memcached完全剖析系列教程–1. memcached的基础
memcached是什么?
memcached 是以LiveJournal 旗下Danga Interactive 公司的Brad Fitzpatric 为首开发的一款软件。现在已成为 豆瓣、Facebook、 Vox 等众多服务中提高Web应用扩展性的重要因素。
许多Web应用都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、网站显示延迟等重大影响。
这时就该memcached大显身手了。memcached是高性能的分布式内存缓存服务器。一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。

1:一般情况下memcached的用途
memcached的特征
memcached作为高速运行的分布式缓存服务器,具有以下的特点。
· 协议简单
· 基于libevent的事件处理
· 内置内存存储方式
· memcached不互相通信的分布式
协议简单
memcached的服务器客户端通信并不使用复杂的XML等格式,而使用简单的基于文本行的协议。因此,通过telnet 也能在memcached上保存数据、取得数据。下面是例子:
$ telnet localhost 11211
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
set foo 0 0 3 (保存命令)
bar (数据)
STORED (结果)
get foo (取得命令)
VALUE foo 0 3 (数据)
bar (数据)
协议文档位于memcached的源代码内,也可以参考以下的URL:
http://code.sixapart.com/svn/memcached/trunk/server/doc/protocol.txt
基于libevent的事件处理
libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。 memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。关于事件处理这里就不再详细介绍,可以参考Dan Kegel的The C10K Problem。
libevent: http://www.monkey.org/~provos/libevent/
The C10K Problem: http://www.kegel.com/c10k.html
内置内存存储方式
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。 memcached本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。关于内存存储的详细信息,本连载的第二讲以后前坂会进行介绍,请届时参考。
memcached不互相通信的分布式
memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。各个memcached不会互相通信以共享信息。那么,怎样进行分布式呢?这完全取决于客户端的实现。本连载也将介绍memcached的分布式。

图2:memcached的分布式
接下来简单介绍一下memcached的使用方法。
安装memcached
memcached的安装比较简单,这里稍加说明。
memcached支持许多平台:
Linux
FreeBSD
Solaris (memcached 1.2.5以上版本)
Mac OS X
另外也能安装在Windows上。这里使用Fedora Core 8进行说明。
memcached的安装
运行memcached需要本文开头介绍的libevent库。Fedora 8中有现成的rpm包,通过yum命令安装即可。
$ sudo yum install libevent libevent-devel
memcached的源代码可以从memcached网站上下载。本文执笔时的最新版本为1.2.5。 Fedora 8虽然也包含了memcached的rpm,但版本比较老。因为源代码安装并不困难,这里就不使用rpm了。
下载memcached:http://memcached.org/
memcached安装与一般应用程序相同,configure、make、make install就行了。
$ wget http://www.danga.com/memcached/dist/memcached-1.2.5.tar.gz
$ tar zxf memcached-1.2.5.tar.gz
$ cd memcached-1.2.5
$ ./configure
$ make
$ sudo make install
默认情况下memcached安装到/usr/local/bin下。
memcached的启动
从终端输入以下命令,启动memcached。
$ /usr/local/bin/memcached -p 11211 -m 64m -vv
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
中间省略
slab class 38: chunk size 391224 perslab 2
slab class 39: chunk size 489032 perslab 2
<23 server listening
<24 send buffer was 110592, now 268435456
<24 server listening (udp)
<24 server listening (udp)
<24 server listening (udp)
<24 server listening (udp)
这里显示了调试信息。这样就在前台启动了memcached,监听TCP端口11211 最大内存使用量为64M。调试信息的内容大部分是关于存储的信息,下次连载时具体说明。
作为daemon后台启动时,只需:
$ /usr/local/bin/memcached -p 11211 -m 64m -d
这里使用的memcached启动选项的内容如下:
选项 | 说明 |
-p | 使用的TCP端口。默认为11211 |
-m | 最大内存大小。默认为64M |
-vv | 用very vrebose模式启动,调试信息和错误输出到控制台 |
-d | 作为daemon在后台启动 |
上面四个是常用的启动选项,其他还有很多,通过
$ /usr/local/bin/memcached -h
