摘要: 为了使nginx支持windows服务,本文阐述以下主要的改进实现。ngx_main函数 为了在SCM服务中复用main函数的逻辑,将其重命名为ngx_main,并添加第3个参数is_scm以兼容控制台运行方式,声明在core/nginx.h中。
Code highligh...
阅读全文
posted @
2016-07-12 15:31 春秋十二月 阅读(4498) |
评论 (0) |
编辑 收藏
1 struct state_machine {
2 int state;
3  4
4 };
5 6 enum {
7 s1,
8 s2,
9 10 sn
11 };
假设s1为初始状态,状态变迁为s1->s2->...->sn。
常规实现 状态机处理函数state_machine_handle通常在一个循环内或被事件驱动框架调用,输入data会随时序变化,从而引起状态的变迁,伪代码框架如下。
1 void handle_s1(struct state_machine *sm, void *data)
void handle_s1(struct state_machine *sm, void *data)
2
 {
{
3 //do something about state 1
//do something about state 1
4 if(is_satisfy_s2(data))
5 sm->state = s2;
6 }
}
7
8void handle_s2(struct state_machine *sm, void *data)
9{
10 //do something about state 2
11 if(is_satisfy_s3(data))
12 sm->state = s3;
13}
14
15void handle_sn_1(struct state_machine *sm, void *data)
16{
17 //do something about state n-1
18 if(is_satisfy_sn(data))
19 sm->state = sn;
20}
21
22void state_machine_handle(struct state_machine *sm, void *data)
23{
24
 switch(sm->state){
switch(sm->state){
25 case s1:
26 handle_s1(sm,data);
27 break;
28
29 case s2:
30 handle_s2(sm,data);
31 break;
32
33 case sn:
34 handle_sn(sm,data);
35 break;
36 }
}
37} sm->state初始化为s1。
改进实现
为了免去丑陋的switch case分支结构,在state_machine内用成员函数指针handler替代了state,改进后的框架如下。
1 struct state_machine;
struct state_machine;
2typedef void (*state_handler)(struct state_machine*,void*);
3
4
 struct state_machine {
struct state_machine {
5 state_handler handler;
state_handler handler;
6
7 };
};
8
9void handle_s1(struct state_machine *sm, void *data)
10{
11 //do something about state 1
12 if(is_satisfy_s2(data))
13 sm->handler = handle_s2;
14}
15
16void handle_s2(struct state_machine *sm, void *data)
17{
18 //do something about state 2
19 if(is_satisfy_s3(data))
