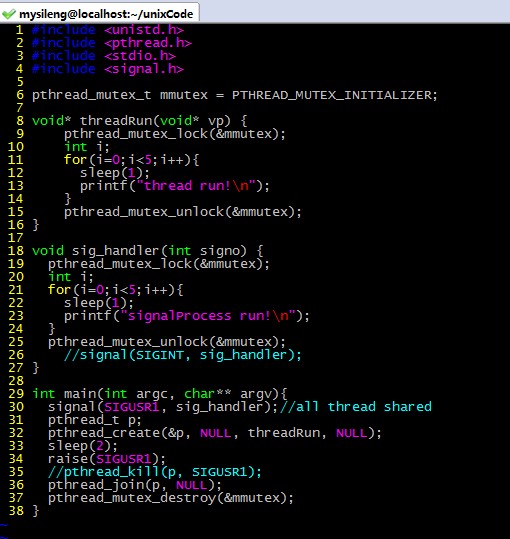
|
|
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; public class MyEclipseGen { private static final String LL = "Decompiling this copyrighted software is a violation of both your license agreement and the Digital Millenium Copyright Act of 1998 (http://www.loc.gov/copyright/legislation/dmca.pdf). Under section 1204 of the DMCA, penalties range up to a $500,000 fine or up to five years imprisonment for a first offense. Think about it; pay for a license, avoid prosecution, and feel better about yourself."; public String getSerial(String userId, String licenseNum) { java.util.Calendar cal = java.util.Calendar.getInstance(); cal.add(1, 3); cal.add(6, -1); java.text.NumberFormat nf = new java.text.DecimalFormat("000"); licenseNum = nf.format(Integer.valueOf(licenseNum)); String verTime = new StringBuilder("-").append( new java.text.SimpleDateFormat("yyMMdd").format(cal.getTime())) .append("0").toString(); String type = "YE3MP-"; String need = new StringBuilder(userId.substring(0, 1)).append(type) .append("300").append(licenseNum).append(verTime).toString(); String dx = new StringBuilder(need).append(LL).append(userId) .toString(); int suf = this.decode(dx); String code = new StringBuilder(need).append(String.valueOf(suf)) .toString(); return this.change(code); } private int decode(String s) { int i; char[] ac; int j; int k; i = 0; ac = s.toCharArray(); j = 0; k = ac.length; while (j < k) { i = (31 * i) + ac[j]; j++; } return Math.abs(i); } private String change(String s) { byte[] abyte0; char[] ac; int i; int k; int j; abyte0 = s.getBytes(); ac = new char[s.length()]; i = 0; k = abyte0.length; while (i < k) { j = abyte0[i]; if ((j >= 48) && (j <= 57)) { j = (((j - 48) + 5) % 10) + 48; } else if ((j >= 65) && (j <= 90)) { j = (((j - 65) + 13) % 26) + 65; } else if ((j >= 97) && (j <= 122)) { j = (((j - 97) + 13) % 26) + 97; } ac[i] = (char) j; i++; } return String.valueOf(ac); } public MyEclipseGen() { super(); } public static void main(String[] args) { try { System.out.println("please input register name:"); BufferedReader reader = new BufferedReader(new InputStreamReader( System.in)); String userId = null; userId = reader.readLine(); MyEclipseGen myeclipsegen = new MyEclipseGen(); String res = myeclipsegen.getSerial(userId, "5"); System.out.println("Serial:" + res); reader.readLine(); } catch (IOException ex) { } } }
在网上搜了一下,发现有很多人提供了解决的办法,但我一一试过,最终都不行。
解决方案列表如下:
1、[分享]Spring启动异常: cvc-elt.1: Cannot find the declaration of element 'beans'
2、spring从sun jdk到IBMjdk
这两篇文章中都提供了各自的解决方法,但为何在我的应用中就是不行了?
其实不是不行,而是需要根据Spring的版本不同,进行不同的处理,刚好我用的是Spring2.5,所以解决起来需要另一种方法,即配置文件XML的头部的声明应该为:
 <?xml version="1.0" encoding="UTF-8"?> <?xml version="1.0" encoding="UTF-8"?>
<!--
- Application context definition for JPetStore's business layer.
- Contains bean references to the transaction manager and to the DAOs in
- dataAccessContext-local/jta.xml (see web.xml's "contextConfigLocation").
-->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.0.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.0.xsd">
数组和指针概念很容易让初学者混淆,这里把我所知道的概括一下,希望对大家有所帮助。 一维数组和一级指针的相同和差异一维数组的名字大部分情况下可以当成一个常指针来看,也就是说: int a[3] int * const p; 则数组名a可以在大部分p能用的地方使用,有两种情况比较特殊: - p可以在定义是初始化一个地址如:int *p const = new int[100];,而且这也是唯一的初始化他的机会。而数组则是有操作系统载入可执行文件时初始化内存空间的。
- sizeof运算符对p计算将获得指针的长度(现在一般为4),而对数组名则得到数组占有的所有字节数。
在内存排布上,一维数组和一阶指针指向的内存是完全一样的。 高维数组和高阶指针对于高维数组(以二维为例,其他完全一样),情况和一维数组完全不一样。例如对于数组和指针: int a[3][4] int**p; 他们就没有任何可比性。初学者从一维数组中的知识简单的推断出a是一个等价于int**的东西,*a就可以得到一个 int*的值,这其实是完全错误的。 从内存排布上,数组按照先低维后高维的顺序一次排列数组的每个元素。其中低维到高维是指定义数组时,离数组名越近的维为低维,反之为高维,例如上面这个数组,3就是低维的维数,4为高维的维数,因此,在内存中,上面这个数组占有12个int单元,所有单元靠在一起,其顺序则为 a[0][0],a[0][1],a[0][2],a[0][3] a[1][0],a[1][1],a[1][2],a[1][3] a[2][0],a[2][1],a[2][2],a[2][3]
如果a是一个和二阶指针等价的常量,那么他的值应该指向一个指针数组才对,而实际上这样的指针数组是不存在。 从前面这个排布还可以看出一个问题,在排列过程中,数组的最低维不确定是没有关系的,但是为了安排好数组元素的先后顺序,高维的维数必须确定,也就是说在使用数组类型来定义指针时,必须首先确定高维,例如: int (*p)[3] = new int[4][3] 是可以的,但是 int (*p)[] = new int[4][3] 就不行。 回到一维数组仔细考虑一维数组和多维数组,是不是编译器对一维数组特殊处理了?其实也不是,数组名其实代表的是数组对象也就是其第一个元素的地址,从这个角度讲,一维数组名a代表了a[0]的地址,二维数组名a代表了a[0][0]的地址,高维数组的名字从这个意义讲更接近1阶指针.
