|
置顶随笔
#
摘要: 项目地址: http://github.com/adoggie/TCE 从12年的时候开始想做一个rpc的东东,这些年来陆陆续续往里面增加不同的功能、特点。
tce是一个 全栈的东西,并不是 protocalbuf,或者接近 thrift。 支持语言: csharp,python,java,objc,javascript,actionscript,c++,我想这些够了。
阅读全文
摘要: 有问题的c++通信代码的识别,希望写c++的码农不要犯同样的错 阅读全文
近日获得一份微信营销系统的代码,看其功能比较丰富,便开始窥其代码的实现。为了将整个业务系统跑起来,还真的花了不少时间琢磨,幸好不负我的几十年功力,终于将运营环境和开发环境搭建成功,并将系统的授权代码全部剔除(软件厂商控制使用授权)。 准备条件: 1. 互联网服务器(必须开启80,443端口) 2. 申请域名,且绑定到服务器 3. 微信公众号申请,并通过微信认证(300人民币) 先上系统部署图 : 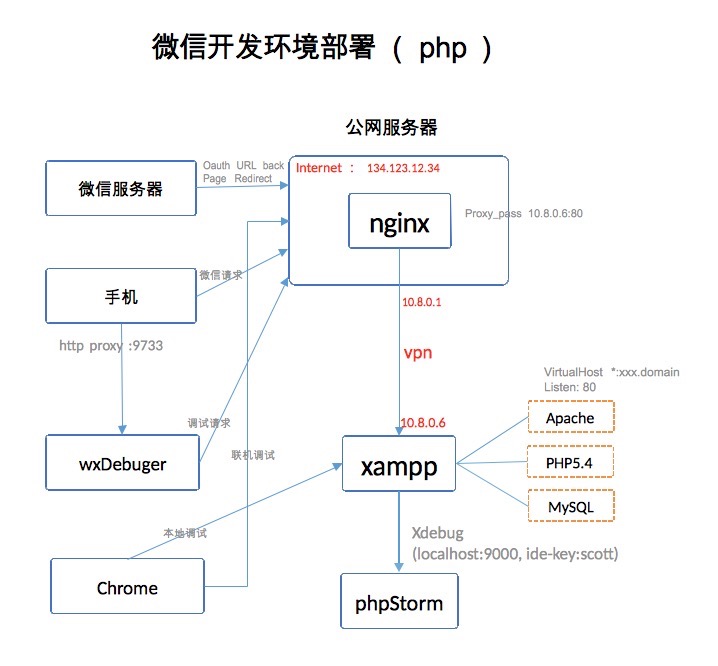 几个部件需要介绍一下: 1. xampp : 开发php的套件,包含了apache,php,mysql,用起来很简单,不过我是部署在linux和mac 上,要留意的是文件目录访问权限的问题,mac下 所有的服务进程跑在root用户下; 2. phpstrom: 开发php的ide,出自jetbrains(我个人理解是目前开发工具最牛逼的公司)。 管理数据库推荐 DataGrip 软件。 3. xdebug : 这个东西是php与phpstrom的调试接口 ,apche接收到http请求,转给php解释器,php解释器再phpStorm进行调试互动(建立xdebug的9000端口的tcp连接),开发者可以在phpStorm里面随意下断点。 注意: 在php.ini中需配置 ide-key:scott , 我是在nginx的转发头里面添加了 XDEBUG_SESSION=scott,令所有经过 nginx 服务器的http请求都被转到phpStorm中,否则无法实现代码断点。 4. wxDebuger: 这是微信提供的本地微信页面调试工具,开发这可以利用winre来调试手机上的页面,也可以脱离手机,直接调试微信页面(要调试微信的wxjssdk必须使用wxDebuger)。 5. nginx : 在公网服务器部署nginx作为http服务器,接收各种用户请求,并将其转发到xampp。 6. vpn : 这个是关键,为了实现本地开发调试的目的,我在公网服务器上部署了openvpn,并在mac开发机上部署了xampp,phpstorm等,并安装vpn客户端 Tunnelblick,其自动拨号到公网服务器,获得地址10.8.0.6,nginx将http请求转发到了我本地的开发机器上,这样我可以很方便的进行远程和本地调试了。 主要的功能描述: 1. 手机、浏览器、调试器 发起的http请求到达公网服务器,nginx通过vpn转发到本地开发机,开发者在phpstorm中断点调试代码,并将处理结果按原路返回。 2. 微信服务器的主要作用是获取 粉丝信息、oauth认证回调、服务器鉴权等功能 , HTTP(302)是 oauth的灵魂 。 3. 这种配置架构很灵活的可以将开发模式切换到部署模式,只需要将xampp部署到公网服务器,并在 nginx的反向代理指到本地xampp服务即可。 附录 nginx.conf server {
listen 80;
server_name wx.xxxx.com www.xxxx.com;
proxy_set_header X-real-ip $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://10.8.0.6:8081;
proxy_set_header Cookie "$http_cookie;XDEBUG_SESSION=scott";
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-real-ip $remote_addr;
}
}
摘要: 6.x 版本系统自带python 2.6,升级2.7的方式网上有很多版本,本人试用下来觉得诸多不便。
工作项目中越来越多的开发特性必须要求工作在py2.7版本中,例如: django 1.7+已经不支持 py2.6.x了; pyBox2d也不支持。
这次选择的最新版本 python 2.7.11 阅读全文
访问sf,记录下一下代码 (注册sf的app,登记 callback-url,执行sql查询) #coding:utf-8
__author__ = 'scott'
import imp
imp.load_source('init','../init_script.py')
import urllib2,urllib,json,sys,os
import traceback,threading,time,struct,os,os.path,shutil,distutils.dir_util,array,base64,zlib,struct,binascii
import datetime
from libs.python.lemon import webapi
callback = 'http://localhost:8002/oauth'
client_id = '3MVG9ZL0ppGP5UrC_wQ8U02mOhowPKwjeaaLsWZ3BcYYVqiSsy1rL_D2h6qG.rGPnb_j6IcgLHPdhmvomzDFj'
client_secret = '9046731979xxxxxxx'
def accessToken(request,code,state):
url = 'https://login.salesforce.com/services/oauth2/token'
data = {
'grant_type':'authorization_code',
'code':code,
'client_id':client_id,
'client_secret':client_secret,
'redirect_uri':callback
}
result = ''
try:
result = urllib2.urlopen(url,urllib.urlencode(data) )
except:
traceback.print_exc()
result = result.read()
return json.loads( result )
def oauth(request):
cr = webapi.SuccCallReturn()
code = webapi.GET(request,'code','')
state = webapi.GET(request,'state','')
cr.result=[code,state]
token = accessToken(request,code,state)
cr.result.append(token)
print token
try:
sqlExecute(token['access_token'],token['instance_url'])
except:
traceback.print_exc()
return cr.httpResponse()
import cookielib
# -H "Authorization: OAuth token" -H "X-PrettyPrint:1" "
def sqlExecute(token,url_host):
httpHandler = urllib2.HTTPHandler(debuglevel=1)
