|
#
查看端口被占用情况:
开始==》运行==》cmd==》netstat -ano|more(后面加more可以分页显示) 可获得PID,记下PID
查看进程被谁启动:
任务管理器==》查看(V)==》选择列(S)…==》勾选“PID(进程标识符)”==》找到PID对应的映像名称……
摘要: 编写自己的一个ping程序,可以说是许多人迈出网络编程的第一步吧!!这个ping程序的源代码经过我的修改和调试,基本上可以取代windows中自带的ping程序. 各个模块后都有我的详细注释和修改日志,希望能够对大家的学习
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighli... 阅读全文
插入排序
1.直接插入排序
原理:将数组分为无序区和有序区两个区,然后不断将无序区的第一个元素按大小顺序插入到有序区中去,最终将所有无序区元素都移动到有序区完成排序。
要点:设立哨兵,作为临时存储和判断数组边界之用。
实现:
Void InsertSort(Node L[],int length)
{
Int i,j;//分别为有序区和无序区指针
for(i=1;i<length;i++)//逐步扩大有序区
{
j=i+1;
if(L[j]<L[i])
{
L[0]=L[j];//存储待排序元素
While(L[0]<L[i])//查找在有序区中的插入位置,同时移动元素
{
L[i+1]=L[i];//移动
i--;//查找
}
L[i+1]=L[0];//将元素插入
}
i=j-1;//还原有序区指针
}
}
2.希尔排序
原理:又称增量缩小排序。先将序列按增量划分为元素个数相同的若干组,使用直接插入排序法进行排序,然后不断缩小增量直至为1,最后使用直接插入排序完成排序。
要点:增量的选择以及排序最终以1为增量进行排序结束。
实现:
Void shellSort(Node L[],int d)
{
While(d>=1)//直到增量缩小为1
{
Shell(L,d);
d=d/2;//缩小增量
}
}
Void Shell(Node L[],int d)
{
Int i,j;
For(i=d+1;i<length;i++)
{
if(L[i]<L[i-d])
{
L[0]=L[i];
j=i-d;
While(j>0&&L[j]>L[0])
{
L[j+d]=L[j];//移动
j=j-d;//查找
}
L[j+d]=L[0];
}
}
}
交换排序
1.冒泡排序
原理:将序列划分为无序和有序区,不断通过交换较大元素至无序区尾完成排序。
要点:设计交换判断条件,提前结束以排好序的序列循环。
实现:
Void BubbleSort(Node L[])
{
Int i ,j;
Bool ischanged;//设计跳出条件
For(j=n;j<0;j--)
{
ischanged =false;
For(i=0;i<j;i++)
{
If(L[i]>L[i+1])//如果发现较重元素就向后移动
{
Int temp=L[i];
L[i]=L[i+1];
L[i+1]=temp;
Ischanged =true;
}
}
If(!ischanged)//若没有移动则说明序列已经有序,直接跳出
Break;
}
}
2.快速排序
原理:不断寻找一个序列的中点,然后对中点左右的序列递归的进行排序,直至全部序列排序完成,使用了分治的思想。
要点:递归、分治
实现:
选择排序
1.直接选择排序
原理:将序列划分为无序和有序区,寻找无序区中的最小值和无序区的首元素交换,有序区扩大一个,循环最终完成全部排序。
要点:
实现:
Void SelectSort(Node L[])
{
Int i,j,k;//分别为有序区,无序区,无序区最小元素指针
For(i=0;i<length;i++)
{
k=i;
For(j=i+1;j<length;j++)
{
If(L[j]<L[k])
k=j;
}
If(k!=i)//若发现最小元素,则移动到有序区
{
Int temp=L[k];
L[k]=L[i];
L[i]=L[temp];
}
}
}
2.堆排序
原理:利用大根堆或小根堆思想,首先建立堆,然后将堆首与堆尾交换,堆尾之后为有序区。
要点:建堆、交换、调整堆
实现:
Void HeapSort(Node L[])
{
BuildingHeap(L);//建堆(大根堆)
For(int i=n;i>0;i--)//交换
{
Int temp=L[i];
L[i]=L[0];
L[0]=temp;
Heapify(L,0,i);//调整堆
}
}
Void BuildingHeap(Node L[])
{ For(i=length/2 -1;i>0;i--)
Heapify(L,i,length);
}
归并排序
原理:将原序列划分为有序的两个序列,然后利用归并算法进行合并,合并之后即为有序序列。
要点:归并、分治
实现:
Void MergeSort(Node L[],int m,int n)
{
Int k;
If(m<n)
{
K=(m+n)/2;
MergeSort(L,m,k);
MergeSort(L,k+1,n);
Merge(L,m,k,n);
}
}
基数排序
原理:将数字按位数划分出n个关键字,每次针对一个关键字进行排序,然后针对排序后的序列进行下一个关键字的排序,循环至所有关键字都使用过则排序完成。
要点:对关键字的选取,元素分配收集。
实现:
Void RadixSort(Node L[],length,maxradix)
{
Int m,n,k,lsp;
k=1;m=1;
Int temp[10][length-1];
Empty(temp); //清空临时空间
While(k<maxradix) //遍历所有关键字
{
For(int i=0;i<length;i++) //分配过程
{
If(L[i]<m)
Temp[0][n]=L[i];
Else
Lsp=(L[i]/m)%10; //确定关键字
Temp[lsp][n]=L[i];
n++;
}
CollectElement(L,Temp); //收集
n=0;
m=m*10;
k++;
}
}
dll是在你的程序运行的时候才连接的文件,因此它是一种比较小的可执行文件格式,.dll还有其他的文件格式如.ocx等,所有的.dll文件都是可执行;
lib是在你的程序编译连接的时候就连接的文件,因此你必须告知编译器连接的lib文件在那里。一般来说,与动态连接文件相对比,lib文件也被称为是静态连接库。当你把代码编译成这几种格式的文件时,在以后他们就不可能再被更改。如果你想使用lib文件,就必须:
1. 包含一个对应的头文件告知编译器lib文件里面的具体内容
2 .设置lib文件允许编译器去查找已经编译好的二进制代码
如果你想从你的代码分离一个dll文件出来代替静态连接库,仍然需要一个lib文件。这个lib文件将被连接到程序告诉操作系统在运行的时候你想用到什么 dll文件,一般情况下,lib文件里有相应的dll文件的名字和一个指明dll输出函数入口的顺序表。如果不想用lib文件或者是没有lib文件,可以使用WIN32 API函数LoadLibrary、GetProcAddress。事实上,我们可以在Visual C++ IDE中以二进制形式打开lib文件,大多情况下会看到ASCII码格式的C++函数或一些重载操作的函数名字。
