基于云计算的价格查询实现
上篇博客提到价格查询功能,当时正在考虑做成云计算模式,所以当时连多线程都没考虑,就是准备将功能都交给云计算系统的,由云计算内部管理线程和调度问题,所以当时实现就根本不用考虑多线程,现在功能基本实现,下面大致讲讲我的做法。
国内很多人谈到全文检索就必提lucene,提到云计算就必提google的map/reduce、开源的hadoop、amazon的ec2,似乎只有那些东西才叫云计算,咱是实战派,没兴趣口舌之争,在俺看来分布式存储+分布式计算就叫云计算,俺就看了看google的map/reduce论文,照其思想在win下做了个简单的job/task调度系统,使其能支撑俺的第一个实战应用价格查询,图示如下:
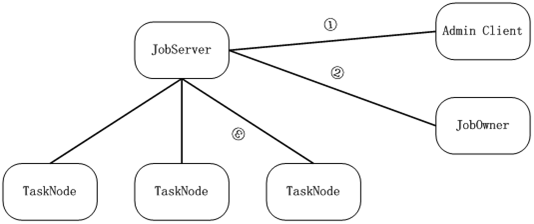
① 、adminclient承担管理功能,可查看任务及执行情况,可查看Tasknode机器情况,如果需要可管理Task,目前只支持简单的几条命令,adminclient主动连jobserver登录成功后可发送管理命令。
② 、JobOwner提交一个Job之后返回一个jobid,如果意外断开可通过下次重连的时候提交jobid和一个sessionid可提取job结果数据,job提交通过提交一个zip包即可,参数等文件都打在包里面,tasknode可直接解包执行里面的dll。Jobowner主动连jobserver,登录成功后可发job命令。
③ TaskNode是执行具体任务的客户端,job包用zip打包后发布给tasknode,tasknode参与计算并反馈结果。TaskNode设计成多线程模式,一个线程保持和jobserver的通信,其他线程参与运算,Tasknode可同时执行多个不同的任务,如a线程执行价格查询,b线程执行hash破解等。Tasknode主动连jobserver,登录后可接受jobserver分派的任务,由于tasknode是主动连jobserver的,所以即使是内网机器或者任意有闲置资源的机器都可作为Tasknode,不管它是家里的、公司的、还是网吧的,这也是该系统基于windows实现的一个重要前提,因为win的机器是如此的多,在国内win的机器无处不在。
JobServer是job调度器,管理包分发以及任务分割、调度,典型的执行流程是这样,jobowner提交一个命名的包给jobserver,jobserver将该包部署管理,之后jobowner 可给jobserver提交任务,jobserver收到任务后根据任务指定的包配置执行,如部署包后装载dll并执行任务分割操作,分割是将一个job分割为多个task,之后再将每个task提交给一个tasknode执行,并管理tasknode的输出以及可能的出错,出错现在的处理是交给另一个tasknode执行,当剩下最后一个tasknode的时候会将该tsaknode同步叫给另一个不同的tasknode执行,不管谁最后成功执行这个tasknode,只要该task执行成功立即结束整个job,并将结果反馈给jobowner,jobowner也可在执行中提交查询命令,jobserver会将被查询job当前的输出返回,这样碰到需要长时间执行的任务也能适用。
从以上介绍可以看到,具体任务是由包执行的,这个包实际上可能是一个dll,也可能是几个dll加上一些配置文件组成,之所以设计成这种模式,主要是考虑整个系统在win上方便部署,主dll需要支持几个固定的接口:
//任务dll初始化函数
typedef bool (*jobtask_init_)(jobtaskfunc *jtfunc, bool tasknode);
//map分割函数
typedef size_t (*jobtask_split_)(jobtaskfunc *jtfunc,
const char *input, size_t len,
std::vector<CAutoBuffer *> &vbuf);
//reduce打包函数
typedef size_t (*jobtask_reduce_)(jobtaskfunc *jtfunc,
