This note is about book .NET and COM.Think of XML Web services simply as components or Application Programming Interfaces (APIs) exposed on a Web site rather than a DLL residing on your own computer.
An assembly is a self-describing logical component. Assemblies are units of deployment, units of security, units of versioning, and units of scope for the types contained within. Although an assembly is typically one executable or one DLL, it could be made up of multiple files.
Any assemblies with type definitions contain corresponding type information describing them. This information is called metadata (data about data).
Reflection is the process of programmatically obtaining type information. Programs can dynamically inspect (“reflect upon”) the metadata for any assemblies, dynamically instantiate objects and invoke members, and even emit metadata dynamically (a technology called Refection Emit). Reflection provides late binding facilities like COM’s IDispatch and IDispatchEx interfaces, type inspection like COM’s ITypeInfo and ITypeInfo2 interfaces, and much more.
How Unmanaged Code Interacts with Managed Code
Three technologies exist that enable the interaction between unmanaged and managed code:
Platform Invocation Services (PInvoke)
1 static class GameSharp
2 {
3 /// The native methods in the DLL's unmanaged code.
4 internal static class UnsafeNativeMethods
5 {
6 const string _dllLocation = "CoreDLL.dll";
7 [DllImport(_dllLocation)]
8 public static extern void SimulateGameDLL(int a, int b);
9 }
10 }
Choosing a Calling Convention
The calling convention of an entry point can be specified using another DllImportAttribute named parameter, called CallingConvention. The choices for this are as follows:
CallingConvention.Cdecl. The caller is responsible for cleaning the stack. Therefore, this calling convention is appropriate for methods that accept a variable number of parameters (like printf).
CallingConvention.FastCall. This is not supported by version 1.0 of the .NET Framework.
CallingConvention.StdCall. This is the default convention for PInvoke methods running on Windows. The callee is responsible for cleaning the stack.
CallingConvention.ThisCall. This is used for calling unmanaged methods defined on a class. All but the first parameter is pushed on the stack since the first parameter is the this pointer, stored in the ECX register.
CallingConvention.Winapi. This isn’t a real calling convention, but rather indicates to use the default calling convention for the current platform. On Windows (but not Windows CE), the default calling convention is StdCall.
Declare always uses Winapi, and the default for DllImportAttribute is also Winapi. As you might guess, this is the calling convention used by Win32 APIs, so this setting doesn’t need to be used in this chapter’s examples.
1 using System;
2 using System.Runtime.InteropServices;
3 4 public class LibWrap
5 {
6 // C# doesn't support varargs so all arguments must be explicitly defined.
7 // CallingConvention.Cdecl must be used since the stack is
8 // cleaned up by the caller.
9
10 // int printf( const char *format [, argument] )
)
11 12 [DllImport("msvcrt.dll", CharSet=CharSet.Unicode, CallingConvention=CallingConvention.Cdecl)]
13 public static extern int printf(String format,
int i,
double d);
14 15 [DllImport("msvcrt.dll", CharSet=CharSet.Unicode, CallingConvention=CallingConvention.Cdecl)]
16 public static extern int printf(String format,
int i, String s);
17 }
18 19 public class App
20 {
21 public static void Main()
22 {
23 LibWrap.printf("\nPrint params: %i %f", 99, 99.99);
24 LibWrap.printf("\nPrint params: %i %s", 99, "abcd");
25 }
26 }
Mixed-Mode Programming Using Managed Extensions to C++
COM Interoperability

Good COM server implementation in C#
posted @
2013-06-27 03:32 鹰击长空 阅读(365) |
评论 (0) |
编辑 收藏
As demand of project, I need to learn this language a little bit more. Although I have written some Python script before, still there is numerous knowledge need to learn.