今天写程序的时候要用到二维数组作参数传给一个函数,我发现将二维数组作参数进行传递还不是想象得那么简单,但是最后我也解决了遇到的问题,所以这篇文章主要介绍如何处理二维数组当作参数传递的情况,希望大家不至于再在这上面浪费时间。 下文是我从互联网上download的一篇文章,讲的很好,但是我后面将指出问题所在,并加以改进,希望对你有所帮助:
首先,我引用了谭浩强先生编著的《C程序设计》上面的一节原文,它简要介绍了如何将二维数组作为参数传递,原文如下(略有改变,请原谅): [原文开始] 可以用二维数组名作为实参或者形参,在被调用函数中对形参数组定义时可以指定所有维数的大小,也可以省略第一维的大小说明,如: void Func(int array[3][10]); void Func(int array[][10]); 二者都是合法而且等价,但是不能把第二维或者更高维的大小省略,如下面的定义是不合法的: void Func(int array[][]); 因为从实参传递来的是数组的起始地址,在内存中按数组排列规则存放(按行存放),而并不区分行和列,如果在形参中不说明列数,则系统无法决定应为多少行多少列,不能只指定一维而不指定第二维,下面写法是错误的: void Func(int array[3][]);实参数组维数可以大于形参数组,例如实参数组定义为: void Func(int array[3][10]); 而形参数组定义为: int array[5][10]; 这时形参数组只取实参数组的一部分,其余部分不起作用。 [原文结束] 大家可以看到,将二维数组当作参数的时候,必须指明所有维数大小或者省略第一维的,但是不能省略第二维或者更高维的大小,这是由编译器原理限制的。大家在学编译原理这么课程的时候知道编译器是这样处理数组的: 对于数组 int p[m][n]; 如果要取p[i][j]的值(i>=0 && i<m && 0<=j && j < n),编译器是这样寻址的,它的地址为: p + i*n + j; 从以上可以看出,如果我们省略了第二维或者更高维的大小,编译器将不知道如何正确的寻址。但是我们在编写程序的时候却需要用到各个维数都不固定的二维数组作为参数,这就难办了,编译器不能识别阿,怎么办呢?不要着急,编译器虽然不能识别,但是我们完全可以不把它当作一个二维数组,而是把它当作一个普通的指针,再另外加上两个参数指明各个维数,然后我们为二维数组手工寻址,这样就达到了将二维数组作为函数的参数传递的目的,根据这个思想,我们可以把维数固定的参数变为维数随即的参数,例如: void Func(int array[3][10]); void Func(int array[][10]); 变为: void Func(int **array, int m, int n); 在转变后的函数中,array[i][j]这样的式子是不对的(不信,大家可以试一下),因为编译器不能正确的为它寻址,所以我们需要模仿编译器的行为把array[i][j]这样的式子手工转变为: *((int*)array + n*i + j); 在调用这样的函数的时候,需要注意一下,如下面的例子: int a[3][3] = { {1, 1, 1}, {2, 2, 2}, {3, 3, 3} }; Func(a, 3, 3);
根据不同编译器不同的设置,可能出现warning 或者error,可以进行强制转换如下调用: Func((int**)a, 3, 3); 其实多维数组和二维数组原理是一样的,大家可以自己扩充的多维数组,这里不再赘述。写到这里,我先向看了这篇文章后悔的人道歉,浪费你的时间了。下面是一个完整的例子程序,这个例子程序的主要功能是求一个图中某个顶点到其他顶点的最短路经,图是以邻接矩阵的形式存放的(也就是一个二维数组),其实这个函数也是挺有用的,但是我们这篇文章的重点在于将二维数组作为函数的参数传递。 上文结束,上文最后指出了实现二位数组作为函数参数的方法,但是它实现的是将静态的二位数组作为参数,但是如何将动态而为数组作为参数呢?上面的方法显然是不合适的,下面是我琢磨出来的方法。 先将静态数组作为参数的代码贴出来: #include <iostream>
using namespace std;
void Calc(int **A, int m, int n);
int _tmain(int argc, _TCHAR* argv[])
{
int row = 0;
int col = 0;
int i = 0;
int A[3][3];
for (row = 0; row < 3; row++)
{
for (col = 0; col < 3; col++)
{
A[row][col] = row + col;
}
}
Calc((int **)A, 3, 3);
return 0;
}
void Calc(int **A, int m, int n)
{
if (NULL == A || m <1 || n < 1)
{
return;
}
int row = 0;
int col = 0;
int i = 0;
int j = 0;
int **matrix = NULL;
matrix = new int*[m];
if (NULL == matrix)
{
return;
}
for (row = 0; row < m; row++)
{
matrix[row] = new int[n];
if (NULL == matrix[row])
{
for (i = 0; i < row; i++)
{
delete []matrix[i];
matrix[i] = NULL;
}
delete []matrix;
matrix = NULL;
return;
}
}
for (row = 0; row < m; row++)
{
for (col = 0; col < n; col++)
{
matrix[row][col] = *((int *)A + row * n + col);
//matrix[row][col] = A[row][col];
}
}
for (row = 0; row < m; row++)
{
for (col = 0; col < n; col++)
{
cout<<matrix[row][col]<<" ";
}
cout<<"\n";
}
} 下面是动态二位数组作为函数参数时的代码: #include <iostream>
using namespace std;
void Calc(int **A, int m, int n);
int main(int argc, char* argv[])
{
int row = 0;
int col = 0;
int i = 0;
int **A = NULL;
A = new int*[3];
if (NULL == A)
{
return 0;
}
for (row = 0; row < 3; row++)
{
A[row] = new int[3];
if (NULL == A[row])
{
for (i = 0; i < row; i++)
{
delete []A[i];
A[i] = NULL;
}
delete []A;
A = NULL;
return 0;
}
}
for (row = 0; row < 3; row++)
{
for (col = 0; col < 3; col++)
{
A[row][col] = row + col;
}
}
Calc((int **)A, 3, 3);
return 0;
}
void Calc(int **A, int m, int n)
{
if (NULL == A || m <1 || n < 1)
{
return;
}
int row = 0;
int col = 0;
int i = 0;
int j = 0;
int **matrix = NULL;
matrix = new int*[m];
if (NULL == matrix)
{
return;
}
for (row = 0; row < m; row++)
{
matrix[row] = new int[n];
if (NULL == matrix[row])
{
for (i = 0; i < row; i++)
{
delete []matrix[i];
matrix[i] = NULL;
}
delete []matrix;
matrix = NULL;
return;
}
}
for (row = 0; row < m; row++)
{
for (col = 0; col < n; col++)
{
//matrix[row][col] = *((int *)A + row * n + col);
matrix[row][col] = A[row][col];
}
}
for (row = 0; row < m; row++)
{
for (col = 0; col < n; col++)
{
cout<<matrix[row][col]<<" ";
}
cout<<"\n";
}
}
注意上面的代码的不同之处,即将动态二维数组作为函数参数时,在函数里面应用时候要将其伪装成静态二维数组! 这样,以上的两段代码不仅实现了堆和栈之间数据的传递,而且实现了堆和堆之间数据的传递!
