Centos 7.6 yum升级GCC8版本:
1.安装scl源:
yum install centos-release-scl scl-utils-build
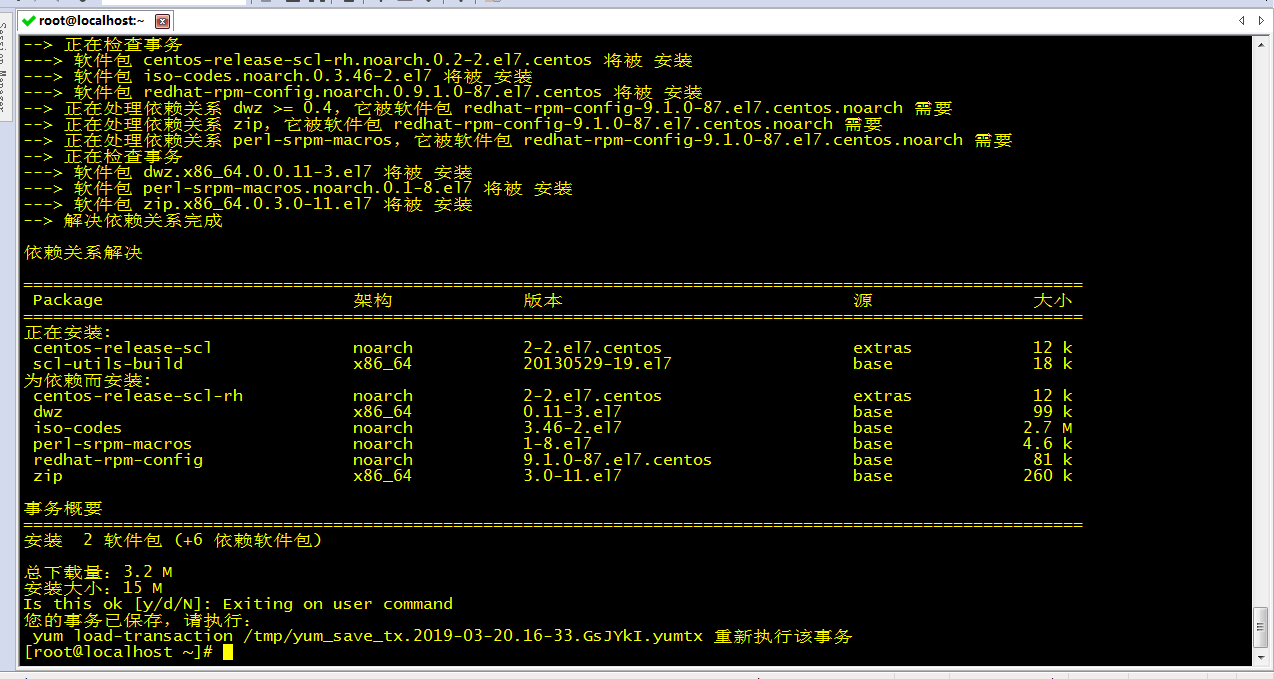
执行:
yum load-transaction /tmp/yum_save_tx.2019-03-20.16-33.GsJYkI.yumtx
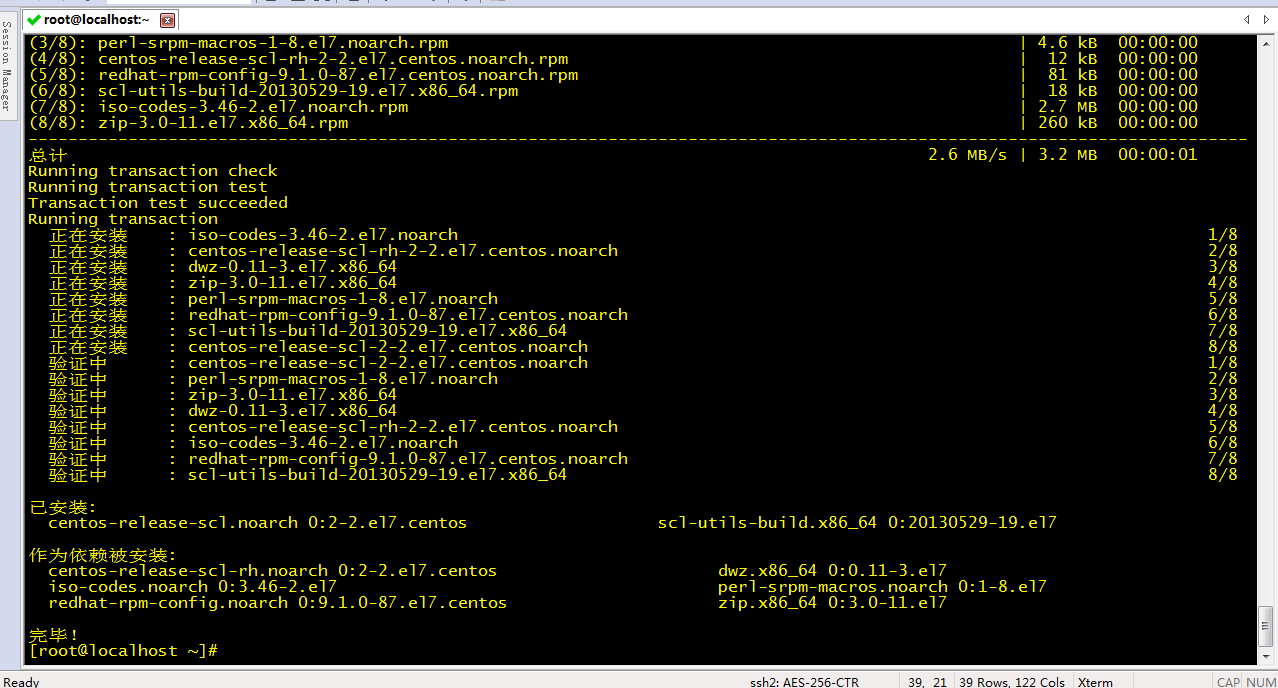
2.列出scl可用源:
yum list all --enablerepo='centos-sclo-rh'
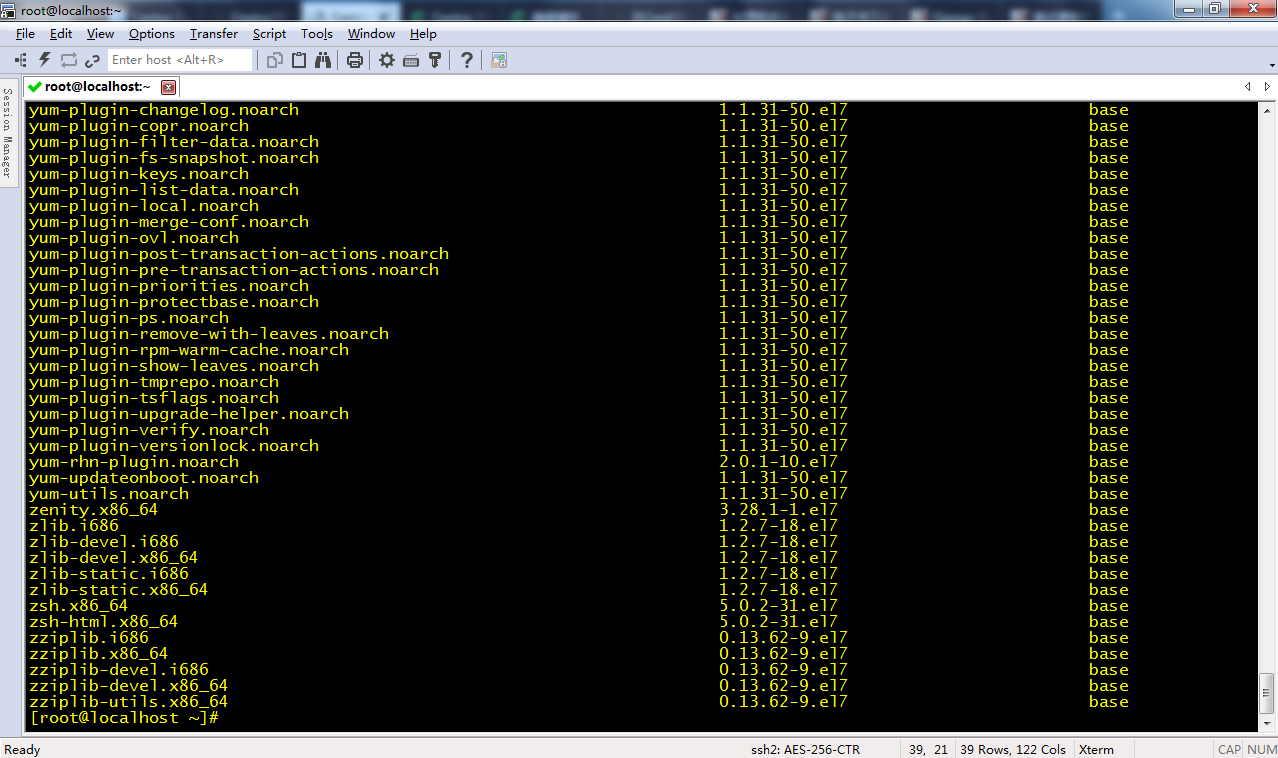
yum list all --enablerepo='centos-sclo-rh' | grep "devtoolset-"
