#
今天在VS2008下编译VS自带Sample中的一个例子,TstCon,因为之前的机器装的是XP系统,该程序曾成功编译过,不过今天在Windows Server 2008 R2下打开失败,在朋友的Windows 7 Ultimate下打开也失败,试用以管理员身份运行,失败,试用修改兼容性选项为Windows XP SP3/SP2方式,均失败。
其实这个时候可能是一些Vista以上版本的OS所提供的新功能引起的限制。就当前的这个例子而言,是因为编译的时候,启用用户帐户控制(UAC)默认为“是”所致,将解决方案内所有工程选中,右键属性,修改“配置属性”->“链接器”->“清单文件”->“启用用户帐户控制(UAC)”为“否”,重新生成解决方案,即可。

准确地说还是经验不足,这么简单的事居然想了好几分钟,当然也要怪VS在没有重新生成前的诡异现象。
今晚在类中加入两个数组用来做计数,因为之前代码有所改动,VS编译(增量)的结果居然出现了无数次的程序崩溃,害我一度怀疑是不是我的数组写的有问题。囧。最后无奈之下,点了重新生成,居然顺利通过了,很生气,愤怒中。
但是另外却发现了一个问题,也就是当size_t用作循环的时候。因为以前都是用int做循环的,现在换成unsigned int(也就是size_t)后,一下子没反应过来,就顺手这么写了:
for( size_t i = MAX - 1; i >= 0; --i)
{
//……
}
乍一看似乎没啥问题,因为我循环内的代码是删除资源的,因此程序也频频崩溃。
step over的结果才让人惊讶,因为当size_t i = 0的时候,--i的结果是无穷大,而无穷大则肯定满足i>=0的条件,所以当我们期待程序停住的时候,程序是不会停住的。
修正的方式:
1、使用正向遍历。
2、增加判断条件(i>=0 && i < MAX),但这里也可能存在问题,因为size_t可能被定义为unsigned int,但是MAX可能是个更大的数,比如unsigned long long,当然这样的比较不是很有意义,或者会实现一些转换,但是如果这种情况发生的话,程序可能还是会通过一个随机的i进入到一个未知的空间中,从而造成崩溃。而且增加判断条件也使得程序的运行成本提高。
本来想好好写写C++ Traits的,刚刚接到interview的通知,先贴代码,改天再议。
/*
* cpp_traits.cpp
*
* Created on: 2010-4-26
* Author: volnet@tom.com
*/
#include <iostream>
// kinds of types for overloading.
struct undefined_type {};
struct int32_type {};
struct int64_type {};
// typedef some has_trivial_* for difference types.
template <class T>
struct type_traits {
typedef undefined_type has_trivial_type;
};
// define the partial specialization functions.
template <>
struct type_traits<int> {
typedef int32_type has_trivial_type;
};
template <>
struct type_traits<long> {
typedef int64_type has_trivial_type;
};
// the dispatcher method for all kinds of types.
template <class T>
void type_detect(T& p){
typedef typename type_traits<T>::has_trivial_type trivial_type;
type_detect(p, trivial_type());
}
// define the functions for dispatching.
template <class T>
void type_detect(T& p, undefined_type) {
std::cout << p;
std::cout << " // It's a undefined type, we have NOT found the dispatcher function." << std::endl;
}
template <class T>
void type_detect(T& p, int32_type) {
std::cout << p;
std::cout << " // It's a int32" << std::endl;
}
template <class T>
void type_detect(T& p, int64_type) {
std::cout << p;
std::cout << " // It's a int64" << std::endl;
}
int main(void) {
int int32num = 2010;
type_detect(int32num);
long int64num = 2010L;
type_detect(int64num);
std::string str = "2010";
type_detect(str);
std::cout << "-------end of program." << std::endl;
return EXIT_SUCCESS;
}
本文来自C/C++用户日志,17(10),1999年10月 原文链接
大部分人都听说过auto_ptr指针,但是并非所有人都每天使用它。不使用它是不明智的(可耻的),因为auto_ptr的设计初衷是为了解决C++设计和编码的普遍问题,将它用好可以写出更健壮的代码。本文指出如何正确使用auto_ptr以使程序变得安全,以及如何避开危险,而不是一般使用auto_ptr的恶习所致的创建间歇性和难以诊断的问题。
为什么它是一个“自动”指针
auto_ptr只是许许多多智能指针中的一种。许多商业库提供许多更强大的智能指针,可以完成更多的事情。从可以管理引用计数到提供更先进的代理服务等。应该把auto_ptr认为是智能指针中的福特Escort[注释]:一个基于简单且通用目的的智能指针,既没有小发明也没有丰富的特殊目的更不需要高性能,但是能将许多普通的事情做好,并且能够适合日常使用的智能指针。
auto_ptr做这样一件事:拥有一个动态分配内存对象,并且在它不再需要的时候履行自动清理的职责。这里有个没有使用auto_ptr指针的不安全的例子:
// Example 1(a): Original code
//
void f()
{
T* pt( new T );
/*...more code...*/
delete pt;
}
我们每天都像这样写代码,如果f()只是一个三行程序,也没做什么多余的事情,这样做当然可以很好工作。但是如果f()没有执行delete语句,比如程序提前返回(return)了,或者在执行的时候抛出异常了,然后就导致已经分配的对象没有被删除,因此我们就有了一个经典的内存泄漏。
一个使Example(1)安全的办法是用一个“智能”的指针拥有这个指针,当销毁的时候,删除那个被指的自动分配的对象。因为这个智能指针被简单地用为自动对象(这就是,当它离开它的作用域的时候自动销毁对象),所以它被称作“自动”指针。
// Example 1(b): Safe code, with auto_ptr
//
void f()
{
auto_ptr<T> pt( new T );
/*...more code...*/
} // cool: pt's destructor is called as it goes out
