题目:1分钟内用户上线的数目是60万,如果用户在5分钟内重复上线,就给他发警告,问如何设计?
考虑:要判断用户是否在5分内重复上线,那么至少要(也只需要)保存距当前时刻5分钟内的登录用户的信息(只要简单的ID)
从这个开始出发,需要考虑的问题为2个:
1.如何在迅速判断用户是否在保存的数据中 (这个理所当然想道用hash)
2. 如果把过期的数据删掉 (这个就想到维护一个时间链表,把到期的通过链表来删除)
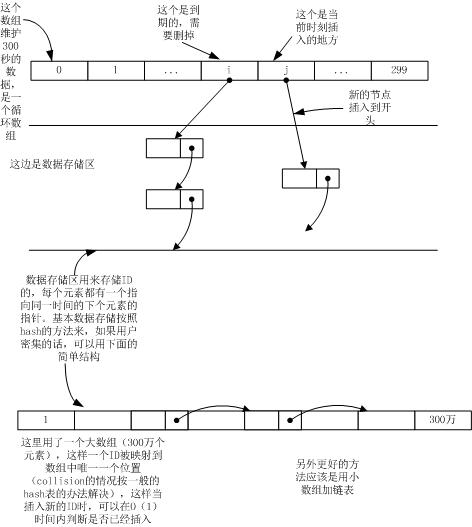
这个是半年前腾讯面试的时候碰到的题目,当时觉得很难,今天走在路上突然想起,想了想,突然想到这种方法,也许不是最好,但至少解决了,也了解了一件事
static的作用有2个,一个是控制名字的可见性,一个是控制生存期
1.控制名字的可见性
这时候是跟extern相对应的,作用与文件作用域(file scope)内的所有名字(变量名或函数名),其它定义在函数内或类内的变量名或函数名都不具有文件作用域。
一般情况下,当你定义了一个全局范围内变量或函数名的时候,默认的是extern,如在下面的file1.cpp
 //file1.cpp
//file1.cpp
int a=1; //完整的应该是extern int a=1;但extern是缺省的
void f() //同上一样,这里也是定义


 {
{

 }
}那么在file2.cpp中你不能再声明a跟f,否则会引起名字冲突,当你想要使用file1.cpp中的a跟f时,可以如下
extern int a; //不运行赋值,这里只是声明,不可以省去extern,否则编译器会认为是重定义
void f(); //同样是声明,而且对函数而言,可以省去extern
extern int b=1;//这里是定义
这样就可以在file2.cpp中使用a跟f了
反过来,你在文件作用域范围内定义了一个名字,你不希望被其它文件引用,这时候就要在前面加上static,此时这个变量具有internal linkage,它不能被其它文件引用,同时在其它文件中声明同名变量不会认为有冲突(因为static 使得名字只在本文件内可见)。
2.控制生存期
static 变量同global 变量一样,放在static存储区,只有当程序运行结束时,这些变量才会消失
当static变量定义在函数中时,它仅在该函数内可见,当每次函数调用完,这个变量的值都会保留下来
当static变量定义在类当中时,这个变量就同类的对象无关,真个类只有一个该变量的副本,不过它定义了多少个对象,而且对改变量的改变可以只通过类来改变,该变量的变化对所有同类的对象是可见的
摘要: 其实真正要说的是虚函数,不过其中要扯倒重载,所以顺便也说了下重载1. 重载1.1 简单重载 在C++中,是允许同名函数的存在
int add(int i,int j);float add(float i,float);
...