eg: y = raw_input(‘Enter a number’)
# y is a string
list = [ 'abcd', 786 , 2.23, 'john', 70.2 ] tinylist = [123, 'john']
print list # Prints complete list
print list[0] # Prints first element of the list
print list[1:3] # Prints elements starting from 2nd till 3rd
print list[2:] # Prints elements starting from 3rd element
print tinylist * 2 # Prints list two times
print list + tinylist # Prints concatenated list
tuple = ( 'abcd', 786 , 2.23, 'john', 70.2 ) tinytuple = (123, 'john')
print tuple # Prints complete list
print tuple[0] # Prints first element of the list
print tuple[1:3] # Prints elements starting from 2nd till 3rd
print tuple[2:] # Prints elements starting from 3rd element
print tinytuple * 2 # Prints list two times
print tuple + tinytuple # Prints concatenated lists
posted @
2012-12-20 12:41 鹰击长空 阅读(268) |
评论 (0) |
编辑 收藏
I didn't use VS2008 for a long time, but today I need to build a project with it. It cost me several hours to solve some small issues. It seems have lots of bug. I will list them as follows:
First of all, I cannot edit the resource file with the default program. Searched with Google, this is a bug of VS. Just replace the slash in absolute including path with double slash;
The second issue is additional lib. In VS2010, multiply lib file names is separate by semicolon, but in VS2009 it is space;
posted @
2012-10-11 11:08 鹰击长空 阅读(304) |
评论 (0) |
编辑 收藏
在编写共享库时,为保证ABI(app binary interface)兼容:
1 尽量使用C语言 2不要在接口类使用虚函数和模板; 3 不要改变成员函数的访问权限; 4 不要使用STL 5 不要依赖使用虚拟析构函数,最好自己实现,显式调用;
6 不要在DLL里面申请内存,DLL外释放,DLL和APP可能不在同一个内存堆;
可重入(reentrant)函数可以由多于一个任务并发使用,而不必担心数据错误。相反, 不可重入(non-reentrant)函数不能由超过一个任务所共享,除非能确保函数的互斥(或者使用信号量,或者在代码的关键部分禁用中断)。可重入函数可以在任意时刻被中断,稍后再继续运行,不会丢失数据。可重入函数要么使用本地变量,要么在使用全局变量时保护自己的数据。
Reentrant Function:A function whose effect, when called by two or more threads,is guaranteed to be as if the threads each executed thefunction one after another in an undefined order, even ifthe actual execution is interleaved.
Thread-Safe Function:A function that may be safely invoked concurrently by multiple threads.
函数可重入的必要条件:
1 不使用任何(局部)静态变量或者全局的非常量;
2 不返回任何局部静态或者全局非常量指针;
3 仅依赖调用方的参数;
4 不依赖任何单个资源的锁;
5 不调用任何不可重入的函数;
In classical OS, stack grows downwards. After each push operatation, the value of ebp becomes small, and vice versa.
esp is the top of the stack.
ebp is usually set to esp at the start of the function. Local variables are accessed by subtracting a constant offset from ebp. All x86 calling conventions define ebp as being preserved across function calls. ebp itself actually points to the previous frame's base pointer, which enables stack walking in a debugger and viewing other frames local variables to work.
Most function prologs look something like:
push ebp ; Preserve current frame pointer
mov ebp, esp ; Create new frame pointer pointing to current stack top
sub esp, 20 ; allocate 20 bytes worth of locals on stack.
Then later in the function you may have code like (presuming both local variables are 4 bytes)
mov [ebp-4], eax ; Store eax in first local
mov ebx, [ebp - 8] ; Load ebx from second local
objdump is a program for displaying various information about object files. For instance, it can be used as a disassembler to view executable in assembly form. It is part of the GNU Binutils for fine-grained control over executable and other binary data.
For example, to completely disassemble a binary:
objdump -Dslx file
posted @
2012-07-17 22:20 鹰击长空 阅读(357) |
评论 (0) |
编辑 收藏
How Cocoa Bindings Work (via KVC and KVO)
Cocoa bindings can be a little confusing, especially to newcomers. Once you have an understanding of the underlying concepts, bindings aren’t too hard. In this article, I’m going to explain the concepts behind bindings from the ground up; first explaining Key-Value Coding (KVC), then Key-Value Observing (KVO), and finally explaining how Cocoa bindings are built on top of KVC and KVO.
Key-Value Coding (KVC)
The first concept you need to understand is Key-Value Coding (KVC), as KVO and bindings are built on top of it.
Objects have certain "properties". For example, a Person object may have an name property and an address property. In KVC parlance, the Person object has a value for the name key, and for the address key. "Keys" are just strings, and "values" can be any type of object[1]. At it’s most fundamental level, KVC is just two methods: a method to change the value for a given key (mutator), and a method to retrieve the value for a given key (accessor). Here is an example:
void ChangeName(Person* p, NSString* newName)
{
//using the KVC accessor (getter) method
NSString* originalName = [p valueForKey:@"name"];
//using the KVC mutator (setter) method.
