#
这是编程之美之中的一道题,编程之美中的解法固然好,但自己手写一遍还是印象深刻。话说,只有想不到,没有做不到。
C语言版(关键在思路,更好的表示,特别是whoIsOk1的表示,可能编程之美上的做法更工业化,这里为了简化说明问题,用了很多magic number):
/*
* chinese_chess_admiral_marshal.c
*
* Created on: 2008-9-14
* Author: Volnet
* WebSite: http://volnet.cnblogs.com/
* http://www.cppblog.com/mymsdn/
*/
#include <stdio.h>
#include <stdlib.h>
/*
* admiral
* 1 2 3
* 4 5 6
* 7 8 9
*
* marshal
* 1 2 3
* 4 5 6
* 7 8 9
*
* who can't sit in the same column.
* e.g. if admiral in "1", the marshal can't in the "1"、"4"、"7".
* */
/*
* The five functions do the same thing.
* */
void whoIsOk1();
void whoIsOk2();
void whoIsOk3();
void whoIsOk4();
void whoIsOk5();
int main(void) {
whoIsOk1();
printf("-----------------------------------\n");
whoIsOk2();
printf("-----------------------------------\n");
whoIsOk3();
printf("-----------------------------------\n");
whoIsOk4();
printf("-----------------------------------\n");
whoIsOk5();
//printf("-----------------------------------\n");
return EXIT_SUCCESS;
}
void whoIsOk1() {
/*Normal one*/
unsigned int i, j, total;
total = 0;
for (i = 1; i <= 9; i++)
for (j = 1; j <= 9; j++)
if (i % 3 != j % 3) {
printf("A=%d,B=%d\n", i, j);
total++;
}
printf("total = %d\n", total);
}
/*
* i:iiii0000
* j:0000jjjj
* */
/* g:a variable who can contains 8 bits.
* */
#define iGET(g) ((g&0xf0)>>4)
#define jGET(g) (g&0x0f)
#define iSET(g,i) (g=(g&0x0f)|((i)<<4))
#define jSET(g,j) (g=(g&0xf0)|(j))
void whoIsOk2() {
/*only one variable except “total”*/
unsigned char ij;
/* for testing
ij = 0x53;
iSET(ij,3);
jSET(ij,5);
printf("%x\n%d\n%d\n",ij,iGET(ij),jGET(ij)); */
int total;
total = 0;
for (iSET(ij,1); iGET(ij) <= 9; iSET(ij,iGET(ij)+1))
for (jSET(ij,1); jGET(ij) <= 9; jSET(ij,jGET(ij)+1))
if (iGET(ij) % 3 != jGET(ij) % 3) {
printf("A=%d,B=%d\n", iGET(ij), jGET(ij));
total++;
}
printf("total = %d\n", total);
}
void whoIsOk3() {
/* The principle of the function is :
* get the number 19 from one variable.
* get the number 19 from the same variable.
* we know the variable i/9 would mutex with i%9.
* e.g.
* int i = 20;
* i/7 == 2;
* i%7 == 6;
*
* int j = 14;
* j/7 == 2;
* j%7 == 0;
*
* i - j == 6;
* if(k/7 from 14 to 20)
* k%7 would from 0 to 6 (total = 7);
* so we can get the double circle from one variable.
* */
unsigned int i = 81, total;
total = 0;
do {
if (i / 9 % 3 != i % 9 % 3) {
printf("A=%d,B=%d\n", i / 9 + 1, i % 9 + 1);
total++;
}
} while (i--);
printf("total = %d\n", total);
}
/*whoIsOk3 is nearly equals to whoIsOk4*/
void whoIsOk4() {
unsigned int i = 81, total;
total = 0;
while (i--) {
if (i / 9 % 3 != i % 9 % 3) {
printf("A=%d,B=%d\n", i / 9 + 1, i % 9 + 1);
total++;
}
}
printf("total = %d\n", total);
}
typedef struct {
unsigned x :4;
unsigned y :4;
} complex_counter;
void whoIsOk5() {
/*use an struct scheme to mix two variables in one*/
complex_counter i;
i.x = i.y = 0;
unsigned int total;
total = 0;
for (i.x = 1; i.x <= 9; i.x++)
for (i.y = 1; i.y <= 9; i.y++)
if (i.x % 3 != i.y % 3) {
printf("A=%d,B=%d\n", i.x, i.y);
total++;
}
printf("total = %d\n", total);
}
值得注意的一点是形如#define jSET(g,j) (g=(g&0xf0)|(j))这样的语句
为了避免二义性,也为了避免被宏替换后的操作符顺序依赖,尽量对使用的变量单独用()括起来,因为它不是一个字母在战斗……-_-"
执行结果(片段):
A=1,B=2
A=1,B=3
A=1,B=5
A=1,B=6
A=1,B=8
A=1,B=9
A=2,B=1
A=2,B=3
A=2,B=4
A=2,B=6
A=2,B=7
A=2,B=9
A=3,B=1
A=3,B=2
A=3,B=4
A=3,B=5
A=3,B=7
A=3,B=8
A=4,B=2
A=4,B=3
A=4,B=5
A=4,B=6
A=4,B=8
A=4,B=9
A=5,B=1
A=5,B=3
A=5,B=4
A=5,B=6
A=5,B=7
A=5,B=9
A=6,B=1
A=6,B=2
A=6,B=4
A=6,B=5
A=6,B=7
A=6,B=8
A=7,B=2
A=7,B=3
A=7,B=5
A=7,B=6
A=7,B=8
A=7,B=9
A=8,B=1
A=8,B=3
A=8,B=4
A=8,B=6
A=8,B=7
A=8,B=9
A=9,B=1
A=9,B=2
A=9,B=4
A=9,B=5
A=9,B=7
A=9,B=8
total = 54
void changeString(char **t){
*t = "world";
}
void changeString2(char *t[]){
*t = "world2";
}
typedef char *String;
void changeString3(String *s){
*s = "world3";
}
void Inc(int *i){
(*i)++;
}问题列表:
1、如何改变外部变量?
