Posted on 2020-03-10 16:22
杜仲当归 阅读(291)
评论(0) 编辑 收藏 引用

接上文,轨迹异常挖掘一般的实现模式如下:
数据预处理 -- 提取数据特征 -- 异常检测 -- 数据可视化(可选)-- 得到结果
其中,数据预处理部分将接入的GPS数据根据不同的异常检测方案进行处理。例如网格化GPS数据,去掉不合理的轨迹点,对轨迹进行压缩。在得到轨迹数据集(MOD, Moving Object Database)后,将需要使用的数据特征提取出来,然后使用异常检测算法检查异常轨迹。最终将异常轨迹用地图的方式展现,或者根据检测算法得到异常轨迹的结果。
针对城市道路的情况,轨迹预处理中最有力的方案是地图匹配。它和网格化近似,是一种离散化的手段,但比网格化更为精准。关于地图匹配有许多成熟优秀的算法,例如HMM,ST-Matching等,将在其他主题中展开,此处不再一一详述。
3.异常检测
先说个远的,异常定义本身就有各式各样的说法。Ng说:“异常点就是给定两个参数r k,当离某点距离小于等于r的点数量小于k时,该点被定义为异常点” 。是不是很绕?其实可以在点上画个圈(二维,三维就是画个球),圈内点太少就可视作异常点。这是针对数据集中单独的点的做法。轨迹相对处理起来也比较简单,因为只有二维(最多再加上时间维度),高维的异常检测才是考验算法的难点。现有的算法对于轨迹异常有许多不同的处理方法,自从Han小组在08年提出了TRAOD之后,这方面的算法如雨后春笋举不胜数,大致可以分为几种主要的类型:
1.基于距离的方法
如果某轨迹与其他轨迹的距离很远,应能视作为异常轨迹。这是Ng对点定义的扩展。因此,计算轨迹之间的距离即为问题关键点。在这个问题上有很多技巧,如两轨迹中间点的欧氏距离,两轨迹的Hausdorff距离,等等。
2.基于密度的方法
方法是聚类(DBSCAN类、K-MEAN类)。思路是稀疏即异常。缺点在上一章已经提过,上面两种方法其实思路是一致的,缺点也有相同的地方,参数需要先验知识,不同区域的参数取值不一致。
3.基于分类的方法
需要根据特征提出可靠的分类算法。缺点是特征提取需要“强悍”的技巧,且在某些维度上未必有简单的分类。
4.基于子轨迹Sub-Traj的方法
Han组的首创,将原始轨迹划分为子轨迹,对子轨迹聚类。这种解法还需要考虑全局对轨迹的影响。
顺便说个知乎大佬的看法:异常代表三个词:无监督、多分类、解释。无监督很好理解,也许在特征提取之后会采取一些监督下的分类策略。多分类就是多样化的异常情况,解释是最终的结果,即需要将分类结果转化为语义。
4.特征提取
特征提取决定了后续对两条轨迹是否判定为同类。最一般方式可以根据距离来计算相似度,不同的线段间两两提取出特征,从而进行相似度度量。
文献Sub-trajectoryand Trajectory-Neighbor-based Outlier Detection over Trajectory Streams ,Zhu2018 中提出了两种特征提取的方式,如下图。
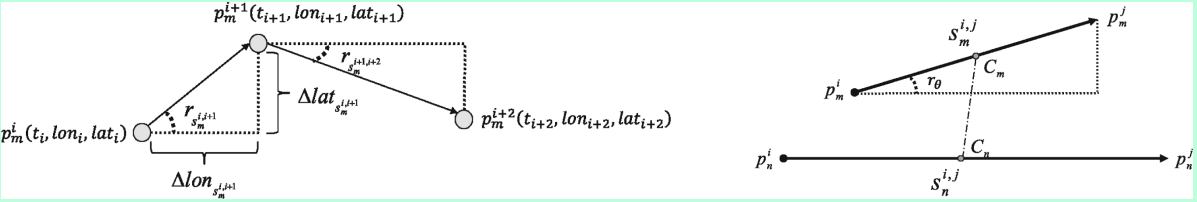
1) intra
该提取方式体现了轨迹本身的特征:
ΔX, ΔY, Δt,三个参数确定了轨迹本身的方向、速度等特征。
2) inter
该提取方式用两轨迹中点的欧氏距离进行衡量,计算轨迹间的距离。此外,计算两条轨迹间的夹角。该特征用于衡量两条轨迹在空间上的相似程度。