首先生成抽象语法树,方法如下:
1.根节点为0时表示没有default标签,为1时表示有default标签
2.第0个根节点表示switch里的条件
3.若有default标签,则最后一个根节点为default子树
4.每个根节点为0时表示在此标签下没有stmt_list语句块,这个节点的唯一孩子为要匹配的表达式;为1时表示有语句块,根节点的左孩子表示要匹配的表达式,右孩子为要执行的语句块
注意:Equal指令会弹出两操作数,应此在Equal指令执行之前必须先保留switch里exp的副本(即Push一次),最后弹出副本
测试代码:
1 integer aaa,bbb
2
3 function ccc()
4 switch aaa + 1 do
5 default:
6 aaa = 123
7 case 123:
8 do
9 aaa = aaa + 1
10 while aaa < 789 end
11 case 456:
12 aaa = 123
13 end switch
14 end function
生成虚拟机代码:
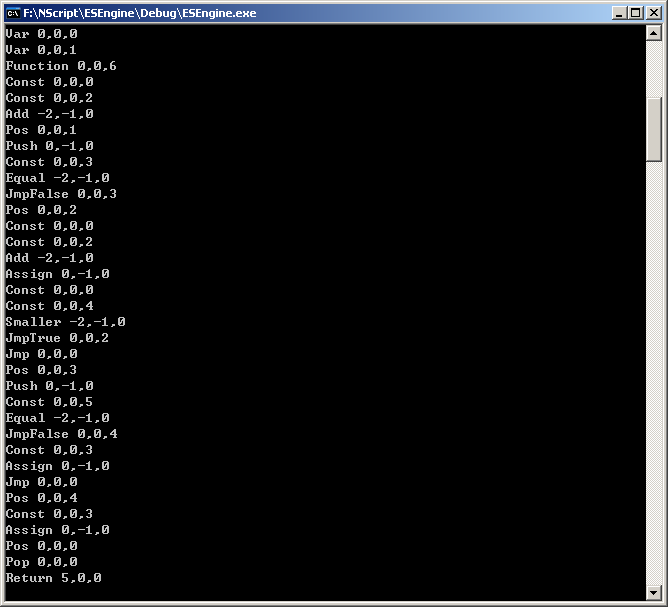
posted @
2010-09-29 15:55 lwch 阅读(1313) |
评论 (0) |
编辑 收藏
For语句的翻译比较复杂,有3个前置条件和运行代码,1个语句块,也就有4*3*2*1=24种情况.应此在生成抽象语法树的时候我采用的是2进制位来表示当前块是否存在,其中最底位表示stmt_list语句块,倒数第2位表示by之后的语句是否存在,倒数第3位表示to之后的表达式是否存在,倒数第4位表示for之后的语句是否存在.
代码:
1 integer aaa,bbb
2
3 function ccc()
4 do
5 for aaa = 456 to by do
6 if aaa == 456 then
7 aaa = 789
8 end if
9 next
10 aaa = 123
11 while aaa == 123 end
12 end function
翻译结果:
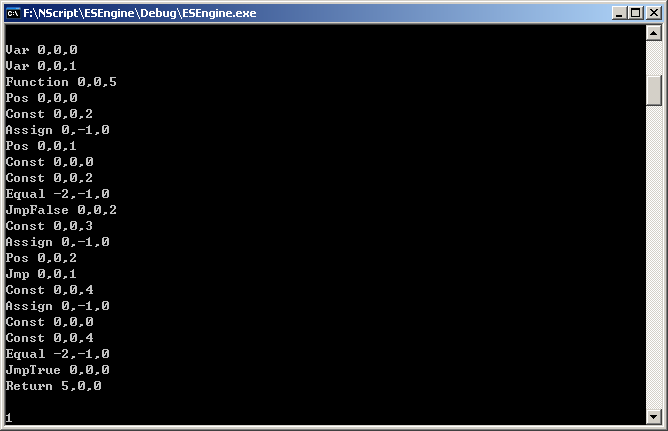
posted @
2010-09-22 12:20 lwch 阅读(1655) |
评论 (0) |
编辑 收藏
已实现do,while,if和赋值语句的语法制导翻译,这次将他们逐层嵌套起来看看翻译结果是否正确.
