我的IOCP网络模块设计
为了设计一个稳定易用高效的iocp网络模块,我前前后后花了好几个月的时间,也曾阅读过网上很多资料和代码,但是非常遗憾,能找到的资料一般都说得很含糊,很少有具体的,能找到的代码离真正能商用的网络模块差得太远,大多只是演示一下最基本的功能,而且大多是有很多问题的,主要问题如下:
1、 很多代码没有处理一次仅发送成功部分数据的情况。
2、 几乎没有找到能正确管理所有资源的代码。
3、 大多没有采用用pool,有的甚至画蛇添足用什么map查找对应客户端,没有充分使用perhandle, perio。
4、 接收发送数据大多拷贝太多次数。
5、 接收管理大多很低效,没有充分发挥iocp能力。
6、 几乎都没有涉及上层如何处理逻辑,也没有提供相应解决方案(如合并io线程处理或单独逻辑线程)。
7、 大多没有分离流数据和包数据。
…
问题还有很多,就不一一列出来了,有一定设计经验的人应该有同感。要真正解决这些问题也不是那么容易的,特别是在win下用iocp的时候资源释放是个麻烦的问题,我在资源管理上花了很多时间,起初也犯了很多错误,后来在减少同步对象上又花了不少时间(起初client用了两个同步对象,后来减少为1个)。下面我就我所设计的网络模块的各个部分进行简单的讲解
一、内存管理。
内存管理是采用池模式,设计了一个基础池类,可以管理某固定大小的池
class CBufferPool
{
…
void *newobj();
void delobj(void *pbuf);
…
};
在基础池类上提供了一个模板的对象池
template <class T>
class CObjPool : public CBufferPool
{
public:
T *newobj()
{
void *p = CBufferPool::newobj();
T *pt = new(p) T;
return pt;
}
void delobj(T* pt)
{
pt->~T();
CBufferPool::delobj(pt);
}
};
在基础池的基础上定义了一个简单的通用池
class CMemoryPool
{
private:
CBufferPool bp[N];
…
};
通用池是由N个不同大小的基础池组成的,分配的时候圆整到合适的相近基础池并由基础池分配。
最后还提供了一个内存分配适配器类,从该类派生的类都支持内存池分配。
class t_alloc
{
public:
static void *operator new(size_t size)
{
return CMemoryPool::instance().newobj(size);
}
static void operator delete(void *p, size_t size)
{
CMemoryPool::instance().delobj(p, size);
}
};
根据测试CMempool分配速度比CObjpool<>稍微慢一点点,所以我在用的时候就直接用t_alloc类派生,而不是用对象池,这是个风格问题,也许有很多人喜欢用更高效一点的objpool方式,但这个并不大碍。
在网络模块中OVERLAPPED派生类就要用池进行分配,还有CIocpClient也要用池分配,再就是CBlockBuffer也是从池分配的。
如下定义:
struct IOCP_ACCEPTDATA : public IOCP_RECVDATA, public t_alloc
class CIocpClient : public t_alloc
二、数据缓冲区。
数据缓冲区CBlockBuffer为环形,大小不固定,随便分配多少,主要有以下几个元素:
Char *pbase; //环形首部
Char *pread; //当前读指针
Char *pwrite; //当前写指针
Int nCapacity; //缓冲区大小
Long nRef; //关联计数器
用这种形式管理缓冲区有很多好处,发送数据的时候如果只发送了部分数据只要修改pread指针即可,不用移动数据,接收数据并处理的时候如果只处理了部分数据也只要修改pread指针即可,有新数据到达后直接写到pwrite并修改pwrite指针,不用多次拷贝数据。nRef关联计数还可处理一个包发给N个人的问题,如果要给N个人发送相同的包,只要分配一个缓冲区,并设置nRef为N就可以不用复制N份。
三、收发缓冲区管理
发送缓冲区
我把CIocpClient的发送数据设计为一个CBlockBuffer 的队列,如果队列内有多个则WSASend的时候一次发送多个,如果只有一个则仅发送一个,CIocpClient发送函数提供了两个,分别是:
Bool SendData(char *pdata, int len);
Bool SendData(CBlockBuffer *pbuffer);
第一个函数会检测发送链的最后一个数据块能否容纳发送数据,如果能复制到最后一个块,如果不能则分配一个CBlockBuffer挂到发送链最后面,当然这个里面要处理同步。
接收缓冲区
接收管理是比较简单的,只有一个CBlockBuffer,WSARecv的时候直接指向CBlockBuffer->pwrite,所以如果块大小合适的话基本上是不用拼包的,如果一次没有收到一个完整的数据包,并且块还有足够空间容纳剩余空间,那么再提交一个WSARecv让起始缓冲指向CBlockBuffer->pwrite如此则收到一个完整数据包的过程都不用重新拼包,收到一个完整数据包之后可以调用虚函数让上层进行处理。
在IocpClient层其实是不支持数据包的,在这个层次只有流的概念,这个后面会专门讲解。
四、IocpServer的接入部分管理
