
之前曾经
为Parser Combinator写过一篇教程。这次为了处理
Vczh Library++新设计的ManagedX托管语言,我为Parser Combinator新增了三个组合子。
第一个是def,第二个是let。它们组合使用。def(pattern, defaultValue)的意思是,如果pattern成功了那么返回pattern的分析结构,否则返回defaultValue。let(pattern, value)的意思是,如果pattern成功了则返回value,否则失败。因此他们可以一起使用。举个例子,ManagedX跟C#一样具有5种type accessor:public, protected, protected internal, private, internal。其中四种accessor的文法类型是token,剩下的protected internal则是tuple<token, token>。因此我们无法很方便地为它写一个记号到语法树的转换函数。而且对于缺省情况要返回private的这种行为,在EBNF+handler上直接表达出来也比较困难。当def和let还不存在的时候,我们需要这么写:
accessor = (PUBLIC[ToAccessor] | PROTECTED[ToAccessor] | PRIVATE[ToAccessor] | INTERNAL[ToAccessor] | (PROTECTED + INTERNAL)[ToProtectedInternal])[ToAccessorWithDefault];
这个时候我们需要创建三个函数,分别是ToAccessor、ToProtectedInternal和ToAccessorWithDefault。因为accessor本身不是一个重要的语法元素,所以我们不需要为accessor记录一些源代码的位置信息。表达式则需要位置信息,这可以在我们产生错误信息的时候知道错误发生在源代码中的位置。而accessor总是直接属于某一个重要的语法元素的,所以不需要保存。如果不需要保存位置信息的话,那么一个ToXXX的函数其实就是没有必要的。这个时候可以让def和let来简化操作:
accessor = def(
let(PUBLIC, acc::Public) | let(PROTECTED, acc::Protected) | let(PRIVATE, acc::Private) | let(INTERNAL, acc::Internal) | let(PROTECTED+INTERNAL, acc::ProtectedInternal), acc::Private);
看起来好像差不多,但实际上我们已经减少了那三个不需要存在的函数。
============================无耻的分割线====================================
第三个是binop。做这个主要是因为那个通用的lrec(左递归组合子)在对付带大量括号的表达式的时候性能表现不好。这里稍微解释一下原因。假设我们的语言有>、+、*和()四种操作符,那文法一般都写成:
exp0 = NUMBER | '(' exp3 ')'
exp1 = exp1 '*' exp0 | exp0
exp2 = exp2 '+' exp1 | exp1
exp3 = exp3 '>' exp2 | exp2
因此可以很容易的知道,当我们分析1*2*3的时候,走的是下面的路子:
exp3
= exp2
= exp1
= exp1 '*' exp0
= exp1 '*' exp1 '*' exp0
= '1' '*' '2' '*' '3'
现在我们做一个简单的变换,把1*2*3变成((1*2)*3)。意义不变,但是分析的路径却完全改变了:
exp3
= exp2
= exp1
= exp0
= '(' exp3 ')'
= '(' exp2 ')'
= '(' exp1 ')'
= '(' exp1 '*' exp0 ')'
= '(' exo0 '*' exp0 ')'
= '(' '(' exp3 ')' '*' exp0 ')'
= '(' '(' exp2 ')' '*' exp0 ')'
= '(' '(' exp1 ')' '*' exp0 ')'
= '(' '(' exp1 '*' exp0 ')' '*' exp0 ')'
= '(' '(' exp0 '*' exp0 ')' '*' exp0 ')'
= '(' '(' '1' '*' '2' ')' '*' '3' ')'
咋一看好像没什么区别,但是对于ManagedX这种有十几个优先级的操作符的语言来说,如果给一个复杂的表达式的每一个节点都加上括号,等于一下子增加了上千层文法的递归分析。由于Parser Combinator是递归向下分析器,因此路径有这么长,那么递归的层次也会有这么长。而且为了避免boost::Spirit那个天杀的超慢编译速度的问题,这里牺牲了一点点性能,将组合字的Parse函数做成了虚函数,所以编译速度提高了超多。一般来说一个需要编译一个半小时的boost::Spirit语法分析器用我的库只需要几秒钟就可以编译完了。不过现在却带来了问题。括号一多,性能下降的比较明显。但是我们显然不能因噎废食,因此我决定往Parser Combinator提供一个手写的带优先级的左右结合一二元操作符语法分析器。为了将这个手写的分析器插入框架并变得通用,我决定采用下面的结构。下面的代码是从ManagedX的语法分析器中截取出来的:
1 expression = binop(exp0)
2 .pre(ADD_SUB, ToPreUnary).pre(NOT_BITNOT, ToPreUnary).pre(INC_DEC, ToPreUnary).precedence()
3 .lbin(MUL_DIV_MOD, ToBinary).precedence()
4 .lbin(ADD_SUB, ToBinary).precedence()
5 .lbin(LT << LT, ToBinaryShift).lbin(GT >> GT, ToBinaryShift).precedence()
6 .lbin(LT, ToBinary).lbin(LE, ToBinary).lbin(GT, ToBinary).lbin(GE, ToBinary).precedence()
7 .post(AS + type, ToCasting).post(IS + type, ToIsType).precedence()
8 .lbin(EE, ToBinary).lbin(NE, ToBinary).precedence()
9 .lbin(BITAND, ToBinary).precedence()
10 .lbin(XOR, ToBinary).precedence()
11 .lbin(BITOR, ToBinary).precedence()
12 .lbin(AND, ToBinary).precedence()
13 .lbin(OR, ToBinary).precedence()
14 .lbin(QQ, ToNullChoice).precedence()
15 .lbin(QT + (expression << COLON(NeedColon)), ToChoice).precedence()
16 .rbin(OPEQ, ToBinaryEq).rbin(EQ, ToAssignment).precedence()
17 ;
binop组合子的参数代表整个带优先级的最高优先级表达式组合字(参考上面给出的>+*()文法,可以知道这里的exp0是什么意思)。binop给出了四个子组合子,分别是pre(前缀一元操作符)、post(后缀一元操作符)、lbin(左结合二元操作符)和rbin(右结合二元操作符)。precedence代表一个优先级的所有操作符定义结束。这里我做了一个小限制,也就是每一个precedence只能包含pre、post、lbin和rbin的其中一种。实践表明这种限制不会带来任何问题。因此这里我们得到了一张操作符和优先级的关系表。到了这里我们就可以在Parser Combinator的框架下写一个手写的语法分析器(下载