代码:
1 integer aaa
2
3 function ccc()
4 while aaa == 123 do
5 do
6 if aaa == 123 then
7 if aaa == 456 then aaa = 123
8 else aaa = 456
9 end if
10 end if
11 while aaa == 123 end
12 end while
13 aaa = 456
14 end function
翻译结果:
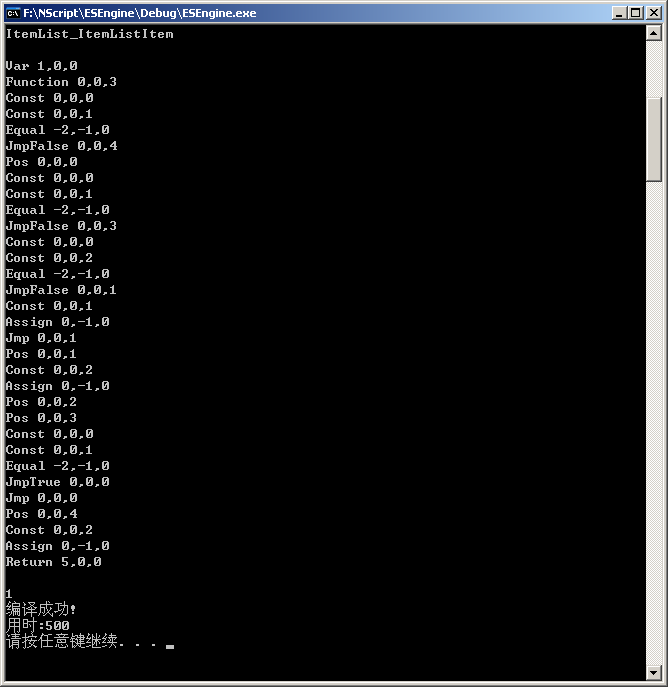
posted @
2010-09-20 22:29 lwch 阅读(1633) |
评论 (2) |
编辑 收藏1 integer aaa
2
3 function ccc()
4 if aaa and true then
5 end if
6 end function
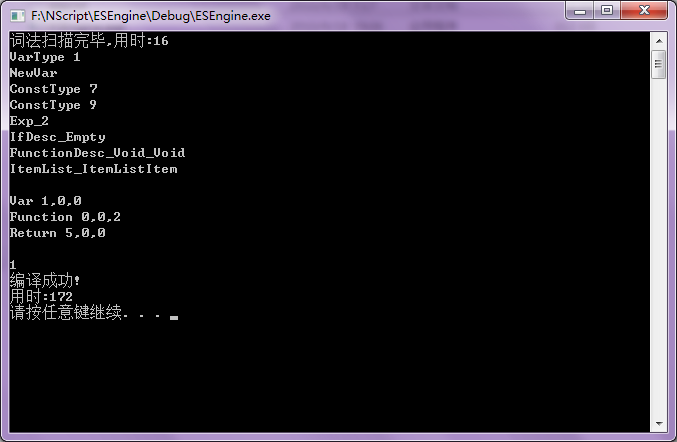
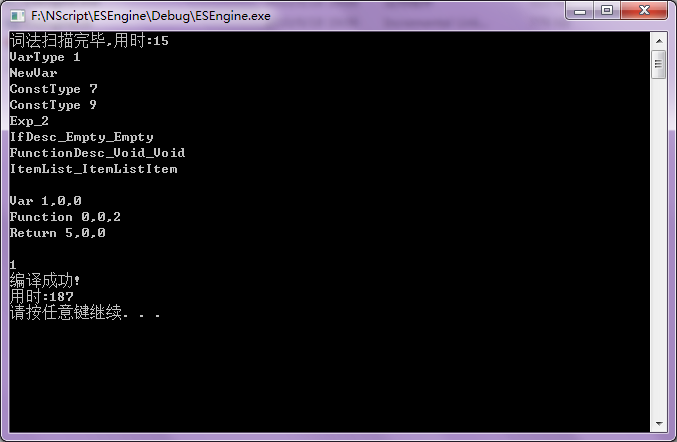
1 integer aaa
2
3 function ccc()
4 if aaa and true then
5 aaa = 123
6 end if
7 end function
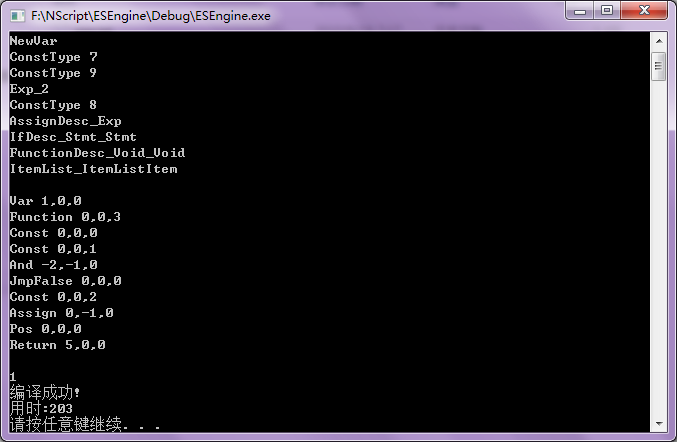
1 integer aaa
2
3 function ccc()