// of scope, and the object is deleted automatically
现在这段代码将不会再T对象上发生泄漏了,不必在意这个方法是正常退出还是异常退出,因为pt的析构函数将总是在堆栈弹出的时候被调用。清理工作将自动进行。
最后,使用auto_ptr和使用内建指针一样地容易,如果要“收回”资源并且再次手动管理的话,我们可以调用release():
// Example 2: Using an auto_ptr
//
void g()
{
T* pt1 = new T;
// right now, we own the allocated object
// pass ownership to an auto_ptr
auto_ptr<T> pt2( pt1 );
// use the auto_ptr the same way
// we'd use a simple pointer
*pt2 = 12; // same as "*pt1 = 12;"
pt2->SomeFunc(); // same as "pt1->SomeFunc();"
// use get() to see the pointer value
assert( pt1 == pt2.get() );
// use release() to take back ownership
T* pt3 = pt2.release();
// delete the object ourselves, since now
// no auto_ptr owns it any more
delete pt3;
} // pt2 doesn't own any pointer, and so won't
// try to delete it... OK, no double delete
最后,我们可以使用auto_ptr的reset()方法将auto_ptr重置向另一个对象。如果auto_ptr已经获得一个对象,这个过程就像是它先删除已经拥有的对象,因此调用reset(),就像是先销毁了auto_ptr,然后重建了一个新的并拥有该新对象:
// Example 3: Using reset()
//
void h()
{
auto_ptr<T> pt( new T(1) );
pt.reset( new T(2) );
// deletes the first T that was
// allocated with "new T(1)"
} // finally, pt goes out of scope and
// the second T is also deleted
包装指针数据成员
同样,auto_ptr也可以被用于安全地包装指针数据成员。考虑下面使用Pimpl idiom(或者,编译器防火墙)的例子:[1]
// Example 4(a): A typical Pimpl
//
// file c.h
//
class C
{
public:
C();
~C();
/*...*/
private:
class CImpl; // forward declaration
CImpl* pimpl_;
};
// file c.cpp
//
class C::CImpl { /*...*/ };
C::C() : pimpl_( new CImpl ) { }
C::~C() { delete pimpl_; }
简单地说,就是C的私有细节被实现为一个单独的对象,藏匿于一个指针之中。该思路要求C的构造函数负责为隐藏在类内部的辅助“Pimpl”对象分配内存,并且C的析构函数负责销毁它。使用auto_ptr,我们会发现这非常容易:
// Example 4(b): A safer Pimpl, using auto_ptr
//
// file c.h
//
class C
{
public:
C();
/*...*/
private:
class CImpl; // forward declaration
auto_ptr<CImpl> pimpl_;
};
// file c.cpp
//
class C::CImpl { /*...*/ };
C::C() : pimpl_( new CImpl ) { }
现在,析构函数不需要担心删除pimpl_指针了,因为auto_ptr将自动处理它。事实上,如果没有其它需要显式写析构函数的原因,我们完全不需要自定义析构函数。显然,这比手动管理指针要容易得多,并且将对象所有权包含进对象是一个不错的习惯,这正是auto_ptr所擅长的。我们将在最后再次回顾这个例子。
所有权,源,以及调用者(Sinks)
它本身很漂亮,并且做得非常好:从函数传入或传出auto_ptrs,是非常有用的,比如函数的参数或者返回值。
让我们看看为什么,首先我们考虑当拷贝auto_ptr的时候会发生什么:一个auto_ptr获得一个拥有指针的对象,并且在同一时间只允许有一个auto_ptr可以拥有这个对象。当你拷贝一个auto_ptr的时候,你自动将源auto_ptr的所有权,传递给目标auto_ptr;如果目标auto_ptr已经拥有了一个对象,这个对象将先被释放。在拷贝完之后,只有目标auto_ptr拥有指针,并且负责在合适的时间销毁它,而源将被设置为空(null),并且不能再被当作原有指针的代表来使用。
例如:
// Example 5: Transferring ownership from
// one auto_ptr to another
//
void f()
{
auto_ptr<T> pt1( new T );
auto_ptr<T> pt2;
pt1->DoSomething(); // OK
pt2 = pt1; // now pt2 owns the pointer,
// and pt1 does not
pt2->DoSomething(); // OK
} // as we go out of scope, pt2's destructor
// deletes the pointer, but pt1's does nothing
但是要避免陷阱再次使用已经失去所有权的auto_ptr:
// Example 6: Never try to do work through
// a non-owning auto_ptr
//
void f()
{
auto_ptr<T> pt1( new T );
auto_ptr<T> pt2;
pt2 = pt1; // now pt2 owns the pointer, and
// pt1 does not
pt1->DoSomething();
// error! following a null pointer
}
谨记于心,我们现在看看auto_ptr如何在源和调用者之间工作。“源”这里是指一个函数,或者其它创建一个新资源的操作,并且通常将移交出资源的所有权。一个“调用者”函数反转这个关系,也就是获得已经存在对象的所有权(并且通常还负责释放它)。而不是有一个源和调用者,返回并且利用一个秃头指针(译者注:而不是使用一个局部变量来传递这个指针),虽然,通过一个秃头指针来获得一个资源通常很好:
// Example 7: Sources and sinks
//
// A creator function that builds a new
// resource and then hands off ownership.
//
auto_ptr<T> Source()
{
return auto_ptr<T>( new T );
}
// A disposal function that takes ownership
// of an existing resource and frees it.