源代码并打开Library\Combinator\_Binop.h)来做了。至于如何手写语法分析器,我之前给出了
一篇文章,大家可以参考这个来阅读_Binop.h。
binop比起简单的用lrec做同样的事情,性能在debug下提高了100多倍,release下面则少一点。到了这里,Parser Combinator重新满足了性能要求,我们可以放心大胆的用一点点无所谓的性能换取一千多倍的编译时间了。在这里贴出当binop还没出现的时候我用lrec给出的操作符文法的实现:
1 exp1 = exp0
2 | ((ADD_SUB | NOT_BITNOT | INC_DEC) + exp1)[ToUnary]
3 ;
4
5 exp2 = lrec(exp1 + *((MUL_DIV_MOD + exp1)[ToBinaryLrec]), ToLrecExpression);
6 exp3 = lrec(exp2 + *((ADD_SUB + exp2)[ToBinaryLrec]), ToLrecExpression);
7 exp4 = lrec(exp3 + *((((LT << LT) | (GT >> GT)) + exp3)[ToBinaryShiftLrec]), ToLrecExpression);
8 exp5 = lrec(exp4 + *(((LT | LE | GT | GE) + exp4)[ToBinaryLrec] | (AS + type)[ToCastingLrec] | (IS + type)[ToIsTypeLrec]), ToLrecExpression);
9 exp6 = lrec(exp5 + *(((EE | NE) + exp5)[ToBinaryLrec]), ToLrecExpression);
10 exp7 = lrec(exp6 + *((BITAND + exp6)[ToBinaryLrec]), ToLrecExpression);
11 exp8 = lrec(exp7 + *((XOR + exp7)[ToBinaryLrec]), ToLrecExpression);
12 exp9 = lrec(exp8 + *((BITOR + exp8)[ToBinaryLrec]), ToLrecExpression);
13 exp10 = lrec(exp9 + *((AND + exp9)[ToBinaryLrec]), ToLrecExpression);
14 exp11 = lrec(exp10 + *((OR + exp10)[ToBinaryLrec]), ToLrecExpression);
15 exp12 = lrec(exp11 + *((QQ + exp11)[ToNullChoiceLrec]), ToLrecExpression);
16 exp13 = lrec(exp12 + *((QT + (exp12 + (COLON(NeedColon) >> exp12)))[ToChoiceLrec]), ToLrecExpression);
17 expression = (exp13 + OPEQ + expression)[ToBinaryEq]
18 | (exp13 + EQ + expression)[ToAssignment]
19 | exp13
20 ;
21
22
posted @
2011-06-04 21:45 陈梓瀚(vczh) 阅读(3588) |
评论 (10) |
编辑 收藏
摘要: 经历了大约一个多星期的挑选,Vczh Library++3.0托管语言的语法树大约就定下来了。跟本地语言有一个缺省的语法叫NativeX一样,这次的语法就叫ManagedX了。当然ManagedX只是设计来直接反映托管语言语法树的一门语言,如果愿意的话,这个语法树还能被编译成其他长得像(嗯,只能是像,因为必须是托管的,有类没指针等)Basic啦Pascal那样...
阅读全文
posted @
2011-05-28 00:33 陈梓瀚(vczh) 阅读(3209) |
评论 (17) |
编辑 收藏
我至今依稀还记得毕业前做
Vczh Library++3.0的伟大目标,就是实现把动态语言通过“动态语言”->“托管语言”->“本地语言”->“低级中间指令”->“X86代码”最终编译成机器码,同时开放出所有中间过程。这样的话添加一个就变成一个写parser的简单工作,添加一个类库会惠及所有语言,添加一个运行是目标(譬如说可以输出ARM等)可以让在这上面的所有语言都能运行在该目标是。现在第一个阶段完成了,就是把本地语言和低级中间指令给做了。
其实现在叫本地语言不太合适,只是那个东西就是C+泛型+concept mapping的组合体,可以轻易被翻译成X86,所以才这么叫的。暂时还是写了个虚拟机直接执行低级中间指令。在整个开发过程中,我还给这种语言写了一个基本的函数库:字符串、数学函数、内存管理、垃圾收集(只是函数库,而不是语法,目前只有简单的暂时的实现)、线程、同步原语和线程池。有了这些设施之后就可以开始做托管语言了。
托管语言比较麻烦的地方在于类库是必需的。譬如说字符串、数组和函数对象这些东西其实是无法靠语言本身做出来的,所以只能成为预定义的类库。那这些类库用什么写呢?当然是我们的本地语言(之前还写了一个叫NativeX的parser)啦。现在的设想就有,先把预定义的类库的声明用托管语言本身写出来,然后编译器会提供一个功能将托管语言编译成本地语言(目标箭头之一),然后把所有标记成“外部函数”的函数跳过。每一个函数在生成本地语言的时候都会给出一个经过计算的名字。然后只需要再用NativeX写出这些同名的函数实现就好了。剩下的一些能够用托管语言自己实现的函数,就可以整个被编译成本地语言。编译出来的本地语言会依赖与之前写出来的一个垃圾收集函数库。这种函数库在本地语言只有一个声明,脚本引擎在运行的时候可以给这些名字bind上一个实现。所以实际上垃圾收集函数库的实现是可以替换的(只是必须在初始化的时候指定)。将来万一我重写的实现不够好,人们还能自己搞一套出来换掉,达到他们不可告人的目的。
至于托管语言本身有什么功能,肯定是抄自这个世界上最先进的
弱类型以面向对象作为主要范式的托管语言——C#啦,啊哈哈哈哈。Java的
语言本身根本没有被抄的价值。至于之后的动态语言,肯定是被编译到托管语言的。只是这个过程不会跟DLR那么简单直接把类型和表达式拿去映射。这里面可以做很多有趣的事情的,譬如尽量推导出动态语言里面每一个变量的类型约束(我们很多时候其实都知道动态语言里面的某个变量是有限若干个类型的集合的),然后为他们产生出更加有效的代码。这里可能会将一个函数编译成目的相同但是类型不同的几份(注意这里不是在做泛型展开)。
第二个阶段就开始了。
posted @
2011-05-15 01:59 陈梓瀚(vczh) 阅读(3583) |
评论 (21) |
编辑 收藏
主要目的是那个觉得不写代码就要死的室友想干点什么事情,觉得TFS太大了,所以做了个SVN。因此我们装了一个SVN的插件“Ankh SVN2”到Visual Studio 2010里面。然后尝试添加了个solution。Team Foundation Client有Source Control Explorer,因此这个破svn也得有个东西吧,然后我就在View目录下看到了Repository Explorer。一打开,有目录,欣喜若狂。然后我就在那个solution的目录下右键点delete,想看看效果。
卧槽,没有进Pending Changes!
