protobuf简介
protobuf是google提供的一个开源序列化框架,类似于XML,JSON这样的数据表示语言,其最大的特点是基于二进制,因此比传统的XML表示高效短小得多。虽然是二进制数据格式,但并没有因此变得复杂,开发人员通过按照一定的语法定义结构化的消息格式,然后送给命令行工具,工具将自动生成相关的类,可以支持java、c++、python等语言环境。通过将这些类包含在项目中,可以很轻松的调用相关方法来完成业务消息的序列化与反序列化工作。
protobuf在google中是一个比较核心的基础库,作为分布式运算涉及到大量的不同业务消息的传递,如何高效简洁的表示、操作这些业务消息在google这样的大规模应用中是至关重要的。而protobuf这样的库正好是在效率、数据大小、易用性之间取得了很好的平衡。
更多信息可参考官方文档
例子介绍
先下载protobuf-2.3.0.zip源代码库,下载后解压,选择vsprojects目录下的protobuf.sln解决方案打开,编译整个方案顺利成功。其中有一些测试工程,库相关的工程是libprotobuf、libprotobuf-lite、libprotoc和protoc。其中protoc是命令行工具。在example目录下有一个地址薄消息的例子,业务消息的定义文件后缀为.proto,其中的addressbook.proto内容为:
package tutorial;
option java_package = "com.example.tutorial";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2; // Unique ID number for this person.
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
// Our address book file is just one of these.
message AddressBook {
repeated Person person = 1;
}
该定义文件,定义了地址薄消息的结构,顶层消息为AddressBook,其中包含多个Person消息,Person消息中又包含多个PhoneNumber消息。里面还定义了一个PhoneType的枚举类型。
类型前面有required表示必须,optional表示可选,repeated表示重复,这些定义都是一目了然的,无须多说。关于消息定义的详细语法可参考官方文档。
现在用命令行工具来生成业务消息类,切换到protoc.exe所在的debug目录,在命令行敲入:
protoc.exe --proto_path=..\..\examples --cpp_out=..\..\examples ..\..\examples\addressbook.proto
该命令中--proto_path参数表示.proto消息定义文件路径,--cpp_out表示输出c++类的路径,后面接着是addressbook.proto消息定义文件。该命令会读取addressbook.proto文件并生成对应的c++类头文件和实现文件。执行完后在examples目录生存了addressbook.pb.h和addressbook.pb.cpp。
现在新建两个空控制台工程,第一个不妨叫AddPerson,然后把examples目录下的add_person.cc、addressbook.pb.h和addressbook.pb.cpp加入到该工程,另一个工程不妨叫ListPerson,将examples目录下的list_people.cc、addressbook.pb.h和addressbook.pb.cpp加入到该工程,在两个工程的项目属性中附加头文件路径../src。两个工程的项目依赖都选择libprotobuf工程(库)。
给AddPerson工程添加一个命令行参数比如叫addressbook.dat用于将地址薄信息序列化写入该文件,然后编译运行AddPerson工程,根据提示输入地址薄信息:
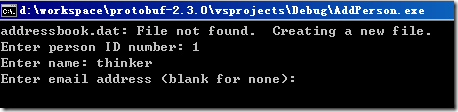
输入完成后,将序列化到addressbook.dat文件中。
在ListPerson工程的命令行参数中加读取文件参数..\AddPerson\addressbook.dat,然后在运行ListPerson工程,可在 list_people.cc的最后设个断点,避免命令行窗口运行完后关闭看不到结果:
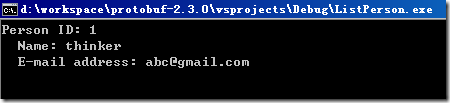