httpsHandler = urllib2.HTTPSHandler(debuglevel=1)
opener = urllib2.build_opener(httpHandler, httpsHandler)
urllib2.install_opener(opener)
sf_cmd_query="%s/services/data/v20.0/query/?%s"%(url_host, urllib.urlencode({'q':'select count() from account'}))
headers = {
'Authorization':'OAuth %s'%token,
'X-PrettyPrint':1
}
httpReq = urllib2.Request( sf_cmd_query,headers=headers )
r = opener.open(httpReq).read()
print r
pass
url1 = """https://login.salesforce.com/services/oauth2/authorize?response_type=code&client_id=%s&redirect_uri=%s&state=first"""%(client_id,callback)
def launchBrowserForOAuth():
import webbrowser
webbrowser.open(url1)
if __name__ == '__main__':
launchBrowserForOAuth()
python内部数据容器有dict和list两种 ,工作中最常用的方式是定义一些数据结构(数据即代码),例如:
1 frog={'name':'scott',
2 'age':2,
3 'parts':{
4 'eye':'green','leg':85
5 },
6 ''friend":['moee','wee'],
7 "hometown":'affica'
8 } frog对象定义了小动物的某些属性,访问frog对象属性时,通过 dict,list的取值方法进行访问,例如: print frog['name'] print frog['friend'][0] 有时觉得这种表达方式太原始了,需要改进,最好是以 '.'方式访问对象属性,例如: print frog.name 代码来开始和结束吧, class _x 1 class _x:
2 """
3 从简单数据类型转换成python对象
4
5 p = _x({'name':'boob','body':{'color':'black'},'toys':[1,2,3,],'age':100})
6 print p['toys'][1]
7 print len(p.toys)
8 print p.body.colors
9 """
10 def __init__(self,primitive):
11 self.data = primitive
12
13 def __getattr__(self, item):
14 value = self.data.get(item,None)
15 if type(value) == dict:
16 value = _x(value)
17 return value
18
19 def __len__(self):
20 return len(self.data)
21
22 def __str__(self):
23 return str(self.data)
24
25 def __getitem__(self, item):
26 value = None
27 if type(self.data) in (list,tuple):
28 value = self.data[item]
29 if type(value) in (dict,list,tuple):
30 value = _x(value)
31 elif type(self.data) == dict:
32 value = self.__getattr__(item)
33 return value
相关技术: haproxy_keepalived_nginx_uwsgi_gevent_django
之前部署django一直采用 apache + mod_wsgi,用得倒也没啥问题,看到越来越多的人采用nginx部署,所以也尝试了一下,结果很让人欣喜。
nginx够小够简洁,编译、配置相当简单,但要知道她仅仅是个静态webserver,动态功能需要搭配相应的cgi来实现;
uwsgi是个啥东西,看其官方文档还真写的相当详细,功能很丰富,但我的需求可能只会使用其30%的功能;
uwsgi可以认为是python代码运行的loader,或者是容器(container),这有点像java的container(resin,tomcat)。看了其配置文档,很是惊喜,其不仅可以配置为多进程+多线程模式,也可以配置为单进程+多线程模式,并能保持高并发高销率,非常感兴趣。
一直以来自己总在寻找一种 高效、灵活的django的应用容器。
apache默认都是多进程模式,http又是无状态的,不同的请求被分派到不同的进程处理,request处理都是隔离的。多进程带来的问题是高昂的系统开销(apache也支持多线程处理)。
这种隔离又带来了诸多不便,request之间不能共享状态、数据和协作,不能很好的完成与外部系统的协同工作(例如request共享同一个服务器的socket连接或者访问控制某个rs232端口)
所以很想有种类似java的应用容器这样的东东。
接触了gevent,其核心是io异步分派,单线程模拟多协程来对应用层多任务的支持,几近疯狂io效率得到了我的认可。ps:八过smp系统就应该启动多个gevent服务,不然其他核心数都浪费了。
采用gevent+django的模式搭建了自己得app容器,也跑了几个项目,总体效果还是可以。
nginx+uwsgi+django 的配合开始应用到新项目中
上海交通违章查询网站: http://www.shjtaq.com/Server1/dzjc_new.asp 验证码图片获取地址: http://www.shjtaq.com/Server1/validatecode.asp?m=2304.046
服务器通过页面请求的session-id来区分之后提交的验证码。 第一次请求查询页面时,服务器将访问session(cookie)传到客户端,之后的查询和验证码获取时客户端携带之前的cookie传送到服务器,服务器端保存着当前 session-id与验证码 的对应关系。
查询返回记录可通过 xpath或者 beautifulsoup进行解析
程序使用python完成,也是个简单的小爬虫,scrapy 之类的没必要使用了,gevent完成异步通信。
交通网的验证码生成还是比较简单,做自动识别可找几个简单的图形识别程序即可。
如若不行,则人工输入喽
开始抓yixun.com的商品信息,开始很开心,但一下子来了问题。http请求回来的商品分类条目用<a href=>, 但这个href不能直接使用,因为页面加载之后会启动js程序(一般都是jquery)对页面element进行配置和处理,例如:设置风格、事件等等。
yixun玩了个防页面过期的小技巧:
>每个请求page在server都会产生一个有效期变量XY(具体算法不详),
>如果获取商品<a>直接请求,server将返回失败,因为<a href>并未包含XY
>page加载完成之后js代码设置<a>被点击时触发事件E,E将XY添加到<a href>内
>然后可以正确请求了 易迅防止请求页面过期,在主页中设置了一下参数: <script type="text/javascript"> window.yPageId = '17384560'; window.yPageLevel = '2';</script>