[p setValue:newName forKey:@"name"];
NSLog(@"Changed %@'s name to: %@", originalName, newName);
}
Now let’s say the Person object has a third key: a spouse key. The value for the spouse key is another Person object. KVC allows you to do things like this:
void LogMarriage(Person* p)
{
//just using the accessor again, same as example above
NSString* personsName = [p valueForKey:@"name"];
//this line is different, because it is using
//a "key path" instead of a normal "key"
NSString* spousesName = [p valueForKeyPath:@"spouse.name"];
NSLog(@"%@ is happily married to %@", personsName, spousesName);
}
Cocoa makes a distinction between "keys" and "key paths". A "key" allows you to get a value on an object. A "key path" allows you to chain multiple keys together, separated by dots. For example, this…
[p valueForKeyPath:@"spouse.name"];
… is exactly the same as this…
[[p valueForKey:@"spouse"] valueForKey:@"name"];
That’s all you need to know about KVC for now.
Let’s move on to KVO.
Key-Value Observing (KVO)
Key-Value Observing (KVO) is built on top of KVC. It allows you to observe (i.e. watch) a KVC key path on an object to see when the value changes. For example, let’s write some code that watches to see if a person’s address changes. There are three methods of interest in the following code:
watchPersonForChangeOfAddress: begins the observing
observeValueForKeyPath:ofObject:change:context: is called every time there is a change in the value of the observed key path
dealloc stops the observing
static NSString* const KVO_CONTEXT_ADDRESS_CHANGED = @"KVO_CONTEXT_ADDRESS_CHANGED"
@implementation PersonWatcher
-(void) watchPersonForChangeOfAddress:(Person*)p;
{
//this begins the observing
[p addObserver:self
forKeyPath:@"address"
options:0
context:KVO_CONTEXT_ADDRESS_CHANGED];
//keep a record of all the people being observed,
//because we need to stop observing them in dealloc
[m_observedPeople addObject:p];
}
//whenever an observed key path changes, this method will be called
- (void)observeValueForKeyPath:(NSString *)keyPath
ofObject:(id)object
change:(NSDictionary *)change
context:(void *)context;
{
//use the context to make sure this is a change in the address,
//because we may also be observing other things
if(context == KVO_CONTEXT_ADDRESS_CHANGED){
NSString* name = [object valueForKey:@"name"];
NSString* address = [object valueForKey:@"address"];
NSLog(@"%@ has a new address: %@", name, address);
}
}
-(void) dealloc;
{
//must stop observing everything before this object is
//deallocated, otherwise it will cause crashes
for(Person* p in m_observedPeople){
[p removeObserver:self forKeyPath:@"address"];
}
[m_observedPeople release]; m_observedPeople = nil;
[super dealloc];
}
-(id) init;
{
if(self = [super init]){
m_observedPeople = [NSMutableArray new];
}
return self;
}
@end
This is all that KVO does. It allows you to observe a key path on an object to get notified whenever the value changes.
Cocoa Bindings
Now that you understand the concepts behind KVC and KVO, Cocoa bindings won’t be too mysterious.
Cocoa bindings allow you to synchronise two key paths[2] so they have the same value. When one key path is updated, so is the other one.
For example, let’s say you have a Person object and an NSTextField to edit the person’s address. We know that every Person object has an address key, and thanks to the Cocoa Bindings Reference, we also know that every NSTextField object has a value key that works with bindings. What we want is for those two key paths to be synchronised (i.e. bound). This means that if the user types in the NSTextField, it automatically updates the address on the Person object. Also, if we programmatically change the the address of the Person object, we want it to automatically appear in the NSTextField. This can be achieved like so:
void BindTextFieldToPersonsAddress(NSTextField* tf, Person* p)
{
//This synchronises/binds these two together:
//The `value` key on the object `tf`
//The `address` key on the object `p`
[tf bind:@"value" toObject:p withKeyPath:@"address" options:nil];
}
What happens under the hood is that the NSTextField starts observing the address key on the Person object via KVO. If the address changes on the Person object, the NSTextField gets notified of this change, and it will update itself with the new value. In this situation, the NSTextField does something similar to this:
- (void)observeValueForKeyPath:(NSString *)keyPath
ofObject:(id)object
change:(NSDictionary *)change
context:(void *)context;
{
if(context == KVO_CONTEXT_VALUE_BINDING_CHANGED){
[self setStringValue:[object valueForKeyPath:keyPath]];
}
}
When the user starts typing into the NSTextField, the NSTextField uses KVC to update the Person object. In this situation, the NSTextField does something similar to this:
- (void)insertText:(id)aString;
{
NSString* newValue = [[self stringValue] stringByAppendingString:aString];
[self setStringValue:newValue];
//if "value" is bound, then propagate the change to the bound object
if([self infoForBinding:@"value"]){
id boundObj = ...; //omitted for brevity
NSString* boundKeyPath = ...; //omitted for brevity
[boundObj setValue:newValue forKeyPath:boundKeyPath];
}
}
For a more complete look at how views propagate changes back to the bound object, see my article: Implementing Your Own Cocoa Bindings.