//
void Sink( auto_ptr<T> pt )
{
}
// Sample code to exercise the above:
auto_ptr<T> pt( Source() ); // takes ownership
注意下面的微妙的变化:
-
Source()分配了一个新对象并且以一个完整安全的方式将它返回给调用者,并让调用者成为指针的拥有着。即使调用者忽略了返回值(显然,如果调用者忽略了返回值,你应该从来没有写过代码来删除这个对象,对吧?),分配的对象也将被自动安全地删除。
在本文的最后,我将演示返回一个auto_ptr是一个好习惯。让返回值包裹进一些东西比如auto_ptr通常是使得函数变得强健的有效方式。
-
Sink()通过传值的方式获得对象所有权。当执行完Sink()的时候,当离开作用域的时候,删除操作将被执行(只要Sink()没有将所有权转移)。上面所写的Sink()函数实际上并没有对参数做任何事情,因此调用“Sink(pt);”就等于写了“pt.reset(0);”,但是大部分的Sink函数都将在释放它之前做一些工作。
不可以做的事情,以及为什么不能做
谨记:千万不要以我之前没有提到的方式使用auto_ptrs。我已经看见过很多程序员试着用其他方式写auto_ptrs就像他们在使用其它对象一样。但问题是auto_ptr并不像其他对象。这里有些基本原则,我将把它们提出来以引起你的注意:
For auto_ptr, copies are NOT equivalent. (复制auto_ptr将与原来的不相等)
当你试着在一般的代码中使用auto_ptrs的时候,它将执行拷贝,并且没有任何提示,拷贝是不相等的(结果,它确实就是拷贝)。看下面这段代码,这是我在C++新闻组经常看见的:
// Example 8: Danger, Will Robinson!
//
vector< auto_ptr<T> > v;
/* ... */
sort( v.begin(), v.end() );
在标准容器中使用auto_ptrs总是不安全的。一些人可能要告诉你,他们的编译器或者类库能够很好地编译它们,而另一些人则告诉你在某一个流行的编译器的文档中看到这个例子,不要听他们的。
问题是auto_ptr并不完全符合一个可以放进容器类型的前提,因为拷贝auto_ptrs是不等价的。首先,没有任何东西说明,vector不能决定增加并制造出“扩展”的内部拷贝。再次,当你调用一个一般函数的时候,它可能会拷贝元素,就像sort()那样,函数必须有能力假设拷贝是等价的。至少一个流行的排序拷贝“核心”的元素,如果你试着让它与auto_ptrs一起工作的话,它将拷贝一份“核心”的auto_ptr对象(因此转移所有权并且将所有权转移给一个临时对象),然后对其余的元素也采取相同的方式(从现有成员创建更多的拥有所有权的auto_ptr),当排序完成后,核心元素将被销毁,并且你将遇到一个问题:这组序列里至少一个auto_ptr(也就是刚才被掉包的那个核心元素)不再拥有对象所有权,而那个真实的指针已经随着临时对象的销毁而被删除了!
于是标准委员会回退并希望做一些能够帮助你避免这些行为的事情:标准的auto_ptr被故意设计成当你希望在使用标准容器的时候使用它时打断你(或者,至少,在大部分的标准库实现中打断你)。为了达到这个目的,标准委员会利用这样一个技巧:让auto_ptr's的拷贝构造函数和赋值操作符的右值(rhs)指向非常量。因为标准容器的单元素insert()函数,需要一个常量作为参数,因此auto_ptrs在这里就不工作了。(译者注:右值不能赋值给非常量)
使用const auto_ptr是一个好习惯
将一个auto_ptr设计成const auto_ptrs将不再丢失所有权:拷贝一个const auto_ptr是违法的(译者注:没有这样的构造函数),实际上你可以针对它做的唯一事情就是通过operator*()或者operator->()解引用它或者调用get()来获得所包含的指针的值。这意味着我们有一个简单明了的风格来表达一个绝不丢失所有权的auto_ptr:
// Example 9: The const auto_ptr idiom
//
const auto_ptr<T> pt1( new T );
// making pt1 const guarantees that pt1 can
// never be copied to another auto_ptr, and
// so is guaranteed to never lose ownership
auto_ptr<T> pt2( pt1 ); // illegal
auto_ptr<T> pt3;
pt3 = pt1; // illegal
pt1.release(); // illegal
pt1.reset( new T ); // illegal
这就是我要说的cosnt!因此如果现在你要向世界证明你的auto_ptr是不会被改变并且将总是删除其所有权,加上const就是你要做的。const auto_ptr风格是有用的,你必须将它谨记于心。
auto_ptr以及异常安全
最后,auto_ptr对写出异常安全的代码有时候非常必要,思考下面的代码:
// Example 10(a): Exception-safe?
//
String f()
{
String result;
result = "some value";
cout << "some output";
return result;
}
该函数有两个可见的作用:它输出一些内容,并且返回一个String。关于异常安全的详细说明超出了本文的范围[2],但是我们想要取得的目标就是强异常安全的保障,归结为确保函数的原子性——如果有异常,所有的作用一起发生或者都不发生。
虽然在例10(a)中的代码非常精巧,看起来相当接近于异常安全的代码,但仍然有一些小的瑕疵,就像下面的客户代码所示:
String theName;
theName = f();
因为结果通过值返回,因此String的拷贝构造函数将被调用,而拷贝赋值操作符被调用来将结果拷贝到theName中。如果任何一个拷贝失败了,f()就完成了所有它的工作以及所有它的任务(这很好),但是结果是无法挽回的(哎哟我的妈呀)
我们可以做的更好吗,是否可以通过避免拷贝来避免这个问题?例如,我们可以 让函数有一个非常量引用参数并向下面这样返回值:
// Example 10(b): Better?
//
void f( String& result )
{
cout << "some output";
result = "some value";
}
这看起来很棒,但实际不是这样的,返回result的赋值的函数只完成了一个功能,而将其它事情留给了我们。它仍然会出错。因此这个做法不可取。
解决这个问题的一个方法是返回一个指向动态分配指针的String对象,但是最好的解决方案是让我们做的更多,返回一个指针包含在auto_ptr:
// Example 10(c): Correct (finally!)
