|
|
这是我们操作系统的大作业。 原理就是inline hook 那个 proc 文件系统,根目录下的 readdir 的函数。 替换掉第三个参数,filldir。 代码爆短,60来行。 Ubuntu 10.04 测试可用。
 #include <linux/kernel.h> #include <linux/kernel.h>
#include <linux/kprobes.h>
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/fs.h>
int register_kprobe(struct kprobe *kp);
  static struct kprobe kp = static struct kprobe kp =  { {
 .symbol_name = "proc_pid_readdir", .symbol_name = "proc_pid_readdir",
 }; };
static filldir_t old_filldir;
static int pid;
module_param(pid, int, 0744);
static int filldir(void * __buf, const char * name, int namlen, loff_t offset,
u64 ino, unsigned int d_type)
{
int p;
sscanf(name, "%d", &p);
if (p == pid)
return 0;
return old_filldir(__buf, name, namlen, offset, ino, d_type);
}
/**//* kprobe pre_handler: called just before the probed instruction is executed */
static int handler_pre(struct kprobe *pr, struct pt_regs *regs)
{
old_filldir = (filldir_t)regs->cx;
regs->cx = (typeof(regs->cx))filldir;
return 0;
}
static int __init k_init(void)
{
int ret;
kp.pre_handler = handler_pre;
ret = register_kprobe(&kp);
  if (ret < 0) { if (ret < 0) {
printk(KERN_INFO "register_kprobe failed, returned %d\n", ret);
return ret;
 } }
printk(KERN_INFO "Planted kprobe at %p; pid %d\n", kp.addr, pid);
return 0;
}
static void __exit k_exit(void)
{
unregister_kprobe(&kp);
printk(KERN_INFO "kprobe at %p unregistered\n", kp.addr);
}
module_init(k_init);
module_exit(k_exit);
MODULE_LICENSE("GPL");
sleep 1000 &
pid=`jobs -p`
echo 'before hide'
ps aux | grep $pid
insmod k.ko pid=$pid
echo 'after hide'
ps aux | grep $pid
rmmod k.ko
echo 'after unhide'
ps aux | grep $pid
可以看出,达到最大size的时候一定是某个蛋糕刚好被分完,如果再大一点的话,肯定就不能解决了。
比这个size小,则无论如何都可以解决。
所以可以通过二分答案的方法来解决这个问题。就很简单了。 注意:这题精度要求很高,pi的值需要通过acos(-1)来求,eps要到e-5。 我用C++提交能够AC,g++一直WA。 吗的,数据能不能宽容点。
#include <stdio.h>
#include <math.h>
#include <algorithm>
using namespace std;
int N, F;
double pi = acos(-1.0);
double pie[10032];
double sum, maxp;
int main()
{
double l, r, m;
int i, t, c;
scanf("%d", &t);
while (t--) {
scanf("%d%d", &N, &F);
F++;
maxp = sum = 0;
for (i = 0; i < N; i++) {
scanf("%d", &c);
pie[i] = c*c*pi;
maxp = max(maxp, pie[i]);
sum += pie[i];
}
l = maxp / F;
