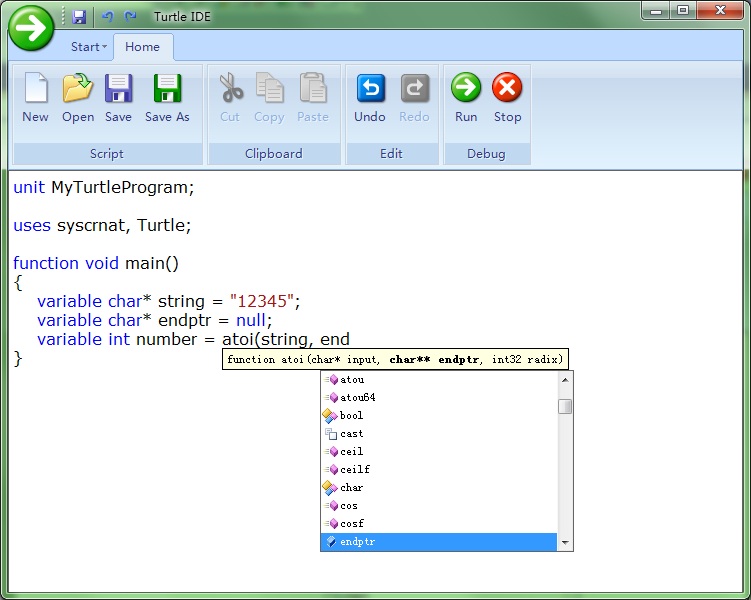
花了两天时间,集成了以前开发的山寨Office2007的Ribbon框架,和之前开发的Intellisense算法和控件,打算做一个可以点击Run之后出一只小乌龟画图的小demo哇哈哈。然后以此作为
Vczh Library++ 3.0的第一个Release的Demo。
vle.exe大概已经做完了,现在checkin了一个vlscript.dll的框架,但是还没有实现里面的具体的函数。到时候这个用C#写的demo就会调用C++写的vlscript.dll,来实现乌龟画图功能。
这个破IDE的代码在“Tools\Release\VleSource\VlTurtle\VlTurtle.csproj”,大家有兴趣的话可以去下载。打开那个solution,然后用release编译,然后再release目录下执行Deploy.bat之后,就可以F5看到效果了。
此时的心情简直无以伦比。
posted @
2011-02-24 08:54 陈梓瀚(vczh) 阅读(25329) |
评论 (26) |
编辑 收藏这破东西也做了一年半了,因此打算给它制作第一个Release。这个Release将计划包含下面的东西:
1、vle.exe。这是一个编译器和虚拟机的命令行程序。通过这个程序可以把NativeX程序编译成assembly、可以执行基于控制台的assembly程序、以及运行我为这个平台开发的一个单元测试工具。这些是已经开发完成的了。接下来还要给vle.exe添加链接功能。所谓的链接功能是指将多个assembly合并成一个,并且预先展开所有模板函数、模板变量和concept mapping等等。虽然NativeX程序跟C语言很像(多了泛型和concept mapping),也需要头文件,不过其机制并不像#include那样把文件复制进去,而是类似pascal。为了调用另一个assembly而必须的头文件可以让编译器在编译的过程中产生,不需要人去维护。
2、vlscript.dll。这是一个编译器和虚拟机的函数库。这个函数库将会制作成C而不是C++的格式。我在尽可能让vlscript.dll包含vle.exe所具有的全部功能以外,还要添加一些其他的譬如可以遍历一个assembly里面各种声明什么的的一些功能,以便二次开发的时候可以利用vlscript.dll完成很多有趣的事情。
3、TurtleDotNet.exe。这暂时还是一个设想。还记得旧社会的LOGO语言吧?最近新出的Microsoft Small Basic也跟LOGO一样可以使用乌龟画图。这是一个很好的教程式的函数库,因此我也打算做一个。因为时间的关系,我并不会在第一个Release里面包含一个NativeX的IDE,而只是包含一个C#写的窗口程序,可以读取assembly并提供乌龟画图的功能。这也同时展示了C#如何跟C的dll进行互操作。
4、各种NativeX的demo。现在已经开发好的demo包含一个四则运算分析器的程序。这个程序从字符串生成语法树(NativeX也可以利用虚函数表来模拟多态,虽然这需要人肉完成而不是语法完成),然后做各种事情。我还附带一个四则运算分析库的单元测试程序。另一个开发好的demo是一个猜数字游戏。程序随机产生4个0-9范围内的数字,然后让你也输入4个,告诉你命中了多少,半命中(数字对位置不对)了多少,然后一直到你放弃或者猜中为止,程序结束。
上面已经开发好的东西已经check in在codeplex里面了,感兴趣的话可以
自行下载。不过那个vle.exe是以源代码的形式存放的(不像Release,都是编译好的东西),因此如果想要看到效果的话,需要装有Visual Studio 2010。编译完之后,在Tools\Release\Vlpp\和Tools\Release\Vlpp\ScriptSample\CrossAssemblyInvoking\Binary\下面有Readme.txt,会告诉你在编译完vle.exe之后如何部署他们,使得上述的两个NativeX demo可以编译和运行。
拭目以待吧,哇哈哈。
posted @
2011-02-19 23:29 陈梓瀚(vczh) 阅读(3476) |
评论 (1) |
编辑 收藏流水账。
今年春节回家的时候带了三本书。去年中秋节的时候外服发了200块钱的卓越卡(啊,不是公司的,啊,说出来没人信),我觉得自己还是个看书的人,因此买了8本书。不过我觉得自己大概不是个做文学的人,所以买的都是些什么数学啊物理的民科书。里面有本讲时间的,原本以为是物理,结果是本哲学书,坚持到看完了才知道。之后8本只看了1/4本,于是到了春节。家里的电脑是02年买的,到现在就跟屎一样,因此给家里添置了一台。不过在这之前的三天,只能把上网的时间用来看书了,然后把这本书给解决掉了。接下来解决了那本哲学的,现在在看一本我也不知道他在说什么的。
我是怀着一种什么心情来看书的呢?觉得不看书就如同有负罪感一般,因此总是千方百计想把它们看完。看完的时候是什么感觉呢?除了接收到了知识感到欣喜以外,还有一种神奇的感觉类似“如释重负”的感觉。我觉得很不舒服。
对比起自己更加喜爱的编程,我突然想起在大学的时候,不写程序也是有负罪感的,不过现在没有了。当时其实我也很坦白,说不写程序会有负罪感,并且引以为豪,以此证明自己是一个爱写程序的人。现在想起来是有点滑稽。人每天都说话,说话就是生活,但有一两天你没说话,你有没有负罪感呢?想必是没有的。没有人会觉得一两天不说话会对不起自己或者对不起别人。当然吃饭是不一样的,不吃饭是会死的。写程序对于现在的我来说就如同说话。写程序就是生活,但是有一两天你没写程序,其实也觉得没什么,这种事常有。但是自己是不会因此就再也不写程序的,就如同你自己不会因为一两天不说话就永远不说话一样。当然如果你一两天不吃饭,估计就永远不吃饭了……