一般我们最主要的关于lib文件的麻烦就是出现unresolved symble 这类错误,这就是lib文件连接错误或者没有包含.c、.cpp文件到工程里,关键是如果在C++工程里用了C语言写的lib文件,就必需要这样包含:
extern "C"
{
#include "myheader.h"
}
这是因为C语言写的lib文件没有C++所必须的名字破坏,C函数不能被重载,因此连接器会出错。
在VC中不用MFC如何制作dll
方法一:使用export 和 import
在VC中建立一个Console Application,建立2个文件:Dll.h 和 Dll.cpp
Dll.h
========================================================
#ifdef MYLIBAPI
#else
#define MYLIBAPI extern "C" _declspec (dllimport)
#end if
MYLIBAPI int Add (int iLeft, int iRight)
MYLIBAPI int Sub (int iLeft, int iRight)
========================================================
Dll.cpp
========================================================
#define MYLIBAPI extern "C" _declspec (dllexport)
#include "Dll.h"
int Add (int iLeft, int iRight)
{
return iLeft + iRight ;
}
int Sub (int iLeft, int iRight)
{
return iLeft - iRight ;
}
========================================================
保存文件。在Project->setting->link 最下面加上 “/dll”, "/"之前一定要与前一项有空格。然后编译,就可以在debug 或 release下面找到dll 和 lib 文件了使用的时候包含dll.h文件。
方法二:使用def文件
建立一个console application, 建立2个文件dll.h 和 dll.cpp
Dll.h
========================================================
int Add (int iLeft, int iRight) ;
int Sub (int iLeft, int iRight) ;
========================================================
Dll.cpp
========================================================
#include "Dll.h"
int Add (int iLeft, int iRight)
{
return iLeft + iRight ;
}
int Sub (int iLeft, int iRight)
{
return iLeft - iRight ;
}
========================================================
然后再当前目录下面建立一个.def文件,文件名最好和要输出的dll名字一样,扩展名为.def, 里面写上:
LIBRARY dllname.dll
EXPORTS
Add @1
Add @2
然后将这个文件添加到工程中,在link中设置 /dll, 然后编译在debug或release中就可以找到dll和lib了
使用的时候加上dll.h文件。
===============================
补充一点:
dll是个编译好的程序,调用时可以直接调用其中的函数,不参加工程的编译。而lib应该说是一个程序集,只是把一些相应的函数总结在一起,如果调用lib中的函数,在工程编译时,这些调用的函数都将参加编译。
简单讲,静态库就是直接将需要的代码连接进可执行程序;动态库就是在需要调用其中的函数时,根据函数映射表找到该函数然后调入堆栈执行。
做成静态库可执行文件本身比较大,但不必附带动态库
做成动态库可执行文件本身比较小,但需要附带动态库
其它没有什么对于程序员而言很大的区别,有的Unix可能不支持动态库,所以只好用静态库。
DLL与LIB的区别:
1.DLL是一个完整程序,其已经经过链接,即不存在同名引用,且有导出表,与导入表lib是一个代码集(也叫函数集)他没有链接,所以lib有冗余,当两个lib相链接时地址会重新建立,当然还有其它相关的不同,用lib.exe就知道了;
2.在生成dll时,经常会生成一个.lib(导入与导出),这个lib实际上不是真正的函数集,其每一个导出导入函数都是跳转指令,直接跳转到DLL中的位置,这个目的是外面的程序调用dll时自动跳转;
3.实际上最常用的lib是由lib.exe把*.obj生成的lib。
我们在用C/C++语言写程序的时侯,内存管理的绝大部分工作都是需要我们来做的。实际上,内存管理是一个比较繁琐的工作,无论你多高明,经验多丰富,难免会在此处犯些小错误,而通常这些错误又是那么的浅显而易于消除。但是手工“除虫”(debug),往往是效率低下且让人厌烦的,本文将就"段错误"这个内存访问越界的错误谈谈如何快速定位这些"段错误"的语句。 下面将就以下的一个存在段错误的程序介绍几种调试方法:
1 dummy_function (void)
2 {
3 unsigned char *ptr = 0x00;
4 *ptr = 0x00;
5 }
6
7 int main (void)
8 {
9 dummy_function ();
10
11 return 0;
12 }
|
作为一个熟练的C/C++程序员,以上代码的bug应该是很清楚的,因为它尝试操作地址为0的内存区域,而这个内存区域通常是不可访问的禁区,当然就会出错了。我们尝试编译运行它:
xiaosuo@gentux test $ ./a.out
段错误
|
果然不出所料,它出错并退出了。 1.利用gdb逐步查找段错误:这种方法也是被大众所熟知并广泛采用的方法,首先我们需要一个带有调试信息的可执行程序,所以我们加上“-g -rdynamic"的参数进行编译,然后用gdb调试运行这个新编译的程序,具体步骤如下:
xiaosuo@gentux test $ gcc -g -rdynamic d.c
xiaosuo@gentux test $ gdb ./a.out
GNU gdb 6.5
Copyright (C) 2006 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...Using host libthread_db library "/lib/libthread_db.so.1".
(gdb) r
Starting program: /home/xiaosuo/test/a.out
Program received signal SIGSEGV, Segmentation fault.
