1、二叉搜索树是二叉树的一种,树的每个结点含有一个数据项,每个数据项有一个键值。结点的存储位置是由键值的大小决定的,所以二叉搜索树是关联式容器。
(1)、 若它的左子树不空,则左子树上所有结点的键值均小于它的根结点的键值;
(2)、若它的右子树不空,则右子树上所有结点的键值均大于它的根结点的键值;
(3)、它的左、右子树也分别为二叉排序树。
注意:::二叉排序树是一种
动态树表,树的结构通常不是一次生成的。而是在查找的过程中,当树中不存在关键字等于给定值的节点时再进行插入。新插入的结点一定是一个新添加的
叶子结点,并且是查找不成功时查找路径上访问的最后一个结点的左孩子或右孩子结点。
2、插入与查找算法:
查找:
(1)、若二叉排序树非空,将给定值与根节点的关键字值比较,若相等,则查找成功;
(2)、若不等,则当根节点的关键字值大于给定值时,到根的左子树中进行查找;
(3)、否则到根的右子树中进行查找。若找到,则查找过程是走了一条从树根到所找到节点的路径;
(4)、否则,查找过程终止于一棵空树。
//① 、普通查找,查找不成功返回NULL
递归思想:
BiTree SearchBST (BiTree *T,KeyType key)
{
//在根指针T所指二叉排序树中递归地查找某关键字等于key的数据元素
//若查找成功,则返回指向该数据元素结点的指针,否则返回空指针
if( (!T)||(key==T—>data.key))
return (T); //查找结束,此时T为NULL,或者为该结点
else if (key< T—>data.key)
return(SearchBST(T—>lchild,key)); //在左子树中继续查找
else
return(SearchBST(T —>rchild,key));// 在右子树中继续查找
}//SearchBST
非递归思想:
BiTree SearchBST (BiTree *root,KeyType key)
{
BiTree *p;
if( root == NULL)return NULL;//查找结束,此时根为NULL,
p = root;
while(p!=NULL)
{
if(p ->key==Key)breat;
if( Key < p ->key) p =p ->lchild;//在左子树中继续查找
else p = p ->rchild;//在右子树中继续查找
}
return p;
}
//② 、查找不成功,返回插入位置
//在根指针T所指二叉排序树中递归地查找其关键字等于key的数据元素,
//若查找成功,则指针p指向该数据元素结点,并返回TRUE,
//否则指针p指向查找路径上访问的最后一个结点并返回FALSE,
//指针f指向T的双亲,其初始调用值为NULL
BOOL SearchBST(BiTree *T,KeyType key,BiTree *f,BiTree &p)
{
if(!T) {p=f;return FALSE;} //查找不成功
else if (key==T—>data.key)
{p=T;return TRUE;} //查找成功
else if (key<T—>data.key) SearchBST(T—>lchild,key,T,p); //在左子树中继续查找
else SearchBST(T—>rchild,key,T,p);//在右子树中继续查找
}//SearchBST
插入:
(1)、首先执行查找算法,找出被插结点的父亲结点。没找到则新建子结点
(2)、判断被插结点是其父亲结点的左、右儿子。将被插结点作为叶子结点插入。
(3)、若二叉树为空。则首先单独生成根结点
基于BOOL SearchBST(BiTree *T,KeyType key,BiTree *f,BiTree &p)的插入算法
相当于新建子树。
//当二叉排序树T中不存在关键字等于e.key的数据元素时,插入e并返回TRUE,否则返回FALSE
Status Insert BST(BiTree &T,ElemType e)
{
if(!SearchBST(T,e.key,NULL,p) ) //返回P为插入的结点点
{ //先查找,不成功新建结点
s=(BiTree)malloc(sizeof(BiTNode));
s->data=e; s->lchild= s->rchild=NULL;
if (!p) T = s; //被插结点*s为新的根结点 ,原树为空
else if (e.key<p->data.key) p->lchild=s; //被插结点*s为左孩子
else p—>rchild=s //被插结点*s为右孩子
return TRUE;
}
else
return FALSE; //树中已有关键字相同的结点,不再插入
}// Insert BST
void InsertBST(BSTree *Tptr,KeyType key)
{
//若二叉排序树 *Tptr中没有关键字为key,则插入,否则直接返回
BSTNode *f,*p=*TPtr; //p的初值指向根结点
while(p){ //查找插入位置
if(p->key==key) return;//树中已有key,无须插入
f=p; //f保存当前查找的结点
p=(key<p->key)?p->lchild:p->rchild;
//若key<p->key,则在左子树中查找,否则在右子树中查找
} //endwhile
//f为插入的结点
p=(BSTNode *)malloc(sizeof(BSTNode));
p->key=key; p->lchild=p->rchild=NULL; //生成新结点
if(*TPtr==NULL) //原树为空
*Tptr=p; //新插入的结点为新的根
else //原树非空时将新结点关p作为关f的左孩子或右孩子插入
if(key<f->key)
f->lchild=p;
