
2015年1月9日
本来我都忘记了,结果有网友提醒我要写,我就来写一写。
现在的年终总结已经没什么内容了,主要是GacUI (www.gaclib.net)的开发实在太漫长。我现在在做拖控件程序GacStudio,希望在做完之后可以有Blend编辑WPF的效果,在xml里面写data binding的时候不同的地方会有不同的intellisense。这当然是很难的,所以才想做。因此今年就把GacUI做到可以有Control Template、Item Template、Data Binding、XML Resource和加载,于是终于可以开始做GacStudio了。GacStudio整个会使用GacUI推荐的Data Binding来写。这有三个好处:1、检验Data Binding是否设计的好顺便抓bug;2、检验性能;3、证明GacUI是屌的,大家都可以用。
我还在github开了一个数据库项目,在https://github.com/vczh/herodb,不过因为现在没有台式机,笔记本太烂装不了Ubuntu的虚拟机,所以暂停开发,等到我设备到了我再继续写。这个东西写完之后会合并进GacUI作为扩展的一部分,可以开很多脑洞,这个我就不讲了。
我觉得2014年最伟大的成就就是,我终于搬去西雅图了,啊哈哈哈哈。
posted @
2015-01-08 14:58 陈梓瀚(vczh) 阅读(18013) |
评论 (14) |
编辑 收藏
2014年7月15日
上次有人来要求我写一篇文章谈谈什么代码才是好代码,是谁我已经忘记了,好像是AutoHotkey还是啥的专栏的作者。撇开那些奇怪的条款不谈,靠谱的 代码有一个共同的特点,就是DRY。DRY就是Don't Repeat Yourself,其实已经被人谈了好多年了,但是几乎所有人都会忘记。
什么是DRY(Don't Repeat Yourself)
DRY 并不是指你不能复制代码这么简单的。不能repeat的其实是信息,不是代码。要分析一段代码里面的什么东西时信息,就跟给物理题做受力分析一样,想每次 都做对其实不太容易。但是一份代码总是要不断的修补的,所以在这之前大家要先做好TDD,也就是Test Driven Development。这里我对自己的要求是覆盖率要高达95%,不管用什么手段,总之95%的代码的输出都要受到检验。当有了足够多的测试做后盾的时 候,不管你以后发生了什么,譬如说你发现你Repeat了什么东西要改,你才能放心大胆的去改。而且从长远的角度来看,做好TDD可以将开发出相同质量的代码的时间缩短到30%左右(这是我自己的经验值) 。
什么是信息
信息这个词不太好用语言下定义,不过我可以举个例子。譬如说你要把一个配置文件里面的字符串按照分隔符分解成几个字符串,你大概就会写出这样的代码:
// name;parent;description
void ReadConfig(const wchar_t* config)
{
auto p = wcschr(config, L';'); // 1
if(!p) throw ArgumentException(L"Illegal config string"); // 2
DoName(wstring(config, p)); // 3
auto q = wcschr(p + 1, L';'); // 4
if(!q) throw ArgumentException(L"Illegal config string"); // 5
DoParent(wstring(p + 1, q); // 6
auto r = wcschr(q + 1, L';'); // 7
if(r) throw ArgumentException(L"Illegal config string"); // 8
DoDescription(q + 1); // 9
}
这段短短的代码重复了多少信息?
- 分隔符用的是分号(1、4、7)
- 第二/三个片段的第一个字符位于第一/二个分号的后面(4、6、7、9)
- 格式检查(2、5、8)
- 异常内容(2、5、8)
除了DRY以外还有一个问题,就是处理description的方法跟name和parent不一样,因为他后面再也没有分号了。
那这段代码要怎么改呢?有些人可能会想到,那把重复的代码抽取出一个函数就好了:
wstring Parse(const wchar_t& config, bool end)
{
auto next = wcschr(config, L';');
ArgumentException up(L"Illegal config string");
if (next)
{
if (end) throw up;
wstring result(config, next);
config = next + 1;
return result;
}
else
{
if (!end) throw up;
wstring result(config);
config += result.size();
return result;
}
}
// name;parent;description
void ReadConfig(const wchar_t* config)
{
DoName(Parse(config, false));
DoParent(Parse(config, false));
DoDescription(Parse(config, true));
}
是不是看起来还很别扭,好像把代码修改了之后只把事情搞得更乱了,而且就算config对了我们也会创建那个up变量,就仅仅是为了不 重复代码。而且这份代码还散发出了一些不好的味道,因为对于Name、Parent和Description的处理方法还是不能统一,Parse里面针对 end变量的处理看起来也是很重复,但实际上这是无法在这样设计的前提下消除的。所以这个代码也是不好的,充其量只是比第一份代码强一点点。
实 际上,代码之所以要写的好,之所以不能repeat东西,是因为产品狗总是要改需求,不改代码你就要死,改代码你就要加班,所以为了减少修改代码的痛苦, 我们不能repeat任何信息。举个例子,有一天产品狗说,要把分隔符从分号改成空格!一下子就要改两个地方了。description后面要加tag! 这样你处理description的方法又要改了因为他是以空格结尾不是0结尾。
因此针对这个片段,我们需要把它改成这样:
vector<wstring> SplitString(const wchar_t* config, wchar_t delimiter)
{
vector<wstring> fragments;
while(auto next = wcschr(config, delimiter))
{
fragments.push_back(wstring(config, next));
config = next + 1;
}
fragments.push_back(wstring(config));
return fragments; // C++11就是好!
}
void ReadConfig(const wchar_t* config)
{
auto fragments = SplitString(config, L';');
if(fragments.size() != 3)
{
throw ArgumentException(L"Illegal config string");
}
DoName(fragments[0]);
DoParent(fragments[1]);
DoDescription(fragments[2]);
}
我们可以发现,分号(L';')在这里只出现了一次,异常内容也只出现了一次,而且处理name、parent和 description的代码也没有什么区别了,检查错误也更简单了。你在这里还给你的Library增加了一个SplitString函数,说不定在以 后什么地方就用上了,比Parse这种专门的函数要强很多倍。
大家可以发现,在这里重复的东西并不仅仅是复制了代码,而是由于你把 同一个信息散播在了代码的各个部分导致了有很多相近的代码也散播在各个地方,而且还不是那么好通过抽成函数的方法来解决。因为在这种情况下,就算你把重复 的代码抽成了Parse函数,你把函数调用了几次实际上也等于重复了信息。因此正确的方法就是把做事情的方法变一下,写成SplitString。这个 SplitString函数并不是通过把重复的代码简单的抽取成函数而做出来的。去掉重复的信息会让你的代码的结构发生本质的变化。
这个问题其实也有很多变体:
- 不能有Magic Number。L';'出现了很多遍,其实就是个Magic Number。所以我们要给他个名字,譬如说delimiter。
- 不要复制代码。这个应该不用我讲了。
- 解耦要做成正交的。SplitString虽然不是直接冲着读config来写的,但是它反映了一个在其它地方也会遇到的常见的问题。如果用Parse的那个版本,显然只是看起来解决了问题而已,并没有给你带来任何额外的效益。
信息一旦被你repeat了,你的代码就会不同程度的出现各种腐烂或者破窗,上面那三条其实只是我能想到的比较常见的表现形式。这件事情也告诉我们,当高手告诉你什么什么不能做的时候,得想一想背后的原因,不然跟封建迷信有什么区别。
