。不过在设计字符编码时,我们还是习惯用16进制表示数字。即将23383写成0x5BD7,将134192写成0x20C30。
3.3 用基本数据类型表示字符(Character encoding form)
设计字符编码的第三层是用编程语言中的基本数据类型来表示字符。可以将这个层次理解成程序员看到的字符编码。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“UCS Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:
BYTE data_utf8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; // UTF-8编码
WORD data_utf16[] = {0x6c49, 0x5b57}; // UTF-16编码
DWORD data_utf32[] = {0x6c49, 0x5b57}; // UTF-32编码
这里用BYTE、WORD、DWORD分别表示无符号8位整数,无符号16位整数和无符号32位整数。UTF-8、UTF-16、UTF-32分别以BYTE、WORD、DWORD作为编码单位。
“汉字”的UTF-8编码需要6个字节。“汉字”的UTF-16编码需要两个WORD,大小是4个字节。“汉字”的UTF-32编码需要两个DWORD,大小是8个字节。4.2节会介绍将数字映射到UTF编码的规则。
3.4 作为字节流的字符(Character encoding scheme)
字符编码的第四层是计算机看到的字符,即在文件或内存中的字节流。例如,“字”的UTF-32编码是0x5b57,如果用little endian表示,字节流是“57 5b 00 00”。如果用big endian表示,字节流是“00 00 5b 57”。
字符编码的第三层规定了一个字符由哪些编码单位按什么顺序表示。字符编码的第四层在第三层的基础上又考虑了编码单位内部的字节序。UTF-8的编码单位是字节,不受字节序的影响。UTF-16、UTF-32根据字节序的不同,又衍生出UTF-16LE、UTF-16BE、UTF-32LE、UTF-32BE四种编码方案。LE和BE分别是Little Endian和Big Endian的缩写。
3.5 小结
通过四层模型,我们又把字符编码中发生的这些事情梳理了一遍。其实大多数代码页都不需要完整的四层模型,例如GB18030以字节为编码单位,直接规定了字节序列和字符的映射关系,跳过了第二层,也不需要第四层。
4 再谈Unicode
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
Unicode字符集可以简写为UCS(Unicode Character Set)。早期的Unicode标准有UCS-2、UCS-4的说法。UCS-2用两个字节编码,UCS-4用4个字节编码。UCS-4根据最高位为0的最高字节分成2^7=128个group。每个group再根据次高字节分为256个平面(plane)。每个平面根据第3个字节分为256行 (row),每行有256个码位(cell)。group 0的平面0被称作BMP(Basic Multilingual Plane)。将UCS-4的BMP去掉前面的两个零字节就得到了UCS-2。
Unicode标准计划使用group 0 的17个平面: 从BMP(平面0)到平面16,即数字0-0x10FFFF。《谈谈Unicode编码》主要介绍了BMP的编码,本文将介绍完整的Unicode编码,并从多个角度浏览Unicode。本文的介绍基于Unicode 5.0.0版本。
4.1 浏览Unicode
先看一些数字:每个平面有2^16=65536个码位。Unicode计划使用了17个平面,一共有17*65536=1114112个码位。其实,现在已定义的码位只有238605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。其中平面15和平面16上只是定义了两个各占65534个码位的专用区(Private Use Area),分别是0xF0000-0xFFFFD和0x100000-0x10FFFD。所谓专用区,就是保留给大家放自定义字符的区域,可以简写为PUA。