我把IocpServer设计为可以支持打开多个监听端口,对每个监听端口接入用户后调用IocpServer的虚函数分配客户端:
virtual CIocpClient *CreateNewClient(int nServerPort)
分配客户端之后会调用IocpClient的函数 virtual void OnInitialize();分配内部接收和发送缓冲区,这样就可以根据来自不同监听端口的客户端分配不同的缓冲区和其他资源。
Accept其实是个可以有很多选择的,最简单的做法可以用一个线程+accept,当然这个不是高效的,也可以采用多个线程的领导者-追随者模式+accept实现,还可以是一个线程+WSAAccept,或者多个线程的领导者-追随者模式+WSAAccept模式,也可以采用AcceptEx模式,我是采用AcceptEx模式做的,做法是有接入后投递一个AcceptEx,接入后重复利用此OVERLAPPED再投递,这样即使管理大量连接也只有起初的几十个连接会分配 OVERLAPPED后面的都是重复利用前面分配的结构,不会导致再度分配。
IocpServer还提供了一个虚函数
virtual bool CanAccept(const char *pip, int port){return true;}
来管理是否接入某个ip:port 的连接,如果不接入直接会关闭该连接并重复利用此前分配的WSASocket。
五、资源管理
Iocp网络模块最难的就是这个了,什么时候客户端关闭或服务器主动关闭某个连接并收回资源,这是最难处理的问题,我尝试了几种做法,最后是采用计数器管理模式,具体做法是这样的:
CIocpClient有2个计数变量
volatile long m_nSending; //是否正发送中
volatile long m_nRef; //发送接收关联字
m_nSending表示是否有数据已WSASend中没有返回
m_nRef表示WSASend和WSARecv有效调用未返回和
在合适的位置调用
inline void AddRef(const char *psource);
inline void Release(const char *psource);
增引用计数和释放引用计数
if(InterlockedDecrement(&m_nRef)<=0)
{
//glog.print("iocpclient %p Release %s ref %d\r\n", this, psource, m_nRef);
m_server->DelClient(this);
}
当引用计数减少到0的时候删除客户端(其实是将内存返回给内存池)。
六、锁使用
锁的使用至关重要,多了效率低下,少了不能解决问题,用多少个锁在什么粒度上用锁也是这个模块的关键所在。
IocpClient有一个锁 DECLARE_SIGNEDLOCK_NAME(send); //发送同步锁
这个锁是用来控制发送数据链管理的,该锁和前面提到的volatile long m_nSending;共同配合管理发送数据链。
可能有人会说recv怎么没有锁同步,是的,recv的确没有锁,recv不用锁是为了最大限度提高效率,如果和发送共一个锁则很多问题可以简化,但没有充分发挥iocp的效率。Recv接收数据后就调用OnReceive虚函数进行处理。可以直接io线程内部处理,也可以提交到某个队列由独立的逻辑线程处理。具体如何使用完全由使用者决定,底层不做任何限制。
七、服务器定时器管理
服务器定义了如下定时器函数,利用系统提供的时钟队列进行管理。
bool AddTimer(int uniqueid, DWORD dueTime, DWORD period, ULONG nflags=WT_EXECUTEINTIMERTHREAD);
bool ChangeTimer(int uniqueid, DWORD dueTime, DWORD period);
bool DelTimer(int uniqueid);
//获取Timers数量
int GetTimerCount() const;
TimerIterator GetFirstTimerIterator();
TimerNode *GetNextTimer(TimerIterator &it);
bool IsValidTimer(TimerIterator it)
设计思路是给每个定时器分配一个独立的id,根据id可修改定时器的首次触发时间和后续每次触发时间,可根据id删除定时器,也可遍历定时器。定时器时间单位为毫秒。
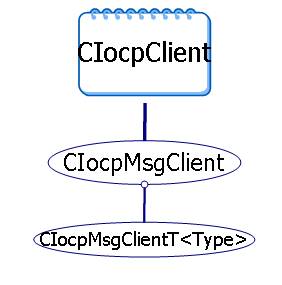
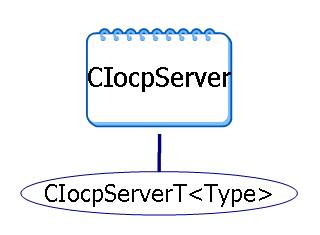
八、模块类结构
模块中最重要的就是两个类CIocpClient和CIocpServer,其他有几个类从这两个类派生,图示如下:
|
 图表 1 图表 1
|
 图表 2 图表 2
|
CIocpClient是完全流式的,没有包概念。CIocpMsgClient从CIocpClient派生,内部支持包概念:
class CIocpMsgClient : public CIocpClient
{
…
virtual void OnDataTooLong(){};
virtual void OnMsg(PKHEAD *ph){};
bool SendMsg(WORD mtype, WORD stype, const char *pdata, int length);
…
};
template <class TYPE>
class CIocpMsgClientT : public CIocpMsgClient