posted @
2014-07-15 06:44 陈梓瀚(vczh) 阅读(15989) |
评论 (9) |
编辑 收藏
2014年3月23日
文章中引用的代码均来自https://github.com/vczh/tinymoe。
看了前面的三篇文章,大家应该基本对Tinymoe的代码有一个初步的感觉了。在正确分析"print sum from 1 to 100"之前,我们首先得分析"phrase sum from (lower bound) to (upper bound)"这样的声明。Tinymoe的函数声明又很多关于block和sentence的配置,不过这里并不打算将所有细节,我会将重点放在如何写一个针对无歧义语法的递归下降语法分析器上。所以我们这里不会涉及sentence和block的什么category和cps的配置。
虽然"print sum from 1 to 100"无法用无歧义的语法分析的方法做出来,但是我们可以借用对"phrase sum from (lower bound) to (upper bound)"的语法分析的结果,动态构造能够分析"print sum from 1 to 100"的语法分析器。这种说法看起来好像很高大上,但是其实并没有什么特别难的技巧。关于"构造"的问题我将在下一篇文章《跟vczh看实例学编译原理——三:Tinymoe与有歧义语法分析》详细介绍。
在我之前的博客里我曾经写过《如何手写语法分析器》,这篇文章讲了一些简单的写递归下降语法分析器的规则,尽管很多人来信说这篇文章帮他们解决了很多问题,但实际上细节还不够丰富,用来对编程语言做语法分析的话,还是会觉得复杂性太高。这篇文章也同时作为《如何手写语法分析器》的补充。好了,我们开始进入无歧义语法分析的主题吧。
我们需要的第一个函数是用来读token并判断其内容是不是我们希望看到的东西。这个函数比较特别,所以单独拿出来讲。在词法分析里面我们已经把文件分行,每一行一个CodeToken的列表。但是由于一个函数声明独占一行,因此在这里我们只需要对每一行进行分析。我们判断这一行是否以cps、category、symbol、type、phrase、sentence或block开头,如果是那Tinymoe就认为这一定是一个声明,否则就是普通的代码。所以这里假设我们找到了一行代码以上面的这些token作为开头,于是我们就要进入语法分析的环节。作为整个分析器的基础,我们需要一个ConsumeToken的函数:
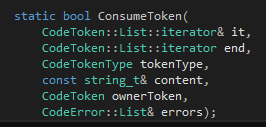
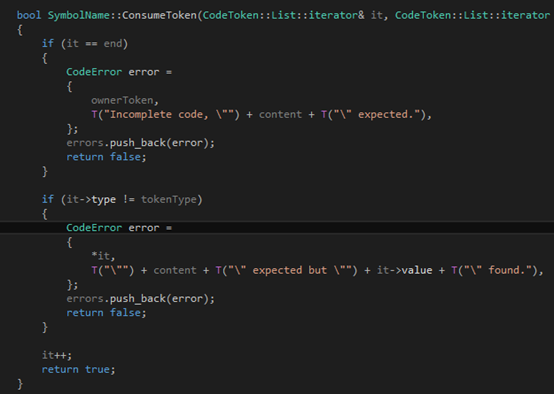
作为一个纯粹的C++11的项目,我们应该使用STL的迭代器。其实在写语法分析器的时候,基于迭代器的代码也比基于"token在数组里的下表"的代码要简单得多。这个函数所做的内容是这样的,它查看it指向的那个token,如果token的类型跟tokenType描述的一样,他就it++然后返回true;否则就是用content和ownerToken来产生一个错误信息加入errors列表里,然后返回false。当然,如果传进去的参数it本身就等于end,那自然要产生一个错误。自然,函数体也十分简单:
那对于标识符和数字怎么办呢?明眼人肯定一眼就看出来,这是给检查符号用的,譬如左括号、右括号、冒号和关键字等。在声明里面我们是不需要太复杂的东西的,因此我们还需要两外一个函数来输入标识符。Tinymoe事实上有两个针对标识符的语法分析函数,第一个是读入标识符,第二个不仅要读入标识符还要判断是否到了行末否则报错:
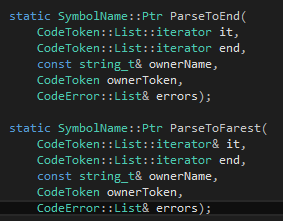
在这里我需要强调一个重点,在写语法分析器的时候,函数的各式一定要整齐划一。Tinymoe的语法分析函数有两个格式,分别是针对parse一行的一个部分,和parse一个文件的一些行的。ParseToEnd和ParseToFarest就属于parse一行的一个部分的函数。这种函数的格式如下:
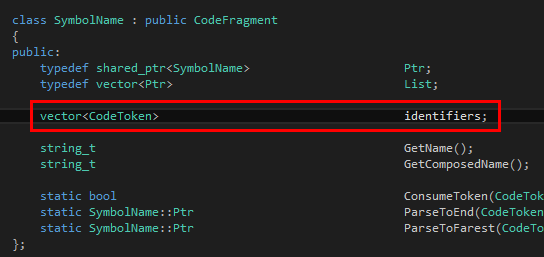
返回值一定是语法树的一个节点。在这里我们以share_ptr<SymbolName>作为标识符的节点。一个标识符可以含有多个标识符token,譬如说the Chinese people、the real Tinymoe programmer什么的。因此我们可以简单地推测SymbolName里面有一个vector<CodeToken>。这个定义可以在TinymoeLexicalAnalyzer.h的最后一部分找到。
前两个参数分别是iterator&和指向末尾的iterator。末尾通常指"从这里开始我们不希望这个parser函数来读",当然这通常就意味着行末。我们把"末尾"这个概念抽取出来,在某些情况下可以得到极大的好处。
最后一个token一定是vector<CodeError>&,用来存放过程中遇到的错误。
除了函数格式以外,我们还需要所有的函数都遵循某些前置条件和后置条件。在语法分析里,如果你试图分析一个结构但是不幸出现了错误,这个时候,你有可能可以返回一个语法树的节点,你也有可能什么都返回不了。于是这里就有两种情况:
你可以返回,那就证明虽然输入的代码有错误,但是你成功的进行了错误恢复——实际上就是说,你觉得你自己可以猜测这份代码的作者实际是要表达什么意思——于是你要移动第一个iterator,让他指向你第一个还没读到的token,以便后续的语法分析过程继续进行下去。
你不能返回,那就证明你恢复不了,因此第一个iterator不能动。因为这个函数有可能只是为了测试一下当前的输入是否满足一个什么结构。既然他不是,而且你恢复不出来——也就是你猜测作者本来也不打算在这里写某个结构——因此iterator不能动,表示你什么都没有读。
当你根据这样的格式写了很多语法分析函数之后,你会发现你可以很容易用简单结构的语法分析函数,拼凑出一个复杂的语法分析函数。但是由于Tinymoe的声明并没有一个编程语言那么复杂,所以这种嵌套结构出现的次数并不多,于是我们这里先跳过关于嵌套的讨论,等到后面具体分析"函数指针类型的参数"的时候自然会涉及到。
说了这么多,我觉得也应该上ParseToEnd和ParseToFarest的代码了。首先是ParseToEnd:
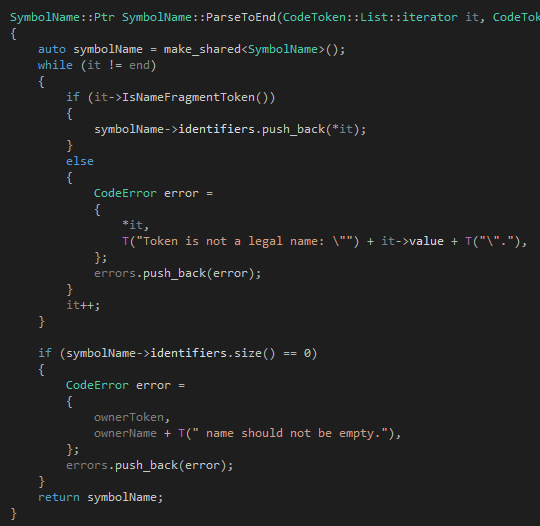
我们很快就可以发现,其实语法分析器里面绝大多数篇幅的代码都是关于错误处理的,真正处理正确代码的部分其实很少。ParseToEnd做的事情不多,他就是从it开始一直读到end的位置,把所有不是标识符的token都扔掉,然后把所有遇到的标识符token都连起来作为一个完整的标识符。也就是说,ParseToEnd遇到类似"the real 100 Tinymoe programmer"的时候,他会返回"the real Tinymoe programmer",然后在"100"的地方报一个错误。
ParseToFarest的逻辑差不多:
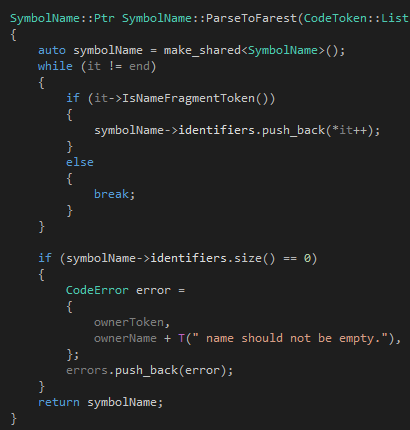
只是当这个函数遇到"the real 100 Tinymoe programmer"的时候,会返回"the real",然后把光标移动到"100",但是没有报错。
看了这几个基本的函数之后,我们可以进入正题了。做语法分析器,当然还是从文法开始。跟上一篇文章一样,我们来尝试直接构造一下文法。但是语法分析器跟词法分析器的文法的区别是,词法分析其的文法可以 "定义函数"和"调用函数"。
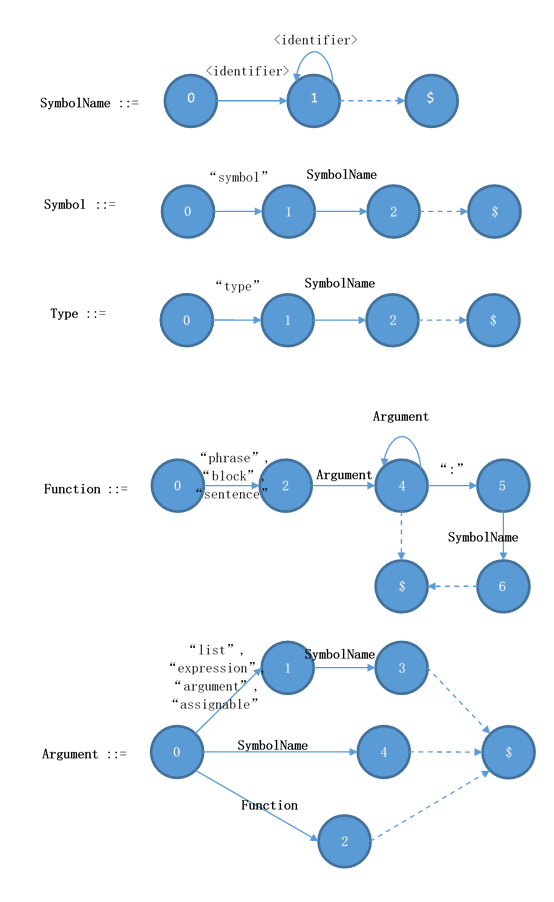
首先,我们来看symbol的文法:
SymbolName ::= <identifier> { <identifier> }
Symbol ::= "symbol" SymbolName
其次,就是type的声明。type是多行的,不过我们这里只关心开头的一样:
Type ::= "type" SymbolName [ ":" SymbolName ]
在这里,中括号代表可有可无,大括号代表重复0次或以上。现在让我们来看函数的声明。函数的生命略为复杂:
Function ::= ("phrase" | "sentence" | "block") { SymbolName | "(" Argument ")" } [ ":" SymbolName ]
Argument ::= ["list" | "expression" | "argument" | "assignable"] SymbolName
Argument ::= SymbolName
Argument ::= Function
Declaration ::= Symbol | Type | Function
在这里我们看到Function递归了自己,这是因为函数的参数可以是另一个函数。为了让这个参数调用起来更加漂亮一点,你可以把参数写成函数的形式,譬如说:
pharse (the number) is odd : odd numbers
return the number % 2 == 1
end
print all (phrase (the number) is wanted) in (numbers)