平面0也有一个专用区:0xE000-0xF8FF,有6400个码位。平面0的0xD800-0xDFFF,共2048个码位,是一个被称作代理区(Surrogate)的特殊区域。它的用途将在4.2节介绍。
238605-65534*2-6400-2408=99089。余下的99089个已定义码位分布在平面0、平面1、平面2和平面14上,它们对应着Unicode目前定义的99089个字符,其中包括71226个汉字。平面0、平面1、平面2和平面14上分别定义了52080、3419、43253和337个字符。平面2的43253个字符都是汉字。平面0上定义了27973个汉字。
在更深入地了解Unicode字符前,我们先了解一下UCD。
4.1.1 什么是UCD
UCD是Unicode字符数据库(Unicode Character Database)的缩写。UCD由一些描述Unicode字符属性和内部关系的纯文本或html文件组成。大家可以在Unicode组织的网站看到UCD的最新版本。
UCD中的文本文件大都是适合于程序分析的Unicode相关数据。其中的html文件解释了数据库的组织,数据的格式和含义。UCD中最庞大的文件无疑就是描述汉字属性的文件Unihan.txt。在UCD 5.0,0中,Unihan.txt文件大小有28,221K字节。Unihan.txt中包含了很多有参考价值的索引,例如汉字部首、笔划、拼音、使用频度、四角号码排序等。这些索引都是基于一些比较权威的辞典,但大多数索引只能检索部分汉字。
我介绍UCD的目的主要是为了使用其中的两个概念:Block和Script。
4.1.2 Block
UCD中的Blocks.txt将Unicode的码位分割成一些连续的Block,并描述了每个Block的用途:
| 开始码位 | 结束码位 | Block名称(英文) | Block名称(中文) |
| 0000 | 007F | Basic Latin | 基本拉丁字母 |
| 0080 | 00FF | Latin-1 Supplement | 拉丁字母补充-1 |
| 0100 | 017F | Latin Extended-A | 拉丁字母扩充-A |
| 0180 | 024F | Latin Extended-B | 拉丁字母扩充-B |
| 0250 | 02AF | IPA Extensions | 国际音标扩充 |
| 02B0 | 02FF | Spacing Modifier Letters | 进格修饰字符 |
| 0300 | 036F | Combining Diacritical Marks | 组合附加符号 |
| 0370 | 03FF | Greek and Coptic | 希腊文和哥普特文 |
| 0400 | 04FF | Cyrillic | 西里尔文 |
| 0500 | 052F | Cyrillic Supplement | 西里尔文补充 |
| 0530 | 058F | Armenian | 亚美尼亚文 |
| 0590 | 05FF | Hebrew | 希伯来文 |
| 0600 | 06FF | Arabic | 基本阿拉伯文 |
| 0700 | 074F | Syriac | 叙利亚文 |
| 0750 | 077F | Arabic Supplement | 阿拉伯文补充 |
| 0780 | 07BF | Thaana | 塔纳文 |
| 07C0 | 07FF | NKo | N'Ko字母表 |
| 0900 | 097F | Devanagari | 天成文书(梵文) |
| 0980 | 09FF | Bengali | 孟加拉文 |
| 0A00 | 0A7F | Gurmukhi | 锡克教文 |
| 0A80 | 0AFF | Gujarati | 古吉拉特文 |
| 0B00 | 0B7F | Oriya | 奥里亚文 |
| 0B80 | 0BFF | Tamil | 泰米尔文 |
| 0C00 | 0C7F | Telugu | 泰卢固文 |
| 0C80 | 0CFF | Kannada | 卡纳达文 |
| 0D00 | 0D7F | Malayalam | 德拉维族文 |
| 0D80 | 0DFF | Sinhala | 僧伽罗文 |
| 0E00 | 0E7F | Thai | 泰文 |
| 0E80 | 0EFF | Lao | 老挝文 |
| 0F00 | 0FFF | Tibetan | 藏文 |