r = sum / F;
while (l + 0.00001 < r) {
m = (l + r) / 2;
c = 0;
for (i = 0; i < N; i++)
c += floor(pie[i] / m);
if (c < F)
r = m;
else
l = m;
}
printf("%.4lf\n", l);
}
return 0;
}
摘要: 可以开一个闭hash表。栈里面存放的只是hash表的下标。这样比较两个set是否一样,就只需要比较他们的下标是否一样。同时对每个set,要保存它的孩子,一样存放的是hash表的下标。
union和intersect操作,如果是按序存放孩子的话,复杂度可以低至O(N)。空间复杂度为O(N^2)。
#include <stdio.h>#include <str... 阅读全文
摘要: 题目大意:给出一个已经完成的数独,和一个未完成的数独。判断前者能否经过演化后成为后者的解。演化的操作有:1)改变数字1~9的映射2)旋转数独3)交换3x9中的行或列4)交换两个3x9解法:实际上就是常规的搜索,不过代码难写点。4)中共有6*6种情况3)中共有(6*6*6)*(6*6*6)种情况在搜索3)的时候,首先固定列,然后枚举行,这样就可以节省一些时间。我的代码 250ms
Code hig... 阅读全文
题目的意思是: 给一个有n个点,m条边的无向图 两点之间可以存在多条边 现在每次随机增加一条边 问使得全部点都连通需要增加多少次(期望值) 首先,求出所有连通分量。用并查集。 每次随机增加一条边的时候一共有两种情况: 1)这条边连接了两个不同的连通分量,它的概率是p 2)这条边在一个连通分量里,它的概率是q = 1 - p 前者可以改变连通分量的数量,后者不能 如果把当前图的状态视为一个子问题 那么就可以用动态规划解决问题了 图的状态可以表示为:有多少个连通分量,每个连通分量包含多少个点
比如说图的状态 (2, 3, 3) 表示有三个连通分量,每个连通分量包含的点的个数分别为 2, 3, 3 动态规划的转移方程为: f = p*(1+r) + p*q*(2+r) + p*q^2*(3+r) .... 其中r为p发生后,新状态的期望值 这个东西高中的时候学过,呵呵。 而1)中也包含多种情况,需要两两枚举 最大的问题是,f的值是一个无限数列,它的极值很难求。但无论如何,有高手求出来了。。在这里:http://archive.cnblogs.com/a/1325929/
它的极值是 f = p * (1 / (1 - q) + r) / (1 - q)
我对照了一下标程,确实是这个。 后来我自己推导了一下,发现它可以化成多个等比数列相加的形式,求和后,发现当n趋向于无穷大的时候,它的极限就是上面这个公式。 (注意:i*q^i, 当0<q<1,i趋向于无穷大的时候等于0) 这样程序就可以写了。动态规划保存每个图的状态。 如果用python写,只要建立一个tuple到float的映射就可以了。非常方便。 java中也有List<int>到Double的映射。 c里面估计就得用hash了。 py代码,参照标程写的。
fi = open('in')
fo = open('out')
dp = {():0}
ti = 0
def get(s):
if s in dp:
return dp[s]
q = sum([i*(i-1) for i in s])*1.0/2/nn
res = 0
for i in range(len(s)):
for j in range(len(s)):
if i < j:
l = list(s)
del l[max(i,j)]
del l[min(i,j)]
l.append(s[i]+s[j])
l.sort()
r = get(tuple(l))
p = s[i]*s[j]*1.0/nn
res += p*(1+r-r*q)/pow(1-q,2)
dp[s] = res
return res
while 1:
a = fi.readline().split()
if a == None or len(a) != 2:
break
N, M = int(a[0]), int(a[1])
nn = N*(N-1)/2
s = [ i for i in range(N) ]
for i in range(M):
u, v = [ int(i) for i in fi.readline().split() ]
u -= 1
v -= 1
k = s[u]
for j in range(N):
if s[j] == k:
s[j] = s[v]
ss = [ s.count(i) for i in set(s) ]
ss.sort()
print '----', ti
mine = get(tuple(ss))
ans = float(fo.readline().strip())
print 'mine', mine, 'ans', ans
print len(dp)
ti += 1
标程 用很简洁的代码写了并查集,值得借鉴!