20 sm->handler = handle_s3;
21}
22
23void handle_sn_1(struct state_machine *sm, void *data)
24{
25 //do something about state n-1
26 if(is_satisfy_sn(data))
27 sm->handler = handle_sn;
28}
29
30void state_machine_handle(struct state_machine *sm, void *data)
31{
32 sm->handler(sm, data);
33}
sm->handler初始化为handle_s1,该方法在性能上应略优于常规方法,而且逻辑更清晰自然,非常适合于网络流的处理,在nginx中分析http和email协议时,得到了广泛应用。
posted @
2016-05-05 09:46 春秋十二月 阅读(4045) |
评论 (1) |
编辑 收藏 由于使用objdump反汇编linux内核的输出太多(2.6.32-220.el6.x86_64统计结果为1457706行),而很多时候只是想查看特定部分的机器码与汇编指令,例如函数的入口、堆栈、调用了哪个函数等,为了高效和通用,因此编写了一个简单的awk脚本,其命令行参数说明如下:
● SLINE表示匹配的起始行号(不小于1),SPAT表示匹配的起始行模式,这两个只能有一个生效,当都有效时,以SLINE为准。
● NUM表示从起始行开始的连续输出行数(不小于1,含起始行),EPAT表示匹配的结束行模式,这两个只能有一个生效,当都有效时,以NUM为准。
脚本实现 检查传值 由于向脚本传入的值在BEGIN块内没生效,在动作块{}和END块内有效,但若在{}内进行检查则太低效,因为处理每条记录都要判断,所以为了避免在{}内进行多余的判断,就在BEGIN块内解析命令行参数来间接获得传值,当传值无效时,给出提示并退出。
1for(k=1;k<ARGC;++k){
2 str=ARGV[k]
3 if(1==match(str,"SLINE=")){
4 SLINE = substr(str,7)
5 }else if(1==match(str,"SPAT=")){
6 SPAT = substr(str,6)
7 }else if(1==match(str,"NUM=")){
8 NUM = substr(str,5)
9 }else if(1==match(str,"EPAT=")){
10 EPAT = substr(str,6)
11 }
12 }
13
14 if(SLINE<=0 && SPAT==""){
15 print "Usage: rangeshow must specifies valid SLINE which must be greater than 0, or SPAT which can't be empty"
16 exit 1
17 }
18
19 if(NUM<=0 && EPAT==""){
20 print "Usage: rangeshow must specifies valid NUM which must be greater than 0, or EPAT which can't be empty"
21 exit 1
22} 结束处理 当处理了NUM条记录或匹配了结束行模式时,应退出动作块{}。
1if(0==start_nr){
2
3}else{
4 if(NUM>0) {
5 if(NR<start_nr+NUM) {
6 ++matched_nr
7 print $0
8 }else
9 exit 0
10
11 }else{
12 ++matched_nr
13 print $0
14 if(0!=match($0,EPAT))
15 exit 0
16 }
17} 完整脚本下载:
rangeshow。
脚本示例
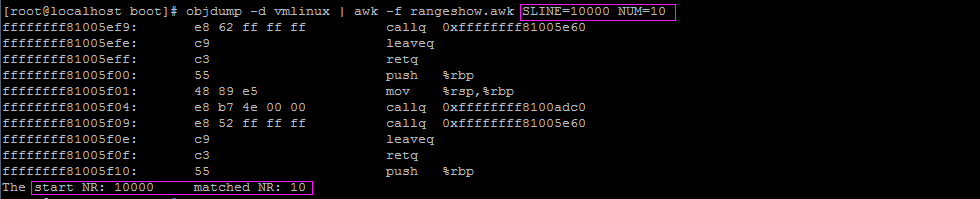
查看linux内核第10000行开始的10条指令,如下图