根据设定的晶振,怎么样确定asm("nop");延时了多少时间?比如7.3728MHz下,一个asm("nop");代表多少时间呢?
指令周期是执行一条指令所需要的时间,一般由若干个机器周期组成,是从取指令、分析取数到执行完所需的全部时间。指令不同,所需的机器周期数也不同。对于一些简单的的单字节指令,在取指令周期中,指令取出到指令寄存器后,立即译码执行,不再需要其它的机器周期。对于一些比较复杂的指令,例如转移指令、乘法指令,则需要两个或者两个以上的机器周期。通常含一个机器周期的指令称为单周期指令,包含两个机器周期的指令称为双周期指令。
机器周期:通常用内存中读取一个指令字的最短时间来规定CPU周期,(也就是 计算机通过内部或外部总线进行一次信息传输从而完成一个或几个微操作所需要的时间它一般由12个时钟周期组成。而时钟周期=1秒/晶振频率,因此单片机的机器周期=12秒/晶振频率
指令周期=若干个机器周期=12个时钟周期12秒/晶振频率 (51系列)
摘要: Hibernate 一对多外键双向关联 一、模型介绍 一个人(Person)对应多个地址(Address)。 二、实体(省略getter、setter方法) public class Person1nfk_sx implements Serializable { private int personid... 阅读全文
若Eclipse 报 “Exception in thread "main" java.lang.OutOfMemoryError: Java heap space ”错误,我们可以通过一下方法进行处理:首先, 打开Eclipse软件,选择菜单栏run,在二级菜单中选择 Debug Configurations,然后:在弹出的窗口中选择(x)=arguments选项卡,VM arguments中输入所需要的内存最大占用量,比如输入-Xmx800m即可。
好啦,从这里开始我们就开始学习linux的一些常用命令。首先进入centos-》应用程序-》附件-》终端,开始命令行之旅。
一、文件处理命令
1.网络信息查看命令:ifconfig 英文原型:intface config(附加的。。。可以无视)
2.文件处理命令:ls 英文原型:list 命令所在路径:/bin/ls 执行权限:所有用户
功能表述:显示文件目录 常用可选项:-a -l -i(a表示all即显示所有文件目录,l表示long即显示详细文件属性,i显示文件的inode)
注:当键入ls -l时候,会输出类似如下图所示信息

第1个字母表示的文件类型(d表示目录,-表示2进制文件,l表示软链接文件)
第2-4字母表示的是文件拥有者的权限(r表示read,w表示write,x表示execute)
第5-7和第8-10字符分别表示文件所属组的权限与其他用户的权限
第11个数字表示此文件的硬链接数
第12个单词表示文件拥有者是谁?
第13个单词表示文件所属组是谁?
接下来的数字是文件的大小(字节单位)和文件最后修改的时间
3.文件处理命令:cd 英文原型:change directory 命令所在路径:shell内置命令 执行权限:所有用户
功能表述:切换目录
注:.表示当前目录,..表示上级目录,/表示根目录
4.文件处理命令:pwd 英文原型:print working directory 命令所在路径:/bin/pwd 执行权限:所有用户
功能表述:显示当前所在的工作目录
5.文件处理命令:mkdir 英文原型:make directory 命令所在路径:/bin/mkdir 执行权限:所有用户
功能表述:创建目录
6.文件处理命令:touch 命令所在路径:/bin/touch 执行权限:所有用户
功能表述:创建文件
7.文件处理命令:cp 英文原型:copy 命令所在路径:/bin/cp 执行权限:所有用户
功能表述:复制文件或目录 常用可选项:-R -p(-R表示复制目录,p表示复制时不改变时间)
注:cp 源文件 目的文件
8.文件处理命令:mv 英文原型:move 命令所在路径:/bin/mv 执行权限:所有用户
功能表述:剪切文件或改名
9.文件处理命令:rm 英文原型:remove 命令所在路径:/bin/rm 执行权限:所有用户
功能表述:删除文件或目录 常用可选项:-r -f(r表示删除目录,f表示force即强制删除无须任何询问)
10.文件处理命令:cat 英文原型:concatenate and display file 命令所在路径:/bin/cat 执行权限:所有用户
功能表述:显示文件内容(适合较短文件)
11.文件处理命令:more 命令所在路径:/bin/more 执行权限:所有用户
功能表述:分页显示文件内容
注:进入分页显示状态后,空格表示下一页,回车表示下一行,q表示退出分页显示模式
12.文件处理命令:head 命令所在路径:/bin/head 执行权限:所有用户
功能表述:显示文件头几行 常用可选项:-number(此处数字表示需要显示的文件头几行的数字)
13.文件处理命令:tail 命令所在路径:/bin/tail 执行权限:所有用户
功能表述:显示文件后几行 常用可选项:-number -f(此处数字表示需要显示的文件后几行的数字,f表示动态显示)
注:对于一些日志,实时在更新,那么通常使用-f选项来关注日志不断更新的末尾.