卧槽,History不能Revert!!
卧槽,client端文件夹还在,对他任何操作都失败!!!
卧槽,渣都不剩了啊!!!!
幸好那只是一个临时的solution。要是在Repository Explorer里面手一抖在trunk文件夹上面Delete了,后果不堪设想啊。然后我就获得了一个教训。想看client端的文件夹的source control状态,去Working Copy Explorer,那里面的Delete是进Pending Changes的。Reposiory Explorer删除个文件夹,直接就在服务器端删掉了,神马都没有了。这一辈子都不要打开Repository Explorer。然后我想起了以前看过的一篇文章《Unix Haters》里面说到unix的哲学就是,不警告,不报告,不祷告。像Delete这种东西,要是真他妈不进Pending Changes,至少告诉我他不进Pending Changes……
瞬间想起来,各位读者们,这篇文章仅跟客户端插件有关,这里不涉及任何svnadmin命令行内容。谢谢合作。
posted @
2011-05-03 06:56 陈梓瀚(vczh) 阅读(5431) |
评论 (14) |
编辑 收藏
从某种意义上来说,做图形也好,做GUI也好,做编译器也好,大概都是一种情结。其实只要稍微想一想就知道,能把它们三者有机统一起来的,就只有游戏。我很久以前的确是为了想开发游戏才对编程产生兴趣的,而学习游戏开发占据了我前六年的时间。虽然现在不做了,不过偶尔总是会觉得手痒。但是做游戏没美工做不好怎么办呢?就只好写游戏代码了。但是没有资源写出来的游戏又不好玩,于是就只好写库。那写什么库呢,自然就只有渲染器、界面引擎和脚本引擎了。我的博客的大部分文章也是围绕着这三件事情建立起来,而且在中间不断切换的。
撒,所以今天就轮到GUI了。我一直很想做出一个自绘的GUI出来,无奈一直设计不出一个好的架构。后来尝试用原生API,但是却又很不喜欢MFC的设计,就尝试自己照着.NET Framework和Delphi那套VCL的样子
封装了一个控件库出来。无奈原生API细节无敌多,后来没做把所有的功能都全部做完。因此后来一段时间凡是需要界面我都直接用C#做。然后CEGUI出了,WPF和Silverlight也出了,我发现如今要做一个漂亮的GUI非自绘已经做不到了,所以我又做了一次尝试。
去年在美帝的时候曾经试图再设计一次,得到了一些结果。后来我发现其实根本没办法为GDI、DirectX、OpenGL和其它绘图设备抽象一个公用的接口,否则就会遭遇大量性能问题。因为在很多细节上,譬如说渲染文字,为了达到较高的性能,OpenGL和DirectX需要使用几乎相反的策略来做。因此这次我又换了一个方法,而且在
Vczh Library++ 3.0的Candidate目录下已经checkin了一个试验品。
我把一个自绘的GUI分成了下面若干个层次。
1、NativeWindow。NativeWindow表示的是一个顶层窗口的实现。譬如说我们想用Windows的窗口作为自绘窗口的顶层窗口(游戏里面的很多顶层窗口是绘制在游戏窗口里面的,所以顶层窗口并不一定是Windows的窗口)。
2、控件库。控件库包含了这个自绘GUI库的所有预定义控件。控件本身包含对用户输入的相应逻辑,但是每一个控件的绘制以及鼠标点中测试不在此范围内。
3、控件皮肤接口。每一个最终控件都会拥有一个控件皮肤接口。每当控件的状态发生了变化,控件会调用皮肤接口更新控件的当前状态。每当控件需要知道某一个点是否位于一个控件里面的时候,他也会去调用该控件的皮肤获得结果。因此控件皮肤接口包含了一切关于绘制(因此理所当然也就包含了点中测试)的逻辑。
为了达到最高的性能,一套皮肤的实现只能绑定在某种绘图设备上,也就是说缺省状态下一套为GDI设备设计出来的皮肤是不能直接使用在DirectX设备上面的。当然我这个框架的设计也是足够开放的,如果你非得用同一套代码来实现不同绘图设备上的皮肤,那么你是可以自己动手丰衣足食,做到给GDI和DirectX设计一个公共接口并插入我的GUI框架的(只不过这种做法一般情况下都会惨死)。
那么如何添加绘图设备呢?目前NativeWindow有一个基于Windows窗口的实现,并且NativeWindow的接口要求该实现在创建、销毁、接收到很多窗口事件的时候都调用某一个回调对象。我们可以通过注册一个全局回调对象或者具体窗口的回调对象来获得NativeWindow状态的变更。基于Windows窗口的NativeWindow实现还提供了一个额外函数,可以让你获得一个NativeWindow的HWND(但这个函数并不被控件库依赖)。现在我还实现了一个基于HWND+HDC的绘图设备,主要方法就是先注册全局回调对象,每当知道一个NativeWindow被创建了,我就会注册一个NativeWindow的回调对象,用来维护一个窗口里面的一块32位DIBSections位图缓冲区。窗口的大小如果变化了,我也会在适当的时候重新创建一块合适的缓冲区。不过为了避免每一次大小变化都会创建新的缓冲区,我创建的缓冲区的大小总会比窗口大一点。然后这个GDI绘图设备就暴露了一个函数,可以获得一个NativeWindow的HDC和WinGDIElementEnvironment。