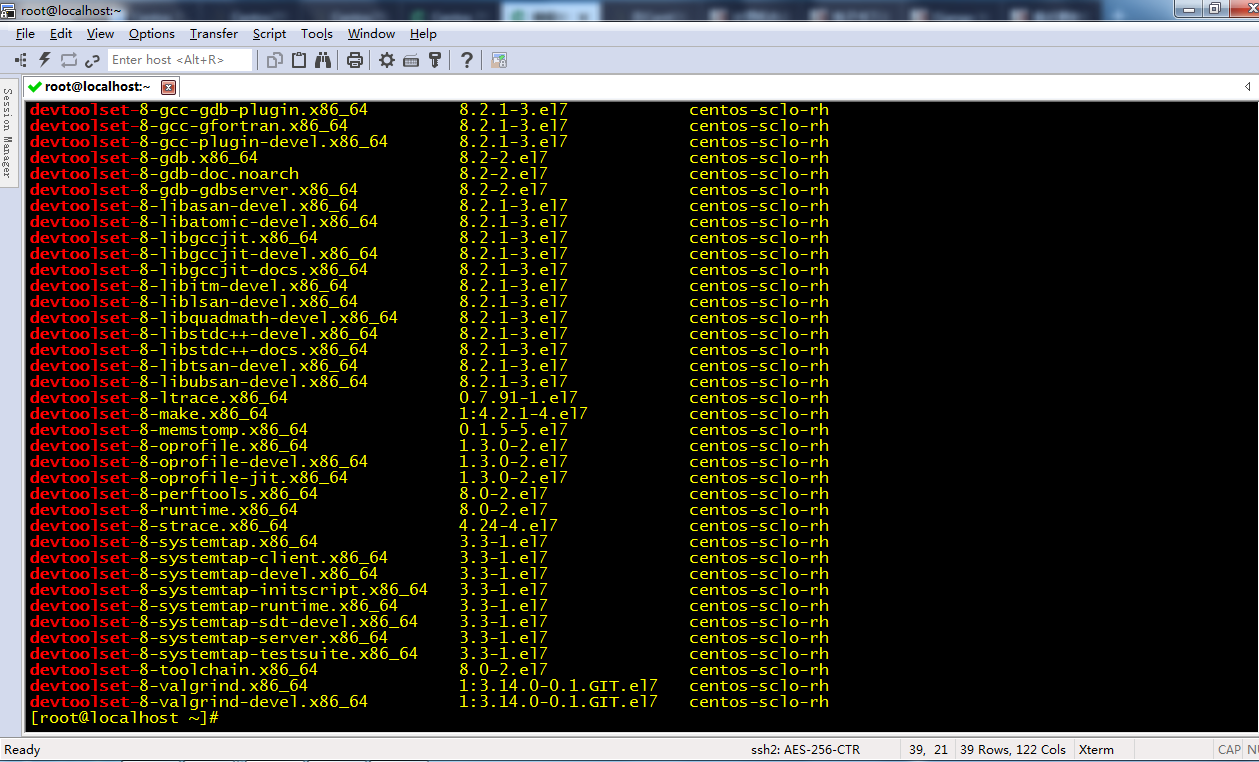
3.安装8版本的gcc、gcc-c++、gdb工具链(toolchian):
yum install -y devtoolset-8-toolchain
scl enable devtoolset-8 bash
gcc --version

posted @
2020-04-02 15:54 长戟十三千 阅读(2067) |
评论 (0) |
编辑 收藏
摘要: 3。磁盘I/O分析方法 (1)计算每磁盘的I/O数每磁盘的I/O数可用来与磁盘的I/O能力进行对比,如果经过计算得到的每磁盘I/O数超过了磁盘标称的I/O能力,则说明确实存在磁盘的性能瓶颈。 (2)与Processor: Privileged Time 合并进行分析&n...