{
…
void AddMsg(DWORD id, CBFN pfn);
BOOL DelMsg(DWORD id);
…
};
CIocpMsgClientT模板类支持内嵌入式定义,如在
CMyDoc中可这样定义
CIocpMsgClientT<CMyDoc> client;
后面可以调用client.AddMsg(UMSG_LOGIN, OnLogin);关联一个类成员函数作为消息处理函数,使用很方便。
CIocpServerT定义很简单,从CIocpServer派生,重载了CreateNewClient函数
template <class TClient>
class CIocpServerT : public CIocpServer
{
public:
//如果CIocpClient派生了则也需要重载下面的函数,这里可以根据nServerPort分配不同的CIocpClient派生类
virtual CIocpClient *CreateNewClient(int nServerPort)
{
CIocpClient *pclient = new TClient;
…
return pclient;
}
};
八、应用举例
class CMyClient : public CIocpMsgClient
{
public:
CMyClient() : CIocpMsgClient()
{
}
virtual ~CMyClient()
{
}
virtual void OnConnect()
{
Printf(“用户连接%s:%d连接到服务器\r\n”, GetPeerAddr().ip(),GetPeerAddr().port());
}
virtual void OnClose()
{
Printf(“用户%s:%d关闭连接\r\n”, GetPeerAddr().ip(),GetPeerAddr().port());
}
virtual void OnMsg(PKHEAD *phead)
{
SendData((const char *)phead, phead->len+PKHEADLEN);
}
virtual void OnSend(DWORD dwbyte)
{
Printf(“成功发送%d个字符\r\n”, dwbyte);
}
virtual void OnInitialize()
{
m_sendbuf = newbuf(1024);
m_recvbuf = newbuf(4096);
}
friend class CMyServer;
};
class CMyServer : public CIocpServer
{
public:
CMyServer() : CIocpServer
{
}
virtual void OnConnect(CIocpClient *pclient)
{
printf("%p : %d 远端用户%s:%d连接到本服务器.\r\n", pclient, pclient->m_socket,
pclient->GetPeerAddr().ip(), pclient->GetPeerAddr().port());
}
virtual void OnClose(CIocpClient *pclient)
{
printf("%p : %d 远端用户%s:%d退出.\r\n", pclient, pclient->m_socket,
pclient->GetPeerAddr().ip(), pclient->GetPeerAddr().port());
}
virtual void OnTimer(int uniqueid)
{
If(uniqueid == 10)
{
}
Else if(uniqueid == 60)
{
}
}
//这里可以根据nServerPort分配不同的CIocpClient派生类
virtual CIocpClient *CreateNewClient(int nServerPort)
{
// If(nServerPort == ?)
// …
CIocpClient *pclient = new CMyClient;
…
return pclient;
}
};
Int main(int argc, char *argv[])
{
CMyServer server;
server.AddTimer(60, 10000, 60000);
server.AddTimer(10, 10000, 60000);
//第二个参数为0表示使用默认cpu*2个io线程,>0表示使用该数目的io线程。
//第三个参数为0表示使用默认cpu*4个逻辑线程,如果为-1表示不使用逻辑线程,逻辑在io线程内计算。>0则表示使用该数目的逻辑线程
server.StartServer("1000;2000;4000", 0, 0);
}
从示例可看出,对使用该网络模块的人来说非常简单,只要派生两个类,集中精力处理消息函数即可,其他内容内部全部包装了。
九、后记
我研究iocp大概在2005年初,前一个版本的网络模块是用多线程+异步事件来做的,iocp网络模块基本成型在2005年中,后来又持续进行了一些改进,2005底进入稳定期,2006年又做了一些大的改动,后来又持续进行了一些小的改进,目前该模块作为服务程序框架已经在很多项目中稳定运行了1年半左右的时间。在此感谢大宝、Chost Cheng、Sunway等众多网友,是你们的讨论给了我灵感和持续改进的动力,也是你们的讨论给了我把这些写出来的决心。若此文能给后来者们一点点启示我将甚感欣慰,若有错误欢迎批评指正。
oldworm
oldworm@21cn.com
2007.9.24