2、啥时候我们需要使用**?
前言:
先看Inc,我们知道int i是一个值类型,为了能够达到修改它的目的,我们需要将i的实际地址通过值传递的方式从调用函数传递给被调用函数,因为对相同的地址的变量进行操作,所以我们的Inc(&i)将如我们所愿,顺利地递增。
以上两个版本的changeString都是可以达到修改调用函数中的字符串的。如果按照下面的代码将得到不正确的结果。
错误代码示例:
void errorChangeString(char *t){
t = "change!";
}
int main(void){
char *s = "Hello";
errorChangeString(s);
return EXIT_SUCCESS;
}在错误示例代码中,假设传递的s则为指向字面值"Hello"的首字母'H'所在的地址值,假设这个值为0x1000。在errorChangeString中,假设"change"字面值的首字母'c'所在的地址值为0x2000,s被拷贝给了t,t的任何改动和s没有任何关联,因此,s仍然指向0x1000,而不是指向0x2000。
我们应如何看待char **t?
若要让所谓的t的值能够跟着s变化,我们则需要指向指针的指针来帮忙。我们知道要让函数传递(C语言只有值传递)后,仍然指向相同的值(这里指s始终为0x4000(s指向0x1000,假设它自身地址为0x4000)),则我们需要将这个传递的值进行一次包装,使我们通过形参也能够控制相同的地址所在的变量(这里指0x4000),因此,我们对形参定义一个指针,形如 char* *t(等价于char **t),这样*t与s就代表了相同的值而不会因为传递而无法操纵s,因此可以在被调用函数内部使用*t来指代要操作的外部变量(通过参数传递),因此在内部*t="world"(假设"world"的首地址为0x2000),则s的值就被修改为"world"的首地址。(如下图所示)
 我们应如何看待char *t[]?
我们应如何看待char *t[]?在我们的changeString2(char *t[])中,我们用char *t[]取代了char **t,我们知道char *t[]代表t是一个数组,数组的每一个成员都是一个char*类型的指针。我们也成为
指针数组。下面让我们看一个调用:
void changeStrArr(char *t[]){
*t = "World";
}
int main(void){
char *sArr[] = {
"Hello"
};
printf("%s",*sArr);
changeStrArr(sArr);
printf("%s",*sArr); //printf("%s",sArr[0]);
return EXIT_SUCCESS;
}这是教科书上比较常见的指针数组形式,甚至还会简单不少(它们的数组通常会有多个元素并用*t++来控制移位)。sArr在这里就是这个数组,因此sArr[0]即为指向该数组第一个元素的指针(因为是指针数组,每一个元素都是一个指针),因此使用printf("%s",*sArr); 或者printf("%s",sArr[0]);都将标准输出sArr的第一个元素所指向的字符串。
下面我们来看一下下面这段代码:
void changeString2(char *t[]); //函数体见本文顶部
int main(void){
char *s="Hello";
printf("%s",s);
changeString2(&s);
printf("%s",s);
return EXIT_SUCCESS;
}从这段代码中我们主要讲s换成了一个字符而不是上一段代码中的字符指针数组sArr,从上一段代码我们可以得知s和sArr之间的关系,*s==*sArr[0]==**sArr;(我们可以通过strcmp(q,qArr[0])或者strcmp(q,*qArr);进行判断,我们知道strcmp(const char *_Str1, const char *_Str2);也就是我们传递的q和*qArr均为字符指针也就是它们的定义通常为char *q和char **qArr)。为此我们可以将其进行移项,也可以得到等价表达式(规律:==两侧同时添加相同符号等式依旧不变(在*和&的逻辑里成立),同时出现&*,两符号起中和作用(先从一个地址中取值,再从值反求它的地址,因此最终结果还是地址本身))也就是&*s==&*sArr[0]==&**sArr <=> s==sArr[0]==*sArr,这样,再进行一次,&s==&sArr[0]==&*sArr,也就是&s==&sArr[0]==sArr因此changeStrArr(sArr)<=>changeStrArr(&s),因此从上面的代码段到下面代码段的演化是成功的(changeString2和changeStrArr本质上没有差别)。
下面的示例图则从本质上分别分析了两者的各自的理由(非上述推理):
 用typedef char *String;改良后的程序具有更高的可读性
用typedef char *String;改良后的程序具有更高的可读性可以看到第三段代码中我们在函数声明前用typedef语句定义了typedef char *String;首先从typedef的本质来讲,这种定义将导致使用它的changeString3与changeString函数具有相同的本质,但是从阅读的习惯上来讲,用String而不是用char *的方式,则显得更加亲切。首先我们从众多起他语言中,比如C#中,C#实现了类型String/string的方式,我们知道String是一个引用类型,但我们同时也知道string类型有个显著的特征,就是它虽然是引用类型,每次对它的操作总是像值类型一样被复制,这时候,我们定义的任何(C#):ChangeString(string str);将不起作用,而我们需要增加ref关键字来告诉编译器它是同一实例,而不进行重新申请空间重新分配等一系列复杂操作,于是ChangeString(ref string str);的语句就有类似值类型的一些地方了,同样,在C语言中,changeString2(String *s)也达到了同样的效果。这样的方式也同时对我们更加了解第一种方式起到了辅助作用。(用C#来比喻可能不是太好,因为很多读者通常都是先接触C再有机会才接触C#的,而且也没有讲解到本质)
void changeString3(String *s); //函数体见本文顶部
int main(void){
char *s="Hello";
printf("%s",s);
changeString3(&s);
printf("%s",s);
return EXIT_SUCCESS;
}本质呢?因为任何一次的"Hello",其中的"Hello"是常量,而不是变量,它的存储空间在编译时就已经确定了,它放在了静态常量区中,因此它的地址不会变也不能加减。因此String,也就是char *指向的是一个不可变的常量,而非变量。(例如我们一直假设char *s = "Hello",的首地址s==0x1000(s的值,不是s的地址),那么它始终是0x1000,但是s是变量,s可以抛弃0x1000指向别的字符串字面值(char literal),但是我们知道C语言中只有按值传递,因此我们必须用它的指针假设s的地址0x3000,那么,我们将0x3000进行传递,这样内部就可以对0x3000进行操作了,这样可以用(0x3000)->value的方式修改value指向0x2000的地址(假设这个地址是"GoodBye"的值),这样我们的s就被修改了。因为我们的常量在编译时就已经分配了地址,在程序加载后就长久存在,知道应用程序退出后会跟着宿主一并消失,所以我们同样不需要free操作)。
下一个问题:
啥时候我们需要用到**?