WinGDIElementEnvironment是基于HWND+HDC的这一套实现上专有的、为了GDI皮肤设计出来的一个公共的资源库(譬如用来保存各种面向业务逻辑的pen啊brush什么的,比如说disable的时候什么颜色,选中的时候什么颜色等等)。如果你想设计一个基于HWND+DirectX的皮肤,那么类似WinGDIElementEnvironment的这套东西要重新做一次——因为为了达到相同的性能。具体细节相差太大。当然HWND+HDC上面可以有多套皮肤,WinGDIElementEnvironment是公用的。WinGDIElementEnvironment要求绘制是通过一个具体的WinGDIElement对象达到的,而一套皮肤可以有自己的一套WinGDIElement的实现。WinGDIElement被设计成面向业务的、一套皮肤的基本元素组成部分,譬如说按钮边框啦、焦点长方形啦、文字啦,而不是带有pen和brush的长方形啊,文字啊,各种乱七八糟的最低等级的绘图元素。举一个例子,按钮边框跟菜单边框很像,都可以用Rectangle来组成。但是Element里面就直接是按钮边框和菜单边框,而不是一个可以让你自由修改颜色的Rectangle。因为不同的控件要共享配色方案,而配色方案是由业务逻辑+空间状态的集合实现的,因此WinGDIElement还是一个比较高层次的概念。当一个WinGDIElement被渲染的时候,他会给你一个HDC,然后你根据被设置的状态来调用GDI函数绘制到HDC指向的32位DIBSections位图缓冲区上面。
那么,当我们使用HWND+HDC的实现,创建了一个布满了控件的窗口,那实际上是发生了什么事情呢?首先控件自己会组成一棵树。其次,控件的皮肤也会组成一棵树。现在就有控件树跟皮肤树两颗树了。控件树负责所有用户输入变更状态的逻辑部分,而皮肤树负责绘图和点中测试。而一个HWND+HDC实现的皮肤树,会在皮肤组合成树的时候,在底下又组合出了一颗WinGDIElement树。因此大局上就是:
控件树(负责相应输入变更状态)--> 皮肤树(负责储存控件状态的可视部分并决定什么时候需要刷新)-->WinGDIElement树(负责绘图整个窗口)
这个时候,如果我们仅仅需要简单的重新绘制窗口的话,那么控件树跟皮肤树都不需要被访问到,底层仅需要让WinGDIElement树重新绘制一遍即可。而WinGDIElement的粒度实际上也不小,因此不会每一个图元都有一个WinGDIElement从而使得创建出了一大堆对象的。
最后一个设计就是在什么时候才重绘窗口的问题。假设说我们现在收到了一个WM_KEYDOWN消息,最终传播到了控件树里面去,然后修改了10个控件上面的文字。每当你修改文字的时候实际上都需要重绘,那如何将无数次不可控的重绘合并成一次呢?SendMessage(WM_PAINT)是立刻执行的,所以Windows自带的合并WM_PAINT的方法在这个时候是无效的。我所采取的解决方法就是:反正控件树的所有消息来源都是从NativeWindow里面来的,那实际上控件树发出一个重绘请求的时候,我就会把NativeWindow的HWND实现里面的一个bool变量设成true,然后当NativeWindow每一个传播到控件树的消息结束传播之后,才读一次那个变量,如果是true,那么就调用WinGDIElement进行重绘并把变量设计成false。坏处是每一个传播到控件树的消息在处理完之后都必须检查是否需要重绘,好处是这个东西被封装在了NativeWindow的HWND实现里面里面,无论是控件树、皮肤树还是WinGDIElement树也好,都在也不需要关心绘图时机的事情了。
因为GUI被分割成了很多层,而且每一层的都关心业务逻辑的不同部分,所以他们都是可以被替换的。譬如说我们可以做成:
HWND+HDC实现:最普通的方法
HWND+DirectX:WPF和Silverlight地方法
单一HWND+多个虚拟窗口+DirectX:可以在游戏里面用
无论下面的绘图设备和窗口实现如何发生变化,GUI控件的逻辑部分都跟这些实现严格分离,因此不会受到影响。而且大部分情况下,我们是不需要拥有一个跨绘图设备的皮肤库的,譬如说游戏和应用程序,外表总不能做成一样的。对于那些需要同时在DirectX和OpenGL上面运行的程序(譬如说3dsmax),它已经有DirectX和OpenGL的公共接口了,因此这些软件可以利用它们的公共接口来实现GUI的绘图设备部分,从而在上面构造起来的皮肤自然是可以跨DirectX和OpenGL的。