14.文件处理命令:ln 英文原型:link 命令所在路径:/bin/ln 执行权限:所有用户
功能表述:创建链接 常用可选项:-s(s表示soft即创建的链接是软链接)
现在看下图,来演示创建软链接
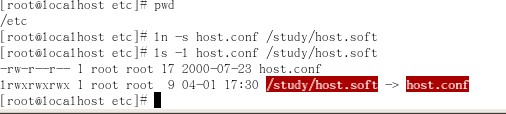
上图中首先用ln -s创建一个软链接host.soft,而这个软件链接指向了/etc/host.conf文件。其实所谓的软链接在windows里面就当于快捷方式而已。可以看见软链接的类型是l类型,而软链接的权限基本上全是满的,后面还用箭头表示了软链接指向那个文件。
如果没有用-s则创建硬链接,应注意硬链接是windows里面没有的功能,硬链接相当于一个可以可以动态更新的副本。而且当原文件删除后,软连接就无用了,硬链接却还有用。看如下指令:
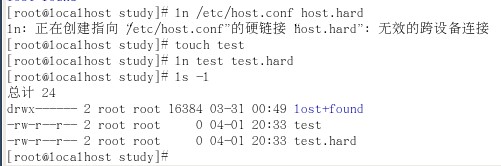
首先我试图创建一个硬链接由/study/host.hard指向/etc/host.conf,但是失败了。原因是/study和/根分区不是一个物理分区,在我装系统的时候,把根分区和/study分成了sda0和sda1两个物理分区。所以结论是硬链接只能在同一个物理分区上进行。然后我建立了一个test文件,并创建了一个硬链接指向它,可以看见权限和内容是完全一样的。
那以上是为什么呢?链接的底层到底是怎么实现的呢?
由于linux下的文件是通过索引节点号(Inode)来唯一标示文件,硬链接可以认为并不是一个新文件而只是一个指针,指向原文件索引节点的指针,系统并不为它重新分配inode。每添加一个一个硬链接,原文件的链接数就加1。而软链接却是一个新的文件,所以有不同的inode,只不过它的文件内容是原文件的路径。
二、权限管理命令:
1.权限管理命令:chmod 英文原型:change the permission mode 命令所在路径:/bin/chmod 执行权限:所有用户
功能表述:更改文件或目录权限
注:chmod有两种格式,第一种是字母格式,chmod u/g/o +/-/= r/w/x 文件名/目录名(u代表user即文件所有者,g代表gourp即文件所属组,o代表other即其他用户,+-=分别表示添加、删除、赋予权限的操作,rwx代表权限).第二种格式是数字格式,chmod xyz(xyz分别是三个0-7的数字,每个0-7的数字其实是3个二进制的换算,3个二进制分别表示rwx,也就是说r是4、w是2、x是1。而x代表文件所有者得权限数字,y代表所属组权限数字,z是其他用户的权限数字.比如某文件的权限是rwxr-xr-x 换成数字形式就是 755).接下来看下面一个实验:
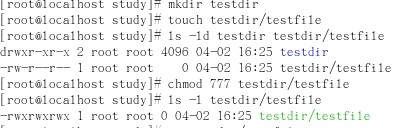

上面代码中创建了一个目录,后又在目录创建了一个文件并给予满权限,但当我用一个普通用户去删除这个文件时候却为什么说权限不够呢?可是权限上说other的权限是rwx丫。原因其实在于我们对rwx的理解,其实rwx对于文件和目录是不同的。总结如下:
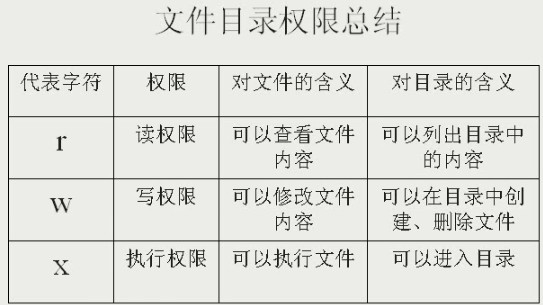
文件的r(cat、more、head、tail)、w(echo、vi)、x(命令、脚本)
目录的r(ls)、w(touch、rm、mkdir)、x(cd)
2.权限管理命令:chown 英文原型:change file ownership 命令所在路径:/bin/chown 执行权限:所有用户
功能表述:改变文件或目录所有者
注:chown 用户 文件
3.权限管理命令:chgrp 英文原型:change file group 命令所在路径:/bin/chgrp 执行权限:所有用户
功能表述:改变文件或目录所属组
注:chgrp 所属组 文件
4.权限管理命令:umask 命令所在路径:/bin/umask 执行权限:所有用户
功能表述:显示和设置文件的缺省权限 常用可选项:-S(S表示以rwx的方式显示缺省权限)
注:umask有两种使用方式,演示如下:

第一种是rws的方式显示出缺省权限,而第二种方式是显示的0002,这是什么意思呢?第一个数字0是表示一种特殊权限位,而后面的三个数字就是分别表示ugo的缺省权限,可是为什么不是775呢?显然775+002=777,所以我们可以看出002其实是缺省缺陷的掩码。哇哈哈~
三、文件搜索命令:
1.文件搜索命令:which 命令所在路径:/user/bin/which 执行权限:所有用户
功能表述:显示系统命令所在目录
2.文件搜索命令:find 命令所在路径:/user/bin/which 执行权限:所有用户
功能表述:查找文件或目录
注:find的命令较为复杂,大致格式为find 目标目录 搜索选项 搜索条件。常用的搜索选项有4种:
(1)-name 以文件或目录的名称来搜索,常用*,?等通配符连用
(2)-size 以文件或者目录大小来搜索,用+(大于)、-(小于)某一个数字来搜索。单位是512字节(block),100M=204800
(3)-user 以文件的拥有者来搜索
(4)以时间的搜索方式,常用-ctime、-atime、-mtime、-cmin、-amin、-mmin,其中time表示天,min表示分钟,c表示change指代文件或目录的属性被修改过,a表示access指代文件或目录被访问过,m表示modify指代文件或目录的内容被修改过。另外用-表示在某段时间之内,+表示某段时间之外。举例如下:
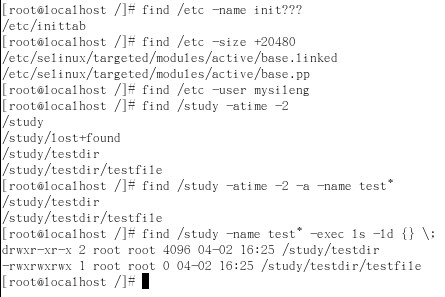
以上程序段在列举了上面4种方式外,还加入了两种连接符。第一种是逻辑连接符,-a表示and即逻辑与,-o表示or即逻辑或.第二种是执行连接符,当你用find查询到一个元素集合时,你可以通过-exec来对集合中的元素进行操作,要特别注意格式:-exec 操作命令 {}\另外可以用ok来代替exec,两者之间功能相似,不同的在于exec是直接执行,而ok会先询问再执行。
3.文件搜索命令:locate 命令所在路径:/user/bin/locate 执行权限:所有用户
功能表述:寻找文件或者目录