通过以上的几个直观的示例,我们大体了解了一个字符串通过一个函数参数进行修改的具体情况。这是一个很发散性的问题,我也没有一个很肯定的100%的答案。
从void **v;(//void代表任意类型,可以是int/char/struct node等)定义的本质上来观察这个问题,我们可以推论void **v;,当我们需要获取并改变*v的地址值得时候,我们都有这个需要(因为单从void *v的角度讲,我们只能够获取v的地址改变v的值,但不能改变v的地址)。那我们什么需要获取并改变*v的值呢?从上面的分析我们不难得出,我们在需要改变v的地址的时候即有这个需要。
下面是一个链表的例子:
#include <stdio.h>
#include <stdlib.h>
typedef struct node{
int value;
struct node *next;
} Node;
Node *createList(int firstItem){
Node *head = (Node *)malloc(sizeof(Node));
head ->value = firstItem;
head ->next = NULL;
return head;
}
void addNode(Node *head, Node **pCurrent,int item){
Node *node = (Node *)malloc(sizeof(Node));
node ->value = item;
node ->next = NULL;
(*pCurrent)->next=node;
*pCurrent = node;
}
typedef void (*Handler)(int i);
void foreach(Node *head, Handler Ffront, Handler Flast){
if(head->next!=NULL){
Ffront(head->value);
foreach(head->next,Ffront,Flast);
}
else
{
Flast(head->value);
}
}
void printfFront(int i){
printf("%d -> ",i);
}
void printfLast(int i){
printf("%dn",i);
}
int main(void){
Node *head, *current;
current = head = createList(0);
for(int i=1;i<10;i++)
addNode(head,¤t,i);
foreach(head, printfFront, printfLast);
return EXIT_SUCCESS;
}//函数输出
0 -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8 -> 9
这个程序中的关键部分就是当前节点值current的确定,部分老师可能会图方便采用全局变量进行当前值的确定,这个在抛弃型的示例中当然无伤大雅,也很好地描述了链表的本质,这本没什么关系,但是链表是一个常用的数据结构,并发怎么办?操作多个链表怎么办?总之我们要秉承“方法共享,数据不共享的原则”,这样就不太容易出现问题了。这里我们在main函数中定义了唯一的*head用于标识链表的头,并希望它始终扮演链表头的角色,不然我们最后将无法找到它了。我们用一个同样类型的节点current指向了当前节点,并始终指向当前节点(随着链表的移动,它将指向最后一个节点)。由于我们的current是主函数中定义的,而它的修改是在被调函数中进行的。因为我们需要改变的*current的值,根据我们的分析,对于要修改值的,我们有使用**的必要,而类似只需要读取值的head,则没有任何需要了。
这个程序代表了一种使用**的典型用法,也是大部分需要使用**的用法。
总结:
不论它怎么变化,怎么复杂,我们需要把握几点:
1、C语言中,函数传递永远是值传递,若需要按地址传递,则需要用到指针(类似func(void *v){...});
2、在对于需要变化外部值的时候,直接寻址的使用*,间接寻址的使用**;
3、对于复杂的表达式,善于使用嵌套的思路去分析(编译器亦或如此),注意各符号之间的优先级。
这句是非常经典、简洁的指针操作语句,但是它在gcc编译器下居然会出现警告。
warning: suggest parentheses around assignment used as truth value
理由:在C语言中,非0即代表TRUE,反之为FALSE。上面的语句以*s的值用于最后的判断。但是由于长期的编程实践告诉我们,人们经常在“=”和“==”的使用上出现手误,所以gcc编译器为此要求我们明确地告诉编译器它是“=”而不是“==”,是故意,而非手误。
既然我们的语句如上所示,并非要用“==”,因此我们只需修改成下列样式即可:
参考:
1、http://www.network-theory.co.uk/docs/gccintro/gccintro_94.html
2、http://darkmomo.blogspot.com/2008/05/suggest-parentheses-around-assignment.html
都说是MinGW4.0之后GDB并没有被包含在安装包之中,需要另外下载安装。
话说原理很简单,就是折腾那么个gdb.exe来,然后放在MinGW的bin目录中,期间无外乎就是去把它下下来。说是如此简单,但是到了http://www.gnu.org/software/gdb/download/后才发现,原来只提供源码,要自己回家编译。
话说编译也不难,编译器啥的都已经有了,按理上个MSYS(也有了)然后用./configure make就可以开始搞了……(一切如README所述)。但是往往好事多磨,最后总是会有Error跳出来拦路。我这个本来就是门外汉,没有Error都已经很吃力了,有Error显然吃不消。
话说这里找到一篇文章,图文并茂,还说的很正点,可惜它所提到的软件,在sourceForge.net上死活没找到。
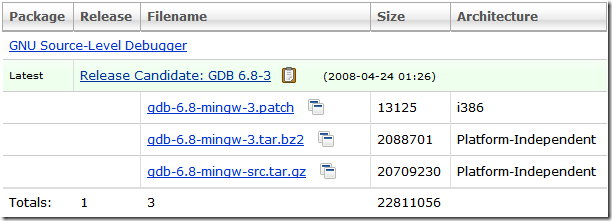
下了那个patch文件回来,看了里面的内容,貌似不像是更新,话说patch文件怎么用都不知道。赶快搜了几下试了几下,也没成功。就直接把图文并茂里面的图上的关键字拿去“GDB 6.8 for MinGW Setup”搜索,在CSDN上找到了,话说昨天晚上也找到了,可惜昨晚那个网页不灵光了,死活打不开。