| 1000 | 109F | Myanmar | 缅甸文 |
| 10A0 | 10FF | Georgian | 格鲁吉亚文 |
| 1100 | 11FF | Hangul Jamo | 朝鲜文 |
| 1200 | 137F | Ethiopic | 埃塞俄比亚文 |
| 1380 | 139F | Ethiopic Supplement | 埃塞俄比亚文补充 |
| 13A0 | 13FF | Cherokee | 切罗基文 |
| 1400 | 167F | Unified Canadian Aboriginal Syllabics | 加拿大印第安方言 |
| 1680 | 169F | Ogham | 欧甘文 |
| 16A0 | 16FF | Runic | 北欧古字 |
| 1700 | 171F | Tagalog | 塔加路文 |
| 1720 | 173F | Hanunoo | 哈努诺文 |
| 1740 | 175F | Buhid | 布迪文 |
| 1760 | 177F | Tagbanwa | Tagbanwa文 |
| 1780 | 17FF | Khmer | 高棉文 |
| 1800 | 18AF | Mongolian | 蒙古文 |
| 1900 | 194F | Limbu | 林布文 |
| 1950 | 197F | Tai Le | 德宏傣文 |
| 1980 | 19DF | New Tai Lue | 新傣文 |
| 19E0 | 19FF | Khmer Symbols | 高棉文 |
| 1A00 | 1A1F | Buginese | 布吉文 |
| 1B00 | 1B7F | Balinese | 巴厘文 |
| 1D00 | 1D7F | Phonetic Extensions | 拉丁字母音标扩充 |
| 1D80 | 1DBF | Phonetic Extensions Supplement | 拉丁字母音标扩充增补 |
| 1DC0 | 1DFF | Combining Diacritical Marks Supplement | 组合附加符号补充 |
| 1E00 | 1EFF | Latin Extended Additional | 拉丁字母扩充附加 |
| 1F00 | 1FFF | Greek Extended | 希腊文扩充 |
| 2000 | 206F | General Punctuation | 一般标点符号 |
| 2070 | 209F | Superscripts and Subscripts | 上标和下标 |
| 20A0 | 20CF | Currency Symbols | 货币符号 |
| 20D0 | 20FF | Combining Diacritical Marks for Symbols | 符号用组合附加符号 |
| 2100 | 214F | Letterlike Symbols | 似字母符号 |
| 2150 | 218F | Number Forms | 数字形式 |
| 2190 | 21FF | Arrows | 箭头符号 |
| 2200 | 22FF | Mathematical Operators | 数学运算符号 |
| 2300 | 23FF | Miscellaneous Technical | 零杂技术用符号 |
| 2400 | 243F | Control Pictures | 控制图符 |
| 2440 | 245F | Optical Character Recognition | 光学字符识别 |
| 2460 | 24FF | Enclosed Alphanumerics | 带括号的字母数字 |
| 2500 | 257F | Box Drawing | 制表符 |
| 2580 | 259F | Block Elements | 方块元素 |
| 25A0 | 25FF | Geometric Shapes | 几何形状 |
| 2600 | 26FF | Miscellaneous Symbols | 零杂符号 |
| 2700 | 27BF | Dingbats | 杂锦字型 |
| 27C0 | 27EF | Miscellaneous Mathematical Symbols-A | 零杂数学符号-A |
| 27F0 | 27FF | Supplemental Arrows-A | 箭头符号补充-A |