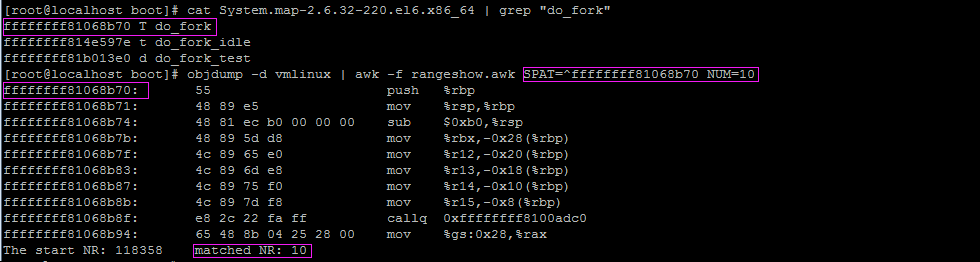
查看linux内核函数do_fork入口开始的10条指令,如下图
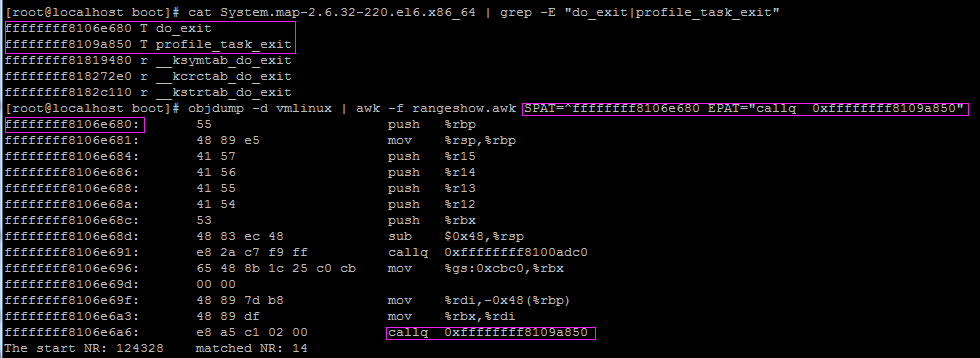
查看linux内核第10000行开始到callq的一段指令,如下图

查看linux内核函数do_exit入口到调用profile_task_exit的一段指令,如下图
posted @
2015-10-27 15:36 春秋十二月 阅读(1772) |
评论 (1) |
编辑 收藏
本文根据RFC793协议规范和BSD 4.4的实现,总结了
TCP分组丢失时的状态变迁,如下图所示:实线箭头表示客户端的状态变迁,线段虚线箭头表示服务端的状态变迁,圆点虚线箭头表示客户端或服务端的状态变迁;黑色文字表示正常时的行为,红色文字表示分组丢失时的行为。
这里假设重传时分组依然会丢失,当在不同状态(CLOSED除外)分组丢失后,最终会关闭套接字而回到CLOSED状态。下面逐个分析各状态时的情景。
SYN_SENT
连接阶段第1次握手,客户端发送的SYN分组丢失,因此超时收不到服务端的SYN+ACK而重传SYN,尝试几次后放弃,关闭套接字。
SYN_RCVD
1)连接阶段第2次握手,服务端响应的SYN+ACK分组丢失,因此超时收不到客户端的ACK而重传SYN+ACK,尝试几次后放弃,发送RST并关闭套接字。
2)连接阶段第3次握手,客户端发送的ACK分组丢失,因此服务端超时收不到ACK而重传SYN+ACK,尝试几次后放弃,发送RST并关闭套接字。
3)同时打开第2次握手,本端响应的SYN+ACK分组丢失,因此对端超时收不到SYN+ACK而重传SYN、尝试几次后放弃、发送RST并关闭套接字,而此时本端收到RST。
ESTABLISHED
1)连接阶段第3次握手,客户端发送ACK分组后,虽然丢失但会进入该状态(因为ACK不需要确认),但此时服务端还处于SYN_RCVD状态,因为超时收不到客户端的ACK而重传SYN+ACK、尝试几次后放弃、发送RST并关闭套接字,而此时客户端收到RST。
2)数据传输阶段,本端发送的Data分组丢失,因此超时收不到对数据的确认而重传、尝试几次后放弃、发送RST并关闭套接字,而此时对端收到RST。
FIN_WAIT_1
1)关闭阶段第1次握手,客户端发送的FIN分组丢失,因此超时收不到服务端的ACK而重传FIN,尝试几次后放弃,发送RST并关闭套接字。
2)关闭阶段第2次握手,服务端响应的ACK分组丢失,因此客户端超时收不到ACK而重传FIN,尝试几次后放弃,发送RST并关闭套接字。
FIN_WAIT_2
关闭阶段第3次握手,服务端发送的FIN分组丢失,因此超时收不到客户端的ACK而重传FIN、尝试几次后放弃、发送RST并关闭套接字,而此时客户端收到RST。
CLOSING
同时关闭第2次握手,本端发送的ACK分组丢失,导致对端超时收不到ACK而重传FIN、尝试几次后放弃、发送RST并关闭套接字,而此时本端收到RST。
TIME_WAIT
关闭阶段第4次握手,客户端响应的ACK分组丢失,导致服务端超时收不到ACK而重传FIN、尝试几次后放弃、发送RST并关闭套接字,而此时客户端收到RST。
CLOSE_WAIT
关闭阶段第2次握手,服务端响应的ACK分组丢失,导致客户端超时收不到ACK而重传FIN、尝试几次后放弃、发送RST并关闭套接字,而此时服务端收到RST。
LAST_ACK
关闭阶段第3次握手,服务端发送的FIN分组丢失,导致超时收不到客户端的ACK而重传FIN、尝试几次后放弃、发送RST并关闭套接字。
posted @
2015-10-05 00:44 春秋十二月 阅读(3285) |
评论 (1) |
编辑 收藏
摘要: 由于linux内核中的struct list_head已经定义了指向前驱的prev指针和指向后继的next指针,并且提供了相关的链表操作方法,因此为方便复用,本文在它的基础上封装实现了一种使用开链法解决冲突的通用内核Hash表glib_htable,提供了初始化、增加、查找、删除、清空和销毁6种操作,除初始化和销毁外,其它操作都做了同步,适用于中断和进程上下文。...