在页面内容中显示 <a ytag="40037" href="http://searchex.yixun.com/705938t705942-1-/" target="_blank">路由器</a> 注意: 返回的html就是如此
但如果用户点击(左键或者右键)此 node对象时,js代码会动态插入一个YTAG的变量
未点击:
<a ytag="40037" href="http://searchex.yixun.com/705938t705942-1-/" target="_blank">路由器</a>
点击:
<a ytag="40037" href="http://searchex.yixun.com/705938t705942-1-/?YTAG=2.1738456040037" target="_blank">路由器</a>
变量生成方式在这个js中实现:
此js 使用了jquery,页面完成加载之后,将配置页面元素的onclick行为,如果点击了页面元素,将YTAG属性加入到商品<a href=""/>中去
js代码凌乱可以使用: 进行格式化观察
js代码: G.header.search = { init: function() { G.header.search.event(); G.header.search.setInputStyle(); G.header.search.autoComplete(); },G.header.search.init();query: function() { var input = $("#q_show"), v = $.trim(input.val()), c = $("#cate_show").val(), ret = true, href = input.attr("_href"); if (v === G.header._Q_SHOW_DEF_TEXT && href) { window.location.href = href; ret = false; } else if (v === "" || v === G.header._Q_SHOW_DEF_TEXT) { if (!c || (c && c == "")) { input.focus(); ret = false; } } if ($('#q_show').parents("form").find('input[name="YTAG"]').length === 0) { var ytag = $('#q_show').parents("form").find('input[type="submit"]').attr("ytag"); var YTAG = (window.yPageLevel || 0) + '.' + (window.yPageId || 0) + ytag; $('#q_show').parents("form").append($('<input type="hidden" name="YTAG" value="' + YTAG + '" />')); } return ret; }
程序定义了G.header.search对象,并进行初始化init() ,query()是用户点击查询时触发使用 init()内部配置了query函数,用于鼠标点击时候生成YTAG属性 看代码就很简单了
YTAG生成方式就是 window.yPageLevel+'.'+window.yPageId + <a ytag="40037"> 这样一个商品条目的href就获得了
tkinter工作在主线程,而gevent是单线程工作,如何整合在一起? 瞅到一段代码,迅速收藏 1 import gevent
2 from gevent import socket
3 import Tkinter as tk
4
5 class SockLoop(object):
6 def __init__(self, callback):
7 self.callback = callback
8
9 def __call__(self, sock, client):
10 while 1:
11 mes = sock.recv(256)
12 ret = self.callback(client, mes)
13 if ret is not None:
14 sock.send(ret)
15
16 def socket_server(port, callback):
17 ssock = socket.socket(socket.AF_INET, socket.SOCK_STREAM, socket.IPPROTO_TCP)
18 ssock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
19 ssock.bind(('', port))
20 ssock.listen(5)
21
22 while 1:
23 sock, client = ssock.accept()
24 gevent.spawn(callback, sock, client)
25
26 class App(object):
27 def __init__(self, root):
28 self.greenlet = None
29 self.root = root
30 self._build_window(root)
31 self.root.after(100, self._connect)
32
33 def add_text(self, text):
34 cleaned_string = text.replace('\r', '')
35 self.text.insert(tk.END, cleaned_string)
36
37 def quit(self):
38 self.root.quit()
39
40 def _build_window(self, root):
41 self.frame = tk.Frame(root)
42 self.text = tk.Text(self.frame)
43 self.quit_button = tk.Button(self.frame, text="Quit", command=self.quit)
44 self.text.pack()
45 self.quit_button.pack()
46 self.frame.pack()
47
48 def _connect(self):
49 self.greenlet = gevent.spawn(
50 socket_server,
51 8080,
52 SockLoop(lambda cl, txt: self.add_text("%s: %s" % (cl, txt))))
53 self.gevent_loop_step()
54
55 def gevent_loop_step(self):
56 gevent.sleep()
57 self.root.after_idle(self.gevent_loop_step)
58
59
60 if __name__ == '__main__':
61 root = tk.Tk()
62 app = App(root)
63 root.mainloop()
俺不是果粉,但开发必须mac
参加的开发者大会,老外没一个不是mac的,也的确如此,mac是开发神器,虽然贵点,但还是很值,对得起他的身价 。
这是一种态度,价值观世界观的体现
linux+windows的完美结合,不!! ui远超windows
14.5k mac pro 15 retina 8G 内存 250 G ssd ,都配置差了点,但目前够了,有钱了再买台高配的,然后imac,还有那个外星桶的工作站
酷毙!
