+ - * / += -= *= /= >> <<
1 #include <iostream>
2 using namespace std;
3
4 class Complex
5 {
6 private:
7 double real;
8 double image;
9 public:
10 Complex(double r = 0.0, double i = 0.0) : real(r), image(i) {}
11 Complex(const Complex& c)
12 {
13 real = c.real;
14 image = c.image;
15 }
16 ~Complex() {}
17 Complex& operator=(const Complex& c)
18 {
19 if (this != &c)
20 {
21 real = c.real;
22 image = c.image;
23 }
24 return *this;
25 }
26 Complex& operator+=(const Complex& c)
27 {
28 real += c.real;
29 image += c.image;
30 return *this;
31 }
32 Complex& operator-=(const Complex& c)
33 {
34 real -= c.real;
35 image -= c.image;
36 return *this;
37 }
38 Complex& operator*=(const Complex& c)
39 {
40 double r2 = real, i2 = image;
41 real = r2 * c.real - i2 * c.image;
42 image = r2 * c.image + i2 * c.real;
43 return *this;
44 }
45 Complex& operator/=(const Complex& c)
46 {
47 double r2 = real, i2 = image;
48 real = (r2 * c.real + i2 * c.image) / (c.real * c.real + c.image * c.image);
49 image = (i2 * c.real - r2 * c.image) / (c.real * c.real + c.image * c.image);
50 return *this;
51 }
52 friend Complex operator+(const Complex& c1, const Complex& c2);
53 friend Complex operator-(const Complex& c1, const Complex& c2);
54 friend Complex operator*(const Complex& c1, const Complex& c2);
55 friend Complex operator/(const Complex& c1, const Complex& c2);
56 friend istream& operator>>(istream& in, Complex& c);
57 friend ostream& operator<<(ostream& out, const Complex& c);
58 };
59
60 Complex operator+(const Complex& c1, const Complex& c2)
61 {
62 Complex t(c1);
63 return t += c2;
64 }
65
66 Complex operator-(const Complex& c1, const Complex& c2)
67 {
68 Complex t(c1);
69 return t -= c2;
70 }
71
72 Complex operator*(const Complex& c1, const Complex& c2)
73 {
74 Complex t(c1);
75 return t *= c2;
76 }
77
78 Complex operator/(const Complex& c1, const Complex& c2)
79 {
80 Complex t(c1);
81 return t /= c2;
82 }
83
84 istream& operator>>(istream& in, Complex& c)
85 {
86 in >> c.real >> c.image;
87 if (!in)
88 {
89 cerr << "Input error!" << endl;
90 exit(1);
91 }
92 return in;
93 }
94
95 ostream& operator<<(ostream& out, const Complex& c)
96 {
97 out << c.real << '+' << c.image << 'i';
98 return out;
99 }
100
101 int main()
102 {
103 Complex c1(1.0, 2.0), c2(3.0, 4.0);
104 cout << c1 << endl;
105 cout << c2 << endl;
106 cout << c1 + c2 << endl;
107 cout << c1 - c2 << endl;
108 cout << c1 * c2 << endl;
109 cout << c1 / c2 << endl;
110
111 Complex c3(5.0, 6.0), c4(7.0, 8.0);
112 c1 += c2 += c3 += c4;
113 cout << c1 << endl;
114 cout << c2 << endl;
115 cout << c3 << endl;
116 cout << c4 << endl;
117 return 0;
118 }
posted @
2011-04-21 23:46 unixfy 阅读(186) |
评论 (0) |
编辑 收藏
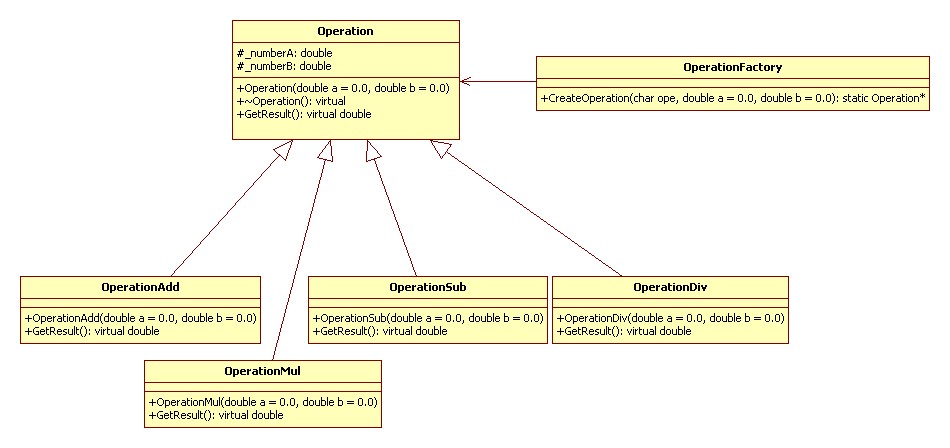
来自于《大话设计模式》
如果需要添加其他操作,需要
·添加一个操作类
·修改 OperationFactory
·修改客户代码以使用这个操作
UML 类图如下:
实例代码 C++:
1 #include <iostream>
2 using namespace std;
3
4 class Operation
5 {
6 protected:
7 double _numberA;
8 double _numberB;
9 public:
10 Operation(double a = 0.0, double b = 0.0) : _numberA(a), _numberB(b) {}
11 virtual ~Operation() {}
12 virtual double GetResult()
13 {
14 double result = 0.0;
15 return result;
16 }
17 };
18