Conclusion
That’s that basics of how KVC, KVO and bindings work. The views use KVC to update the model, and they use KVO to watch for changes in the model. I have left out quite a bit of detail in order to keep the article short and simple, but hopefully it has given you a firm grasp of the concepts and principles.
Footnotes
[1] KVC values can also be primitives such as BOOL or int, because the KVC accessor and mutator methods will perform auto-boxing. For example, a BOOL value will be auto-boxed into an NSNumber*.
[2] When I say that bindings synchronise two key paths, that’s not technically correct. It actually synchronises a "binding" and a key path. A "binding" is a string just like a key path but it’s not guaranteed to be KVC compatible, although it can be. Notice that the example code uses @"address" as a key path but never uses @"value" as a key path. This is because @"value" is a binding, and it might not be a valid key path.
posted @
2012-07-16 16:27 鹰击长空 阅读(339) |
评论 (0) |
编辑 收藏
Create a new local repository:prompt>
mkdir /path/to/repo:
prompt>
cd /path/to/repoprompt>
git initInitialized empty Git repository in /path/to/repo/.git/
prompt>
... create file(s) for first commit ...
prompt>
git add .prompt>
git commit -m 'initial import'Created initial commit bdebe5c: initial import.
1 files changed, 1 insertions(+), 0 deletions(-)
Note that the commit action
only commits to your local repository.
Change one of my github repo name
in two steps:
Firstly, cd to your local git directory, and find out what remote name(s) refer to that URL
$ git remote -v origin git@github.com:someuser/someproject.git
Then, set the new URL
$ git remote set-url origin git@github.com:someuser/newprojectname.git
or in older versions of git, you might need
$ git remote rm origin $ git remote add origin git@github.com:someuser/newprojectname.git
(origin is the most common remote name, but it might be called something else.)
But if there's lots of people who are working on your project, they will all need to do the above steps, and maybe you don't even know how to contact them all to tell them. That's what #1 is about.
Further reading:
Footnotes:
1 The exact format of your URL depends on which protocol you are using, e.g.
push your local repository into remote repository:prompt>git push origin master
To amend the last wrong commit:
git commit --amend -m "New commit message"
If the commit you want to fix isn’t the most recent one:
-
git rebase --interactive $parent_of_flawed_commit
If you want to fix several flawed commits, pass the parent of the oldest one of them.
-
An editor will come up, with a list of all commits since the one you gave.
- Change
pick to reword (or on old versions of Git, to edit) in front of any commits you want to fix. - Once you save, git will replay the listed commits.
-
Git will drop back you into your editor for every commit you said you want to reword, and into the shell for every commit you wanted to edit. If you’re in the shell:
- Change the commit in any way you like.
git commit --amendgit rebase --continue
Most of this sequence will be explained to you by the output of the various commands as you go. It’s very easy, you don’t need to memorise it – just remember that git rebase --interactive lets you correct commits no matter how long ago they were.
Today, when I try to push some code to the remote, it told me the there is a permission issue, I finally fixed it by created a new key, add it to my git account and local account. Here is the process of adding to local
$ git push -u origin master
Permission denied (publickey).
fatal: The remote end hung up unexpectedly
$ ssh -vT git@github.com
OpenSSH_4.6p1, OpenSSL 0.9.8e 23 Feb 2007
debug1: Connecting to github.com [207.97.227.239] port 22.
debug1: Connection established.
debug1: No more authentication methods to try.
Permission denied (publickey).
$ ssh-add -l
Could not open a connection to your authentication agent.
$ eval `ssh-agent`
Agent pid 4968
If you did not have a key, generate one according this https://help.github.com/articles/generating-ssh-keys
then add the key
$ ssh-add /c/Users/li/.ssh/key
Identity added: /c/Users/li/.ssh/key
$ ssh -vT git@github.com
OpenSSH_4.6p1, OpenSSL 0.9.8e 23 Feb 2007
debug1: Connecting to github.com [207.97.227.239] port 22.
debug1: Connection established.
debug1: identity file /c/Users/li/.ssh/identity type -1
Hi ***! You've successfully authenticated, but GitHub does not provide shell access.
debug1: channel 0: free: client-session, nchannels 1
debug1: Transferred: stdin 0, stdout 0, stderr 0 bytes in 0.3 seconds
debug1: Bytes per second: stdin 0.0, stdout 0.0, stderr 0.0
debug1: Exit status 1
$ git push -u origin master
Counting objects: 46, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (42/42), done.