4 if aaa and true then
5 else
6 end if
7 end function
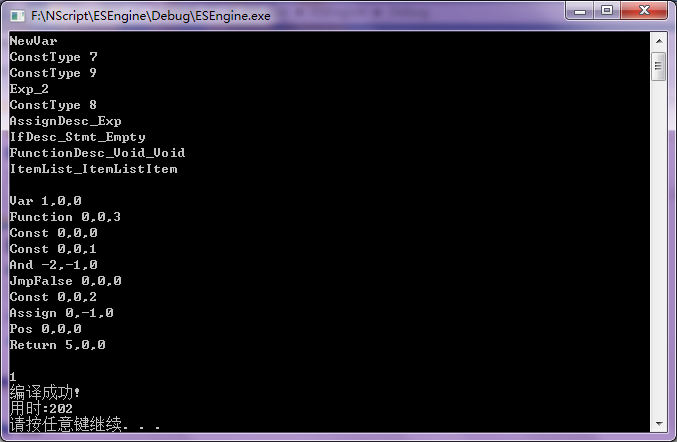
1 integer aaa
2
3 function ccc()
4 if aaa and true then
5 aaa = 123
6 else
7 end if
8 end function
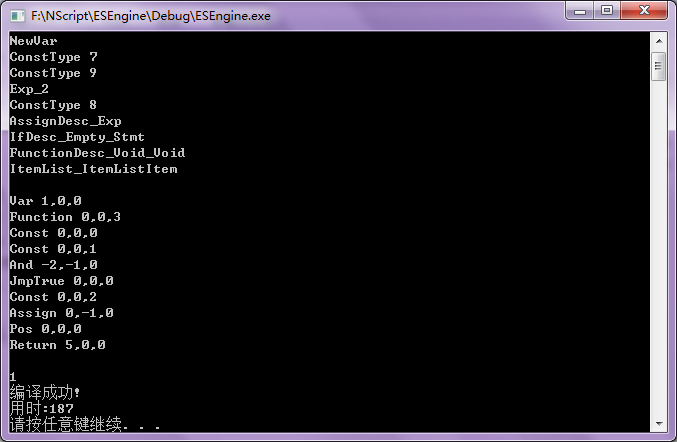
1 integer aaa
2
3 function ccc()
4 if aaa and true then
5 else
6 aaa = 123
7 end if
8 end function
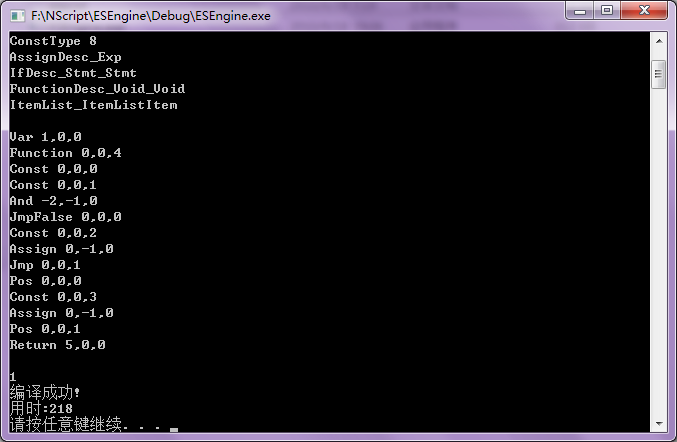
1 integer aaa
2
3 function ccc()
4 if aaa and true then
5 aaa = 123
6 else
7 aaa = 456
8 end if
9 end function
posted @
2010-09-19 07:27 lwch 阅读(1661) |
评论 (0) |
编辑 收藏
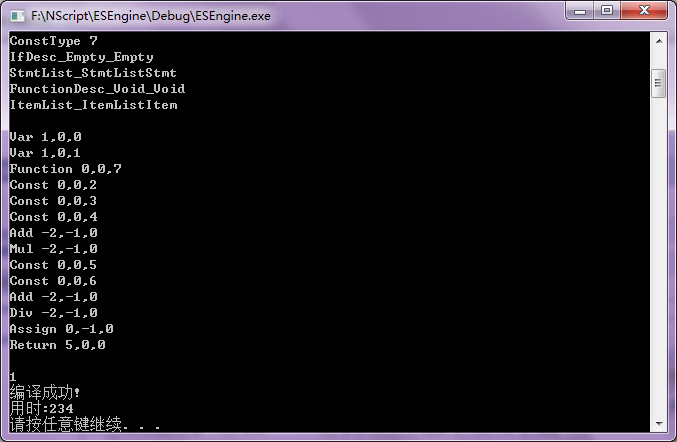
首先生成抽象语法树(AST)
生成方法:
1.移进时将Number,String或Symbol分别加入对应集合
2.归约时从集合中取出对应的成员,并删除这条产生式里的所有终结符