//
auto_ptr<String> f()
{
auto_ptr<String> result = new String;
*result = "some value";
cout << "some output";
return result; // rely on transfer of ownership;
// this can't throw
}
这里是一个技巧,当我们有效隐藏所有的工作来构造第二个功能(返回值)当确保它可以被安全返回给调用者并且在第一个功能(打印消息)完成的时候没有抛出操作。我们知道一旦cout完成,返回值将成功交到调用者手中,并且无论如何都会正确清理:如果调用者接受返回值,调用者将得到这个拷贝的auto_ptr临时对象的所有权;如果调用者没有接受返回值,也就是忽略返回值,分配的String将在临时auto_ptr被销毁的时候自动清理。这种安全扩展的代价呢?就像我们经常实现的强异常安全一样,强安全通常消耗一些效率(通常比较小)——这里指额外的动态内存分配。但是当我们在效率和正确性之间做出选择的话,我们通常会选择后者!
让我们养成在日常工作中使用auto_ptr的习惯。auto_ptr解决了常见的问题,并且能够使你的代码变得更安全和健壮,特别是它可以防止内存泄漏以及确保强安全。因为它是标准的,因此它在不同类库和平台之间是可移植的,因此无论你在哪里使用它,它都将是对的。
致谢
This article is drawn from material in the new book Exceptional C++: 47 engineering puzzles, programming problems, and exception-safety solutions by Herb Sutter, © 2000 Addison Wesley Longman Inc., which contains further detailed treatments of points touched on briefly in this article, including exception safety, the Pimpl (compiler-firewall) Idiom, optimization, const-correctness, namespaces, and other C++ design and programming topics.
注释
-
Pimpl风格可以有效减少项目构建时间,因为它在C私有部分改变的时候,阻止客户代码引起广泛的重新编译。更多关于Pimpl风格以及如何部署编译器墙,参考这本Exceptional C++的条款26到30。(Addison-Wesley, 2000)
-
See the article "Exception-Safe Generic Containers" originally published in C++ Report and available on the Effective C++ CD (Scott Meyers, Addison-Wesley, 1999) and Items 8 to 19 in Exceptional C++ (Herb Sutter, Addison-Wesley, 2000).
先看一段简单的C++代码:
Type get(int I){
return Type(i);
}
Type t = get(1);
这里, 我们从C++的基本语义看上去, 应该是Type(i) 调用一次拷贝构造函数, 在堆栈中生成一个临时对象;然后,用该对象构造返回对象;然后对这个临时对象调用析构函数;在调用者方, 用返回的临时对象调用拷贝构造函数以初始化对象t, 返回对象的析构函数在这之后, 函数返回之前调用。
所以, Type t = get(i); 应该有三个拷贝构造函数和两个析构函数的调用.
可是, 还有一种说法是, 编译器可能会对这两个临时对象进行优化,最终的优化结果会是只有一次的构造函数。因为很明显地可以看到, 这里我们其实只是要用一个整数构造一个Type对象。
嗯. 似乎很有道理!
那么, 哪一种说法对呢? 没有调查就没有发言权,于是本人用VC++6.0做了实验。 放了些cout<<…..在拷贝构造函数里,观察打印的结果, 结果却是跟我的simple, naïve的预测一致。三个拷贝构造函数, 两个析构函数。
“你个弱智编译器!脑袋进水了吧?”(忘了编译器没脑袋了)“很明显在这个例子里我的两个临时对象都没有用的啊!”
于是,上网, 查资料, google一下吧!
下面是我查到的一些结果:
其实, 这种对值传递的优化的研究, 并不只局限于返回值。对下面这个例子:
void f(T t) { }
void main(void){
T t1;
f(t1);
}
也有这种考虑。
f(T)是按值传递的。语义上应该做一个复制, 使得函数内部对T的改变不会影响到原来的t1.
但是,因为在调用f(t1)之后, 我们没有再使用t1(除了一个隐含的destructor调用),是否可能把复制优化掉, 直接使用t1呢?这样可以节省掉一个拷贝构造函数和一个析构函数。
可是, 不论是对返回值的优化, 还是对上面这种局部对象的优化,在1995年的C++新标准草案出台前都是为标准所严格限制的 (虽然有些编译器并没有遵行这个标准, 还是支持了这种“优化”)
那么, 这又是为什么呢?
这里面涉及到一个普遍的对side-effect的担忧。
什么又是side-effect呢?
所谓side-effect就是一个函数的调用与否能够对系统的状态造成区别。
int add(int i, int j){ return i+j; }就是没有side-effect的,而
void set(int* p, int I, int v){ p[I]=v; }就是有side-effect的。因为它改变了一个数组元素的值, 而这个数组元素在函数外是可见的。
通常意义上来说, 所有的优化应该在不影响程序的可观察行为的基础上进行的。否则,快则快了, 结果却和所想要的完全不同!
而C++的拷贝构造函数和析构函数又很多都是有side-effect的。如果我们的“优化”去掉了一个有side-effect的拷贝构造函数和一个析构函数, 这个“优化”就有可能改变程序的可观察行为。(注意, 我这里说的是“可能”,因为“负负得正”, 两个有side-effect的函数的调用, 在不考虑并行运行的情况下, 也许反而不会影响程序的可观察行为。不过, 这种塞翁失马的事儿, 编译器就很难判断了)
基于这种忧虑, 1995年以前的标准, 明确禁止对含有side-effect的拷贝构造函数和析构函数的优化。同时, 还有一些对C++扩充的提议, 考虑让程序员自己对类进行允许优化的声明。 程序员可以明确地告诉编译器:不错, 我这个拷贝构造函数, 析构函数是有side-effect, 但你别管, 尽管优化, 出了事有我呢!
