最新版本地址:/Files/saha/CCS0.5.rar
参考资料:http://www.sluijten.com/winglet/ http://www.frayn.net/beowulf/theory.html
Monday, April 16, 2012 总体框架设计
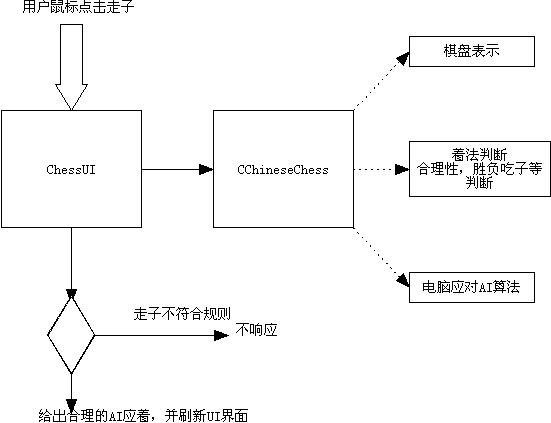
分离UI和AI算法,以利于以后不同平台的移植。其中AI算法部分做到平台无关性。
基本框架如下:
Thursday, April 19, 2012简单的UI及棋子移动实现
设置棋盘为16*16的数组。冗余部分便于棋子出界判断。
红棋值从8-14,黑棋值从16-22.其余部分全部为0

基本UI实现,基本象棋类实现。
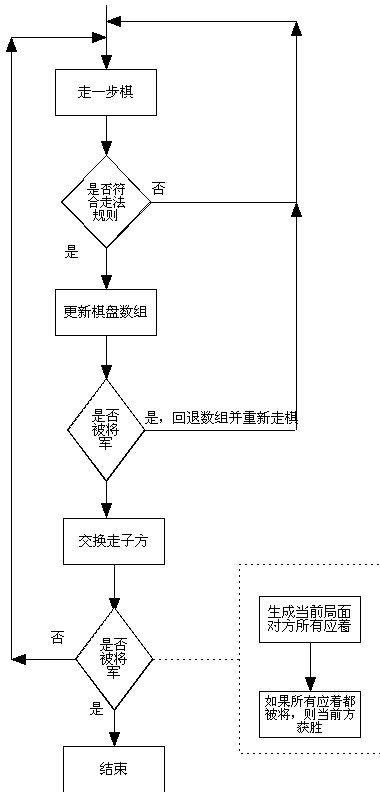
Tuesday, April 24, 2012实现棋子规则
1. 实现各个棋子的走法规则,将照面规则暂时未实现。
2. 实现了将军判断函数
3. 支持了翻转功能
4. 实现一些细节。结束后不允许再走棋,重新初始化棋盘等。
Thursday, April 26, 2012
重新实现棋子走法规则判断逻辑如下:
Friday, May 11, 2012
1.基本的人工智能算法 Alpha-Beta搜索.
其中
Alpha为搜索到的最好值,beta为对方的最坏值。一般起始时设置Alpha为负无穷,beta为正无穷。
之所以在递归内部要传入-beta和-alpha是为了反应对方走棋,及简化代码。即表示我方的最好值与对方的最坏值的对应关系。
int AlphaBeta(int depth, int alpha, int beta)
{
if (depth == 0)
{
return Evaluate(); //如果是第一层返回局面估计
}
GenerateLegalMoves(); //产生当前的所有下一步走法
while (MovesLeft()) //排序并遍历每一步走法
{
MakeNextMove(); //走一步
//递归搜索
val = -AlphaBeta(depth - 1, -beta, -alpha);
UnmakeMove(); //回退该步
//如果比最坏情况还坏,则返回最坏情况
if (val >= beta)
{
return beta;
}
//如果比最好情况差,则保持它为目前探索到的最好情况
if (val > alpha)
{
alpha = val;
}
}
return alpha; //返回目前找到的最好情况,其对应的走法即是搜索到的最好着法
}
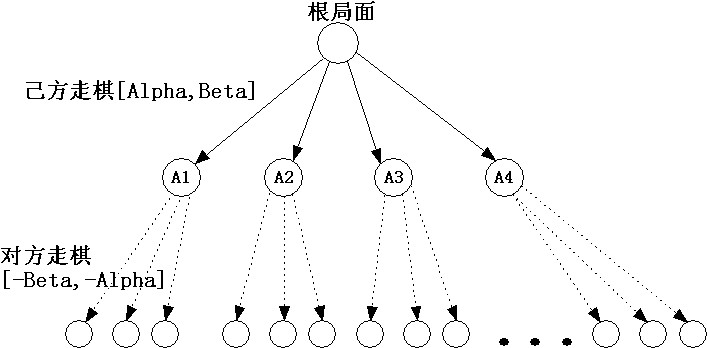
从根局面开始,默认的Alpha和Beta值分别为己方被杀和对方被杀的分值,递归搜索己方所有走法。
当一个走法返回的估计值A1>=Beta时,认为该节点是杀棋,则己方必选择该走法,因此其余节点不用再搜索,只要保存该走法并返回,称为beta截断。
当一个走法A1<=Alpha时,认为该节点比己方所能接受的最差结果更差,因此不保留该走法(这里无法做截断)。
当一个走法A1>Alpha && A1<Beta时,认为该节点是主变例节点(PV Principal Variation),需要保留该走法,并将Alpha设为A1,并继续探索剩余节点。
对于对方走棋时,只要将上下限取反调用同一alpha-beta函数即可。
2.增加自动测试功能,能电脑vs电脑测试
3.增加不同的电脑级别,以搜索层数划分
Wednesday, May 12, 2012
1.增加声音开关功能
2.悔棋功能,最多支持悔512步
V0.2版本完成
Wednesday, May 30, 2012
1.空着向前裁剪