命令可以显示。许多选项可以改变memcached的各种行为,推荐读一读。
用客户端连接
许多语言都实现了连接memcached的客户端,其中以Perl、PHP为主。仅仅memcached网站上列出的语言就有:
Perl PHP Python Ruby C# C/C++ Lua
等等。
memcached客户端API:http://www.danga.com/memcached/apis.bml
这里介绍通过mixi正在使用的Perl库链接memcached的方法。
使用Cache::Memcached
Perl的memcached客户端有:
Cache::Memcached
Cache::Memcached::Fast
Cache::Memcached::libmemcached
等几个CPAN模块。这里介绍的Cache::Memcached是memcached的作者Brad Fitzpatric的作品,应该算是memcached的客户端中应用最为广泛的模块了。
Cache::Memcached - search.cpan.org: http://search.cpan.org/dist/Cache-Memcached/
使用Cache::Memcached连接memcached
下面的源代码为通过Cache::Memcached连接刚才启动的memcached的例子:
#!/usr/bin/perl
use strict;
use warnings;
use Cache::Memcached;
my $key = "foo";
my $value = "bar";
my $expires = 3600; # 1 hour
my $memcached = Cache::Memcached->new({
servers => ["127.0.0.1:11211"],
compress_threshold => 10_000
});
$memcached->add($key, $value, $expires);
my $ret = $memcached->get($key);
print "$retn";
在这里,为Cache::Memcached指定了memcached服务器的IP地址和一个选项,以生成实例。Cache::Memcached常用的选项如下所示。
选项 | 说明 |
servers | 用数组指定memcached服务器和端口 |
compress_threshold | 数据压缩时使用的值 |
namespace | 指定添加到键的前缀 |
另外,Cache::Memcached通过Storable模块可以将Perl的复杂数据序列化之后再保存,因此散列、数组、对象等都可以直接保存到memcached中。
保存数据
向memcached保存数据的方法有:
add replace set
它们的使用方法都相同:
my $add = $memcached->add( '键', '值', '期限' );
my $replace = $memcached->replace( '键', '值', '期限' );
my $set = $memcached->set( '键', '值', '期限' );
向memcached保存数据时可以指定期限(秒)。不指定期限时,memcached按照LRU算法保存数据。这三个方法的区别如下:
选项 | 说明 |
add | 仅当存储空间中不存在键相同的数据时才保存 |
replace | 仅当存储空间中存在键相同的数据时才保存 |
set | 与add和replace不同,无论何时都保存 |
获取数据
获取数据可以使用get和get_multi方法。
my $val = $memcached->get('键');
my $val = $memcached->get_multi('键1', '键2', '键3', '键4', '键5');
一次取得多条数据时使用get_multi。get_multi可以非同步地同时取得多个键值,其速度要比循环调用get快数十倍。
删除数据
删除数据使用delete方法,不过它有个独特的功能。
$memcached->delete('键', '阻塞时间(秒)');
删除第一个参数指定的键的数据。第二个参数指定一个时间值,可以禁止使用同样的键保存新数据。此功能可以用于防止缓存数据的不完整。但是要注意,set函数忽视该阻塞,照常保存数据
增一和减一操作
可以将memcached上特定的键值作为计数器使用。
my $ret = $memcached->incr('键');
$memcached->add('键', 0) unless defined $ret;
增一和减一是原子操作,但未设置初始值时,不会自动赋成0。因此,应当进行错误检查,必要时加入初始化操作。而且,服务器端也不会对超过2 32时的行为进行检查。
总结
这次简单介绍了memcached,以及它的安装方法、Perl客户端Cache::Memcached的用法。只要知道memcached的使用方法十分简单就足够了。
下次将说明memcached的内部结构。了解memcached的内部构造,就能知道如何使用memcached才能使Web应用的速度更上一层楼。欢迎继续阅读下一章。
memcached完全剖析系列教程–2.理解memcached的内存存储
[ 2009-12-18 10:37 by plhwin | 访问:20,462次 | 查看评论  发表评论 ]
发表评论 ]
本文目录
Slab Allocation机制:整理内存以便重复使用
· Slab Allocation的主要术语
· 在Slab中缓存记录的原理
· Slab Allocator的缺点
· 使用Growth Factor进行调优
· 查看memcached的内部状态
· 查看slabs的使用状况
· 内存存储的总结
Slab Allocation机制:整理内存以便重复使用
最近的memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
下面来看看Slab Allocator的原理。下面是memcached文档中的slab allocator的目标:
引用
the primary goal of the slabs subsystem in memcached was to eliminate memory fragmentation issues totally by using fixed-size memory chunks coming from a few predetermined size classes.
