2020年2月26日
#
Refer to How to Easily Create Ramdisk on Linux
This tutorial will show you how to quickly create a RAM disk in any Linux distro (Debian, Ubuntu, Linux, Fedora, Arch Linux, CentOS, etc). Compared to commercial Windows RAM disk software that costs money, Linux can utilize this cool feature 100% free of charge.
What is RAM Disk?
RAM disk is also known as RAM drive. It’s a portion of your RAM that are formated with a file system. You can mount it to a directory on your Linux system and use it as a disk partition.
Why use RAM disk?
RAM is ultra-fast compared to even the fastest solid state drive (SSD). As you may know, the main performance bottleneck in today’s computer is the speed of hard drive, so moving programs and files to the RAM disk yields super fast computing experience.
Pros of RAM disk:
- Ultra-fast
- Can sustain countless reads and writes
Cons of RAM disk:
- RAM is volatile which means all data in RAM disk will be lost when the computer shutdowns or reboots. However, this can be a pro in some situations, if you use it wisely.
- RAM is expensive so it has limited capacity. You need to make sure not allocate too much space for RAM disk, or the operating system would run out of RAM.
You can do a lot of interesting things with RAM disk.
- RAM disk is best suited for temporary data or caching directories, such as Nginx FastCGI cache. If you use a SSD and there will be a lot of writes to a particular directory, you can mount that directory as a RAM disk to reduce wear out of SSD.
- I also use RAM disk to temporary store screenshots when writing articles on this blog, so when my computer shut down, those screenshots will automatically be deleted on my computer.
- You may not believe it, but I use RAM disk to run virtual machines inside VirtualBox. My SSD is about 250G. I can’t run many VMs directly on the SSD and I’m not happy about the speed of my 2TB mechanical hard drive (HDD). I can move the VM from HDD to RAM disk before starting the VM, so the VM can run much faster. After shutting down the VM, I move the VM files back to HDD, which takes less than 1 minute. This of course requires your computer to have a large capacity RAM.
How to Create a RAM Disk in Any Linux Distro
First make a directory which can be anywhere in the file system such as
sudo mkdir /tmp/ramdisk
If you want to let every user on your Linux system use the RAM disk, then change its permission to 777.
sudo chmod 777 /tmp/ramdisk
Next, check how much free RAM are left on your system with htop command line utility because we don’t want to use too much RAM.
htop
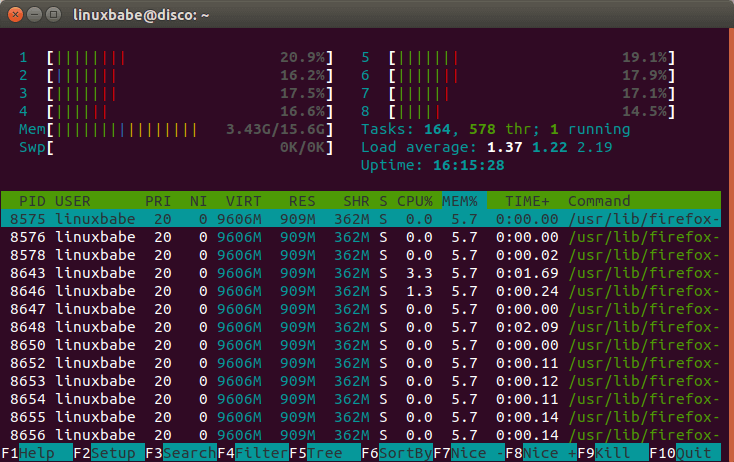
Then all left to do is to specify the file system type, RAM disk size, device name and mount it to the above directory. You can see from the screenshot above that I have plenty of free RAM, so I can easily allocate 1GB for my RAM disk. This can be done with the following one-liner. It will be using tmpfs file system and its size is set to 1024MB. myramdisk is the device name I gave to it.
sudo mount -t tmpfs -o size=1024m myramdisk /tmp/ramdisk
To allocate 10G for the RAM disk, run this instead.
sudo mount -t tmpfs -o size=10G myramdisk /tmp/ramdisk
If we issue the following command
mount | tail -n 1
We can see it’s successfully mounted.

Now if I copy my VirtualBox machines file (5.8G) into the RAM disk, my RAM usage suddenly goes up to 9.22G.
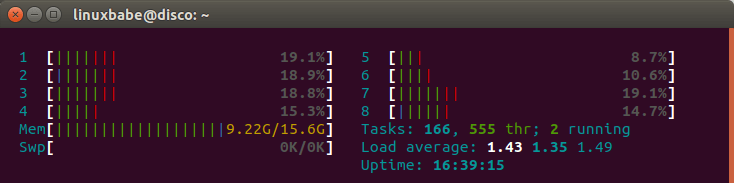
If I unmount RAM disk,
sudo umount /tmp/ramdisk/
Everything in that directory will be lost and RAM usage goes down to original.