19 class OperationAdd : public Operation
20 {
21 public:
22 OperationAdd(double a = 0.0, double b = 0.0) : Operation(a, b) {}
23 virtual double GetResult()
24 {
25 return _numberA + _numberB;
26 }
27 };
28
29 class OperationSub : public Operation
30 {
31 public:
32 OperationSub(double a = 0.0, double b = 0.0) : Operation(a, b) {}
33 virtual double GetResult()
34 {
35 return _numberA - _numberB;
36 }
37 };
38
39 class OperationMul : public Operation
40 {
41 public:
42 OperationMul(double a = 0.0, double b = 0.0) : Operation(a, b) {}
43 virtual double GetResult()
44 {
45 return _numberA * _numberB;
46 }
47 };
48
49 class OperationDiv : public Operation
50 {
51 public:
52 OperationDiv(double a = 0.0, double b = 0.0) : Operation(a, b) {}
53 virtual double GetResult()
54 {
55 if (_numberB == 0.0)
56 {
57 throw runtime_error("Denominator is 0!");
58 }
59 return _numberA / _numberB;
60 }
61 };
62
63 class OperationFactory
64 {
65 public:
66 static Operation* CreateOperation(char ope, double a = 0.0, double b = 0.0)
67 {
68 Operation* ret = 0;
69 switch (ope)
70 {
71 case '+':
72 ret = new OperationAdd(a, b);
73 break;
74 case '-':
75 ret = new OperationSub(a, b);
76 break;
77 case '*':
78 ret = new OperationMul(a, b);
79 break;
80 case '/':
81 ret = new OperationDiv(a, b);
82 break;
83 default:
84 break;
85 }
86 return ret;
87 }
88 };
89
90 int main()
91 {
92 try
93 {
94 Operation* p_ope;
95 p_ope = OperationFactory::CreateOperation('+', 3.0, 5.0);
96 if (p_ope != 0)
97 {
98 cout << p_ope->GetResult() << endl;
99 delete p_ope;
100 p_ope = 0;
101 }
102
103 p_ope = OperationFactory::CreateOperation('-', 3.0, 5.0);
104 if (p_ope != 0)
105 {
106 cout << p_ope->GetResult() << endl;
107 delete p_ope;
108 p_ope = 0;
109 }
110
111 p_ope = OperationFactory::CreateOperation('*', 3.0, 5.0);
112 if (p_ope != 0)
113 {
114 cout << p_ope->GetResult() << endl;
115 delete p_ope;
116 p_ope = 0;
117 }
118
119 p_ope = OperationFactory::CreateOperation('/', 3.0, 5.0);
120 if (p_ope != 0)
121 {
122 cout << p_ope->GetResult() << endl;
123 delete p_ope;
124 p_ope = 0;
125 }
126
127 p_ope = OperationFactory::CreateOperation('/', 3.0, 0.0);
128 if (p_ope != 0)
129 {
130 cout << p_ope->GetResult() << endl;
131 delete p_ope;
132 p_ope = 0;
133 }
134 }
135 catch (const exception& e)
136 {
137 cerr << e.what() << endl;
138 }
139 return 0;
140 }
posted @
2011-04-21 14:19 unixfy 阅读(217) |
评论 (0) |
编辑 收藏
来自于《算法:C 语言实现》
1 // 字符串查找
2
3 #include <stdio.h>
4 #define N 10000
5
6 int main()
7 {
8 int i, j, t;
9 char a[N], p[N];
10 scanf("%s %s", a, p);
11
12 for (i = 0; a[i] != 0; ++i)
13 {
14 for (j = 0; p[j] != 0; ++j)
15 {
16 if (a[i + j] != p[j])
17 {
18 break;
19 }
20 }
21 if (p[j] == 0)
22 {
23 printf("%d ", i);
24 }
25 }
26 printf("\n");
27 return 0;
28 }
posted @
2011-04-20 17:47 unixfy 阅读(59) |
评论 (0) |
编辑 收藏
来自于《算法:C 语言实现》
1 // 约瑟夫问题-循环链表
2
3 #include <stdio.h>
4 #include <stdlib.h>
5
6 typedef struct node* link;
7
8 struct node
9 {
10 int item;
11 link next;
12 };
13
14 int main()
15 {
16 int i, N, M;
17 link p;
18 scanf("%d %d", &N, &M);
19 link t = (link)malloc(sizeof (*t)), x = t;
20 t->item = 1;
21 t->next = t;