也就是说,Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
Slab Allocation的原理相当简单。 将分配的内存分割成各种尺寸的块(chunk),并把尺寸相同的块分成组(chunk的集合)

图1:Slab Allocation的构造图
而且,slab allocator还有重复使用已分配的内存的目的。也就是说,分配到的内存不会释放,而是重复利用。
Slab Allocation的主要术语
Page:分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk:用于缓存记录的内存空间。
Slab Class:特定大小的chunk的组。
在Slab中缓存记录的原理
下面说明memcached如何针对客户端发送的数据选择slab并缓存到chunk中。
memcached根据收到的数据的大小,选择最适合数据大小的slab(图2)。 memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。

图2:选择存储记录的组的方法
实际上,Slab Allocator也是有利也有弊。下面介绍一下它的缺点。
Slab Allocator的缺点
Slab Allocator解决了当初的内存碎片问题,但新的机制也给memcached带来了新的问题。
这个问题就是,由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了(图3)。

图3:chunk空间的使用
对于该问题目前还没有完美的解决方案,但在文档中记载了比较有效的解决方案。
引用
The most efficient way to reduce the waste is to use a list of size classes that closely matches (if that’s at all possible) common sizes of objects that the clients of this particular installation of memcached are likely to store.
就是说,如果预先知道客户端发送的数据的公用大小,或者仅缓存大小相同的数据的情况下,只要使用适合数据大小的组的列表,就可以减少浪费。
但是很遗憾,现在还不能进行任何调优,只能期待以后的版本了。但是,我们可以调节slab class的大小的差别。接下来说明growth factor选项。
使用Growth Factor进行调优
memcached在启动时指定 Growth Factor因子(通过-f选项),就可以在某种程度上控制slab之间的差异。默认值为1.25。但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。
让我们用以前的设置,以verbose模式启动memcached试试看:
$ memcached -f 2 -vv
下面是启动后的verbose输出:
slab class 1: chunk size 128 perslab 8192
slab class 2: chunk size 256 perslab 4096
slab class 3: chunk size 512 perslab 2048
slab class 4: chunk size 1024 perslab 1024
slab class 5: chunk size 2048 perslab 512
slab class 6: chunk size 4096 perslab 256
slab class 7: chunk size 8192 perslab 128
slab class 8: chunk size 16384 perslab 64
slab class 9: chunk size 32768 perslab 32
slab class 10: chunk size 65536 perslab 16
slab class 11: chunk size 131072 perslab 8
slab class 12: chunk size 262144 perslab 4
slab class 13: chunk size 524288 perslab 2
可见,从128字节的组开始,组的大小依次增大为原来的2倍。这样设置的问题是,slab之间的差别比较大,有些情况下就相当浪费内存。因此,为尽量减少内存浪费,两年前追加了growth factor这个选项。
来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第10组):
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
slab class 4: chunk size 184 perslab 5698
slab class 5: chunk size 232 perslab 4519
slab class 6: chunk size 296 perslab 3542
slab class 7: chunk size 376 perslab 2788
slab class 8: chunk size 472 perslab 2221
slab class 9: chunk size 592 perslab 1771
slab class 10: chunk size 744 perslab 1409
可见,组间差距比因子为2时小得多,更适合缓存几百字节的记录。从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。
将memcached引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整growth factor,以获得最恰当的设置。内存是珍贵的资源,浪费就太可惜了。
接下来介绍一下如何使用memcached的stats命令查看slabs的利用率等各种各样的信息。
查看memcached的内部状态
memcached有个名为stats的命令,使用它可以获得各种各样的信息。执行命令的方法很多,用telnet最为简单:
$ telnet 主机名 端口号
连接到memcached之后,输入stats再按回车,即可获得包括资源利用率在内的各种信息。此外,输入”stats slabs”或”stats items”还可以获得关于缓存记录的信息。结束程序请输入quit。
这些命令的详细信息可以参考memcached软件包内的protocol.txt文档。
$ telnet localhost 11211
Trying ::1...