写代码,写好代码其实并不难,但如果要做好文档,能完整阐述清楚自己的构思、想法和逻辑结构,这比较难,自己也缺少这方面的耐心。 很多opensource的代码根本不需要文档也能一目了然,这是一种定力 多年前的项目中使用到python和ffmpeg, 网络上搜索了一下,均不能满足自己的要求。ffmpeg的python绑定提供的均是文件级的访问控制,也就是说没有暴露更多的可控接口来用。 所以还是一切都自己来做 ffmpeg采用0.81版本以上,当时发现mov文件在0.71以下无法正常解码,到0.81则解决了此问题。 python包装ffmpeg的方式很多,最好的可能就是swig,但太烦了,最后选择ctypes来访问ffmpeg接口。 如果直接使用ffmpeg的api接口也不太合适,因为要暴露很多ffmpeg的接口、数据类型、常数定义等。 所以我是这么处理: 1. 编写一个功能动态库来包装ffmpeg,提供基本的业务功能 ,屏蔽ffmpeg细节,这里叫ffmpeg_media_codec.dll 2. 用ctypes包装此ffmpeg_media_codec.dll,这里是ffmpeg.py 3. 业务代码使用ffmpeg.py提供的接口访问、解码多媒体文件 代码: http://sw2us.com/static/projects/py-ffmpeg/ffmpeg_media_codec.dll 暴露的c接口 1 ffmpeg lib interface list:
2 ===========================
4 typedef unsigned char StreamByte_t;
6 struct MediaStreamInfo_t{
7 int codec_type;
8 int codec_id;
9 int width;
10 int height;
11 int gopsize;
12 int pixfmt;
13 int tb_num;
14 int tb_den;
15 int bitrate;
16 int frame_number;
17 int videostream; //视频流编号
18 };
19
20 struct MediaVideoFrame_t{
21 StreamByte_t * rgb24;
22 size_t size;
23 int width;
24 int height;
25 unsigned int sequence; //控制播放顺序
26 unsigned int duration; //播放时间
27 };
28
29 struct MediaPacket_t{
30 StreamByte_t* data;
31 size_t size;
32 AVPacket * pkt;
33 int stream; //流编号
34 int dts;
35 int pts;
36 size_t sequence;
37 size_t duration;
39 };
40
41 struct MediaFormatContext_t;
42
43 //解码器
44 struct MediaCodecContext_t{
45 AVCodecContext * codecCtx; //AVCodecContext*
46 AVCodec * codec;
47 int stream; //流编号
48 AVFrame * rgbframe24; //
49 AVFrame* frame; //
50 StreamByte_t* buffer;
51 size_t bufsize;
52 void * user;
53 MediaStreamInfo_t si;
54 };
55
56 struct MediaFormatContext_t{
57 AVFormatContext * fc; //AVFormatContext*
58 MediaStreamInfo_t video; //视频信息
60 };
66 #ifdef __cplusplus
67 extern "C" {
68 #endif
69
70 int InitLib(); //初始化解码库
71 void Cleanup(); //
73 MediaCodecContext_t* InitAvCodec(MediaStreamInfo_t* si); //根据媒体类型分配解码器对象
74 void FreeAvCodec(MediaCodecContext_t* codec); //释放解码器对象
76 MediaVideoFrame_t * DecodeVideoFrame(MediaCodecContext_t* ctx,MediaPacket_t* pkt); //送入媒体包进行解码,返回视频帧
77 void FreeVideoFrame(MediaVideoFrame_t* frame); //释放视频帧
79 MediaPacket_t * AllocPacket(); //分配一个流媒体包对象(用于网传)
80 void FreePacket(MediaPacket_t* pkt); //释放流媒体包
82 MediaFormatContext_t* InitAvFormatContext(char * file); //媒体文件访问上下文,申请
83 void FreeAvFormatContext(MediaFormatContext_t* ctx); //释放
84 MediaPacket_t* ReadNextPacket(MediaFormatContext_t* ctx); //读媒体文件一个数据包
85 void ReadReset(MediaFormatContext_t* ctx) ; //重置媒体访问读取位置
86 int SeekToTime(int timesec) ; //跳跃到指定时间 ffmpeg.py 包装: 1 import ctypes
2 from ctypes import *
5 _lib = cdll.LoadLibrary('ffmpeg.dll')
6
7 _int_types = (c_int16, c_int32)
8 if hasattr(ctypes, 'c_int64'):
9 # Some builds of ctypes apparently do not have c_int64
10 # defined; it's a pretty good bet that these builds do not
11 # have 64-bit pointers.
12 _int_types += (ctypes.c_int64,)
13 for t in _int_types:
14 if sizeof(t) == sizeof(c_size_t):
15 c_ptrdiff_t = t
16
17 class c_void(Structure):
18 # c_void_p is a buggy return type, converting to int, so
19 # POINTER(None) == c_void_p is actually written as
20 # POINTER(c_void), so it can be treated as a real pointer.
21 _fields_ = [('dummy', c_int)]
26 class MediaStreamInfo_t(Structure):
27 _fields_ = [
28 ('codec_type', c_int),
29 ('codec_id', c_int),
30 ('width', c_int),
31 ('height', c_int),
32 ('gopsize', c_int),
33 ('pixfmt', c_int),
34 ('tb_num',c_int),
35 ('tb_den',c_int),
36 ('bitrate',c_int),
37 ('frame_number',c_int),
38 ('videostream',c_int),
39 ('duration',c_int),
40 ('extr',POINTER(c_char)), #解码器 额外hash表数据
41 ('extrsize',c_int),
42 ]
43
44 class MediaVideoFrame_t(Structure):
45 _fields_=[
46 ('rgb24',POINTER(c_char)),
47 ('size',c_uint),
48 ('width',c_int),
49 ('height',c_int),
50 ('sequence',c_uint),
51 ('duration',c_uint)
52 ]
53
54 class MediaPacket_t(Structure):
55 _fields_=[
56 ('data',POINTER(c_char)),
57 ('size',c_uint),
58 ('pkt',c_char_p),
59 ('stream',c_int),
60 ('dts',c_int),
61 ('pts',c_int),