| 2800 | 28FF | Braille Patterns | 盲文 |
| 2900 | 297F | Supplemental Arrows-B | 箭头符号补充-B |
| 2980 | 29FF | Miscellaneous Mathematical Symbols-B | 零杂数学符号-B |
| 2A00 | 2AFF | Supplemental Mathematical Operators | 数学运算符号 |
| 2B00 | 2BFF | Miscellaneous Symbols and Arrows | 零杂符号和箭头 |
| 2C00 | 2C5F | Glagolitic | 格拉哥里字母表 |
| 2C60 | 2C7F | Latin Extended-C | 拉丁字母扩充-C |
| 2C80 | 2CFF | Coptic | 科普特文 |
| 2D00 | 2D2F | Georgian Supplement | 格鲁吉亚文补充 |
| 2D30 | 2D7F | Tifinagh | 提非纳字母 |
| 2D80 | 2DDF | Ethiopic Extended | 埃塞俄比亚文扩充 |
| 2E00 | 2E7F | Supplemental Punctuation | 标点符号补充 |
| 2E80 | 2EFF | CJK Radicals Supplement | 中日韩部首补充 |
| 2F00 | 2FDF | Kangxi Radicals | 康熙字典部首 |
| 2FF0 | 2FFF | Ideographic Description Characters | 汉字结构描述字符 |
| 3000 | 303F | CJK Symbols and Punctuation | 中日韩符号和标点 |
| 3040 | 309F | Hiragana | 平假名 |
| 30A0 | 30FF | Katakana | 片假名 |
| 3100 | 312F | Bopomofo | 注音符号 |
| 3130 | 318F | Hangul Compatibility Jamo | 朝鲜文兼容字母 |
| 3190 | 319F | Kanbun | 日文的汉字批注 |
| 31A0 | 31BF | Bopomofo Extended | 注音符号扩充 |
| 31C0 | 31EF | CJK Strokes | 中日韩笔划 |
| 31F0 | 31FF | Katakana Phonetic Extensions | 片假名音标扩充 |
| 3200 | 32FF | Enclosed CJK Letters and Months | 带括号的中日韩字母及月份 |
| 3300 | 33FF | CJK Compatibility | 中日韩兼容字符 |
| 3400 | 4DBF | CJK Unified Ideographs Extension A | 中日韩统一表意文字扩充A |
| 4DC0 | 4DFF | Yijing Hexagram Symbols | 易经六十四卦象 |
| 4E00 | 9FFF | CJK Unified Ideographs | 中日韩统一表意文字 |
| A000 | A48F | Yi Syllables | 彝文音节 |
| A490 | A4CF | Yi Radicals | 彝文字根 |
| A700 | A71F | Modifier Tone Letters | 声调修饰字母 |
| A720 | A7FF | Latin Extended-D | 拉丁字母扩充-D |
| A800 | A82F | Syloti Nagri | Syloti Nagri字母表 |
| A840 | A87F | Phags-pa | Phags-pa字母表 |
| AC00 | D7AF | Hangul Syllables | 朝鲜文音节 |
| D800 | DB7F | High Surrogates | 高位替代 |
| DB80 | DBFF | High Private Use Surrogates | 高位专用替代 |
| DC00 | DFFF | Low Surrogates | 低位替代 |
| E000 | F8FF | Private Use Area | 专用区 |