0x08048524 in dummy_function () at d.c:4
4 *ptr = 0x00;
(gdb)
|
哦?!好像不用一步步调试我们就找到了出错位置d.c文件的第4行,其实就是如此的简单。 从这里我们还发现进程是由于收到了SIGSEGV信号而结束的。通过进一步的查阅文档(man 7 signal),我们知道SIGSEGV默认handler的动作是打印”段错误"的出错信息,并产生Core文件,由此我们又产生了方法二。 2.分析Core文件:Core文件是什么呢?
| The default action of certain signals is to cause a process to terminate and produce a core dump file, a disk file containing an image of the process's memory at the time of termination. A list of the signals which cause a process to dump core can be found in signal(7). |
以上资料摘自man page(man 5 core)。不过奇怪了,我的系统上并没有找到core文件。后来,忆起为了渐少系统上的拉圾文件的数量(本人有些洁癖,这也是我喜欢Gentoo的原因之一),禁止了core文件的生成,查看了以下果真如此,将系统的core文件的大小限制在512K大小,再试:
xiaosuo@gentux test $ ulimit -c
0
xiaosuo@gentux test $ ulimit -c 1000
xiaosuo@gentux test $ ulimit -c
1000
xiaosuo@gentux test $ ./a.out
段错误 (core dumped)
xiaosuo@gentux test $ ls
a.out core d.c f.c g.c pango.c test_iconv.c test_regex.c
|
core文件终于产生了,用gdb调试一下看看吧:
xiaosuo@gentux test $ gdb ./a.out core
GNU gdb 6.5
Copyright (C) 2006 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...Using host libthread_db library "/lib/libthread_db.so.1".
warning: Can't read pathname for load map: 输入/输出错误.
Reading symbols from /lib/libc.so.6...done.
Loaded symbols for /lib/libc.so.6
Reading symbols from /lib/ld-linux.so.2...done.
Loaded symbols for /lib/ld-linux.so.2
Core was generated by `./a.out'.
Program terminated with signal 11, Segmentation fault.
#0 0x08048524 in dummy_function () at d.c:4
4 *ptr = 0x00;
|
哇,好历害,还是一步就定位到了错误所在地,佩服一下Linux/Unix系统的此类设计。 接着考虑下去,以前用windows系统下的ie的时侯,有时打开某些网页,会出现“运行时错误”,这个时侯如果恰好你的机器上又装有windows的编译器的话,他会弹出来一个对话框,问你是否进行调试,如果你选择是,编译器将被打开,并进入调试状态,开始调试。 Linux下如何做到这些呢?我的大脑飞速地旋转着,有了,让它在SIGSEGV的handler中调用gdb,于是第三个方法又诞生了: 3.段错误时启动调试:
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <string.h>
void dump(int signo)
{
char buf[1024];
char cmd[1024];
FILE *fh;
snprintf(buf, sizeof(buf), "/proc/%d/cmdline", getpid());
if(!(fh = fopen(buf, "r")))
exit(0);
if(!fgets(buf, sizeof(buf), fh))
exit(0);
fclose(fh);
if(buf[strlen(buf) - 1] == '\n')
buf[strlen(buf) - 1] = '\0';
snprintf(cmd, sizeof(cmd), "gdb %s %d", buf, getpid());
system(cmd);
exit(0);
}
void
dummy_function (void)
{
unsigned char *ptr = 0x00;
*ptr = 0x00;
}
int
main (void)
{
signal(SIGSEGV, &dump);
dummy_function ();
return 0;
}
|
编译运行效果如下:
xiaosuo@gentux test $ gcc -g -rdynamic f.c
xiaosuo@gentux test $ ./a.out
GNU gdb 6.5
Copyright (C) 2006 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i686-pc-linux-gnu"...Using host libthread_db library "/lib/libthread_db.so.1".
Attaching to program: /home/xiaosuo/test/a.out, process 9563
Reading symbols from /lib/libc.so.6...done.
Loaded symbols for /lib/libc.so.6
Reading symbols from /lib/ld-linux.so.2...done.
Loaded symbols for /lib/ld-linux.so.2
0xffffe410 in __kernel_vsyscall ()
(gdb) bt
#0 0xffffe410 in __kernel_vsyscall ()
#1 0xb7ee4b53 in waitpid () from /lib/libc.so.6
#2 0xb7e925c9 in strtold_l () from /lib/libc.so.6
#3 0x08048830 in dump (signo=11) at f.c:22
#4 <signal handler called>
#5 0x0804884c in dummy_function () at f.c:31
#6 0x08048886 in main () at f.c:38
|
怎么样?是不是依旧很酷? 以上方法都是在系统上有gdb的前提下进行的,如果没有呢?其实glibc为我们提供了此类能够dump栈内容的函数簇,详见/usr/include/execinfo.h(这些函数都没有提供man page,难怪我们找不到),另外你也可以通过 gnu的手册进行学习。 4.利用backtrace和objdump进行分析:重写的代码如下:
#include <execinfo.h>
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
/* A dummy function to make the backtrace more interesting. */
void
dummy_function (void)
{
unsigned char *ptr = 0x00;
*ptr = 0x00;
}
void dump(int signo)
{
void *array[10];
size_t size;
char **strings;
size_t i;
size = backtrace (array, 10);
strings = backtrace_symbols (array, size);
printf ("Obtained %zd stack frames.\n", size);
for (i = 0; i < size; i++)
printf ("%s\n", strings[i]);
free (strings);
exit(0);
}
int
main (void)
{
signal(SIGSEGV, &dump);
dummy_function ();
return 0;
}
|
编译运行结果如下:
xiaosuo@gentux test $ gcc -g -rdynamic g.c
xiaosuo@gentux test $ ./a.out
Obtained 5 stack frames.