62 ('sequence',c_uint),
63 ('duration',c_uint)
64 ]
65
66
67 class MediaCodecContext_t(Structure):
68 _fields_=[
69 ('codecCtx',c_char_p),
70 ('codec',c_char_p),
71 ('stream',c_int),
72 ('rgbframe24',c_char_p),
73 ('frame',c_char_p),
74 ('buffer',c_char_p),
75 ('bufsize',c_uint),
76 ('user',c_char_p),
77 ('si',MediaStreamInfo_t)
78 ]
79
80 class MediaFormatContext_t(Structure):
81 _fields_=[
82 ('fc',c_char_p),
83 ('video',MediaStreamInfo_t)
84 ]
85
86 InitAvCodec = _lib.InitAvCodec
87 InitAvCodec.restype = POINTER(MediaCodecContext_t)
88 InitAvCodec.argtypes = [POINTER(MediaStreamInfo_t)]
89
90
91 FreeAvCodec = _lib.FreeAvCodec
92 FreeAvCodec.restype = None
93 FreeAvCodec.argtypes = [POINTER(MediaCodecContext_t)]
96 DecodeVideoFrame = _lib.DecodeVideoFrame
97 DecodeVideoFrame.restype = POINTER(MediaVideoFrame_t)
98 DecodeVideoFrame.argtypes = [POINTER(MediaCodecContext_t),POINTER(MediaPacket_t)]
100 FreeVideoFrame = _lib.FreeVideoFrame
101 FreeVideoFrame.restype = None
102 FreeVideoFrame.argtypes = [POINTER(MediaVideoFrame_t)]
104 AllocPacket = _lib.AllocPacket
105 AllocPacket.restype = POINTER(MediaPacket_t)
106 AllocPacket.argtypes = []
109 FreePacket = _lib.FreePacket
110 FreePacket.restype = None
111 FreePacket.argtypes = [POINTER(MediaPacket_t),c_int]
113 InitAvFormatContext = _lib.InitAvFormatContext
114 InitAvFormatContext.restype = POINTER(MediaFormatContext_t)
115 InitAvFormatContext.argtypes = [c_char_p]
117 FreeAvFormatContext = _lib.FreeAvFormatContext
118 FreeAvFormatContext.restype = None
119 FreeAvFormatContext.argtypes = [POINTER(MediaFormatContext_t)]
122 ReadNextPacket = _lib.ReadNextPacket
123 ReadNextPacket.restype = POINTER(MediaPacket_t)
124 ReadNextPacket.argtypes = [POINTER(MediaFormatContext_t)]
127 ReadReset = _lib.ReadReset
128 ReadReset.restype = None
129 ReadReset.argtypes = [POINTER(MediaFormatContext_t)]
130
131 SeekToTime = _lib.SeekToTime
132 SeekToTime.restype = c_int
133 SeekToTime.argtypes = [POINTER(MediaFormatContext_t),c_int]
134
135 FlushBuffer = _lib.FlushBuffer
136 FlushBuffer.restype =None
137 FlushBuffer.argtypes = [POINTER(MediaCodecContext_t)]
138
139 InitLib = _lib.InitLib
140 InitLib.restype =None
141 InitLib.argtypes = []
142
143 Cleanup = _lib.Cleanup
144 Cleanup.restype =None
145 Cleanup.argtypes = [] 好了,看看如何使用这些接口 视频文件播放: http://sw2us.com/static/projects/py-ffmpeg/test_qt.py
从事webgis及其应用有些时日,实验性质的东西一直没有被大规模应用,一路走来颇多辛苦 现将代码放出,有兴趣的朋友可看看,包括地图数据处理编译、地图渲染服务程序、wms程序、tce
近一周时间都在玩p2p,本来以为实现很简单,但做起来实属不易 。 Udp穿透Nat会遇到多种Nat类型: 1.FULL CORE 2. RESTRICT 3. PORT-RESTRICT 4. SYMMETRIC 1-3三种NAT实现穿透很简单,问题在于处理第4种类型:对等NAT SYMMETRIC NAT的工作模式区分在于内网通过NAT时分配的外部端口的方式不同,这又有三种情况: 1. 端口递增: 通常新端口号会是前一次分配端口号加1或者加固定值 2. 端口在当前NAT最新端口的左右区间: 例如当前NAT外网端口P,那新的分配端口会落在 -N < P < N 3. 随机分配SR (这个根据当时NAT的网络情况参数等作为函数f(x)的因子决定) 这第三种分配方式,目前无解,只要任意一端存在SR,则无法穿透 当然很多技术研究者提出了如何猜测动态端口的方案,例如:统计技术的使用,服务器可对固定NAT进行采样分析等等。。 这个很难哦! 面对SR我直接放弃了,还真不巧,测试了3,4个网络环境的NAT,居然50%是SR,50%是SYMMETRIC的1,2种类型 。 还是老实的服务器中转把! 一些p2p资料供参考: http://114.215.178.29/static/p2p
应用中经常用pyCrypto 来生成用户Token等相关信息,够简单,所以贴代码分享 部分代码被关闭或者打开,使用者请自行调整,如果了解rsa很简单理解一下代码 1 GCONFS={
2 'auth_public_keyfile':'public.rsa',
3 'auth_private_keyfile':'private.rsa'
4 }
5
6
7 def encrypt_des(key,text):
8 from Crypto.Cipher import DES
9 import base64
10 from Crypto import Random
11 #iv = Random.get_random_bytes(8)
12 des = DES.new(key, DES.MODE_ECB)
13 reminder = len(text)%8
14 if reminder ==0: # pad 8 bytes
15 text+='\x08'*8
16 else:
17 text+=chr(8-reminder)* (8-reminder)
18 #text+=' '*(8-len(text)%8)
19 return des.encrypt(text)
20 #return base64.encodestring(des.encrypt(text))
21
22 def decrypt_des(key,text):
23 from Crypto.Cipher import DES
24 import base64
25 # print key
26 des = DES.new(key, DES.MODE_ECB)
27 text = des.decrypt(text)
28 pad = ord(text[-1])
29 if pad == '\x08':
30 return text[:-8]
31 return text[:-pad]
32
33
34 def rsa_generate():
35 from Crypto.PublicKey import RSA
36 from Crypto import Random
37 random_generator = Random.new().read