| F900 | FAFF | CJK Compatibility Ideographs | 中日韩兼容表意文字 |
| FB00 | FB4F | Alphabetic Presentation Forms | 字母变体显现形式 |
| FB50 | FDFF | Arabic Presentation Forms-A | 阿拉伯文变体显现形式-A |
| FE00 | FE0F | Variation Selectors | 字型变换选取器 |
| FE10 | FE1F | Vertical Forms | 竖排标点符号 |
| FE20 | FE2F | Combining Half Marks | 组合半角标示 |
| FE30 | FE4F | CJK Compatibility Forms | 中日韩兼容形式 |
| FE50 | FE6F | Small Form Variants | 小型变体形式 |
| FE70 | FEFF | Arabic Presentation Forms-B | 阿拉伯文变体显现形式-B |
| FF00 | FFEF | Halfwidth and Fullwidth Forms | 半角及全角字符 |
| FFF0 | FFFF | Specials | 特殊区域 |
| 10000 | 1007F | Linear B Syllabary | 线形文字B音节文字 |
| 10080 | 100FF | Linear B Ideograms | 线形文字B表意文字 |
| 10100 | 1013F | Aegean Numbers | 爱琴海数字 |
| 10140 | 1018F | Ancient Greek Numbers | 古希腊数字 |
| 10300 | 1032F | Old Italic | 古意大利文 |
| 10330 | 1034F | Gothic | 哥特文 |
| 10380 | 1039F | Ugaritic | 乌加里特楔形文字 |
| 103A0 | 103DF | Old Persian | 古波斯文 |
| 10400 | 1044F | Deseret | 德塞雷特大学音标 |
| 10450 | 1047F | Shavian | 肃伯纳速记符号 |
| 10480 | 104AF | Osmanya | Osmanya字母表 |
| 10800 | 1083F | Cypriot Syllabary | 塞浦路斯音节文字 |
| 10900 | 1091F | Phoenician | 腓尼基文 |
| 10A00 | 10A5F | Kharoshthi | 迦娄士悌文 |
| 12000 | 123FF | Cuneiform | 楔形文字 |
| 12400 | 1247F | Cuneiform Numbers and Punctuation | 楔形文字数字和标点 |
| 1D000 | 1D0FF | Byzantine Musical Symbols | 东正教音乐符号 |
| 1D100 | 1D1FF | Musical Symbols | 音乐符号 |
| 1D200 | 1D24F | Ancient Greek Musical Notation | 古希腊音乐符号 |
| 1D300 | 1D35F | Tai Xuan Jing Symbols | 太玄经符号 |
| 1D360 | 1D37F | Counting Rod Numerals | 算筹 |
| 1D400 | 1D7FF | Mathematical Alphanumeric Symbols | 数学用字母数字符号 |
| 20000 | 2A6DF | CJK Unified Ideographs Extension B | 中日韩统一表意文字扩充 B |
| 2F800 | 2FA1F | CJK Compatibility Ideographs Supplement | 中日韩兼容表意文字补充 |
| E0000 | E007F | Tags | 标签 |
| E0100 | E01EF | Variation Selectors Supplement | 字型变换选取器补充 |
| F0000 | FFFFF | Supplementary Private Use Area-A | 补充专用区-A |