阅读全文
posted @
2020-03-12 11:19 长戟十三千 阅读(756) |
评论 (0) |
编辑 收藏# mount -t cifs //10.0.0.1/share /mnt/sharefolder -o username=sensirx,password=sensirx,vers=2.0
posted @
2020-03-09 15:26 长戟十三千 阅读(335) |
评论 (0) |
编辑 收藏1. 电脑下载VBoxAdditions,网址:http://download.virtualbox.org/virtualbox/5.1.12/Oracle_VM_VirtualBox_Extension_Pack-5.1.12.vbox-extpack
2. 下载完成后双击打开,按照下一步的指示安装完成。
3. 电脑下载VBoxAdditions,网址:http://download.virtualbox.org/virtualbox/5.1.12/VBoxGuestAdditions_5.1.12.iso
4. CentOS挂上光驱:
mkdir /mnt/cdrom
mount /dev/cdrom /mnt/cdrom
5. 将光驱内的文件夹复制到硬盘中。(如果直接在光驱中执行安装,会因为权限问题导致无法安装。)
cp -R /mnt/cdrom /usr/local/src/VBoxAdditions
6. (可选)安装前需要设置安装环境,如果已设置,那么这一步可以跳过:
yum install gcc
yum install make
yum install kernel-headers
yum install kernel-devel
7. 进入文件夹,开始安装:./VBoxLinuxAdditions.run install
重启系统!!!!!!!!!!!!!!!!!
8. 启用共享文件夹:
mkdir /mnt/share
mount -t vboxsf vmshare /mnt/share
注释:vmshare为visualbox界面配置里添加的共享文件路径和名称
ln -s /mnt/share /home/myshare (软连接到用户myshare下)
9. 成功!
————————————————
版权声明:本文为CSDN博主「熊小憨」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/suma110/article/details/54343686
posted @
2020-02-16 19:51 长戟十三千 阅读(502) |
评论 (0) |
编辑 收藏MariaDB 数据库管理系统是 MySQL 的一个分支,主要由开源社区在维护,采用 GPL 授权许可。开发这个分支的原因之一是:甲骨文公司收购了 MySQL 后,有将 MySQL 闭源的潜在风险,因此社区采用分支的方式来避开这个风险。MariaDB完全兼容mysql,使用方法也是一样的
有的centos7已经默认安装了Mariadb,可以查看自己的有没有安装,没有安装的再进行安装,已经安装了可以不用安装也可以卸载了重装。卸载命令 yum remove mariadb-server
 我的系统环境
我的系统环境
1、安装MariaDB
通过yum安装就行了。简单快捷,安装mariadb-server,默认依赖安装mariadb,一个是服务端、一个是客户端。
[root@mini ~]# yum install mariadb-server
2、配置MariaDB
1)安装完成后首先要把MariaDB服务开启,并设置为开机启动
[root@mini ~]# systemctl start mariadb # 开启服务 [root@mini ~]# systemctl enable mariadb # 设置为开机自启动服务
2)首次安装需要进行数据库的配置,命令都和mysql的一样
[root@mini ~]# mysql_secure_installation
3)配置时出现的各个选项
Enter current password for root (enter for none): # 输入数据库超级管理员root的密码(注意不是系统root的密码),第一次进入还没有设置密码则直接回车 Set root password? [Y/n] # 设置密码,y New password: # 新密码 Re-enter new password: # 再次输入密码 Remove anonymous users? [Y/n] # 移除匿名用户, y Disallow root login remotely? [Y/n] # 拒绝root远程登录,n,不管y/n,都会拒绝root远程登录 Remove test database and access to it? [Y/n] # 删除test数据库,y:删除。n:不删除,数据库中会有一个test数据库,一般不需要 Reload privilege tables now? [Y/n] # 重新加载权限表,y。或者重启服务也许
4)测试是否能够登录成功,出现 MariaDB [(none)]> 就表示已经能够正常登录使用MariaDB数据库了
[root@mini ~]# mysql -u root -p Enter password: Welcome to the MariaDB monitor. Commands end with ; or \g. Your MariaDB connection id is 8 Server version: 5.5.60-MariaDB MariaDB Server Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MariaDB [(none)]>
3、设置MariaDB字符集为utf-8
1)/etc/my.cnf 文件
在 [mysqld] 标签下添加
init_connect='SET collation_connection = utf8_unicode_ci' init_connect='SET NAMES utf8' character-set-server=utf8 collation-server=utf8_unicode_ci skip-character-set-client-handshake
2)/etc/my.cnf.d/client.cnf 文件
在 [client] 标签下添加
default-character-set=utf8
3)/etc/my.cnf.d/mysql-clients.cnf 文件
在 [mysql] 标签下添加
default-character-set=utf8
4)重启服务
[root@mini ~]# systemctl restart mariadb