3.将产生的语法树节点压入栈中
4.当遇到产生式item_list->item_list item或stmt_list->stmt_list stmt时从栈中弹出两颗语法树并按顺序连接起来
5.当遇到非终结符时弹出相应数量的语法树节点,生成新的根节点并把弹出的语法树节点都连接到这个新的根节点上
6.当归约到第0条产生式时检查栈的元素数量,1为正常值,然后对抽象语法树进行前序遍历并生成虚拟机代码
posted @
2010-09-17 22:21 lwch 阅读(777) |
评论 (0) |
编辑 收藏
摘要: 1 %token "function" "as" "end"; 2 %token "integer" "string" "bool" "pointer"; 3 %token "if" "then" "e...
阅读全文
posted @
2010-09-17 22:04 lwch 阅读(1104) |
评论 (0) |
编辑 收藏
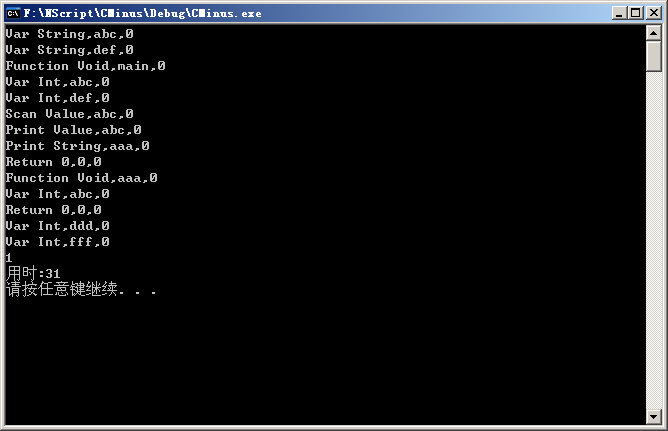
输入文件:
1 string abc,def;
2
3 void main()
4 {
5 int abc,def;
6 read(abc);
7 write(abc);
8 write("aaa");
9 }
10
11 void aaa()
12 {
13 int abc;
14 }
15
16 int ddd,fff;
生成虚拟机代码为:
赋值语句逻辑比较复杂还未完成..