Connected to localhost.
Escape character is '^]'.
stats
STAT pid 481
STAT uptime 16574
STAT time 1213687612
STAT version 1.2.5
STAT pointer_size 32
STAT rusage_user 0.102297
STAT rusage_system 0.214317
STAT curr_items 0
STAT total_items 0
STAT bytes 0
STAT curr_connections 6
STAT total_connections 8
STAT connection_structures 7
STAT cmd_get 0
STAT cmd_set 0
STAT get_hits 0
STAT get_misses 0
STAT evictions 0
STAT bytes_read 20
STAT bytes_written 465
STAT limit_maxbytes 67108864
STAT threads 4
END
quit
另外,如果安装了libmemcached这个面向C/C++语言的客户端库,就会安装 memstat 这个命令。使用方法很简单,可以用更少的步骤获得与telnet相同的信息,还能一次性从多台服务器获得信息。
$ memstat --servers=server1,server2,server3,...
libmemcached可以从下面的地址获得:
http://tangent.org/552/libmemcached.html
查看slabs的使用状况
使用memcached的创造着Brad写的名为memcached-tool的Perl脚本,可以方便地获得slab的使用情况(它将memcached的返回值整理成容易阅读的格式)。可以从下面的地址获得脚本:
http://code.sixapart.com/svn/memcached/trunk/server/scripts/memcached-tool
使用方法也极其简单:
$ memcached-tool 主机名:端口 选项
查看slabs使用状况时无需指定选项,因此用下面的命令即可:
$ memcached-tool 主机名:端口
获得的信息如下所示:
# Item_Size Max_age 1MB_pages Count Full?
1 104 B 1394292 s 1215 12249628 yes
2 136 B 1456795 s 52 400919 yes
3 176 B 1339587 s 33 196567 yes
4 224 B 1360926 s 109 510221 yes
5 280 B 1570071 s 49 183452 yes
6 352 B 1592051 s 77 229197 yes
7 440 B 1517732 s 66 157183 yes
8 552 B 1460821 s 62 117697 yes
9 696 B 1521917 s 143 215308 yes
10 872 B 1695035 s 205 246162 yes
11 1.1 kB 1681650 s 233 221968 yes
12 1.3 kB 1603363 s 241 183621 yes
13 1.7 kB 1634218 s 94 57197 yes
14 2.1 kB 1695038 s 75 36488 yes
15 2.6 kB 1747075 s 65 25203 yes
16 3.3 kB 1760661 s 78 24167 yes
各列的含义为:
列 | 含义 |
# | slab class编号 |
Item_Size | Chunk大小 |
Max_age | LRU内最旧的记录的生存时间 |
1MB_pages | 分配给Slab的页数 |
Count | Slab内的记录数 |
Full? | Slab内是否含有空闲chunk |
从这个脚本获得的信息对于调优非常方便,强烈推荐使用。
内存存储的总结
本次简单说明了memcached的缓存机制和调优方法。希望读者能理解memcached的内存管理原理及其优缺点。
下次将继续说明LRU和Expire等原理,以及memcached的最新发展方向—— 可扩充体系(pluggable architecher)。
memcached完全剖析系列教程–3.memcached的删除机制和发展方向
[ 2009-12-25 08:16 by plhwin | 访问:3,968次 |  查看评论 发表评论 ]
查看评论 发表评论 ]
本文目录
memcached在数据删除方面有效利用资源
· 数据不会真正从memcached中消失
· Lazy Expiration
· LRU:从缓存中有效删除数据的原理
memcached的最新发展方向
· 关于二进制协议
· 二进制协议的格式
· HEADER中引人注目的地方
外部引擎支持
· 外部引擎支持的必要性
· 简单API设计的成功的关键
· 重新审视现在的体系
· 总结
memcached是缓存,所以数据不会永久保存在服务器上,这是向系统中引入memcached的前提。本次介绍memcached的数据删除机制,以及memcached的最新发展方向——二进制协议(Binary Protocol)和外部引擎支持。