那写程序对于我是什么呢?初中的时候,觉得写程序很有意思,自己搞着搞着总能摆弄出一点事情来,没有理过微软的fellow们。高中的时候,觉得写程序是一种追求,很有远大理想,看到了微软主页上的那三十多个fellow,觉得自己将来就是想成为他们一样的人。大学的时候,觉得写程序是一种义务,虽然自己再也不拿fellow当终极目标了,觉得修炼自己就是一种快乐,觉得反正自己的目标大概是要成为一个厉害的人的,不管将来是不是fellow都无所谓。到了现在,写程序俨然变成了生活的一部分。自己仍然对自己有严厉的要求,写出来的代码要高性能要好改还要富有艺术感,但已经不觉得厉害不厉害是一件多么大不了的事情了。我就是写程序,写程序就是我,反正迟早是要厉害的,那只是时间问题,也就不执着于那个了。
因此我现在没有宣称自己是喜欢写程序的人了,而宣称我自己就是写程序的人。想必当年觉得“喜欢写程序”就是自己身份的一个标签,认为只要不写程序,我也就不成为我,而且对不起贴在身上的标签了。如今,程序还是在写,但标签已经没了。激情在,理想在,功夫也在,程序也一直在写。只是写程序已经变成了自己想写就写,不想写就不写,随心所欲的状态了。
因此对比起看书,说不定自己仍然很在意“喜欢看民科书”的标签。实际上我也是这么做的,对外宣称自己是喜欢看民科书的人,而不是看民科书的人,跟写程序相反。所以大概会有这种感觉罢。
想想以前也有过不少爱好,譬如4岁的时候开始的钢琴,8岁的时候开始的看民科书。10岁的时候开始的糊变形金刚,14岁的时候开始的写程序。坚持下来的也就是看民科书跟写程序了。然后经历都是差不多的,一个事情自己做得好,然后就慢慢有了追求,然后就变成了标签,如果顺利的话那个事情也就成为了生活了。
什么时候看民科书能成为生活呢?我想能看的民科书的数量也是有限的,大概也只能当个标签吧,说不定哪天自己写程序写爽了,也写写跟编程相关的民科书,然后就贴上了个“喜欢写民科书”的标签了。
posted @
2011-02-08 09:09 陈梓瀚(vczh) 阅读(4231) |
评论 (13) |
编辑 收藏
今天做了一整天终于优化了kd-tree和Ambient Occlusion。先上
代码,后上图。
首先是做了一个kd-tree,渲染一幅有一千三百多万个三角形的图仅需要0.4秒。
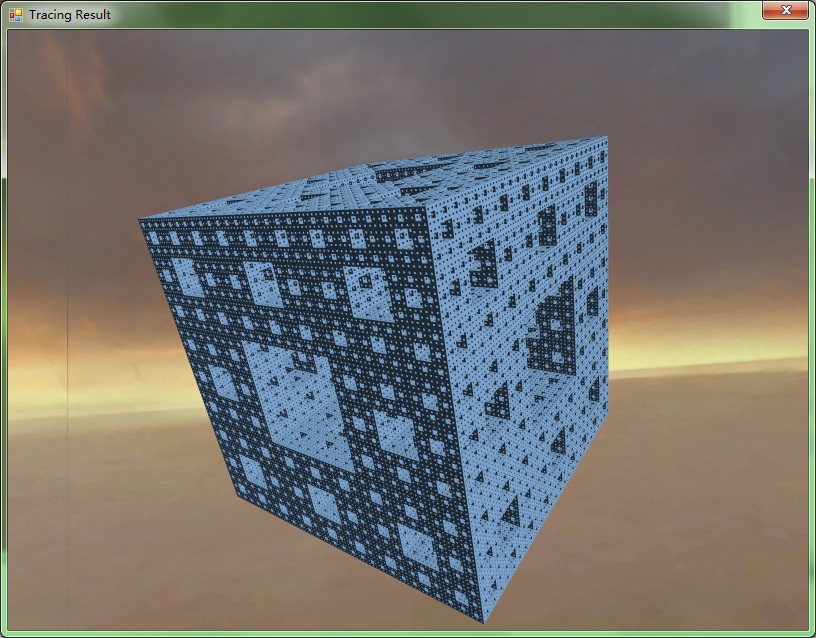
其次是Ambient Occlusion
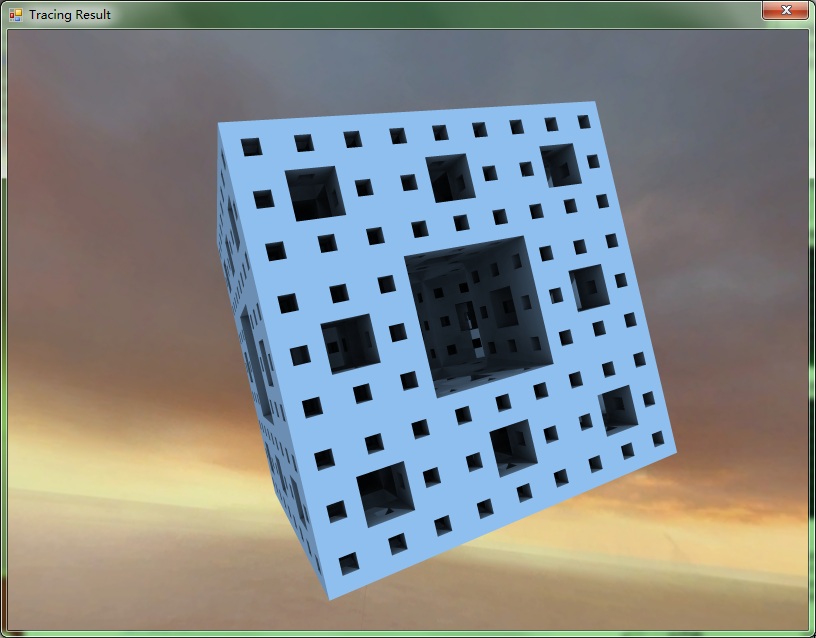
第三幅是对比图。上图有Ambient Occlusion,下图没有。
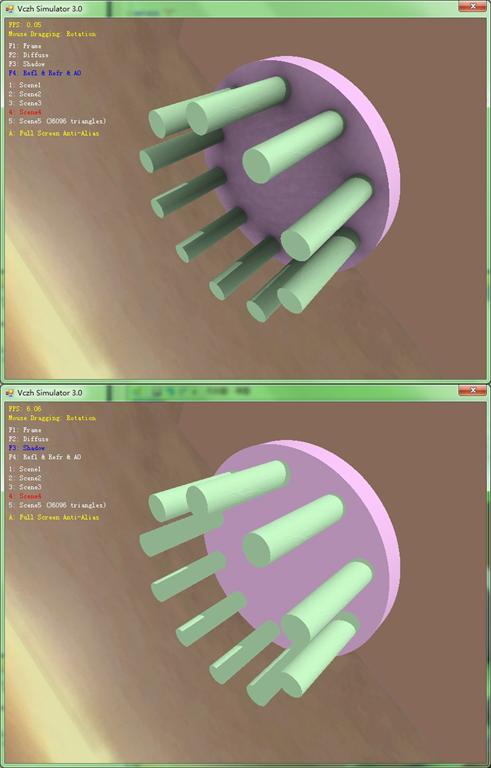
再加两张(博客发布后才添加的)。算法没变,只不过多了模型,就暂时不更新代码了:
posted @
2011-01-21 22:45 陈梓瀚(vczh) 阅读(11468) |
评论 (11) |
编辑 收藏
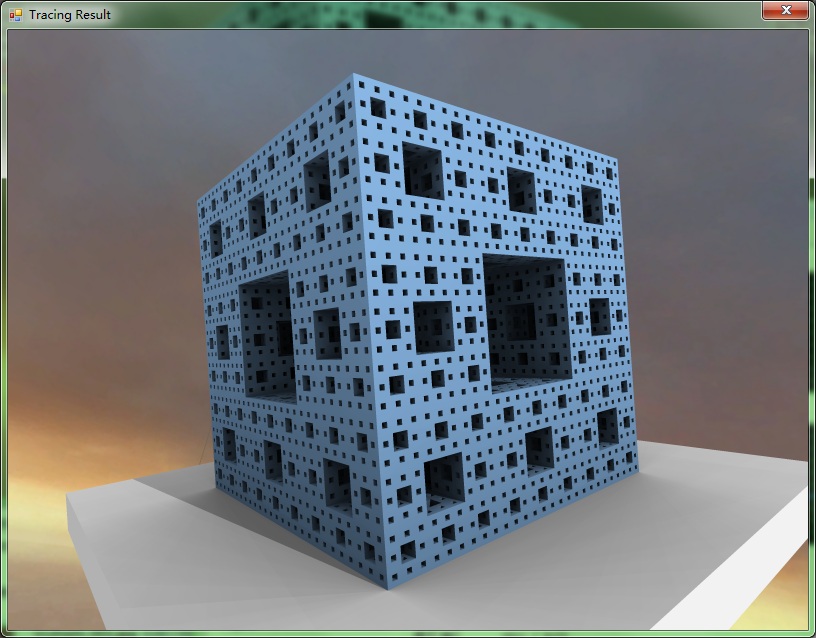
最近休了几天假玩一玩所以进展比较慢。直到今天我做了高亮、4*4全屏幕消锯齿、圆柱体和三角形模型。不过目前三角形我没有用kd-tree,所以巨慢。在i7上做一个36096个面的Menger Sponge再加上全屏幕消锯齿花掉了20分钟……
点击
这里下载当前进度的代码。
下面开始贴图:
Blinn Specular:
全屏幕消锯齿:
传说中三万多个三角形的Menger Sponge
无聊做的圆柱体求交函数:
posted @
2011-01-20 09:10 陈梓瀚(vczh) 阅读(5184) |
评论 (9) |
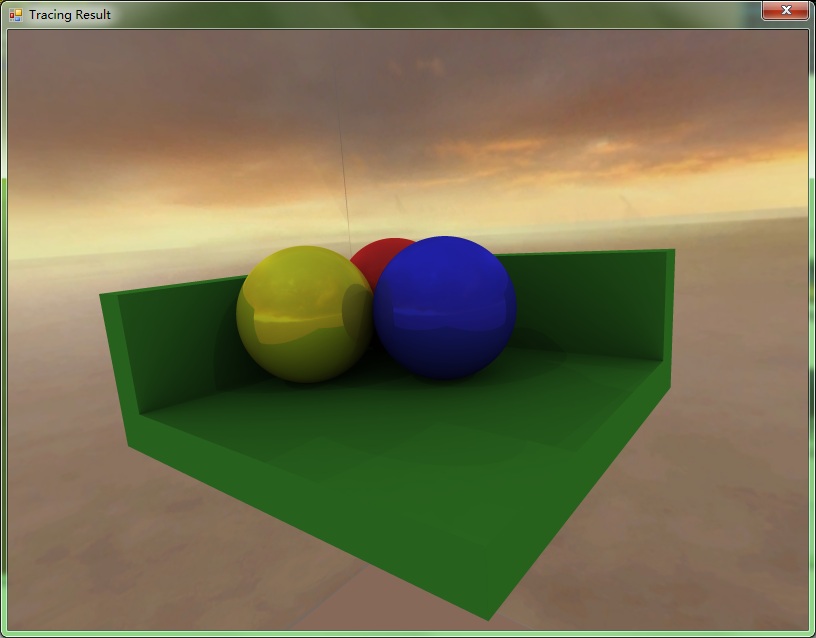
编辑 收藏 每年总有那么几个星期不想写编译器,这个时候做做ray tracing就变成一件很美妙的事情了。因此这个星期重写了当年那个超烂的光线追踪,然后加上了贴图的功能。当然图是可以直接贴在物体上的,还支持了法线贴图,譬如说下面做的地球在不同方向的光线的照射下显得有立体效果:
之所以FPS有16是因为我已经不再当年那个破thinkpad上渲染,而在一个i7四核超线程三通道的CPU上做了。渲染的时候为了简单,把屏幕等分成了八行,然后创建八个线程分别绑定到八个CPU上面去(SetThreadAffinityMask),最后渲染完出来。当然比起那些专业的还是显得相当慢,现在很多光线追踪软件都用了GPU来做,不过我GPU也没用,SSE指令也没用,就纯粹C++写。如今也懒得用C++做GUI了,所以把核心用C++做成了之后,export几个函数出来,用C#的P/Invoke直接调用。C++渲染完以后给一个HBITMAP,C#拿过来就往窗口上画,还是十分方便的哈。多语言开发万岁。
重写了光线追踪之后仍然把折射和反射给做了,因此可以做出个类似凸透镜一样的东西:
需要提一下的是,做贴图的时候实现了nearest、linear和bicubic三种插值方法。nearest基本上就是不插值,所以放大了之后会有马赛克效果。linear是线性插值,如果放得太大还是能看出一点模糊的马赛克。bicubic效果就好很多了,如果大家有兴趣的话可以到
这里去看。为了达到更好的效果,后面还有计划做ray differential和各向异性过滤。ray differential之后就可以做photon mapping(一种比较高效的全局光照模型)了。做完photon mapping之后,无聊的心情大概就结束了,可以继续写编译器了吧。
嗯嗯,虽然ray differential和photon mapping还没做,