Writing objects: 100% (46/46), 21.33 KiB, done.
Total 46 (delta 1), reused 0 (delta 0)
Create a new repository in a new directory via the following commands.
# Switch to home
cd ~
# Make new directory
mkdir repo02
# Switch to new directory
cd ~/repo02
# Clone
git clone ../remote-repository.git .
posted @
2012-07-09 22:04 鹰击长空 阅读(498) |
评论 (0) |
编辑 收藏
Chapter 4
Some people find the “90/10” rule helpful: 90 percent of the running time of most programs is spent in only
10 percent of the code (Hennessy and Patterson, 2002)
Use a vector instead of an array whenever possible.
Vectors provide fast (constant time) element insertion and deletion at the end of the vector, but slow
(linear time) insertion and deletion anywhere else. Insertion and deletion are slow because the operation
must move all the elements “down” or “up” by one to make room for the new element or to fill the
space left by the deleted element. Like arrays, vectors provide fast (constant time) access to any of their
elements.
You should use a vector in your programs when you need fast access to the elements, but do not plan to
add or remove elements often. A good rule of thumb is to use a vector whenever you would have used
an array.
The name deque is an abbreviation for a double-ended queue. A deque is partway between a vector and a
list, but closer to a vector. Like a vector, it provides quick (constant time) element access. Like a list, it
provides fast (amortized constant time) insertion and deletion at both ends of the sequence. However,
unlike a list, it provides slow (linear time) insertion and deletion in the middle of the sequence.
You should use a deque instead of a vector when you need to insert or remove elements from either end
of the sequence but still need fast access time to all elements. However, this requirement does not apply
to many programming problems; in most cases a vector or queue should suffice.
A set in STL is a collection of elements. Although the mathematical definition of a set implies an
unordered collection, the STL set stores the elements in an ordered fashion so that it can provide reasonably
fast lookup, insertion, and deletion.
Use a set instead of a vector or list if you want equal performance for insertion, deletion,and lookup.
Note that a set does not allow duplication of elements. That is, each element in the set must be unique. If
you want to store duplicate elements, you must use a multiset.
Chapter8
Initializer lists allow initialization of data members at the time of their creation.
An initializer list allows you to provide initial values for data members as they are created, which is more efficient than assigning values to them later.
However, several data types must be initialized in an initializer list. The following table summarizes them:a、 const data members; b、Reference data members C、Object data members or Superclasses without default constructors
Initializer lists initialize data members in their declared order in the class definition,not their order in the list.
Chapter9
Pass objects by const reference instead of by value.
The default semantics for passing arguments to functions in C++ is pass-by-value. That means that the function or method receives a copy of the variable, not the variable itself. Thus, whenever you pass an object to a function or method the compiler calls the copy constructor of the new object to initialize it. The copy constructor is also called whenever you return an object from a function or method.
posted @
2012-07-09 19:41 鹰击长空 阅读(463) |
评论 (0) |
编辑 收藏
print all permutations of a given string. A permutation, also called an “arrangement number” or “order,” is a rearrangement of the elements of an ordered list S into a one-to-one correspondence with S itself. A string of length n has n! permutation.
|
# include <stdio.h>
void swap (char *x, char *y)
{
char temp;
temp = *x;
*x = *y;
*y = temp;
}
void permute(char *a, int i, int n)
{
int j;
if (i == n)
printf("%s\n", a);
else
{
for (j = i; j <= n; j++)
{
swap((a+i), (a+j));
permute(a, i+1, n);
swap((a+i), (a+j));
}
}
}
int main()
{
char a[] = "ABC";
permute(a, 0, 2);
getchar();
return 0;
}
|
2. find the sum of contiguous subarray within a one-dimensional array of numbers which has the largest sum.