22 for (i = 2; i <= N; ++i)
23 {
24 /*x = x->next = (link)malloc(sizeof (*x));
25 x->item = i;
26 x->next = t;*/
27 p = (link)malloc(sizeof (*x));
28 p->item = i;
29 x->next = p;
30 x = x->next;
31 x->next = t;
32 }
33
34 while (x != x->next)
35 {
36 for (i = 1; i < M; ++i)
37 {
38 x = x->next;
39 }
40 // x->next = x->next->next;
41 t = x->next;
42 x->next = x->next ->next;
43 free(t);
44 --N;
45 }
46 printf("%d\n", x->item);
47 free(x);
48 return 0;
49 }
posted @
2011-04-20 17:39 unixfy 阅读(134) |
评论 (0) |
编辑 收藏
来自于《算法:C 语言实现》
1 // 求素数
2 // 埃拉托色尼筛法
3
4 #include <stdio.h>
5 #define N 10000
6
7 int main()
8 {
9 int i, j, a[N];
10 for (i = 2; i < N; ++i)
11 {
12 a[i] = 1;
13 }
14 for (i = 2; i * i <= N; ++i)
15 {
16 if (a[i] == 1)
17 {
18 for (j = i; i * j < N; ++j)
19 {
20 a[i * j] = 0;
21 }
22 }
23 }
24 for (i = 2; i < N; ++i)
25 {
26 if (a[i] == 1)
27 {
28 printf("%4d ", i);
29 }
30 }
31 printf("\n");
32 return 0;
33 }
posted @
2011-04-20 17:25 unixfy 阅读(232) |
评论 (0) |
编辑 收藏
来自于《算法:C 语言实现》
1 // 顺序搜索算法
2
3 #include <stdio.h>
4
5 int search(int a[], int v, int l, int r)
6 {
7 int i;
8 for (i = l; i <= r; ++i)
9 {
10 if (v == a[i])
11 {
12 return i;
13 }
14 }
15 return -1;
16 }
17
18 int main()
19 {
20 int a[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
21 int i, pos;
22 for (i = 10; i >= -1; --i)
23 {
24 printf("%d\n", search(a, i, 0, 9));
25 }
26 return 0;
27 }
1 // 二分搜索算法
2
3 #include <stdio.h>
4
5 int search(int a[], int v, int l, int r)
6 {
7 int m;
8 while (r >= l)
9 {
10 m = (l + r) / 2;
11 if (v == a[m])
12 {
13 return m;
14 }
15 if (v > a[m])
16 {
17 l = m + 1;
18 }
19 else
20 {
21 r = m - 1;
22 }
23 }
24 return -1;
25 }
26
27 int main()
28 {
29 int a[] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
30 int i, pos;
31 for (i = 10; i >= -1; --i)
32 {
33 printf("%d\n", search(a, i, 0, 9));
34 }
35 return 0;
36 }
posted @
2011-04-20 17:12 unixfy 阅读(106) |
评论 (0) |
编辑 收藏来自于《算法:C 语言实现》
1.
1 // 快速查找算法
2
3 #include <stdio.h>
4 #define N 10000
5
6 int main()
7 {
8 int i, p, q, t, id[N];
9 for (i = 0; i < N; ++i)
10 {
11 id[i] = i;
12 }
13 while (scanf("%d %d", &p, &q) == 2)
14 {
15 if (id[p] == id[q])
16 {
17 continue;
18 }
19 for (t = id[p], i = 0; i < N; ++i)
20 {
21 if (id[i] == t)
22 {
23 id[i] = id[q];
24 }
25 }
26 printf(" %d %d\n", p, q);
27 }
28 }
2.
1 // 快速合并算法
2
3 #include <stdio.h>
4 #define N 10000
5
6 int main()
7 {
8 int i, j, p, q, id[N];
9 for (i = 0; i < N; ++i)
10 {
11 id[i] = i;
12 }
13 while (scanf("%d %d", &p, &q) == 2)
14 {
15 for (i = p; i != id[i]; i = id[i]);
16 for (j = q; j != id[j]; j = id[j]);
17 if (i == j)
18 {
19 continue;
20 }
21 id[i] = j;
22 printf(" %d %d\n", p, q);
23 }
24 }
3.
1 // 加权快速合并算法
2
3 #include <stdio.h>
4 #define N 10000
5
6 int main()
7 {
8 int i, j, p, q, id[N], sz[N];
9 for (i = 0; i < N; ++i)
10 {
11 id[i] = i;
12 sz[i] = 1;
13 }
14 while (scanf("%d %d", &p, &q) == 2)
15 {
16 for (i = p; i != id[i]; i = id[i]);
17 for (j = q; j != id[j]; j = id[j]);
18 if (i == j)
19 {
20 continue;
21 }
22 if (sz[i] < sz[j])
23 {
24 id[i] = j;
25 sz[j] += sz[i];
26 }
27 else
28 {
29 id[j] = i;
30 sz[i] += sz[j];
31 }
32 printf(" %d %d\n", p, q);
33 }
34 }
4.