else f->rchild=p;
} //InsertBST4、删除算法
①删除操作的一般步骤
(1) 进行查找
查找时,令p指向当前访问到的结点,parent指向其双亲(其初值为NULL)。若树中找不到被删结点则返回,否则被删结点是*p。
(2) 删去*p。
删*p时,应将*p的子树(若有)仍连接在树上且保持BST性质不变。按*p的孩子数目分三种情况进行处理。
②删除*p结点的三种情况(1)*p是叶子(即它的孩子数为0)
无须连接*p的子树,只需将*p的双亲*parent中指向*p的指针域置空即可。
(2)*p只有一个孩子*child
只需将*child和*p的双亲直接连接后,即可删去*p。
注意: *p既可能是*parent的左孩子也可能是其右孩子,而*child可能是*p的左孩子或右孩子,故共有4种状态。
(3)*p有两个孩子
先令q=p,将被删结点的地址保存在q中;然后找*q的中序后继*p,并在查找过程中仍用parent记住*p的双亲位置。*q的中序后继*p一定是*q的右子树中最左下的结点,它无左子树。因此,可以将删去*q的操作转换为删去的*p的操作,即在释放结点*p之前将其数据复制到*q中,就相当于删去了*q。
③二叉排序树删除算法
分析:
上述三种情况都能统一到情况(2),算法中只需针对情况(2)处理即可。
注意边界条件:若parent为空,被删结点*p是根,故删去*p后,应将child置为根。
算法:删除关键字为key的结点
void DelBSTNode(BSTree *Tptr,KeyType key)
{
//在二叉排序树*Tptr中删去关键字为key的结点
BSTNode *parent=NUll,*p=*Tptr,*q,*child;
while(p)
{
//从根开始查找关键字为key的待删结点
if(p->key==key) break;//已找到,跳出查找循环
parent=p; //parent指向*p的双亲
p=(key<p->key)?p->lchild:p->rchild; //在关p的左或右子树中继续找
}
//注意:也可以使用基于BOOL SearchBST(BiTree *T,KeyType key,BiTree *f,BiTree &p)的查找算法
//结果是 parent 记录了要删除结点的父结点,p指向要删除的结点
if(!p) return; //找不到被删结点则返回
q=p; //q记住被删结点*p
if(q->lchild && q->rchild) //*q的两个孩子均非空,故找*q的中序后继*p
for(parent=q,p=q->rchild; p->lchild; parent=p,p=p=->lchild);
//现在情况(3)已被转换为情况(2),而情况(1)相当于是情况(2)中child=NULL的状况
child=(p->lchild)?p->lchild:p->rchild;//若是情况(2),则child非空;否则child为空
if(!parent) //*p的双亲为空,说明*p为根,删*p后应修改根指针
*Tptr=child; //若是情况(1),则删去*p后,树为空;否则child变为根
else{ //*p不是根,将*p的孩子和*p的双亲进行连接,*p从树上被摘下
if(p==parent->lchild) //*p是双亲的左孩子
parent->lchild=child; //*child作为*parent的左孩子
else parent->rchild=child; //*child作为 parent的右孩子
if(p!=q) //是情况(3),需将*p的数据复制到*q
q->key=p->key; //若还有其它数据域亦需复制
} //endif
free(p); /释放*p占用的空间
} //DelBSTNode
给出三种情况的不同算法
第一种:
btree * DelNode(btree *p)
{
if (p->lchild)
{
btree *r = p->lchild; //r指向其左子树;
while(r->rchild != NULL)//搜索左子树的最右边的叶子结点r
{
r = r->rchild;
}
r->rchild = p->rchild;
btree *q = p->lchild; //q指向其左子树;
free(p);
return q;
}
else
{
btree *q = p->rchild; //q指向其右子树;
free(p);
return q;
}
}
第二种:
btree * DelNode(btree *p)
{
if (p->lchild)
{
btree *r = p->lchild; //r指向其左子树;
btree *prer = p->lchild; //prer指向其左子树;
while(r->rchild != NULL)//搜索左子树的最右边的叶子结点r
{
prer = r;
r = r->rchild;
}
if(prer != r)//若r不是p的左孩子,把r的左孩子作为r的父亲的右孩子
{
prer->rchild = r->lchild;
r->lchild = p->lchild; //被删结点p的左子树作为r的左子树
}
r->rchild = p->rchild; //被删结点p的右子树作为r的右子树
free(p);
return r;
}
else
{
btree *q = p->rchild; //q指向其右子树;
free(p);
return q;
}
}
posted @
2011-10-03 10:07 Yu_ 阅读(651) |
评论 (0) |
编辑 收藏哈夫曼树定义为:给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman tree)。
1、那么什么是权值?什么是路径长度?什么是带权路径长度呢?