5)进入mariadb查看字符集
未配置字符集前 配置字符集后
4、远程链接mariadb数据库
mariadb默认是拒绝 root 远程登录的。这里用的是 navicat 软件连接数据库
1)关闭防火墙
① 关闭防火墙 systemctl stop firewalld
[root@mini ~]# systemctl stop firewalld
② 在不关闭防火墙的情况下,允许某端口的外来链接。步骤如下,开启3306端口,重启防火墙
[root@mini ~]# firewall-cmd --query-port=3306/tcp # 查看3306端口是否开启 no [root@mini ~]# firewall-cmd --zone=public --add-port=3306/tcp --permanent # 开启3306端口 success [root@mini ~]# firewall-cmd --reload # 重启防火墙 success [root@mini ~]# firewall-cmd --query-port=3306/tcp # 查看3306端口是否开启 yes
2)先查看mysql数据库中的user表
[root@mini ~]# mysql -u root -p # 先通过本地链接进入数据库 MariaDB [(none)]> use mysql; MariaDB [mysql]> select host, user from user; +-----------+------+ | host | user | +-----------+------+ | 127.0.0.1 | root | | ::1 | root | | mini | root | +-----------+------+ 3 rows in set (0.00 sec)
3)将与主机名相等的字段改为 "%" ,我的主机名为mini,
MariaDB [mysql]> update user set host='%' where host='mini'; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 MariaDB [mysql]> select host, user from user; +-----------+------+ | host | user | +-----------+------+ | % | root | | 127.0.0.1 | root | | localhost | root | +-----------+------+ 3 rows in set (0.00 sec)
4)刷新权限表,或重启mariadb服务,一下二选一即可
MariaDB [mysql]> flush privileges; Query OK, 0 rows affected (0.00 sec)
[root@mini ~]# systemctl restart mariadb
注意:刷新权限表是在数据库中,重启服务是在外部命令行中
6)重新远程链接mariadb

posted @
2020-02-15 11:45 长戟十三千 阅读(286) |
评论 (0) |
编辑 收藏1.何为队列
听到队列相信大家对其并不陌生,在我们现实生活中队列随处可见,去超市结账,你会看见大家都会一排排的站得好好的,等待结账,为什么要站得一排排的,你想象一下大家都没有素质,一窝蜂的上去结账,不仅让这个超市崩溃,还会容易造成各种踩踏事件,当然这些事其实在我们现实中也是会经常发生。
当然在计算机世界中,队列是属于一种数据结构,队列采用的FIFO(first in firstout),新元素(等待进入队列的元素)总是被插入到尾部,而读取的时候总是从头部开始读取。在计算中队列一般用来做排队(如线程池的等待排队,锁的等待排队),用来做解耦(生产者消费者模式),异步等等。
2.jdk中的队列
在jdk中的队列都实现了java.util.Queue接口,在队列中又分为两类,一类是线程不安全的,ArrayDeque,LinkedList等等,还有一类都在java.util.concurrent包下属于线程安全,而在我们真实的环境中,我们的机器都是属于多线程,当多线程对同一个队列进行排队操作的时候,如果使用线程不安全会出现,覆盖数据,数据丢失等无法预测的事情,所以我们这个时候只能选择线程安全的队列。在jdk中提供的线程安全的队列下面简单列举部分队列:
| 队列名字 | 是否加锁 | 数据结构 | 关键技术点 | 是否有锁 | 是否有界 |
| ArrayBlockingQueue | 是 | 数组array | ReentrantLock | 有锁 | 有界 |
| LinkedBlockingQueue | 是 | 链表 | ReentrantLock | 有锁 | 有界 |
| LinkedTransferQueue | 否 | 链表 | CAS | 无锁 | 无界 |
| ConcurrentLinkedQueue | 否 | 链表 | CAS | 无锁 | 无界 |
我们可以看见,我们无锁的队列是无界的,有锁的队列是有界的,这里就会涉及到一个问题,我们在真正的线上环境中,无界的队列,对我们系统的影响比较大,有可能会导致我们内存直接溢出,所以我们首先得排除无界队列,当然并不是无界队列就没用了,只是在某些场景下得排除。其次还剩下ArrayBlockingQueue,LinkedBlockingQueue两个队列,他们两个都是用ReentrantLock控制的线程安全,他们两个的区别一个是数组,一个是链表,在队列中,一般获取这个队列元素之后紧接着会获取下一个元素,或者一次获取多个队列元素都有可能,而数组在内存中地址是连续的,在操作系统中会有缓存的优化(下面也会介绍缓存行),所以访问的速度会略胜一筹,我们也会尽量去选择ArrayBlockingQueue。而事实证明在很多第三方的框架中,比如早期的log4j异步,都是选择的ArrayBlockingQueue。
当然ArrayBlockingQueue,也有自己的弊端,就是性能比较低,为什么jdk会增加一些无锁的队列,其实就是为了增加性能,很苦恼,又需要无锁,又需要有界,这个时候恐怕会忍不住说一句你咋不上天呢?但是还真有人上天了。
3.Disruptor
Disruptor就是上面说的那个天,Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,并且是一个开源的并发框架,并获得2011Duke’s程序框架创新奖。能够在无锁的情况下实现网络的Queue并发操作,基于Disruptor开发的系统单线程能支撑每秒600万订单。目前,包括Apache Storm、Camel、Log4j2等等知名的框架都在内部集成了Disruptor用来替代jdk的队列,以此来获得高性能。
3.1为什么这么牛逼?