这比起一年前作的GUI实现又进了一大步。上一次的GUI尝试为不同的绘图设备抽象一套公共接口,后来惨死。不知道这次实际上做出来的效果如何,拭目以待吧。
posted @
2011-04-29 19:50 陈梓瀚(vczh) 阅读(5620) |
评论 (13) |
编辑 收藏
为了避免留言再次被删掉,我还是直接在这里说几句话好了。
在这里展示一下饭同学所珍爱的原创代码“
http://www.cppblog.com/johndragon/archive/2011/04/27/145123.html”。
匹配一个通配符的方法很多。譬如说我之前还写过处理正则表达式的“
http://www.cppblog.com/vczh/archive/2008/05/22/50763.html”,或者说饭同学的那个帖子,或者说《beautiful code》里面那个递归的做法。饭同学在cppblog上还算是出镜率比较高的,因此他以前在博客上干过些什么事情我都是看了的。我猜他大概就不知道那个《beautiful code》(结果他自己承认了),因此靠着记忆贴了出来。我们都知道没有编译过的代码出了点bug是正常的。后面还说了一句啥“寥寥几行瞬间搞定”,其实也就是调侃一下。《beautiful code》这本书很出名,我不会认为会有什么人会误以为那个递归的算法是我自己原创的,当然也就猜不出饭同学后面竟然会说我是为了证明自己聪明。
不过事情的发展比较出乎我意料。因为留言都被删掉了,所以我拿不出证据,大家要质疑也随便你们。
饭同学自己说努力研读了“我的”代码,然后指出这个问题有bug。好,这都是正常的。那他虽然文章里面写了bug出现在*的处理里面,但是实际上这是后来加上去的,在留言里面他从来没说bug在哪里,取而代之的是什么我为了证明自己聪明得逞啦,对人态度不好啦,对待程序的态度不好啦,各种乱七八糟的东西。我就想说一句“卧槽”。
在这里对z某同学再次感激。虽然言辞比较激动,但好歹不会随便觉得人家在转发别人的代码是为了证明自己聪明(怎么可能呢)。
后面还有,我简单回应了一下这代码是我贴过来的,然后说了几句饭同学不应该反应大,不要随便猜测我是为了如何如何。然后饭同学回复了一句大概说的是我的留言没有意思的事情。没意思你就忽略嘛,你觉得整个事情就向着没意思的方向发展你可以关闭回复嘛。你还回复我岂不是更没意思。我最后一句留言说的是“还是说代码吧,说我更没意思”,然后所有留言就寿终正寝了。
所以说做程序员还是不能太激动。有人贴代码你看代码就好了,何必要通过否定一个人的行为来否定他所写的代码(更何况这是别人写的)呢? 还有,要是动不动就觉得别人贴代码是在挑战你的话,那只会浪费时间在处理这些破事情而已。还是写自己的代码吧,这么做划不来。
---------------------------------这里refer一下后来多出来的那个文章的部分--------------------------------------
话说我从来没有“坚持自己是在做学术研究”,那其实是饭同学在被删掉的那部分留言中坚持自己做学术研究。而且也没有“不少人匿名来支持”,我看到的就是z某同学一个人而已(难道后来人数暴增?)。态度问题的话那随便你怎么看,我又不吝啬传播别人的知识,你爱看不看。
关于递归的方法:
VCZH提供了一个递归的解法,并且“寥寥数行,瞬间搞定”。
不过,递归会带来堆栈的问题。
而且他的方法里存在BUG,我就不贴上来了。
据他称那种方法来自一本 beautiful code的书。此书我没看过,所以不清楚。
从他的方法本身看,他只能提供是否匹配的一个结果,并且匹配模版和待匹配的字符串必须是0结尾,并且不返回结束匹配时的匹配进度。
并且在处理*的时候,有些许小BUG。
虽然他一直在坚持自己是在做学术研究,也有不少人匿名来支持他,不过我觉得他还是有些态度问题。
总是喜欢在别人的贴上表现自己。做的太过了就是显摆了。
从他回帖说的那些话,比如“寥寥数行,瞬间搞定”这些,以及并不完善的代码看来,他根本就没有看过我的代码,只是凭字面意思就开始贴代码。
我实在不清楚他说这些话和贴代码的原因是什么。这些我就不再讨论了,我也删除了他的回复。
不过我想说,如果你一直以这种态度来回别人的帖子,那你会成为一个令人讨厌的人。
posted @
2011-04-27 23:04 陈梓瀚(vczh) 阅读(3412) |
评论 (20) |
编辑 收藏 每次完成一个任务的时候,都要看看有没有什么潜在的可以把功能是现成库的地方。这十分有利于提高自己的水平。但至于你写出来的库会不会有人用,那是另一回事情了。
这次为了完成一个多编程语言+多自然语言的文档编写工具,不得不做一个可以一次生成一大批文本文件的模板结构出来。有了模板必然有元数据,元数据必然是类似字符串的东西,所以顺手就支持了xml和json。为了应付巨大的xml和json,必然要做出xml和json的流式读写。大家应该听说过SAX吧,大概就是那样的。