我就先把代码丢上啦,不仅可以做备份,大家也能搞下来看一看。当然需要有Visual Studio 2010才能编译的。选择release编译之后到release文件夹下去启动,debug的话慢的不能忍。而且我的多线程模型是一个核(超线程的话算两个)一个线程,那些古老的双核CPU大概性能会很惨不忍赌吧……
posted @
2011-01-08 23:54 陈梓瀚(vczh) 阅读(6964) |
评论 (15) |
编辑 收藏
根据之前的计划,让
Vczh Library++3.0的编译器变成语言的公共后端的同时,开放几乎所有层的API让人们可以从各种基础上开发自己的DSL,所以在做完NativeX之后,接下来的事情就是写必要程度的库之后,做一些基础设施让托管语言可以被编译到NativeX上面去。因此现在需要完成的东西有:
1、内存池,用来实现NativeX的new和delete。这个已经做完了。下一篇文章将详细描述这个内存池的结构。
2、线程和同步对象。这个很快就做完了。NativeX的线程不仅需要有基本的功能,还需要做一个内置的消息循环。当一部分线程选择使用消息循环作为它的结构的时候,其他线程就可以把一些代码片段发送给这个线程执行了。并且要做到跟C#一样,当线程被外部强行中止的时候,线程内部会抛出一个异常,然后让线程自己去处理。
3、基本的字符串和数学函数库
4、垃圾收集器。这个垃圾收集器是不属于NativeX的语法的。这个垃圾收集器将被开发成一个NativeX的函数库,用于支持更高层次语言的编译。
当然为了完成这个目标,我给NativeX加上了一些无关痛痒但是却会带来方便的语法:
1、#public编译选项。只要在structure、function或者variable上面标记了#public的话,这个特殊的标志就会被记录在编译后的二进制文件的元数据里面。NativeX现在的元数据分为两种。第一种是运行时元数据。
之前的文章提到NativeX的模板函数和其他模板的东西都是可以直接编译进二进制文件的,因此模板函数的实例化实际上是在运行是的时候做的。不过现在我也实现了一个编译选项(不属于NativeX,需要用C++去控制),
可以在编译完所有二进制文件之后,将他们合并成一个大的二进制文件并且预先展开所有需要的模板函数。这一步可以用于加快运行速度,还可以为将来运行时编译成x86或者x64做准备。当#public被记录到元数据里面之后,编译器就可以从编译好的二进制文件里面重新还原出该二进制文件的头文件。
2、sizeof(type)、offsetof(type::member)、typeof(expression)和typeof(type::member)。这个纯粹是为了配合内存池和未来的垃圾收集器而做出来的。当你需要alloc一个东西的时候,你显然需要知道一个类型的尺寸,而这个是会跟随着不同的情况而变化的,所以就给出了这些东西,让编译器帮助你计算各种跟类型相关的数字。
3、常量定义。这个还没实现,到时候的语法可能会是constant type name = value;。而且当他被标记上#public之后,就可以在生成头文件的时候包含该常量了。
为了让C++可以给NativeX添加外部函数,我做了一个辅助类用来简化这个过程。举个例子,我们需要实现一个叫做MemCreate的创建内存池的函数。首先我们需要在NativeX里面声明它:
1 structure __ForeignHandle
2 {
3 }
4
5 foreign function __ForeignHandle* __MemCreate()
6 alias SystemCoreForeignFunctions.MemCreate;
这里的alias后面的一大串是外部函数的名称,而__MemCreate则是他对于NativeX的名称。接下来我们就得在C++实现这个函数了:
1 #include "ScriptingUtilityForeignFunctions.h"
2 #include "..\Languages\LanguageRuntime.h"
3 #include "..\..\Entity\GeneralObjectPoolEntity.h"
4 #include "..\..\Threading.h"
5
6 namespace vl
7 {
8 namespace scripting
9 {
10 namespace utility
11 {
12 using namespace basicil;
13 using namespace entities;
14 using namespace collections;
15
16 class SystemCoreMemoryManagerPlugin : public LanguagePlugin
17 {
18 public:
19 struct PoolPackage
20 {
21 GeneralObjectPool pool;
22 CriticalSection cs;
23
24 PoolPackage(vint poolUnitSize, vint poolUnitCount)
25 :pool(poolUnitSize, poolUnitCount)
26 {
27 }
28 };
29
30 List<Ptr<PoolPackage>> pools;
31 CriticalSection pluginCs;
32
33 class MemCreate : public Object, public IBasicILForeignFunction
34 {
35 protected:
36 SystemCoreMemoryManagerPlugin* plugin;