上面已经把Disruptor吹出了花了,你肯定会产生疑问,他真的能有这么牛逼吗,我的回答是当然的,在Disruptor中有三大杀器:
- CAS
- 消除伪共享
- RingBuffer 有了这三大杀器,Disruptor才变得如此牛逼。
3.1.1锁和CAS
我们ArrayBlockingQueue为什么会被抛弃的一点,就是因为用了重量级lock锁,在我们加锁过程中我们会把锁挂起,解锁后,又会把线程恢复,这一过程会有一定的开销,并且我们一旦没有获取锁,这个线程就只能一直等待,这个线程什么事也不能做。
CAS(compare and swap),顾名思义先比较在交换,一般是比较是否是老的值,如果是的进行交换设置,大家熟悉乐观锁的人都知道CAS可以用来实现乐观锁,CAS中没有线程的上下文切换,减少了不必要的开销。 这里使用JMH,用两个线程,每次1一次调用,在我本机上进行测试,代码如下:
@BenchmarkMode({Mode.SampleTime}) @OutputTimeUnit(TimeUnit.MILLISECONDS) @Warmup(iterations=3, time = 5, timeUnit = TimeUnit.MILLISECONDS) @Measurement(iterations=1,batchSize = 100000000) @Threads(2) @Fork(1) @State(Scope.Benchmark) public class Myclass { Lock lock = new ReentrantLock(); long i = 0; AtomicLong atomicLong = new AtomicLong(0); @Benchmark public void measureLock() { lock.lock(); i++; lock.unlock(); } @Benchmark public void measureCAS() { atomicLong.incrementAndGet(); } @Benchmark public void measureNoLock() { i++; } } 复制代码
测试出来结果如下:
| 测试项目 | 测试结果 |
| Lock | 26000ms |
| CAS | 4840ms |
| 无锁 | 197ms |
可以看见Lock是五位数,CAS是四位数,无锁更小是三位数。 由此我们可以知道Lock>CAS>无锁。
而我们的Disruptor中使用的就是CAS,他利用CAS进行队列中的一些下标设置,减少了锁的冲突,提高了性能。
另外对于jdk中其他的无锁队列也是使用CAS,原子类也是使用CAS。
3.1.2伪共享
谈到了伪共享就不得不说计算机CPU缓存,缓存大小是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。但是从CPU芯片面积和成本的因素来考虑,缓存都很小。

CPU缓存可以分为一级缓存,二级缓存,如今主流CPU还有三级缓存,甚至有些CPU还有四级缓存。每一级缓存中所储存的全部数据都是下一级缓存的一部分,这三种缓存的技术难度和制造成本是相对递减的,所以其容量也是相对递增的。
为什么CPU会有L1、L2、L3这样的缓存设计?主要是因为现在的处理器太快了,而从内存中读取数据实在太慢(一个是因为内存本身速度不够,另一个是因为它离CPU太远了,总的来说需要让CPU等待几十甚至几百个时钟周期),这个时候为了保证CPU的速度,就需要延迟更小速度更快的内存提供帮助,而这就是缓存。对这个感兴趣可以把电脑CPU拆下来,自己把玩一下。
每一次你听见intel发布新的cpu什么,比如i7-7700k,8700k,都会对cpu缓存大小进行优化,感兴趣可以自行下来搜索,这些的发布会或者发布文章。
Martin和Mike的 QConpresentation演讲中给出了一些每个缓存时间:
| 从CPU到 | 大约需要的CPU周期 | 大约需要的时间 |
| 主存 | | 约60-80纳秒 |
| QPI 总线传输(between sockets, not drawn) | | 约20ns |
| L3 cache | 约40-45 cycles | 约15ns |
| L2 cache | 约10 cycles | 约3ns |
| L1 cache | 约3-4 cycles | 约1ns |
| 寄存器 | | 1 cycle |
缓存行
在cpu的多级缓存中,并不是以独立的项来保存的,而是类似一种pageCahe的一种策略,以缓存行来保存,而缓存行的大小通常是64字节,在Java中Long是8个字节,所以可以存储8个Long,举个例子,你访问一个long的变量的时候,他会把帮助再加载7个,我们上面说为什么选择数组不选择链表,也就是这个原因,在数组中可以依靠缓冲行得到很快的访问。

缓存行是万能的吗?NO,因为他依然带来了一个缺点,我在这里举个例子说明这个缺点,可以想象有个数组队列,ArrayQueue,他的数据结构如下:
class ArrayQueue{ long maxSize; long currentIndex; } 复制代码
对于maxSize是我们一开始就定义好的,数组的大小,对于currentIndex,是标志我们当前队列的位置,这个变化比较快,可以想象你访问maxSize的时候,是不是把currentIndex也加载进来了,这个时候,其他线程更新currentIndex,就会把cpu中的缓存行置位无效,请注意这是CPU规定的,他并不是只吧currentIndex置位无效,如果此时又继续访问maxSize他依然得继续从内存中读取,但是MaxSize却是我们一开始定义好的,我们应该访问缓存即可,但是却被我们经常改变的currentIndex所影响。

Padding的魔法
为了解决上面缓存行出现的问题,在Disruptor中采用了Padding的方式,
class LhsPadding { protected long p1, p2, p3, p4, p5, p6, p7; } class Value extends LhsPadding { protected volatile long value; } class RhsPadding extends Value { protected long p9, p10, p11, p12, p13, p14, p15; } 复制代码
其中的Value就被其他一些无用的long变量给填充了。这样你修改Value的时候,就不会影响到其他变量的缓存行。
最后顺便一提,在jdk8中提供了@Contended的注解,当然一般来说只允许Jdk中内部,如果你自己使用那就得配置Jvm参数 -RestricContentended = fase,将限制这个注解置位取消。很多文章分析了ConcurrentHashMap,但是都把这个注解给忽略掉了,在ConcurrentHashMap中就使用了这个注解,在ConcurrentHashMap每个桶都是单独的用计数器去做计算,而这个计数器由于时刻都在变化,所以被用这个注解进行填充缓存行优化,以此来增加性能。

3.1.3RingBuffer