后来上www.xunlei.com随便搜了个GDB第一条就是了~瀑布汗~
下载地址(gdb-6.3.2)http://prdownloads.sourceforge.net/mingw/gdb-6.3-2.exe?download
改天一定把那个6.8给编译出来……
在使用Eclipse的时候,一个非常优秀的功能就是能够使用Spell checker对拼写进行检查。如果您没有用过,或者您不太理解我说的,那你就回顾一下WORD里面那些令人看上去很不舒服的波浪线,虽然看着不舒服,可是它却减少了很多错误的拼写。
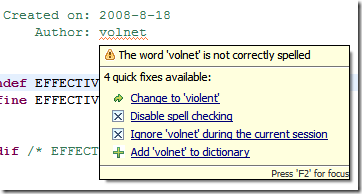
在有些版本中(网上有部分朋友和我一样在使用CDT的时候出现了这个问题),可能会丢失用户字典(Missing User Dictionary),如下图:
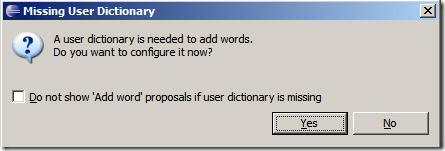
在偏好设置中,我们能看到的spelling的选项内,拼写引擎不存在。
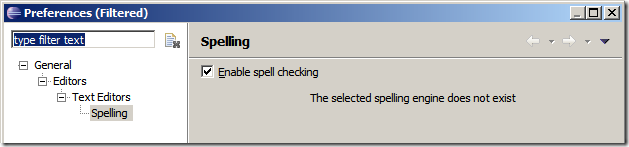
这里介绍一个第三方拼写检查插件。在Help->Software Update中选择Available Software选项卡。
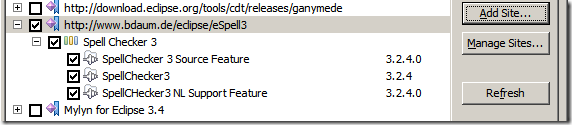
点击Add State...,添加下面网站的信息http://www.bdaum.de/eclipse/eSpell3链接,相关介绍见下面链接:http://www.eclipseplugincentral.com/Web_Links-index-req-viewlink-cid-85.html

点击“Install”即可进行安装了。(安装过程需要连接互联网。)

另人高兴和雀跃的并不是这个拼写检查插件,它比想象中的要差劲,我似乎看到了满页的波浪线,虽然可能可以通过修改参数来使之更人性化,但是我还是觉得不如没有它更好。默认的spelling居然生效了。剩下的内容可以参看http://www.javalobby.org/java/forums/t17453.html了。
作用域是一个在绝大多数(事实上我没有见过没有作用域概念的程序语言)程序语言的必然组成部分。日常良好的使用使用习惯和程序设计风格,有时候让我们渐渐忘记了这些作用域的准确定义,因为它通常没给我们带来什么麻烦。这里我将其写下来,仅在勾起大家模糊回忆中清晰的轮廓,也许有你所知的,也许有你所惑的,又或者可能我的理解和你的理解甚至格格不入,烦请大家积极指正。
几个概念:
a.外部变量,许多程序设计的书上用“全局变量”一词,这里做一个统一,本文中“外部变量”就是所谓的“全局变量”。
b.自动变量,许多程序设计的书上用“局部变量”一词,这里做一个统一,本文中“自动变量”就是所谓的也可以称作“动态局部变量”,与此相对的还有“静态局部变量”,这两种局部变量的并集就是通常所说的“局部变量”了。
这两种叫法都是有其特定的道理和阐述的意义的。局部变量就是直言了其作用的范围,它是局部的可见的(这一点您应该深有体会)。因为在一个函数内声明一个变量,形如int a;它从它的声明式开始,直到该函数的末尾(以“}”符号所标识)有效。在函数体的外部,该变量a不存在并且无效。这样的声明事实上是auto int a;声明式的一种省略写法,因此称之为“自动变量”,因为它在该函数调用开始的时候初始化内存空间,在调用结束的时候将释放该函数的内存空间,而这一切不需要人工的干预,因此它是自动的。
c.静态变量,又称之为“静态局部变量”,它通常与auto int a;的形式相反,它采用了static关键字进行修饰,static int a;。这样的声明导致了它在编译时就分配了内存空间,并在整个程序的运行过程中持续有效。唯一的限制是它仅在它所在的函数范围内有效。
1、外部变量的作用域从它声明的位置开始,到其所在(待编译)的文件的末尾结束。
参看以下代码:
#include <stdio.h>
#include <stdlib.h>
void extern1Processor(void);
int main(void){
/*下面的语句因为extern1Variable变量的定义在main函数的后面
* 因此该函数将产生编译错误。
* extern1Variable' undeclared (first use in this function)
printf("main.extern1Variable:%d\n",extern1Variable);*/
extern1Processor();
return EXIT_SUCCESS;
}
int extern1Variable = 2003;
/*下面能够正确使用extern1Variable变量,因为extern1Variable的
* 定义在extern1Processor(void);方法之上。*/
void extern1Processor(void){
printf("extern1Processor.extern1Variable:%d\n",extern1Variable);
}
2、如果要在外部变量的定义之前使用该变量,则必须在相应的变量声明中强制地使用关键字extern。
参看以下代码:
#include <stdio.h>
#include <stdlib.h>
void extern2Processor(void);
int main(void) {
extern int extern2Variable;
printf("extern2Processor.extern2Variable:%d\n", extern2Variable);
extern2Processor();
return EXIT_SUCCESS;
}
int extern2Variable = 2004;
void extern2Processor(void) {
printf("extern2Processor.extern2Variable:%d\n", extern2Variable);
}输出结果:
extern2Processor.extern2Variable:2004
extern2Processor.extern2Variable:2004
3、如果外部变量的定义与变量的使用不在同一个源文件中,则必须在相应的变量声明中强制地使用关键字extern。