37 public:
38 MemCreate(SystemCoreMemoryManagerPlugin* _plugin)
39 :plugin(_plugin)
40 {
41 }
42
43 void Invoke(BasicILInterpretor* interpretor, BasicILStack* stack, void* result, void* arguments)
44 {
45 LanguageArgumentReader reader(result, arguments, stack);
46 Ptr<PoolPackage> pool=new PoolPackage(1048576, 256);
47
48 CriticalSection::Scope scope(plugin->pluginCs);
49 plugin->pools.Add(pool);
50 reader.Result<PoolPackage*>()=pool.Obj();
51 }
52 };
53
54 static vint MemAlloc(void* result, void* arguments)
55 {
56 LanguageArgumentReader reader(result, arguments);
57 PoolPackage* pool=reader.NextArgument<PoolPackage*>();
58 vint size=reader.NextArgument<vint>();
59
60 CriticalSection::Scope scope(pool->cs);
61 reader.Result<char*>()=pool->pool.Alloc(size);
62 return reader.BytesToPop();
63 }
64
65 static vint MemFree(void* result, void* arguments)
66 {
67 LanguageArgumentReader reader(result, arguments);
68 PoolPackage* pool=reader.NextArgument<PoolPackage*>();
69 char* pointer=reader.NextArgument<char*>();
70
71 CriticalSection::Scope scope(pool->cs);
72 reader.Result<bool>()=pool->pool.Free(pointer);
73 return reader.BytesToPop();
74 }
75
76 static vint MemIsValidHandle(void* result, void* arguments)
77 {
78 LanguageArgumentReader reader(result, arguments);
79 PoolPackage* pool=reader.NextArgument<PoolPackage*>();
80 char* pointer=reader.NextArgument<char*>();
81
82 CriticalSection::Scope scope(pool->cs);
83 reader.Result<bool>()=pool->pool.IsValid(pointer);
84 return reader.BytesToPop();
85 }
86
87 static vint MemGetHandleSize(void* result, void* arguments)
88 {
89 LanguageArgumentReader reader(result, arguments);
90 PoolPackage* pool=reader.NextArgument<PoolPackage*>();
91 char* pointer=reader.NextArgument<char*>();
92
93 CriticalSection::Scope scope(pool->cs);
94 reader.Result<vint>()=pool->pool.GetSize(pointer);
95 return reader.BytesToPop();
96 }
97
98 static vint MemGetOwnerHandle(void* result, void* arguments)
99 {
100 LanguageArgumentReader reader(result, arguments);
101 PoolPackage* pool=reader.NextArgument<PoolPackage*>();
102 char* pointer=reader.NextArgument<char*>();
103
104 CriticalSection::Scope scope(pool->cs);
105 reader.Result<char*>()=pool->pool.GetHandle(pointer);
106 return reader.BytesToPop();
107 }
108 protected:
109 bool RegisterForeignFunctions(BasicILRuntimeSymbol* symbol)
110 {
111 return
112 symbol->RegisterForeignFunction(L"SystemCoreForeignFunctions", L"MemCreate", new MemCreate(this)) &&