posted @
2010-09-01 16:09 lwch 阅读(1446) |
评论 (0) |
编辑 收藏分析文件:
1 string abc;
2
3 void main()
4 {
5 int a,b,c;
6 read(a);
7 write("aaa");
8 write(a);
9 b = 10;
10 c = 100;
11 }
12
13 int cc()
14 {
15 }
结果:
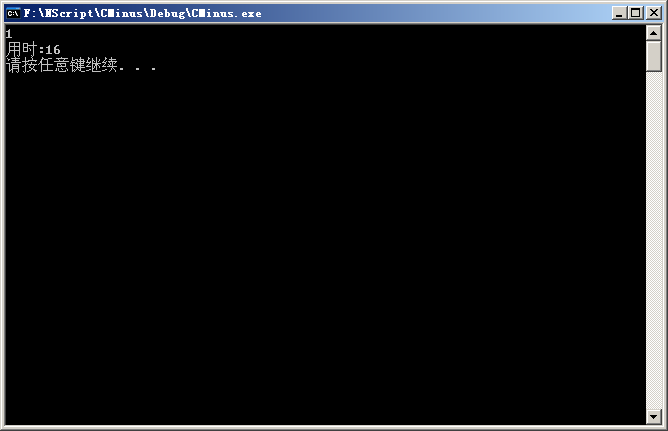
下面的工作则是大量的语义处理...
posted @
2010-08-31 23:27 lwch 阅读(661) |
评论 (0) |
编辑 收藏分析器文法:
1 %token "%token" "%start" ;
2 %token ";" "->" "|" ;
3
4 %start program ;
5
6 program -> item_list
7 ;
8
9 item_list -> item_list item
10 | item
11 ;
12
13 item -> token_def ";"
14 | start_def ";"
15 | rule_def ";"
16 | ";"
17 ;
18
19 token_def -> token_def "{String}"
20 | "%token" "{String}"
21 ;
22
23 start_def -> "%start" "{Symbol}"
24 ;
25
26 rule_def -> "{Symbol}" "->" rhs_list
27 ;
28
29 rhs_list -> rhs_list "|" rhs
30 | rhs
31 ;
32
33 rhs -> rhs "{String}"
34 | rhs "{Symbol}"
35 | "{String}"
36 | "{Symbol}"
37 ;
38
NScriptMacro 主要用来将给定的文法文件转化为LALR(1)分析表,生成的cpp和h文件可使用分析器分析,out文件是语法分析表
里面有个简单的CMinus的例子
posted @
2010-08-30 17:29 lwch 阅读(1530) |
评论 (1) |
编辑 收藏
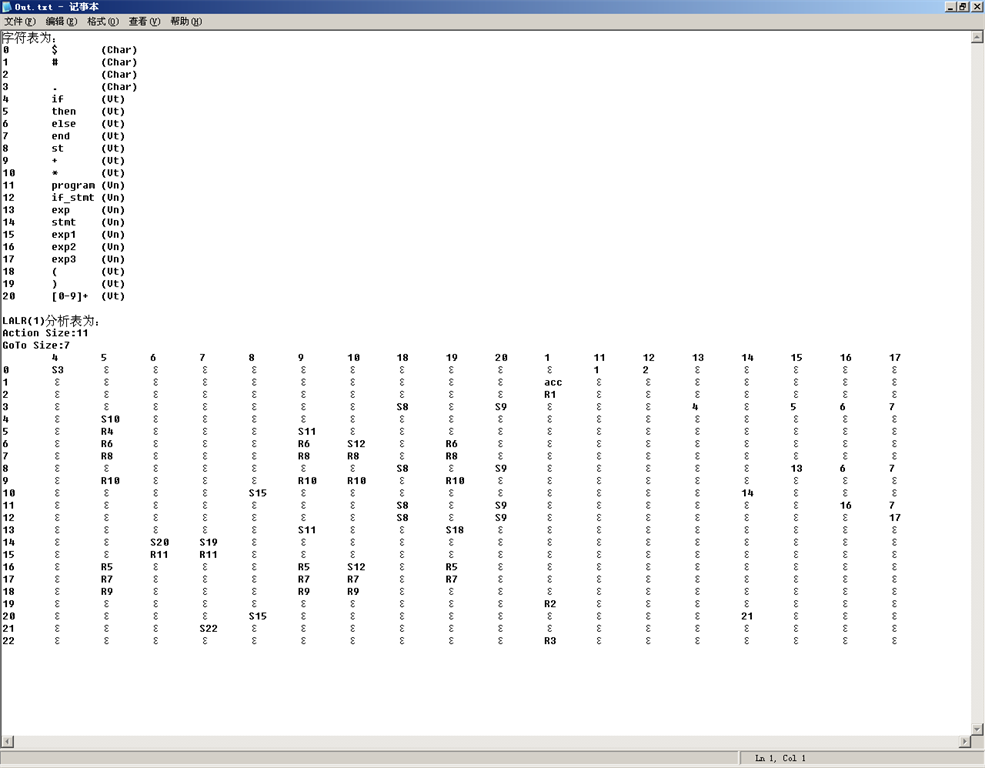
对于给定文法文件:
1 %token "if" "then" "else" "end" ;
2 %token "st" ;
3 %token "+" "*" ;
4
5 %start program ;
6
7 program -> if_stmt
8 ;
9
10 if_stmt -> "if" exp "then" stmt "end"
11 | "if" exp "then" stmt "else" stmt "end"
12 ;
13
14 exp -> exp1
15 ;
16
17 exp1 -> exp1 "+" exp2
18 | exp2
19 ;
20
21 exp2 -> exp2 "*" exp3
22 | exp3
23 ;
24
25 exp3 -> "{LQ}" exp1 "{RQ}"
26 | "{digit}"
27 ;
28
29 stmt -> "st"
30 ;
生成分析表得:
posted @
2010-08-28 15:28 lwch 阅读(307) |
评论 (0) |
编辑 收藏 1 %token "%token" "%start" ;
2 %token ";" "->" "|" ;