阅读全文
posted @
2015-09-15 17:18 春秋十二月 阅读(2211) |
评论 (0) |
编辑 收藏
nginx的域名解析器使用已连接udp(收发前先调用ngx_udp_connect)发送dns查询、接收dns响应,如上篇
tcp异步连接所讲,iocp需要先投递udp的接收操作,才能引发接收完成的事件,因此要对域名解析器和udp异步接收作些改进。
发送后投递
dns查询由ngx_resolver_send_query函数实现,定义在core/ngx_resolver.c中。
1static ngx_int_t ngx_resolver_send_query(ngx_resolver_t *r, ngx_resolver_node_t *rn)
2{
3
4
 if (rn->naddrs == (u_short) -1) {
if (rn->naddrs == (u_short) -1) {
5 n = ngx_send(uc->connection, rn->query, rn->qlen);
6
7 }
}
8
9#if (NGX_HAVE_INET6)
10 if (rn->query6 && rn->naddrs6 == (u_short) -1) {
11 n = ngx_send(uc->connection, rn->query6, rn->qlen);
12
13 }
14#endif
15
16#if (NGX_WIN32)
17 if (ngx_event_flags & NGX_USE_IOCP_EVENT){
18 uc->connection->read->ready = 1;
19 ngx_resolver_read_response(uc->connection->read);
20}
21#endif
22
23 return NGX_OK;
24}
当nginx用于代理连接上游服务器前,要先解析域名,首次调用链为:
ngx_http_upstream_init_request->
ngx_resolver_name->
ngx_resolver_name_locked->
ngx_resolver_send_query;若5s(单次超时)后还没收到dns响应,则再发送1次查询,调用链为:
ngx_resolver_resend_handler->
ngx_resolver_resend->
ngx_resolver_send_query,如此反复,直到收到响应或30s(默认总超时)后不再发送查询。它调用ngx_send发送dns查询,16行~21行代码为笔者添加,ngx_resolver_read_response函数用于接收并分析dns响应报文,它会调用到下面的ngx_udp_overlapped_wsarecv函数。
异步接收
由ngx_udp_overlapped_wsarecv函数实现,定义在os/win32/ngx_udp_wsarecv.c中。
1ssize_t ngx_udp_overlapped_wsarecv(ngx_connection_t *c, u_char *buf, size_t size)
2{
3 int flags, rc;
4 WSABUF wsabuf;
5 ngx_err_t err;
6 ngx_event_t *rev;
7 WSAOVERLAPPED *ovlp;
8 u_long bytes;
9
10 rev = c->read;
11
12 if (!rev->ready) {
13 ngx_log_error(NGX_LOG_ALERT, c->log, 0, "ngx_udp_overlapped_wsarecv second wsa post");
14 return NGX_AGAIN;
15 }
16
17 if (rev->complete) {
18 if (ngx_event_flags & NGX_USE_IOCP_EVENT) {
19 if (rev->ovlp.error && rev->ovlp.error != ERROR_MORE_DATA) {
20 ngx_connection_error(c, rev->ovlp.error, "ngx_udp_overlapped_wsarecv() failed");
21 return NGX_ERROR;
22 }
23 }
24
25 rev->complete = 0;
26 }
27
28 ovlp = NULL;
29 wsabuf.buf = (CHAR *) buf;
30 wsabuf.len = (ULONG) size;
31 flags = 0;
32
33retry:
34 rc = WSARecv(c->fd, &wsabuf, 1, (DWORD*)&bytes, (LPDWORD)&flags, ovlp, NULL);
35
36 if (rc == -1) {
37 rev->ready = 0;
38 err = ngx_socket_errno;
39
40 if (err == WSA_IO_PENDING) {
41 return NGX_AGAIN;
42 }
43
44 if (err == WSAEWOULDBLOCK) {
45 if (ngx_event_flags & NGX_USE_IOCP_EVENT) {
46 rev->ovlp.type = NGX_IOCP_IO;