113 symbol->RegisterLightFunction(L"SystemCoreForeignFunctions", L"MemAlloc", MemAlloc) &&
114 symbol->RegisterLightFunction(L"SystemCoreForeignFunctions", L"MemFree", MemFree) &&
115 symbol->RegisterLightFunction(L"SystemCoreForeignFunctions", L"MemIsValidHandle", MemIsValidHandle) &&
116 symbol->RegisterLightFunction(L"SystemCoreForeignFunctions", L"MemGetHandleSize", MemGetHandleSize) &&
117 symbol->RegisterLightFunction(L"SystemCoreForeignFunctions", L"MemGetOwnerHandle", MemGetOwnerHandle);
118 }
119 };
120
121 Ptr<LanguagePlugin> CreateMemoryManagerPlugin()
122 {
123 return new SystemCoreMemoryManagerPlugin();
124 }
125 }
126 }
127 }
外部函数分两种,一种是需要全局状态的,而另一种不需要。在不需要的时候,我提供了一个不会跟虚函数打交道的接口来加快(虽然其实可以忽略,只是为了满足那些有畸形性能欲望的人的心理而已)运行时的性能。
就先说到这里了。NativeX函数库的测试用例已经开始在做了,可以去
Vczh Library++3.0下载最新代码之后,在下面的目录找到:
Library\Scripting\Utility\:这里是外部函数的实现。
UnitTest\Binary\ScriptCoreLibrary\:这里是NativeX将外部函数简单的封装起来之后的函数库,以及他们的测试用例。我为NativeX实现了一个简单的单元测试框架。
UnitTest\UnitTest\TestScripting_Utility_System_CoreNative.cpp:这个是NativeX单元测试框架的host。
posted @
2011-01-01 05:14 陈梓瀚(vczh) 阅读(3880) |
评论 (7) |
编辑 收藏距离元旦也就十几天了,2010就要过去了。从第一行Hello World到现在,已经有10年了,所幸从未中断,因此从某种意义上来讲,我已经写了10年的程序了。每个人回顾以往走过的路的时候,往往会发现今天的结果来源于之前的一些“关键步骤”。显然我也是一样的,所以这次的总结跟以往不同,就不列出之前做过的种种程序,而是聊一聊这些关键步骤和影响我的人给我带来的影响。当然算得上关键步骤的,只能是那些能够左右人生轨迹的事情。
老爸、外婆和爷爷
这倒不是说老爸老妈把我生下来了怎么样怎么样。老爸在我幼小的时候教我一些简单的数学,给了我很多书,还有外婆教我识字,结果就是我从大概二年级开始就能够阅读老爸留给我的一些科普读物了。这些科普读物是他小的时候看的,上面还有语录,每一篇的几位都是伟大的思想指引我们前进云云。当然这并不妨碍书本的内容的质量。老爸的书也都一直保存得很好,后来我爷爷也给我弄了一套科普的启蒙读物,现在还保留着,只不过很多翻烂了。这套书是翻译的,小日本写的,不过内容却十分丰富。里面包含了数学、物理、生物、手工和一些其他的很多东西,甚至连汽车和飞机的结构都有。加上外婆也十分赞成并且指引我看这些书,其结果就是从小就对一些科学的事情感兴趣——当然也包括数学。从三年级开始到中学,老爸就给我买一些数学奥林匹克的书。当然这并不是让我去参加竞赛用的,只是他觉得既然他小时候也喜欢搞数学那我也应该继承这个优点,从而就让我去弄那些东西了。在五年级的时候,那次全市的数学竞赛老爸也帮了我很多,我也拿了很好的成绩。维持了那么多年从不间断的强大的自信心和信念就是从这个时候开始的。人喜欢搞一些事情很大程度上都是因为那些事情曾经被搞得很好,因此我也就喜欢上数学了,后来有机会体验到了数学的定理和公式的美妙之处,让我一发不可收拾。
汕头市华侨中学的领导们
这是个好学校。我整个读书的生涯,唯一一次体验到什么是素质教育就是在这里。可是后来由于各种微妙的问题导致这所学校的竞争力下降,这从某种程度上来说算是悲哀吧。我第一次接触到编程就是在这里。初中二年级的时候,学校开Basic的课,但是并没有试图让我们参加竞赛——其实连提都没提,只是就这么当成正常的课来上。把编程学得好,满足下面两个条件的话基本上可以说就是在走捷径,第一个是会从心底里对公式和定理产生美的感觉,第二个就是要持续不断地在编程上体会到成就感。这也是我为什么在一篇写给师弟师妹的文章里面提到刚开始的时候学习制作软件界面也是十分重要的,因为这会让你产生源源不断的动力,好让你给以后学习算法打下精神基础。QBasic教完自然就教Visual Basic了,当然都是很浅的内容。不过我由于受到吸引,从那以后就一直往书店里面跑,去扫荡各种跟Visual Basic有关的书,后来学到了不少。我初二在新华书店很偶然的发现了那本《Visual Basic高级图形程序设计教程》,不过坦白说我其实是被插图吸引的。那个时候发现Visual Basic竟然可以仅凭代码绘制出那么漂亮的图形,从而兴趣提高了不少。不过学习这个也是很辛苦的,这导致我不得不在初三的时候就去寻找并学习立体解析几何,高中的时候提前学习数学分析,都是为了看懂这本书啊。这本书我从初二一直看到上了大学,还带去宿舍看,看了好多年才把它每一页都琢磨透。这从某种程度上来说也算是缘分吧。