This is how you can test if your RAM disk is working.
Test RAM Disk Speed
To test write speed of RAM disk, you can use dd utility.
sudo dd if=/dev/zero of=/tmp/ramdisk/zero bs=4k count=100000
Which gave me 2.8GB/s write speed.

To test read speed, run:
sudo dd if=/tmp/ramdisk/zero of=/dev/null bs=4k count=100000
Which gave me 3.1 GB/s read speed.
I also did a speed test on my SSD. The write speed is 534MB/s and read speed 1.6GB/s.
Auto-mount on System Boot
Edit /etc/fstab file.
sudo nano /etc/fstab
Add an entry like this:
myramdisk /tmp/ramdisk tmpfs defaults,size=1G,x-gvfs-show 0 0
x-gvfs-show will let you see your RAM disk in file manager. Save and close the file. Your Linux system will automatically mount the RAM disk when your computer boots up.
To mount it immediately without reboot, run the following command.
sudo mount -a
2019年11月28日
#
1. 使用pure或者view函数,直接拿到返回值,但不是所有的函数都能声明成pure/view。
2. 使用event包装返回值,但是在emit之前返回的函数是没有event的,如果需要每条path都返回有意义的return value,可能需要定义很多个event。(不考虑require throw的情况下)
3. 使用web3.eth.Contract.call,需要ABI和deployed address,这个用法有个缺点是将函数变成了constant的,即和1一样无法改变合约内部状态,只能说在特定的场景下有用。
4. EIP-758(https://eips.ethereum.org/EIPS/eip-758),返回returnData在subscribe的通道上,但是看目前的状态还是draft。
2019年3月27日
#
原文
在此在使用git提交代码时候,有时候会遇到一个问题,就是自己明明只修改了其中几行,提交上去以后发现整个文件都被修改了,在设置了格式风格以后还会有提交不上去的情况,这个时候经常让人摸不到头脑,其实就是CRLF和LF在作怪
CRLF LF CR 都是什么意思:
CRLF: 是carriagereturnlinefeed的缩写。中文意思是回车换行。
LF: 是line feed的缩写,中文意思是换行。
CR: 是carriagereturn的缩写。中文意思是回车。
简单的换行回车为什么会引出这么多的问题呢,关键在于操作系统之间的分歧:
早期的mac系统使用CR当做换行,现在也已经统一成了LF
Unix(包含现在大量使用的linux)系统使用LF
windows系统使用LFCR当做换行(自作聪明的兼容性??)
也正是因为不同系统的分歧,在多人协作共同开发的时候,可能导致提交代码时候产生问题。
解决方法:
Android Studio内部可以设置不同模式,具体位置在setting-->搜索code style见下图:
其中有四个选项System-Dependent LF CR CRLF,默认是System-Dependent,也就是根据你是什么系统选择什么类型,如果想要自定义的话可以在这里设置,以后创建的新代码也默认用设置的方式
而如果想单独修改某个文件的类型,也可以在右下角进行修改,见下图:
跨平台合作时候的解决方式:
当我们使用git库提交代码的时候,有的人可能使用mac,有的人使用linux,有的人使用windows,不同的开发环境如果都是按照自己系统的方式任意修改换行类型,难免会让代码库整体混乱或者产生许多没有必要的代码更新
那么解决该问题的方式有:core.autocrlf命令
git为了防止以上问题扰乱跨平台合作开发,使用命令可以转化LF和CRLF
具体体现为:
- git config --global core.autocrlf true
Git可以在你push时自动地把行结束符CRLF转换成LF,而在pull代码时把LF转换成CRLF。用core.autocrlf来打开此项功能,如果是在Windows系统上,把它设置成true,这样当签出代码时,LF会被转换成CRLF
- git config --global core.autocrlf input
Linux或Mac系统使用LF作为行结束符;当一个以CRLF为行结束符的文件不小心被引入时你肯定想进行修正,把core.autocrlf设置成input来告诉 Git 在push时把CRLF转换成LF,pull时不转换
- git config --global core.autocrlf false
在本地和代码库中都保留CRLF,无论pull还是push都不变,代码库什么样,本地还是什么样子
当然在多人跨平台工作时候,最好还是约定使用LF,还是CRLF,然后不同系统进行对应的设置,这样是工作规范,也有利于提高工作效率,希望以上可以帮助大家。
作者:sososun
链接:https://www.jianshu.com/p/dd7464cf32b5
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
2019年1月17日
#
原文
在此
由于Go没有为slice提供shuffle函数,所以需要自己想办法。由于我只需要随机一次遍历1 -> N,所以这段code最匹配。
func main() {
vals := []int{10, 12, 14, 16, 18, 20}
r := rand.New(rand.NewSource(time.Now().Unix()))
for _, i := range r.Perm(len(vals)) {
val := vals[i]
fmt.Println(val)
}
}
似乎go不像scala有那种惰性求值的特性,所以这里的r.Perm()还是产生了一个slice,如果N很大可能是个问题。
2018年8月14日
#
测试中想通过命令行传递一些参数给test func,网上找了一些资料但过程不是很顺利,这里记录一下。
首先go test有一个-args的参数说可以达到这个目的,但实测下来发现有没有没区别。。。
google查到的大部分也是用到了flag类型。
flag.go的注释写的比较清楚
/*
Package flag implements command-line flag parsing.