| 100000 | 10FFFF | Supplementary Private Use Area-B | 补充专用区-B |
Block是Unicode字符的一个属性。属于同一个Block的字符有着相近的用途。Block表中的开始码位、结束码位只是用来划分出一块区域,在开始码位和结束码位之间可能还有很多未定义的码位。使用UniToy,大家可以按照Block浏览Unicode字符,既可以按列表显示:
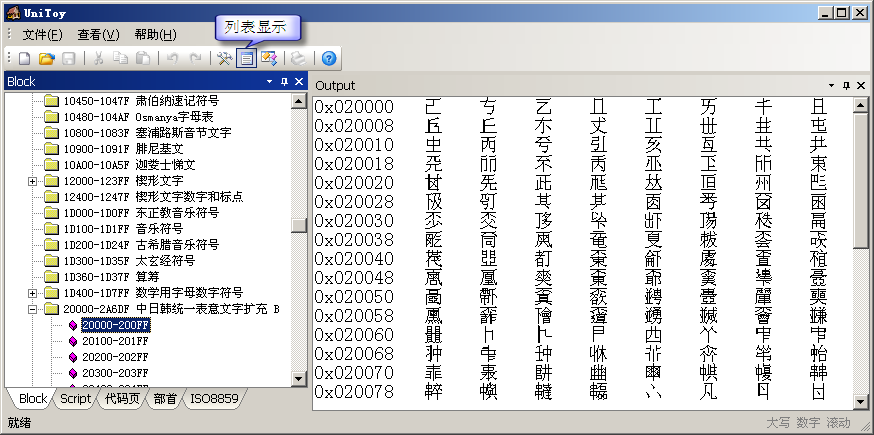
也可以显示每个字符的详细信息: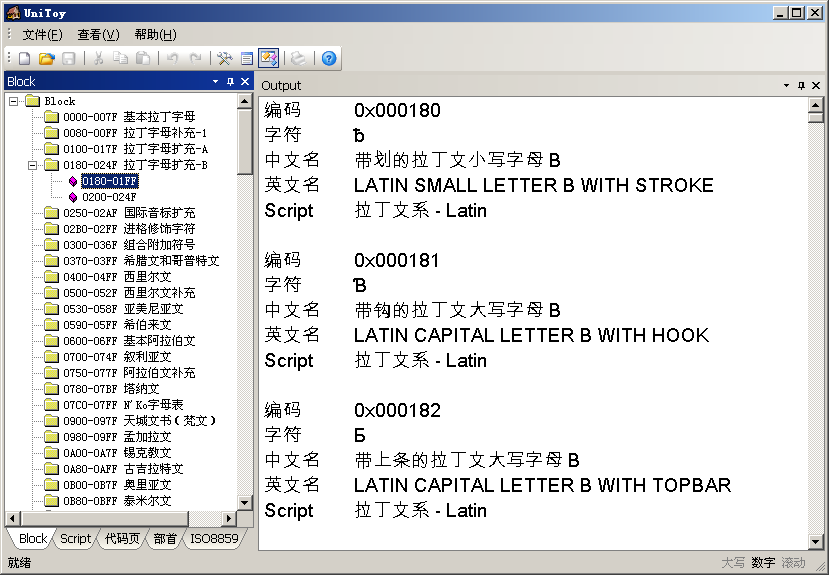
4.1.3 Script
Unicode中每个字符都有一个Script属性,这个属性表明字符所属的文字系统。Unicode目前支持以下Script:
| Script名称(英文) | Script名称(中文) | Script包含的字符数 |
| Arabic | 阿拉伯文 | 966 |
| Armenian | 亚美尼亚文 | 90 |
| Balinese | 巴厘文 | 121 |
| Bengali | 孟加拉文 | 91 |
| Bopomofo | 汉语注音符号 | 64 |
| Braille | 盲文 | 256 |
| Buginese | 布吉文 | 30 |
| Buhid | 布迪文 | 20 |
| Canadian Aboriginal | 加拿大印第安方言 | 630 |
| Cherokee | 切罗基文 | 85 |
| Common | Common | 5020 |
| Coptic | 科普特文 | 128 |
| Cuneiform | 楔形文字 | 982 |
| Cypriot | 塞浦路斯音节文字 | 55 |
| Cyrillic | 西里尔文 | 277 |
| Deseret | 德塞雷特大学音标 | 80 |
| Devanagari | 天成文书(梵文) | 107 |
| Ethiopic | 埃塞俄比亚文 | 461 |
| Georgian | 格鲁吉亚文 | 120 |
| Gothic | 哥特文 | 94 |
| Glagolitic | 格拉哥里字母表 | 27 |
| Greek | 希腊文 | 506 |
| Gujarati | 古吉拉特文 | 83 |
| Gurmukhi | 锡克教文 | 77 |
| Han | 汉文 | 71570 |
| Hangul | 韩文书写系统 | 11619 |
| Hanunoo | 哈努诺文 | 21 |
| Hebrew | 希伯来文 | 133 |
| Hiragana | 平假名 | 89 |
| Inherited | Inherited | 461 |
| Kannada | 卡纳达文 | 86 |
| Katakana | 片假名 | 164 |
| Kharoshthi | 迦娄士悌文 | 65 |
| Khmer | 高棉文 | 146 |
| Lao | 老挝文 | 65 |
| Latin | 拉丁文系 | 1070 |
| Limbu | 林布文(尼泊尔东部) | 66 |
| Linear B | 线形文字B | 211 |
| Malayalam | 德拉维族文(印度) | 78 |
| Mongolian | 蒙古文 | 152 |
| Myanmar | 缅甸文 | 78 |
| New Tai Lue | 新傣文 | 80 |
| Nko | N'Ko字母表 | 59 |
| Ogham | 欧甘文字 | 29 |
| Old Italic | 古意大利文 | 35 |
| Old Persian | 古波斯文 | 50 |
| Oriya | 奥里亚文 | 81 |
| Osmanya | Osmanya字母表 | 40 |
| Phags Pa | Phags Pa字母表(蒙古) | 56 |
| Phoenician | 腓尼基文 | 27 |
| Runic | 古代北欧文 | 78 |
| Shavian | 肃伯纳速记符号 | 48 |
| Sinhala | 僧伽罗文 | 80 |
| Syloti Nagri | Syloti Nagri字母表(印度) | 44 |
| Syriac | 叙利亚文 | 77 |
| Tagalog | 塔加路文(菲律宾) | 20 |