在Disruptor中采用了数组的方式保存了我们的数据,上面我们也介绍了采用数组保存我们访问时很好的利用缓存,但是在Disruptor中进一步选择采用了环形数组进行保存数据,也就是RingBuffer。在这里先说明一下环形数组并不是真正的环形数组,在RingBuffer中是采用取余的方式进行访问的,比如数组大小为 10,0访问的是数组下标为0这个位置,其实10,20等访问的也是数组的下标为0的这个位置。
实际上,在这些框架中取余并不是使用%运算,都是使用的&与运算,这就要求你设置的大小一般是2的N次方也就是,10,100,1000等等,这样减去1的话就是,1,11,111,就能很好的使用index & (size -1),这样利用位运算就增加了访问速度。 如果在Disruptor中你不用2的N次方进行大小设置,他会抛出buffersize必须为2的N次方异常。
当然其不仅解决了数组快速访问的问题,也解决了不需要再次分配内存的问题,减少了垃圾回收,因为我们0,10,20等都是执行的同一片内存区域,这样就不需要再次分配内存,频繁的被JVM垃圾回收器回收。

自此三大杀器已经说完了,有了这三大杀器为Disruptor如此高性能垫定了基础。接下来还会在讲解如何使用Disruptor和Disruptor的具体的工作原理。
3.2Disruptor怎么使用
下面举了一个简单的例子:
ublic static void main(String[] args) throws Exception { // 队列中的元素 class Element { @Contended private String value; public String getValue() { return value; } public void setValue(String value) { this.value = value; } } // 生产者的线程工厂 ThreadFactory threadFactory = new ThreadFactory() { int i = 0; @Override public Thread newThread(Runnable r) { return new Thread(r, "simpleThread" + String.valueOf(i++)); } }; // RingBuffer生产工厂,初始化RingBuffer的时候使用 EventFactory<Element> factory = new EventFactory<Element>() { @Override public Element newInstance() { return new Element(); } }; // 处理Event的handler EventHandler<Element> handler = new EventHandler<Element>() { @Override public void onEvent(Element element, long sequence, boolean endOfBatch) throws InterruptedException { System.out.println("Element: " + Thread.currentThread().getName() + ": " + element.getValue() + ": " + sequence); // Thread.sleep(10000000); } }; // 阻塞策略 BlockingWaitStrategy strategy = new BlockingWaitStrategy(); // 指定RingBuffer的大小 int bufferSize = 8; // 创建disruptor,采用单生产者模式 Disruptor<Element> disruptor = new Disruptor(factory, bufferSize, threadFactory, ProducerType.SINGLE, strategy); // 设置EventHandler disruptor.handleEventsWith(handler); // 启动disruptor的线程 disruptor.start(); for (int i = 0; i < 10; i++) { disruptor.publishEvent((element, sequence) -> { System.out.println("之前的数据" + element.getValue() + "当前的sequence" + sequence); element.setValue("我是第" + sequence + "个"); }); } } 复制代码
在Disruptor中有几个比较关键的: ThreadFactory:这是一个线程工厂,用于我们Disruptor中生产者消费的时候需要的线程。 EventFactory:事件工厂,用于产生我们队列元素的工厂,在Disruptor中,他会在初始化的时候直接填充满RingBuffer,一次到位。 EventHandler:用于处理Event的handler,这里一个EventHandler可以看做是一个消费者,但是多个EventHandler他们都是独立消费的队列。 WorkHandler:也是用于处理Event的handler,和上面区别在于,多个消费者都是共享同一个队列。 WaitStrategy:等待策略,在Disruptor中有多种策略,来决定消费者获消费时,如果没有数据采取的策略是什么?下面简单列举一下Disruptor中的部分策略
-
BlockingWaitStrategy:通过线程阻塞的方式,等待生产者唤醒,被唤醒后,再循环检查依赖的sequence是否已经消费。
-
BusySpinWaitStrategy:线程一直自旋等待,可能比较耗cpu
-
LiteBlockingWaitStrategy:线程阻塞等待生产者唤醒,与BlockingWaitStrategy相比,区别在signalNeeded.getAndSet,如果两个线程同时访问一个访问waitfor,一个访问signalAll时,可以减少lock加锁次数.
-
LiteTimeoutBlockingWaitStrategy:与LiteBlockingWaitStrategy相比,设置了阻塞时间,超过时间后抛异常。
-
YieldingWaitStrategy:尝试100次,然后Thread.yield()让出cpu
EventTranslator:实现这个接口可以将我们的其他数据结构转换为在Disruptor中流通的Event。
3.3工作原理
上面已经介绍了CAS,减少伪共享,RingBuffer三大杀器,介绍下来说一下Disruptor中生产者和消费者的整个流程。
3.3.1生产者
对于生产者来说,可以分为多生产者和单生产者,用ProducerType.Single,和ProducerType.MULTI区分,多生产者和单生产者来说多了CAS,因为单生产者由于是单线程,所以不需要保证线程安全。
在disruptor中通常用disruptor.publishEvent和disruptor.publishEvents()进行单发和群发。