repeat with the number in all numbers
if the number is wanted
print the number
end
end
end
print main
print all odd numbers in array of (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
end
我们给"(the number) is odd"这个判断一个数字是不是奇数的函数,起了一个别名叫"odd numbers",这个别名不能被调用,但是他等价于一个只读的变量保存着奇数函数的函数指针。于是我们就可以把它传递给"print all (…) in (…)"这个函数的第一个参数了。第一个参数声明成函数,所以我们可以在print函数内直接调用这个参数指向的odd numbers函数。
事实上Tinymoe的SymbolName是可以包含关键字的,但是我为了不让它写的太长,于是我就简单的写成了上面的那条式子。那Argument是否可以包含关键字呢?答案当然是可以的,只是当它以list、expression、argument、assignable、phrase、sentence、block开始的时候,我们强行认为他有额外的意义。
现在一个Tinymoe的声明的第一行都由Declaration来定义。当我们识别出一个正确的Declaration之后,我们就可以根据分析的结果来对后面的行进行分析。譬如说symbol后面没有东西,于是就这么完了。type后面都是成员函数,所以我们一直找到"end"为止。函数的函数体就更复杂了,所以我们会直接跳到下一个看起来像Declaration的东西——也就是以symbol、type、phrase、sentence、block、cps、category开始的行。这些步骤都很简单,所以问题的重点就是,如何根据Declaration的文法来处理输入的字符串。
为了让文法可以真正的运行,我们需要把它做成状态机。根据之前的描述,这个状态及仍然需要有"定义函数"和"执行函数"的能力。我们可以先假装他们是正则表达式,然后把整个状态机画出来。这个时候,"函数"本身我们把它看成是一个跟标识符无关的输入,然后就可以得到下面的状态机:
这样我们的状态机就暂时完成了。但是现在还不能直接把它转换成代码,因为当我们遇到一个输入,而我们可以选择调用函数,而且可以用的函数还不止一个的时候,那应该怎么办呢?答案就是要检查我们的文法是不是有歧义。
文法的歧义是一个很有意思的问题。在我们真的实践一个编译器的时候,我们会遇到三种歧义:
文法本身就是有歧义的,譬如说C++著名的A* B;的问题。当A是一个变量的时候,这是一个乘法表达式。当A是一个类型的时候,这是一个变量声明语句。如果我们在语法分析的时候不知道A到底指向的是什么东西,那我们根本无从得知这一句话到底要取什么意思,于是要么返回错误,要么两个结果一起返回。这就是问法本身固有的歧义。
文法本身没有歧义,但是在分析的过程中却无法在走每一步的时候都能够算出唯一的"下一个状态"。譬如说C#著名的A<B>C;问题。当A是一个变量的时候,这个语句是不成立的,因为C#的一个语句的根节点不能是一个操作符(这里是">")。当A是一个类型的时候,这是一个变量声明语句。从结果来看,这并没有歧义,但是当我们读完A<B>的时候仍然不知道这个语句的结构到底是取哪一种。实际上B作为类型参数,他也可以有B<C>这样的结构,因此这个B可以是任意长的。也就是说我们只有在">"结束之后再多读几个字符才能得到正确的判断。譬如说C是"(1)",那我们知道A应该是一个模板函数。如果C是一个名字,A多半应该是一个类型。因此我们在做语法分析的时候,只能两种情况一起考虑,并行处理。最后如果哪一个情况分析不下去了,就简单的扔掉,剩下的就是我们所需要的。
文法本身没有歧义,而且分析的过程中只要你每一步都往后多看最多N个token,酒可以算出唯一的"下一个状态"到底是什么。这个想必大家都很熟悉,因为这个N就是LookAhead。所谓的LL(1)、SLR(1)、LR(1)、LALR(1)什么的,这个1其实就是N=1的情况。N当然不一定是1,他也可以是一个很大的数字,譬如说8。一个文法的LookAhead是多少,这是文法本身固有的属性。一个LR(2)的状态机你非要在语法分析的时候只LookAhead一个token,那也会遇到第二种歧义的情况。如果C语言没有typedef的话,那他就是一个带有LookAhead的没有歧义的语言了。
看一眼我们刚才写出来的文法,明显就是LookAhead=0的情况,而且连左递归都没有,写起来肯定很容易。那接下来我们要做的就是给"函数"算first set。一个函数的first set,顾名思义就是,他的第一个token都可以是什么。SymbolName、Symbol、Type、Function都不用看了,因为他们的文法第一个输入都是token,那就是他们的first set。最后就剩下Argument。Argument的第一个token除了list、expression、argument和assignable以外,还有Function。因此Argument的first set就是这些token加上Function的first set。如果文法有左递归的话,也可以用类似的方法做,只要我们在函数A->B->C->…->A的时候,知道A正在计算于是返回空集就可以了。当然,只有左递归才会遇到这种情况。
然后我们检查一下每一个状态,可以发现,任何一个状态出去的所有边,他接受的token或者函数的first set都是没有交集的。譬如Argument的0状态,第一条边接受的token、第二条边接受的SymbolName的first set,和第三条边接受的Function的first set,是没有交集的,所以我们就可以断定,这个文法一定没有歧义。按照上次状态机到代码的写法,我们可以机械的写出代码了。写代码的时候,我们把每一个文法的函数,都写成一个C++的函数。每到一个状态的时候,我们看一下当前的token是什么,然后再决定走哪条边。如果选中的边是token边,那我们就跳过一个token。如果选中的边是函数边,那我们不跳过token,转而调用那个函数,让函数自己去跳token。《如何手写语法分析器》用的也是一样的方法,如果对这个过程不清楚的,可以再看一遍这个文章。
于是我们到了定义语法树的时候了。幸运的是,我们可以直接从文法上看到语法树的形状,然后稍微做一点微调就可以了。我们把每一个函数都看成一个类,然后使用下面的规则:
对于A、A B、A B C等的情况,我们转换成class里面有若干个成员变量。
对于A | B的情况,我们把它做成继承,A的语法树和B的语法树继承自一个基类,然后这个基类的指针就放在class里面做成员变量。
对于{ A },或者A { A }的情况,那个成员变量就是一个vector。
对于[ A ]的情况,我们就当A看,区别只是,这个成员变量可以填nullptr。
对于每一个函数,要不要用shared_ptr来装则见仁见智。于是我们可以直接通过上面的文法得到我们所需要的语法树:
首先是SymbolName:
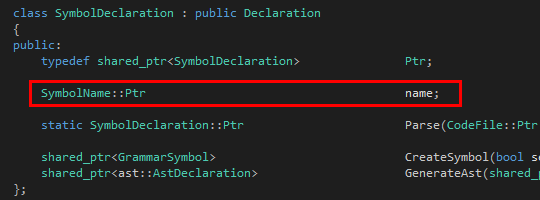
其次是Symbol:
然后是Type:
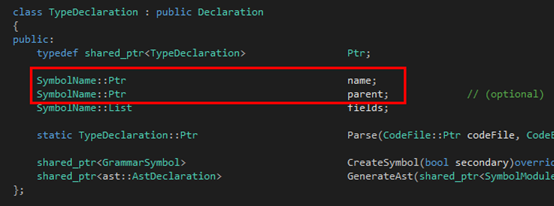
接下来是Argument:
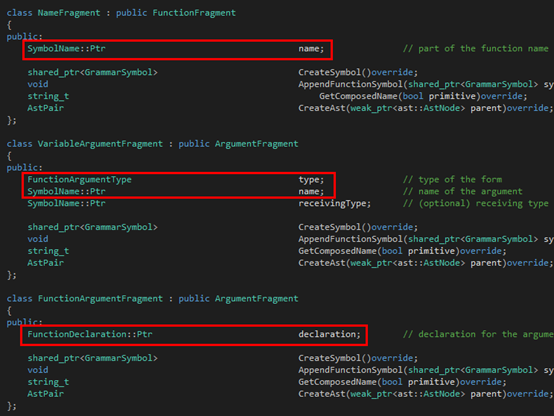
最后是Function:
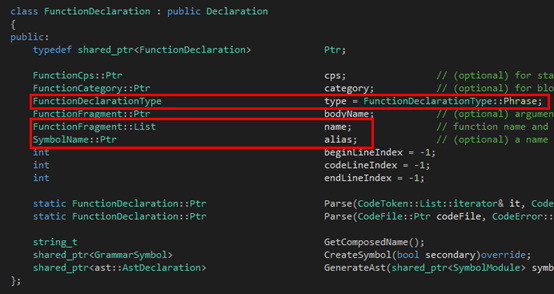
大家可以看到,在Argument那里,同时出去的三条边就组成了三个子类,都继承自FunctionFragment。图中红色的部分就是Tinymoe源代码里在上述的文法里出现的那部分。至于为什么还有多出来的部分,其实是因为这里的文法是为了叙述方便简化过的。至于Tinymoe关于函数声明的所有语法可以分别看下面的四个github的wiki page:
https://github.com/vczh/tinymoe/wiki/Phrases,-Sentences-and-Blocks
https://github.com/vczh/tinymoe/wiki/Manipulating-Functions
https://github.com/vczh/tinymoe/wiki/Category
https://github.com/vczh/tinymoe/wiki/State-and-Continuation
在本章的末尾,我将向大家展示Tinymoe关于函数声明的那一个Parse函数。文章已经把所有关键的知识点都讲了,具体怎么做大家可以上https://github.com/vczh/tinymoe 阅读源代码来学习。
首先是我们的函数头:
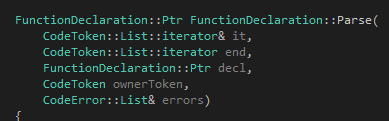
回想一下我们之前讲到的关于语法分析函数的格式:
返回值一定是语法树的一个节点。在这里我们以share_ptr<SymbolName>作为标识符的节点。一个标识符可以含有多个标识符token,譬如说the Chinese people、the real Tinymoe programmer什么的。因此我们可以简单地推测SymbolName里面有一个vector<CodeToken>。这个定义可以在TinymoeLexicalAnalyzer.h的最后一部分找到。