空着裁剪的含义就是如果当前的局势优势巨大,即使不走这一步棋让对方走还是能产生beta截断,相当于少搜索了一层,能大大缩短搜索的时间。
存在的一个问题是在残局阶段,当存在无棋可走的情况下,使用空着恰恰避开了这种问题,从而导致估计不准确,因此在残局时需要进行判断来决定是否使用空着裁剪,一种流行的简单做法是到了残局就不进行空着裁剪。
2.静态搜索
相对稳定的局面称为“安静”(Quiet)或“寂静”(Quiescent)的局面,它们需要通过“静态搜索”(Quiescence Search)来达到。
目前采用简单的策略即只考虑所有的吃子走法来进行搜索。
3.局面检验Zobrist键值
Zobrist用一个整型数值来代表一个棋的局面,目前采用的做法是对于每一个棋盘位置的14种情况(7种红棋,7种黑棋)产生14*256个随机数,每一个棋局是所有存在棋子的棋盘位置的随机数异或而得到的一个整型值(称为Zobrist键值),据前人经验这种表示方法出现冲突的概率非常小。这种表示方法的另一个好处是去除一个棋子和添加一个棋子都是异或操作(由于异或的异或得到原来的值),利用Zobrist键值可以做重复局面判断,长将判断。
V0.3版本完成
Thursday, June 14, 2012
1.修改Zobrist键值从原来的32位无符号变为int64(据前人经验32位存在冲突有很多争论,而64位虽然仍存在冲突的局面,但是实战中这种情况非常罕见)。
2.修改重复局面检查函数,从以前的把所有历史局面全部检查到现在的只检查最近6步,以减少不必要的检查。
3.增加主变例搜索优化。即对当前搜索存在PV走法时,对以后的每一个节点搜索的搜索上下限先设为[-Alpha-1, -Alpha],如果当前节点的值比pv值要大则重新对该节点进行正常搜索,否则丢弃该节点进行下一个节点的搜索。据统计可以提供10%的搜索效率,在程序中直接使用没有明显的变化。。。
4.增加置换表。
基本思想:每一个搜索过的局面都记录他的平均值,以避免以后搜索到同一局面时的重复计算工作。
使用zobrist-hash值记录每个搜索过的局面。一个置换表的元素包括以下结构:
CCSINT64 ulZobristKey; //hash-key
CCSUINT32 depth : 8; //搜索深度
CCSUINT32 flags : 2; //标志,分为PV,BETA,ALPHA3种
CCSUINT32 mvBest : 22; //该局面下的最佳走法
CCSINT32 nValue; //该局面下的估计值
其中flags3种标志代表不同含义。
pv表示主变例搜索的结果,即这时的nValue是个精确值,可以直接使用
BETA表示该局面的估计值至少为nValue。
ALPHA表示该局面的估计值最多为nValue。
在alpha-beta搜索中的使用如下:
if (HASH_PV == pItem->flags)
{
return nValue;
}
if (HASH_BETA == pItem->flags && nValue >= nBeta)
{
return nBeta;
}
else if (HASH_ALPHA == pItem->flags && nValue <= nAlpha)
{
return nAlpha;
}
return VALUEUNKNOWN;
是否正确还有待测试。
使用置换表时除了判断zobrist-hash值是否相同外,还要判断当前走棋方是否与记录中的走棋方一致,不一致不能替换.
Friday, July 27, 2012
修改置换表的使用方式
去除输棋后的不文明用语
在腾讯游戏中进行测试,使用中等水平在1000分以下玩家中胜率95%+
posted on 2012-04-16 17:44
saha 阅读(755)
评论(0) 编辑 收藏 引用 所属分类:
棋类AI