38 key = RSA.generate(1024, random_generator)
39
40
41 #print key.publickey().encrypt('123213213123213213',20)
42 public = key.publickey().exportKey()
43 #print key.publickey().exportKey()
44 private = key.exportKey()
45 return public,private
46
47 def rsa_encrypt(key,text):
48 '''
49 传入私钥key和待加密明文数据text
50 自动生成8字节长度随机密码P,用P将text进行des加密生成E,
51 用私钥key加密P生成P2
52
53 key - private key
54 text - orignal text
55 @return: [P2+E] RSA加密的des秘钥 + 加密的密文
56 '''
57 import uuid
58 from Crypto.PublicKey import RSA
59 deskey = hashlib.md5(uuid.uuid1().hex).hexdigest()[:8]
60 text = encrypt_des(deskey,text)
61
62 key = RSA.importKey(key)
63 r = key.encrypt(deskey,32)
64
65 return r[0]+text # 加密的key,和des加密的数据
66
67 def rsa_decrypt(key,text):
68 from Crypto.PublicKey import RSA
69 try:
70 rsa = RSA.importKey(key)
71 deskey = text[:128]
72 text = text[128:]
73 deskey = rsa.decrypt(deskey)
74 return decrypt_des(deskey,text)
75 except:
76 return ''
77
78 class Cipher:
79 def __init__(self):
80 # self.pubkey = pubkey
81 # self.privkey = privkey
82 pass
83
84 def encrypt(self,key,text):
85 return rsa_encrypt(key,text)
86
87
88 def decrypt(self,key,text):
89 return rsa_decrypt(key,text)
90
91 @staticmethod
92 def getCipher():
93 try:
94 cip = Cipher()
95 return cip
96 except:
97 traceback.print_exc()
98 return None
99
100 def encryptToken(user):
101 '''
102 用户信息转换为token
103 '''
104 token=''
105 try:
106 d = json.dumps(user)
107 # f = open(GCONFS['auth_public_keyfile'],'r')
108 # pubkey = f.read()
109 # f.close()
110 pubkey = ENCRYPT_PUBKEY
111 # d = Cipher.getCipher().encrypt(pubkey,d) #rsa encrpyt
112 token = base64.encodestring(d).strip()
113 #print 'token size:',len(token)
114 except:
115 print traceback.format_exc()
116 token = ''
117
118 return token
119
120 def decryptToken(token):
121 user = None
122 try:
123 # f = open(GCONFS['auth_private_keyfile'],'r')
124 # privkey = f.read()
125 # f.close()
126 privkey = ENCRYPT_PRIVKEY
127 d = base64.decodestring(token)
128 # d = Cipher.getCipher().decrypt(privkey,d) #rsa decrept
129 user = json.loads(d)
130 except:
131 #print traceback.format_exc()
132 pass
133 return user
系统中,用户的消息在移动设备与接入服务器建立的Tcp长连接上传递。这些消息包括:文本,复合文本,位置信息,音频剪辑,图像等等。 发送者传送消息到平台系统内部并将消息写入gridfs,待接收者上线时平台将消息推送至接收者。 考虑到带宽利用,接收者得到的消息将不包含二进制数据,例如: 音频,图像等等。 这要求接收者对平台发起一次获取消息包内指定的音频和图像数据的请求。 移动端向平台请求二进制数据的情况还包含 【离线文件传送】场景 。 二进制数据往往是指那些数据量比较大的对象,这些对象在移动两端交换时,交互通道将不占用与接入服务器的连接通道,而是通过nginx传送到平台内部; 同样接收者获取二进制数据也是通过nginx获取。这种请求是HTTP的。 这里整理的是如何在平台部署 【负载均衡的集群的分布式的文件服务】 nginx : http服务,提供反向代理和负载均衡服务(集群可用DNS或考虑LVS方案) mongodb+gridfs : 用于文件服务提供,其内置gridfs提供了分布式,海量存储的方案 gevent+webpy : nginx直接读取gridfs是不合适的,配置了cgi才能完成特定功能,这里使用webpy,比django更轻更好用。 webpy的作用是接收到上传和下传文件的请求,读写gridfs文件内容给移动端。 gevent是高效的通信框架,虽然单线程工作,但性能非常的好; 用好gevent关键在与外部的io必须全部都是异步的,例如: 数据库,文件磁盘访问等等。 mongodb对gevent已经支持,gevent对webpy,django,psycopg2支持也相当的好,所以要提供webservice服务那就考虑用gevent+webpy或django把,性能是杠杠的,比 apache+mod_wsgi要好很多 ,而且gevent是进程内的不同的HTTP REQUEST可以是共享数据的,这一点非常诱惑(apache+mod_wsgi的REQUEST可是隔离的哦!除非您通过redis的PUB/SUB实现两个REQUEST的通信) 关注的问题: 1.下传大文件时的处理 如果直接用nginx当然没有这个问题 ,但用webpy读取文件返回HttpResponse时问题来了,总不至于读取整个文件,然后再return。 这种方式在php有flush方法,python只能用yield来做 2.上传大文件时的处理 当接收到http的文件POST请求时,文件已经全部缓存到web服务器,如果同时几千个文件上传在进行,服务器就会被挤爆,这也是很多网站不允许大文件上传的缘故吧。关于这个问题,我想就需要修改一下webpy关于文件上传的处理代码了,将接收到的文件数据以流的形式写入到gridfs里去作为临时文件被缓存,等完全接收文件时,才通知到handler代码,这样必定高效很多(新的问题又来了,会不会把gridfs搞爆掉! 处理时考虑延时缓存提交gridfs把)。 BUF_SIZE = 262144
class download:
def GET(self):
file_name = 'file_name'
file_path = os.path.join('file_path', file_name)
f = None
try:
f = open(file_path, "rb")
webpy.header('Content-Type','application/octet-stream')
webpy.header('Content-disposition', 'attachment; filename=%s.dat' % file_name)
while True:
c = f.read(BUF_SIZE)
if c:
yield c
else:
break
except Exception, e:
print e
yield 'Error'
finally:
if f:
f.close()
links: http://api.mongodb.org/python http://webpy.org/cookbook/storeupload.zh-cn http://webpy.org/cookbook/streaming_large_files http://gevent.org 下份代码 demo很值得看哦 gevent 1.0 由libev 替换了libevent