有了xml和json之后,就可以在上面实现query了。把xml和json统一起来是一个比较麻烦的问题,因为本身从结构上来看他们是不相容的。而且为了便于给vlscript.dll添加compiler service的支持,势必要在dll上面做出字符串到语法树或者语法树到字符串这样子的操作。本地dll接口显然不可能做出一个顺眼的异构树结构,因此势必要把语法树表示成xml或者json。因此就有了下面的结构:
1、一颗简洁但是功能强大的字符串,在上面可以存放xml、json和强类型数据。
2、可以把xml和树相互转换。
3、可以把json和树相互转换。
4、当树存放的是强类型数据(基本类型都会用字符串存放)的时候,树可以映射到一个带有约束的xml或者json结构上去。
在这里可以展示一下什么是强类型数据。我们知道json表达的结构是弱类型的。当你拿到一个object的时候你不知道它的类型,你只知道他有多少个成员变量。强类型结构要求object有一个类型标记,数组也有一个类型标记(因为我们不能从数组的元素类型推断出数组本身的类型——因为类型可以拥有继承关系),基本类型还要可扩展(json只支持数字、字符串、布尔值和null,显然是不够的)。下面贴一个强类型数据结构的xml和json的表现形式:
1 <Developer>
2 <Languages>
3 <array:String>
4 <primitive:String value = "C++"/>
5 <primitive:String value = "C#"/>
6 <primitive:String value = "F#"/>
7 <primitive:String value = "Haskell"/>
8 </array:String>
9 </Languages>
10 <Name>
11 <primitive:String value = "vczh"/>
12 </Name>
13 <Project>
14 <Project>
15 <Host>
16 <primitive:String value = "Codeplex"/>
17 </Host>
18 <Language>
19 <primitive:String value = "C++"/>
20 </Language>
21 </Project>
22 </Project>
23 </Developer>
1 {
2 "$object" : "Developer",
3 "Languages" : {
4 "$array" : "String",
5 "value" : [{
6 "$primitive" : "String",
7 "value" : "C++"
8 }, {
9 "$primitive" : "String",
10 "value" : "C#"
11 }, {
12 "$primitive" : "String",
13 "value" : "F#"
14 }, {
15 "$primitive" : "String",
16 "value" : "Haskell"
17 }]
18 },
19 "Name" : {
20 "$primitive" : "String",
21 "value" : "vczh"
22 },
23 "Project" : {
24 "$object" : "Project",
25 "Host" : {
26 "$primitive" : "String",
27 "value" : "Codeplex"
28 },
29 "Language" : {
30 "$primitive" : "String",
31 "value" : "C++"
32 }
33 }
34 }
上面的xml和json都是对一个相同的强类型数据结构的表示。我们可以看到$array、$object和$primitive是用来区分他们的实际类型的。
下面是流式xml和json的读写的接口。可以很容易的看出用这种方法来读写xml和json必须将代码做成一个超级复杂的状态机才可以。这里太长贴不下,如果大家有兴趣的话可以去
Vczh Library++3.0下载最新代码并打开
Library\Entity\TreeXml.cpp
Library\Entity\TreeJson.cpp
Library\Entity\TreeQuery.cpp
1 class XmlReader
2 {
3 public:
4 enum ComponentType
5 {
6 ElementHeadOpening, // name
7 ElementHeadClosing, //
8 ElementClosing, //
9 Attribute, // name, value
10 Text, // value
11 CData, // value
12 Comment, // value
13
14 BeginOfFile,
15 EndOfFile,