import java.util.*;
import java.io.File;
import java.io.PrintWriter;
import java.io.FileNotFoundException;
public class interconnect_pm {
private static int nn;
public static void main(String[] args) throws FileNotFoundException {
Scanner in = new Scanner(new File("in"));
PrintWriter out = new PrintWriter("ans.out");
int n = in.nextInt();
nn = (n * (n - 1)) / 2;
int m = in.nextInt();
int[] p = new int[n];
for (int i = 0; i < n; i++) p[i] = i;
for (int i = 0; i < m; i++) {
int u = in.nextInt();
int v = in.nextInt();
u--;
v--;
int k = p[u];
for (int j = 0; j < n; j++) {
if (p[j] == k) {
p[j] = p[v];
}
}
}
List<Integer> st = new ArrayList<Integer>();
for (int i = 0; i < n; i++) {
int s = 0;
for (int j = 0; j < n; j++) {
if (p[j] == i) s++;
}
if (s > 0) {
st.add(s);
}
}
Collections.sort(st);
List<Integer> fn = new ArrayList<Integer>();
fn.add(n);
mem.put(fn, 0.0);
out.println(get(st));
System.out.println(mem.size());
out.close();
}
static Map<List<Integer>, Double> mem = new HashMap<List<Integer>, Double>();
private static double get(List<Integer> st) {
Double ret = mem.get(st);
if (ret != null) return ret;
int m = st.size();
int[][] a = new int[m][m];
for (int i = 0; i < m; i++) {
for (int j = i + 1; j < m; j++) {
a[i][j] = st.get(i) * st.get(j);
}
}
int s = 0;
for (int i = 0; i < m; i++) {
s += st.get(i) * (st.get(i) - 1) / 2;
}
double res = 0;
for (int i = 0; i < m; i++) {
for (int j = i + 1; j < m; j++) {
List<Integer> ss = new ArrayList<Integer>(st.size() - 1);
boolean q = true;
int z = st.get(i) + st.get(j);
for (int k = 0; k < m; k++) {
if (k != i && k != j) {
int zz = st.get(k);
if (q && zz >= z) {
q = false;
ss.add(z);
}
ss.add(zz);
}
}
if (q)
ss.add(z);
double p = a[i][j] * 1.0 / (nn - s);
double e = a[i][j] * 1.0 / ((1 - s * 1.0 / nn) * (1 - s * 1.0 / nn) * nn);
e = e + get(ss) * p;
res += e;
}
}
System.out.println(st);
mem.put(st, res);
return res;
}
}
这题真不是盖的,要是不看解题报告,恐怕一辈子都做不出来啦。。 题目直接就是要解决一个叫做“最大密度子图的问题”。 就是在一简单图里面找出n个点,这n个点之间有m条边,让m/n最大。 这种问题还是有点实际意义的。 算法很复杂,找了一份高中生巨牛写的文档(90后真不是盖的)。http://wenku.baidu.com/view/986baf00b52acfc789ebc9a9.html