./a.out(dump+0x19) [0x80486c2]
[0xffffe420]
./a.out(main+0x35) [0x804876f]
/lib/libc.so.6(__libc_start_main+0xe6) [0xb7e02866]
./a.out [0x8048601]
|
这次你可能有些失望,似乎没能给出足够的信息来标示错误,不急,先看看能分析出来什么吧,用objdump反汇编程序,找到地址0x804876f对应的代码位置:
xiaosuo@gentux test $ objdump -d a.out
|
8048765: e8 02 fe ff ff call 804856c <signal@plt>
804876a: e8 25 ff ff ff call 8048694 <dummy_function>
804876f: b8 00 00 00 00 mov $0x0,%eax
8048774: c9 leave
|
我们还是找到了在哪个函数(dummy_function)中出错的,信息已然不是很完整,不过有总比没有好的啊! 后记:本文给出了分析"段错误"的几种方法,不要认为这是与孔乙己先生的"回"字四种写法一样的哦,因为每种方法都有其自身的适用范围和适用环境,请酌情使用,或遵医嘱。
跟诸如Object Pascal和Ada等其它一些语言不同,C++语言并没有内在地提供一种将类的方法作为回调函数使用的方案。在C语言中,这种回调函数被称作算子(functor),在事件驱动类程序中普遍存在。主要问题基于这样一个事实:某个类的多个实例各自位于内存的不同位置。这就需要在回调的时候不仅需要一个函数指针,同时也需要一个指针指向某个实例本身(译者注:否则回调时便无法知道目前正在操作的是哪个对象,C++类的非静态方法包含一个默认的“参数”:this指针,就是起这种作用的)。所以,针对问题的定义,有一个很直观的解决方法就是使用模板和编译时的实例化及特化。
解决方案
这里的方案只支持一个模板参数,但如果一些能够如愿的话,随着更多的编译器完全实现C++标准,以后将会支持动态的模板参数,比如“…”形式的模板参数列表(参见《C++ Templates, The Complete Guide》),那时,我们就可以可以实现无需全部预定义的参数集合。(文中所有代码的注释为译者加,下同。)
template < class Class, typename ReturnType, typename Parameter >
class SingularCallBack
{
public:
//指向类成员函数的指针,用他来实现回调函数。
typedef ReturnType (Class::*Method)(Parameter);
//构造函数
SingularCallBack(Class* _class_instance, Method _method)
{
class_instance = _class_instance;
method = _method;
};
//重载函数调用运算符()
ReturnType operator()(Parameter parameter)
{
return (class_instance->*method)(parameter);
};
//与上面的()等价的函数,引入这个函数的原因见下文
ReturnType execute(Parameter parameter)
{
return operator()(parameter);
};
private:
Class* class_instance;
Method method;
};
模板的使用
模板(template)的使用非常方便,模板本身可被实例化为一个对象指针(object pointer)或者一个简单的类(class)。当作为对象指针使用时,C++有另外一个令人痛苦的限制:operator() 不可以在指针未被解引用的情况下调用,对于这个限制,一个简便的但却不怎么优雅的解决方法在一个模板内部增加一个execute方法(method),由这个方法从模板内部来调用operator()。除了这一点不爽之外,实例化SinglarCallBack为一个对象指针将可以使你拥有一个由回调组成的vector,或者任何其他类型的集合,这在事件驱动程序设计中是非常需要的。
假设以下两个类已经存在,而且我们想让methodB作为我们的回调方法,从代码中我们可以看到当传递一个class A类的参数并调用methodB时,methodB会调用A类的output方法,如果你能在stdout上看到"I am class A :D",就说明回调成功了。
class A
{
public:
void output()
{
std::cout << "I am class A :D" << std::endl;
};
};
class B
{
public:
bool methodB(A a)
{
a.output();
return true;
}
};
有两种方法可以从一个对象指针上调用一个回调方法,较原始的方法是解引用(dereference)一个对象指针并运行回调方法(即:operator()),第二个选择是运行execute方法。
//第一种方法:
A a;
B b;
SingularCallBack< B,bool,A >* cb;
cb = new SingularCallBack< B,bool,A >(&b,&B::methodB);
if((*cb)(a))
{
std::cout << "CallBack Fired Successfully!" << std::endl;
}
else
{
std::cout << "CallBack Fired Unsuccessfully!" << std::endl;
}
//第二种方法:
A a;
B b;
SingularCallBack< B,bool,A >* cb;
cb = new SingularCallBack< B,bool,A >(&b,&B::methodB);
if(cb->execute(a))
{
std::cout << "CallBack Fired Successfully!" << std::endl;
}
else
{
std::cout << "CallBack Fired Unsuccessfully!" << std::endl;
}
下面的代码示范了怎样将一个模板实例化成一个普通的对象并使用之。
A a;
B b;
SingularCallBack< B,bool,A >cb(&b,&B::methodB);
{
std::cout << "CallBack Fired Successfully!" << std::endl;
}
else
{
std::cout << "CallBack Fired Unsuccessfully!" << std::endl;
}
更复杂的例子,一个回调模板可以像下面这样使用:
class AClass
{
public:
AClass(unsigned int _id): id(_id){};
~AClass(){};
bool AMethod(std::string str)
{
std::cout << "AClass[" << id << "]: " << str << std::endl;
return true;
};
private:
unsigned int id;
};
typedef SingularCallBack < AClass, bool, std::string > ACallBack;
int main()
{
std::vector < ACallBack > callback_list;