16 WrongFormat,
17 };
18 public:
19 XmlReader(stream::TextReader& _reader);
20 ~XmlReader();
21
22 ComponentType CurrentComponentType()const { return componentType; }
23 const WString& CurrentName()const { return name; }
24 const WString& CurrentValue()const { return value; }
25 bool Next();
26 bool IsAvailable()const { return componentType!=EndOfFile && componentType!=WrongFormat; }
27 };
28
29 class XmlWriter
30 {
31 public:
32 XmlWriter(stream::TextWriter& _writer, bool _autoNewLine=true, const WString& _space=L" ");
33 ~XmlWriter();
34
35 bool OpenElement(const WString& name);
36 bool CloseElement();
37 bool WriteElement(const WString& name, const WString& value);
38 bool WriteAttribute(const WString& name, const WString& value);
39 bool WriteText(const WString& value);
40 bool WriteCData(const WString& value);
41 bool WriteComment(const WString& value);
42 };
43
44 class JsonReader
45 {
46 public:
47 enum ComponentType
48 {
49 ObjectOpening,
50 ObjectClosing,
51 Field,
52 ArrayOpening,
53 ArrayClosing,
54 Bool,
55 Int,
56 Double,
57 String,
58 Null,
59
60 BeginOfFile,
61 EndOfFile,
62 WrongFormat,
63 };
64 public:
65 JsonReader(stream::TextReader& _reader);
66 ~JsonReader();
67
68 ComponentType CurrentComponentType()const { return componentType; }
69 const WString& CurrentValue()const { return value; }
70 bool Next();
71 bool IsAvailable()const { return componentType!=EndOfFile && componentType!=WrongFormat; }
72 };
73
74 class JsonWriter
75 {
76 public:
77 JsonWriter(stream::TextWriter& _writer, bool _autoNewLine=true, const WString& _space=L" ");
78 ~JsonWriter();
79
80 bool OpenObject();
81 bool CloseObject();
82 bool AddField(const WString& name);
83 bool OpenArray();
84 bool CloseArray();
85 bool WriteBool(bool value);
86 bool WriteInt(vint value);
87 bool WriteDouble(double value);
88 bool WriteString(const WString& value);
89 bool WriteNull();
90 };
有xml自然要有xpath,只不过xpath用来处理json和强类型数据结构都有点力不从心,所以我打算修改xpath,做成适合查询我这种跟它们稍微有点不同的树的查询语句,然后加入到Vczh Library++3.0里面去。有了这个之后就可以做很多事情了,譬如说在模板生成器里面使用query来查询复杂的配置,譬如说在脚本语言里面支持xml和json,还有很多其他的等等。query写完之后就可以开始写一个可以一次生成一大批文本文件的模板生成器了。我会将模板生成本身写成一个可以扩展功能的库,最后再写一个DocWrite.exe利用这个库实现一个文档生成器。