注:此命令功能类似于find,但查找方式不同。find是在硬盘中查找,而locate是在文件目录的数据库查找,速度与效率比find快很多。但有一个缺点就是,如果你需要查找的文件在目录数据库中没有记录的话就查找不到,所以常配合更新目录数据库的updatedb使用。

从上面程序段可以看出,我新创建的test.file文件刚开始用locate查找不到,而用find却可以查到。但当我更新过目录文件数据库后,再用locate就可以查询到了。
4. 文件搜索命令:grep 命令所在路径:/bin/locate 执行权限:所有用户
功能表述:在指定文件中搜索指定的字符串行并输出
注:举例如下,在services文件中查找含tftp字符串的行,并输出

四、帮助命令:
1.帮助命令:man 英文原型:manual 命令所在路径:/usr/bin/man 执行权限:所有用户
功能表述:获取帮组信息
注:man后面可以接命令,同时也可以接配置文件。如果命令和配置文件同名,默认是命令帮组(man 1 commad),你可以man 5 配置file
2.帮助命令:whatis 执行权限:所有用户
功能表述:获取简短帮助信息
注:whatis也是从某帮助信息的数据库中查询帮助,所以常用makewhatis来更新相关数据库。
3.帮助命令:help 执行权限:所有用户
功能表述:查看shell内置命令的帮助,man是误差查询shell内置命令的帮助的。当你用man查询的时候如果查不到你所需要的东西。也许用help你会有意外的收获,哇呵呵。
五、压缩命令:
1.压缩命令:gzip 命令所在路径:/bin/gzip 执行权限:所有用户
功能表述:压缩文件(只能是文件,不能是目录)
注:gzip压缩文件会丢失原文件。gzip -d 文件,是解压缩
2.压缩命令:gunzip 命令所在路径:/bin/gunzip 执行权限:所有用户
功能表述:解压gizp文件
3.压缩命令:tar 命令所在路径:/bin/tar 执行权限:所有用户
功能表述:把文件或目录打包成一个二进制文件 常用可选项:-cxvfz(c代表create即创建,x代表execute即解包,v代表view即查看打包或解包过程,f与c连用表示打包后的文件名称,f与x连用表示解包的目标名称,z与c连用表示打包后压缩,z与x连用表示解包后解压)
注:f必须放在可选项的最后,源文件在前,目标文件在后。下面演示该命令:

4.压缩命令:zip 命令所在路径:/usr/bin/zip 执行权限:所有用户
功能表述:以zip的形式压缩文件或目录 常用可选项:-r(r表示压缩目录)
注:zip格式是与window之间无需转换而可通用的压缩格式,用来压缩一些不大且共享与双系统间的文件很好。
5.压缩命令:unzip 命令所在路径:/usr/bin/unzip 执行权限:所有用户
功能表述:以zip的形式解压文件或目录
6.压缩命令:bzip2 命令所在路径:/usr/bin/bzip2 执行权限:所有用户
功能表述:以bzip2的形式压缩文件(是gzip的升级版) 常用可选项:-k(压缩后保留原文件)
六、网络通信命令:
1.网络通信命令:write 命令所在路径:/usr/bin/write 执行权限:所有用户
功能表述:向另外一个用户实时发送消息,并以CTRL+d结束
注:格式是write 用户
2.网络通信命令:wall 命令所在路径:/usr/bin/wall 执行权限:所有用户
功能表述:向所有用户广播消息
3.网络通信命令:ping 命令所在路径:/usr/sbin/ping 执行权限:所有用户
功能表述:发送icmp报文 常用可选项:-cs(c代表count即控制报文数目,s代表报文大小)
七、系统命令:
1.系统命令:shutdown 命令所在路径:/usr/sbin/shutdown 执行权限:所有用户
功能表述:关机 常用可选项:-h(h代表hour即多少小时以后关机)
2.系统命令:reboot 命令所在路径:/usr/sbin/reboot 执行权限:所有用户
功能表述:重启
八、Shell命令:
shell是一整命令行解释程序,一个linux操作系统可以有多个shell,我们可以查看:
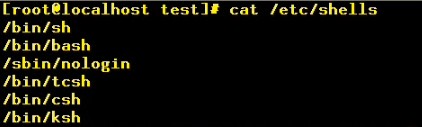
操作系统默认的一般是bash,我也是用bash。在shell中,你可用tab键自动补全。
1.Shell命令:alias
功能表述:别名机制,alias 别名="命令 -选项"(若没有选项可不用引号)
注:unalias 别名,可以解除别名
2.Shell命令:alias
功能表述:别名机制,alias 别名="命令 -选项"(若没有选项可不用引号)
注:unalias 别名,可以解除别名
3.Shell命令:> >> < 2>
功能表述:输出、附加输出、输入、错误输出
注:进程的文件描述字是 输出为0,输入为1,错误输出为2

4.Shell命令: | (管道)
功能表述:把前一个命令的输出结果作为下一个命令的输入参数。

第一个把ls命令的查询结果用more命令来读取,后面类似。
5.Shell命令: ; && || (命令连接符)
功能表述:如下

6.Shell命令: ``(命令替换符号)
功能表述:如下

今天从头开始学习linux,表示我本来就不会,呵呵。我的所有笔记都是从lamp兄弟连的视频里整理出来的(不做广告,但那视频确实还可以),记录下来给自己以后用。首先从linux的安装开始讲解,哇哈哈哈!~~~~~下面按步骤开始:
1.进行前期准备工作,我们需要下载两个东西。ps:我装linux是基于虚拟机,那样比较适合菜鸟。第一个要下载的东西就是虚拟机vmware,你可以到http://www.vmware.com/的官方网站去下载最新的版本,这次我下载的是VMware-workstation-7.1.3版(貌似用workstation比较好,比较强大).第二个要下载的东西就是操作系统了,我选用的是centos,一个红帽系列的linux,你可以到http://www.centos.org/去下载,这次我下载的是CentOS-5.5-i386-bin-DVD版本(注意别下成源码了,要下的是镜像文件).