AClass a1(1);
AClass a2(2);
AClass a3(3);
callback_list.push_back(ACallBack(&a1, &AClass::AMethod));
callback_list.push_back(ACallBack(&a2, &AClass::AMethod));
callback_list.push_back(ACallBack(&a3, &AClass::AMethod));
for (unsigned int i = 0; i < callback_list.size(); i++)
{
callback_list[i]("abc");
}
for (unsigned int i = 0; i < callback_list.size(); i++)
{
callback_list[i].execute("abc");
}
return true;
}
下面这个例子比上面的又复杂一些,你可以混合从同一个公共基类(base class)上继承下来的不同的类到一个容器中,于是你就可以调用位于继承树的最底层的类的方法(most derived method)。(译者注,C++的多态机制)
class BaseClass
{
public:
virtual ~BaseClass(){};
virtual bool DerivedMethod(std::string str){ return true; };
};
class AClass : public BaseClass
{
public:
AClass(unsigned int _id): id(_id){};
~AClass(){};
bool AMethod(std::string str)
{
std::cout << "AClass[" << id << "]: " << str << std::endl;
return true;
};
bool DerivedMethod(std::string str)
{
std::cout << "Derived Method AClass[" << id << "]: " << str << std::endl;
return true;
};
private:
unsigned int id;
};
class BClass : public BaseClass
{
public:
BClass(unsigned int _id): id(_id){};
~BClass(){};
bool BMethod(std::string str)
{
std::cout << "BClass[" << id << "]: " << str << std::endl;
return true;
};
bool DerivedMethod(std::string str)
{
std::cout << "Derived Method BClass[" << id << "]: " << str << std::endl;
return true;
};
private:
unsigned int id;
};
typedef SingularCallBack < BaseClass, bool, std::string > BaseCallBack;
int main()
{
std::vector < BaseCallBack > callback_list;
AClass a(1);
BClass b(2);
callback_list.push_back(BaseCallBack(&a, &BaseClass::DerivedMethod));
callback_list.push_back(BaseCallBack(&b, &BaseClass::DerivedMethod));
for (unsigned int i = 0; i < callback_list.size(); i++)
{
callback_list[i]("abc");
}
for (unsigned int i = 0; i < callback_list.size(); i++)
{
callback_list[i].execute("abc");
}
return true;
}
为简捷起见,与实例的验证(instance validation)相关的必要代码没有被包含进来,在实际的程序设计中,类实例的传递应该基于这样的结构:使用类似智能指针(smart pointer)的包装类。STL(标准模板库)提供了两个极好的选择:aotu_ptr以及它的后继:shared_ptr。Andrei Alexandrescu所著的《Modern C++ Design》一书也提供了一个面向策略设计(policy design oriented)的智能指针类。这三种方案中各有自己的优缺点,最终由用户自己来决定究竟那一种最适合他们的需要。
一 拷贝构造函数是C++最基础的概念之一,大家自认为对拷贝构造函数了解么?请大家先回答一下三个问题:
1. 以下函数哪个是拷贝构造函数,为什么?
- X::X(const X&);
- X::X(X);
- X::X(X&, int a=1);
- X::X(X&, int a=1, b=2);
2. 一个类中可以存在多于一个的拷贝构造函数吗?
3. 写出以下程序段的输出结果, 并说明为什么? 如果你都能回答无误的话,那么你已经对拷贝构造函数有了相当的了解。
- #include
- #include
-
- struct X {
- template<typename T>
- X( T& ) { std::cout << "This is ctor." << std::endl; }
-
- template<typename T>
- X& operator=( T& ) { std::cout << "This is ctor." << std::endl; }
- };
-
- void main() {
- X a(5);
- X b(10.5);
- X c = a;
- c = b;
- }
解答如下:
1. 对于一个类X,如果一个构造函数的第一个参数是下列之一:
a) X&
b) const X&
c) volatile X&
d) const volatile X&
且没有其他参数或其他参数都有默认值,那么这个函数是拷贝构造函数.
- X::X(const X&);
- X::X(X&, int=1);
2.类中可以存在超过一个拷贝构造函数,
- class X {
- public:
- X(const X&);
- X(X&);
- };
注意,如果一个类中只存在一个参数为X&的拷贝构造函数,那么就不能使用const X或volatile X的对象实行拷贝初始化.
- class X {
- public:
- X();
- X(X&);
- };
-
- const X cx;
- X x = cx;
如果一个类中没有定义拷贝构造函数,那么编译器会自动产生一个默认的拷贝构造函数.
这个默认的参数可能为X::X(const X&)或X::X(X&),由编译器根据上下文决定选择哪一个.
默认拷贝构造函数的行为如下:
默认的拷贝构造函数执行的顺序与其他用户定义的构造函数相同,执行先父类后子类的构造.
拷贝构造函数对类中每一个数据成员执行成员拷贝(memberwise Copy)的动作.
a)如果数据成员为某一个类的实例,那么调用此类的拷贝构造函数.
b)如果数据成员是一个数组,对数组的每一个执行按位拷贝.
c)如果数据成员是一个数量,如int,double,那么调用系统内建的赋值运算符对其进行赋值.
3. 拷贝构造函数不能由成员函数模版生成.