Usage:
Define flags using flag.String(), Bool(), Int(), etc.
This declares an integer flag, -flagname, stored in the pointer ip, with type *int.
import "flag"
var ip = flag.Int("flagname", 1234, "help message for flagname")
If you like, you can bind the flag to a variable using the Var() functions.
var flagvar int
func init() {
flag.IntVar(&flagvar, "flagname", 1234, "help message for flagname")
}
Or you can create custom flags that satisfy the Value interface (with
pointer receivers) and couple them to flag parsing by
flag.Var(&flagVal, "name", "help message for flagname")
For such flags, the default value is just the initial value of the variable.
After all flags are defined, call
flag.Parse()
to parse the command line into the defined flags.

*/
因此需要做的事情就是:
1. 定义flag,这个需要在main()执行之前完成,我这里在test文件里面用全局变量完成,但a可以放在函数里面。
var (
// Define global args flags.
pA = flag.Int("a", 0, "a.")
a = 0
)
2. parse flag,这个要在test func执行之前,所以可以考虑加入一个init()在test文件里。
func init() {
flag.Parse()
a = *pA
}
后面使用这些变量就没有问题了,比如这样
func TestInit(t *testing.T) {
flag.Parse()
t.Log("a = ", a)
}
这里用到的主要是flag的功能,测试用发现有没有-args问题不大,所以这个用法可能不是很符合go test的要求,先用起来再说了。
REF
1. https://www.golangtc.com/t/584cbd16b09ecc2e1800000b
2. https://stackoverflow.com/.../process-command-line-arguments-in-go-test
3. https://hsulei.com/2017/08/23/gotest如何使用自定义参数/
原文在此
学习shell的时候总是被shell里的条件判断方式搞得头疼,经常不知道改 用[],[[]],(())还是test,let,而很少有书把它们的关系讲解的很清楚(应该是我悟性差或是看书太少),今天总结一下,基础的东西如它们 的使用方法不再赘述,重点说说它们的区别的使用时应该注意的地方。
先说[]和test,两者是一样的,在命令行里test expr和[ expr ]的效果相同。test的三个基本作用是判断文件、判断字符串、判断整数。支持使用与或非将表达式连接起来。要注意的有:
1.test中可用的比较运算符只有==和!=,两者都是用于字符串比较的,不可用于整数比较,整数比较只能使用-eq, -gt这种形式。无论是字符串比较还是整数比较都千万不要使用大于号小于号。当然,如果你实在想用也是可以的,对于字符串比较可以使用尖括号的转义形式, 如果比较"ab"和"bc":[ ab \< bc ],结果为真,也就是返回状态为0.
然后是[[ ]],这是内置在shell中的一个命令,它就比刚才说的test强大的多了。支持字符串的模式匹配(使用=~操作符时甚至支持shell的正则表达 式)。简直强大的令人发指!逻辑组合可以不使用test的-a,-o而使用&&,||这样更亲切的形式(针对c、Java程序员)。当 然,也不用想的太复杂,基本只要记住
1.字符串比较时可以把右边的作为一个模式(这是右边的字符串不加双引号的情况下。如果右边的字符串加了双引号,则认为是一个文本字符串。),而不仅仅是一个字符串,比如[[ hello == hell? ]],结果为真。
另外要注意的是,使用[]和[[]]的时候不要吝啬空格,每一项两边都要有空格,[[ 1 == 2 ]]的结果为“假”,但[[ 1==2 ]]的结果为“真”!后一种显然是错的
3.最后就是let和(()),两者也是一样的(或者说基本上是一样的,双括号比let稍弱一些)。主要进行算术运算(上面的两个都不行),也比较适合进 行整数比较,可以直接使用熟悉的<,>等比较运算符。可以直接使用变量名如var而不需要$var这样的形式。支持分号隔开的多个表达式
2018年8月1日
#
图片来源:https://blog.slock.it/public-vs-private-chain-7b7ca45044f
2018年7月21日
#
REF: https://dominik.honnef.co/posts/2014/12/an_incomplete_list_of_go_tools/
go get github.com/golang/lint/golint
go get github.com/kisielk/errcheck
go get golang.org/x/tools/cmd/benchcmp
go get github.com/cespare/prettybench
go get github.com/ajstarks/svgo/benchviz
go get golang.org/x/tools/cmd/stringer
go get github.com/josharian/impl
go get golang.org/x/tools/cmd/goimports
go get sourcegraph.com/sqs/goreturns
go get code.google.com/p/rog-go/exp/cmd/godef
go get github.com/nsf/gocode
go get golang.org/x/tools/cmd/oracle
go get golang.org/x/tools/cmd/gorename
go get github.com/kisielk/godepgraph
2018年7月14日
#
Introduction
Solidiay doc about ABI and contract access.