3
4 %start program ;
5
6 program -> item_list
7 ;
8
9 item_list -> item_list item
10 | item
11 ;
12
13 item -> token_def ";"
14 | start_def ";"
15 | rule_def ";"
16 | ";"
17 ;
18
19 token_def -> token_def "{String}"
20 | "%token" "{String}"
21 ;
22
23 start_def -> "%start" "{Symbol}"
24 ;
25
26 rule_def -> "{Symbol}" "->" rhs_list
27 ;
28
29 rhs_list -> rhs_list "|" rhs
30 | rhs
31 ;
32
33 rhs -> rhs "{String}"
34 | rhs "{Symbol}"
35 | "{String}"
36 | "{Symbol}"
37 ;
38
去除了letter定义,暂时还不支持正则表达式..
posted @
2010-08-28 15:23 lwch 阅读(256) |
评论 (0) |
编辑 收藏 1 #include <iostream>
2
3 template <typename _Type>
4 class HashTable
5 {
6 public:
7 HashTable(int Length)
8 {
9 Element = new _Type[Length];
10 for(int i=0;i<Length;i++)
11 Element[i] = -1;
12 this->Length = Length;
13 Count = 0;
14 }
15
16 ~HashTable()
17 {
18 delete[] Element;
19 }
20
21 // Hash函数
22 virtual int Hash(_Type Data)
23 {
24 return Data % Length;
25 }
26
27 // 再散列法
28 virtual int ReHash(int Index,int Count)
29 {
30 return (Index + Count) % Length;
31 }
32
33 // 查找某个元素是否在表中
34 virtual bool SerachHash(_Type Data,int& Index)
35 {
36 Index = Hash(Data);
37 int Count = 0;
38 while(Element[Index] != -1 && Element[Index] != Data)
39 Index = ReHash(Index,++Count);
40 return Data == Element[Index] ? true : false;
41 }
42
43 virtual int SerachHash(_Type Data)
44 {
45 int Index = 0;
46 if(SerachHash(Data,Index)) return Index;
47 else return -1;
48 }
49
50 // 插入元素
51 bool InsertHash(_Type Data)
52 {
53 int Index = 0;
54 if(Count < Length && !SerachHash(Data,Index))
55 {