权值:哈夫曼树的权值是自己定义的,他的物理意义表示数据出现的次数、频率。可以用树的每个结点数据域data存放一个特定的数表示它的值。
路径长度:在一棵树中,从一个结点往下可以达到的孩子或子孙结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。 树中所有叶子节点的带权路径长度之和,WPL=sigma(w*l)
2、哈夫曼树的构造过程。(结合图例)
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树
3、哈夫曼树的应用:哈夫曼编码(前缀编码)
哈夫曼编码
在数据通信中,通常需要把要传送的文字转换为由二进制字符0和1组成的二进制串,这个过程被称之为编码(Encoding)。例如,假设要传送的电文为DCBBADD,电文中只有A、B、C、D四种字符,若这四个字符采用表(a)所示的编码方案,则电文的代码为11100101001111,代码总长度为14。若采用表(b) 所示的编码方案,则电文的代码为0110101011100,代码总长度为13。

字符集的不同编码方案
哈夫曼树可用于构造总长度最短的编码方案。具体构造方法如下:
设需要编码的字符集为{d1,d2,…,dn},各个字符在电文中出现的次数或频率集合为{w1,w2,…,wn}。以d1,d2,…,dn作为叶子结点,以w1,w2,…,wn作为相应叶子结点的权值来构造一棵哈夫曼树。规定哈夫曼树中的左分支代表0,右分支代表1,则从根结点到叶子结点所经过的路径分支组成的0和1的序列便为该结点对应字符的编码就是哈夫曼编码(Huffman Encoding)。
在建立不等长编码中,必须使任何一个字符的编码都不是另一个编码的前缀,这样才能保证译码的唯一性。例如,若字符A的编码是00,字符B的编码是001,那么字符A的编码就成了字符B的编码的后缀。这样,对于代码串001001,在译码时就无法判定是将前两位码00译成字符A还是将前三位码001译成B。这样的编码被称之为具有二义性的编码,二义性编码是不唯一的。而在哈夫曼树中,每个字符结点都是叶子结点,它们不可能在根结点到其它字符结点的路径上,所以一个字符的哈夫曼编码不可能是另一个字符的哈夫曼编码的前缀,从而保证了译码的非二义性。
下图就是电文DCBBADD的哈夫曼树:

4、哈夫曼树的实现
由哈夫曼树的构造算法可知,用一个数组存放原来的n个叶子结点和构造过程中临时生成的结点,数组的大小为2n-1。所以,哈夫曼树类HuffmanTree中有两个成员字段:data数组用于存放结点,leafNum表示哈夫曼树叶子结点的数目。结点有四个域,一个域weight,用于存放该结点的权值;一个域lChild,用于存放该结点的左孩子结点在数组中的序号;一个域rChild,用于存放该结点的右孩子结点在数组中的序号;一个域parent,用于判定该结点是否已加入哈夫曼树中。
哈夫曼树结点的结构为:| 数据 | weight | lChild | rChild | parent |
public class Node
{
char c; //存储的数据,为一个字符
private double weight; //结点权值
private int lChild; //左孩子结点
private int rChild; //右孩子结点
private int parent; //父结点
//结点权值属性
public double Weight
{
get
{
return weight;
}
set
{
weight = value;
}
}
//左孩子结点属性
public int LChild
{
get
{
return lChild;
}
set
{
lChild = value;
}
}
//右孩子结点属性
public int RChild
{
get
{
return rChild;
}
set
{
rChild = value;
}
}
//父结点属性
public int Parent
{
get
{
return parent;
}
set
{
parent = value;
}
}
//构造器
public Node()
{
weight = 0;
lChild = -1;
rChild = -1;
parent = -1;
}
//构造器
public Node(double weitht)
{
this.weight = weitht;
lChild = -1;
rChild = -1;
parent = -1;
}
//构造器
public Node(int w, int lc, int rc, int p)
{
weight = w;
lChild = lc;
rChild = rc;
parent = p;
}
}
public class HuffmanTree
{
private Node[] data; //结点数组
private int leafNum; //叶子结点数目
//索引器
public Node this[int index]
{
get
{
return data[index];
}
set
{
data[index] = value;
}
}
//叶子结点数目属性
public int LeafNum
{
get
{
return leafNum;
}
set
{
leafNum = value;
}
}
//构造器
public HuffmanTree(int n)
{
data = new Node[2 * n - 1];
leafNum = n;
}
//创建哈夫曼树
public void Create(Node[] datain)
{
double minL, minR;
minL = minR = double.MaxValue;
int lchild, rchild;
lchild = rchild = -1;
int length = data.Length;
//初始化哈夫曼树
for (int i = 0; i < length; i++)
data[i] = new Node();
for (int i = 0; i < datain.Length; i++)
data[i] = datain[i];
//处理n个叶子结点,建立哈夫曼树
for (int i = leafNum; i < length; i++)
{
//在全部结点中找权值最小的两个结点
for (int j = 0; j < i; j++)
{
if (data[j].Parent == -1)
{
if (data[j].Weight < minL)
{
minR = minL;
minL = data[j].Weight;
rchild = lchild;
lchild = j;
}
else if (data[j].Weight < minR)
{
minR = data[j].Weight;
rchild = j;
}
}
}
data[lchild].Parent = data[rchild].Parent = i;
data[i].Weight = minL + minR;
data[i].LChild = lchild;
data[i].RChild = rchild;
}
}
}
class Program
{
static void Main(string[] args)
{
HuffmanTree tree = new HuffmanTree(5);
Node[] nodes = new Node[] { new Node(1), new Node(2), new Node(2.5d), new Node(3), new Node(2.6d) };
tree.Create(nodes);
Console.ReadLine();
}
}
/////////////////////////////节选自网络上的资料、
posted @
2011-10-02 17:04 Yu_ 阅读(3068) |
评论 (1) |
编辑 收藏
优先队列是不同于先进先出队列的另一种队列。每次从队列中取出的是具有
最高优先权的元素。每个元素都有一个优先权或值
/////用堆实现优先队列
1、把优先队列中的元素按优先级大小组织成堆,堆顶元素具有最大优先级。
2、优先队列的插入与删除可以用堆的插入与删除实现。
3、优先队列在定义为priority_queue ,在STL中#include<queue> 中实现、
priority_queue<int, vector<int>, greater<int> >qi2;
其中
第二个参数为容器类型。
第三个参数为比较函数。
posted @
2011-10-02 11:22 Yu_ 阅读(292) |
评论 (0) |
编辑 收藏
估计还要问问:什么是堆,什么是堆排序?堆与计算机分配内存的堆相同吗?
很多资料给出:堆的定义是
(1)、n个关键字序列(Kl,K2,…,Kn)称为(Heap),当且仅当该序列满足如下性质(简称为堆性质):
ki≤K2i且ki≤K2i+1 或 Ki≥K2i且ki≥K2i+1 (1≤i≤ n) //ki相当于二叉树的非叶结点,K2i则是左孩子,k2i+1是右孩子
(2)若将此序列所存储的向量R[1..n]看做是一棵
完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:
树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
(3)、根结点(亦称为堆顶)的关键字是堆里所有结点关键字中
最小者的堆称为
小根堆,又称最小堆。根结点(亦称为堆顶)的关键字是堆里所有结点关键字中
最大者,称为大根堆,又称
最大堆。
(4)、堆中任一子树亦是堆。
(5)、堆可以视为一棵完全的二叉树,完全二叉树的一个“优秀”的性质是,除了最底层之外,每一层都是满的,这使得堆可以利用数组来表示(普通的一般的二叉树通常用链表作为基本容器表示),每一个结点对应数组中的一个元素。那么堆排序呢?