#include<stdio.h>
int maxSubArraySum(int a[], int size)
{
int max_so_far = 0, max_ending_here = 0;
int i;
for(i = 0; i < size; i++)
{
max_ending_here = max_ending_here + a[i];
if(max_ending_here < 0)
max_ending_here = 0;
if(max_so_far < max_ending_here)
max_so_far = max_ending_here;
}
return max_so_far;
}
int main()
{
int a[] = {-2, -3, 4, -1, -2, 1, 5, -3};
int max_sum = maxSubArraySum(a, 8);
printf("Maximum contiguous sum is %d\n", max_sum);
getchar();
return 0;
}
|
posted @
2012-07-05 17:51 鹰击长空 阅读(355) |
评论 (0) |
编辑 收藏
From
http://www.newsmth.net/nForum/#!article/Apple/136327窗口
----
其实 Mac OS X 的老用户们都该熟悉了,和 Windows 不一样,这个系统里“窗口”并非
最重要的概念,一个程序的逻辑结构是:
+---------------------------------------------+
| Application |
| +-------------------------+ +-----------+ |
| | Window | | Menu | |
| | +----------------+ | +-----------+ |
| | | Control | | |
| | | +---------+ | | |
| | | | Control | | | |
| | | +---------+ | | |
| | +----------------+ | |
| +-------------------------+ |
+---------------------------------------------+
也就是说,菜单是独立于窗口的存在,有窗口和控件的区别。这和 Windows 中一切的
本质都是窗口有很大的区别。
虽然 Mac OS X 中区分 Window, Control 和 Menu 这几种概念,但并不代表其设计上
没有考虑到它们之间的一致性。在 Carbon 中,这些实体都是用 FooRef 的形式来表示
的,Ref 就有指针的意思,比如你创建了一个窗口之后,就会得到对应的
WindowRef,其实这就是一个用来操纵这个窗口的指针,而你创建控件之后,对应的
是 ControlRef,创建菜单对应的自然是 MenuRef 了,还是很好理解的吧。
我们这里先只谈窗口。很显然,要创建窗口,还得有些其他的属性,让我们看看
Carbon 的 CreateNewWindow 这个函数的原形是怎么要求的:
OSStatus CreateNewWindow (
WindowClass windowClass,
WindowAttributes attributes,
const Rect *contentBounds,
WindowRef *outWindow
);
WindowClass 是一个常量,我们最常见的一种是 kDocumentWindowClass (也是下面
打算要用的),还有 kDrawerWindowClass,这也很好理解:那种可以伸缩的 Drawer
嘛,kAlertWindowClass 呢?就是我们常见的提示框了。
WindowAttributes 则是针对具体 WindowClass 再作更仔细的属性定制了,这也是一个
32 位的无符号整数,但和 WindowClass 只能 n 选 1 不同,你可以把属性用位或 (|) 组
合起来使用。反正一时也记不住那么多,就先设置为
kWindowStandardDocumentAttributes | kWindowStandardHandlerAttribute 好了。前
者保证我们的窗口具有其他标准的文档窗口相同的特性,而后者给窗口加上系统提供的
标准 event handler,以自动处理一般的 event。下面是用于设置的代码:
WindowAttributes windowAttrs;
windowAttrs = kWindowStandardDocumentAttributes |
kWindowStandardHandlerAttribute;
直到这里,“event”都还是一个很模糊的概念,虽然我们前面多次提到了它,但为了避
免过多的讲理论,我拖到现在才来介绍它。
Event (事件) 其实是 Carbon 编程的基础。鼠标点击、键盘输入、菜单命令都是以
event 的形式发出的。窗口需要重绘、移动和放缩时,也会告知你的应用程序一个
event。当你的程序切换到前端或者后端时,你也会收到 event 告知你这个信息。
Carbon 程序的工作就是通过回应 event 来实现与用户和系统交互。
Carbon 的 event 处理是基于回调 (callback) 机制的。你可以定义针对不同 event 类型
的 event handler,然后在 Carbon Event Manager 中注册 (Install) 之。然后每当
event 发生时,Carbon Event Manager 就会调用你注册的 handler 函数。每个 event
handler 都必须与一个具体的 event target 对象关联起来,比如 target 是菜单、窗口或
整个程序。
应用程序包含窗口和菜单,窗口包含控件,控件还能进一步包含控件。一旦 event 出
现,首先得到通知的是最里层的 target,比如点击 button 的 event 首先发到 button 控
件上。如果最里面的 target 没有相关的 handler,就把 event 传播到更外层的包含它的
target 上。Carbon 给窗口和应用程序的 event target 提供了标准的 handler。标准
handler 可以负责处理类似窗口针对鼠标的操作,比如拖拽,伸缩等等。这样一来,你
就只需要关心自己的程序里针对拖拽或伸缩的特殊反映,而不比费神于那些所有程序都
通用的部分了。
当然,如果你愿意,也可以覆盖标准的 handler,比如有人可能会写个针对拉伸窗口的
handler,给窗口的伸缩增加音效。我们这里没那么复杂,用标准的就好啦。
第三个参数就更好理解了,是一个指向 Rect 这个结构体的指针,说明了窗口在屏幕坐
标系 [1] 中的位置和大小。这个东西其实还是 QuickDraw 中的概念,所以在程序中我
们也调用 QuickDraw 的 API 来完成设置:
#define kWindowTop 100
#define kWindowLeft 50
#define kWindowRight 800
#define kWindowBottom 600
Rect contentRect;
SetRect(&contentRect, kWindowLeft, kWindowTop,