摘要: 贴代码 Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> 1 #--coding:utf-8-- 2 3 ... 阅读全文
多样的文本消息 ----------------- struct MimeText_t{
int type;
string text;
}; MimeText_t 可以包含普通的文本、图像和音频文件的id 图像和音频数据发送到服务器,服务器并不直接将数据发送到接收者,而是发送 音频和图像的描述uri信息 接收者解释json,显示text文本,读取emoticon编号,显示表情图片; image,audio则显示占位(如果当前wifi可用,则自己自动加载image和audio资源) ,如果非wifi信号则待用户点击此占位,然后从服务器请求image和audio资源到本地。 文本描述: 字体大小,颜色,文本link,表情符号 文本用json组织 , { set:[ text:{text:'this is',bg-color:#ff0000,color:#ffffff,font-name:'arial',font-size:20,bold:true,italic:true}, text:{text:'shanghai',color:#ff0000,font-name:'arial',font-size:20,bold:true,italic:true,link:'http://sw2us.com/images/shanghai.png'}, image:{id:1001,width:200,height:200,uri:'http://sw2us.com/images/bear.png'}, audio:{id:2001,duration:5,uri:'http://sw2us.com/clips/a001.mp3'}, location:{lon:121.221,lat,time,speed,direction,text:'立月路2001号浦星公路口'}, emoticon:{id:201} ], } 属性名简化: --------------------- ----------------------- 1 - text [ 1: text , 2: bg-color , 3: color , 4: font-name, 5:font-size, 6:bold, 7:italic ] 2 - image [ 1: id , 2:width , 3:height , 4:uri] 3 - audio [ 1:id , 2:duration,3:uri] 4 - location [ 1:lon, 2:lat, 3:time, 4:speed, 5:direction, 6:text] 5 - emoticon [ 1: id ] ----------------------- 0 - false 1 - true
2016年9月18日
#
摘要: 项目地址: http://github.com/adoggie/TCE 从12年的时候开始想做一个rpc的东东,这些年来陆陆续续往里面增加不同的功能、特点。
tce是一个 全栈的东西,并不是 protocalbuf,或者接近 thrift。 支持语言: csharp,python,java,objc,javascript,actionscript,c++,我想这些够了。
阅读全文
2016年8月23日
#
干了17,8年一线技术工作,还不如刚毕业的985学生,真是好笑。
现在觉得也没啥多想的,现在乐于出去跟不同公司谈谈技术问题,面试完,基本也给对方上完一通技术课程。
晚上看一17岁小朋友在直播写带代码,满有意思,自己也想玩玩。
tce工程加入csharp支持中,本地代码差不多一半,lex分析还没开动,要抓紧了,早点能在unity上跑起来。
公司这两个月要搞个证照系统,设计完框架了,要写代码了。
2016年3月24日
#
摘要: 有问题的c++通信代码的识别,希望写c++的码农不要犯同样的错 阅读全文
近日获得一份微信营销系统的代码,看其功能比较丰富,便开始窥其代码的实现。为了将整个业务系统跑起来,还真的花了不少时间琢磨,幸好不负我的几十年功力,终于将运营环境和开发环境搭建成功,并将系统的授权代码全部剔除(软件厂商控制使用授权)。 准备条件: 1. 互联网服务器(必须开启80,443端口) 2. 申请域名,且绑定到服务器 3. 微信公众号申请,并通过微信认证(300人民币) 先上系统部署图 : 几个部件需要介绍一下: 1. xampp : 开发php的套件,包含了apache,php,mysql,用起来很简单,不过我是部署在linux和mac 上,要留意的是文件目录访问权限的问题,mac下 所有的服务进程跑在root用户下; 2. phpstrom: 开发php的ide,出自jetbrains(我个人理解是目前开发工具最牛逼的公司)。 管理数据库推荐 DataGrip 软件。 3. xdebug : 这个东西是php与phpstrom的调试接口 ,apche接收到http请求,转给php解释器,php解释器再phpStorm进行调试互动(建立xdebug的9000端口的tcp连接),开发者可以在phpStorm里面随意下断点。 注意: 在php.ini中需配置 ide-key:scott , 我是在nginx的转发头里面添加了 XDEBUG_SESSION=scott,令所有经过 nginx 服务器的http请求都被转到phpStorm中,否则无法实现代码断点。 4. wxDebuger: 这是微信提供的本地微信页面调试工具,开发这可以利用winre来调试手机上的页面,也可以脱离手机,直接调试微信页面(要调试微信的wxjssdk必须使用wxDebuger)。 5. nginx : 在公网服务器部署nginx作为http服务器,接收各种用户请求,并将其转发到xampp。 6. vpn : 这个是关键,为了实现本地开发调试的目的,我在公网服务器上部署了openvpn,并在mac开发机上部署了xampp,phpstorm等,并安装vpn客户端 Tunnelblick,其自动拨号到公网服务器,获得地址10.8.0.6,nginx将http请求转发到了我本地的开发机器上,这样我可以很方便的进行远程和本地调试了。 主要的功能描述: 1. 手机、浏览器、调试器 发起的http请求到达公网服务器,nginx通过vpn转发到本地开发机,开发者在phpstorm中断点调试代码,并将处理结果按原路返回。 2. 微信服务器的主要作用是获取 粉丝信息、oauth认证回调、服务器鉴权等功能 , HTTP(302)是 oauth的灵魂 。 3. 这种配置架构很灵活的可以将开发模式切换到部署模式,只需要将xampp部署到公网服务器,并在 nginx的反向代理指到本地xampp服务即可。 附录 nginx.conf server {
listen 80;
server_name wx.xxxx.com www.xxxx.com;
proxy_set_header X-real-ip $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://10.8.0.6:8081;
proxy_set_header Cookie "$http_cookie;XDEBUG_SESSION=scott";
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-real-ip $remote_addr;
}
}
2016年1月29日
#
摘要: 6.x 版本系统自带python 2.6,升级2.7的方式网上有很多版本,本人试用下来觉得诸多不便。
工作项目中越来越多的开发特性必须要求工作在py2.7版本中,例如: django 1.7+已经不支持 py2.6.x了; pyBox2d也不支持。
这次选择的最新版本 python 2.7.11 阅读全文
2015年6月29日
#
访问sf,记录下一下代码 (注册sf的app,登记 callback-url,执行sql查询) #coding:utf-8
__author__ = 'scott'
import imp
imp.load_source('init','../init_script.py')
import urllib2,urllib,json,sys,os
import traceback,threading,time,struct,os,os.path,shutil,distutils.dir_util,array,base64,zlib,struct,binascii
import datetime
from libs.python.lemon import webapi
callback = 'http://localhost:8002/oauth'
client_id = '3MVG9ZL0ppGP5UrC_wQ8U02mOhowPKwjeaaLsWZ3BcYYVqiSsy1rL_D2h6qG.rGPnb_j6IcgLHPdhmvomzDFj'