哎, side-effect真是一个让人又恨又爱的东西!它使编译器的优化变得困难;加大了程序维护和调试的难度。因此 functional language 把side-effect当作洪水猛兽一样,干脆禁止。但同时,我们又很难离开side-effect. 不说程序员们更习惯于imperative 的编程方法, 象数据库操作,IO操作都天然就是side-effect.
不过,个人还是认为C++标准对“优化”的保守态度是有道理的。无论如何,让“优化”可以潜在地偷偷地改变程序的行为总是让人想起来就不舒服的。
但是, 矛盾是对立统一的。(想当年俺马列可得了八十多分呢)。 对这种aggressive的“优化”的呼声是一浪高过一浪。 以Stan Lippeman为首的一小撮顽固分子对标准的颠覆和和平演变的阴谋从来就没有停止过。 这不?在1996年的一个风雨交加的夜晚, 一个阴险的C++新标准草案出炉了。在这个草案里, 加入了一个名为RVO (Return Value Optimization) 的放宽对优化的限制, 妄图走资本主义道路, 给资本家张目的提案。其具体内容就是说:允许编译器对命名过的局部对象的返回进行优化, 即使拷贝构造函数/析构函数有side-effect也在所不惜。这个提议背后所隐藏的思想就是:为了提高效率, 宁可冒改变程序行为的风险。宁要资本主义的苗, 不要社会主义的草了!
我想, 这样的一个罪大恶极的提案竟会被提交,应该是因为C++的值拷贝的语义的效率实在太“妈妈的”了。 当你写一个 Complex operator+(const Complex& c1, const Complex& c2);的时候, 竟需要调用好几次拷贝构造函数和析构函数!同志们!(沉痛地, 语重心长地)社会主义的生产关系的优越性怎么体现啊?
接下来, 当我想Google C++最新的标准, 看RVO是否被最终采纳时, 却什么也找不到了。 到ANSI的网站上去, 居然要付钱才能DOWNLOAD文档。 “老子在城里下馆子都不付钱, down你几个烂文档还要给钱?!”
故事没有结局, 实在是不爽。 也不知是不是因为标准还没有敲定, 所以VC++6 就没有优化, 还是VC根本就没完全遵守标准。
不过,有一点是肯定的。 当写程序的时候, 最好不要依赖于RVO (有人, 象Stan Lippeman, 又叫它NRV优化)。 因为, 不论对标准的争论是否已经有了结果, 实际上各个编译器的实现仍还是各自为政, 没有统一。 一个叫SCOtt Meyers的家伙(忘了是卖什么的了)就说, 如果你的程序依赖于RVO, 最好去掉这种依赖。也就是说, 不管RVO到底标准不标准, 你还是不能用。 不仅不能用, 还得时刻警惕着RVO可能带来的程序行为上的变化。 (也不知这帮家伙瞎忙了半天到底为啥!)
说到这里, 倒想起了C#里一个困惑了我很久的问题。记得读C#的specification的时候, 非常不解为什么C#不允许给value type 定义析构函数。
这里, 先简略介绍一下C#里的value type (原始数据类型, struct 类型)。
在C#里的value_type就象是值, 永远只能copy, 取值。因此, 它永远是in-place的。如果你把一个value type的数据放在一个对象里,它的生命期就和那个对象相同;如果你声明一个value type 的变量在函数中, 它的生命期就在lexical scope里。
{
The_ValueType value;
}//value 到这里就死菜了
啊呀呀! 这不正是我们怀念的C++的stack object吗?
在C++里,Auto_ptr, shared_ptr, 容器们, 不都是利用析构函数来管理资源的吗?
C#,Java 虽然利用garbage collection技术来收集无用对象, 使我们不用再担心内存的回收。 但garbage collection并不保证无用对象一定被收集, 并不保证Dispose()函数一定被调用, 更不保证一个对象什么时候被回收。 所以对一些非内存的资源, 象数据库连接, 网络连接, 我们还是希望能有一个类似于smart pointer的东西来帮我们管理啊。(try-finally 虽然可以用, 但因为它影响到lexical scope, 有时用起来不那么方便)
于是, 我对C#的取消value type的析构函数充满了深厚的阶级仇恨。
不过, 现在想来, C#的这种设计一定是惩于C++失败的教训:
1. value type 没有拷贝构造函数。C#只做缺省copy, 没有side-effect
2. value type 不准有析构函数。C#有garbage collection, 析构函数的唯一用途只会是做一些side-effect象关闭数据库连接。 所以取消了析构函数, 就取消了value type的side-effect.
3. 没有了side-effect, 系统可以任意地做优化了
对以下程序:
The_Valuetype get(int I){return The_Valuetype(i);}
The_Valuetype t = get(1);
在C#里我们可以快乐地说:只调用了一次构造函数。 再没有side-effect的沙漠, 再没有难以优化的荒原, smart pointer望而却步, 效率之花处处开遍。 I have a dream, ……
转载自:http://gugu99.itpub.net/post/34143/466008
/*
* type_infer_in_const_char_array.cpp
*
* Created on: 2010-4-4
* Author: volnet
* Ref: http://topic.csdn.net/u/20100403/16/aebc3e87-ae49-4a18-ba0b-263348b512e3.html
* ShortRef: http://is.gd/be914
*/
#include <stdlib.h>
#include <iostream>
#ifdef _MSC_VER
#include <typeinfo.h>
#else
#include <typeinfo>
#endif
template <typename T>
int compare(const T &v1, const T &v2) {
std::cout << "invoking compare ..." << std::endl;
if(v1<v2) return -1;
if(v2<v1) return 1;
return 0;
}
int main()
{
//error:
// no matching function for call to `compare(const char[3], const char[6])'
// compare("hi","world");
compare<const char*>("hi","world");
//what's the real type about "abcd"?