英语补习老师李培涛
初中的英语被我一不小心搞的一塌糊涂,甚至到了快不及格的地步了,所幸当时我妈(特别感谢)非得让我找一个英语的补习老师,所以就遇到了李老师了。虽然说补习课是要交钱的,不过李老师人倒是很好,不是为了收钱而收钱,还是花了很大精力实践了因材施教的。我的英语就被他给搞好了。我们知道英语对于编程来说是不可或缺的一个重要条件,因为中文的资料从数量或者质量上来说,都远远比不上英文的资料。如果英语不好,这除了阻止知识到达你的大脑里面以外,没有好处。
汕头市第一中学的张朝阳老师
高一的时候是张老师给我们上的计算机课,这个时候他告诉我们有NOI这种东西,不过我着实对算法没什么兴趣,因为那个时候我对图形更感兴趣,而且绝大多数图形的算法都不是搜索算法,而是跟数学知识有着更直接的联系。因此我就没有花多少时间在算法上面了。不过其实什么时候学习算法并不重要,只要你在工作之前学了就好了。原本那个时候也想靠NOI看看能不能混个保送什么的,由于我其实也不太认真做这个,因此只好亲自高考了。但是在这里我并不是说张老师教给了我什么知识,其实那段时间我都是靠自学。只不过因为我在非NOI的编程竞赛里面的成绩很好,所以他给我大开方便之门,让我可以利用学校的各种资源。我们都知道万恶的学校经常会不知不觉做出一些扼制青少年素质全面发展的事情,因此张老师给我的方便是十分重要的,包括我可以拥有机房的钥匙以便我在任何时候可以进去使用计算机写程序。课还是要上的,但是由于我每一年都参加NOI,所以自习课我就可以跑去机房了,写代码的时间也就大大增加了,这着实是十分有好处。
CSTC的同僚们
CSTC我现在也搞不清楚究竟他们的使命是干啥,不过印象里面就是北京工业大学的几个写代码比较厉害的人搞起来的。我有幸在上高中的时候接触到了他们,其中曾毅和唐良两个人对我的帮助很大。曾毅告诉我为了将来的前途也好,为了自己编程能力的发展也好,搞一个好学校总是必须的。唐良是在我上了大学之后告诉我这个世界上还有《算法导论》这本书,让我的数据结构和算法知识有了十分稳固的基础。当然其实不会数据结构和算法并不是说你就写不了什么复杂的程序,而只是导致你写出来的复杂的程序质量很差性能比较低而已。在高中的时候我已经做出了一个pascal的无指针版本的解释程序了,不过在这个时候我说实话除了链表以外,什么都不知道,编译原理也不知道,所有的东西都是硬凑出来的。当然程序还是能运行的,就是写好之后就无法再修改了,实在改不下去。
华南理工大学的陈健老师
高三的时候写出来的pascal解释器实在是让我十分兴奋,所以在刚入学不久听说我们的班主任陈建老师教编译原理的,我就跟她说我对这方面有兴趣了,而且当时还为我的下一个解释器写了一个很长的设计文档。这份文档一开始只是写给我自己的,后来顺便就给她看了。陈老师倒是没说什么,过了许久,给了我一本《编译原理》。当然这不是龙书,说实话那本课本也非常糟糕,只是这让我知道这个世界上还有这种东西,也就足够了。大一的时候迅速看完了这本书,觉得很不爽,就把龙书搞到手,然后看了一部分。大一结束的时候就做出一个面向对象带模板和垃圾收集的静态类型脚本语言了,陈老师实在是功不可没。作为老师,能教你什么是不重要的,告诉你你还有什么不会才是最重要而且最有用的。
华南理工大学的陈天老师
这位老师给我们上了大一的C++课,不仅功底扎实,而且可以课也讲得很好,无奈在我大三的时候说是实在不行了,跑去做程序员了。我就不对这件事情作评论了。陈天老师不仅告诉了我《设计模式》是十分重要的,而且也经常鼓励我进行更加深入的学习,对我帮助很大。
g9yuayon
这是个人才啊,而且编程水平也十分地令人叹为观止。不过他对我帮助最大的莫过于告诉我这个世界上还存在着《Parsing Techniques》了。这是世界上最好的描述语法分析的书,连龙书的前几个章节都不如这本书讲得好。当然龙书还是包含了后端的,而《Parsing Techniques》是只有前端的。不仅如此,他还给了我不少论文看。其实如果看得下去的话,论文带来的帮助远比算法要大得多。因为数据结构和算法真正普遍实用的也就那么几种,其实知识量是十分少的,还比不上数学分析。既然数学分析一年就可以上完,那实用数据结构和算法其实是不需要花那么久的。不过那些更加深刻的数据结构和算法当然不在此列了——还是很多的。但是论文,是方向性十分强,而且解决的问题其实范围更狭窄的东西。只不过如果认真研读论文的话,可以学到很多知识以外的东西,譬如说作者是如何整理他们的结果的。遇到好心的作者的话你连他们怎么发现这个事情都可以知道。由于从小就喜欢数学,所以看论文的时候看得十分入迷,也就看得更加认真仔细了。g9yuayon介绍给我的论文的确都是十分漂亮的,在我掌握了知识的同时,又让我的基础变得更扎实,并且对编程也更加喜爱了。
龚敏敏一伙
这倒是一个共同作用的结果,也是我第一个联系比较紧密的圈子。群里面的人都分布在各大公司,而且水平都不错,并且都是在研究图形学的。至于说为什么会跟他们接触,当然是因为高中的时候对图形学特别热衷的关系了。虽然后来转去做编译器了,不过学习图形学并不是一个浪费,因为这个漫长的过程让我的数学知识变的扎实,而且也产生了很多题目让我练习编写一些至少有点小规模的程序。实践是检验真理的唯一标准,这话是不错的。
我还要提一下LYT同学。LYT并没有在编程上帮助我,其实是我在教LYT写代码,只是LYT肯让我教那么久着实也不容易。为了教LYT学会写简单的编译器,让我不得不将我学过的知识从头到尾整理了一遍,而且还让我思考如何使得一个人在学会编程的同时可以保持乐趣、自信心和良好的习惯。这个过程十分有意义,不仅让我有一个机会可以从头整理我学会的知识,思考一些更加深刻的东西,让自己对知识的掌握更加深刻和牢固,而且其实对被教也是有帮助的。利己利人,何乐不为。LYT经过了我三年的精心指导,从对编程什么都不知道开始,最终顺利拿到了网易的offer,而且工资也没比我低多少,实在是让我感到十分高兴。