在disruptor发布一个事件进入队列需要下面几个步骤:
- 首先获取RingBuffer中下一个在RingBuffer上可以发布的位置,这个可以分为两类:
- 从来没有写过的位置
- 已经被所有消费者读过,可以在写的位置。 如果没有读取到会一直尝试去读,disruptor做的很巧妙,并没有一直占据CPU,而是通过LockSuport.park(),进行了一下将线程阻塞挂起操作,为的是不让CPU一直进行这种空循环,不然其他线程都抢不到CPU时间片。
 获取位置之后会进行cas进行抢占,如果是单线程就不需要。
获取位置之后会进行cas进行抢占,如果是单线程就不需要。
- 接下来调用我们上面所介绍的EventTranslator将第一步中RingBuffer中那个位置的event交给EventTranslator进行重写。
- 进行发布,在disruptor还有一个额外的数组用来记录当前ringBuffer所在位置目前最新的序列号是多少,拿上面那个0,10,20举例,写到10的时候这个avliableBuffer就在对应的位置上记录目前这个是属于10,有什么用呢后面会介绍。进行发布的时候需要更新这个avliableBuffer,然后进行唤醒所有阻塞的生产者。
下面简单画一下流程,上面我们拿10举例是不对的,因为bufferSize必须要2的N次方,所以我们这里拿Buffersize=8来举例:下面介绍了当我们已经push了8个event也就是一圈的时候,接下来再push 3条消息的一些过程: 1.首先调用next(3),我们当前在7这个位置上所以接下来三条是8,9,10,取余也就是0,1,2。 2.重写0,1,2这三个内存区域的数据。 3.写avaliableBuffer。

对了不知道大家对上述流程是不是很熟悉呢,对的那就是类似我们的2PC,两阶段提交,先进行RingBuffer的位置锁定,然后在进行提交和通知消费者。具体2PC的介绍可以参照我的另外一篇文章再有人问你分布式事务,给他看这篇文章。
3.3.1消费者
对于消费者来说,上面介绍了分为两种,一种是多个消费者独立消费,一种是多个消费者消费同一个队列,这里介绍一下较为复杂的多个消费者消费同一个队列,能理解这个也就能理解独立消费。 在我们的disruptor.strat()方法中会启动我们的消费者线程以此来进行后台消费。在消费者中有两个队列需要我们关注,一个是所有消费者共享的进度队列,还有个是每个消费者独立消费进度队列。 1.对消费者共享队列进行下一个Next的CAS抢占,以及对自己消费进度的队列标记当前进度。 2.为自己申请可读的RingBuffer的Next位置,这里的申请不仅仅是申请到next,有可能会申请到比Next大的一个范围,阻塞策略的申请的过程如下:
- 获取生产者对RingBuffer最新写的位置
- 判断其是否小于我要申请读的位置
- 如果大于则证明这个位置已经写了,返回给生产者。
- 如果小于证明还没有写到这个位置,在阻塞策略中会进行阻塞,其会在生产者提交阶段进行唤醒。 3.对这个位置进行可读校验,因为你申请的位置可能是连续的,比如生产者目前在7,接下来申请读,如果消费者已经把8和10这个序列号的位置写进去了,但是9这个位置还没来得及写入,由于第一步会返回10,但是9其实是不能读的,所以得把位置向下收缩到8。
 4.如果收缩完了之后比当前next要小,则继续循环申请。 5.交给handler.onEvent()处理
4.如果收缩完了之后比当前next要小,则继续循环申请。 5.交给handler.onEvent()处理
一样的我们举个例子,我们要申请next=8这个位置。 1.首先在共享队列抢占进度8,在独立队列写入进度7 2.获取8的可读的最大位置,这里根据不同的策略进行,我们选择阻塞,由于生产者生产了8,9,10,所以返回的是10,这样和后续就不需要再次和avaliableBuffer进行对比了。 3.最后交给handler进行处理。

4.Log4j中的Disruptor
下面的图展现了Log4j使用Disruptor,ArrayBlockingQueue以及同步的Log4j吞吐量的对比,可以看见使用了Disruptor完爆了其他的,当然还有更多的框架使用了Disruptor,这里就不做介绍了。

作者:咖啡拿铁
链接:https://juejin.im/post/5b5f10d65188251ad06b78e3
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
posted @
2020-01-16 20:12 长戟十三千 阅读(1973) |
评论 (1) |
编辑 收藏
1、共享内存实现跨进程消息队列:《UNIX网络编程卷2》,消息队列,p85
offset识别结构体内容,防止重复加载内存地址变更。共享信号量或者无锁环形队列,MAGIC NUMBER 验证,防止版本不一致。
2、虚拟实时:《linux内核设计与实现》, 进程调度,p43
调度时使用时间记账。虚拟运行时间 +=加权(上一帧运行时间); while {run get_task( min(虚拟运行时间) ) ;}(true);
移动检测时曾用到过异常移动的加权算法,与这个类似。每步移动异常加权,总量超过后,执行 禁止移动时间=异常总量/速度 的惩罚。
3、等待队列:《linux内核设计与实现》, 进程调度,p50
在读列上自旋,没有事件则调度等待,否则返回。
epoll源码:自旋锁+就绪队列,mutex+红黑树数据
无限法则服务器:接口->协程+rpc->服务组件, 可灰更微服务,共享内存1s拉起,接口自动测试,全局锁服务器用于独占某些服务或操作。
ECS模式:word=system+entity; system=sys1+sys2+sysn; entity=componentN;
位标记的静态数组:int info_flg; T vct_info; 《linux内核设计与实现》, 软中断,p111。 tasklet:利用静态软中断,添加调度策略:高低优先级链表。ksoftirqd:每个cpu上低优先级内核线程池,处理高并发软中断,防止造成用户线程饥饿。
posted @
2020-01-16 16:32 长戟十三千 阅读(445) |
评论 (0) |
编辑 收藏
摘要: inline是C++关键字,在函数声明或定义中,函数返回类型前加上关键字inline,即可以把函数指定为内联函数。这样可以解决一些频繁调用的函数大量消耗栈空间(栈内存)的问题。关键字inline必须与函数定义放在一起才能使函数成为内联函数,仅仅将inline放在函数声明前面不起任何作用。inline是一种“用于实现”的关键字,而不是一种“用于声明”的...
阅读全文
posted @
2020-01-13 11:28 长戟十三千 阅读(412) |
评论 (0) |
编辑 收藏
摘要: 3)下面的函数被用来计算某个整数的平方,它能实现预期设计目标吗?如果不能,试回答存在什么问题:1234int square(volatile int *ptr){ return ((*ptr) * (*ptr));}3)这段代码是个恶作剧。这段代码的目的是用来返指针*ptr指向值的平方,但是,...