前两个参数分别是iterator&和指向末尾的iterator。末尾通常指"从这里开始我们不希望这个parser函数来读",当然这通常就意味着行末。我们把"末尾"这个概念抽取出来,在某些情况下可以得到极大的好处。
最后一个token一定是vector<CodeError>&,用来存放过程中遇到的错误。
我们可以清楚地看到这个函数满足上文提出来的三个要求。剩下来的参数有两个,第一个是decl,如果不为空那代表调用函数的人已经帮你吧语法树给new出来了,你应该直接使用它。领一个参数ownerToken则是为了产生语法错误使用的。然后我们看代码:
第一步,我们判断输入是否为空,然后根据需要报错:
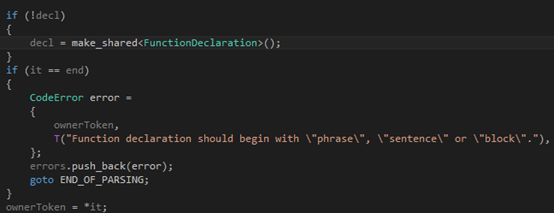
第二步,根据第一个token来确定函数的形式是phrase、sentence还是block,并记录在成员变量type里:
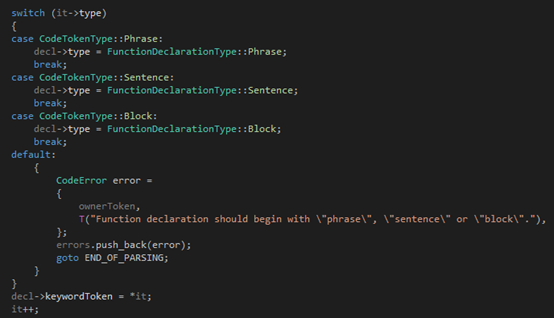
第三步是一个循环,我们根据当前的token(还记不记得之前说过,要先看一下token是什么,然后再决定走哪条边?)来决定我们接下来要分析的,是ArgumentFragment的两个子类(分别是VariableArgumentFragment和FunctionArgumentFragment),还是普通的函数名的一部分,还是说函数已经结束了,遇到了一个冒号,因此开始分析别名:
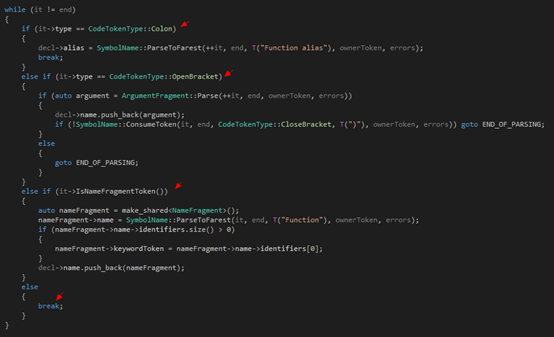
最后就不贴了,是检查格式是否满足语义的一些代码,譬如说block的函数名必须由参数开始啦,或者phrase的参数不能是argument和assignable等。
这篇文章就到此结束了,希望大家在看了这片文章之后,配合wiki关于语法的全面描述,已经知道如何对Tinymoe的声明部分进行语法分析。紧接着就是下一篇文章——Tinymoe与带歧义语法分析了,会让大家明白,想对诸如"print sum from 1 to 100"这样的代码做语法分析,也不需要多复杂的手段就可以做出来。
posted @
2014-03-23 00:51 陈梓瀚(vczh) 阅读(8504) |
评论 (2) |
编辑 收藏
2014年3月2日
文章中引用的代码均来自https://github.com/vczh/tinymoe。
实现Tinymoe的第一步自然是一个词法分析器。词法分析其所作的事情很简单,就是把一份代码分割成若干个token,记录下他们所在文件的位置,以及丢掉不必要的信息。但是Tinymoe是一个按行分割的语言,自然token列表也就是二维的,第一维是行,第二维是每一行的token。在继续讲词法分析器之前,先看看Tinymoe包含多少token:
符号:(、)、,、:、&、+、-、*、/、\、%、<、>、<=、>=、=、<>
关键字:module、using、phrase、sentence、block、symbol、type、cps、category、expression、argument、assignable、list、end、and、or、not
数字:123、456.789
字符串:"abc\r\ndef"
标识符:tinymoe
注释:-- this is a comment
Tinymoe对于token有一个特殊的规定,就是字符串和注释都是单行的。因此如果一个字符串在没有结束之前就遇到了换行,那么这种写法定义为你遇到了一个没有右双引号的字符串,需要报个错,然后下一行就不是这个字符串的内容了。
一个词法分析器所需要做的事情,就是把一个字符串分解成描述此法的数据结构。既然上面已经说到Tinymoe的token列表是二维的,因此数据结构肯定会体现这个观点。Tinymoe的词法分析器代码可以在这里找到:https://github.com/vczh/tinymoe/blob/master/Development/Source/Compiler/TinymoeLexicalAnalyzer.h。
首先是token:
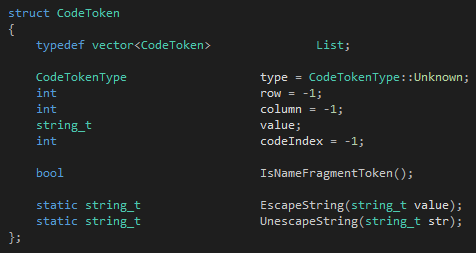
CodeTokenType是一个枚举类型,标记一个token的类型。这个类型比较细化,每一个关键字有自己的类型,每一个符号也有自己的类型,剩下的按种类来分。我们可以看到token需要记录的最关键的东西只有三个:类型、内容和代码位置。在token记录代码位置是十分重要的,正确地记录代码位置可以让你能够报告带位置的错误、从语法树的节点还原成代码位置、甚至在调试的时候可以把指令也换成位置。
这里需要提到的是,string_t是一个typedef,具体的声明可以在这里看到:https://github.com/vczh/tinymoe/blob/master/Development/Source/TinymoeSTL.h。Tinymoe是完全由标准的C++11和STL写成的,但是为了适应不同情况的需要,Tinymoe分为依赖code page的版本和Unicode版本。如果编译Tinymoe代码的时候声明了全局的宏UNICODE_TINYMOE的话,那Tinymoe所有的字符处理将使用wchar_t,否则使用char。char的类型和Tinymoe编译器在运行的时候操作系统当前的code page是绑定的。所以这里会有类似string_t啊、ifstream_t啊、char_t等类型,会在不同的编译选项的影响下指向不同的STL类型或者原生的C++类型。github上的VC++2013工程使用的是wchar_t的版本,所以string_t就是std::wstring。
Tinymoe的词法分析器除了token的类型以外,肯定还需要定义整个文件结构在词法分析后的结果:
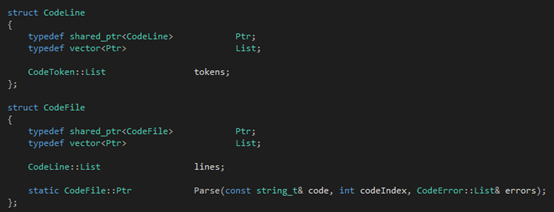
这个数据结构体现了"Tinymoe的token列表是二维的"的这个观点。一个文件会被词法分析器处理成一个shared_ptr<CodeFIle>对象,CodeFile::lines记录了所有非空的行,CodeLine::tokens记录了该行的所有token。
现在让我们来看词法分析的具体过程。关于如何从正则表达式构造词法分析器可以在这里(http://www.cppblog.com/vczh/archive/2008/05/22/50763.html)看到,不过我们今天要讲一讲如何人肉构造词法分析器。方法其实是一样的,首先人肉构造状态机,然后把用状态机分析输入的字符串的代码抄过来就可以了。但是很少有人会解耦得那么开,因为这样写很容易看不懂,其次有可能会遇到一些极端情况是你无法用纯粹的正则表达式来分词的,譬如说C++的raw string literal:R"tinymoe(这里的字符串没有转义)tinymoe"。一个用【R"<一些字符>(】开始的字符串只能由【)<同样的字符>"】来结束,要顺利分析这种情况,只能通过在状态机里面做hack才能解决。这就是为什么我们人肉构造词法分析器的时候,会把状态和动作都混在一起写,因为这样便于处理特殊情况。
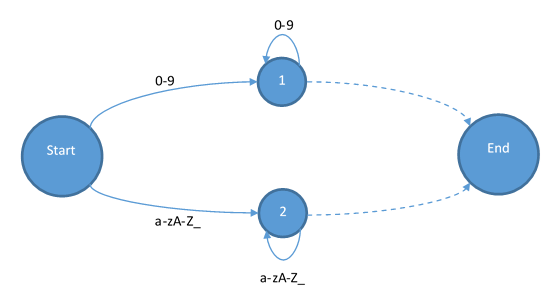
不过幸好的是,Tinymoe并没有这种情况发生。所以我们可以直接从状态机入手。为了简单起见,我在下面的状态机中去掉所有不是+和-的符号。首先,我们需要一个起始状态和一个结束状态:

首先我们添加整数和标识符进去:
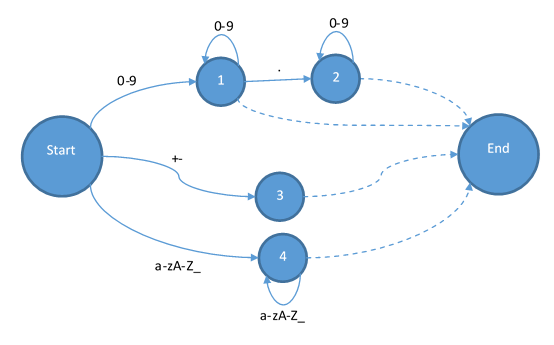
其次是加减和浮点:
最后把字符串和注释补全:
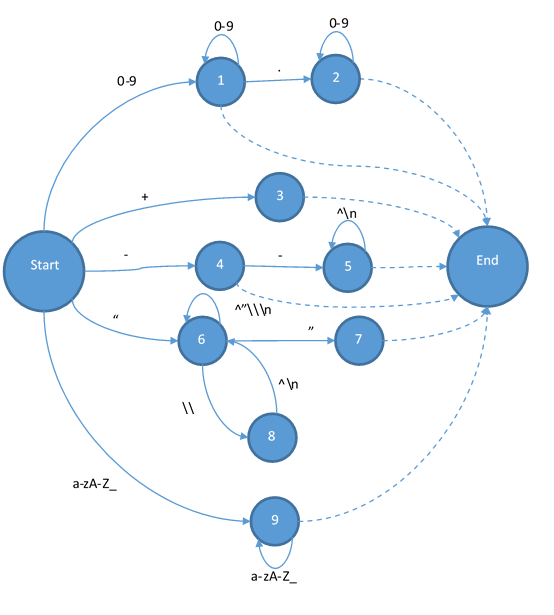
这样状态机就已经完成了。读过编译原理的可能会问,为什么终结状态都是由虚线而不是带有输入的实现指向的?因为虚线在这里有特殊的意义,也就是说它不能移动输入的字符串的指针,而且他还要负责添加一个token。当状态跳到End之后,那他就会变成Start,所以实际上Start和End是同一个状态。这个状态机也不是输入什么字符都能跳转到下一个状态的。所以当你发现输入的字符让你无路可走的时候,你就是遇到了一个词法错误。
这样我们的设计就算完成了,接下来就是如何用C++来实现它了。为了让代码更容易阅读,我们应该给Start和1-9这么多状态起名字,做法如下:
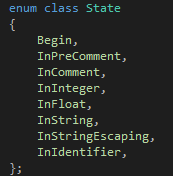
在这里类似状态3这样的状态被我省略掉了,因为这个状态唯一的出路就是虚线,所以跳到这个状态意味着你要立刻执行虚线,也就是说你不需要做"跳到这个状态"这个动作。因此它不需要有一个名字。
然后你只要按照下面的做法翻译这个状态机就可以了:
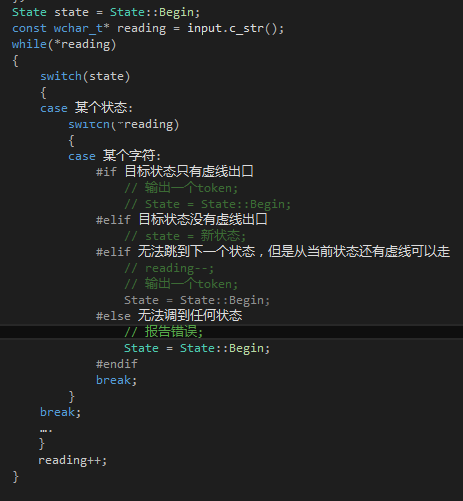
只要写到这里,那么我们就初步完成了词法分析器了。其实任何系统的主要功能都是相对容易实现的,往往是次要的功能才需要花费大量的精力来完成,而且还很容易出错。在这里"次要的功能"就是——记录token的行列号,还有维护CodeFile::lines避免空行的出现!