47 ovlp = (WSAOVERLAPPED *)&rev->ovlp;
48 ngx_memzero(ovlp, sizeof(WSAOVERLAPPED));
49
50 wsabuf.buf = NULL;
51 wsabuf.len = 0;
52 flags = MSG_PEEK;
53
54 goto retry;
55 }
56
57 return NGX_AGAIN;
58 }
59
60 ngx_connection_error(c, err, "ngx_udp_overlapped_wsarecv() failed");
61 rev->error = 1;
62
63 return NGX_ERROR;
64 }
65
66 if ((ngx_event_flags & NGX_USE_IOCP_EVENT) && ovlp) {
67 rev->ready = 0;
68 return NGX_AGAIN;
69 }
70
71 return bytes;
72}
先以非阻塞方式接收,若发生WSAWOULDBLOCK错误,则使用MSG_PEEK标志投递一个0字节的重叠接收操作,当dns响应返回时发生完成事件,会再次进入ngx_resolver_read_response而调用到该函数,此时rev->complete为1,rev->ovlp.error为ERROR_MORE_DATA(GetQueuedCompletionStatus返回的错误),由于使用了MSG_PEEK,因此数据还在接收缓冲区中,要忽略ERROR_MORE_DATA而继续接收,这时就能成功了。不管WSARecv返回WSA_IO_PENDING错误还是成功,iocp都会得到完成通知,所以这里当重叠操作投递成功时,返回NGX_AGAIN,便于在回调内统一处理。
posted @
2015-06-25 17:01 春秋十二月 阅读(6231) |
评论 (0) |
编辑 收藏
iocp是Windows NT操作系统的一种高效IO模型,对应于Linux中的epoll和FreeBSD中的kqueue,nginx对ske(select、kqueue和epoll的首写字母组合)的支持很好,但截止到1.6.2版本,还不支持iocp。由于ske都是反应器模式,即先注册IO事件,当IO事件发生(读写通知)时,在其回调内主动调用API来读或写数据;而iocp是前摄器模式,要先投递IO操作,才能引发IO事件(完成通知)的发生,在其回调内数据已被动由操作系统读或写完成。因此,iocp的特点决定了nginx对它的支持与ske有所不同。通过hg clone
http://hg.nginx.org/nginx下载的nginx源代码,虽然实现了iocp事件模块、异步接受连接、部分异步读写,但根本不能正常工作,而且不支持异步连接和SCM服务控制,笔者在参考ske模块的实现基础上,改进支持了如下特性:
1. 异步接受连接时的负载均衡
2. 正反向代理的异步连接
3. 异步聚合读写
4. 域名解析时的UDP异步接收
5. 异步文件传输
6. SCM服务控制
由于2、4、6均为原创,其它几点的思路皆源于ske模块的实现(只是平台API不同),因此本文先阐述异步连接的实现。为了兼容select事件模块,所有iocp相关的代码使用NGX_HAVE_IOCP宏和(或)NGX_USE_IOCP_EVENT标志包围,其中NGX_HAVE_IOCP宏用于条件编译,在WIN32平台下,定义为1;当选择的事件模块为iocp时,全局变量ngx_event_flags才包含NGX_USE_IOCP_EVENT标志。
异步连接对端
由ngx_event_connect_peer函数(这里省去了与异步连接无关的代码)实现,定义在event/ngx_event_connect.c中,因为connect不支持异步连接事件的完成通知,所以要使用扩展API ConnectEx。
1ngx_int_t ngx_event_connect_peer(ngx_peer_connection_t *pc)
2{
3 int rc;
4 ngx_int_t event;
5 ngx_err_t err;
6 ngx_uint_t level,family;
7 ngx_socket_t s;
8 ngx_event_t *rev, *wev;
9
10 s = ngx_socket(family = pc->sockaddr->sa_family, SOCK_STREAM, 0);
11
12 #if (NGX_HAVE_IOCP)
13 if((pc->local==NULL||pc->local->sockaddr->sa_family != family)
14 && (ngx_event_flags & NGX_USE_IOCP_EVENT)){
15 if(ngx_iocp_set_localaddr(pc->log,family,&pc->local) != NGX_OK)
16 goto failed;
17 }
18 #endif
19
20
21 #if (NGX_HAVE_IOCP)
22 if(ngx_event_flags&NGX_USE_IOCP_EVENT){
23 LPWSAOVERLAPPED ovlp;
24 ovlp = (LPWSAOVERLAPPED)&wev->ovlp;
25 ngx_memzero(ovlp,sizeof(WSAOVERLAPPED));