阅读全文
第一题,17分钟过河,大家估计都知道了
第二题,写代码判断回文
第三题,写测试案例,就是在输入框输入字符串,然后下面回显这个字符串
第四题,写时针跟分针所夹的角度,好几年没带表了,竟然以为只要是8点,时针就永远指在8。太蠢了,因这道题直接出局,到大厅的时候立刻想到了解法:(hour*5+minute/60*5)-minute如果是负的,反一下负号,最后乘以360/60=6
1. const常量,如const int max = 100;
优点:const常量有数据类型,而宏常量没有数据类型。编译器可以对前者进行类型安全检查,而对后者只进行字符替换,没有类型安全检查,并且在字符替换时可能会产生意料不到的错误(边际效应)
2. const 修饰类的数据成员。如:
class A
{
const int size;
…
}
const数据成员只在某个对象生存期内是常量,而对于整个类而言却是可变的。因为类可以创建多个对象,不同的对象其const数据成员的值可以不同。所以不能在类声明中初始化const数据成员,因为类的对象未被创建时,编译器不知道const 数据成员的值是什么。如
class A
{
const int size = 100; //错误
int array[size]; //错误,未知的size
}
const数据成员的初始化只能在类的构造函数的初始化表中进行。要想建立在整个类中都恒定的常量,应该用类中的枚举常量来实现。如
class A
{…
enum {size1=100, size2 = 200 };
int array1[size1];
int array2[size2];
}
枚举常量不会占用对象的存储空间,他们在编译时被全部求值。但是枚举常量的隐含数据类型是整数,其最大值有限,且不能表示浮点数。
3. const修饰指针的情况,见下式:
int b = 500;
const int* a = & [1]
int const *a = & [2]
int* const a = & [3]
const int* const a = & [4]
如果你能区分出上述四种情况,那么,恭喜你,你已经迈出了可喜的一步。不知道,也没关系,我们可以参考《Effective c++》Item21上的做法,如果const位于星号的左侧,则const就是用来修饰指针所指向的变量,即指针指向为常量;如果const位于星号的右侧,const就是修饰指针本身,即指针本身是常量。因此,[1]和[2]的情况相同,都是指针所指向的内容为常量(const放在变量声明符的位置无关),这种情况下不允许对内容进行更改操作,如不能*a = 3 ;[3]为指针本身是常量,而指针所指向的内容不是常量,这种情况下不能对指针本身进行更改操作,如a++是错误的;[4]为指针本身和指向的内容均为常量。
4. const的初始化
先看一下const变量初始化的情况
1) 非指针const常量初始化的情况:A b;
const A a = b;
2) 指针const常量初始化的情况:
A* d = new A();
const A* c = d;
或者:const A* c = new A();
3)引用const常量初始化的情况:
A f;
const A& e = f; // 这样作e只能访问声明为const的函数,而不能访问一
般的成员函数;
[思考1]: 以下的这种赋值方法正确吗?
const A* c=new A();
A* e = c;
[思考2]: 以下的这种赋值方法正确吗?
A* const c = new A();
A* b = c;
5. 另外const 的一些强大的功能在于它在函数声明中的应用。在一个函数声明中,const 可以修饰函数的返回值,或某个参数;对于成员函数,还可以修饰是整个函数。有如下几种情况,以下会逐渐的说明用法:A& operator=(const A& a);
void fun0(const A* a );
void fun1( ) const; // fun1( ) 为类成员函数
const A fun2( );
1) 修饰参数的const,如 void fun0(const A* a ); void fun1(const A& a);
调用函数的时候,用相应的变量初始化const常量,则在函数体中,按照const所修饰的部分进行常量化,如形参为const A* a,则不能对传递进来的指针的内容进行改变,保护了原指针所指向的内容;如形参为const A& a,则不能对传递进来的引用对象进行改变,保护了原对象的属性。
[注意]:参数const通常用于参数为指针或引用的情况,且只能修饰输入参数;若输入参数采用“值传递”方式,由于函数将自动产生临时变量用于复制该参数,该参数本就不需要保护,所以不用const修饰。
[总结]对于非内部数据类型的输入参数,因该将“值传递”的方式改为“const引用传递”,目的是为了提高效率。例如,将void Func(A a)改为void Func(const A &a)
对于内部数据类型的输入参数,不要将“值传递”的方式改为“const引用传递”。否则既达不到提高效率的目的,又降低了函数的可理解性。例如void Func(int x)不应该改为void Func(const int &x)
2) 修饰返回值的const,如const A fun2( ); const A* fun3( );