- struct X {
- template<typename T>
- X( const T& );
-
- template<typename T>
- operator=( const T& );
- };
-
原因很简单, 成员函数模版并不改变语言的规则,而语言的规则说,如果程序需要一个拷贝构造函数而你没有声明它,那么编译器会为你自动生成一个. 所以成员函数模版并不会阻止编译器生成拷贝构造函数, 赋值运算符重载也遵循同样的规则.(参见Effective C++ 3edition, Item45)
二 针对上面作者的讨论,理解更深了,但是下面我还是会给出一个一般的标准的实现和注意事项:
 #include "stdafx.h" #include "stdafx.h"
#include "stdio.h"
#include <iostream>
#include <string>
struct Test1
   { {
  Test1() { } Test1() { }
Test1(int i) { id = i; }
 Test1(const Test1& test) Test1(const Test1& test)
{
id = test.id;
 } }
Test1& operator = (const Test1& test)
{
if(this == &test)
return *this;
id = test.id;
return *this;
}
int id;
 }; };
class Test2
{
public:
Test2(){ m_pChar = NULL;}
Test2(char *pChar) { m_pChar = pChar;}
Test2(int num)
{
m_pChar = new char[num];
for(int i = 0; i< num; ++i)
m_pChar[i] = 'a';
m_pChar[num-1] = '\0';
}
Test2(const Test2& test)
{
char *pCharT = m_pChar;
m_pChar = new char[strlen(test.m_pChar)];
strcpy(m_pChar, test.m_pChar);
if(!pCharT)
delete []pCharT;
}
Test2& operator = (const Test2& test)
{
if(this == &test)
return *this;
char *pCharT = m_pChar;
m_pChar = new char[strlen(test.m_pChar)];
strcpy(m_pChar, test.m_pChar);
if(!pCharT)
delete []pCharT;
return *this;
}
private:
char *m_pChar;
};
int main(int argc, char* argv[])
{
const Test1 ts(1); // Test1()
const Test1* p_ts = &ts;
const Test1 ts2(ts); //Test(const Test1& test)
const Test1 ts3 = ts; //Test(const Test1& test)
Test1 ts4; ts4 = ts; //Test1& operator = (const Test1& test)
Test2 t(5);
Test2 t2(t);
Test2 t3 = t2;
Test2 t4; t4 = t;
return 0;
}
protobuf简介
protobuf是google提供的一个开源序列化框架,类似于XML,JSON这样的数据表示语言,其最大的特点是基于二进制,因此比传统的XML表示高效短小得多。虽然是二进制数据格式,但并没有因此变得复杂,开发人员通过按照一定的语法定义结构化的消息格式,然后送给命令行工具,工具将自动生成相关的类,可以支持java、c++、python等语言环境。通过将这些类包含在项目中,可以很轻松的调用相关方法来完成业务消息的序列化与反序列化工作。
protobuf在google中是一个比较核心的基础库,作为分布式运算涉及到大量的不同业务消息的传递,如何高效简洁的表示、操作这些业务消息在google这样的大规模应用中是至关重要的。而protobuf这样的库正好是在效率、数据大小、易用性之间取得了很好的平衡。
更多信息可参考官方文档
例子介绍
先下载protobuf-2.3.0.zip源代码库,下载后解压,选择vsprojects目录下的protobuf.sln解决方案打开,编译整个方案顺利成功。其中有一些测试工程,库相关的工程是libprotobuf、libprotobuf-lite、libprotoc和protoc。其中protoc是命令行工具。在example目录下有一个地址薄消息的例子,业务消息的定义文件后缀为.proto,其中的addressbook.proto内容为:
package tutorial;
option java_package = "com.example.tutorial";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2; // Unique ID number for this person.
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
// Our address book file is just one of these.
message AddressBook {
repeated Person person = 1;
}
该定义文件,定义了地址薄消息的结构,顶层消息为AddressBook,其中包含多个Person消息,Person消息中又包含多个PhoneNumber消息。里面还定义了一个PhoneType的枚举类型。
类型前面有required表示必须,optional表示可选,repeated表示重复,这些定义都是一目了然的,无须多说。关于消息定义的详细语法可参考官方文档。
现在用命令行工具来生成业务消息类,切换到protoc.exe所在的debug目录,在命令行敲入:
protoc.exe --proto_path=..\..\examples --cpp_out=..\..\examples ..\..\examples\addressbook.proto
该命令中--proto_path参数表示.proto消息定义文件路径,--cpp_out表示输出c++类的路径,后面接着是addressbook.proto消息定义文件。该命令会读取addressbook.proto文件并生成对应的c++类头文件和实现文件。执行完后在examples目录生存了addressbook.pb.h和addressbook.pb.cpp。
现在新建两个空控制台工程,第一个不妨叫AddPerson,然后把examples目录下的add_person.cc、addressbook.pb.h和addressbook.pb.cpp加入到该工程,另一个工程不妨叫ListPerson,将examples目录下的list_people.cc、addressbook.pb.h和addressbook.pb.cpp加入到该工程,在两个工程的项目属性中附加头文件路径../src。两个工程的项目依赖都选择libprotobuf工程(库)。
给AddPerson工程添加一个命令行参数比如叫addressbook.dat用于将地址薄信息序列化写入该文件,然后编译运行AddPerson工程,根据提示输入地址薄信息:
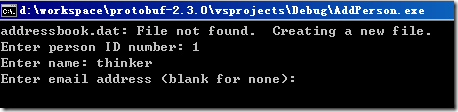
输入完成后,将序列化到addressbook.dat文件中。
在ListPerson工程的命令行参数中加读取文件参数..\AddPerson\addressbook.dat,然后在运行ListPerson工程,可在 list_people.cc的最后设个断点,避免命令行窗口运行完后关闭看不到结果:
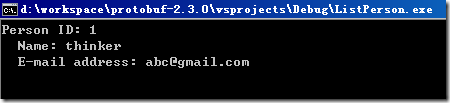
写入地址薄的操作,关键操作就是调用address_book.SerializeToOstream进行序列化到文件流。
而读取操作中就是address_book.ParseFromIstream从文件流反序列化,这都是框架自动生成的类中的方法。
其他操作都是业务消息的字段set/get之类的对象级操作,很明了。更详细的API参考官方文档有详细说明。
在TCP网络编程中的考虑
从上面的例子可以看出protobuf这样的库是很方便高效的,那么自然的想到在网络编程中用来做业务消息的序列化、反序列化支持。在基于UDP协议的网络应用中,由于UDP本身是有边界,那么用protobuf来处理业务消息就很方便。但在TCP应用中,由于TCP协议没有消息边界,这就需要有一种机制来确定业务消息边界。在TCP网络编程中这是必须面对的问题。
注意上面的address_book.ParseFromIstream调用,如果流参数的内容多一个字节或者少一个字节,该方法都会返回失败(虽然某些字段可能正确得到结果了),也就是说送给反序列化的数据参数除了格式正确还必须有正确的大小。因此在tcp网络编程中,要反序列化业务消息,就要先知道业务数据的大小。而且在实际应用中可能在一个发送操作中,发送多个业务消息,而且每个业务消息的大小、类型都不一样。而且可能发送很大的数据流,比如文件。
显然消息边界的确认问题和protobuf库无关,还得自己搞定。在官方文档中也提到,protobuf并不太适合来作大数据的处理,当业务消息超过1M时,就应该考虑是否应该用另外的替代方案。当然对于大数据,你也可以分割为多个小块用protobuf做小块消息封装进行传递。但对很多应用这样的作法显得比较多余,比如发送一个大的文件,一般是在接收方从协议栈收到多少数据就写多少数据到磁盘,这是一种边接收边处理的流模式,这种模式基本上和每次收到的数据量没有关系。这种模式下再采用分割成小消息进行反序列化就显得多此一举了。
由于每个业务消息的大小和处理方式都可能不一样,那么就需要独立抽象出一个边界消息来区分不同的业务消息,而且这个边界消息的格式和大小必须固定。对于网络编程熟手,可能早已经想到了这样的消息,我们可以结合protobuf库来定义一个边界消息,不妨叫BoundMsg:
message BoundMsg
{
required int32 msg_type = 1;
required int32 msg_size = 2;
}
可以根据需要扩充一些字段,但最基本的这两个字段就够用了。我们只需要知道业务消息的类型和大小即可。这个消息大小是固定的8字节,专门用来确定数据流的边界。有了这样的边界消息,在接收端处理任何业务消息就很灵活方便了,下面是接收端处理的简单伪代码示例:
if(net_read(buf,8))
{
boundMsg.ParseFromIstream(buf);
switch(boundMsg.msg_type)
{
case BO_1:
if(net_read(bo1Buf,boundMsg.msg_size))
{
bo1.ParseFromIstream(bo1Buf);
....