1 // 带有等分路径压缩的加权快速-合并算法
2
3 #include <stdio.h>
4 #define N 10000
5
6 int main()
7 {
8 int i, j, p, q, id[N], sz[N];
9 for (i = 0; i < N; ++i)
10 {
11 id[i] = i;
12 sz[i] = 1;
13 }
14 while (scanf("%d %d", &p, &q) == 2)
15 {
16 for (i = p; i != id[i]; i = id[i])
17 {
18 id[i] = id[id[i]];
19 }
20 for (j = q; j != id[j]; j = id[j])
21 {
22 id[j] = id[id[j]];
23 }
24 if (i == j)
25 {
26 continue;
27 }
28 if (sz[i] < sz[j])
29 {
30 id[i] = j;
31 sz[j] += sz[i];
32 }
33 else
34 {
35 id[j] = i;
36 sz[i] += sz[j];
37 }
38 printf(" %d %d\n", p, q);
39 }
40 }
posted @
2011-04-20 17:01 unixfy 阅读(380) |
评论 (0) |
编辑 收藏TinyXML
TinyXML 是一个简单的、小的、可以容易地集成到其他程序中的 C++ 解析器。
1. 它可以做些什么
简单地讲,TinyXML 可以分析 XML 文档并从一个可以被读取、修改和存储的文档对象模型(Document Object Model, DOM)。
XML 是 eXtensible Markup Language 的简称。它允许你建立自己的文档标记。HTML 可以很好地为浏览器标记文档,XML 允许你定义任何文档标记,比如一个描述为组织应用的 “to do” 列表的文档。XML 是一种非常结构化和方便的格式。所有那些用来存储应用数据的稳健格式都可以用 XML 来代替。这样的解析器对一切适用。
你可以到 http://www.w3.org/TR/2004/REC-xml-20040204 寻找完整、正确的说明书。你也可以到 http://skew.org/xml/tutorial 来看一下 XML 的简介。
有不懂的方法来读取和交互 XML 数据。TinyXML 使用一个文档对象模型(DOM),XML 数据被解析为一个可以浏览、操作和写到硬盘或其他输出流的 C++ 对象。你也可以从 C++ 对象建立一个 XML 文档,并将其写到硬盘或其他的输出流中。
TinyXML 被设计成容易和快速地学习。它有两个头文件和四个 cpp 文件。你可以很简单地将其添加到你的工程中。这里有一个例子文件 xmltest.cpp,你可以从这里开始。
TinyXML 是在 ZLib 协议下发布的,你可以将其应用于开源项目中或者商业代码中。这个协议的细节位于每个源文件的最上端。
TinyXML 尝试成为一个灵活的解析器,正确的和顺从于 XML 输出。
TinyXML 应该可以在任何合适的 C++ 系统中编译。它不依赖于异常机制和运行时类型识别(RTTI)。在有或无 STL 支持的环境下,它都可以编译。TinyXML 完全支持 UTF-8 编码,和最前面的 64k 的字符实体。
2。它不可以做什么
TinyXML 不能解析或使用 DTDs(Document Type Definitions)或者 XSLs(eXtensible Stylesheet Language)。有其他的解析器(http://www.sourceforge.org, 搜索 XML)可以做其上的工作。但是这些解析器更大,需要更长的时间以建立在你的工程中,更高的学习曲线并且有更多的限制协议。如果你需要为一个浏览器工作或者有更完全的 XML 需求,TinyXML 并不适合你。
下面的 DTD 语法在 TinyXML 中无法解析:
@verbatim
<!DOCTYPE Archiv [
<!ELEMENT Comment (#PCDATA)>
]>
@endverbatim
TinyXML 视 !DOCTYPE 节点非法嵌入一个 !ELEMENT 节点。将来这个问题可能被解决。
3。教程
对于急切的人,这里有个教程可以帮助你入门。非常好的入门方法,但是把这个手册读完是值得的。
4。代码状况
TinyXML 是一个成熟的、被测试过的代码。它非常稳定。如果你发现了 bugs,请在 sourceforge (http://www.sourceforge.net/projects/tinyxml)上写一份 bug 报告。我们将尽快将其校正。
有一些需要改进的方面,如果你对 TinyXML 有兴趣,请加入检查 sourceforge。
5. 相关的工程
TinyXML 工程,你可能发现它非常有用。
TinyXPath:http://tinyxpath.sourceforge.net ,一个小的 XPath 语法解码器,C++ 实现。
TinyXML++:http://code.google.com/p/ticpp ,一个相对 TinyXML 更新接口的 XML 解析器。它利用了许多 C++ 的功能,比如模板、异常处理机制和许多更好的错误处理。
6。特征
6。1 使用 STL
TinyXML 在有或无 STL 的环境下都可以被编译。当使用 STL 时,TinyXML 使用 std::string 类,支持 std::istream, std::ostream, operator<<, 和 operator>>。许多 API 有 'const char*' 和 'const std::strign&' 两种形式。
当 STL 支持被编译出时,非 STL 文件不管怎么被包含。所有的 string 类是有 TinyXML 自身实现的。API 都使用 'const char*' 形式来支持输入。
使用编译时 #define:
TIXML_USE_STL
来编译一个版本或其他版本。可以通过编译期传递或者放在 "tinyxml.h" 文件的第一行中。
注意:如果在 Linux 中编译测试代码,设置环境变量 TINYXML_USE_STL=YES/NO 来控制编译。在 Windows 工程文件中,STL 和 non STL 目标都是被支持的。在你的工程中,在 tinyxml.h 的文件的第一行中添加 #define TIXML_USE_STL 是非常容易的。
6。2 UTF-8
TinyXML 支持允许以任何语言操作 XML 文件的 UTF-8 编码方式。TinyXML 也支持合法模式(legacy mode),其实一种被用于 UTF-8 之前的编码方式,可以被描述成“扩展的ASCII”(extended ASCII).