| Tagbanwa | Tagbanwa文(菲律宾) | 18 |
| Tai Le | 德宏傣文 | 35 |
| Tamil | 泰米尔文 | 71 |
| Telugu | 泰卢固文(印度) | 80 |
| Thaana | 马尔代夫书写体 | 50 |
| Thai | 泰国文 | 86 |
| Tibetan | 藏文 | 195 |
| Tifinagh | 提非纳字母表 | 55 |
| Ugaritic | 乌加里特楔形文字 | 31 |
| Yi | 彝文 | 1220 |
其中,有两个Script值有着特殊的含义:
- Common:Script属性为Common的字符可能在多个文字系统中使用,不是某个文字系统特有的。例如:空格、数字等。
- Inherited:Script属性为Inherited的字符会继承前一个字符的Script属性。主要是一些组合用符号,例如:在“组合附加符号”区(0x300-0x36f),字符的Script属性都是Inherited。
UCD中的Script.txt列出了每个字符的Script属性。使用UniToy可以按照Script属性查看字符。例如:
左侧Script窗口中,第一层节点是按英文字母顺序排列的Script属性。第二层节点是包含该Script文字的行(row),点击后显示该行内属于这个Script的字符。这样,就可以集中查看属于同一文字系统的字符。
4.1.4 Unicode中的汉字
前面提过,在Unicode已定义的99089个字符中,有71226个字符是汉字。它们的分布如下:
| Block名称 | 开始码位 | 结束码位 | 数量 |
| 中日韩统一表意文字扩充A | 3400 | 4db5 | 6582 | |
| 中日韩统一表意文字 | 4e00 | 9fbb | 20924 | |
| 中日韩兼容表意文字 | f900 | fa2d | 302 | |
| 中日韩兼容表意文字 | fa30 | fa6a | 59 | |
| 中日韩兼容表意文字 | fa70 | fad9 | 106 |
| 中日韩统一表意文字扩充B | 20000 | 2a6d6 | 42711 | |
| 中日韩兼容表意文字补充 | 2f800 | 2fa1d | 542 |
UCD的Unihan.txt中的部首偏旁索引(kRSUnicode)可以检索全部71226个汉字。kRSUnicode的部首是按照康熙字典定义的,共214个部首。简体字按照简体部首对应的繁体部首检索。UniToy整理了康熙字典部首对应的简体部首,提供了按照部首检索汉字的功能:
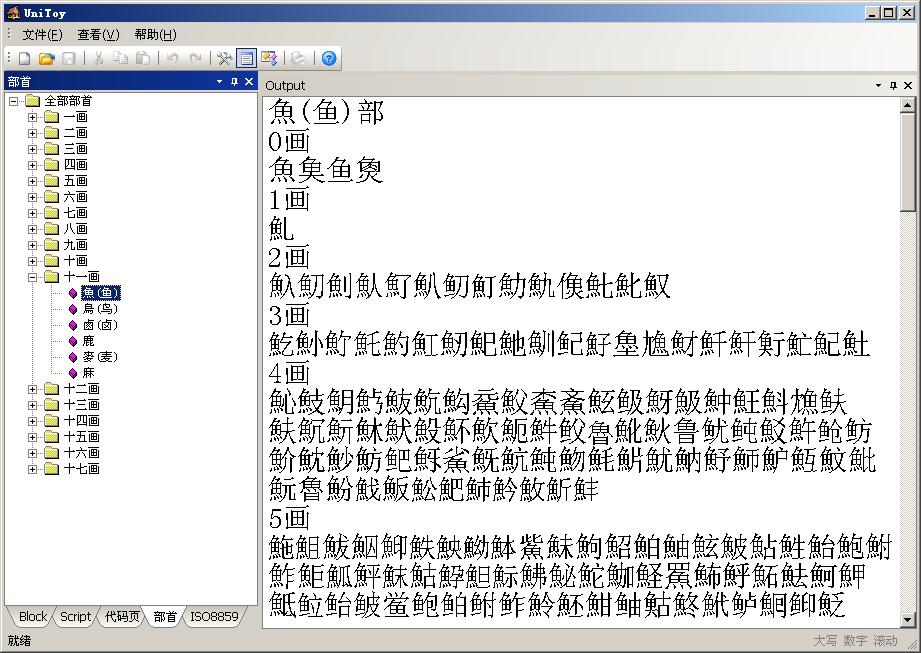
4.2 UTF编码
在字符编码的四个层次中,第一层的范围和第二层的编码在4.1节已经详细讨论过了。本节讨论第三层的UTF编码和第四层的字节序,主要谈谈第三层的UTF编码,即怎样将Unicode定义的编码转换成程序数据。
4.2.1 UTF-8
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
| Unicode编码(16进制) | UTF-8 字节流(二进制) |
| 000000 - 00007F | 0xxxxxxx |
| 000080 - 0007FF | 110xxxxx 10xxxxxx |
| 000800 - 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000 - 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
例2:“”字的Unicode编码是0x20C30。0x20C30在0x010000-0x10FFFF之间,使用用4字节模板了:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0。
4.2.2 UTF-16
UniToy有个“输出编码”功能,可以输出当前选择的文本编码。因为UniToy内部采用UTF-16编码,所以输出的编码就是文本的UTF-16编码。例如:如果我们输出“汉”字的UTF-16编码,可以看到0x6C49,这与“汉”字的Unicode编码是一致的。如果我们输出“”字的UTF-16编码,可以看到0xD843, 0xDC30。“”字的Unicode编码是0x20C30,它的UTF-16编码是怎样得到的呢?