kWindowRight, kWindowBottom);
设置的正是这个矩形四个点的坐标。
[1]: 注意屏幕坐标系中左上角是 (0, 0)。
最后一个参数是一个输出,也就是我们最终创建出来的那个新窗口的指针了。所以,我
们一般是这样创建窗口的:
WindowRef theWindow;
CreateNewWindow(kDocumentWindowClass, windowAttrs,
&contentRect, &theWindow);
等等,窗口是创建好了,存在 theWindow 指针里,可窗口的标题呢?我们这样设置:
SetWindowTitleWithCFString(theWindow, CFSTR("Hello Carbon"));
注意这里的 CFSTR 是一个宏,用于把 C 的 const char * 字符串转换为 Core
Foundation 定义的 CFStringRef 字符串,对于 CFString 的详细介绍可以看 Strings
Programming Guide for Core Foundation [2],不过其实现在我们知道它包括的是一个
数组和数组的长度,数组的元素都是 Unicode 字符 (UniChar),就行了,具体的转换细
节暂时不必考虑。
[2]:
http://developer.apple.com/documentation/CoreFoundation/Conceptual/ CFStrings/CFStrings.html
一切完毕之后,我们就可以显示这个窗口了:
ShowWindow(theWindow);
下面把完整的代码列出 (你也可以看附件里面的):
/* hello.c: testing Carbon basics */
#include <Carbon/Carbon.h>
#define kWindowTop 100
#define kWindowLeft 50
#define kWindowRight 800
#define kWindowBottom 600
int main(int argc, char *argv[])
{
WindowRef theWindow;
WindowAttributes windowAttrs;
Rect contentRect;
windowAttrs = kWindowStandardDocumentAttributes |
kWindowStandardHandlerAttribute;
SetRect(&contentRect, kWindowLeft, kWindowTop,
kWindowRight, kWindowBottom);
CreateNewWindow(kDocumentWindowClass, windowAttrs,
&contentRect, &theWindow);
SetWindowTitleWithCFString(theWindow,
CFSTR("Hello Carbon"));
ShowWindow(theWindow);
RunApplicationEventLoop();
return 0;
}
这一节的内容,呃,还是超出了我的预计,你要是有兴趣不妨再看看 Carbon Event
Manager Programming Guide,event 还是一个比较 tricky 的概念,而我们要到后面
用到的时候才会深谈。下一节讲菜单的创建。
posted @
2012-07-04 10:39 鹰击长空 阅读(929) |
评论 (1) |
编辑 收藏
The original post is http://igoro.com/archive/efficient-auto-complete-with-a-ternary-search-tree/
Over the past couple of years, auto-complete has popped up all over the web. Facebook, YouTube, Google, Bing, MSDN, LinkedIn and lots of other websites all try to complete your phrase as soon as you start typing.
Auto-complete definitely makes for a nice user experience, but it can be a challenge to implement efficiently. In many cases, an efficient implementation requires the use of interesting algorithms and data structures. In this blog post, I will describe one simple data structure that can be used to implement auto-complete: a ternary search tree.
Trie: simple but space-inefficient
Before discussing ternary search trees, let’s take a look at a simple data structure that supports a fast auto-complete lookup but needs too much memory: a trie. A trie is a tree-like data structure in which each node contains an array of pointers, one pointer for each character in the alphabet. Starting at the root node, we can trace a word by following pointers corresponding to the letters in the target word.
Each node could be implemented like this in C#:
class TrieNode
{
public const int ALPHABET_SIZE = 26;
public TrieNode[] m_pointers = new TrieNode[ALPHABET_SIZE];
public bool m_endsString = false;
}
Here is a trie that stores words AB, ABBA, ABCD, and BCD. Nodes that terminate words are marked yellow:
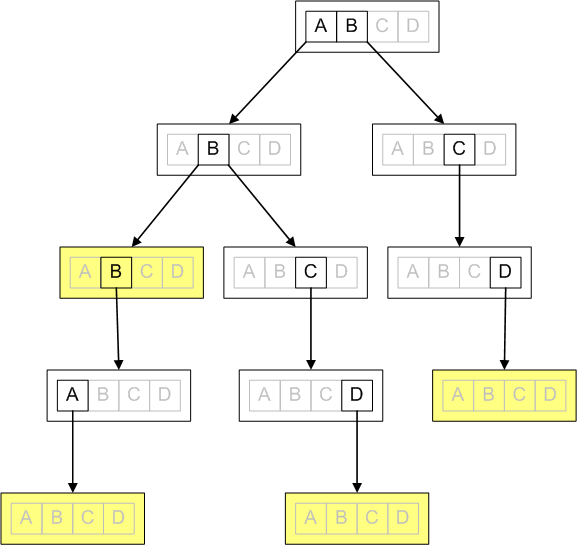
Implementing auto complete using a trie is easy. We simply trace pointers to get to a node that represents the string the user entered. By exploring the trie from that node down, we can enumerate all strings that complete user’s input.