这样声明了返回值后,const按照"修饰原则"进行修饰,起到相应的保护作用。const Rational operator*(const Rational& lhs, const Rational& rhs)
{
return Rational(lhs.numerator() * rhs.numerator(),
lhs.denominator() * rhs.denominator());
}
返回值用const修饰可以防止允许这样的操作发生:Rational a,b;
Radional c;
(a*B) = c;
一般用const修饰返回值为对象本身(非引用和指针)的情况多用于二目操作符重载函数并产生新对象的时候。
[总结]
1. 一般情况下,函数的返回值为某个对象时,如果将其声明为const时,多用于操作符的重载。通常,不建议用const修饰函数的返回值类型为某个对象或对某个对象引用的情况。原因如下:如果返回值为某个对象为const(const A test = A 实例)或某个对象的引用为const(const A& test = A实例) ,则返回值具有const属性,则返回实例只能访问类A中的公有(保护)数据成员和const成员函数,并且不允许对其进行赋值操作,这在一般情况下很少用到。
2. 如果给采用“指针传递”方式的函数返回值加const修饰,那么函数返回值(即指针)的内容不能被修改,该返回值只能被赋给加const 修饰的同类型指针。如:
const char * GetString(void);
如下语句将出现编译错误:
char *str=GetString();
正确的用法是:
const char *str=GetString();
3. 函数返回值采用“引用传递”的场合不多,这种方式一般只出现在类的赙值函数中,目的是为了实现链式表达。如:
class A
{…
A &operate = (const A &other); //赋值函数
}
A a,b,c; //a,b,c为A的对象
…
a=b=c; //正常
(a=B)=c; //不正常,但是合法
若负值函数的返回值加const修饰,那么该返回值的内容不允许修改,上例中a=b=c依然正确。(a=B)=c就不正确了。
[思考3]: 这样定义赋值操作符重载函数可以吗?
const A& operator=(const A& a);
6. 类成员函数中const的使用
一般放在函数体后,形如:void fun() const;
任何不会修改数据成员的函数都因该声明为const类型。如果在编写const成员函数时,不慎修改了数据成员,或者调用了其他非const成员函数,编译器将报错,这大大提高了程序的健壮性。如:
class Stack
{
public:
void Push(int elem);
int Pop(void);
int GetCount(void) const; //const 成员函数
private:
int m_num;
int m_data[100];
};
int Stack::GetCount(void) const
{
++m_num; //编译错误,企图修改数据成员m_num
Pop(); //编译错误,企图调用非const函数
Return m_num;
}
7. 使用const的一些建议
1 要大胆的使用const,这将给你带来无尽的益处,但前提是你必须搞清楚原委;
2 要避免最一般的赋值操作错误,如将const变量赋值,具体可见思考题;
3 在参数中使用const应该使用引用或指针,而不是一般的对象实例,原因同上;
4 const在成员函数中的三种用法(参数、返回值、函数)要很好的使用;
5 不要轻易的将函数的返回值类型定为const;
6除了重载操作符外一般不要将返回值类型定为对某个对象的const引用;
[思考题答案]
1 这种方法不正确,因为声明指针的目的是为了对其指向的内容进行改变,而声明的指针e指向的是一个常量,所以不正确;
2 这种方法正确,因为声明指针所指向的内容可变;
3 这种做法不正确;
在const A::operator=(const A& a)中,参数列表中的const的用法正确,而当这样连续赋值的时侯,问题就出现了:
A a,b,c:
(a=B)=c;
因为a.operator=(B)的返回值是对a的const引用,不能再将c赋值给const常量。
给定 P=a1×a2×a3×……×an,依据乘法结合律,不改变其顺序,只用括号表示成对的乘积,试问有几种括号化的方案
n=4的例子如下

假设这个数是h(n-1), (这里之所以是n-1,是因为实际上n指的是元素个数,每2个元素乘一次,只要n-1次就可以乘完)
那么显然h(n-1)=h(0)h(n-2)+h(1)h(n-3)+...+h(n-2)h(0)
对应的例子则是
a(b(cd)) a((bc)d) h(0)h(n-2) (只要先对右边的n-2个元素进行乘积,接着再跟最左边的元素相乘,h(0)=1)
(ab)(cd) h(1)h(n-3) (先乘最左边的2个元素,再乘最右边的n-3个元素,之后再把这2个元素相乘)
(a(bc))d ((ab)c)d h(n-2)h(0)
从括号化展开的应用
1. 进出栈
对括号进行进出栈的模拟,左括号代表进栈,右括号代表进行出栈,那么进出栈的顺序就相当于括号化的方案
2.三角剖分
三角剖分就是从距阵乘法类比过来的,而距阵乘法就是括号化的问题