4.2.2.1 编码规则
UTF-16编码以16位无符号整数为单位。我们把Unicode编码记作U。编码规则如下:
- 如果U<0x10000,U的UTF-16编码就是U对应的16位无符号整数(为书写简便,下文将16位无符号整数记作WORD)。
- 如果U≥0x10000,我们先计算U'=U-0x10000,然后将U'写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码(二进制)就是:110110yyyyyyyyyy110111xxxxxxxxxx。
为什么U'可以被写成20个二进制位?Unicode的最大码位是0x10ffff,减去0x10000后,U'的最大值是0xfffff,所以肯定可以用20个二进制位表示。例如:“”字的Unicode编码是0x20C30,减去0x10000后,得到0x10C30,写成二进制是:0001 0000 1100 0011 0000。用前10位依次替代模板中的y,用后10位依次替代模板中的x,就得到:1101100001000011 1101110000110000,即0xD843 0xDC30。
4.2.2.2 代理区(Surrogate)
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有两个WORD,第一个WORD的高6位是110110,第二个WORD的高6位是110111。可见,第一个WORD的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二个WORD的取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。
为了将一个WORD的UTF-16编码与两个WORD的UTF-16编码区分开来,Unicode编码的设计者将0xD800-0xDFFF保留下来,并称为代理区(Surrogate):
| D800 | DB7F | High Surrogates | 高位替代 |
| DB80 | DBFF | High Private Use Surrogates | 高位专用替代 |
| DC00 | DFFF | Low Surrogates | 低位替代 |
高位替代就是指这个范围的码位是两个WORD的UTF-16编码的第一个WORD。低位替代就是指这个范围的码位是两个WORD的UTF-16编码的第二个WORD。那么,高位专用替代是什么意思?我们来解答这个问题,顺便看看怎么由UTF-16编码推导Unicode编码。
解:如果一个字符的UTF-16编码的第一个WORD在0xDB80到0xDBFF之间,那么它的Unicode编码在什么范围内?我们知道第二个WORD的取值范围是0xDC00-0xDFFF,所以这个字符的UTF-16编码范围应该是0xDB80 0xDC00到0xDBFF 0xDFFF。我们将这个范围写成二进制:
1101101110000000 11011100 00000000 - 1101101111111111 1101111111111111
按照编码的相反步骤,取出高低WORD的后10位,并拼在一起,得到
1110 0000 0000 0000 0000 - 1111 1111 1111 1111 1111
即0xe0000-0xfffff,按照编码的相反步骤再加上0x10000,得到0xf0000-0x10ffff。这就是UTF-16编码的第一个WORD在0xdb80到0xdbff之间的Unicode编码范围,即平面15和平面16。因为Unicode标准将平面15和平面16都作为专用区,所以0xDB80到0xDBFF之间的保留码位被称作高位专用替代。
4.2.3 UTF-32
UTF-32编码以32位无符号整数为单位。Unicode的UTF-32编码就是其对应的32位无符号整数。
4.2.4 字节序
根据字节序的不同,UTF-16可以被实现为UTF-16LE或UTF-16BE,UTF-32可以被实现为UTF-32LE或UTF-32BE。例如:
| 字符 | Unicode编码 | UTF-16LE | UTF-16BE | UTF32-LE | UTF32-BE |
| 汉 | 0x6C49 | 49 6C | 6C 49 | 49 6C 00 00 | 00 00 6C 49 |
| 0x20C30 | 43 D8 30 DC | D8 43 DC 30 | 30 0C 02 00 | 00 02 0C 30 |
那么,怎么判断字节流的字节序呢?
Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符"零宽无中断空格"。这个字符的编码是FEFF,而反过来的FFFE(UTF-16)和FFFE0000(UTF-32)在Unicode中都是未定义的码位,不应该出现在实际传输中。下表是各种UTF编码的BOM:
| UTF编码 | Byte Order Mark |
| UTF-8 | EF BB BF |
| UTF-16LE | FF FE |
| UTF-16BE | FE FF |
| UTF-32LE | FF FE 00 00 |
| UTF-32BE | 00 00 FE FF |
5 结束语
程序员的工作就是将复杂的世界简单地表达出来,希望这篇文章也能做到这一点。本文的初稿完成于2007年2月14日。我会在我的个人主页http://www.fmddlmyy.cn维护这篇文章的最新版本。