// const char * or const char [n] ?
std::cout << typeid("hi").name() << std::endl; // char const [3]
std::cout << typeid("world").name() << std::endl; // char const [6]
std::cout << typeid("dlrow").name() << std::endl; // char const [6]
// the compiler infer the typename T is char const [6]
compare("world", "dlrow");
}
首先我们面临的挑战是,声明堆中的数据需要我们用new关键字,直到我们显示调用了delete之后,它们才会被移除,但问题是,我们什么时候应该移除?如果调用语句在上下行中,我们自然知道如何移除。我们知道如果对象声明在堆中,那么在它离开它的作用域中的时候,可以自动释放,如果我们能够用栈对象来管理堆对象,在栈对象自动释放的时候,释放堆对象,就不需要显式调用delete语句了:
于是就有了下面的做法,应该不难理解:
template<class T>
class smart_ptr {
public:
smart_ptr(T* t = 0) { real_ptr = t; }
~smart_ptr() { delete real_ptr; }
T* operator ->() const { return real_ptr; }
T& operator *() const { return *real_ptr; }
private:
T* real_ptr;
};
我们希望我们的智能指针能够像指针一样地工作,但下面的工作方式似乎存在问题:
在普通的dumb指针中,以下行为是正确的:
void letUsGo(BaseClass* objPtr);
DerivedClass* derivedObjPtr2 = new DerivedClass();
letUsGo(derivedObjPtr2);
delete derivedObjPtr2;
但是,以下代码呢?
void letUsSmartGo(const smart_ptr<BaseClass>& objPtr);
smart_ptr<DerivedClass> smartDerivedObjPtr2(new DerivedClass());
// the smart_ptr<DerivedClass> is not inherited from the smart_ptr<BaseClass>
// the compiler can't find the class to cast it, so it must cause the error.
letUsSmartGo(smartDerivedObjPtr2);
下面的过程描述了这个变化所需要的一些支持:
1、error C2664: “letUsSmartGo”: 不能将参数 1 从“smart_ptr<T>”转换为“const smart_ptr<T> &”
2、smartDerivedObjPtr2的类型:
smart_ptr<DerivedClass> smartDerivedObjPtr2(new DerivedClass());
3、letUsSmartGo的声明:
void letUsSmartGo(const smart_ptr<BaseClass>&);
4、问题转化为,如何从smart_ptr<DerivedClass>到const smart_ptr<BaseClass>&的转变。
5、针对letUsSmartGo的声明,可以有的实参类型包括:
const smart_ptr<BaseClass>
smart_ptr<BaseClass>
假设存在以下类型 smart_derived_ptr : smart_ptr<BaseClass>,那么smart_derived_ptr也是可以被传递的。
6、这里存在这样一个问题:
new DerivedClass() 被传递给smartDerivedObjPtr2之后,smartDerivedObjPtr2就拥有了它的指针。如果从smartDerivedObjPtr2隐式转换成另一个smart_ptr<X>后,我们需要解决的就是将smartDerivedObjPtr2所拥有的指针传递给smart_ptr<X>并将smartDerivedObjPtr2的内部指针清零(这样就不会在smartDerivedObjPtr2被销毁的时候,因为调用delete real_ptr,而它的新拷贝在离开作用域的时候,一样会再次调用delete real_ptr,而此时real_ptr指向的对象已经被释放,因此这样的行为是未定义的。)
7、因此,定义如下方法即可:
template<class T>
class smart_ptr {
public:
smart_ptr(T* t = 0) {
std::cout << "creating smart_ptr ...smart_ptr(T* t = 0)" << std::endl;
real_ptr = t;
}
template<class U>
smart_ptr(smart_ptr<U>& rhs) : real_ptr(rhs.real_ptr){
std::cout << "creating smart_ptr ...smart_ptr(smart_ptr<U>& rhs)" << std::endl;
rhs.real_ptr = 0;
}
~smart_ptr() {
std::cout << "destoring smart_ptr ..." << std::endl;
delete real_ptr;
}
T* operator ->() const { return real_ptr; }
T& operator *() const { return *real_ptr; }
T* real_ptr;
};
8、但是这里real_ptr按照习惯应该是一个私有成员,而且我们在完成该方法时候,希望能够实现一种所谓的所有权转移,也就是将内部的指针传递给另一个智能指针,而这应该是一个原子过程。因此,我们实现以下方法:
template<class T>
class smart_ptr {
public:
smart_ptr(T* t = 0) {
std::cout << "creating smart_ptr ...smart_ptr(T* t = 0)" << std::endl;
real_ptr = t;
}
template<class U>
smart_ptr(smart_ptr<U>& rhs) : real_ptr(rhs.release()){
std::cout << "creating smart_ptr ...smart_ptr(smart_ptr<U>& rhs)" << std::endl;
}
~smart_ptr() {
std::cout << "destoring smart_ptr ..." << std::endl;
delete real_ptr;
}
T* operator ->() const { return real_ptr; }
T& operator *() const { return *real_ptr; }
// helper
T* release() {
T* tmp = real_ptr;
real_ptr = 0;
return tmp;
}
private:
T* real_ptr;
};

1、设置“生成时启用C/C++代码分析”为“是”,如果不设置此项,程序速度将出乎你的意料……

2、点击“分析”->“启动性能向导”

3、在“性能资源管理器”中右键新建的性能报告节点,右键“启动并启用分析功能”。

虽然此处有“启用分析功能”,但如果在配置里面没有进行设置,第一次的测试报告结果将是不准确的。
4、选择两个性能报告(ctrl+鼠标),右键“比较性能报告”。

用性能报告将有助于提高程序的性能,并且快速定位问题所在,剩下的结果就是你自己需要多观察,分析性能报告所反映的问题了。
更多
VC++ 6.0详见这里>> http://neural.cs.nthu.edu.tw/jang/mir/technicalDocument/vc6_profile/index.htm
第三方工具>> http://www.semdesigns.com/Products/Profilers/CppProfiler.html
这不是一篇向导,全面的向导请看
这里(http://goo.gl/XcAf)。
这仅是一篇笔记。这里用
bjam方式进行编译。
- 下载boost。(http://cdnetworks-kr-1.dl.sourceforge.net/project/boost/boost/1.42.0/boost_1_42_0.tar.bz2)
- 解压到指定文件夹,我是将它解压到根目录下的一个sourcecode文件夹下。
/home/volnet/sourcecode/boost_1_42_0
- 启动终端(ctrl+f2,输入“gnome-terminal”)。生成bjam脚本。
./bootstrap.sh --prefix=/home/volnet/sourcecode/boost_install
如果不带--prefix参数的话(推荐),默认的路径是/usr/local/include和/usr/local/lib ./bootstrap.sh
使用--help参数可以查看帮助,用-h可以查看简要帮助。 ./bootstrap.sh --help
生成脚本bjam,已经存在的脚本将被自动备份。volnet@Ubuntu:~/sourcecode/boost_1_42_0$ ./bootstrap.sh --prefix=/home/volnet/sourcecode/boost_install/
Building Boost.Jam with toolset gcc... tools/jam/src/bin.linuxx86/bjam
Detecting Python version... 2.6
Detecting Python root... /usr
Unicode/ICU support for Boost.Regex?... /usr
Backing up existing Boost.Build configuration in project-config.jam.4
Generating Boost.Build configuration in project-config.jam...