假设在不同的源文件file1.c与file2.c中,我们都需要定义一个变量int aVariable = 2;时,分别编译二者,它们将都包含一个变量aVariable的声明和定义。但是当我们将它们一起加载的时候,由于它们都是外部变量,相同的变量名导致编译器不知道它们的主次关系。因此,这里我们要求程序员一定要用extern将主次分出来。比如file1.c中int aVariable = 2;这句话声明了aVariable的类型为int,为它分配了sizeof(int)内存大小的一块内存空间,它的值为2。在file2.c中我们声明它extern int aVariable;(这里不能使用extern int aVariable=3;但是可以使用int aVariable;)这句话告诉了编译器aVariable不是我这个源文件中进行声明的,它来自外部(一个未知的位置)。这样在单独编译该文件gcc -c file2.c的时候就不会因为缺失声明式而引发编译错误了。
有同学认为这里的int aVariable;是声明,不是定义,这是一种错误的观点。在外部变量中,形如:
file1.c file2.c
---------------------------------------------------------------
int aVariable = 3; int aVariable;
int main(){
……
}其中的int aVariable;定义了外部变量aVariable,并为之分配了存储单元。
这同时也成为了外部变量和静态变量必须是常量表达式,且只初始化一次的理由。如果我们对两边都进行初始化(定义),编译器将不知道让谁成为主要初始化的值。事实上,外部变量和静态变量的值初始化过程是在编译时进行的,它们的值都被放在静态存储区,也就是我们惯常在汇编中的DATA SEGMENT部分,因此它们必须是常量表达式,并且有且只有初始化一次,否则我们将可能写出类似这样的语句(而这样的语句本身就是错误的):
DATA SETMENT
INFO1 "INFOMATION1"
"INFOMATION2" ;这样的定义是不允许的
DATA ENDS
……按照概念extern通常被看作是外部的,因此通常情况下初始化操作一般是在无extern的声明式后的,若在extern一边进行初始化,则有违常理(主次不分了)。但是由于将初始化步骤仅放在extern一边满足只初始化一次的原则,因此编译不会出错,但是根据不同的编译器可能会给出警告提示。
参看以下代码:
包含main的源文件:
#include <stdio.h>
#include <stdlib.h>
void extern3Processor(void);
int main(void) {
extern3Processor();
return EXIT_SUCCESS;
}
extern int extern3Variable;
void extern3Processor(void) {
printf("extern3Processor.extern3Variable:%d\n", extern3Variable);
}externFile.c文件:(这个文件很简单,就包含了一个外部变量的定义)
int extern3Variable = 2005;
编译多个文件如下:(将.c文件编译为.o文件,再将这几个.o文件一起加载到.exe文件中(UNIX中通常为.out文件),通常在对个别文件作出修改后,我们只需要重新编译那个文件,然后将这些新旧.o文件一起加载到.exe文件中即可。)
gcc -O0 -g3 -Wall -c -fmessage-length=0 -osrc\EffectiveArea.o ..\src\EffectiveArea.c
gcc -O0 -g3 -Wall -c -fmessage-length=0 -osrc\externFile.o ..\src\externFile.c
gcc -oEffectiveArea.exe src\externFile.o src\EffectiveArea.o
输出结果:
extern3Processor.extern3Variable:2005
4、之前提到的文字中包含“声明”和“定义”,它们其实有着严格的区别。
声明:变量声明用于说明变量的属性(主要是变量的类型)
定义:变量定义除了需要声明之外,还引起了存储器分配。
5、在步骤3中我们发现在任意文件中定义的外部变量均可在其它文件中进行使用,只要我们使用了extern关键字告诉编译器这个变量的声明式,我们就可以顺利通过编译。虽然这个方式能够实现在多个文件中共享数据,但是考虑到文件的管理与项目的不可预测性,这样的方式未免让我们有了些许的担心。要是我定义的变量被别人恶意引用了怎么办?对于只进行读操作的行为,可能这种灾难是比较小的,但是对于写操作的行为,就有可能影响到变量的正确性。
用static声明限定外部变量和函数,可以将其后声明的对象的作用域限定为被编译源文件的剩余部分。
参看以下代码:
包含main的源文件:
#include <stdio.h>
#include <stdlib.h>
void static1Processor(void);
int main(void) {
static1Processor();
return EXIT_SUCCESS;
}
extern int static1Variable;
void static1Processor(void) {
printf("static3Processor.static3Variable:%d\n", static1Variable);
}staticFile.c文件:(这个文件很简单,就包含了一个外部变量的定义,与externFile.c所不同的是它的定义增加了static关键字修饰):
static int static1Variable = 2006;
输出结果(编译错误,无任何输出结果):
由于static int static1Variable = 2006;导致了static1Variable变量只对staticFile.c文件可见。
对于函数,它也是具有类似的限制:
包含main的源文件:
#include <stdio.h>
#include <stdlib.h>
/*两种定义均无法引用void static2Processor(void);方法的具体实现。*/
/*void static2Processor(void);*/
extern void static2Processor(void);
int main(void) {
static2Processor();
return EXIT_SUCCESS;
}staticFile.c:
#include <stdio.h>