But, a trie has a major problem that you can see in the diagram above. The diagram only fits on the page because the trie only supports four letters {A,B,C,D}. If we needed to support all 26 English letters, each node would have to store 26 pointers. And, if we need to support international characters, punctuation, or distinguish between lowercase and uppercase characters, the memory usage grows becomes untenable.
Our problem has to do with the memory taken up by all the null pointers stored in the node arrays. We could consider using a different data structure in each node, such as a hash map. However, managing thousands and thousands of hash maps is generally not a good idea, so let’s take a look at a better solution.
Ternary search tree to the rescue
A ternary tree is a data structure that solves the memory problem of tries in a more clever way. To avoid the memory occupied by unnecessary pointers, each trie node is represented as a tree-within-a-tree rather than as an array. Each non-null pointer in the trie node gets its own node in a ternary search tree.
For example, the trie from the example above would be represented in the following way as a ternary search tree:

The ternary search tree contains three types of arrows. First, there are arrows that correspond to arrows in the corresponding trie, shown as dashed down-arrows. Traversing a down-arrow corresponds to “matching” the character from which the arrow starts. The left- and right- arrow are traversed when the current character does not match the desired character at the current position. We take the left-arrow if the character we are looking for is alphabetically before the character in the current node, and the right-arrow in the opposite case.
For example, green arrows show how we’d confirm that the ternary tree contains string ABBA:

And this is how we’d find that the ternary string does not contain string ABD:

Ternary search tree on a server
On the web, a significant chunk of the auto-complete work has to be done by the server. Often, the set of possible completions is large, so it is usually not a good idea to download all of it to the client. Instead, the ternary tree is stored on the server, and the client will send prefix queries to the server.
The client will send a query for words starting with “bin” to the server:

And the server responds with a list of possible words:

Implementation
Here is a simple ternary search tree implementation in C#:
public class TernaryTree
{
private Node m_root = null;
private void Add(string s, int pos, ref Node node)
{
if (node == null) { node = new Node(s[pos], false); }
if (s[pos] < node.m_char) { Add(s, pos, ref node.m_left); }
else if (s[pos] > node.m_char) { Add(s, pos, ref node.m_right); }
else
{
if (pos + 1 == s.Length) { node.m_wordEnd = true; }
else { Add(s, pos + 1, ref node.m_center); }
}
}
public void Add(string s)
{
if (s == null || s == "") throw new ArgumentException();
Add(s, 0, ref m_root);
}
public bool Contains(string s)
{
if (s == null || s == "") throw new ArgumentException();
int pos = 0;
Node node = m_root;
while (node != null)
{
int cmp = s[pos] - node.m_char;
if (s[pos] < node.m_char) { node = node.m_left; }
else if (s[pos] > node.m_char) { node = node.m_right; }
else
{
if (++pos == s.Length) return node.m_wordEnd;
node = node.m_center;
}
}
return false;
}
}
And here is the Node class:
class Node
{
internal char m_char;
internal Node m_left, m_center, m_right;
internal bool m_wordEnd;
public Node(char ch, bool wordEnd)
{
m_char = ch;
m_wordEnd = wordEnd;
}
}
Remarks
For best performance, strings should be inserted into the ternary tree in a random order. In particular, do not insert strings in the alphabetical order. Each mini-tree that corresponds to a single trie node would degenerate into a linked list, significantly increasing the cost of lookups. Of course, more complex self-balancing ternary trees can be implemented as well.
And, don’t use a fancier data structure than you have to. If you only have a relatively small set of candidate words (say on the order of hundreds) a brute-force search should be fast enough.
Further reading
Another article on tries is available on DDJ (careful, their implementation assumes that no word is a prefix of another):
http://www.ddj.com/windows/184410528
If you like this article, also check out these posts on my blog:
posted @
2012-06-25 23:26 鹰击长空 阅读(519) |
评论 (0) |
编辑 收藏