在我2009年7月份毕业之后就去了Microsoft而且尚未跳槽。从毕业后开始到现在这段时间现任女朋友2A同学给了我很大的支持,并没有觉得整天宅在电脑前写代码看动画片很没前途,而且还帮忙寻找各种书带我去书店鼓励我等等,对此十分感谢。
当然这并不是说其他人就对我没有帮助,而只是没有满足文章一开始提出来的“左右人生轨迹”的条件而已。因为对我有帮助的人其实非常多,志同道合的朋友也不少,在这里我就不一一列举了。
祝各位读者们也能够对编程感兴趣而且在这个道路上不断坚持越走越远。
<><><><><><><><><><>
后记。突然想起来我忘记写上,其实小日本的动画片都是一些非常具有教育意义的东西,这让我学会了很多黑暗的社会没有任何机会让我知道的人生的道理。大家一定要看啊。
<><><><><><><><><><>
后记2。今天空明流产说他是搞图形那一群人里面为数不多的还做做shader前端的,所以我再提一下,啊哈哈哈。
posted @
2010-12-18 09:17 陈梓瀚(vczh) 阅读(10611) |
评论 (33) |
编辑 收藏
时隔一个月,终于在
Vczh Library++ 3.0的IDE工程里实现了用户自定义类型变绿(抄C#的娃哈哈)鼠标移动到对象上会出tooltip、显示函数参数提示和Code snippet的功能了。由于我的
语法树的每一个节点都包含了它在源代码中的位置,所以鼠标指向一个字符的时候,可以计算出他在语法树的位置,从而可以查到他的声明的语法树节点,再用声明节点的位置就可以把声明的代码复制出来显示在tooltip上面了:
同样的方法可以用来实现显示函数参数。这个比tooltip要复杂一点,因为要吧语法树的声明重新组织成代码才能显示出来,而且还有模板函数的类型问题。不过现在有两个小功能还没实现,第一个是在没输入的时候移动光标不会更新参数,这只是个小问题。另一个是对一个函数指针调用的时候做提示,这个还要进一步考虑。下图显示的是对一个模板函数做参数提示的时候,参数的类型会自动特化:
接下来就是code snippet了。Code snippet是一个强大的功能,可以让你免除一些无谓的手指的劳动。Visual Studio里面提供了大量的code snippet,不过在这里我暂时只提供for和forr两种,用来输入for循环。下面是使用code snippet输入一个for循环的全过程:
Code snippet是一个比较复杂的功能,在这里我只实现了上下文无关的一些特性。Visual Studio里面的就更为高级了,他在插入一个类名的时候,可以根据上下文来判断是否需要出现完整的namespace。当然由于现在我用来做intellisense的语言还没有这么复杂的元素,所以也就无从做起了。
所有的代码可以在
Vczh Library++ 3.0里面找到。这篇文章的代码跟
(十)的时候的代码已经大为不同了。经过一系列的重构,intellisense功能最终被做成一个灵活的插件形式,所有的细节都可以更改,甚至连code snippet那个黄色的输入位置都可以再往上画东西。因为在开发intellisense的时候发现了NativeX语言语法上一个二义性,因此NativeX的语法也做了一处小修改。而且我趁着这个时候重构了所有NativeX的测试用例,把在C++里面构造语法树改成了用一系列make file和反射函数并运行的方式直接使用NativeXProvider编译、运行main函数并与记录在index文件中的结果进行比较的方法。
接下来可以做的事情就比较多了。首先我要开始完成NativeX的调试功能,其次我要拿Microsoft SQL Server那个超级复杂的T-SQL来研究一个从文法产生intellisense代码(是的,你没看错,是intellisense代码)的方法,最后要在intellisense上实现NativeX的重构。对于那个自动生成intellisense代码的算法,目前还仅仅出于YY阶段,当然生成出来的也只能是上下文无关的intellisense。譬如说帮你列出数据库里面的所有表啦,或者帮你列出前面声明过的变量啦,不属于自动生成的范围。不过自动生成的intellisense还是会告诉你“现在需要弹出变量列表,需要提供内容”的这样一种信息来让你可以往里面添加一些不能自动生成的东西。当然做不做得出来那是另外一回事了,先研究研究。
posted @
2010-12-04 18:59 陈梓瀚(vczh) 阅读(13355) |
评论 (16) |
编辑 收藏 有两个星期没有更新博客了,主要是最近在研究一种更灵活的代码编辑框的框架设计,修了很多bug,还有公司的事情多了起来。现在全部都解决了,因此开始写这一篇博客。上一篇文章提到了我搞定了一个智能提示的原型,当然现在已经在Vczh Library++ 3.0上面添加了鼠标指向一个对象显示声明代码和打括号的时候提示函数参数(部分完成)的功能了。今天来说一下我是如何实现这些功能的。当然我不会讲所有细节,只会讲重点,如何实现那个界面也不包括在这里。我要说的是,如何立刻知道任意一个位置所在的代码究竟是什么东西。
如果你没有读过之前的几篇文章的话,建议去翻一翻,因为我之前提到了一些背景,还有我实现的C#版yacc(当然只是指功能,并不兼容),IDE和编译器的语法分析器的异同和实现一个IDE用的语法分析器要注意的地方。