。 该文档描述了一系列的最小割算法,其中包括这个“最大密度子图问题”。 我编码能力差,不想写c代码,写了一个py的脚本,能过官方数据,就是速度巨慢,开了一分钟也没跑完。。
import sys
def dinic(N, S, T, caps):
to = []
cap = []
head = [[] for i in range(N)]
d = [-1]*N
ans = 0
cut = set()
for a, b, c in caps:
head[a].append(len(cap))
cap.append(c)
to.append(b)
head[b].append(len(cap))
cap.append(0)
to.append(a)
def build():
for i in range(N):
d[i] = -1
q = [S]
d[S] = 0
cut.clear()
while len(q):
x = q[0]
del q[0]
for i in head[x]:
y = to[i]
if cap[i] and d[y] == -1:
d[y] = d[x] + 1
if y == T:
return 1
q.append(y)
cut.add(y)
return 0
def find(x, low):
if x == T:
return low
for i in head[x]:
y = to[i]
if cap[i] and d[y] == d[x] + 1:
f = find(y, min(low, cap[i]))
if f:
cap[i] -= f
cap[i^1] += f
return f
return 0
while build():
while 1:
f = find(S, sum(cap))
if f == 0:
break
ans += f
return ans, cut
def max_weight_closure(V, edges):
inf = sum([abs(i) for i in V])
caps = [(a,b,inf) for a,b in edges]
S = len(V)
T = S + 1
for i in range(len(V)):
if V[i] > 0:
caps.append((S,i,V[i]))
elif V[i] < 0:
caps.append((i,T,-V[i]))
flow, cut = dinic(len(V)+2, S, T, caps)
return sum([V[i] for i in cut]), cut
def max_density_subgraph(N, edges):
def solve(g):
V = [-g]*N
E = []
for u,v in edges:
ve = len(V)
E += [(ve,u), (ve,v)]
V.append(1)
w, cut = max_weight_closure(V, E)
if len(cut) == 0:
w = -1
return w, cut
l = 1.0/N
r = len(edges)
while l < r - 0.01:
m = (l + r) / 2
if solve(m)[0] < 0:
r = m
else:
l = m
w, cut = solve(l)
l = [ i for i in cut if i < N]
if len(l) == 0:
l = [0]
return l
def get_density(N, edges, sel):
e = float(len([1 for a,b in edges if a in sel and b in sel]))
return e/float(len(sel))
fi = open('3155.in')
fo = open('3155.out')
g = lambda x : [ int(i) for i in x.readline().split(' ') ]
ti = 0
while 1:
l = g(fi)
if len(l) == 0:
break
N, M = l
print '----', ti
print 'N M', N, M
E = [ [j-1 for j in g(fi)] for i in range(M)]
cut = max_density_subgraph(N, E)
k = g(fo)[0]
ans = [g(fo)[0]-1 for i in range(k)]
d_ans = get_density(N, E, ans)
d_mine = get_density(N, E, cut)