26 wev->ovlp.type = NGX_IOCP_CONNECT;
27 rc = ngx_connectex(s,pc->sockaddr,pc->socklen,NULL,0,NULL,ovlp) ? 0 : -1;
28
29 }else
30 rc = connect(s, pc->sockaddr, pc->socklen);
31 #else
32 rc = connect(s, pc->sockaddr, pc->socklen);
33 #endif
34
35 if (rc == -1) {
36 err = ngx_socket_errno;
37 if (err != NGX_EINPROGRESS
38 #if (NGX_WIN32)
39 /**//* Winsock returns WSAEWOULDBLOCK (NGX_EAGAIN) */
40 && err != NGX_EAGAIN
41 #if (NGX_HAVE_IOCP)
42 && err != WSA_IO_PENDING
43 #endif
44 #endif
45 ){
46
47 ngx_log_error(level, c->log, err, "connect() to %V failed", pc->name);
48 ngx_close_connection(c);
49 pc->connection = NULL;
50
51 return NGX_DECLINED;
52 }
53 }
54
55}
调用ConnectEx前要先bind本地地址,不然发生WSAEINVAL错误;由于域名解析可能返回IPv6记录,导致创建本地套接字的地址族为AF_INET6,因此bind时需要匹配IPv6地址,不然发生WSAEFAULT错误,导致nginx返回
Internal Server Error错误给前端,因此绑定前要调用
ngx_iocp_set_localaddr设定正确的本地地址,当且仅当pc->local为空或地址族不匹配时。
本地初始化与设定
支持IPv6,实现在event/modules/ngx_iocp_module.c。
地址变量定义如下。
1static struct sockaddr_in sin;
2#if (NGX_HAVE_INET6)
3static struct sockaddr_in6 sin6;
4#endif
5static ngx_addr_t local_addr;
sin对应IPv4,sin6对应IPv6,作为bind的套接字本地地址。
sin和sin6在启动iocp事件模块时调用ngx_iocp_init初始化。
1static ngx_int_t ngx_iocp_init(ngx_cycle_t *cycle, ngx_msec_t timer)
2{
3
4 sin.sin_family = AF_INET;
5 sin.sin_port = 0;
6 sin.sin_addr.s_addr = INADDR_ANY;
7
8#if (NGX_HAVE_INET6)
9 sin6.sin6_family = AF_INET6;
10 sin6.sin6_port = 0;
11 sin6.sin6_addr = in6addr_any;
12#endif
13
14 local_addr.name.len = sizeof("INADDR_ANY") - 1;
15 local_addr.name.data = (u_char *)"INADDR_ANY";
16
17}
不论IP地址或端口,都指定为0,表示由系统自动分配出口IP地址和未占用的端口。
本地设定由ngx_iocp_set_localaddr实现。
1ngx_int_t ngx_iocp_set_localaddr(ngx_log_t *log, in_port_t family, ngx_addr_t **local)
2{
3 struct sockaddr *sa;
4 socklen_t len;
5
6 if(AF_INET == family){
7 sa = &sin;
8 len = sizeof(struct sockaddr_in);
9 }
10#if (NGX_HAVE_INET6)
11 else if(AF_INET6 == family){
12 sa = &sin6;
13 len = sizeof(struct sockaddr_in6);
14 }
15#endif
16 else{
17 ngx_log_error(NGX_LOG_ALERT, log, 0, "not supported address family");
18 return NGX_ERROR;
19 }
20
21 local_addr.sockaddr = sa;
22 local_addr.socklen = len;
23 *local = &local_addr;
24
25 return NGX_OK;
26}
对于除IPv4和IPv6外的协议族,则记录一个错误日志。必要时也可扩展支持其它的协议族,例如NetBIOS(对应地址族为AF_NETBIOS),但要看ConnectEx是否支持。
posted @
2015-06-24 17:02 春秋十二月 阅读(7597) |
评论 (1) |
编辑 收藏