尽管我已经做过了那么多次词法分析器,但是我仍然无法一气呵成写对,仍然会出一些bug。面对编译器这种纯计算程序,debug的最好方法就是写单元测试。不过对于不熟悉单元测试的人来讲可能很难一下子想到要做什么测试,在这里我可以把我给Tinymoe谢的一部分单元测试在这里贴一下。
第一个,当然是传说中的"Hello, world!"测试了:
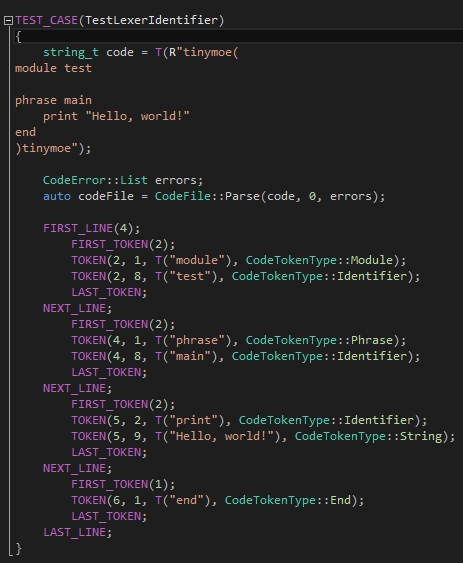
TEST_CASE和TEST_ASSERT(这里暂时没有直接用到TEST_ASSERT)是我为了开发Tinymoe随手撸的一个宏,可以在Tinymoe的代码里看到。为了检查我们有没有粗心大意,我们有必要检查词法分析器的任何一个输出的数据,譬如每一行有多少token,譬如每一个token的行号列好内容和类型。我为了让这些枯燥的测试用例容易看懂,在这个文件(https://github.com/vczh/tinymoe/blob/master/Development/TinymoeUnitTest/TestLexicalAnalyzer.cpp)的开头可以看到FIRST_LINE、FIRST_TOKEN、TOKEN、LAST_TOKEN、NEXT_LINE、LAST_LINE是怎么定义的。其实吧这些宏展开,就是一个普通的遍历CodeFile::lines和CodeLine::tokens的程序,然后TEST_ASSERT一下CodeToken的每一个成员是否我们所需要的值。我相信看到这里很多人肯定把重点放在宏和炫技上,而不是如何设计测试用例上,这是有前途的程序员和没前途的程序员面对一份资料的反应的重要区别之一。没前途的程序员总是会把注意力放在一些莫名其妙的地方,其中一个例子就是"过早优化"。
第二个测试用例针对的是整数和浮点的输出和报错上,重点在于检查每一个token的列号是不是正确的计算了出来:
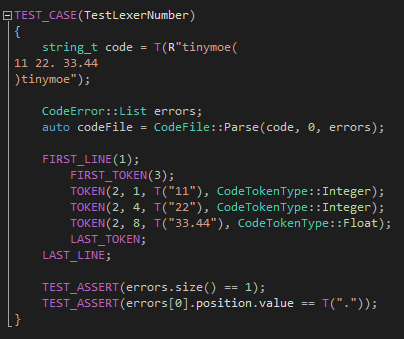
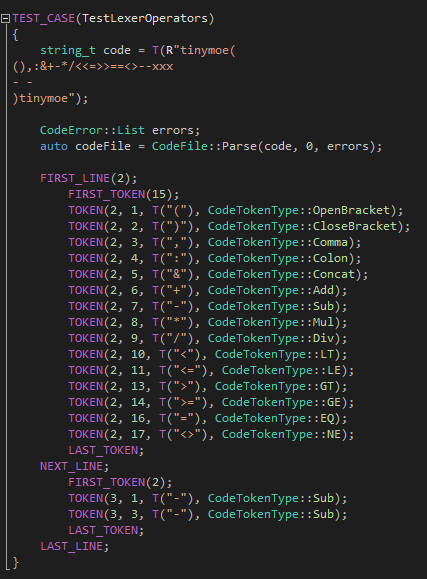
第三个测试用例的重点主要是-符号和—注释的分析:
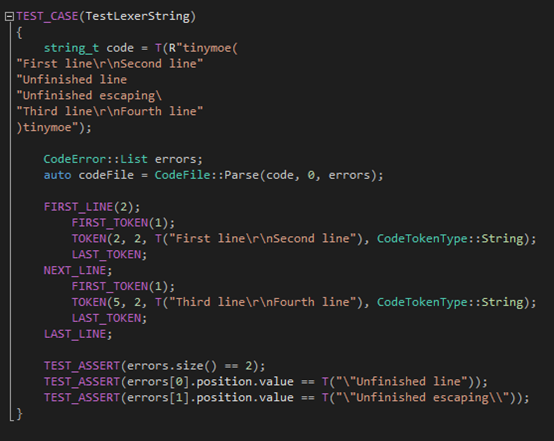
第四个测试用例则是测试字符串的escaping和在面对换行的时候是否正确的处理(之前提到字符串不能换行,遇到一个突然的换行将会被看成缺少双引号):
鉴于词法分析本来内容也不多,所以这篇文章也不会太长。相信有前途的程序员也会在这里得到一些编译原理以外的知识。下一篇文章将会描述Tinymoe的函数头的语法分析部分,将会描述一个编译器的不带歧义的语法分析是如何人肉出来的。敬请期待。
posted @
2014-03-02 07:44 陈梓瀚(vczh) 阅读(13136) |
评论 (10) |
编辑 收藏
2014年3月1日
最近学习C++11的variadic template argument,终于可以摆脱用fpmacro模板来复制一大堆代码的做法了,好开心。这个例子的main函数用lambda写了一个斐波那契数列的递归计算函数。跟以往不同的是,在Y函数的帮助下,这个lambda表达是可以成功看到自己,然后递归调用。当然这仍然需要用普通的C++递归来实现,并不是λ-calculus那个高大上的Y Combinator。
#include
<functional>
#include
<memory>
#include
<iostream>
#include
<string>
using
namespace std;
template<typename
TResult, typename ...TArgs>
class
YBuilder
{
private:
function<TResult(function<TResult(TArgs...)>, TArgs...)> partialLambda;
public:
YBuilder(function<TResult(function<TResult(TArgs...)>, TArgs...)> _partialLambda)
:partialLambda(_partialLambda)
{
}
TResult operator()(TArgs ...args)const
{
return partialLambda(
[this](TArgs ...args)
{
return
this->operator()(args...);
}, args...);
}
};
template<typename
TMethod>
struct
PartialLambdaTypeRetriver
{
typedef
void
FunctionType;
typedef
void
LambdaType;
typedef
void
YBuilderType;
};
template<typename
TClass, typename
TResult, typename ...TArgs>
struct
PartialLambdaTypeRetriver<TResult(__thiscall
TClass::*)(function<TResult(TArgs...)>, TArgs...)>
{
typedef
TResult
FunctionType(TArgs...);
typedef
TResult
LambdaType(function<TResult(TArgs...)>, TArgs...);
typedef
YBuilder<TResult, TArgs...> YBuilderType;
};
template<typename
TClass, typename
TResult, typename ...TArgs>
struct
PartialLambdaTypeRetriver<TResult(__thiscall
TClass::*)(function<TResult(TArgs...)>, TArgs...)const>
{
typedef
TResult
FunctionType(TArgs...);
typedef
TResult
LambdaType(function<TResult(TArgs...)>, TArgs...);
typedef
YBuilder<TResult, TArgs...> YBuilderType;
};
template<typename
TLambda>
function<typename
PartialLambdaTypeRetriver<decltype(&TLambda::operator())>::FunctionType> Y(TLambda
partialLambda)
{
return
typename
PartialLambdaTypeRetriver<decltype(&TLambda::operator())>::YBuilderType(partialLambda);
}
int
_tmain(int
argc, _TCHAR* argv[])
{
auto fib = Y([](function<int(int)> self, int
index)
{
return
index<2
?1
:self(index-1)+self(index-2);
});
for (int i = 0; i < 10; i++)
{
cout << fib(i) << " ";
}
cout << endl;
}
posted @
2014-02-28 08:34 陈梓瀚(vczh) 阅读(11214) |
评论 (3) |
编辑 收藏
2014年2月11日
自从《序》胡扯了快一个月之后,终于迎来了正片。之所以系列文章叫《看实例学编译原理》,是因为整个系列会通过带大家一步一步实现Tinymoe的过程,来介绍编译原理的一些知识点。
但是第一个系列还没到开始处理Tinymoe源代码的时候,首先的跟大家讲一讲我设计Tinymoe的故事。为什么这种东西要等到现在才讲呢,因为之前没有文档,将了也是白讲啊。Tinymoe在github的wiki分为两部分,一部分是介绍语法的,另一部分是介绍一个最小的标准库是如何实现出来的,地址在 https://github.com/vczh/tinymoe/wiki 不带问号的那些都是写完了的。
系列文章的目标
在介绍Tinymoe之前,先说一下这个系列文章的目标。Ideally,只要一个人看完了这个系列,他就可以在下面这些地方得到入门:
当然,这并不能让你成为一个大牛,但是至少自己做做实验,搞一点高大上的东西骗师妹们是没有问题了。
Tinymoe设计的目标
虽然想法很多年前就已经有了,但是这次我想把它实现出来,是为了完成《如何设计一门语言》的后续。光讲大道理是没有意义的,至少得有一个例子,让大家知道这些事情到底是什么样子的。因此Tinymoe有一点教学的意义,不管是使用它还是实现它。
首先,处理Tinymoe需要的知识点多,用于编译原理教学。既然是为了展示编译原理的基础知识,因此语言本身不可能是那种烂大街的C系列的东西。当然除了知识点以外,还会让大家深刻的理解到,难实现和难用,是完全没有关系的!Tinymoe用起来可爽了,啊哈哈哈哈哈。
其次,Tinymoe容易嵌入其他语言的程序,作为DSL使用,可以调用宿主程序提供的功能。这严格的来讲不算语言本身的功能,而是实现本身的功能。就算是C++也可以设计为嵌入式,lua也可以被设计为编译成exe的。一个语言本身的设计并不会对如何使用它有多大的限制。为了让大家看了这个系列之后,可以写出至少可用的东西,而不仅仅是写玩具,因此这也是设计的目标之一。
第三,Tinymoe语法优化于描述复杂的逻辑,而不是优化与复杂的数据结构和算法(虽然也可以)。Tinymoe本身是不存在任何细粒度控制内存的能力的,而且虽然可以实现复杂的数据结构和算法,但是本身描述这些东西最多也就跟JavaScript一样容易——其实就是不容易。但是Tinymoe设计的时候,是为了让大家把Tinymoe当成是一门可以设计DSL的语言,因此对复杂逻辑的描述能力特别强。唯一的前提就是,你懂得如何给Tinymoe写库。很好的使用和很好地实现一个东西是相辅相成的。我在设计Tinymoe之初,很多pattern我也不知道,只是因为设计Tinymoe遵循了科学的方法,因此最后我发现Tinymoe竟然具有如此强大的描述能力。当然对于读者们本身,也会在阅读系列文章的有类似的感觉。
最后,Tinymoe是一个动态类型语言。这纯粹是我的个人爱好了。对一门动态类型语言做静态分析那该多有趣啊,啊哈哈哈哈哈哈。
Tinymoe的设计哲学