}
break;
case BO_2:
if(net_read(bo2Buf,boundMsg.msg_size))
{
bo2.ParseFromIstream(bo2Buf);
....
}
break;
case FILE_DATA:
count = 0;
while(count < boundMsg.msg_size)
{
piece_size = net_read(fileBuf,1024);
write_file(filename,fileBuf,piece_size);
count = count + piece_size;
}
break;
}
}
注意上面如果FILE_DATA消息后,还紧接其他业务消息的话,需要小心,即count累计出的值可能大于
boundMsg.msg_size的值,那么多出来的实际上应该是下一个边界消息数据了。为了避免处理的复杂性,上面所有的循环网络读取操作(上面BO_1,BO_2都可能需要循环读取,为了简化没有写成循环)的缓冲区位置和大小参数应该动态调整,即每次读取时传递的都是还期望读取的数据大小,对于文件的话,可能特殊点,因为边读取边写入,就没有必要事先要分配一个文件大小的缓冲区来存放数据了。对于文件分配一个小缓冲区来读,注意确认下边界即可。
上面是我的一点考虑,不妥之处还请大家讨论交流。想想借助于ACE、MINA这样的网络编程框架,然后结合protobuf这样的序列化框架,网络编程中技术基础设施层面的东西就给我们解决得差不多了,我们可以真正只关注于业务的实现。
摘要: 转载自:Protocol Buffers Language Guide之proto文件类型格式分析[关键点翻译] | 漂泊如风1、 定义一个消息类型:
message SearchRequest {
required string query = 1;
optional int32 page_number = 2;
optional int32 result_per_... 阅读全文
转载自:Protocol Buffers Language Guide之proto文件类型格式分析[关键点翻译] | 漂泊如风
今天来介绍一下“Protocol Buffers”(以下简称protobuf)这个玩意儿。
★protobuf是啥玩意儿?
为了照顾从没听说过的同学,照例先来扫盲一把。
首先,protobuf是一个开源项目(官方站点在“这里 ”),而且是后台很硬的开源项目。网上现有的大部分(至少80%)开源项目,要么是某人单干、要么是几个闲杂人等合伙搞。而protobuf则不然,它是 鼎鼎大名的Google公司开发出来,并且在Google内部久经考验的一个东东。由此可见,它的作者绝非一般闲杂人等可比。
那这个听起来牛X的东东到底有啥用处捏?简单地说,这个东东干的事儿其实和XML差不多,也就是把某种数据结构的信息,以某种格式保存起来。主要用于数据存储、传输协议格式等 场合。有同学可能心理犯嘀咕了:放着好好的XML不用,干嘛重新发明轮子啊?!先别急,后面俺自然会有说道。
话说到了去年(大约是08年7 月),Google突然大发慈悲,把这个好东西贡献给了开源社区。这下,像俺这种喜欢捡现成的家伙可就有福啦!貌似喜欢捡现成的家伙还蛮多滴,再加上 Google的号召力,开源后不到一年,protobuf的人气就已经很旺了。所以俺为了与时俱进,就单独开个帖子来忽悠一把。
★protobuf有啥特色?