56 Element[Index] = Data;
57 Count++;
58 return true;
59 }
60 return false;
61 }
62
63 // 设置Hash表长度
64 void SetLength(int Length)
65 {
66 delete[] Element;
67 Element = new _Type[Length];
68 for(int i=0;i<Length;i++)
69 Element[i] = -1;
70 this->Length = Length;
71 }
72
73 // 删除某个元素
74 void Remove(_Type Data)
75 {
76 int Index = SerachHash(Data);
77 if(Index != -1)
78 {
79 Element[Index] = -1;
80 Count--;
81 }
82 }
83
84 // 删除所有元素
85 void RemoveAll()
86 {
87 for(int i=0;i<Length;i++)
88 Element[i] = -1;
89 Count = 0;
90 }
91
92 void Print()
93 {
94 for(int i=0;i<Length;i++)
95 printf("%d ",Element[i]);
96 printf("\n");
97 }
98 protected:
99 _Type* Element; // Hash表
100 int Length; // Hash表大小
101 int Count; // Hash表当前大小
102 };
103
104 void main()
105 {
106 HashTable<int> H(10);
107 printf("Hash Length(10) Test:\n");
108 int Array[6] = {49,38,65,97,13,49};
109 for(int i=0;i<6;i++)
110 printf("%d\n",H.InsertHash(Array[i]));
111 H.Print();
112 printf("Find(97):%d\n",H.SerachHash(97));
113 printf("Find(49):%d\n",H.SerachHash(49));
114 H.RemoveAll();
115 H.SetLength(30);
116 printf("Hash Length(30) Test:\n");
117 for(int i=0;i<6;i++)
118 printf("%d\n",H.InsertHash(Array[i]));
119 H.Print();
120 printf("Find(97):%d\n",H.SerachHash(97));
121 printf("Find(49):%d\n",H.SerachHash(49));
122 system("pause");
123 }
运行结果:
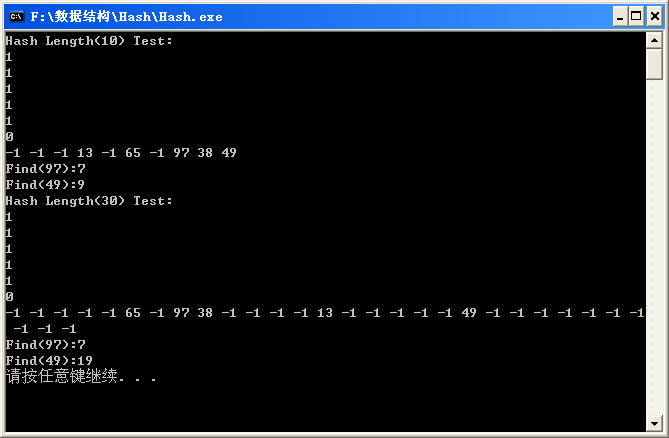
由上图可知给定的Hash表长度越长越不容易产生冲突,性能也就越高.
posted @
2010-08-10 23:37 lwch 阅读(594) |
评论 (1) |
编辑 收藏基本语法:
1 %token "%token" "%letter" "%start" ;
2 %token ":" ";" "->" "|" ;
3
4 %letter string : "{string}" ;