print 'mine', d_mine
print 'ans', d_ans
if abs(d_ans - d_mine) > 0.001:
print 'error'
break
ti += 1
可以认为,新的平分点和旧的平分点中一定有一个点是重合的。 这样此题就变成了一个纯模拟的问题了。 写了个脚本,可以过官方的数据。
import sys
f = sys.stdin
D = 10000.0
for s in f.readlines():
n, m = [ int(i) for i in s.split(' ') ]
m += n
b = 0
ans = 0
g = lambda x,y: D*x/y
for a in range(n):
while g(b, m) <= g(a, n):
b += 1
d = min(abs(g(b, m) - g(a, n)), abs(g(b - 1, m) - g(a, n)))
ans += d
print ans
这题对我来说太难啦,看了报告半天才弄明白是咋回事。 高手们的解题报告相当飘逸。我来写一个造福菜鸟的。 首先来看一下Sample里的第一组数据。 1 2 2 1 2 经过一次变换之后就成了 5 5 5 5 4 它的原理就是 a0 a1 a2 a3 a4 -> (a4+a0+a1) (a0+a1+a2) (a1+a2+a3) (a2+a3+a4) (a3+a4+a0) 如果用矩阵相乘来描述,那就可以表述为1xN和NxN的矩阵相乘,结果仍为1xN矩阵 a = 1 2 2 1 2 b = 1 1 0 0 1 1 1 1 0 0 0 1 1 1 0 0 0 1 1 1 1 0 0 1 1 a * b = 5 5 5 5 4 所以最终结果就是:a * (b^k) 线性代数不合格的同鞋表示压力很大。。 对一个NxN矩阵求k次方,而且这个k很大,N也不小,怎么办? 所以有高手观察到了,这个矩阵长得有点特殊,可以找到一些规律: b^1 = [1, 1, 0, 0, 1] [1, 1, 1, 0, 0] [0, 1, 1, 1, 0] [0, 0, 1, 1, 1] [1, 0, 0, 1, 1] b^2 = [3, 2, 1, 1, 2] [2, 3, 2, 1, 1] [1, 2, 3, 2, 1] [1, 1, 2, 3, 2] [2, 1, 1, 2, 3] b^3 = [7, 6, 4, 4, 6] [6, 7, 6, 4, 4] [4, 6, 7, 6, 4] [4, 4, 6, 7, 6] [6, 4, 4, 6, 7] b^4 = [19, 17, 14, 14, 17] [17, 19, 17, 14, 14] [14, 17, 19, 17, 14] [14, 14, 17, 19, 17] [17, 14, 14, 17, 19] 发现神马没有。就是无论是b的几次幂,都符合A[i][j] = A[i-1][j-1]
高手说是这样推倒出来地: ““”
利用矩阵A,B具有a[i][j]=A[i-1][j-1],B[i][j]=B[i-1][j-1](i-1<0则表示i-1+n,j-1<0则表示j-1+n)
我们可以得出矩阵C=a*b也具有这个性质
C[i][j]=sum(A[i][t]*B[t][j])=sum(A[i-1][t-1],B[t-1][j-1])=sum(A[i-1][t],B[t][j-1])=C[i-1][j-1]
“”“ 这样就可以开一个N大小的数组来存放每次计算的结果了。而没必要用NxN。 N的问题解决了,但是k还是很大,怎么办? 这时候可以用二分法来求b^k b^k = b^1 * b^4 * b^16 。。。 计算过程中,必定会出现数字大于M的情况。 切记 x*y = (x%M)*(y%M) 最后,经过多次优化,这题的代码居然被高手写成了如下的一小坨,实在是。。给力哇
#include<iostream>
using namespace std;
int n,m,d,k;
void mul(long long a[],long long b[])
{
int i,j;
long long c[501];
for(i=0;i<n;++i)for(c[i]=j=0;j<n;++j)c[i]+=a[j]*b[i>=j?(i-j):(n+i-j)];
for(i=0;i<n;b[i]=c[i++]%m);
}
long long init[501],tmp[501];
int main()
{
int i,j;
scanf("%d%d%d%d",&n,&m,&d,&k);
for(i=0;i<n;++i)scanf("%I64d",&init[i]);
for(tmp[0]=i=1;i<=d;++i)tmp[i]=tmp[n-i]=1;