阅读全文
posted @
2020-01-13 11:22 长戟十三千 阅读(384) |
评论 (0) |
编辑 收藏前言
字节对齐是我们初学C语言就会接触到的一个概念,但是到底什么是字节对齐?对齐准则又是什么?为什么要字节对齐呢?字节对齐对我们编程有什么启示?本文将简单理一理字节对齐的那些事。
什么是字节对齐
计算机中内存大小的基本单位是字节(byte),理论上来讲,可以从任意地址访问某种基本数据类型,但是实际上,计算机并非逐字节大小读写内存,而是以2,4,或8的 倍数的字节块来读写内存,如此一来就会对基本数据类型的合法地址作出一些限制,即它的地址必须是2,4或8的倍数。那么就要求各种数据类型按照一定的规则在空间上排列,这就是对齐。
对齐准则是什么
总的来说,字节对齐有以下准则:
- 结构体变量的首地址能够被其对齐字节数大小所整除。
- 结构体每个成员相对结构体首地址的偏移都是成员大小的整数倍,如不满足,对前一个成员填充字节以满足。
- 结构体的总大小为结构体对齐字节数大小的整数倍,如不满足,最后填充字节以满足。
我们通过一个小例子来说明是如何对齐的。
考虑下面的程序
/*================================================================ * Copyright (C) 2018 Ltd. All rights reserved. * * 文件名称:testByteAlign.c * 创 建 者:shouwang * 创建日期:2018年09月15日 * 描 述: * ================================================================*/ #include<stdio.h> #include<stdint.h> struct test { int a; char b; int c; short d; }; int main(int argc,char *argv) { /*在32位和64位的机器上,size_t的大小不同*/ printf("the size of struct test is %zu\n",sizeof(struct test)); return 0; }
编译成32位程序并运行(默认四字节自然对齐),可以看到,结构体test 的大小为16字节,而不是11字节(a占4字节,b占1字节,c占4字节,d占2字节)
#64位机器上编译32位程序可能需要安装一个库 #sudo apt-get install gcc-multilib gcc -m32 -o testByteAlign testByteAlign.c #编译程序 chmod +x testByteAlign #赋执行权限 ./testByteAlign #运行 the size of struct test is 16
实际上,结构体test的成员在内存中可能是像下面这样分布的(数值为偏移量)
未对齐时:
0~345~910~11abcd
对齐时:
0~345~78~1112~1314~15ab填充内容cd填充内容
从上面可以看出,c的偏移为5,不满足对齐要求(它的偏移量应该能够被sizeof(int)大小整除),因此在b后面填充了3个字节,使得c的偏移为8。在b后面填充后,d已经满足对齐要求了,为什么最后还要填充字节呢?或者说,为什么需要满足第三条准则呢?
考虑下面的声明
我们不难知道,teArray[0]的d如果不填充字节,那么teArray[1]的a偏移为14,不满足对齐要求,因此d后面也需要填充字节。
为什么要字节对齐
无论数据是否对齐,大多数计算机还是能够正确工作,而且从前面可以看到,结构体test本来只需要11字节的空间,最后却占用了16字节,很明显浪费了空间,那么为什么还要进行字节对齐呢?最重要的考虑是提高内存系统性能
前面我们也说到,计算机每次读写一个字节块,例如,假设计算机总是从内存中取8个字节,如果一个double数据的地址对齐成8的倍数,那么一个内存操作就可以读或者写,但是如果这个double数据的地址没有对齐,数据就可能被放在两个8字节块中,那么我们可能需要执行两次内存访问,才能读写完成。显然在这样的情况下,是低效的。所以需要字节对齐来提高内存系统性能。
在有些处理器中,如果需要未对齐的数据,可能不能够正确工作甚至crash,这里我们不多讨论。
实际编程中的考虑
实际上,字节对齐的细节都由编译器来完成,我们不需要特意进行字节的对齐,但并不意味着我们不需要关注字节对齐的问题。
空间存储
还是考虑前面的结构体test,其占用空间大小为16字节,但是如果我们换一种声明方式,调整变量的顺序,重新运行程序,最后发现结构体test占用大小为12字节
struct test { int a; char b; short d; int c; };
空间存储情况如下,b和c存储在了一个字节快中:
0~3456~78~11ab填充内容cd
也就是说,如果我们在设计结构的时候,合理调整成员的位置,可以大大节省存储空间。
跨平台通信
由于不同平台对齐方式可能不同,如此一来,同样的结构在不同的平台其大小可能不同,在无意识的情况下,互相发送的数据可能出现错乱,甚至引发严重的问题。因此,为了不同处理器之间能够正确的处理消息,我们有两种可选的处理方法。
我们可以使用伪指令#pragma pack(n)(n为字节对齐数)来使得结构间一字节对齐。
同样是前面的程序,如果在结构体test的前面加上伪指令,即如下:
#pragma pack(1) /*1字节对齐*/ struct test { int a; char b; int c; short d; }; #pragma pack()/*还原默认对齐*/
在这样的声明下,任何平台结构体test的大小都为11字节,这样做能够保证跨平台的结构大小一致,同时还节省了空间,但不幸的是,降低了效率。
当然了对于单个结构体,gcc还有如下的方法,使其1字节对齐
struct test { int a; char b; int c; short d; }__attribute__ ((packed));
注:
- __attribute__((aligned (n))),让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。
- __attribute__ ((packed)),取消结构在编译过程中的优化对齐,也可以认为是1字节对齐。
除了前面的1字节对齐,还可以进行人为的填充,即test结构体声明如下:
struct test { int a; char b; char reserve[3]; int c; short d; char reserve1[2]; };
访问效率高,但并不节省空间,同时扩展性不是很好,例如,当字节对齐有变化时,需要填充的字节数可能就会发生变化。
总结
虽然我们不需要具体关心字节对齐的细节,但是如果不关注字节对齐的问题,可能会在编程中遇到难以理解或解决的问题。因此针对字节对齐,总结了以下处理建议:
- 结构体成员合理安排位置,以节省空间
- 跨平台数据结构可考虑1字节对齐,节省空间但影响访问效率
- 跨平台数据结构人为进行字节填充,提高访问效率但不节省空间
- 本地数据采用默认对齐,以提高访问效率
posted @
2020-01-09 16:54 长戟十三千 阅读(377) |
评论 (0) |
编辑 收藏