堆排序其实就是将一组无序的序列变成堆的过程、下面我们一起看看堆排序的算法。
2、堆排序
以最大堆为例,步骤为:
① 先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区
② 再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R[n]交换,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key
③由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
……
直到无序区只有一个元素为止。
将一个无序的序列建成堆的过程实际上是一个反复筛选的过程。若将此序列看作是一棵完全二叉树,则最后一个非终端结点是[n/2](不大于n/2的整数),因此筛选过程只需从[n/2]开始。要建成一个大顶堆,即先选择一个值最大的元素并与序列中的最后一个元素交换,然后对序列前n-1元素进行筛选,从新调整为一个大顶堆,直到结束。
算法描述如下:
typedef int[] Elem;//采用顺序存储表示完全二叉树
void HeapAdjust(Elem &e,int s,int m)
{//e中s...m的元素除e[s]之外已经满足堆的定义(e[i] <=e[2*i]&&e[i] <=e[2*i+1]
//或e[i]> =e[2*i]&&e[i]> =e[2*i+1]),调整e[s]使的e[s...m]成为一个大顶堆。
selem=e[s];
for(i=2*s;i <=m;i*=2)//沿着值较大的元素(结点)向下筛选
{
if(i <m && e[i] <e[i+1])++i;//i为值较大的元素下标
if(selem> =e[i])break;
e[s]=e[i];
s=i;
}
e[s]=selem;
}
void HeapSort(Elem &e)
{//对顺序表排序
for(i=e.length/2;i> 0;--i)
HeapAdjust(e,i,e.length);
for(i=e.length;i> 1;--i)
{
temp=e[1]; //将堆中的最后一个元素与第一个元素交换
e[1]=e[i];
e[i]=temp;
HeapAdjust(H,1,i-1);//调整1..i-1的元素成为大顶堆
}
}
/////////////////////////////////////////////////////////////
使用堆排序注意的问题:::
1、序列是从1开始的。,注意定义,R[1..n],故要空出R[0]。
2、堆排序算法分为两部分:建立大顶堆和排序。
3、排序的最坏时间复杂度为
O(nlogn)。堆序的平均性能较接近于最坏性能。
4、由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
5、 堆排序是就地排序,辅助空间为O(1), 它是
不稳定的排序方法。
问题:当序列空间为R[0,1....n];时,该怎么去使用堆排序呢?元素后移一位,这明显不是一个好方法。
posted @
2011-10-01 16:55 Yu_ 阅读(1200) |
评论 (0) |
编辑 收藏数据对齐,是指数据所在的内存地址必须是该数据长度的整数倍。比如DWORD数据的内存其实地址能被4除尽,WORD数据的内存地址能被2除尽。x86 CPU能直接访问对齐的数据,当它试图访问一个未对齐的数据时,会在内部进行一系列的调整,这些调整对于程序来说是透明的,但是会降低运行速度,所以编译器在编译程序时会尽量保持数据对齐。
C/C++编译器在内存分配时也保持了数据对齐,请看下例:
struct{
short a1;
short a2;
short a3;
}A;
struct{
long a1;
short a2;
}B;
cout<<sizeof(A)<<","<<sizeof(B)<<endl;//其它代码略去
结构体A和B的大小分别是多少呢?
默认情况下,为了方便对结构体元素的访问和管理,当结构体内的元素都小于处理器长度的时候,便以结构体里面最长的数据为对齐单位,也就是说,结构体的长度一定是最长数据长度的整数倍。
如果结构体内部存在长度大于处理器位数时就以处理器位数为对齐单位。
结构体内类型相同的连续元素将存在连续的空间内,和数组一样。
上例中:
A有3个short类型变量,各自占2字节,总和为6,6是2的倍数,所以sizeof(A)=6;
B有一个long类型变量,占4字节,一个short类型的变量,占2字节,总和6不是最大长度4的倍数,所以要补空字节以增至8实现对齐,所以sizeof(8)=8。
在C++类的设计中遵循同样的道理,但需注意,空类需要占1个字节,静态变量(static)由于在栈中分配,不在sizeof计算范围内。
posted @
2011-10-01 10:13 Yu_ 阅读(600) |
评论 (0) |
编辑 收藏多态性,这个面向对象编程领域的核心概念,本身的内容博大精深,要以一文说清楚实在是不太可能。加之作者本人也还在不断学习中,水平有限。因此本文只能描一下多态的轮廓,使读者能够了解个大概。如果有描的不准的地方,欢迎指出,或与作者探讨(作者Email:nicrosoft@sunistudio.com)
首先,什么是多态(Polymorphisn)?按字面的意思就是“多种形状”。我手头的书上没有找到一个多态的理论性的概念的描述。暂且引用一下Charlie Calverts的对多态的描述吧——多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作(摘自“Delphi4 编程技术内幕”)。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。多态性在Object Pascal和C++中都是通过虚函数(Virtual Function)实现的。
好,接着是“虚函数”(或者是“虚方法”)。虚函数就是允许被其子类重新定义的成员函数。而子类重新定义父类虚函数的做法,称为“覆盖”(override),或者称为“重写”。
这里有一个初学者经常混淆的概念。覆盖(override)和重载(overload)。上面说了,覆盖是指子类重新定义父类的虚函数的做法。而重载,是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。其实,重载的概念并不属于“面向对象编程”,重载的实现是:编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数(至少对于编译器来说是这样的)。如,有两个同名函数:function func(p:integer):integer;和function func(p:string):integer;。那么编译器做过修饰后的函数名称可能是这样的:int_func、str_func。对于这两个函数的调用,在编译器间就已经确定了,是静态的(记住:是静态)。也就是说,它们的地址在编译期就绑定了(早绑定),因此,重载和多态无关!真正和多态相关的是“覆盖”。当子类重新定义了父类的虚函数后,父类指针根据赋给它的不同的子类指针,动态(记住:是动态!)的调用属于子类的该函数,这样的函数调用在编译期间是无法确定的(调用的子类的虚函数的地址无法给出)。因此,这样的函数地址是在运行期绑定的(晚邦定)。结论就是:重载只是一种语言特性,与多态无关,与面向对象也无关!