Bootstrapping is done. To build, run:
./bjam
To adjust configuration, edit 'project-config.jam'.
Further information:
- Command line help:
./bjam --help
- Getting started guide:
http://www.boost.org/more/getting_started/unix-variants.html
- Boost.Build documentation:
http://www.boost.org/boost-build2/doc/html/index.html
- 然后就是利用生成的bjam脚本编译源码了。
volnet@Ubuntu:~/sourcecode/boost_1_42_0$ sudo ./bjam -a -sHAVE_ICU=1 installNote: Building Boost.Regex with Unicode/ICU support enabled Using ICU in /usr/include
- ./是unix-like系统执行文件的前缀,这里就是指要执行bjam文件。
- -a是参数,代表重新编译(Rebuild)。输入./bjam -h获得更多帮助。
- -sHAVE_ICU=1,代表支持Unicode/ICU。点击这里(http://goo.gl/ySEe)
前提:系统内需要安装有libicu-dev,可以在终端输入:
sudo apt-get install libicu-dev
- install,表示安装
- --clean,表示清理。当前语句中包含-a,则不需要先手动清理,否则需要先运行
./bjam --clean
- 如果你执行上一步,会出现诸如:mpi的问题,多半是本机没有安装mpi。根据系统提示,你可以找到有/home/volnet/sourcecode/boost_1_42_0/tools/build/v2/user-config.jam。在文件最后跟上
using mpi ;
即可。然后如果还是有mpi问题,说明本机没有安装mpi。sudo apt-get install mpi-default-dev
界此应该顺利通过编译了。并在/usr/local/lib下有了boost的库了。
下面讨论一下链接静态链接库在Eclipse里的问题。
在
Unix variants向导里,官方提供了一个使用正则表达式的程序。
在Eclipse里,新增c++ project,并使用Linux C++编译器。将代码拷贝到文件中:
因为要静态链接到正则表达式的库,所以如下图所示,设置对应的*.a文件路径到eclipse,以使链接器能够找到它。
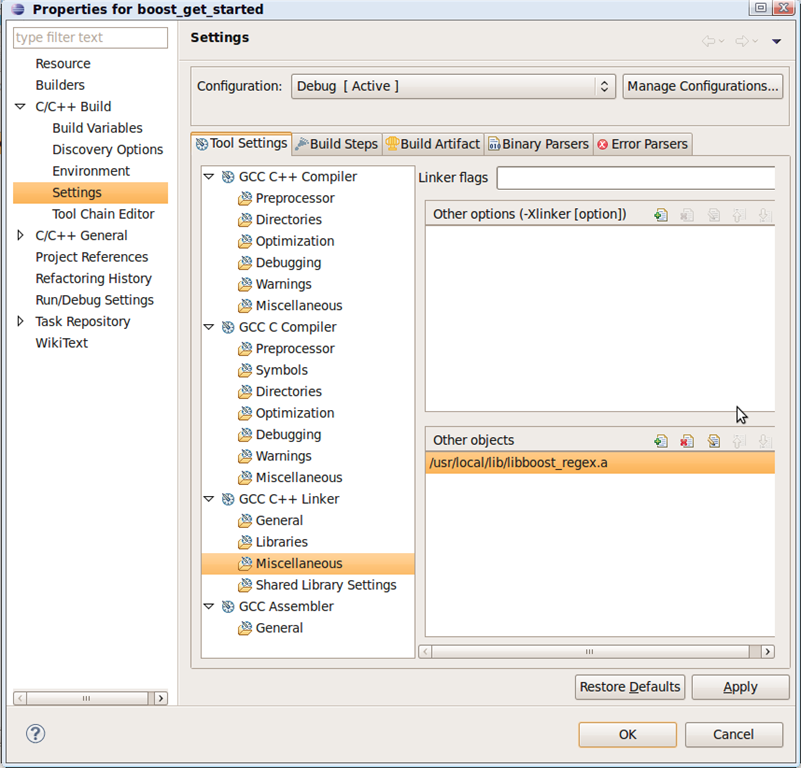
编译通过!
为了我们的程序能够正确载入,我们需要让我们的程序在我们的系统范围内也能够找到我们的库。这时候我们需要在设置一下。详见
这部分的相关介绍。
测试程序!
volnet@Ubuntu:~/workspace/boost_get_started/Debug$ ./boost_get_started < test
Will Success Spoil Rock Hunter?