client_secret = '9046731979xxxxxxx'
def accessToken(request,code,state):
url = 'https://login.salesforce.com/services/oauth2/token'
data = {
'grant_type':'authorization_code',
'code':code,
'client_id':client_id,
'client_secret':client_secret,
'redirect_uri':callback
}
result = ''
try:
result = urllib2.urlopen(url,urllib.urlencode(data) )
except:
traceback.print_exc()
result = result.read()
return json.loads( result )
def oauth(request):
cr = webapi.SuccCallReturn()
code = webapi.GET(request,'code','')
state = webapi.GET(request,'state','')
cr.result=[code,state]
token = accessToken(request,code,state)
cr.result.append(token)
print token
try:
sqlExecute(token['access_token'],token['instance_url'])
except:
traceback.print_exc()
return cr.httpResponse()
import cookielib
# -H "Authorization: OAuth token" -H "X-PrettyPrint:1" "
def sqlExecute(token,url_host):
httpHandler = urllib2.HTTPHandler(debuglevel=1)
httpsHandler = urllib2.HTTPSHandler(debuglevel=1)
opener = urllib2.build_opener(httpHandler, httpsHandler)
urllib2.install_opener(opener)
sf_cmd_query="%s/services/data/v20.0/query/?%s"%(url_host, urllib.urlencode({'q':'select count() from account'}))
headers = {
'Authorization':'OAuth %s'%token,
'X-PrettyPrint':1
}
httpReq = urllib2.Request( sf_cmd_query,headers=headers )
r = opener.open(httpReq).read()
print r
pass
url1 = """https://login.salesforce.com/services/oauth2/authorize?response_type=code&client_id=%s&redirect_uri=%s&state=first"""%(client_id,callback)
def launchBrowserForOAuth():
import webbrowser
webbrowser.open(url1)
if __name__ == '__main__':
launchBrowserForOAuth()
2015年5月26日
#
python内部数据容器有dict和list两种 ,工作中最常用的方式是定义一些数据结构(数据即代码),例如:
1 frog={'name':'scott',
2 'age':2,
3 'parts':{
4 'eye':'green','leg':85
5 },
6 ''friend":['moee','wee'],
7 "hometown":'affica'
8 } frog对象定义了小动物的某些属性,访问frog对象属性时,通过 dict,list的取值方法进行访问,例如: print frog['name'] print frog['friend'][0] 有时觉得这种表达方式太原始了,需要改进,最好是以 '.'方式访问对象属性,例如: print frog.name 代码来开始和结束吧, class _x 1 class _x:
2 """
3 从简单数据类型转换成python对象
4
5 p = _x({'name':'boob','body':{'color':'black'},'toys':[1,2,3,],'age':100})
6 print p['toys'][1]
7 print len(p.toys)
8 print p.body.colors
9 """
10 def __init__(self,primitive):
11 self.data = primitive
12
13 def __getattr__(self, item):
14 value = self.data.get(item,None)
15 if type(value) == dict:
16 value = _x(value)
17 return value
18
19 def __len__(self):
20 return len(self.data)
21
22 def __str__(self):
23 return str(self.data)
24
25 def __getitem__(self, item):
26 value = None
27 if type(self.data) in (list,tuple):
28 value = self.data[item]
29 if type(value) in (dict,list,tuple):
30 value = _x(value)
31 elif type(self.data) == dict:
32 value = self.__getattr__(item)
33 return value
2015年1月1日
#
相关技术: haproxy_keepalived_nginx_uwsgi_gevent_django
之前部署django一直采用 apache + mod_wsgi,用得倒也没啥问题,看到越来越多的人采用nginx部署,所以也尝试了一下,结果很让人欣喜。
nginx够小够简洁,编译、配置相当简单,但要知道她仅仅是个静态webserver,动态功能需要搭配相应的cgi来实现;
uwsgi是个啥东西,看其官方文档还真写的相当详细,功能很丰富,但我的需求可能只会使用其30%的功能;
uwsgi可以认为是python代码运行的loader,或者是容器(container),这有点像java的container(resin,tomcat)。看了其配置文档,很是惊喜,其不仅可以配置为多进程+多线程模式,也可以配置为单进程+多线程模式,并能保持高并发高销率,非常感兴趣。
一直以来自己总在寻找一种 高效、灵活的django的应用容器。
apache默认都是多进程模式,http又是无状态的,不同的请求被分派到不同的进程处理,request处理都是隔离的。多进程带来的问题是高昂的系统开销(apache也支持多线程处理)。
这种隔离又带来了诸多不便,request之间不能共享状态、数据和协作,不能很好的完成与外部系统的协同工作(例如request共享同一个服务器的socket连接或者访问控制某个rs232端口)
所以很想有种类似java的应用容器这样的东东。
接触了gevent,其核心是io异步分派,单线程模拟多协程来对应用层多任务的支持,几近疯狂io效率得到了我的认可。ps:八过smp系统就应该启动多个gevent服务,不然其他核心数都浪费了。
采用gevent+django的模式搭建了自己得app容器,也跑了几个项目,总体效果还是可以。
nginx+uwsgi+django 的配合开始应用到新项目中
2014年10月8日
#
上海交通违章查询网站: http://www.shjtaq.com/Server1/dzjc_new.asp 验证码图片获取地址: http://www.shjtaq.com/Server1/validatecode.asp?m=2304.046
服务器通过页面请求的session-id来区分之后提交的验证码。 第一次请求查询页面时,服务器将访问session(cookie)传到客户端,之后的查询和验证码获取时客户端携带之前的cookie传送到服务器,服务器端保存着当前 session-id与验证码 的对应关系。
查询返回记录可通过 xpath或者 beautifulsoup进行解析
程序使用python完成,也是个简单的小爬虫,scrapy 之类的没必要使用了,gevent完成异步通信。
交通网的验证码生成还是比较简单,做自动识别可找几个简单的图形识别程序即可。
如若不行,则人工输入喽
2014年5月20日
#
|