一. 内存屏障 Memory Barrior
1.1 重排序
同步的目的是保证不同执行流对共享数据并发操作的一致性。在单核时代,使用原子变量就很容易达成这一目的。甚至因为CPU的一些访存特性,对某些内存对齐数据的读或写也具有原子的特性。但在多核架构下即使操作是原子的,仍然会因为其他原因导致同步失效。
首先是现代编译器的代码优化和编译器指令重排可能会影响到代码的执行顺序。
其次还有指令执行级别的乱序优化,流水线、乱序执行、分支预测都可能导致处理器次序(Process Ordering,机器指令在CPU实际执行时的顺序)和程序次序(Program Ordering,程序代码的逻辑执行顺序)不一致。可惜不影响语义依旧只能是保证单核指令序列间,单核时代CPU的Self-Consistent特性在多核时代已不存在(Self-Consistent即重排原则:有数据依赖不会进行重排,单核最终结果肯定一致)。
除此还有硬件级别Cache一致性(Cache Coherence)带来的问题:CPU架构中传统的MESI协议中有两个行为的执行成本比较大。一个是将某个Cache Line标记为Invalid状态,另一个是当某Cache Line当前状态为Invalid时写入新的数据。所以CPU通过Store Buffer和Invalidate Queue组件来降低这类操作的延时。如图:
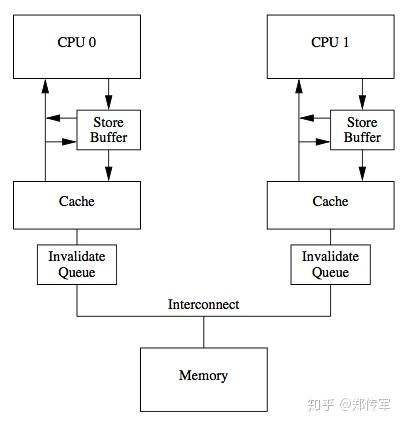
当一个核心在Invalid状态进行写入时,首先会给其它CPU核发送Invalid消息,然后把当前写入的数据写入到Store Buffer中。然后异步在某个时刻真正的写入到Cache Line中。当前CPU核如果要读Cache Line中的数据,需要先扫描Store Buffer之后再读取Cache Line(Store-Buffer Forwarding)。但是此时其它CPU核是看不到当前核的Store Buffer中的数据的,要等到Store Buffer中的数据被刷到了Cache Line之后才会触发失效操作。
而当一个CPU核收到Invalid消息时,会把消息写入自身的Invalidate Queue中,随后异步将其设为Invalid状态。和Store Buffer不同的是,当前CPU核心使用Cache时并不扫描Invalidate Queue部分,所以可能会有极短时间的脏读问题。这里的Store Buffer和Invalidate Queue的说法是针对一般的SMP架构来说的,不涉及具体架构。
内存对于缓存更新策略,要区分Write-Through和Write-Back两种策略。前者更新内容直接写内存并不同时更新Cache,但要置Cache失效,后者先更新Cache,随后异步更新内存。通常X86 CPU更新内存都使用Write-Back策略。
1.2 编译器屏障 Compiler Barrior
/* The "volatile" is due to gcc bugs */ #define barrier() __asm__ __volatile__("": : :"memory")
阻止编译器重排,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
1.3 CPU屏障 CPU Barrior
CPU级别内存屏障其作用有两个:
- 防止指令之间的重排序
- 保证数据的可见性
指令重排中Load和Store两种操作会有Load-Store、Store-Load、Load-Load、Store-Store这四种可能的乱序结果。
Intel为此提供三种内存屏障指令:
- sfence ,实现Store Barrior 会将store buffer中缓存的修改刷入L1 cache中,使得其他cpu核可以观察到这些修改,而且之后的写操作不会被调度到之前,即sfence之前的写操作一定在sfence完成且全局可见;
- lfence ,实现Load Barrior 会将invalidate queue失效,强制读取入L1 cache中,而且lfence之后的读操作不会被调度到之前,即lfence之前的读操作一定在lfence完成(并未规定全局可见性);
- mfence ,实现Full Barrior 同时刷新store buffer和invalidate queue,保证了mfence前后的读写操作的顺序,同时要求mfence之后写操作结果全局可见之前,mfence之前写操作结果全局可见;