ICMP在IP系统间传递差错和管理报文,是任何IP系统必须实现的组成部分。Linux 2.6.34中ICMP模块的实现在linux/icmp.h,net/icmp.h和ipv4/icmp.c中,导出了
icmp_err_convert数组和
icmp_send函数,供其它网络子系统使用。在其它网络子系统中,当检测到错误时,调用icmp_send产生并发送相应的ICMP差错消息到源主机;当源主机收到ICMP不可达差错消息,传递到原始套接字和传输层,而它们使用icmp_err_convert把对应的消息代码转换成套接字层比较容易理解的错误代码。在内核空间中可发送的ICMP消息包括查询应答和差错报文,下面总结了产生这两类消息的网络子系统(及函数)与错误转换。
应答消息
应答消息由ICMP模块的内部函数icmp_reply而非icmp_send发送。根据
RFC1122 3.2.2.9规范, 除非一个主机作为地址掩码代理,否则不能发送回复,这对应ICMP的icmp_address实现为空,因此上表没有列出地址掩码应答项(内核符号为ICMP_ADDRESSREPLY)。
差错消息
差错消息由中间路由器或目的主机产生,当数据报不能成功提交给目的主机时。从上表可见,在IP层的接收、本地处理、转发和输出各过程中,都可能产生差错消息;在传输层如果对应的端口没有打开,那么UDP会产生ICMP端口不可达差错,而
TCP则会使用自己的差错处理机制发送一个RST复位包,这也是上表没有列出TCP子系统的原因。对于重定向差错,由ICMP模块的icmp_redirect调用ip_rt_redirect更新路由;其它差错则由icmp_unreach处理。
错误转换
第2列为icmp_err_convert数组索引,第4列也就是调用socket API出错时返回的errno,最后1列为icmp_err_convert中的fatal成员取值,0表示非致命错误,1表示致命错误,需要报告给用户进程。错误转换会被RAW的raw_err、TCP的tcp_v4_err和UDP的udp_err用到,对于ICMP_DEST_UNREACH类型的差错,使用上表转换;ICMP_SOURCE_QUENCH类型的忽略不处理;ICMP_PARAMETERPROB类型的转换成
EPROTO(协议错误);ICMP_TIME_EXCEEDED类型的转换成
EHOSTUNREACH。
在这要注意,从ICMP_PORT_UNREACH到ECONNREFUSED的转换,不适用于TCP,原因已在
上节说明;而对于UDP的
未连接套接字,如果主机在线而端口没打开,调用sendto得不到ECONNREFUSED错误,但recvfrom会阻塞,这是因为虽然内核收到了ICMP差错,但没上报给应用进程。尽管如此,如果想得到ECONNREFUSED错误,那么可以写个ICMP守护进程,应用进程先把它的套接字描述符通过unix域套接口传递到ICMP守护进程,而守护进程使用raw socket来接收ICMP差错,再发给应用进程。
发送限速
不论一般差错消息还是重定向差错消息,发送限速针对的都是特定目标主机。
一般限速
在使用icmp_send发送差错消息(PMTU消息除外)时,为减少网络拥塞而限制了发送的速率,限速由xrlim_allow函数实现,定义在ipv4/icmp.c中。
1#define XRLIM_BURST_FACTOR 6
2int xrlim_allow(struct dst_entry *dst, int timeout)
3{
4 unsigned long now, token = dst->rate_tokens;
5 int rc = 0;
6
7 now = jiffies;
8 token += now - dst->rate_last;
9 dst->rate_last = now;
10 if (token > XRLIM_BURST_FACTOR * timeout)
11 token = XRLIM_BURST_FACTOR * timeout;
12 if (token >= timeout) {
13 token -= timeout;
14 rc = 1;
15 }
16 dst->rate_tokens = token;
17 return rc;
18}
dst为目标路由缓存,timeout为允许发送的超时(单位为jiffies),dst->rate_tokens记录令牌的个数,当令牌个数不小于timeout时,则减少timeout并允许发送一个消息;反之则不能发送,需等到令牌个数累积到大于timeout时才能发送,但是不能无限大,否则就会导致在一个可能很短的timeout内,发送远多于6个的消息,引起ICMP风暴,所以这里限制了令牌的最大值为XRLIM_BURST_FACTOR*timeout即6倍的超时,也就是说在一个timeout内,最多能发送6个差错消息。
重定向限速
路由子系统使用ip_rt_send_redirect来发送重定向消息,定义在ipv4/route.c中,该函数内部调用icmp_send实现,在它的限速基础上,使用
指数回退算法控制发送速率。
1void ip_rt_send_redirect(struct sk_buff *skb)
2{
3 struct rtable *rt = skb_rtable(skb);
4
5
6 /**//* No redirected packets during ip_rt_redirect_silence;
7 * reset the algorithm.