扫盲完了之后,就该聊一下技术方面的话题了。由于这玩意儿发布的时间较短(未满周岁),所以俺接触的时间也不长。今天在此是先学现卖,列位看官多多包涵 
◇性能好/效率高
现在,俺就来说说Google公司为啥放着好端端的XML不用,非要另起炉灶,重新造轮子。一个根本的原因是XML性能不够好。
先说时间开销:XML格式化(序列化)的开销倒还好;但是XML解析(反序列化)的开销就不敢恭维啦。俺之前经常碰到一些时间性能很敏感的场合,由于不堪忍受XML解析的速度,弃之如敝履。
再来看空间开销:熟悉XML语法的同学应该知道,XML格式为了有较好的可读性,引入了一些冗余的文本信息。所以空间开销也不是太好(不过这点缺点,俺不常碰到)。
由于Google公司赖以吹嘘的就是它的海量数据和海量处理能力。对于几十万、上百万机器的集群,动不动就是PB级的数据量,哪怕性能稍微提高0.1% 也是相当可观滴。所以Google自然无法容忍XML在性能上的明显缺点。再加上Google从来就不缺造轮子的牛人,所以protobuf也就应运而生 了。
Google对于性能的偏执,那可是出了名的。所以,俺对于Google搞出来protobuf是非常滴放心,性能上不敢说是最好,但肯定不会太差。
◇代码生成机制
除了性能好,代码生成机制是主要吸引俺的地方。为了说明这个代码生成机制,俺举个例子。
比如有个电子商务的系统(假设用C++实现),其中的模块A需要发送大量的订单信息给模块B,通讯的方式使用socket。
假设订单包括如下属性:
--------------------------------
时间:time(用整数表示)
客户id:userid(用整数表示)
交易金额:price(用浮点数表示)
交易的描述:desc(用字符串表示)
--------------------------------
如果使用protobuf实现,首先要写一个proto文件(不妨叫Order.proto),在该文件中添加一个名为”Order”的message结构,用来描述通讯协议中的结构化数据。该文件的内容大致如下:
--------------------------------
message Order
{
required int32 time = 1;
required int32 userid = 2;
required float price = 3;
optional string desc = 4;
}
--------------------------------
然后,使用protobuf内置的编译器编译 该proto。由于本例子的模块是C++,你可以通过protobuf编译器的命令行参数(看“这里 ”),指定它生成C++语言的“订单包装类”。(一般来说,一个message结构会生成一个包装类)
然后你使用类似下面的代码来序列化/解析该订单包装类:
--------------------------------
// 发送方
Order order;
order.set_time(XXXX);
order.set_userid(123);
order.set_price(100.0f);
order.set_desc(“a test order”);
string sOrder;
order.SerailzeToString(&sOrder);
// 然后调用某种socket的通讯库把序列化之后的字符串发送出去
// ……
--------------------------------
// 接收方
string sOrder;
// 先通过网络通讯库接收到数据,存放到某字符串sOrder
// ……
Order order;
if(order.ParseFromString(sOrder)) // 解析该字符串
{
cout << “userid:” << order.userid() << endl
<< “desc:” << order.desc() << endl;
}
else
{
cerr << “parse error!” << endl;
}
--------------------------------
有了这种代码生成机制,开发人员再也不用吭哧吭哧地编写那些协议解析的代码了(干这种活是典型的吃力不讨好)。
万一将来需求发生变更,要求给订单再增加一个“状态”的属性,那只需要在Order.proto文件中增加一行代码。对于发送方(模块A),只要增加一行设置状态的代码;对于接收方(模块B)只要增加一行读取状态的代码。哇塞,简直太轻松了!
另外,如果通讯双方使用不同的编程语言来实现,使用这种机制可以有效确保两边的模块对于协议的处理是一致的。
顺便跑题一下。
从某种意义上讲,可以把proto文件看成是描述通讯协议的规格说明书(或者叫接口规范)。这种伎俩其实老早就有了,搞过微软的COM编程或者接触过CORBA的同学,应该都能从中看到IDL(详细解释看“这里 ”)的影子。它们的思想是相通滴。
◇支持“向后兼容”和“向前兼容”
还是拿刚才的例子来说事儿。为了叙述方便,俺把增加了“状态”属性的订单协议成为“新版本”;之前的叫“老版本”。
所谓的“向后兼容”(backward compatible),就是说,当模块B升级了之后,它能够正确识别模块A发出的老版本的协议。由于老版本没有“状态”这个属性,在扩充协议时,可以考虑把“状态”属性设置成非必填 的,或者给“状态”属性设置一个缺省值(如何设置缺省值,参见“这里 ”)。
所谓的“向前兼容”(forward compatible),就是说,当模块A升级了之后,模块B能够正常识别模块A发出的新版本的协议。这时候,新增加的“状态”属性会被忽略。
“向后兼容”和“向前兼容”有啥用捏?俺举个例子:当你维护一个很庞大的分布式系统时,由于你无法同时 升级所有 模块,为了保证在升级过程中,整个系统能够尽可能不受影响,就需要尽量保证通讯协议的“向后兼容”或“向前兼容”。
◇支持多种编程语言
俺开博以来点评的几个开源项目(比如“Sqlite ”、“cURL ”),都是支持很多种 编程语言滴,这次的protobuf也不例外。在Google官方发布的源代码中包含了C++、Java、Python三种语言(正好也是俺最常用的三种,真爽)。如果你平时用的就是这三种语言之一,那就好办了。
假如你想把protobuf用于其它语言,咋办捏?由于Google一呼百应的号召力,开源社区对protobuf响应踊跃,近期冒出很多其它编程语言 的版本(比如ActionScript、C#、Lisp、Erlang、Perl、PHP、Ruby等),有些语言还同时搞出了多个开源的项目。具体细节可以参见“这里 ”。
不过俺有义务提醒一下在座的各位同学。如果你考虑把protobuf用于上述这些语言,一定认真评估对应的开源库。因为这些开源库不是Google官方提供的、而且出来的时间还不长。所以,它们的质量、性能等方面可能还有欠缺。
★protobuf有啥缺陷?
前几天刚刚在“光环效应 ”的帖子里强调了“要同时评估优点和缺点”。所以俺最后再来批判一下这玩意儿的缺点。
◇应用不够广
由于protobuf刚公布没多久,相比XML而言,protobuf还属于初出茅庐。因此,在知名度、应用广度等方面都远不如XML。由于这个原因,假如你设计的系统需要提供若干对外的接口给第三方系统调用,俺奉劝你暂时不要考虑protobuf格式。
◇二进制格式导致可读性差
为了提高性能,protobuf采用了二进制格式进行编码。这直接导致了可读性差的问题(严格地说,是没有可读性)。虽然protobuf提供了TextFormat这个工具类(文档在“这里 ”),但终究无法彻底解决此问题。
可读性差的危害,俺再来举个例子。比如通讯双方如果出现问题,极易导致扯皮(都不承认自己有问题,都说是对方的错)。俺对付扯皮的一个简单方法就是直接 抓包并dump成log,能比较容易地看出错误在哪一方。但是protobuf的二进制格式,导致你抓包并直接dump出来的log难以看懂。
◇缺乏自描述
一般来说,XML是自描述的,而protobuf格式则不是。给你一段二进制格式的协议内容,如果不配合相应的proto文件,那简直就像天书一般。
由于“缺乏自描述”,再加上“二进制格式导致可读性差”。所以在配置文件方面,protobuf是肯定无法取代XML的地位滴。
|