当然我并不会为了写文章就无线提高Tinymoe的实现难度的。为了把他控制在一个正常水平,因此设计Tinymoe的第一条就是:
一、小规模的语言核心+大规模的标准库
其实这跟C++差不多。但是C++由于想做的事情实在是太多了,譬如说视图包涵所有范式等等,因此就算这么做,仍然让C++本身包含的东西过于巨大(其实我还是觉得C++不难怎么办)。
语言核心小,实现起来当然容易。但是你并不能为了让语言核心小就牺牲什么功能。因此精心设计一个核心是必须的,因为所有你想要但是不想加入语言的功能,从此就可以用库来实现了。
譬如说,Tinymoe通过有条件地暴露continuation,要求编译器在编译Tinymoe的时候做一次全文CPS变换。这个东西说容易也不是那么容易,但是至少比你做分支循环异常处理什么的全部加起来要简单多了吧。所以我只提供continuation,剩下的控制流全部用库来做。这样有三个好处:
语言简单,实现难度降低。
为了让库可以发挥应有的作用,语言的功能的选择十分的正交化。不过这仍然在一定的程度上提高了学习的难度。但是并不是所有人都需要写库对吧,很多人只需要会用库就够了。通过一点点的牺牲,正交化可以充分发挥程序员的想象能力。这对于以DSL为目的的语言来说是不可或缺的。
标准库本身可以作为编译器的测试用例。你只需要准备足够多的测试用例来运行标准库,那么你只要用C++(假设你用C++来实现Tinymoe)来跑他们,那所有的标准库都会得到运行。运行结果如果对,那你对编译器的实现也就有信心了。为什么呢,因为标准库大量的使用了语言的各种功能,而且是无节操的使用。如果这样都能过,那普通的程序就更能过了。
说了这么多,那到底什么是小规模的语言核心呢?这在Tinymoe上有两点体现。
第一点,就是Tinymoe的语法元素少。一个Tinymoe表达式无非就只有三类:函数调用、字面量和变量、操作符。字面量就是那些数字字符串什么的。当Tinymoe的函数的某一个参数指定为不定个数的时候你还得提供一个tuple。委托(在这里是函数指针和闭包的统称)和数组虽然也是Tinymoe的原生功能之一,但是对他们的操作都是通过函数调用来实现的,没有特殊的语法。
简单地讲,就是除了下面这些东西以外你不会见到别的种类的表达式了:
1
"text"
sum from 1 to 100
sum of (1, 2, 3, 4, 5)
(1+2)*(3+4)
true
一个Tinymoe语句的种类就更少了,要么是一个函数调用,要么是block,要么是连在一起的几个block:
do something bad
repeat with x from 1 to 100
do something bad with x
end
try
do something bad
catch exception
do something worse
end
有人可能会说,那repeat和try-catch就不是语法元素吗?这个真不是,他们是标准库定义好的函数,跟你自己声明的函数没有任何特殊的地方。
这里其实还有一个有意思的地方:"repeat with x from 1 to 100"的x其实是循环体的参数。Tinymoe是如何给你自定义的block开洞的呢?不仅如此,Tinymoe的函数还可以声明"引用参数",也就是说调用这个函数的时候你只能把一个变量放进去,函数里面可以读写这个变量。这些都是怎么实现的呢?学下去就知道了,啊哈哈哈哈。
Tinymoe的声明也只有两种,第一种是函数,第二种是符号。函数的声明可能会略微复杂一点,不过除了函数头以外,其他的都是类似配置一样的东西,几乎都是用来定义"catch函数在使用的时候必须是连在try函数后面"啊,"break只能在repeat里面用"啊,诸如此类的信息。
Tinymoe的符号十分简单,譬如说你要定义一年四季的符号,只需要这么写:
symbol spring
symbol summer
symbol autumn
symbol winter
symbol是一个"与众不同的值",也就是说你在两个module下面定义同名的symbol他们也是不一样的。所有symbol之间都是不一样的,可以用=和<>来判断。symbol就是靠"不一样"来定义其自身的。
至于说,那为什么不用enum呢?因为Tinymoe是动态类型语言,enum的类型本身是根本没有用武之地的,所以干脆就设计成了symbol。
第二点,Tinymoe除了continuation和select-case以外,没有其他原生的控制流支持。
这基本上归功于先辈发明continuation passing style transformation的功劳,细节在以后的系列里面会讲。心急的人可以先看 https://github.com/vczh/tinymoe/blob/master/Development/Library/StandardLibrary.txt 。这个文件暂时包含了Tinymoe的整个标准库,里面定义了很多if-else/repeat/try-catch-finally等控制流,甚至连coroutine都可以用continuation、select-case和递归来做。
这也是小规模的语言核心+大规模的标准库所要表达的意思。如果可以提供一个feature A,通过他来完成其他必要的feature B0, B1, B2…的同时,将来说不定还有人可以出于自己的需求,开发DSL的时候定义feature C,那么只有A需要保留下来,所有的B和C都将使用库的方法来实现。
这么做并不是完全有益无害的,只是坏处很小,在"Tinymoe的实现难点"里面会详细说明。
二、扩展后的东西跟原生的东西外观一致
这是很重要的。如果扩展出来的东西跟原生的东西长得不一样,用起来就觉得很傻逼。Java的string不能用==来判断内容就是这样的一个例子。虽然他们有的是理由证明==的反直觉设计是对的——但是反直觉就是反直觉,就是一个大坑。
这种例子还有很多,譬如说go的数组和表的类型啦,go本身如果不要数组和表的话,是写不出长得跟原生数组和表一样的数组和表的。其实这也不是一个大问题,问题是go给数组和表的样子搞特殊化,还有那个反直觉的slice的赋值问题(会合法溢出!),类似的东西实在是太多了。一个东西特例太多,坑就无法避免。所以其实在我看来,go还不如给C语言加上erlang的actor功能了事。
反而C++在这件事情上就做得很好。如果你对C++不熟悉的话,有时候根本分不清什么是编译器干的,什么是标准库干的。譬如说static_cast和dynamic_cast长得像一个模板函数,因此boost就可以用类似的手法加入lexical_cast和针对shared_ptr的static_pointer_cast和dynamic_pointer_cast,整个标准库和语言本身浑然一体。这样子做的好处是,当你在培养对语言本身的直觉的时候,你也在培养对标准库的直觉,培养直觉这件事情你不用做两次。你对一个东西的直觉越准,学习新东西的速度就越快。所以C++的设计刚好可以让你在熬过第一个阶段的学习之后,后面都觉得无比的轻松。
不过具体到Tinymoe,因为Tinymoe本身的语法元素太少了,所以这个做法在Tinymoe身上体现得不明显。
Tinymoe的实现难点
首先,语法分析需要对Tinymoe程序处理三遍。Tinymoe对于语句设计使得对一个Tinymoe程序做语法分析不是那么直接(虽然比C++什么的还是容易多了)。举个例子:
module hello world
phrase sum from (lower bound) to (upper bound)
…
end
sentence print (message)
…
end
phrase main
print sum from 1 to 100
end
第一遍分析是词法分析,这个时候得把每一个token的行号记住。第二遍分析是不带歧义的语法分析,目标是把所有的函数头抽取出来,然后组成一个全局符号表。第三遍分析就是对函数体里面的语句做带歧义的语法分析了。因为Tinymoe允许你定义变量,所以符号表肯定是一边分析一边修改的。于是对于"print sum from 1 to 100"这一句,如果你没有发现"phrase sum from (lower bound) to (upper bound)"和"sentence print (message)",那根本无从下手。
还有另一个例子:
module exception handling
…
phrase main
try
do something bad
catch
print "bad thing happened"
end
end
当语法分析做到"try"的时候,因为发现存在try函数的定义,所以Tinymoe知道接下来的"do something bad"属于调用try这个块函数所需提供的代码块里面的代码。接下来是"catch",Tinymoe怎么知道catch是接在try后面,而不是放在try里面的呢?这仍然是由于catch函数的定义告诉我们的。关于这方面的语法知识可以点击这里查看。
正因为如此,我们需要首先知道函数的定义,然后才能分析函数体里面的代码。虽然这在一定程度上造成了Tinymoe的语法分析复杂度的提升,但是其复杂度本身并不高。比C++简单就不说了,就算是C、C#和Java,由于其语法元素太多,导致不需要多次分析所降低的复杂度被完全的抵消,结果跟实现Tinymoe的语法分析器的难度不相上下。
其次,CPS变换后的代码需要特殊处理,否则直接执行容易导致call stack积累的没用的东西过多。因为Tinymoe可以自定义操作符,所以操作符跟C++一样在编译的时候被转换成了函数调用。每一个函数调用都是会被CPS变换的。尽管每一行的函数调用次数不多,但是如果你的程序油循环,循环是通过递归来描述(而不是实现,由于CPS变换后Tinymoe做了优化,所以不存在实际上的递归)的,如果直接执行CPS变换后的代码,算一个1加到1000都会导致stack overflow。可见其call stack里面堆积的closure数量之巨大。
我在做Tinymoe代码生成的实验的时候,为了简单我在单元测试里面直接产生了对应的C#代码。一开始没有处理CPS而直接调用,程序不仅慢,而且容易stack overflow。但是我们知道(其实你们以后才会知道),CPS变换后的代码里面几乎所有的call stack项都是浪费的,因此我把整个在生成C#代码的时候修改成,如果需要调用continuation,就返回调用continuation的语句组成的lambda表达式,在最外层用一个循环去驱动他直到返回null为止。这样做了之后,就算Tinymoe的代码有递归,call stack里面也不会因为递归而积累call stack item了。于是生成的C#代码执行飞快,而且无论你怎么递归也永远不会造成stack overflow了。这个美妙的特性几乎所有语言都做不到,啊哈哈哈哈哈。