while(k)
{
if(k&1)mul(tmp,init);
mul(tmp,tmp);
k>>=1;
}
for(i=0;i<n;++i)if(i)printf(" %I64d",init[i]);else printf("%I64d",init[i]);
printf("\n");
return 0;
}
1. list对象的*操作符
>>> a = [[1]]*10
>>> a
[[1], [1], [1], [1], [1], [1], [1], [1], [1], [1]]
>>> a[1][0] = 2
>>> a
[[2], [2], [2], [2], [2], [2], [2], [2], [2], [2]]
>>>
也就是说,这10个对象实际上是指向的同一个list对象。 这是bug,还是feature?或者是优化? 总之是蛮让人火大的就是了。 用 a = [[0] for x in range(10)] 这种写法就没有这个问题了。 2. 深拷贝
>>> a = [[0] for x in range(10)]
>>> a
[[0], [0], [0], [0], [0], [0], [0], [0], [0], [0]]
>>> b = list(a)
>>> b
[[0], [0], [0], [0], [0], [0], [0], [0], [0], [0]]
>>> a[1][0] = 2
>>> b
[[0], [2], [0], [0], [0], [0], [0], [0], [0], [0]]
>>>
b = list(a) 意味着a和b中都存放这10个指针。指向[0], [0], [0] .... 这10个对象。 a[1][0] = 2 后 a 自己的值没有改变,改变的是第二个 [0] 对象。 由于 b 也是指向它的,所以打印b的时候会发现这一点。 这个问题是自己经常犯的问题,大多都是debug半天才知道怎么回事。 使用 import copy b = copy.deepcopy(a) 可以解决这个问题。 3. 如何避免这些问题 要时刻记得,python中的对象就只有两种,mutable和immutable。也就是可改变和不可改变。 immutable的包括:str tuple int ... mutable可改变的包括:list dict ... immutable的就是原子的。mutable里面存放的都是指向mutable或者immutable的指针。 调试的时候,可以使用id(obj)获得每个对象的id。这个貌似就是python管理的运行时的对象的地址。 如果发现两个obj的id相同,那他们就是同一个货。。
此题看了官方标程,才知道怎么做,其解法实在是相当巧妙! 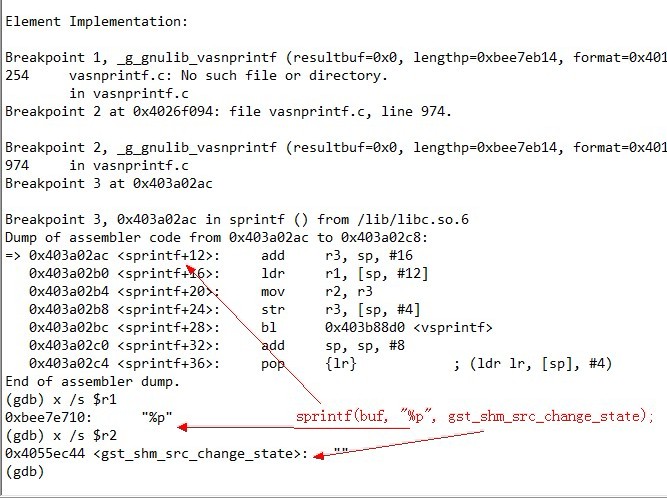 数据给出的点是顺时针顺序的,这点非常重要,我们可以根据这个整理出每条线段的方向。 我们可以发现这个规律: 对于某一列格子,在遇到第一条线段之前,一定是空白的,在第一条线段与第二条线段之间,一定是填充的。。以此类推。 而且经过这一列格子的线段数一定是偶数。 标程给出的算法是: 开一个二维数组保存每个格子黑色部分的面积。 如果这个线段是从左到右的,那么就给这条线段以上的格子加上一个负的面积。 如果是从右到左的,则加上一个正的面积。 如果是垂直的,则忽略这条线段。   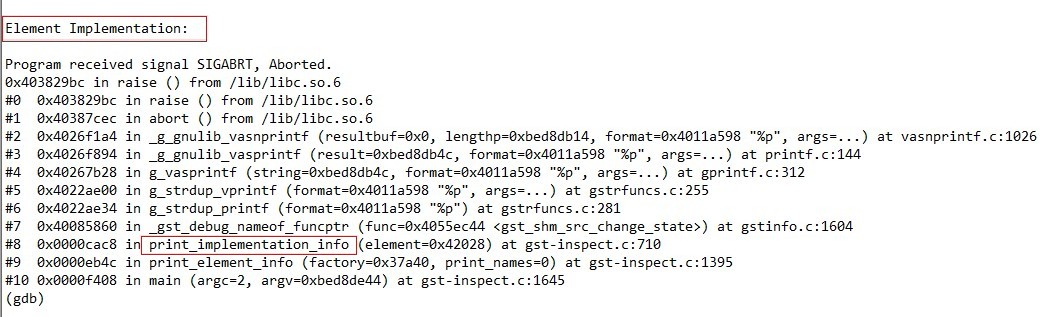 比如说第一条线段是从左到右的,在它以上一共有5个格子,面积依次为:-0.3 -0.6 -1.0 -1.0 -0.6 (大概的数字) 第二条线段是从右到左的,在它以上一共有9个格子,面积依次为:1.0 1.0 1.0 1.0 1.0 1.0 0.6 0.5 0.3 第三条线段是垂直的,忽略它。 第四条线段是从左到右的,在它以上一共有16个格子。。(其中有一个很小很小的) 等等。 给这些格子加上或正或负的增量之后,会发现,恰好完全空白的地方的面积都是0,都被抵消了。 而部分黑色的格子,它的值也是正确的。这就是这个算法的神奇之处~ 标程在这里
{$APPTYPE CONSOLE}
{$R+,Q+,S+,H+,O-}
uses
Math, SysUtils;
Type
Integer=LongInt;
Real=Extended;
Const
TaskID='ascii';
InFile=TaskID+'.in';
OutFile=TaskID+'.out';
MaxN=100;
MaxSize=100;
Eps=1e-12;
Var
N,W,H:Integer;
X,Y:Array[1..MaxN]Of Integer;