引用一句Bruce Eckel的话:“不要犯傻,如果它不是晚邦定,它就不是多态。”
那么,多态的作用是什么呢?我们知道,封装可以隐藏实现细节,使得代码模块化;继承可以扩展已存在的代码模块(类);它们的目的都是为了——代码重用。而多态则是为了实现另一个目的——接口重用!而且现实往往是,要有效重用代码很难,而真正最具有价值的重用是接口重用,因为“接口是公司最有价值的资源。设计接口比用一堆类来实现这个接口更费时间。而且接口需要耗费更昂贵的人力的时间。”
其实,继承的为重用代码而存在的理由已经越来越薄弱,因为“组合”可以很好的取代继承的扩展现有代码的功能,而且“组合”的表现更好(至少可以防止“类爆炸”)。因此笔者个人认为,继承的存在很大程度上是作为“多态”的基础而非扩展现有代码的方式了。
什么是接口重用?我们举一个简单的例子,假设我们有一个描述飞机的基类(Object Pascal语言描述,下同):
type
plane = class
public
procedure fly(); virtual; abstract; //起飞纯虚函数
procedure land(); virtual; abstract; //着陆纯虚函数
function modal() : string; virtual; abstract; //查寻型号纯虚函数
end;
然后,我们从plane派生出两个子类,直升机(copter)和喷气式飞机(jet):
copter = class(plane)
private
fModal : String;
public
constructor Create();
destructor Destroy(); override;
procedure fly(); override;
procedure land(); override;
function modal() : string; override;
end;
jet = class(plane)
private
fModal : String;
public
constructor Create();
destructor Destroy(); override;
procedure fly(); override;
procedure land(); override;
function modal() : string; override;
end;
现在,我们要完成一个飞机控制系统,有一个全局的函数 plane_fly,它负责让传递给它的飞机起飞,那么,只需要这样:
procedure plane_fly(const pplane : plane);
begin
pplane.fly();
end;
就可以让所有传给它的飞机(plane的子类对象)正常起飞!不管是直升机还是喷气机,甚至是现在还不存在的,以后会增加的飞碟。因为,每个子类都已经定义了自己的起飞方式。
可以看到 plane_fly函数接受参数的是 plane类对象引用,而实际传递给它的都是 plane的子类对象,现在回想一下开头所描述的“多态”:多态性是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。
很显然,parent = child; 就是多态的实质!因为直升机“是一种”飞机,喷气机也“是一种”飞机,因此,所有对飞机的操作,都可以对它们操作,此时,飞机类就作为一种接口。
多态的本质就是将子类类型的指针赋值给父类类型的指针(在OP中是引用),只要这样的赋值发生了,多态也就产生了,因为实行了“向上映射”。
多态性
是允许将父对象设置成为和一个或多个它的子对象相等的技术,比如Parent:=Child; 多态性使得能够利用同一类(基类)类型的指针来引用不同类的对象,以及根据所引用对象的不同,以不同的方式执行相同的操作.
c++中多态更容易理解的概念为
允许父类指针或名称来引用子类对象,或对象方法,而实际调用的方法为对象的类类型方法。
作用
把不同的子类对象都当作父类来看,可以屏蔽不同子类对象之间的差异,写出通用的代码,做出通用的编程,以适应需求的不断变化。
赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。也就是说,父亲的行为像儿子,而不是儿子的行为像父亲。
举个例子:从一个基类中派生,响应一个虚命令,产生不同的结果。
比如从某个基类继承出多个对象,其基类有一个虚方法Tdoit,然后其子类也有这个方法,但行为不同,然后这些子对象中的任何一个可以赋给其基类的对象,这样其基类的对象就可以执行不同的操作了。实际上你是在通过其基类来访问其子对象的,你要做的就是一个赋值操作。
使用继承性的结果就是可以创建一个类的家族,在认识这个类的家族时,就是把导出类的对象当作基类的对象,这种认识又叫作upcasting。这样认识的重要性在于:我们可以只针对基类写出一段程序,但它可以适应于这个类的家族,因为编译器会自动就找出合适的对象来执行操作。这种现象又称为多态性。而实现多态性的手段又叫称动态绑定(dynamic binding)。
简单的说,建立一个父类的对象,它的内容可以是这个父类的,也可以是它的子类的,当子类拥有和父类同样的函数,当使用这个对象调用这个函数的时候,定义这个对象的类(也就是父类)里的同名函数将被调用,当在父类里的这个函数前加virtual关键字,那么子类的同名函数将被调用。
posted @
2011-09-30 23:17 Yu_ 阅读(419) |
评论 (0) |
编辑 收藏1、什么是虚函数?