posted @
2011-04-18 05:34 陈梓瀚(vczh) 阅读(3277) |
评论 (3) |
编辑 收藏
在微软亚洲研究院上班已经长达4天了。我找了我本科的同班同学一起住,他也在微软,如果他不加班的话还可以一起吃饭上下班。头一个星期四处见同学,也结识了几个新朋友,然后在家里写写代码。
Vczh Library++3.0最近的进展比较缓慢。我要用一种类似模板+生成器的方法来让我可以很方便地给多个编程语言撰写中英双语的文档,然后分开编译成多个文档,当然每个文档只有一门程序语言以及一门自然语言。因此最近正在着手给VL++3.0添加xml、json以及模板文件的支持。这个模板的编译过程跟xml+xslt比较类似,唯一的区别是我的编译过程可以控制多个步骤产生一大堆文件,譬如说文档本身,譬如说各个脚本实例及其makefile等等。
室友也很喜欢没事写代码,所以我在维护VL++3.0的同时还会跟他一起做一些有意思的小工程来玩一玩。最近在搞一个跟钢琴谱有关的软件及其一些小研究。恰好我跟他小时候都学过钢琴(唯一的区别是他没有断,我断了……),总之都是闲着没事充实生活用的。
工作之后没有在学校的那么多时间,无法维持两天至少能做一个东西来写博客的速度了,降低到了一个月两篇。不容易啊……
posted @
2011-04-11 05:32 陈梓瀚(vczh) 阅读(6105) |
评论 (16) |
编辑 收藏
项目主页:
http://vlpp.codeplex.com 下载页面:
http://vlpp.codeplex.com/releases/view/62850 该Release对应的源代码:
http://vlpp.codeplex.com/SourceControl/changeset/view/70602 第一个release没有文档,因此接下去我得做一个双语的文档生成工具了,然后会在下一个release里面添加完整的NativeX语言和脚本引擎API的文档。因此现在要学习如何使用NativeX和脚本引擎的API的话,可以下载源代码然后到下面的目录寻找资料:
1、UnitTest\Binary\TestFiles\Code:我的单元测试工程使用的NativeX脚本代码
2、UnitTest\Binary\ScriptCoreLibrary:NativeX预定义函数库的源代码
3、Tools\Release\VleSource\VlScriptDotNet:vlscript.dll的.NET封装
4、Tools\Release\VleSource\VlTurtle:使用vlscriptdotnet.dll开发的“强大的乌龟”
因此下载release之后,可以打开Turtle\VlTurtle.exe,然后玩之。一个简单的方法是,打开内置的sample然后点Run,如图:
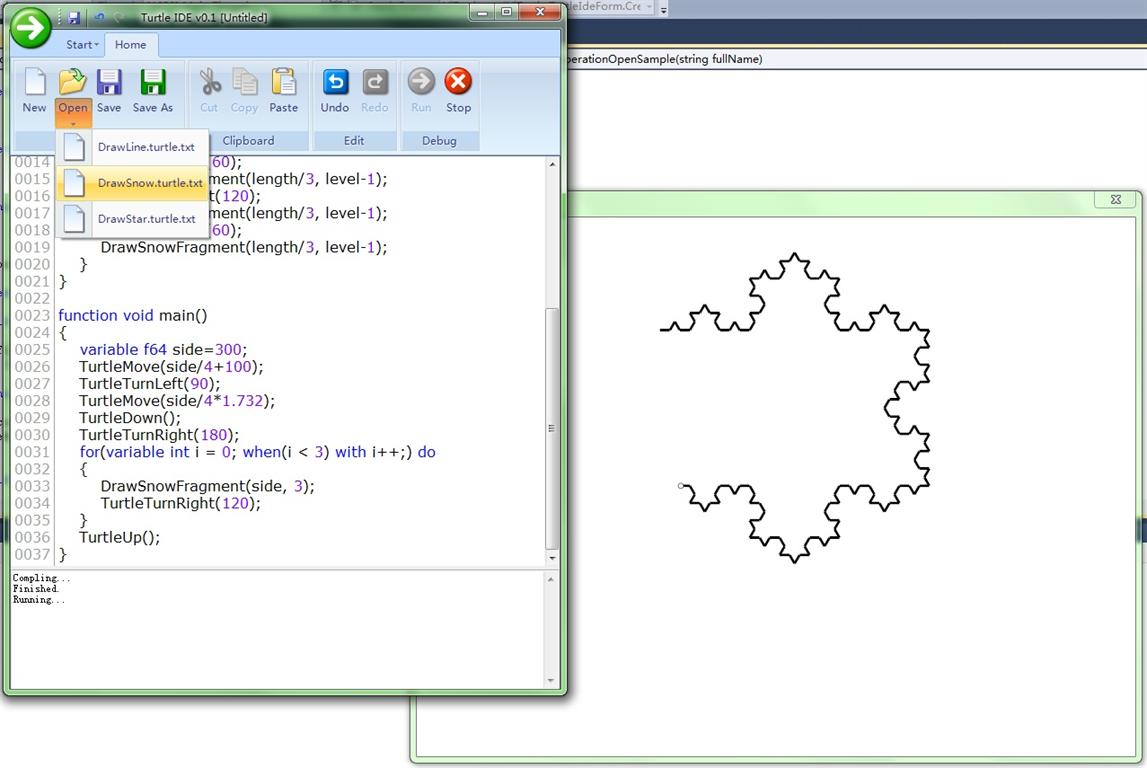
posted @
2011-03-19 21:07 陈梓瀚(vczh) 阅读(11442) |
评论 (16) |
编辑 收藏
这是一个小Demo,用来介绍如何使用C#来调用我C++给出的NativeX编译器和虚拟机的。具体的代码可以在
Vczh Library++3.0里面找到。
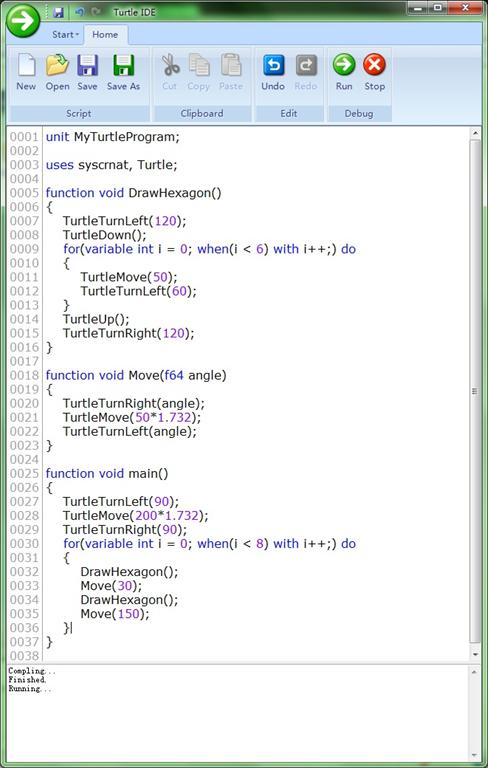
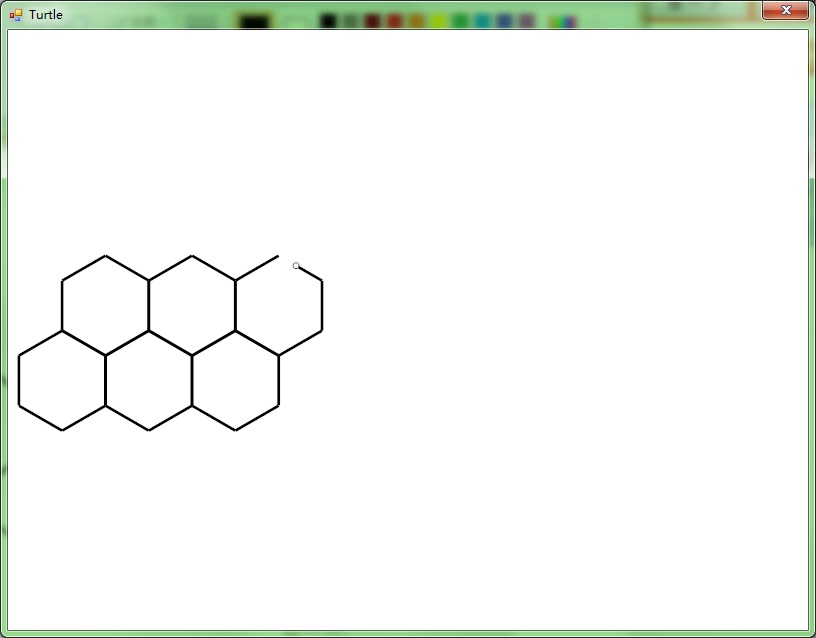
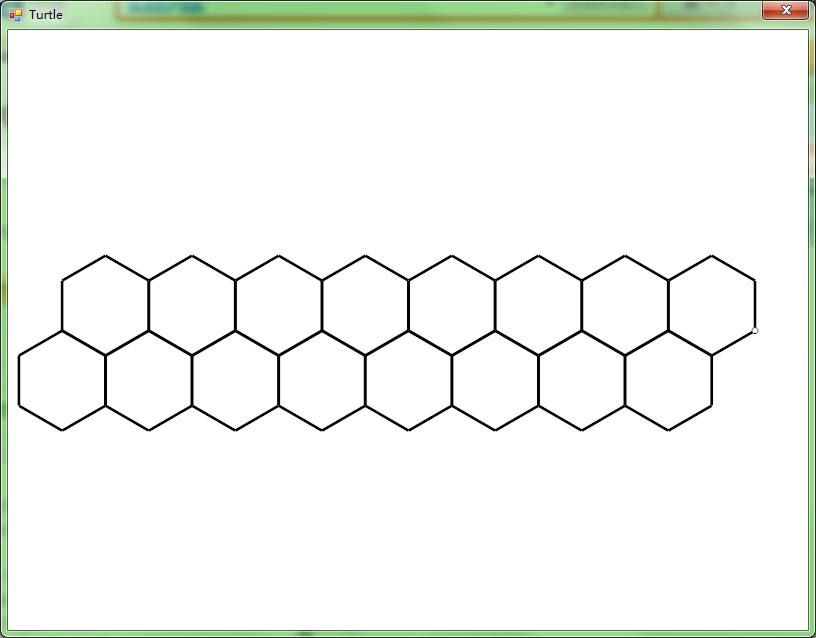
VlTurtle.exe的工作原理十分简单。首先界面由Ribbon和Intellisense构成(超难写,难免会有些问题……),其次按Run的时候会将代码保存到Script\NativeX\NativeX.txt里面,使用Vle.exe编译Script\NativeX\Make.txt,生成assembly文件。如果编译失败,就会出现Error.txt,然后这个编辑器将这个文件读回去显示在界面上。编译成功之后,使用参数“Execute”再启动自己一次,新进程会读生成的assembly文件并使用vlscript.dll的虚拟机函数初始化,寻找main函数并执行。
第一个alpha版本的Release我并不打算把编译器也做进vlscript.dll(其实代码都在,就是没extern),而打算让Vle.exe充当编译器的作用。目前这个破Demo还没做完,New/Open/Save/Save As/Stop点了没反应,而且Run是阻塞的——也就是执行进程没退出,编辑器就会假死。先偷懒了,过几天再改好他,顺便给那只破乌龟加点功能美化一下……
下面先贴图。
posted @
2011-03-11 06:20 陈梓瀚(vczh) 阅读(3529) |
评论 (3) |
编辑 收藏