Res:Array[-1..MaxSize,-1..MaxSize]Of Real;
Procedure Load;
Var
I:Integer;
Begin
ReSet(Input,InFile);
Read(N,W,H);
For I:=1 To N Do Read(X[I],Y[I]);
Close(Input);
End;
Function Floor(A:Real):Integer;
Begin
Result:=Trunc(A+1000)-1000;
End;
Function Ceil(A:Real):Integer;
Begin
Result:=-Floor(-A);
End;
Procedure Process(X1,Y1,X2,Y2,By:Integer);
Var
I,X,Y,U,D:Integer;
XU,XD,YL,YR,Tmp:Real;
Begin
For X:=X1 To X2-1 Do Begin
YL:=(X-X1)/(X2-X1)*(Y2-Y1)+Y1;
YR:=((X+1)-X1)/(X2-X1)*(Y2-Y1)+Y1;
If YL<YR Then Begin
For I:=0 To Floor(YL)-1 Do Res[X,I]:=Res[X,I]+By;
D:=Floor(YL);
U:=Ceil(YR)-1;
If D=U Then Begin
Res[X,D]:=Res[X,D]+By*(YL-D+YR-D)/2;
End Else If D<U Then Begin
XU:=(D+1-Y1)/(Y2-Y1)*(X2-X1)+X1;
Res[X,D]:=Res[X,D]+By*(1-(XU-X)*(D+1-YL)/2);
XD:=(U-Y1)/(Y2-Y1)*(X2-X1)+X1;
Res[X,U]:=Res[X,U]+By*((YR-U)*(X+1-XD)/2);
For I:=D+1 To U-1 Do Begin
XU:=(I+1-Y1)/(Y2-Y1)*(X2-X1)+X1;
XD:=(I-Y1)/(Y2-Y1)*(X2-X1)+X1;
Res[X,I]:=Res[X,I]+By*(X+1-XD+X+1-XU)/2;
End;
End;
End Else Begin
For I:=0 To Floor(YR)-1 Do Res[X,I]:=Res[X,I]+By;
D:=Floor(YR);
U:=Ceil(YL)-1;
If D=U Then Begin
Res[X,D]:=Res[X,D]+By*(YL-D+YR-D)/2;
End Else If D<U Then Begin
XU:=(D+1-Y1)/(Y2-Y1)*(X2-X1)+X1;
Res[X,D]:=Res[X,D]+By*(1-(X+1-XU)*(D+1-YR)/2);
XD:=(U-Y1)/(Y2-Y1)*(X2-X1)+X1;
Res[X,U]:=Res[X,U]+By*((YL-U)*(XD-X)/2);
For I:=D+1 To U-1 Do Begin
XU:=(I+1-Y1)/(Y2-Y1)*(X2-X1)+X1;
XD:=(I-Y1)/(Y2-Y1)*(X2-X1)+X1;
Res[X,I]:=Res[X,I]+By*(XD-X+XU-X)/2;
End;
End;
End;
End;
End;
Procedure Solve;
Var
I,X1,Y1,X2,Y2:Integer;
Begin
FillChar(Res,SizeOf(Res),0);
For I:=1 To N Do Begin
X1:=X[I];
Y1:=Y[I];
X2:=X[I Mod N+1];
Y2:=Y[I Mod N+1];
If X1=X2 Then Continue;
If X1<X2 Then
Process(X1,Y1,X2,Y2,1)
Else
Process(X2,Y2,X1,Y1,-1);
End;
End;
Procedure Save;
Var
X,Y:Integer;
R:Real;
Begin
ReWrite(Output,OutFile);
For Y:=H-1 DownTo 0 Do Begin
For X:=0 To W-1 Do Begin
R:=Res[X,Y];
If R<1/4-Eps Then Write('.') Else If R<1/2-Eps Then Write('+') Else If R<3/4-Eps Then Write('o') Else If R<1-Eps Then Write('$') Else Write('#');
End;
WriteLn;
End;
Close(Output);
End;
begin
Load;
Solve;
Save;
end.
|