memcached在数据删除方面有效利用资源
数据不会真正从memcached中消失
上一篇介绍过, memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible,透明),其存储空间即可重复使用。
Lazy Expiration
memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
LRU:从缓存中有效删除数据的原理
memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为 Least Recently Used(LRU)机制来分配空间。顾名思义,这是删除“最近最少使用”的记录的机制。因此,当memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。从缓存的实用角度来看,该模型十分理想。
不过,有些情况下LRU机制反倒会造成麻烦。memcached启动时通过“-M”参数可以禁止LRU,如下所示:
$ memcached -M -m 1024
启动时必须注意的是,小写的“-m”选项是用来指定最大内存大小的。不指定具体数值则使用默认值64MB。
指定“-M”参数启动后,内存用尽时memcached会返回错误。话说回来,memcached毕竟不是存储器,而是缓存,所以推荐使用LRU。
memcached的最新发展方向
memcached的roadmap上有两个大的目标。一个是二进制协议的策划和实现,另一个是外部引擎的加载功能。
关于二进制协议
使用二进制协议的理由是它不需要文本协议的解析处理,使得原本高速的memcached的性能更上一层楼,还能减少文本协议的漏洞。目前已大部分实现,开发用的代码库中已包含了该功能。 memcached的下载页面上有代码库的链接。
http://danga.com/memcached/download.bml
二进制协议的格式
协议的包为24字节的帧,其后面是键和无结构数据(Unstructured Data)。实际的格式如下(引自协议文档):
Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0/ HEADER /
/ /
/ /
/ /
+---------------+---------------+---------------+---------------+
24/ COMMAND-SPECIFIC EXTRAS (as needed) /
+/ (note length in th extras length header field) /
+---------------+---------------+---------------+---------------+
m/ Key (as needed) /
+/ (note length in key length header field) /
+---------------+---------------+---------------+---------------+
n/ Value (as needed) /
+/ (note length is total body length header field, minus /
+/ sum of the extras and key length body fields) /
+---------------+---------------+---------------+---------------+
Total 24 bytes
如上所示,包格式十分简单。需要注意的是,占据了16字节的头部(HEADER)分为请求头(Request Header)和响应头(Response Header)两种。头部中包含了表示包的有效性的Magic字节、命令种类、键长度、值长度等信息,格式如下:
Request Header
Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0| Magic | Opcode | Key length |
+---------------+---------------+---------------+---------------+
4| Extras length | Data type | Reserved |
+---------------+---------------+---------------+---------------+
8| Total body length |
+---------------+---------------+---------------+---------------+
12| Opaque |
+---------------+---------------+---------------+---------------+
16| CAS |
| |
+---------------+---------------+---------------+---------------+
Response Header
Byte/ 0 | 1 | 2 | 3 |
/ | | | |
|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|0 1 2 3 4 5 6 7|