①、虚函数必须是基类的非
静态成员函数
②、其访问权限可以是protected或public。不能是private ,因为子类继承时,子类不能访问。
③、在编译时是动态联编的::编译程序在编译阶段并不能确切知道将要调用的函数,只有在
程序执行时才能确定将要调用的函数,为此要确切知道该调用的函数,要求联编工作要在程序运行时进行,这种在程序运行时进行联编工作被称为动态联编。
动态联编规定,只能通过指向基类的指针或基类对象的引用来调用虚函数2、定义形式。
virtual 函数返回值类型 虚函数名(形参表)
{ 函数体 }
纯虚函数:virtual 函数名=0
3、虚函数内部机制。
①、每个实例对象里有自己的指针。
②、虚函数(Virtual Function)是通过一张虚函数表(Virtual Table)来实现的。
③、我们通过对象实例的地址得到这张虚函数表,然后就可以遍历其中函数指针,并调用相应的函数。
例子:
假设我们有这样的一个类:
class Base {
public:
virtual void f() { cout << "Base::f" << endl; }
virtual void g() { cout << "Base::g" << endl; }
virtual void h() { cout << "Base::h" << endl; }
};
按照上面的说法,我们可以通过Base的实例来得到虚函数表。 下面是实际例程:
typedef void(*Fun)(void);
Base b;
Fun pFun = NULL;
cout << "虚函数表地址:" << (int*)(&b) << endl;
cout << "虚函数表 — 第一个函数地址:" << (int*)*(int*)(&b) << endl;
/*这里的一点争议的个人看法*/
原文认为(int*)(&b)是虚表的地址,而很多网友都说,(包括我也认为):(int *)*(int*)(&b)才是虚表地址
而(int*)*((int*)*(int*)(&b)); 才是虚表第一个虚函数的地址。
其实看后面的调用pFun = (Fun)*((int*)*(int*)(&b)); 就可以看出,*((int*)*(int*)(&b));转成函数指针给pFun,然后正确的调用到了虚函数virtual void f()。
// Invoke the first virtual function
pFun = (Fun)*((int*)*(int*)(&b));
pFun();
实际运行经果如下:(Windows XP+VS2003, Linux 2.6.22 + GCC 4.1.3)
虚函数表地址:0012FED4
虚函数表 — 第一个函数地址:0044F148
Base::f
通过这个示例,我们可以看到,我们可以通过强行把&b转成int *,取得虚函数表的地址,然后,再次取址就可以得到第一个虚函数的地址了,也就是Base::f(),这在上面的程序中得到了验证(把int* 强制转成了函数指针)。通过这个示例,我们就可以知道如果要调用Base::g()和Base::h(),其代码如下:
(Fun)*((int*)*(int*)(&b)+0); // Base::f()
(Fun)*((int*)*(int*)(&b)+1); // Base::g()
(Fun)*((int*)*(int*)(&b)+2); // Base::h()
这个时候你应该懂了吧。什么?还是有点晕。也是,这样的代码看着太乱了。没问题,让我画个图解释一下。如下所示:
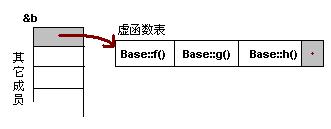
注意:在上面这个图中,我在虚函数表的最后多加了一个结点,这是虚函数表的结束结点,就像字符串的结束符“\0”一样,其标志了虚函数表的结束。这个结束标志的值在不同的编译器下是不同的。在WinXP+VS2003下,这个值是NULL。而在Ubuntu 7.10 + Linux 2.6.22 + GCC 4.1.3下,这个值是如果1,表示还有下一个虚函数表,如果值是0,表示是最后一个虚函数表。
下面,我将分别说明“无覆盖”和“有覆盖”时的虚函数表的样子。没有覆盖父类的虚函数是毫无意义的。我之所以要讲述没有覆盖的情况,主要目的是为了给一个对比。在比较之下,我们可以更加清楚地知道其内部的具体实现。
一般继承(无虚函数覆盖)
下面,再让我们来看看继承时的虚函数表是什么样的。假设有如下所示的一个继承关系:
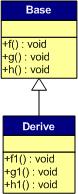
请注意,在这个继承关系中,子类没有重载任何父类的函数。那么,在派生类的实例中,其虚函数表如下所示:
对于实例:Derive d; 的虚函数表如下:
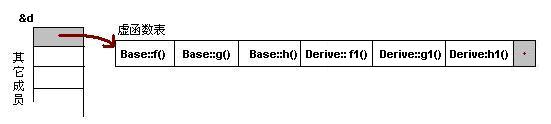
我们可以看到下面几点:
1)虚函数按照其声明顺序放于表中。
2)父类的虚函数在子类的虚函数前面。
我相信聪明的你一定可以参考前面的那个程序,来编写一段程序来验证。
一般继承(有虚函数覆盖)
覆盖父类的虚函数是很显然的事情,不然,虚函数就变得毫无意义。下面,我们来看一下,如果子类中有虚函数重载了父类的虚函数,会是一个什么样子?假设,我们有下面这样的一个继承关系。
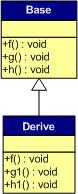
为了让大家看到被继承过后的效果,在这个类的设计中,我只覆盖了父类的一个函数:f()。那么,对于派生类的实例,其虚函数表会是下面的一个样子:
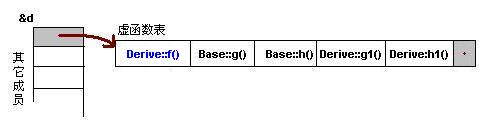
我们从表中可以看到下面几点,
1)覆盖的f()函数被放到了虚表中原来父类虚函数的位置。
2)没有被覆盖的函数依旧。
这样,我们就可以看到对于下面这样的程序,
Base *b = new Derive();
b->f();
由b所指的内存中的虚函数表的f()的位置已经被Derive::f()函数地址所取代,于是在实际调用发生时,是Derive::f()被调用了。这就实现了多态。
多重继承(无虚函数覆盖)
下面,再让我们来看看多重继承中的情况,假设有下面这样一个类的继承关系。注意:子类并没有覆盖父类的函数。
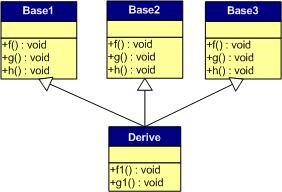
对于子类实例中的虚函数表,是下面这个样子:
 我们可以看到:
我们可以看到:
1) 每个父类都有自己的虚表。
2) 子类的成员函数被放到了第一个父类的表中。(所谓的第一个父类是按照声明顺序来判断的)
这样做就是为了解决不同的父类类型的指针指向同一个子类实例,而能够调用到实际的函数。
多重继承(有虚函数覆盖)
下面我们再来看看,如果发生虚函数覆盖的情况。
下图中,我们在子类中覆盖了父类的f()函数:
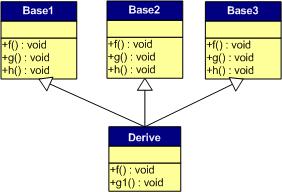
下面是对于子类实例中的虚函数表的图:

我们可以看见,三个父类虚函数表中的f()的位置被替换成了子类的函数指针。这样,我们就可以任一静态类型的父类来指向子类,并调用子类的f()了。如:
Derive d;
Base1 *b1 = &d;
Base2 *b2 = &d;
Base3 *b3 = &d;
b1->f(); //Derive::f()
b2->f(); //Derive::f()
b3->f(); //Derive::f()
b1->g(); //Base1::g()
b2->g(); //Base2::g()
b3->g(); //Base3::g()
安全性
每次写C++的文章,总免不了要批判一下C++。这篇文章也不例外。通过上面的讲述,相信我们对虚函数表有一个比较细致的了解了。水可载舟,亦可覆舟。下面,让我们来看看我们可以用虚函数表来干点什么坏事吧。
一、通过父类型的指针访问子类自己的虚函数
我们知道,子类没有重载父类的虚函数是一件毫无意义的事情。因为多态也是要基于函数重载的。虽然在上面的图中我们可以看到Base1的虚表中有Derive的虚函数,但我们根本不可能使用下面的语句来调用子类的自有虚函数:
Base1 *b1 = new Derive();
b1->f1(); //编译出错
任何妄图使用父类指针想调用子类中的未覆盖父类的成员函数的行为都会被编译器视为非法,所以,这样的程序根本无法编译通过。但在运行时,我们可以通过指针的方式访问虚函数表来达到违反C++语义的行为。(关于这方面的尝试,通过阅读后面附录的代码,相信你可以做到这一点)
二、访问non-public的虚函数
另外,如果父类的虚函数是private或是protected的,但这些非public的虚函数同样会存在于虚函数表中,所以,我们同样可以使用访问虚函数表的方式来访问这些non-public的虚函数,这是很容易做到的。
如:
class Base {
private:
virtual void f() { cout << "Base::f" << endl; }
};
class Derive : public Base{
};
typedef void(*Fun)(void);
void main() {
Derive d;
Fun pFun = (Fun)*((int*)*(int*)(&d)+0);
pFun();
}
结束语
C++这门语言是一门Magic的语言,对于程序员来说,我们似乎永远摸不清楚这门语言背着我们在干了什么。需要熟悉这门语言,我们就必需要了解C++里面的那些东西,需要去了解C++中那些危险的东西。不然,这是一种搬起石头砸自己脚的编程语言。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/hairetz/archive/2009/04/29/4137000.aspx
posted @
2011-09-30 21:58 Yu_ 阅读(413) |
评论 (0) |
编辑 收藏//转自网友博客、
1、 派生类对象与普通类对象的相同之处在于,可以直接访问该类的所有对象(包括this指针指向的对象和其他对象)的protected和private成员(包括其基类成员)。不同之处在于派生类对象只能访问其对应基类对象的protected成员(有隐式this指针传递),而不能访问其基类的其他对象的protect成员,而普通类对象则也可以直接访问该类所有对象的成员。
2、 在C++中,基类指针只能访问在该基类中被声明(或继承)的数据成员和成员函数(包括虚拟成员函数),而与它可能指向的实际对象无关,所以如果需要用基类指针来访问一个没有在该基类中声明但是又在其派生类中定义了的成员,则需要执行dynamic_cast来完成从基类指针到派生类指针的安全向下转换。把一个成员声明为虚拟的,只推延了“在程序执行期间根据指针指向的实际类类型,对于要调用实例的解析过程”
3、 关于基类,派生类的相关补充:
1、 派生表中指定的类必须先被定义好,方可被指定为基类。
2、 派生类的前向声明不能包括其派生表,而只需要类名即可。
3、 缺省的继承是private。
4、 继承而来的派生类的虚拟函数一般加上virtual较好,也可以省略。但基类中一定要声明为virtual。