当然这也是有代价的,因为本质上我只是把保存在stack上的context转移到heap上。不过多亏了.net 4.0的强大的background GC,这样做丝毫没有多余的性能上的损耗。当然这也意味着,一个高性能的Tinymoe虚拟机,需要一个牛逼的垃圾收集器作为靠山。context产生的closure在函数体真的被执行完之后就会被很快地收集,所以CPS加上这种做法并不会对GC产生额外的压力,所有的压力仍然来源于你自己所创建的数据结构。
第三,Tinymoe需要动态类型语言的类型推导。当然你不这么做而把Tinymoe的程序当JavaScript那样的程序处理也没有问题。但是我们知道,正是因为V8对JavaScript的代码进行了类型推导,才产生了那么优异的性能。因此这算是一个优化上的措施。
最后,Tinymoe还需要跨过程分析和对程序的控制流的化简(譬如continuation转状态机等)。目前具体怎么做我还在学习当中。不过我们想,既然repeat函数是通过递归来描述的,那我们能不能通过对所有代码进行inter-procedural analyzing,从而发现诸如
repeat 3 times
do something good
end
就是一个循环,从而生成用真正的循环指令(譬如说goto)呢?这个问题是个很有意思的问题,我觉得我如果可以通过学习静态分析从而解决它,不进我的能力会得到提升,我对你们的科普也会做得更好。
后记
虽然还不到五千字,但是总觉得写了好多的样子。总之我希望读者在看完《零》和《一》之后,对接下来需要学习的东西有一个较为清晰的认识。
posted @
2014-02-10 20:53 陈梓瀚(vczh) 阅读(16504) |
评论 (11) |
编辑 收藏
2014年1月19日
在《如何设计一门语言》里面,我讲了一些语言方面的东西,还有痛快的喷了一些XX粉什么的。不过单纯讲这个也是很无聊的,所以我开了这个《跟vczh看实例学编译原理》系列,意在科普一些编译原理的知识,尽量让大家可以在创造语言之后,自己写一个原型。在这里我拿我创造的一门很有趣的语言 https://github.com/vczh/tinymoe/ 作为实例。
商业编译器对功能和质量的要求都是很高的,里面大量的东西其实都跟编译原理没关系。一个典型的编译原理的原型有什么特征呢?
性能低
错误信息难看
没有检查所有情况就生成代码
优化做得烂
几乎没有编译选项
等等。Tinymoe就满足了上面的5种情况,因为我的目标也只是想做一个原型,向大家介绍编译原理的基础知识。当然,我对语法的设计还是尽量靠近工业质量的,只是实现没有花太多心思。
为什么我要用Tinymoe来作为实例呢?因为Tinymoe是少有的一种用起来简单,而且库可以有多复杂写多复杂的语言,就跟C++一样。C++11额标准库在一起用简直是愉快啊,Tinymoe的代码也是这么写的。但是这并不妨碍你可以在写C++库的时候发挥你的想象力。Tinymoe也是一样的。为什么呢,我来举个例子。
Hello, world!
Tinymoe的hello world程序是很简单的:
module hello world
using standard library
sentence print (message)
redirect to "printf"
end
phrase main
print "Hello, world!"
end
module指的是模块的名字,普通的程序也是一个模块。using指的是你要引用的模块——standard library就是Tinymoe的STL了——当然这个程序并没有用到任何standard library的东西。说到这里大家可能意识到了,Tinymoe的名字可以是不定长的token组成的!没错,后面大家会慢慢意识到这种做法有多么的强大。
后面是print函数和main函数。Tinymoe是严格区分语句和表达式的,只有sentence和block开头的函数才能作为语句,而且同时只有phrase开头的函数才能作为表达式。所以下面的程序是不合法的:
phrase main
(print "Hello, world!") + 1
end
原因就是,print是sentence,不能作为表达式使用,因此他不能被+1。
Tinymoe的函数参数都被写在括号里面,一个参数需要一个括号。到了这里大家可能会觉得很奇怪,不过很快就会有解答了。为什么要这么做,下一个例子就会告诉我们。
print函数用的redirect to是Tinymoe声明FFI(Foreign Function Interface)的方法,也就是说,当你运行了print,他就会去host里面找一个叫做printf的函数来运行。不过大家不要误会,Tinymoe并没有被设计成可以直接调用C函数,所以这个名字其实是随便写的,只要host提供了一个叫做printf的函数完成printf该做的事情就行了。main函数就不用解释了,很直白。
1加到100等于5050
这个例子可以在Tinymoe的主页(https://github.com/vczh/tinymoe/)上面看到:
module hello world
using standard library
sentence print (message)
redirect to "printf"
end
phrase sum from (start) to (end)
set the result to 0
repeat with the current number from start to end
add the current number to the result
end
end
phrase main
print "1+ ... +100 = " & sum from 1 to 100
end
为什么名字可以是多个token?为什么每一个参数都要一个括号?看加粗的部分就知道了!正是因为Tinymoe想让每一行代码都可以被念出来,所以才这么设计的。当然,大家肯定都知道怎么算start + (start+1) + … + (end-1) + end了,所以应该很容易就可以看懂这个函数里面的代码具体是什么意思。
在这里可以稍微多做一下解释。the result是一个预定义的变量,代表函数的返回值。只要你往the result里面写东西,只要函数一结束,他就变成函数的返回值了。Tinymoe的括号没有什么特殊意思,就是改变优先级,所以那一句循环则可以通过添加括号的方法写成这样:
repeat with (the current number) from (start) to (end)
大家可能会想,repeat with是不是关键字?当然不是!repeat with是standard library里面定义的一个block函数。大家知道block函数的意思了吧,就是这个函数可以带一个block。block有一些特性可以让你写出类似try-catch那样的几个block连在一起的大block,特别适合写库。
到了这里大家心中可能会有疑问,循环为什么可以做成库呢?还有更加令人震惊的是,break和continue也不是关键字,是sentence!因为repeat with是有代码的:
category
start REPEAT
closable
block (sentence deal with (item)) repeat with (argument item) from (lower bound) to (upper bound)
set the current number to lower bound
repeat while the current number <= upper bound
deal with the current number
add 1 to the current number
end
end
前面的category是用来定义一些block的顺序和包围结构什么的。repeat with是属于REPEAT的,而break和continue声明了自己只能直接或者间接方在REPEAT里面,因此如果你在一个没有循环的地方调用break或者continue,编译器就会报错了。这是一个花边功能,用来防止手误的。
大家可能会注意到一个新东西:(argument item)。argument的意思指的是,后面的item是block里面的代码的一个参数,对于repeat with函数本身他不是一个参数。这就通过一个很自然的方法给block添加参数了。如果你用ruby的话就得写成这个悲催的样子:
repeat_with(1, 10) do |item|
xxxx
end
而用C++写起来就更悲催了:
repeat_with(1, 10, [](int item)
{
xxxx
});
block的第一个参数sentence deal with (item)就是一个引用了block中间的代码的委托。所以你会看到代码里面会调用它。
好了,那repeat while总是关键字了吧——不是!后面大家还会知道,就连
if xxx
yyy
else if zzz
www
else if aaa
bbb
else
ccc
end
也只是你调用了if、else if和else的一系列函数然后让他们串起来而已。
那Tinymoe到底提供了什么基础设施呢?其实只有select-case和递归。用这两个东西,加上内置的数组,就图灵完备了。图灵完备就是这么容易啊。
多重分派(Multiple Dispatch)
讲到这里,我不得不说,Tinymoe也可以写类,也可以继承,不过他跟传统的语言不一样的,类是没有构造函数、析构函数和其他成员函数的。Tinymoe所有的函数都是全局函数,但是你可以使用多重分派来"挑选"类型。这就需要第三个例子了(也可以在主页上找到):
module geometry
using standard library
phrase square root of (number)
redirect to "Sqrt"
end
sentence print (message)
redirect to "Print"
end
type rectangle
width
height
end
type triangle
a
b
c
end
type circle
radius
end
phrase area of (shape)
raise "This is not a shape."