static int static2Variable = 2007;
static void static2Processor(void) {
printf("static2Processor.static1Variable:%d\n", static2Variable);
}static不仅可以用于声明外部变量,它还可以用于声明内部变量。static类型的内部变量同自动变量一样,是某个特定局部变量,只能在该函数中使用,但它与自动变量不同的是,不管其所在函数是否被调用,它将一直存在,而不像自动变量那样,随着所在函数的被调用和退出而存在和消失。换句话说,static类型的内部变量只是一种只能在某个特定函数中使用但一直占据存储空间的变量。
6、因为extern是为了防止重复定义,而不是防止重复声明。因此对于不可能产生重复定义的函数声明式来说,形如void extern4Processor(void); 这样的语句可以不用增加extern,因为它是重复的声明,而不是定义。
因为函数声明式本身是不允许嵌套的,因此它天生就是外部的,所以默认情况下类似void FunctionName(){……};的形式都有个默认的修饰符extern void FunctionName(){……};只有标识了static的函数不是外部函数。
包含main的源文件:
#include <stdio.h>
#include <stdlib.h>
/*double kinds of declare
* The storage-class specifier, if any,in the declaration specifiers
* shall be either extern or static .
*/
/*extern void extern4Processor(void);*/
void extern4Processor(void);
int main(void) {
extern4Processor();
return EXIT_SUCCESS;
}
externFile.c:
#include <stdio.h>
int extern4Variable = 2008;
void extern4Processor(void) {
printf("extern4Processor.extern4Variable:%d\n", extern4Variable);
}输出结果:
extern4Processor.extern4Variable:2008
7、重复声明并不可怕,可怕的是重复定义。
参看以下代码:
包含main的源文件:
#include <stdio.h>
#include <stdlib.h>
char repeatVariableWithoutDefinition1; /*declear thrice no hurt*/
char repeatVariableWithoutDefinition1; /*declear thrice no hurt*/
char repeatVariableWithoutDefinition1; /*declear thrice no hurt*/
void repeatVariableWithoutDefinition1Func(void);
int main(void) {
repeatVariableWithoutDefinition1Func();
return EXIT_SUCCESS;
}
void repeatVariableWithoutDefinition1Func(void) {
repeatVariableWithoutDefinition1 = 'v';
printf("repeatVariableWithoutDefinition1:%c\n",
repeatVariableWithoutDefinition1);
}otherFile.c:
char repeatVariableWithoutDefinition1;
char repeatVariableWithoutDefinition1;
它的无害是因为它们都是在编译时进行分配的,它们并没有并存,只是仅存了一个罢了。
8、至此,上面已经生成了许多的声明/定义。可以看出,我们的函数是可以跨文件调用的,而且每次调用都要写函数声明式。为此,C语言支持“头文件”,也就是我们经常看到的#include "xxxxx.h"或#include <stdio.h>。其中include <>的时候,将根据相应规则查找该文件(通常在编译器所在Includes文件夹内找),但是""的时候总是先在源文件(*.c)所在文件夹查找,若找不到则使用与#include <>相同规则进行查找。
#include是一个C预处理器,它所指定的文件将在编译时,将其中内容原封不动地替换到#include语句所在的位置。这样的话,我们就有能力实现了一个地方定义函数,多个地方调用的功能了。(每次重新写声明式难免会造成:1、手误,导致拼写错误;2、修改维护困难,可能会漏掉,但又机缘巧合不会出错。)
#include头文件中可以推荐包含文件声明、宏替换等(事实上可以包含任何的文本)。
因为可以包含任何的文本,所以我们有可能因为重复定义而导致一些不必要的麻烦,因为毕竟重复定义是没有任何意义的,还增加编译时间。因此在头文件的内部,我们通常采用条件包含来避免重复地包含。
参看以下代码:
#ifndef EFFECTIVEAREA_H_
#define EFFECTIVEAREA_H_
/*define the content of EffectiveArea.h here!*/
#endif /* EFFECTIVEAREA_H_ */
注意,宏名字是全局有效的,因此我们必须保证它的唯一性,否则,在判断的时候,就会因为两个头文件之间的互相排斥(被认为是同一个文件),但事实上它们之间只是错误地定义了名字。为此我们可以用文件名的等价转换来包含它们,因为文件名是唯一的。(文件名包含它的路径,通常我们将头文件放入同一个文件夹下,因此我们可以保证在同级文件夹下的文件名的唯一性。)
这样我们就可以随心所欲地包含头文件了,而不必担心重复包含头文件所带来的坏处了。
9、对于函数签名声明返回值类型为int的可以省略(不推荐(引发警告))。
参看以下代码:
#include <stdio.h>
#include <stdlib.h>
/*We can omit the declaration of function here only when it's returnType is int.