一般地,TinyXML 试着检测正确的编码方式并使用它。但是,可以通过在头文件中设置 TIXML_DEFAULT_ENCODING 的值来强制使用某一种编码方式。
TinyXML 将要假设一种合法模式,直到一下的其中之一发生:
1)。如果不是标准的,但是 UTF-8 带头字节(UTF-8 lead bytes)出现在文件或数据流的头部,TinyXML 将按照 UTF-8 的编码方式读取。
2)。如果声明的标签被读取,并且它有个 encoding="UTF-8",则按照 UTF-8 编码方式读取。
3)。如果声明的标签被读取,它没有特殊的编码,则按照 UTF-8 编码。
4)。如果声明表中是 encoding="something else",TinyXML 将其读作为合法模式(legacy mode)。在合法模式中,TinyXML 和以前工作一样。不清楚具体是哪种模式,老的内容应该保持工作。
5)。直到上面的一种准则满足,TinyXML 按照合法模式执行。
如果编码是不正确的,或者被检测出来将要发生什么?TinyXML 将其看做不合适的编码。你可能得到的是不正确的结果或乱码。你可能想强制 TinyXML 变为正确的模式。
这一通过 LoadFile( TIXML_ENCODING_LEGACY ) 或者 LoadFile( filename, TIXML_ENCODING_LEGACY ) 的方式强制 TinyXML 设置为合法模式。你可以设置 TIXML_DEFAULT_ENCODING = TIXML_ENCODING_LEGACY 来一直使用合法模式。同样地,你也可以使用同样的技术将其设置为 TIXML_ENCODING_UTF8。
对于英语用户,使用英文的 XML,UTF-8 与 low-ASCII 是一样的,你不需要检测 UTF-8 或者改变你的代码。可以将 UTF-8 看做 ASCII 的一个超集。
UTF-8 不是双字节格式,但是它是 Unicode 的标准编码。
TinyXML 不使用和直接同时支持 wchar, TCHAR, 或者 微软的 _UNICODE。
用 Unicode 指代 UTF-16 是不合适的,UTF-16 是 Unicode 的一种宽字节编码方式。这引起了混乱。
对于 high-ascii 语言,TinyXML 可以处理所有的语言,同时,只要 XML 被编码成 UTF-8。这样有些滑稽,老的程序员和操作系统趋向于使用 default 和 traditional 的代码页。许多应用可以输出 UTF-8,但是老或者顽固的应用是以默认的代码页输出文本的。
例如,日文系统传统上使用 SHIFT-JIS 编码方式。TinyXML 不能读取 SHIFT-JIS 编码的文本。一个好的编辑器可以打开 SHIFT-JIS 的文件并将其保存为 UTF-8 的编码方式。
http://skew.org/xml/tutorial 对转换编码做了很好的介绍。
utf8test.xml 是一个包含英语、西班牙语、俄语和简体中文的 XML 文件。utf8test.gif 是一个在 IE 中渲染的 XML 文件的屏幕截图。注意如果你的电脑里没有正确的字体,你不能看到输出的 GIF 文件,即便你正确地将其解析。也要主要终端的西方代码页输出,以至于 Print() 或者 printf() 不能正确地显示文件。这不是 TinyXML 的 bug,而是操作系统的问题。没有数据丢失或者被 TinyXML 破坏。终端不能渲染 UTF-8。
6。3 实体(Entities)
TinyXML 组织预定义的字符实体,即特殊字符。也就是:
& &
< <
> >
" "
' '
当 XML 文档被读取和转换成 UTF-8 等同物时,这些字符被辨识。比如这样的 XML 文本:
Far & Away
当从 TiXMLText 对象中使用 Value() 查询 “Far & Away”。作为 & 符号写回到 XML 流/文件。老的 TinyXML 版本保留字符实体,但是新版本将它们转换为字符。
另外,任何字符都可以用它的 Unicode 指定:" " 或 " " 都可以指代非中断空白字符。
6.4 打印(Printing)
TinyXML 可以以许多不同的方式打印输出,这些方式既有优势也有限制。
1)。Print( FILE* ). 标准 C 流,包括 C 文件和编制输出。
漂亮的输出,但是你不能对输出选择进行控制。
输出被指向 FILE 对象,所以在 TinyXML 代码中没有预先的内存。
Print() 和 SaveFile()
2)。opeartor<<。输出到 C++ 流。
继承标准 C++ 输入输出流
网络打印,便于网络传输和在 C++ 对象间传递 XML,但是难以阅读。
3)。TiXmlPrinter。输出到 std::string 或者 内存缓冲区。
API 不简洁
将来的打印选择将被添加
将来的版本中,随着打印被重定义和扩展,打印可能改变。
6。5 流(Streams)
有 TIXML_USE_STL 的 TinyXML 支持 C++ 流(operator <<,>>),像 C(FILE*) 流似的。有一些你需要注意的不同。
1)。C 风格输出
以 FILE* 为基础
Print(), SaveFile()
产生格式化输出,伴随大量的空白键,看可能便于阅读。非常快速,容忍格式不好的 XML 文档。例如,一个含有两个根元素和两个声明的 XML 文档仍然可以被打印。
2)。C 风格输入