5、 对于基类的静态成员,所有派生类对象都引用基类创建的这个相同,单一,共享的静态成员,而不是创建该派生类的另一个独立的静态成员。
6、 友员关系不会被继承,派生类没有成为“向它的基类授权友谊的类”的友员。
4、 继承机制下,派生类对象的构造函数(析构函数)调用顺序为:
1、 基类(子对象的)构造函数,若有多个基类,则以类派生表中出现的顺序为序。
2、 成员类对象的构造函数,若有多个成员类对象,则以它们在类定义中被声明的顺序为序。
3、派生类自己的构造函数。
4、派生类对象的析构函数的调用顺序与它的构造函数相反。继承机制下,析构函数的行为如下:派生类的析构函数先被调用,再静态调用基类的析构函数(从直接基类开始)。注意一般基类的析构函数不应该是protected,因为虚拟函数承接了“调用者所属类类型的访问级别”。作为一般规则,我们建议将类层次结构的根基类(声明了一个或多个虚拟函数)的析构函数声明为虚拟的。
5、 关于继承机制下基类构造函数(析构函数)相关的几点说明:
1、 作为一般规则,派生类构造函数应不能直接向一个基类的数据成员赋值,而是要把值传递给适当的基类构造函数来达到初始化赋值的目的。(一般是通过成员初始化表的方式)
2、 若基类不用于创建对象,则最好将其构造函数放在protect区,只允许其派生类对象调用;若基类只允许创建某一个特定的派生类类型的对象,则应该将基类的构造函数放在private区,并将此特定的派生类声明为该基类的友元来达到目的。
3、 派生类并不继承基类的构造函数,每个派生类都必须提供自己的构造函数集,派生类的构造函数只能合法的调用其直接基类的构造函数。(注意这里虚拟继承提供了一个特例:虚拟基类的初始化变成了最终派生类的责任)。
6、 关于虚拟函数的相关
1、 必须使用指针或者引用来支持虚拟函数机制(面向对象程序设计),基类对象由于其静态编译,故不会保留派生类的类型身份。
2、 第一次引入虚拟函数的基类时,必须在类体中将虚拟函数声明为virtual,但若在该基类外部定义该虚拟函数时不能指定virtual。该基类的派生类中该虚拟函数virtual可加可不加,但从多重继承考虑,最好加上。
3、 派生类改写的基类虚拟函数,其原型必须与基类虚拟函数完全匹配(包括const和返回值),但返回值有个特例:派生类实例的返回值可以是基类实例返回类型的公有派生类类型。
4、 纯虚拟函数(声明后紧跟=0,函数定义可写可不写)只是提供了一个可被其派生类改写的接口,其本身不能通过虚拟机制被调用,但可以静态调用(写了函数定义的虚基类的纯虚拟函数)。一般来说,虚拟函数的静态调用的目的是为了效率(避免动态绑定)。
5、 包含(或继承)了一个或多个纯虚拟函数的类被编译器识别为抽象基类,抽象基类不能用来创建独立的类对象,只能作为子对象出现在后续的派生类中。
6、通过基类指针来调用的虚拟函数的真正实例是在运行时刻确定的。但传给虚拟函数的缺省实参是在编译时刻根据被调用函数的对象的类型决定的(也即是若通过基类指针或引用调用派生类实例的虚拟函数,则传递给它的缺省实参是由基类指定的)。
7、 虚拟继承和多继承相关:
1、 虚拟继承主要实为了解决继承了多个基类实例,但是只需要一份单独的共享实例的情况。
2、 非虚拟派生中,派生类只能显式的初始化其直接基类(即派生类只能调用其直接基类的构造函数),而在虚拟派生中,虚拟基类的初始化变成了最终派生类的责任,这个最终派生类是由每个特定的类对象声明来决定的,其非虚拟基类的初始化同非虚拟派生一样,只能由其直接派生类完成。(即中间派生类的对于虚拟基类构造函数的调用被抑制)。
3、 虚拟继承下构造函数的调用顺序按直接基类的声明顺序,对每个继承子树作深度优先遍历。第一步按此顺序调用所有虚拟基类的构造函数;第二步按此顺序调用非虚拟基类的构造函数。析构函数的调用顺序与构造函数相反。
4、 虚拟基类成员的可视性,对于虚拟基类成员的继承比该成员后来重新定义的实例权值(优先级)小,故特化的派生类实例名覆盖了共享的虚拟基类的实例名。而在非虚拟派生下的解析引用过程,每个继承得到的实例都有相同的权值(优先级)。
5、 继承下派生类的类域被嵌套在基类类域中,若一个名字在派生类域中没有被解析出来,则编译器在外围基类域中查找该名字定义。在多继承下,名字解析查找过程为先是在本类类域中查找,再对继承子树中的所有基类同时查找,每个继承得到的实例都有相同的权值(优先级)。若在两个或多个基类子树中都找到了该名字,则对其的使用是二义的。
posted @
2011-09-30 16:18 Yu_ 阅读(462) |
评论 (0) |
编辑 收藏
摘要: 一、 什么是设计模式。
毫无疑问,设计模式是前人总结下来,一些设计经验经过被反复使用、并为多数人知晓、经过分类编目。模式是一种问题的解决思路,它已经适用于一个实践环境,并且可以适用于其他坏境。
最终由GoF总结出23种设计模式。
二、 为什么要使用。
根本原因是为了代码复...
阅读全文
posted @
2011-09-29 08:12 Yu_ 阅读(413) |
评论 (0) |
编辑 收藏
摘要: 1、什么是Bridge模式?这个问题我用一言两语实在无法概括其根本。不过我是这样分析的:①、对象这个概念可以认为是由“属性”和“行为”两个部分组成的。属性我们可以认为是一种静止的,是一种抽象;一般情况下,行为是包含在一个对象中,但是,在有的情况下,我们需要将这些行为也进行归类,形成一个总的行为接口,这就是桥模式的用处。②、Br...
阅读全文
posted @
2011-09-27 18:42 Yu_ 阅读(399) |
评论 (0) |
编辑 收藏