std::vector<CAutoBuffer *> &vbuf,
CAutoBuffer &buf);
//Task执行函数
typedef bool (*jobtask_map_)(jobtaskfunc *jtfunc, const char *cmdline, CAutoBuffer &outbuf);
//释放函数
typedef bool (*jobtask_free_)(jobtaskfunc *jtfunc);
上面init函数主要执行线程相关的初始化,该函数典型的可能是空,或者是
CoInitialize(NULL); 等
Split函数是用来将job输入分割为N个tasknode输入的,该函数由jobserver调用,每个tasknode输入就是map函数的输入,tasknode的任务就是调用map函数,并传递输入,最后将输出返回给jobserver,jobserver在需要的时候调用reduce将各个tasknode的输出打包返回,free函数是个辅助函数,释放资源的。
熟悉google的map/reduce的应该知道,我的实现简化了reduce,在我的实现里面并没有独立的reduce worker,该任务由jobserver自己做了,这一方面是简化实现,另方面也是适应需求的结果,毕竟在我的需求里面输入是很少的(一个典型任务100字节量级),tasknode的计算是很多的,输出也是不多的(1k量级),所以由jobserver打包整个输出也很轻松,用不着一组独立的reduce来管理输出。另外可以看到上面接口用了我的自定义类CAutoBuffer,这个类主要管理不定长数据的,其实用vector<char>也可,但考虑方便,我的实现内部都用了CAutoBuffer。一个典型的分布式应用只要做一个dll,有上面几个函数,并输出一个
struct jobtaskfunc
{
//初始化函数
jobtask_init_ init;
//释放函数
jobtask_free_ free;
//以下被tasknode调用
jobtask_map_ map;
//以下被jobserver调用
jobtask_split_ split;
jobtask_reduce_ reduce;
};
typedef jobtaskfunc *(WINAPI *create_jobtask_)();
函数即可。
学习map/reduce重要的是学习其思想,并不拘泥于实现形式,我想这大概正是国内环境欠缺的,国内能说得头头是道的人太多,能动手干出结果来的人很少,真正坐下来做实事的不多,只喜欢抄抄概念,拿别人的东西过来架设一下,就是这样的人也能混成大拿。我从map/reduce思想出发,学习其思想,简化其实现,为实际应用服务,虽然这个东西很简单,甚至可以说有些简陋,但实际效果不错,虽然现在只部署了两个点,但总体上还是令人满意的。
实现这个jobserver/tasknode系统并部署价格查询花了不到两周时间,实际上花在jobserver、tasknode上的时间大概只有一周多一点,ppsget.dll(具体干活的dll)用正则表达式分析网页并提取输出,该dll被应用到多线程环境后也出了一些问题,用boost::reg的时候居然偶尔会出现异常,原以为boost::reg这样的应用应该是非常明确的,要么找到,要么没有找到,除此不应该有第三态,没想到boost::reg这个不争气的东西不但不是二态的,还容易出现异常,试用了一下tr1::regex也是类似的问题,无奈只能在外面包了一层异常处理,虽然不再被异常搞死,但一旦出现异常就是很慢的,要10s左右才返回,现在也没有特别好的办法,只在异常的时候将页面保存,事后分析并改写正则表达式,尽量将正则表达式做小,将非贪婪式查找用少一点。
下面看看我们价格查询网站 http://www.shprog.com/pps.aspx 的输出:
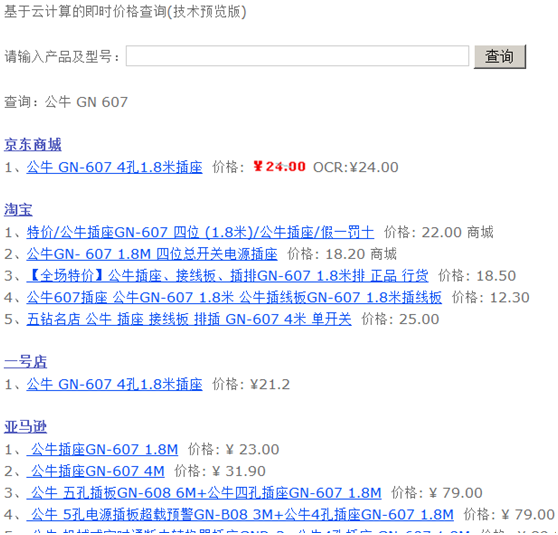
那个360的价格居然是图片,ocr模块是俺同事搞的,现在识别率能达到99%以上,还是很不错的。