5 %letter symbol : "{symbol}" ;
6
7 %start program ;
8
9 string_list -> string_list string
10 | string
11 ;
12
13 symbol_list -> symbol_list symbol
14 | symbol
15 ;
16
17 program -> item_list
18 ;
19
20 item_list -> item_list item
21 | item
22 ;
23
24 item -> token_def ";"
25 | letter_def ";"
26 | start_def ";"
27 | rule_def ";"
28 | ";"
29 ;
30
31 token_def -> "%token" string_list
32 ;
33
34 letter_def -> "%letter" symbol ":" string_list
35 ;
36
37 start_def -> "%start" symbol
38 ;
39
40 rule_def -> symbol "->" rhs_list
41 ;
42
43 rhs_list -> rhs_list "|" rhs
44 | rhs
45 ;
46
47 rhs -> term_list
48 ;
49
50 term_list -> term_list string
51 | term_list symbol
52 | string
53 | symbol
54 ;
生成的分析表:
由于状态数量和非终结符数量过多,所以给出文件
《分析表》 下面是四则混合运算的文法文件:
1 %token "+" "-" ;
2 %token "*" "/" ;
3 %token "(" ")" ;
4
5 %letter AddOp : "+" "-" ;
6 %letter MulOp : "*" "/" ;
7 %letter ID : "{digit}" ;
8 %letter LQ : "(" ;
9 %letter RQ : ")" ;
10
11 %start Program ;
12
13 Program -> Exp
14 ;
15
16 Exp -> Exp AddOp Term
17 | Term
18 ;
19
20 Term -> Term MulOp Factor
21 | Factor
22 ;
23
24 Factor -> LQ Exp RQ
25 | ID
26 ;
posted @
2010-08-03 20:21 lwch 阅读(332) |
评论 (0) |
编辑 收藏
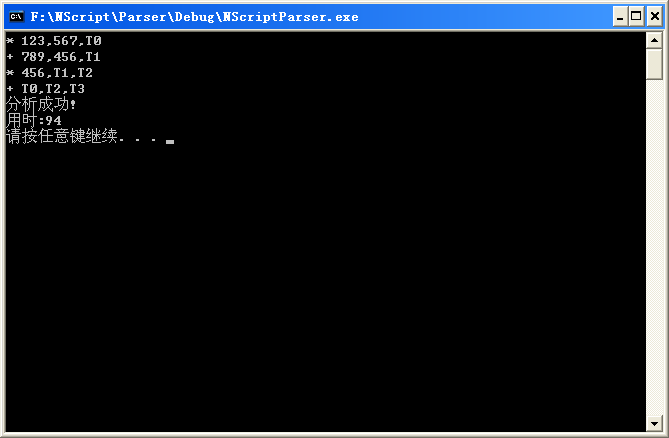
对于给定表达式:
123 * 567 + 456 * (789 + 456)
生成四元码得:
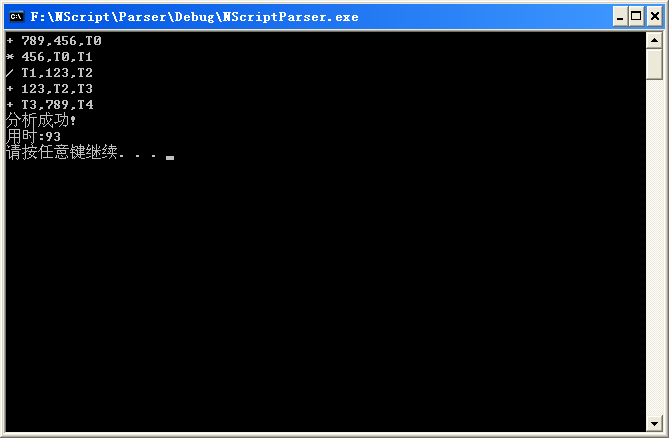
对于表达式:
123 + 456 * (789 + 456) / 123 + 789
生成四元码得:
posted @
2010-08-01 01:05 lwch 阅读(469) |
评论 (0) |
编辑 收藏
对于式子:10 + (5 + 9) / 3 - 7 * 3
求解过程如下:
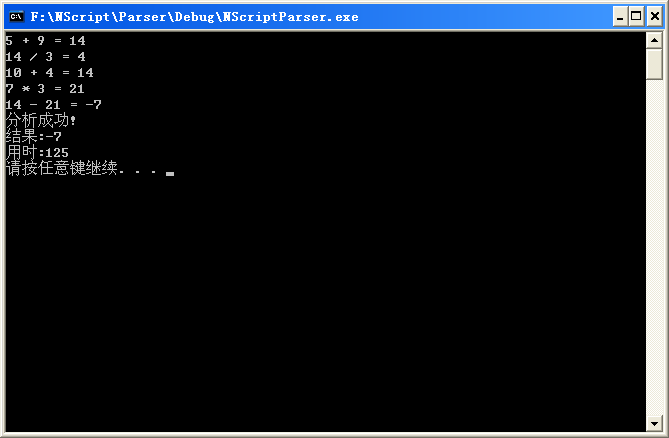
主要在规约过程中增加了调用相关语义处理函数来实现计算.
posted @
2010-07-26 11:41 lwch 阅读(396) |
评论 (0) |
编辑 收藏