https://solidity.readthedocs.io/en/develop/abi-spec.html
https://solidity.readthedocs.io/en/latest/introduction-to-smart-contracts.html?highlight=selfdestruct
http://www.ethdocs.org/en/latest/contracts-and-transactions/accessing-contracts-and-transactions.html
http://ethdocs.org/en/latest/contracts-and-transactions/contracts.html#testing-contracts-and-transactions
https://solidity.readthedocs.io/en/latest/units-and-global-variables.html?highlight=suicide [global variables like msg.sender]
ABI intro in Ethereum Wiki.
https://github.com/ethereum/wiki/wiki/Ethereum-Contract-ABI#argument-encoding
https://github.com/ethereum/go-ethereum/wiki/Contract-Tutorial
JAON rpc api of Eth.
https://github.com/ethereum/wiki/wiki/JSON-RPC#json-rpc-api
https://github.com/ethereum/wiki/wiki/JavaScript-API#contract-methods
Deploy a contract using RPC.
https://github.com/rsksmart/rskj/wiki/Deploying-contracts-using-RPC-calls
A tool to generate the grpc server code for a contract
https://github.com/getamis/grpc-contract
How to test.
http://ethereum-tests.readthedocs.io/en/latest/test_types/transaction_tests.html
https://github.com/ethereum/cpp-ethereum/blob/develop/doc/generating_tests.rst
go-ethereum里面有一批vm和contract相关的tests,结合ABI和contract的定义,可以很容易的写一批自己定制的测试,从web3js或者直接在go project里面调用都可以。
2017年6月19日
#
https://stackoverflow.com/questions/13620281/what-is-the-maven-shade-plugin-used-for-and-why-would-you-want-to-relocate-java
Uber JAR, in short, is a JAR containing everything.
Normally in Maven, we rely on dependency management. An artifact contains only the classes/resources of itself. Maven will be responsible to find out all artifacts (JARs etc) that the project depending on when the project is built.
An uber-jar is something that take all dependencies, and extract the content of the dependencies and put them with the classes/resources of the project itself, in one big JAR. By having such uber-jar, it is easy for execution, because you will need only one big JAR instead of tons of small JARs to run your app. It also ease distribution in some case.
Just a side-note. Avoid using uber-jar as Maven dependency, as it is ruining the dependency resolution feature of Maven. Normally we create uber-jar only for the final artifact for actual deployment or for manual distribution, but not for putting to Maven repository.
Update: I have just discovered I haven't answered one part of the question : "What's the point of renaming the packages of the dependencies?". Here is some brief updates and hopefully will help people having similar question.
Creating uber-jar for ease of deployment is one use case of shade plugin. There are also other common use cases which involve package renaming.
For example, I am developing Foo library, which depends on a specific version (e.g. 1.0) of Bar library. Assuming I cannot make use of other version of Bar lib (because API change, or other technical issues, etc). If I simply declare Bar:1.0 as Foo's dependency in Maven, it is possible to fall into a problem: A Qux project is depending on Foo, and also Bar:2.0 (and it cannot use Bar:1.0 because Qux needs to use new feature in Bar:2.0). Here is the dilemma: should Qux use Bar:1.0 (which Qux's code will not work) or Bar:2.0 (which Foo's code will not work)?
In order to solve this problem, developer of Foo can choose to use shade plugin to rename its usage of Bar, so that all classes in Bar:1.0 jar are embedded in Foo jar, and the package of the embedded Bar classes is changed from com.bar to com.foo.bar. By doing so, Qux can safely depends on Bar:2.0 because now Foo is no longer depending on Bar, and it is using is own copy of "altered" Bar located in another package.