- lock 用来修饰当前指令操作的内存只能由当前CPU使用,若指令不操作内存仍然由用,因为这个修饰会让指令操作本身原子化,而且自带Full Barrior效果;还有指令比如IO操作的指令、exch等原子交换的指令,任何带有lock前缀的指令以及CPUID等指令都有内存屏障的作用。
X86-64下仅支持一种指令重排:Store-Load ,即读操作可能会重排到写操作前面,同时不同线程的写操作并没有保证全局可见,例子见《Intel® 64 and IA-32 Architectures Software Developer’s Manual》手册8.6.1、8.2.3.7节。要注意的是这个问题只能用mfence解决,不能靠组合sfence和lfence解决。(用sfence+lfence组合仅可以解决重排问题,但不能解决全局可见性问题,简单理解不如视为sfence和lfence本身也能乱序重拍)
X86-64一般情况根本不会需要使用lfence与sfence这两个指令,除非操作Write-Through内存或使用 non-temporal 指令(NT指令,属于SSE指令集),比如movntdq, movnti, maskmovq,这些指令也使用Write-Through内存策略,通常使用在图形学或视频处理,Linux编程里就需要使用GNC提供的专门的函数(例子见参考资料13:Memory part 5: What programmers can do)。
下面是GNU中的三种内存屏障定义方法,结合了编译器屏障和三种CPU屏障指令
#define lfence() __asm__ __volatile__("lfence": : :"memory") #define sfence() __asm__ __volatile__("sfence": : :"memory") #define mfence() __asm__ __volatile__("mfence": : :"memory")
代码中仍然使用lfence()与sfence()这两个内存屏障应该也是一种长远的考虑。按照Interface写代码是最保险的,万一Intel以后出一个采用弱一致模型的CPU,遗留代码出问题就不好了。目前在X86下面视为编译器屏障即可。
GCC 4以后的版本也提供了Built-in的屏障函数__sync_synchronize(),这个屏障函数既是编译屏障又是内存屏障,代码插入这个函数的地方会被安插一条mfence指令。
C++11为内存屏障提供了专门的函数std::atomic_thread_fence,方便移植统一行为而且可以配合内存模型进行设置,比如实现Acquire-release语义:
#include <atomic> std::atomic_thread_fence(std::memory_order_acquire); std::atomic_thread_fence(std::memory_order_release);
二、内存模型
2.1 Acquire与Release语义
- 对于Acquire来说,保证Acquire后的读写操作不会发生在Acquire动作之前
- 对于Release来说,保证Release前的读写操作不会发生在Release动作之后
Acquire & Release 语义保证内存操作仅在acquire和release屏障之间发生
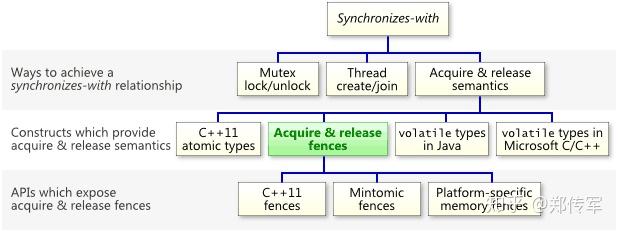
X86-64中Load读操作本身满足Acquire语义,Store写操作本身也是满足Release语义。但Store-Load操作间等于没有保护,因此仍需要靠mfence或lock等指令才可以满足到Synchronizes-with规则。
2.2 happens-before规则
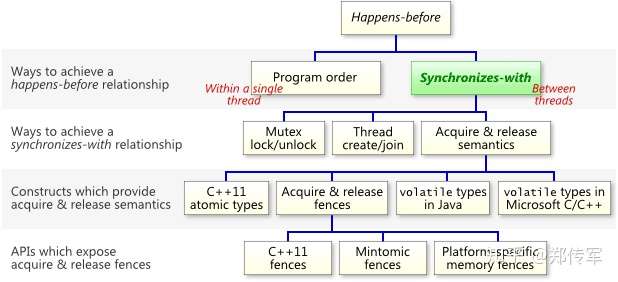
相对于Synchronizes-with规则更宽松,happens-before规则定义指令执行顺序与变量的可见性,类似偏序关系,具有可传递性,因此可以运用于并行逻辑分析。
2.3 内存一致性模型 Memory Model
内存一致性模型从程序员视角,由内存序Memory Ordering和写操作原子性Store Atomicity来定义,针对不同线程中原子操作的全局顺序:
- Strong Consistency / Sequential consistency 顺序一致性
- Release Consistency / release-acquire / release-consume
- Relaxed Consistency
C++11相应定义了6种内存模型:
- std::memory_order_seq_cst 所有读写操作不能跨过,写顺序全线程可见
- std::memory_order_acq_rel 所有读写操作不能跨过,写顺序仅同步线程间可见、std::memory_order_release 所有读写操作不能往后乱序、std::memory_order_acquire 所有读写操作不能向前乱序、std::memory_order_consume 依赖该读操作的后续读写操作不能向前乱序
- std::memory_order_relaxed 无特殊要求
三. volatile 关键字
voldatile关键字首先具有“易变性”,声明为volatile变量编译器会强制要求读内存,相关语句不会直接使用上一条语句对应的的寄存器内容,而是重新从内存中读取。
其次具有”不可优化”性,volatile告诉编译器,不要对这个变量进行各种激进的优化,甚至将变量直接消除,保证代码中的指令一定会被执行。
最后具有“顺序性”,能够保证Volatile变量间的顺序性,编译器不会进行乱序优化。不过要注意与非volatile变量之间的操作,还是可能被编译器重排序的。
需要注意的是其含义跟原子操作无关,比如:volatile int a; a++; 其中a++操作实际对应三条汇编指令实现”读-改-写“操作(RMW),并非原子的。
思考:bool类型是不是适合使用,不会出问题。
不同编程语言中voldatile含义与实现并不完全相同,Java语言中voldatile变量可以被看作是一种轻量级的同步,因其还附带了acuire和release语义。实际上也是从JDK5以后才通过这个措施进行完善,其volatile 变量具有 synchronized 的可见性特性,但是不具备原子特性。Java语言中有volatile修饰的变量,赋值后多执行了一个“load addl $0x0, (%esp)”操作,这个操作相当于一个lock指令,就是增加一个完全的内存屏障指令,这点与C++实现并不一样。volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
Java实践中仅满足下面这些条件才应该使用volatile关键字:
- 变量写入操作不依赖变量当前值,或确保只有一个线程更新变量的值(Java可以,C++仍然不能)
- 该变量不会与其他变量一起纳入
- 变量并未被锁保护
C++中voldatile等于插入编译器级别屏障,因此并不能阻止CPU硬件级别导致的重排。C++11 中volatile语义没有任何变化,不过提供了std::atomic工具可以真正实现原子操作,而且默认加入了内存屏障(可以通过在store与load操作时设置内存模型参数进行调整,默认为std::memory_order_seq_cst)。
C++实践中推荐涉及并发问题都使用std::atomic,只有涉及特殊内存操作的时候才使用volatile关键字。这些情况通常IO相关,防止相关操作被编译器优化,也是volatile关键字发明的本意。
四、使用经验
内存屏障相关并行逻辑使用的分析顺序:线程安全、操作原子性、存储器操作顺序
C++ 使用对齐变量与mfence
C++11 使用std::atomic与std::atomic_thread_fence,先使用默认std::memory_order_seq_cst模型再进行相关优化
Java 使用volatile或atomic
一个经典的例子就是DCL双重检查加锁实现单例模式,本意是想要实现延迟初始化
@NotThreadSafe public class DoubleCheckedLock { private static Resource resoure; public static Resource getInstance() { if (resource == null) { synchronized (DoubleCheckedLock.class) { if (resource == null) resource = new Resource(); } } return resource; } }
问题在于未同步状态下读共享变量,可能获取的是中间值,比如这里获取的resource对象可能还未完全构造好。尽管JDK5以后声明为volatile可以避免这个问题,但DCL已经没有必要,因为Java可以利用JVM内部静态类装载的特点实现“延迟初始化占位类模式”来达到同样的效果。C++下面可以使用pthread_once实现。
后续:同步原语使用(锁、信号量等)、Lockfree与非阻塞操作