2.准备好以后开始安装vmware了,双击安装程序
出现上图,然后一直下一步,记得选典型安装,方便一点。
3.安装好wmware后,开始在wmware里面配置安装centos.先进入wmmare,出现下图界面:
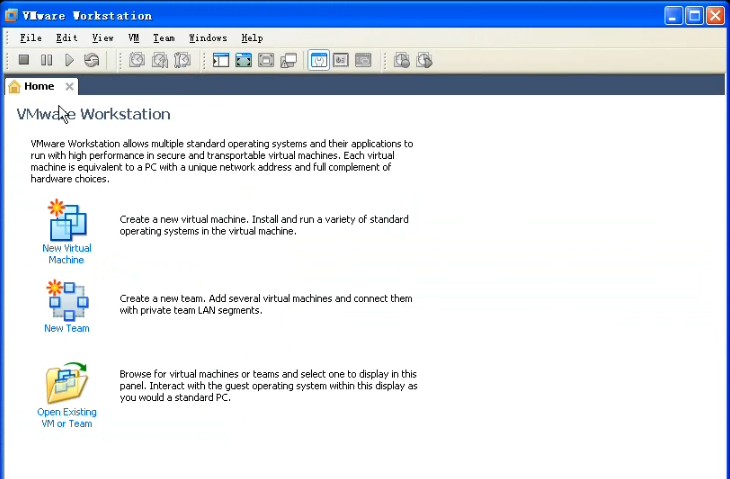
点击中间那个new virtual machine,开始创建一个新的虚拟机,选择典型以后,会出现下图:
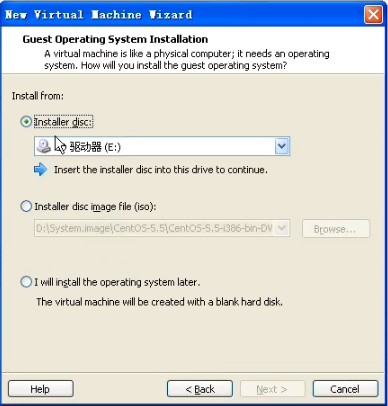
这里是要你选择这个虚拟机操作系统的安装程序在哪里,默认是选择的光驱。但我们已经下了镜像文件,所以点击第二个installer disc image file,然后从browse里面选择我们刚才下载的centos镜像文件即可。继续下一步:
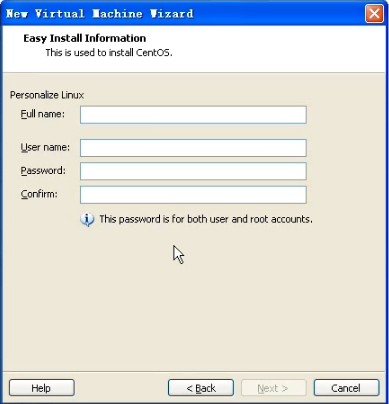
第一个fullname是你这个操作系统在虚拟机叫什么名字,下面那个貌似一个用户的注册,暂时不知道神马用。。请大家告诉我。继续点击下一步,出现一个20G的东西,这个事给虚拟机的这个操作系统分配硬盘,不要看20G这么大,这只是一个上限,一般操作系统用不了20G的,哇呵呵。点击下一步:
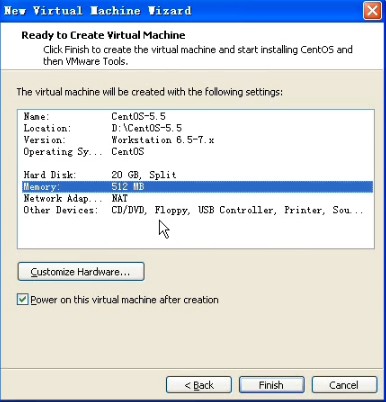
这里列出来的是操作系统硬件的一些配置(不是真正的硬件,你虚拟机虚拟出来的配置),点击customize hardware可以修改里面的参数,一般无视就好,哇呵呵~~再点击finish,wmware就算配置好了,到此搞一段落,接下来是虚拟机就会重启开始进入centos的安装界面,如果你没有重启的话,你就手动点一下power on的按钮来开机。
4.接下来就是安装centos了,重启以后会进入如下界面:
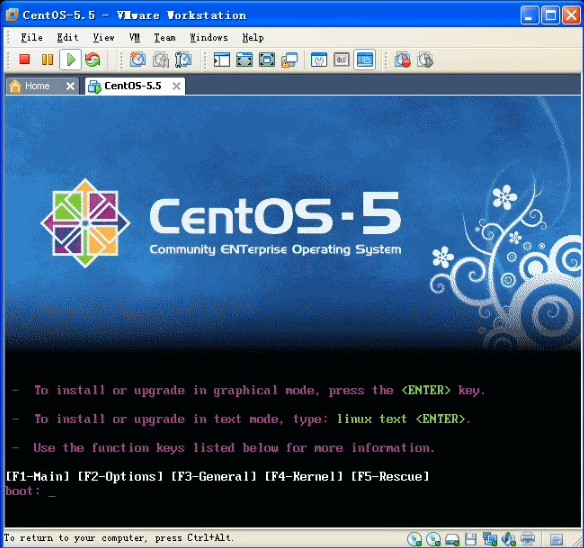