建立在 FILE* 基础上
Parse(), LoadFile()
快速的,格式任意。在你不需要 C++ 流时使用。
3)。C++ 风格输出
建立在 std::ostream 基础上
operator<<
生成压缩输出,便于网络传输而不是易于阅读。依赖于你系统中的输出流类的实现,可能很很慢。XML 文档必须有很好的格式:一个文档应该包含一个正确的根元素。额外的根层元素不能被流输出。
4)。C++ 风格输入
建立在 std::istream 基础上
operator>>
从流中读取 XML,使它利于网络传输。XML 文档虚实完整的。TinyXML 假设 XML 数据时完整的,当其读取了根元素。其他的有多个根元素的错误构造不能被正确读取。operator<< 比 Parse 慢,这与 STL 的实现和 TinyXML 的限制有关。
6。6 空白符(White space)
空白字符被保持还是被压缩在不同的条件下并不统一。例如,用 '_' 代表一个空白符,对于 “Hello____world”。HTML 和一些 XML 解析器中,其被翻译成 “Hello_world”。一些 XML 解析器将其保持不变“Hello___world”。另一些将 __Hello___world__ 转换成 Hello___world。
这个问题还没有被解决的令我满意。TinyXML 支持前两种方法。TiXmlBase::SetCondenseWhiteSpace( bool ) 设置期望的操作。默认的是压缩空白符。
如果你改变默认的方式,你应该在费用解析 XML 数据的调用之前调用 TiXmlBase::SetCondenseWhiteSpace( bool )。我不推荐当他已被建立了还去改变它。
6。7 处理(Handles)
用稳定的方式浏览一个 XML 文档,检测函数调用的返回值是不是 null 很重要。一个错误安全的实现产生的代码像这样一样:
TiXmlElement* root = document.FirstChildElement( "Document" );
if ( root )
{
TiXmlElement* element = root->FirstChildElement( "Element" );
if ( element )
{
TiXmlElement* child = element->FirstChildElement( "Child" );
if ( child )
{
TiXmlElement* child2 = child->NextSiblingElement( "Child" );
if ( child2 )
{
// Finally do something useful.
Handles 可以把这些代码清除。使用 TiXmlHandle 类,前面的这些代码可以缩减为:
TiXmlHandle docHandle( &document );
TiXmlElement* child2 = docHandle.FirstChild( "Document" ).FirstChild( "Element" ).Child( "Child", 1 ).ToElement();
if ( child2 )
{
// do something useful
这种方式更容易处理。可以查看 TiXmlHandle 来获取更多的信息。
6。8 行和列追踪(Row and Column tracking)
能够追踪节点和属性在源文件中的原始位置对于一些应用是非常重要的。另外,知道解析错误发生在哪里可以及时地保存。
TinyXML 可以追踪所有节点和属性在文本文件中的行和列。TiXmlBase::Row() 和 TiXmlBase::Column() 函数返回节点在源文本文件中的位置。正确的制表符可以在 TiXmlDocument::SetTabSize() 中配置。
7。使用和安装
编译和运行 xmltest
这里提供了 Linux 的 Makefile 文件和 Windows Visual C++ 下的 .dsw 文件。正常的编译和运行。它将要向你的硬盘写入 demotest.xml 文件和向屏幕产生输出。它还测试沿着 DOM 用不同的技术打印已发现的节点的数目。
Linux makefile 非常通用,可以在许多系统中运行,它已经在 mingw 和 MacOSX 中测试。你不需要运行 'make depend'。这种依赖已经被硬编码。
7。1 Windows VC6 工程文件
tinyxml: tinyxml library, non-STL
tinyxmlSTL: tinyxml library, STL
tinyXmlTest: test app, non-STL
tinyXmlTestSTL: test app, STL
7。2 Makefile
在 makefile 文件中,你可以设置:
PROFILE, DEBUG 和 TINYXML_USE_STL。细节在 makefile 中。
在 tinyxml 文件夹中,键入 'make clean' 和 'make'。可执行文件 'xmltest' 将被产生。
7。3 在应用中使用
将 tinyxml.cpp, tinyxml.h, tinyxmlerror.cpp, tinyxmlparser.cpp, tinystr.cpp 和 tinystr.h 添加到你的工程文件或 makefile 中。就是这样!它应该可以在任何相容的 C++ 系统中得到编译。你不需要异常处理机制或运行时类型识别(RTTI)。