这里test是一个文件。
关于单一参数构造函数的问题,主要是因为单一参数被编译器用作隐式类型转换,从而导致一些不可预期的事件的发生,请参见代码详细注释:
/*
* single_argument_ctor.cpp
*
* Created on: 2010-3-29
* Author: Volnet
* Compiler: GNU C++(version 3.4.5)
* MSVC CL(version 15.00.30729.01)
*/
#include <stdlib.h>
#include <iostream>
#include <sstream>
// single-argument class
class SingleArgumentClass {
private:
int _inner;
public:
SingleArgumentClass()
:_inner(-1)
{
}
SingleArgumentClass(int actual)
:_inner(actual)
{
}
bool operator==(const SingleArgumentClass& rhs);
std::string str(){
// we'd better to use boost::lexical_cast to cast.
// #region cast
std::stringstream strStream;
strStream << _inner;
std::string str;
strStream >> str;
// #endregion
return str;
}
};
bool
SingleArgumentClass::operator ==(const SingleArgumentClass& rhs){
if(_inner == rhs._inner)
return true;
return false;
}
// single-argument class fixed bug by explicit keyword.
class SingleArgumentClassFixedBugByExplicitKeyword {
private:
int _inner;
public:
SingleArgumentClassFixedBugByExplicitKeyword()
:_inner(-1)
{
}
explicit SingleArgumentClassFixedBugByExplicitKeyword(int actual)
:_inner(actual)
{
}
bool operator==(const SingleArgumentClassFixedBugByExplicitKeyword& rhs);
std::string str(){
// we'd better to use boost::lexical_cast to cast.
// #region cast
std::stringstream strStream;
strStream << _inner;
std::string str;
strStream >> str;
// #endregion
return str;
}
};
bool
SingleArgumentClassFixedBugByExplicitKeyword::operator ==(const SingleArgumentClassFixedBugByExplicitKeyword& rhs){
if(_inner == rhs._inner)
return true;
return false;
}
// single-argument class fixed bug by helper class.
class ActualType {
public:
ActualType(int value):_value(value){};
int get_value(){ return _value; }
private:
int _value;
};
class SingleArgumentClassFixedBugByHelperClass {
private:
int _inner;
public:
SingleArgumentClassFixedBugByHelperClass()
:_inner(-1)
{
}
SingleArgumentClassFixedBugByHelperClass(ActualType actual)
:_inner(actual.get_value())
{
}
bool operator==(const SingleArgumentClassFixedBugByHelperClass& rhs);
std::string str(){
// we'd better to use boost::lexical_cast to cast.
// #region cast
std::stringstream strStream;
strStream << _inner;
std::string str;
strStream >> str;
// #endregion
return str;
}
};
bool
SingleArgumentClassFixedBugByHelperClass::operator ==(const SingleArgumentClassFixedBugByHelperClass& rhs){
if(_inner == rhs._inner)
return true;
return false;
}
void Assert(bool status,
std::string strTrue = std::string("assert result is true;"),
std::string strFalse = std::string("assert result is false;"));
int main(void){
SingleArgumentClass obj(3);
std::cout << obj.str() << std::endl;
// our purpose.
SingleArgumentClass obj1(1);
SingleArgumentClass obj2(1);
Assert(obj1 == obj2, "obj1 == obj2", "obj1 != obj2");
int i = 3;
// warning!!!
// obj is a SingleArgumentClass object.
// i is a integer.
// operator== only define the equal between two SingleArgumentClass object.
// In fact:
// obj == i:
// 1.compiler found the operator== require two SingleArgumentClass object.
// 2.compiler try to find a cast method for casting int to SingleArgumentClass.
// 3.compiler found it can use the SingleArguementClass.Ctor(int)
// to create a new SingleArgumentClass.
// 4.compiler try to create a new SingleArgumentClass object from i.
// 5.so it without any warning and error, but it's logical not we need.
Assert(obj == i, "obj == i //right?", "obj != i");
// Assert(i == obj); // Compile ERROR: no match for 'operator==' in 'i == obj'
// it's may encounter a compile-time error.
// GNU G++: no match for 'operator==' in 'objFixed == i' single_argument_ctor.cpp single_argument_ctor/src 106 C/C++ Problem
// MSVC: 错误 1 error C2679: 二进制“==”: 没有找到接受“int”类型的右操作数的运算符(或没有可接受的转换) {projectpath}\single_argument_ctor\src\single_argument_ctor.cpp 107 single_argument_ctor
SingleArgumentClassFixedBugByExplicitKeyword objFixed(3);
// Assert(objFixed == i, "objFixed == i", "objFixed != i");
SingleArgumentClassFixedBugByHelperClass objFixedByHelper1(3);
SingleArgumentClassFixedBugByHelperClass objFixedByHelper2(3);
// it's may encounter a compile-time error.
// GNU G++: no match for 'operator==' in 'objFixedAuto1 == i' single_argument_ctor.cpp single_argument_ctor/src 158 C/C++ Problem
// MSVC: 错误 1 error C2679: 二进制“==”: 没有找到接受“int”类型的右操作数的运算符(或没有可接受的转换) {projectpath}\single_argument_ctor\src\single_argument_ctor.cpp 163 single_argument_ctor
// Assert(objFixedByHelper1 == i);
}
void Assert(bool status,
std::string strTrue, std::string strFalse)
{
std::cout << (status strTrue : strFalse) << std::endl;
}
解决方法:
1、explicit关键字,在单参数构造函数前使用explicit参数,可以避免单参数构造函数被用于隐式转换。
2、利用中间类的方式,详见代码“SingleArgumentClassFixedBugByHelperClass相关部分”。如果编译器不支持解决方法1,则建议使用此方法。上面代码所提及的两款主流编译器均支持explicit关键字。