上面已经写的很清楚了,如果你要用图形界面的方式安装的的话,请按回车键,这时候我们应该毫不犹豫的按一下回车键,淡然你如果犹豫一下也没关系,哇哈哈~~~进入安装以后,首先要你选择安装过程中的语言,果断选中文不。。。然后会选择键盘,应该是选美国英语式,然后下一步(这个时候可能会弹出一个窗口,说要格式化分区才能装,你点是就是了。放心,他只会把虚拟机分配给操作系统的那部分硬盘格式化,不会影响你现在的系统)。然后继续下一步: 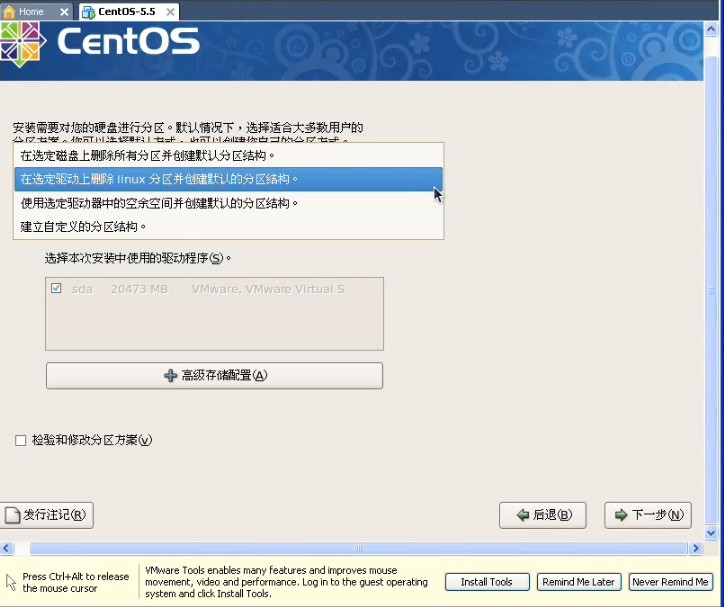 这里的话要稍微慢点,这里是选择分区,我反正是选了自定义分区结构,其他的选了有什么后果我表示不知道!。。。这里出现了一个sda的字样,稍微解释一下,sd表示sata类型的硬盘,sda又表示检测到的第一块sd型的硬盘所以就叫sda,如果你有多块的话,就会叫sdb\sdc等。。然后下一步: 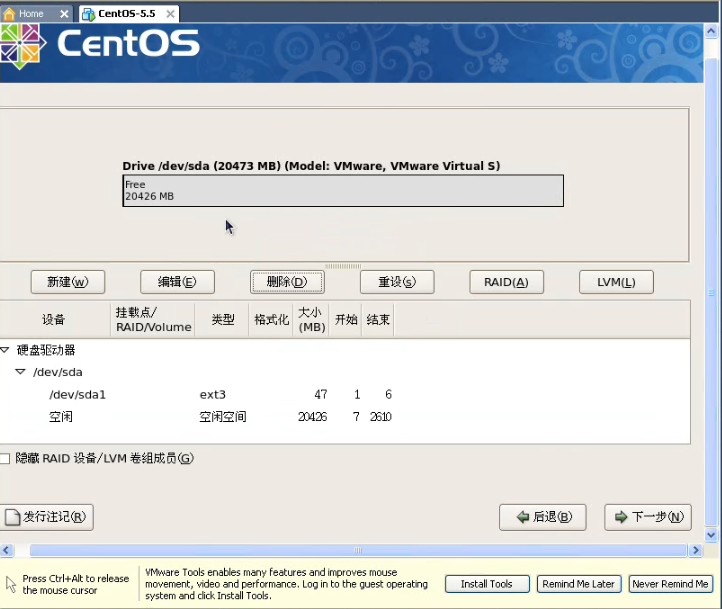 这里就是给刚才的20G硬盘分配空间了。这里需要说一下,linux的文件系统和windows的文件系统是完全不同的,linux没有所谓的盘符的概念(即没有C盘、d盘),换之是完全的一个倒树结构,就是一个根目录,然后所有的文件链接在上面,但是并不是想象的这么简单。以后的笔记中,我会慢慢的帮大家深入浅出linux的文件管理,这里就不说了。首先我点新建的按钮,出现下图: 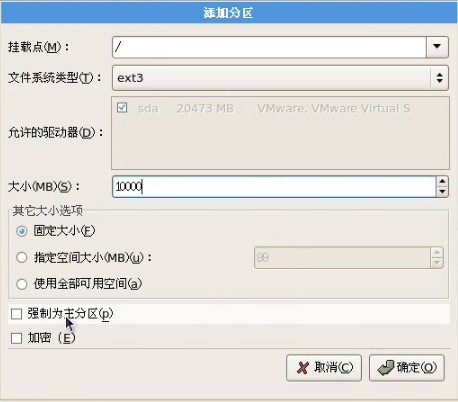 挂载点我们就暂时理解为目录吧,整个分配空间的过程中,我们必须分配两个类型的空间。第一个就是根目录,也就是上图中表示的/(左斜杠),空间类型选ext3就可以了,大小稍微要大一点,因为操作系统的所有文件是会默认放在根目录下面的,如果不够大就game over了。然后第二个必须分配的空间是swap空间,你新建一个目录,挂载点不用选直接在文件系统类型哪里选择swap就可以了,大小的话,官方建议是内存的两倍。