8。TinyXML 怎样工作(How TinyXML works)
一个来自可能是最好的开始方法。例如:
<?xml version="1.0" standalone=no>
<!-- Our to do list data -->
<ToDo>
<Item priority="1"> Go to the <bold>Toy store!</bold></Item>
<Item priority="2"> Do bills</Item>
</ToDo>
它不是一个 To Do 列表,但是它将要这么做。读取这个文件(demo.xml)你可以产生一个文档,并解析它:
TiXmlDocument doc( "demo.xml" );
doc.LoadFile();
这样就可以工作了。现在让我们观察一些行,并且他们是怎样与 DOM 相关联的。
<?xml version="1.0" standalone=no>
第一行是一个声明,转向 TiXmlDeclaration 类。它是这个文档节点的第一个孩子。
这是 TinyXML 解析的唯一的直接/特殊的标签。一样直接标签被存在 TiXmlUnknown 类中。这样当存储到硬盘中时命令不会丢失。
<!-- Our to do list data -->
这是一个注释。这个将生成一个 TiXmlComment 对象。
<ToDo>
"ToDo" 标签定义一个 TiXmlElement 对象。这个对象没有任何属性,但是它包含两个元素。
<Item priority="1">
生成另一个 TiXmlElement 对象,它是 "ToDo" 元素的孩子。这个元素有一个属性,属性名是 "priority",属性值为 "1".
Go to the
这是一个 TiXmlText 对象。这是一个叶子节点,不能包含任何其他的节点。它是 "Item" TiXmlElement 对象的孩子。
<bold>
另一个 TiXmlElement 对象,这是 "Item" 元素的孩子。
等。
观察整个对象树,你可以得到:
TiXmlDocument "demo.xml"
TiXmlDeclaration "version='1.0'" "standalone=no"
TiXmlComment " Our to do list data"
TiXmlElement "ToDo"
TiXmlElement "Item" Attribtutes: priority = 1
TiXmlText "Go to the "
TiXmlElement "bold"
TiXmlText "Toy store!"
TiXmlElement "Item" Attributes: priority=2
TiXmlText "Do bills"
9。文档(Documentation)
文档用 Doxygen 建立,使用的 'dox' 配置文件。
10。协议
TinyXML 是在 zlib 协议下发布的。
这个软件提供了 "as-is",没有任何明确的或隐含的保证。作者不详任何的有本软件产生的损害负责。
任何人可以使用本软件已达到任何目的,包括商业应用,可以修改它并重新发布,但是要服从一下的限制:
1)。这个软件的起源不能被误传;你不能声称是你写的这个最初软件。如果你使用这个软件在你的产品中,应该在产品的文档的文档中有对这个软件的感谢,但这不是必须的。
2)。修改源代码必须明白的标注清楚,不可以将其误传为原来的代码。
3)。这个通知可以从任何源代码的发布中不被删除或修改。
11。参考资料(References)
World Wide Web 协会是 XML 的定义标注主体,他们的网页中包含了大量的信息。
定义说明书可以在 http://www.w3.org/TR/2004/REC-xml-20040204 找到。
我也推荐 Robert Eckstein 写的 XML Pocket Reference 这本书,由 O'Reilly 出版社出版,你这个在这本书获得全部入门的东西。
12。贡献者,联系,一个简短的历史(Contributors, Contacts, and a Brief History)
非常感谢每一位提出建议、错误、想法和鼓励的人。它帮助并使得这个工程有趣。特别感谢那些在网页上保持它一直充满活力的贡献者们。
太多的人攻陷发现的错误和想法,以至于我们在 changes.txt 文件中列出应得的感谢。
TinyXML 最初是由 Lee Thomason 写的。(文档中的“我”。)Lee 在 Yves Berquin、Andraw Ellerton 和 TinyXML 社区的帮助下审查改动和发布最新的版本。
我们感谢你的建议,并非常想知道你是否使用 TinyXML。希望你喜欢它并且发现它很有用。
欢迎提出问题,发表评论和程序错误。你也可以联系我们:
http://www.sourceforge.net/projects/tinyxml
Lee Thomason, Yves Berquin, Andrew Ellerton
posted @
2011-04-18 21:30 unixfy 阅读(1213) |
评论 (0) |
编辑 收藏
摘要: 最初想法来自于《编程珠玑》,下午实现了一下不多说了,直接看代码吧
1 // 2 // HashTable 3 // 4 // goonyangxiaofang(AT)163(D...