8 */
9 if (time_after(jiffies, rt->u.dst.rate_last + ip_rt_redirect_silence))
10 rt->u.dst.rate_tokens = 0;
11
12 /**//* Too many ignored redirects; do not send anything
13 * set u.dst.rate_last to the last seen redirected packet.
14 */
15 if (rt->u.dst.rate_tokens >= ip_rt_redirect_number) {
16 rt->u.dst.rate_last = jiffies;
17 return;
18 }
19
20 /**//* Check for load limit; set rate_last to the latest sent
21 * redirect.
22 */
23 if (rt->u.dst.rate_tokens == 0 || time_after(jiffies, (rt->u.dst.rate_last + (ip_rt_redirect_load << rt->u.dst.rate_tokens)))) {
24 icmp_send(skb, ICMP_REDIRECT, ICMP_REDIR_HOST, rt->rt_gateway);
25 rt->u.dst.rate_last = jiffies;
26 ++rt->u.dst.rate_tokens;
27
28 }
29}
重定向差错使用ip_rt_redirect_silence(默认为(HZ/50)<<10)、ip_rt_redirect_number(默认为9)和ip_rt_redirect_load(默认为HZ/50)3个量来控制发送的速率;rt->u.dst.rate_last记录上次发送的时间,rt->u.dst.rate_tokens累计发送总数,最大值为ip_rt_redirect_number;当两次发送的时间间隔超过ip_rt_redirect_silence或ip_rt_redirect_load<<rt->u.dst.rate_tokens,并且发送总数不超过ip_rt_redirect_number时,才允许发送一个,这样一来,在ip_rt_redirect_silence间隔内,每次发送的超时呈2的指数增长,达到了变减速发送的效果,直到总数达到ip_rt_redirect_number时停止发送,这是因为源主机可能忽略了重定向消息所以停止发送;当ip_rt_redirect_silence时间过后,又允许发送了,这是因为认为源主机没有更新路由所以又需要发送。
posted @
2015-05-18 19:52 春秋十二月 阅读(2786) |
评论 (0) |
编辑 收藏
摘要: 接上篇初始化与创建,本篇阐述Socket操作和销毁两部分的实现。
Socket操作
系统调用read(v)、write(v)是用户空间读写socket的一种方法,为了弄清楚它们是怎么通过VFS将请求转发到特定协议的实现,下面以read为例(write同理),并假定文件描述符对应的是IPv4 TCP类型的socket...
阅读全文
posted @
2015-05-03 16:55 春秋十二月 阅读(5262) |
评论 (0) |
编辑 收藏
摘要: 引言
在Unix的世界里,万物皆文件,通过虚拟文件系统VFS,程序可以用标准的Unix系统调用对不同的文件系统,甚至不同介质上的文件系统进行读写操作。对于网络套接字socket也是如此,除了专属的Berkeley Sockets API,还支持一些标准的文件IO系统调用如read(v)、write(v)和close等。那么为什么socket也支持文件IO系统调...
阅读全文
posted @
2015-05-03 16:31 春秋十二月 阅读(8614) |
评论 (0) |
编辑 收藏