语法分析总是产生语法树或者分析树的,无论开发什么能够感应代码内容的工具,都逃不过语法分析。因此可以肯定的是,在你敲代码的时候,IDE真的在背后生成了一棵树,只不过为了要达到普通文本框的输入性能,很多东西都要移动到后台去做,但是为了瞬间响应并作智能提示,有一些东西要移动到前台做。他们之间的分界线想要界定清楚其实也不是很难。
假设我们要编辑一份超大文件(几万行吧,再超过要开除的哈),每当你打字修改它的时候,一定会进行语法分析并产生语法树。对于这么大规模的代码要产生语法树肯定不是瞬间就能完成的(我那个东西大概要一秒钟多一点),因此这一步是在后台完成的。但是当你打一个"."的时候,你肯定希望立刻就要弹出列表的内容。为了知道列表的内容,你肯定得先知道那个"."出现在了什么表达式里面,以及"."前面的那个表达式究竟是什么类型,这是离不开全文分析的。但是全文分析又太慢,所以我引入了一个技术。
为了完成这个技术,你必须在前台分析得到那个表达式。我们很容易就知道,我们是不可能等待后台分析给我们提供数据的。所以在这里我们要做的是,缓存当前我们感兴趣的代码。在这里简单化一下,如果我们只需要提供按"."弹出列表的话,我们只需要缓存语句(statement)就可以了。怎么做呢?假设我们已经可以通过所在的位置得到代码的内容(下面会讲),那么我们显然可以知道光标的位置所在的语句的语法树对象究竟是什么。有了这个语法树对象,我们就可以从代码里面直接把这个语句的代码文字复制出来,然后缓存语句的代码、语句所在的全文位置和语句所在的作用域。作用域是语法树的一部分,在做完语法分析之后,只需要做简单的语义分析建立作用域就可以计算很多东西了。这个缓存会在光标位置移动的时候更新,也会在当前的全文分析结束的时候更新。
一旦缓存下来之后,你往里面打了一个字符,那我不仅可以更新文本框里面的内容,我还可以更新缓存里面的代码的内容,同时还可以知道新的缓存开始结束位置。一个语句通常都是很短的,最多也就一百来个字符,因此我们立刻在前台对它做语法分析。而且往一个语句里面打字的话,99%以上的情况是不会影响到上下文的,所以这个语句的旧作用域对象仍然可用。这个时候我们用旧的作用域对象来对新的语句做语义分析,那么就可以知道这个语句每一个表达式的类型了,从而知道了"."前面的表达式究竟是什么类型。然后利用旧作用域对象,我们就可以知道这个类型包含了多少成员。到了这一步,列表里面的对象就构造完毕了。
然而后台的全文分析总是会结束的,所有的信息在这个时候就准备好了,然后发个消息给前台让它更新缓存。两种更新缓存都是用GUI的消息驱动的,所以不可能同时发生,只会先后发生。之前谈到的临时更新跟后台的全文分析是并行的,不过这个不会影响我们。只要我们正确处理后台跟前台的信息交换,那么整个智能感应的计算过程就可以做得十分安全,不会发生死锁。我相信这一点应该不是很难。
那么,现在回到了两个最原始的问题。第一个是如何通过位置查找语法树。这个很容易解决,只要在语法分析的时候把所有跟位置有关的信息都记录在树里面就可以了。第二个问题是我们如何处理用户写错的代码。平时编译原理里面所教授的自动错误恢复其实是不好用的,你看看VC++的编译器在你写错了什么东西之后,大部分的错误信息基本上都没法看,因此如何进行错误恢复肯定要我们自己进行精心设计。但是问题来了,我们如何实现它呢?显然手写语法分析器会让我们心烦意乱根本做不下去(还要处处记得记录位置信息……),因此我们需要一个语法分析器生成器。
在这里我建议大家去阅读我博客上的两篇文章,你可以从这两篇文章所给的链接看到一些其他的东西,讲的是如何用组合子开发语法分析器。我这里给语法树添加了一个新属性,也就是一种组合起来强大但是又容易指定的错误恢复技术了。这里的错误恢复技术分为两种,一种是针对循环的,这个大家看代码就可以了,因为跟第二种——也就是序列关系的文法的错误恢复——非常相似,只是一个理论上的变换而已。
内容是这样的。假设我们需要分析下面的表达式:EXPRESSION + "." + MEMBER,那么我们总是希望在残缺不全的代码里面恢复出尽可能正确的信息。我们知道一旦出现了".",用户想要写的必然是一个访问对象成员的表达式,因此我们在"."那里表上记号,变成EXPRESSION + "." + MEMBER。标记有一个副作用,也就是一旦标记所包含的语法分析成功了,那么整条语法会保证产生出指定的语法树结构。如果用户出现了错误,那么所有的错误都会被当成用户少输入了什么东西而引起的。虽然这一个假设对于编译器来说不太合适,但是对于IDE来说显然是合适的。但是这种做法很容易在分析列表结构的代码里引起死循环,所以需要做很多测试来保证你的标记不会造成问题。
下面的例子也可以辅助说明这种方法的有效性。举个例子,你需要做一个函数。你在写函数的过程中显然会临时或者不小心少些一些东西——有时候我们并不是把所有的事情都想清楚了才开始写代码的。这个时候为了正确分析出函数的结构,我们做下面的语法并标记:
FUNCTION_DECLARATION ::= TYPE + NAME + "(" + list<TYPE + NAME, ","> + ")" + COMPOSITE_STATEMENT
VARIABLE_DECLARATION ::= TYPE + NAME + optional("=" + EXPRESSION) + ";"
然后总是保证FUNCTION_DECLARATION的优先级比VARIABLE_DECLARATION更高,我们就总是可以恢复出最正确的语法结构了。这一种做法对于你在连续输入代码的过程中进行正确的提示是相当好用而且方便的。
至于代码生成器本身怎么实现,还是去Vczh Library++ 3.0下载代码吧。
posted @
2010-11-22 03:29 陈梓瀚(vczh) 阅读(13601) |
评论 (14) |
编辑 收藏