阅读全文
posted @
2011-03-09 18:57 unixfy 阅读(426) |
评论 (0) |
编辑 收藏来自于《编程珠玑》
计算球面的距离,输入是球面上点的经度和纬度,得到一个原始点集,再得到另一个测量点集,输出测量点集中的每个点到原始点集中的每个点的距离,这里的距离是两个点的集合距离,即使在笛卡尔坐标系中的欧氏距离,根据经度和纬度,转换为点在笛卡尔积中的 x, y, z 坐标
测试数据:
5
E23 N35
E150 N80
W50 N20
W175 N55
E20 S35
3
E105 S70
W40 S50
W160 S85
1 //
2 // goonyangxiaofang(at)163(dot)com
3 // QQ: 五九一二四七八七六
4 //
5
6 #include <iostream>
7 #include <string>
8 #include <vector>
9 #include <cmath>
10
11 class PointSet
12 {
13 public:
14 struct Point
15 {
16 std::string longitude;
17 std::string latitude;
18 double longi;
19 double lati;
20 double x, y, z;
21 private:
22 void ajust()
23 {
24 if (longitude[0] == 'E')
25 {
26 longi = atof(longitude.c_str() + 1);
27 }
28 else if (longitude[0] == 'W')
29 {
30 longi = 360.0 - atof(longitude.c_str() + 1);
31 }
32 if (latitude[0] == 'N')
33 {
34 lati = atof(latitude.c_str() + 1);
35 }
36 else if (latitude[0] == 'S')
37 {
38 lati = -atof(latitude.c_str() + 1);
39 }
40 x = R * cos(lati * PI / 180.0) * cos(longi * PI / 180.0);
41 y = R * cos(lati * PI / 180.0) * sin(longi * PI / 180.0);
42 z = R * sin(lati * PI / 180.0);
43 }
44 public:
45 Point() : longitude(""), latitude(""), longi(0.0), lati(0.0), x(0.0), y(0.0), z(0.0) {}
46 Point(const std::string& s1, const std::string& s2) : longitude(s1), latitude(s2)
47 {
48 ajust();
49 }
50 Point(const Point& p) : longitude(p.longitude), latitude(p.latitude), longi(p.longi), lati(p.lati), x(p.x), y(p.y), z(p.z) {};
51 Point& operator=(const Point& p)
52 {
53 longitude = p.longitude;
54 latitude = p.latitude;
55 longi = p.longi;
56 lati = p.lati;
57 x = p.x;
58 y = p.y;
59 z = p.z;
60 return *this;
61 }
62 bool operator==(const Point& p) const
63 {
64 return longitude == p.longitude && latitude == p.latitude;
65 }
66 double distance(const Point& p)
67 {
68 return sqrt((x - p.x) * (x - p.x) + (y - p.y) * (y - p.y) + (z - p.z) * (z - p.z));
69 }
70 friend std::istream& operator>>(std::istream& in, Point& p);
71 friend std::ostream& operator<<(std::ostream& out, const Point& p);
72 };
73 private:
74 std::vector<Point> m_set;
75 static const double R;
76 static const double PI;
77 public:
78 void insert(const std::string& s1, const std::string& s2)
79 {
80 Point p(s1, s2);
81 m_set.push_back(p);
82 }
83 void insert(const Point& p)
84 {
85 m_set.push_back(p);
86 }
87 void print()
88 {
89 for (std::size_t i = 0; i < m_set.size(); ++i)
90 {
91 std::cout << "Point " << i + 1 << ": ";
92 std::cout << m_set[i];
93 }
94 }
95 std::size_t size()
96 {
97 return m_set.size();
98 }
99 Point& operator[](std::size_t i)
100 {
101 return m_set[i];
102 }
103 const Point& operator[](std::size_t i) const
104 {
105 return m_set[i];
106 }
107 };
108
109 std::istream& operator>>(std::istream& in, PointSet::Point& p)
110 {
111 std::string s1, s2;
112 in >> s1 >> s2;
113 PointSet::Point p2(s1, s2);
114 p = p2;
115 return in;
116 }
117
118 std::ostream& operator<<(std::ostream& out, const PointSet::Point& p)
119 {
120 out << p.longitude << ' ';
121 out << p.latitude << ' ';
122 out << p.longi << ' ';
123 out << p.lati << ' ';
124 out << p.x << ' ';
125 out << p.y << ' ';
126 out << p.z << ' ';
127 out << std::endl;
128 return out;
129 }
130
131 const double PointSet::R = 6400.0;
132 const double PointSet::PI = 3.1415926;
133
134 int main()
135 {
136 PointSet ps;
137 PointSet::Point p;
138 long n;
139 std::cin >> n;
140 for (long i = 0; i < n; ++i)
141 {
142 std::cin >> p;
143 ps.insert(p);
144 }
145 ps.print();
146
147 PointSet measure_ps;
148 std::cin >> n;
149 for (long i = 0; i < n; ++i)
150 {
151 std::cin >> p;
152 measure_ps.insert(p);
153 }
154 measure_ps.print();
155 for (std::size_t i = 0; i < measure_ps.size(); ++i)
156 {
157 for (std::size_t j = 0; j < ps.size(); ++j)
158 {
159 std::cout << "From " << i + 1 << " to " << j + 1 << ": " << ps[j].distance(measure_ps[i]) << std::endl;
160 }
161 }
162 return 0;
163 }
164
posted @
2011-03-08 14:07 unixfy 阅读(209) |
评论 (0) |
编辑 收藏