end
phrase area of (shape : rectangle)
set the result to field width of shape * field height of shape
end
phrase area of (shape : triangle)
set a to field a of shape
set b to field b of shape
set c to field c of shape
set p to (a + b + c) / 2
set the result to square root of (p * (p - a) * (p - b) * (p - c))
end
phrase area of (shape : circle)
set r to field radius of shape
set the result to r * r * 3.14
end
phrase (a) and (b) are the same shape
set the result to false
end
phrase (a : rectangle) and (b : rectangle) are the same shape
set the result to true
end
phrase (a : triangle) and (b : triangle) are the same shape
set the result to true
end
phrase (a : circle) and (b : circle) are the same shape
set the result to true
end
phrase main
set shape one to new triangle of (2, 3, 4)
set shape two to new rectangle of (1, 2)
if shape one and shape two are the same shape
print "This world is mad!"
else
print "Triangle and rectangle are not the same shape!"
end
end
这个例子稍微长了一点点,不过大家可以很清楚的看到我是如何定义一个类型、创建他们和访问成员变量的。area of函数可以计算一个平面几何图形的面积,而且会根据你传给他的不同的几何图形而使用不同的公式。当所有的类型判断都失败的时候,就会掉进那个没有任何类型声明的函数,从而引发一场。嗯,其实try/catch/finally/raise都是函数来的——Tinymoe对控制流的控制就是如此强大,啊哈哈哈哈。就连return都可以自己做,所以Tinymoe也不提供预定义的return。
那phrase (a) and (b) are the same shape怎么办呢?没问题,Tinymoe可以同时指定多个参数的类型。而且Tinymoe的实现具有跟C++虚函数一样的性质——无论你有多少个参数标记了类型,我都可以O(n)跳转到一个你需要的函数。这里的n指的是标记了类型的参数的个数,而不是函数实例的个数,所以跟C++的情况是一样的——因为this只能有一个,所以就是O(1)。至于Tinymoe到底是怎么实现的,只需要看《如何设计一门语言》第五篇(http://www.cppblog.com/vczh/archive/2013/05/25/200580.html)就有答案了。
Continuation Passing Style
为什么Tinymoe的控制流都可以自己做呢?因为Tinymoe的函数都是写成了CPS这种风格的。其实CPS大家都很熟悉,当你用jquery做动画,用node.js做IO的时候,那些嵌套的一个一个的lambda表达式,就有点CPS的味道。不过在这里我们并没有看到嵌套的lambda,这是因为Tinymoe提供的语法,让Tinymoe的编译器可以把同一个层次的代码,转成嵌套的lambda那样的代码。这个过程就叫CPS变换。Tinymoe虽然用了很多函数式编程的手段,但是他并不是一门函数是语言,只是一门普通的过程式语言。但是这跟C语言不一样,因为它连C#的yield return都可以写成函数!这个例子就更长了,大家可以到Tinymoe的主页上看。我这里只贴一小段代码:
module enumerable
using standard library
symbol yielding return
symbol yielding break
type enumerable collection
body
end
type collection enumerator
current yielding result
body
continuation
end
略(这里实现了跟enumerable相关的函数,包括yield return)
block (sentence deal with (item)) repeat with (argument item) in (items : enumerable collection)
set enumerator to new enumerator from items
repeat
move enumerator to the next
deal with current value of enumerator
end
end
sentence print (message)
redirect to "Print"
end
phrase main
create enumerable to numbers
repeat with i from 1 to 10
print "Enumerating " & i
yield return i
end
end
repeat with number in numbers
if number >= 5
break
end
print "Printing " & number
end
end
什么叫模拟C#的yield return呢?就是连惰性计算也一起模拟!在main函数的第一部分,我创建了一个enumerable(iterator),包含1到10十个数字,而且每产生一个数字还会打印出一句话。但是接下来我在循环里面只取前5个,打印前4个,因此执行结果就是
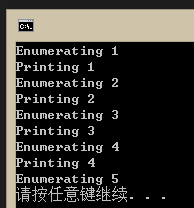
当!
CPS风格的函数的威力在于,每一个函数都可以控制他如何执行函数结束之后写在后面的代码。也就是说,你可以根据你的需要,干脆选择保护现场,然后以后再回复。是不是听起来很像lua的coroutine呢?在Tinymoe,coroutine也可以自己做!
虽然函数最后被转换成了CPS风格的ast,而且测试用的生成C#代码的确也是原封不动的输出了出来,所以运行这个程序耗费了大量的函数调用。但这并不意味着Tinymoe的虚拟机也要这么做。大家要记住,一个语言也好,类库也好,给你的接口的概念,跟实现的概念,有可能完全不同。yield return写出来的确要花费点心思,所以《序言》我也不讲这么多了,后续的文章会详细介绍这方面的知识,当然了,还会告诉你怎么实现的。
尾声
这里我挑选了四个例子来展示Tinymoe最重要的一些概念。一门语言,要应用用起来简单,库写起来可以发挥想象力,才是有前途的。yield return例子里面的main函数一样,用的时候多清爽,清爽到让你完全忘记yield return实现的时候里面的各种麻烦的细节。
所以为什么我要挑选Tinymoe作为实例来科普编译原理呢?有两个原因。第一个原因是,想要实现Tinymoe,需要大量的知识。所以既然这个系列想让大家能够看完实现一个Tinymoe的低质量原型,当然会讲很多知识的。第二个原因是,我想通过这个例子向大家将一个道理,就是库和应用 、编译器和语法、实现和接口,完全可以做到隔离复杂,只留给最终用户简单的部分。你看到的复杂的接口,并不意味着他的实现是臃肿的。你看到的简单的接口,也不意味着他的实现就很简洁。
Tinymoe目前已经可以输出C#代码来执行了。后面我还会给Tinymoe加上静态分析和类型推导。对于这类语言做静态分析和类型推导又很多麻烦,我现在还没有完全搞明白。譬如说这种可以自己控制continuation的函数要怎么编译成状态机才能避免掉大量的函数调用,就不是一个容易的问题。所以在系列一边做的时候,我还会一边研究这个事情。如果到时候系列把编译部分写完的同时,这些问题我也搞明白的话,那我就会让这个系列扩展到包含静态分析和类型推导,继续往下讲。
posted @
2014-01-18 09:21 陈梓瀚(vczh) 阅读(51471) |
评论 (4) |
编辑 收藏
2014年1月4日
2013年我就干了两件事情。第一件是gaclib,第二件是tinymoe。
Gaclib终于做到安全的支持C++的反射、从XML加载窗口和控件了。现在在实现的东西则是一个给gaclib用的workflow小脚本,用来写一些简单的view的逻辑、定义viewmodel接口,还有跟WPF差不多的data binding。
Tinymoe是我大二的时候就设计出来的东西,无奈以前对计算机的理论基础了解的太少,以至于没法实现,直到现在才能做出来。总的来说tinymoe是一个模仿英语语法的严肃的编程语言——也就是说它是不基于NLP的,语法是严格的,写错一个单词也会编译不过。因此所有的函数都要写成短语,包括控制流语句也是。所以我就想了一想,能不能让分支、循环、异常处理和异步处理等等其他语言的内置的功能在我这里都变成库?这当然是可以的,只要做全文的cps变换,然后要求这些控制流函数也写成cps的风格就可以了。
目前的第一个想法是,等搞好了之后先生成javascript或者C#的代码,不太想写自己的VM了,然后就出一个系列文章叫做《看实例跟大牛学编译原理》,就以这个tinymoe作为例子,来把《如何设计一门语言》延续下去,啊哈哈哈哈哈。
写博客是一件很难的事情。我大三开始经营这个cppblog/cnblogs的博客的时候,一天都可以写一篇,基本上是在记录我学到的东西和我造的轮子。现在都比较懒了,觉得整天说自己在开发什么也没意思了,于是想写一些别的,竟然不知如何下手,于是就出了各种没填完的系列。
我觉得我学编程这13年来也是学到了不少东西的,除了纯粹的api和语言的知识以外,很多方法论都给我起到了十分重要的作用。一开始是面向对象,然后是数据结构算法,然后是面向方面编程,然后是函数式编程,后来还接触了各种跟函数式编程有关的概念,譬如说reactive programming啊,actor啊,异步啊,continuation等等。脑子里充满了各种各样的方法论和模型之后,现在无论写什么程序,几乎都可以拿这些东西往上套,然后做出一个维护也很容易(前提是有这些知识),代码也很简洁的程序了。
工作的这四年半里,让我学习到了文档和自动化测试的重要性,于是利用这几年我把文档和测试的能力也锻炼的差不多了。现在我觉得,技术的话工作应付起来是超级简单,但是自己对技术的热情还是促使我不断的研究下去。2014年应该研究的技能就是嘴炮了。
posted @
2014-01-04 05:52 陈梓瀚(vczh) 阅读(10324) |
评论 (9) |
编辑 收藏
2013年11月10日
摘要: 在思考怎么写这一篇文章的时候,我又想到了以前讨论正交概念的事情。如果一个系统被设计成正交的,他的功能扩展起来也可以很容易的保持质量这是没错的,但是对于每一个单独给他扩展功能的个体来说,这个系统一点都不好用。所以我觉得现在的语言被设计成这样也是有那么点道理的。就算是设计Java的那谁,他也不是傻逼,那为什么Java会被设计成这样?我觉得这跟他刚开始想让金字塔的底层程序员也可以顺利使用Java是有关系...
阅读全文
posted @
2013-11-10 01:06 陈梓瀚(vczh) 阅读(10230) |
评论 (6) |
编辑 收藏