* It only cause compile warning "implicit declaration of function 'nodeclare1Func'"
* Because the default function returnType is 'int'. */
/*But we suggest you explicit declare your function here.*/
/*int nodeclare1Func(int param1); */
/*We can not omit anything here!*/
char nodeclare2Func(void);
int main(void) {
nodeclare1Func(2009);
nodeclare2Func();
return EXIT_SUCCESS;
}
int nodeclare1Func(int param1) {
printf("nodeclare1Func.param1:%d\n", param1);
return EXIT_SUCCESS;
}
char nodeclare2Func(void) {
printf("nodeclare2Func.i:%d\n", 2010);
return 'c';
}作用域的内容并不难,掌握它们虽然不需要花费太多的时间(当然我还是比较推崇认真掌握了),但是我们应该从使用习惯上做到合理准确地应用这些特性。对于出现的一些错误能够给出合理的解释。
Shell排序算法是D.L.Shell于1959年发明的,其基本思想是:
下面的这段代码是Shell算法的C语言实现,其中shellsort为原函数,而traceShellsort则为跟踪输出的函数,这里我用了几个标准输出的语句,将数据交换的过程进行一个输出,以更好地理解排序的过程。
#include <stdio.h>
#include <stdlib.h>
#define ARRAY_LENGTH 9
void shellsort(int v[], int n);
void arrayPrintf(int v[], int n);
void traceShellsort(int v[], int n);
int traceOut(int n, int gap, int i, int j, int isnewline);
int traceCount;
int main(void) {
int arr[ARRAY_LENGTH] = { 12, 2, 20, 19, 28, 30, 12, 42, 35 };
printf("Original array:\t\t");
arrayPrintf(arr, ARRAY_LENGTH);
/*sort the array by shell arithmetic*/
//shellsort(arr, ARRAY_LENGTH);
traceShellsort(arr, ARRAY_LENGTH);
putchar('\n');
printf("MinToMax array:\t\t");
arrayPrintf(arr, ARRAY_LENGTH);
return EXIT_SUCCESS;
}
/*shellsort函数:按递增顺序对v[0]…v[n-1]进行排序*/
void shellsort(int v[], int n) {
int gap, i, j, temp;
for (gap = n / 2; gap > 0; gap /= 2)
for (i = gap; i < n; i++)
for (j = i - gap; j >= 0 && v[j] > v[j + gap]; j -= gap) {
temp = v[j];
v[j] = v[j + gap];
v[j + gap] = temp;
}
}
/*shell排序算法的跟踪版,相同的算法,它将输出带有跟踪过程的数据*/
void traceShellsort(int v[], int n) {
int gap, i, j, temp;
extern int traceCount;
traceCount = 1;
for (gap = n / 2; gap > 0; gap /= 2) {
for (i = gap; i < n; i++) {
for (j = i - gap; traceOut(n, gap, i, j, !(j >= 0 && v[j] > v[j
+ gap])) && j >= 0 && v[j] > v[j + gap]; j -= gap) {
temp = v[j];
v[j] = v[j + gap];
v[j + gap] = temp;
arrayPrintf(v, n);
}
}
}
}
/*用于跟踪交换过程*/
int traceOut(int n, int gap, int i, int j, int isnewline) {
printf("%2d. n=%d gap=%d i=%d j=%2d %c", traceCount++, n, gap, i, j,
isnewline ? '\n' : ' ');
return 1;
}
/*用于输出一组数组*/
void arrayPrintf(int v[], int n) {
int i;
for (i = 0; i < n; i++)
printf("%d ", v[i]);
putchar('\n');
}
下面的文字是运行上面一段代码后产生的结果,其中跟踪过程中出现的数组输出,表示该数组步骤中将会产生一次位置交换过程。
Original array: 12 2 20 19 28 30 12 42 35
1. n=9 gap=4 i=4 j=0
2. n=9 gap=4 i=5 j=1
3. n=9 gap=4 i=6 j=2 12 2 12 19 28 30 20 42 35
4. n=9 gap=4 i=6 j=-2
5. n=9 gap=4 i=7 j=3
6. n=9 gap=4 i=8 j=4
7. n=9 gap=2 i=2 j=0
8. n=9 gap=2 i=3 j=1
9. n=9 gap=2 i=4 j=2
10. n=9 gap=2 i=5 j=3
11. n=9 gap=2 i=6 j=4 12 2 12 19 20 30 28 42 35
12. n=9 gap=2 i=6 j=2
13. n=9 gap=2 i=7 j=5
14. n=9 gap=2 i=8 j=6
15. n=9 gap=1 i=1 j=0 2 12 12 19 20 30 28 42 35
16. n=9 gap=1 i=1 j=-1
17. n=9 gap=1 i=2 j=1
18. n=9 gap=1 i=3 j=2
19. n=9 gap=1 i=4 j=3
20. n=9 gap=1 i=5 j=4
21. n=9 gap=1 i=6 j=5 2 12 12 19 20 28 30 42 35
22. n=9 gap=1 i=6 j=4
23. n=9 gap=1 i=7 j=6
24. n=9 gap=1 i=8 j=7 2 12 12 19 20 28 30 35 42
25. n=9 gap=1 i=8 j=6
MinToMax array: 2 12 12 19 20 28 30 35 42
为了更好地查看当前值,我将每一次交换的值用下划线进行标出。
希尔排序(Shell sort)也称“缩小增量排序”。它的做法不是每次一个元素挨一个元素的比较。而是先将整个待排记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。这样大大减少了记录移动次数,提高了排序效率。
算法思路:先取一个正整数d1(d1<n),把全部记录分成d1个组,所有距离为dl的倍数的记录看成是一组,然后在各组内进行插入排序;接着取d2(d2<d1),重复上述分组和排序操作;直到di=1 (i>=1),即所有记录成为一个组为止。希尔排序对增量序列的选择没有严格规定,一般选d1约为n/2,d2为d1/2,d3为d2/2,…,di=1。
在C语言的函数定义上,我们通常都是用的函数定义方式为ANSI-C的函数定义方式。但是在C语言之父创立C语言之时,函数的定义形式并非现在我们所见到的形式。下面的代码显示了这样的差别,注意观察二者在声明与函数体签名上的差别。
#include <stdio.h>
#include <stdlib.h>
/*K&R Standard==============start===================*/
const char* originalFunc();
/*K&R Standard---------------end--------------------*/
/*ANSI Standard=============start===================*/
const char* ANSIFunc(char param1, char* param2);
/*You also can define the function like below.