写入地址薄的操作,关键操作就是调用address_book.SerializeToOstream进行序列化到文件流。
而读取操作中就是address_book.ParseFromIstream从文件流反序列化,这都是框架自动生成的类中的方法。
其他操作都是业务消息的字段set/get之类的对象级操作,很明了。更详细的API参考官方文档有详细说明。
在TCP网络编程中的考虑
从上面的例子可以看出protobuf这样的库是很方便高效的,那么自然的想到在网络编程中用来做业务消息的序列化、反序列化支持。在基于UDP协议的网络应用中,由于UDP本身是有边界,那么用protobuf来处理业务消息就很方便。但在TCP应用中,由于TCP协议没有消息边界,这就需要有一种机制来确定业务消息边界。在TCP网络编程中这是必须面对的问题。
注意上面的address_book.ParseFromIstream调用,如果流参数的内容多一个字节或者少一个字节,该方法都会返回失败(虽然某些字段可能正确得到结果了),也就是说送给反序列化的数据参数除了格式正确还必须有正确的大小。因此在tcp网络编程中,要反序列化业务消息,就要先知道业务数据的大小。而且在实际应用中可能在一个发送操作中,发送多个业务消息,而且每个业务消息的大小、类型都不一样。而且可能发送很大的数据流,比如文件。
显然消息边界的确认问题和protobuf库无关,还得自己搞定。在官方文档中也提到,protobuf并不太适合来作大数据的处理,当业务消息超过1M时,就应该考虑是否应该用另外的替代方案。当然对于大数据,你也可以分割为多个小块用protobuf做小块消息封装进行传递。但对很多应用这样的作法显得比较多余,比如发送一个大的文件,一般是在接收方从协议栈收到多少数据就写多少数据到磁盘,这是一种边接收边处理的流模式,这种模式基本上和每次收到的数据量没有关系。这种模式下再采用分割成小消息进行反序列化就显得多此一举了。
由于每个业务消息的大小和处理方式都可能不一样,那么就需要独立抽象出一个边界消息来区分不同的业务消息,而且这个边界消息的格式和大小必须固定。对于网络编程熟手,可能早已经想到了这样的消息,我们可以结合protobuf库来定义一个边界消息,不妨叫BoundMsg:
message BoundMsg
{
required int32 msg_type = 1;
required int32 msg_size = 2;
}
可以根据需要扩充一些字段,但最基本的这两个字段就够用了。我们只需要知道业务消息的类型和大小即可。这个消息大小是固定的8字节,专门用来确定数据流的边界。有了这样的边界消息,在接收端处理任何业务消息就很灵活方便了,下面是接收端处理的简单伪代码示例:
if(net_read(buf,8))
{
boundMsg.ParseFromIstream(buf);
switch(boundMsg.msg_type)
{
case BO_1:
if(net_read(bo1Buf,boundMsg.msg_size))
{
bo1.ParseFromIstream(bo1Buf);
....
}
break;
case BO_2:
if(net_read(bo2Buf,boundMsg.msg_size))
{
bo2.ParseFromIstream(bo2Buf);
....
}
break;
case FILE_DATA:
count = 0;
while(count < boundMsg.msg_size)
{
piece_size = net_read(fileBuf,1024);
write_file(filename,fileBuf,piece_size);
count = count + piece_size;
}
break;
}
}
注意上面如果FILE_DATA消息后,还紧接其他业务消息的话,需要小心,即count累计出的值可能大于
boundMsg.msg_size的值,那么多出来的实际上应该是下一个边界消息数据了。为了避免处理的复杂性,上面所有的循环网络读取操作(上面BO_1,BO_2都可能需要循环读取,为了简化没有写成循环)的缓冲区位置和大小参数应该动态调整,即每次读取时传递的都是还期望读取的数据大小,对于文件的话,可能特殊点,因为边读取边写入,就没有必要事先要分配一个文件大小的缓冲区来存放数据了。对于文件分配一个小缓冲区来读,注意确认下边界即可。
上面是我的一点考虑,不妥之处还请大家讨论交流。想想借助于ACE、MINA这样的网络编程框架,然后结合protobuf这样的序列化框架,网络编程中技术基础设施层面的东西就给我们解决得差不多了,我们可以真正只关注于业务的实现。