话说学过操作系统的孩子们都知道,swap目录就是虚拟内存机制在硬盘上开创的假内存而已,哇呵呵呵~~~分这两个必须分配的空间以后,如果还有剩下的,你可以任意分配了。。。分完就点下一步,然后是说用grub引导程序来引导操作系统,不用管默认即可,下一步: 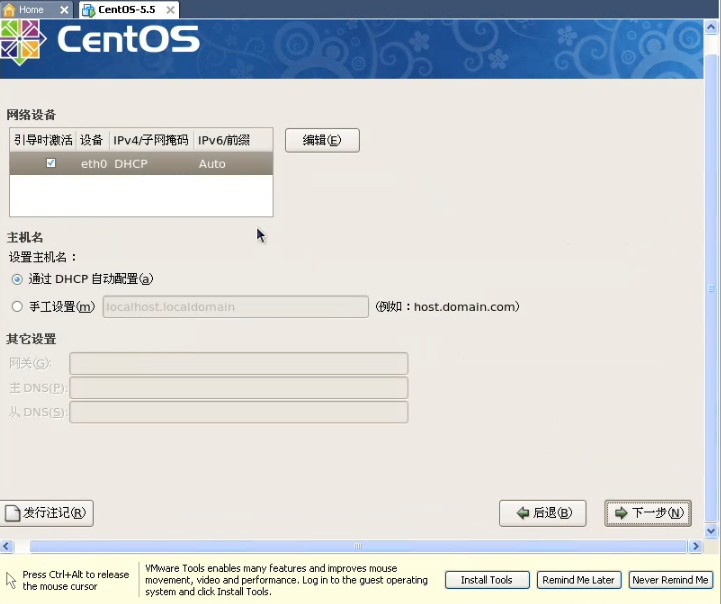 这里非常重要,这里是配置上网的相关信息,因为每个人的情况有所不同,我家的话,是通过单位的局域网接入网络的,然后我家又买了一个无线路由器,所以我家又是一个小局域网,so我选择dhcp的自动配置。如果大家用的是固定IP的话,就自己改一下吧。。下一步,要设置一个密码,这个密码是操作系统的root用户的密码,话说这个root在你这个操作系统里面可是最大的噢,还是设计一个比较高级的密码吧,不然被别人破了。就准备哭把~~~下一步: 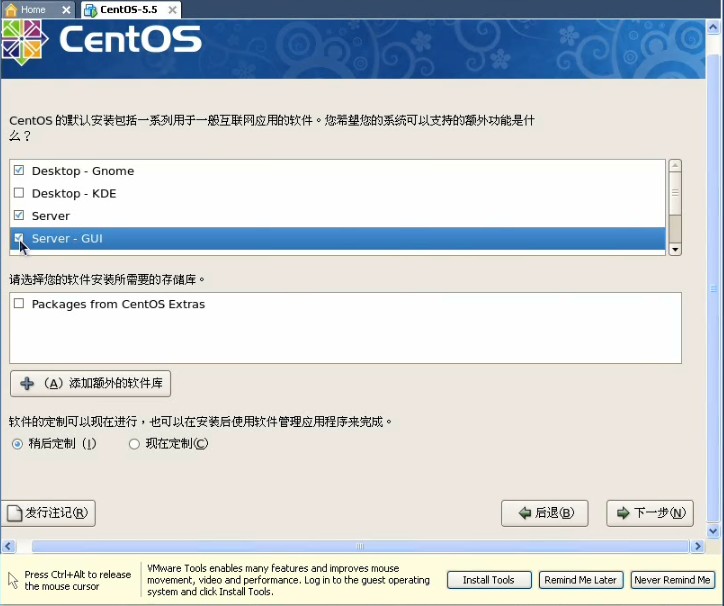 这里是来选择安装一些linux自带的软件,其中上面的框框里面前两个是图形化界面,哈哈一次可以安装2个图像化界面,相当犀利吧,windows可是做不到噢。大家按照自己的意愿选吧,没什么必须的。。下一步。。。貌似没有下一步了。。就又重启真的开始装了。这里注意下,重启以后最好先把操作系统关机,把刚刚之前设置的镜像文件路径改掉,不然重启就又会进入镜像文件中去,而不是进入操作系统。 5.重启进入操作系统之后,首先要配置一些操作系统的东西,比如时间。防火墙之类的。就不说了,然后输入root和你刚刚设置的密码进入下图: 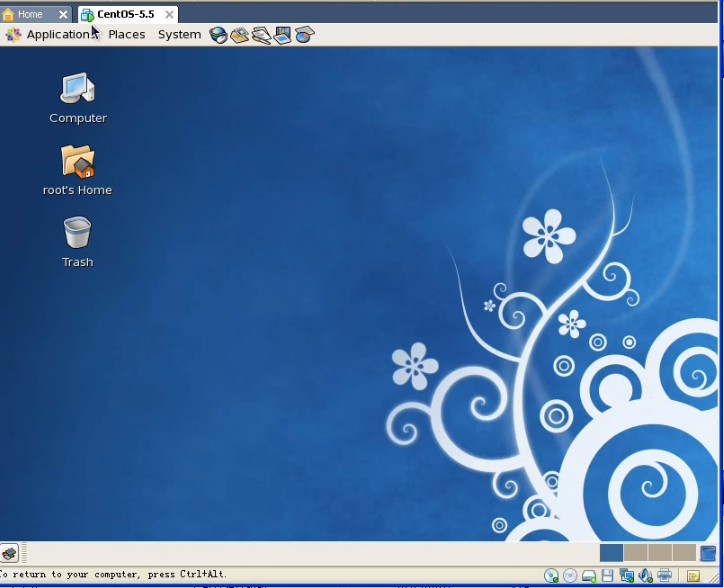 能够到达这里,说明你的linux已经完全装好了。。。。哇哈哈~恭喜恭喜,红包拿来~~~~
学JAVA有3年了吧,全部放弃楼,读研究生准备搞嵌入式了。从头开始,欢迎大家对我进行教育,特此开播记录转变过程。哇呵呵~~
|