* const char* ANSIFunc(char ,char*); */
/*ANSI Standard--------------end--------------------*/
int main() {
printf("const char* originalFunc(param1,param2):%s\n", originalFunc('a',
"word"));
printf("const char* ANSIFunc(param1,param2):%s\n", ANSIFunc('a', "word"));
return EXIT_SUCCESS;
}
/*K&R Standard==============start===================*/
const char* originalFunc(param1, param2)
char param1;char* param2; {
printf("param1:%c\nparam2:%s\n", param1, param2);
return "originalFunc";
}
/*K&R Standard---------------end--------------------*/
/*ANSI Standard=============start===================*/
const char* ANSIFunc(char param1, char* param2) {
printf("param1:%c\nparam2:%s\n", param1, param2);
return "ANSIFunc";
}
/*ANSI Standard--------------end--------------------*/
K&R的风格与ANSI-C的比,K&R风格又称为identifier-list,而另一种风格则又称为declarator,其中originalFunc(param1, param2) 即为这个declarator。事实上两种风格在ANSI 99 标准中(6.9.1节)都有定义,只不过我们更推崇declarator的方式。因为它将对参数进行强制类型转换,而标识符列表的方式则没有进行这项操作。
整理FROM:http://bbs.et8.net/bbs/showthread.php?p=9443319
在VisualStuduo 2008 中文版中,编译我试用VS2003所写的一个项目时,提示无法查找到头文件atlrx.h。
该项目中我使用了ATL的正则表达式类 CAtlRegExp,因此需要对应的头文件<atlrx.h>。
经过搜索发现,在VS2003中,该文件位于
\Program Files\Microsoft Visual Studio .NET 2003\Vc7\atlmfc\include
而2008的目录中确实不存在该文件。
通过2008的在线帮助,查找CAtlRegExp,发现仍然存在,而其附带的例子中仍然使用的是
#include <atlrx.h>
帮助页面:
http://msdn2.microsoft.com/zh-cn/lib...xe(VS.80).aspx
按道理2008应该同样支持该类,但又没有相应的头文件?
有没有别人碰到这个情况?如何处理啊?
如果这个项目无法在VS2008下编译,俺就没法迁移到2008下工作了,还得接着用VS2003(VS 2003我都卸载了,嗨!)
http://connect.microsoft.com/VisualS...dbackID=306398
atlrx.h is not part of VS2008 anymore. ATL Server is now an open source project. You can find more details at http://blogs.msdn.com/vcblog/archive...-software.aspx
按照解决方法中的办法,把VS2003中的头文件复制过来,解决了。(看来库中是有的,只是去掉了头文件)
atlrx.h中包含了模版类的声明和实现,没有额外的库。
下载:http://www.codeplex.com/AtlServer
http://blogs.msdn.com/vcblog/archive/2007/01/19/atl-server-visual-c-shared-source-software.aspx
C++
void CAPPTestApp::RegisterProtocol()
{
CRegKey reg;
reg.Create(HKEY_CLASSES_ROOT,_T("vip"));
reg.SetStringValue(_T(""), _T("URL:vip Protocol"));
reg.SetStringValue(_T("URL Protocol"), _T(""));
DWORD size = MAX_PATH;
CString strPath;
::GetModuleFileName(m_hInstance, strPath.GetBuffer(MAX_PATH), size);
strPath.ReleaseBuffer();
reg.Create(HKEY_CLASSES_ROOT,_T("vip\\DefaultIcon"));
reg.SetStringValue(_T(""), strPath);
strPath += _T(" %1");
reg.Create(HKEY_CLASSES_ROOT,_T("vip\\shell\\open\\command"));
reg.SetStringValue(_T(""), strPath);
::MessageBox(HWND_DESKTOP, _T("The vip protocol has been registered"), _T("APPTest"), MB_OK);
}
用以上代码可以注册形如下方的注册表项:
HKEY_CLASSES_ROOT
vip
(Default) = "URL:vip Protocol"
URL Protocol= ""
DefaultIcon
(Default) = "c:\somepath\APPTest.exe"
shell
open
command
(Default) = "c:\somepath\APPTest.exe" "%1"