+---------------+---------------+---------------+---------------+
0| Magic | Opcode | Key Length |
+---------------+---------------+---------------+---------------+
4| Extras length | Data type | Status |
+---------------+---------------+---------------+---------------+
8| Total body length |
+---------------+---------------+---------------+---------------+
12| Opaque |
+---------------+---------------+---------------+---------------+
16| CAS |
| |
+---------------+---------------+---------------+---------------+
如希望了解各个部分的详细内容,可以checkout出memcached的二进制协议的代码树,参考其中的docs文件夹中的protocol_binary.txt文档。
HEADER中引人注目的地方
看到HEADER格式后我的感想是,键的上限太大了!现在的memcached规格中,键长度最大为250字节,但二进制协议中键的大小用2字节表示。因此,理论上最大可使用65536字节(216)长的键。尽管250字节以上的键并不会太常用,二进制协议发布之后就可以使用巨大的键了。
二进制协议从下一版本1.3系列开始支持。
外部引擎支持
我去年曾经试验性地将memcached的存储层改造成了可扩展的(pluggable)。
http://alpha.mixi.co.jp/blog/?p=129
MySQL的Brian Aker看到这个改造之后,就将代码发到了memcached的邮件列表。 memcached的开发者也十分感兴趣,就放到了roadmap中。现在由我和 memcached的开发者Trond Norbye协同开发(规格设计、实现和测试)。和国外协同开发时时差是个大问题,但抱着相同的愿景,最后终于可以将可扩展架构的原型公布了。代码库可以从 memcached的下载页面 上访问。
外部引擎支持的必要性
世界上有许多memcached的派生软件,其理由是希望永久保存数据、实现数据冗余等,即使牺牲一些性能也在所不惜。我在开发memcached之前,在mixi的研发部也曾经考虑过重新发明memcached。
外部引擎的加载机制能封装memcached的网络功能、事件处理等复杂的处理。因此,现阶段通过强制手段或重新设计等方式使memcached和存储引擎合作的困难就会烟消云散,尝试各种引擎就会变得轻而易举了。
简单API设计的成功的关键
该项目中我们最重视的是API设计。函数过多,会使引擎开发者感到麻烦;过于复杂,实现引擎的门槛就会过高。因此,最初版本的接口函数只有13个。具体内容限于篇幅,这里就省略了,仅说明一下引擎应当完成的操作:
引擎信息(版本等)
引擎初始化
引擎关闭
引擎的统计信息
在容量方面,测试给定记录能否保存
为item(记录)结构分配内存
释放item(记录)的内存
删除记录
保存记录
回收记录
更新记录的时间戳
数学运算处理
数据的flush
对详细规格有兴趣的读者,可以checkout engine项目的代码,阅读器中的engine.h。
重新审视现在的体系
memcached支持外部存储的难点是,网络和事件处理相关的代码(核心服务器)与内存存储的代码紧密关联。这种现象也称为tightly coupled(紧密耦合)。必须将内存存储的代码从核心服务器中独立出来,才能灵活地支持外部引擎。因此,基于我们设计的API,memcached被重构成下面的样子:

重构之后,我们与1.2.5版、二进制协议支持版等进行了性能对比,证实了它不会造成性能影响。
在考虑如何支持外部引擎加载时,让memcached进行并行控制(concurrency control)的方案是最为容易的,但是对于引擎而言,并行控制正是性能的真谛,因此我们采用了将多线程支持完全交给引擎的设计方案。
以后的改进,会使得memcached的应用范围更为广泛。
总结
本次介绍了memcached的超时原理、内部如何删除数据等,在此之上又介绍了二进制协议和外部引擎支持等memcached的最新发展方向。这些功能要到1.3版才会支持,敬请期待!
下次将介绍memcached的应用知识和应用程序兼容性等内容。
memcached完全剖析系列教程–4.memcached的分布式算法
[ 2010-01-02 21:58 by plhwin | 访问:3,583次 |  查看评论 发表评论 ]
查看评论 发表评论 ]
本文目录
memcached的分布式
· memcached的分布式是什么意思?
· Cache::Memcached的分布式方法
· 根据余数计算分散
· 根据余数计算分散的缺点
Consistent Hashing
· Consistent Hashing的简单说明
· 支持Consistent Hashing的函数库
· 总结
memcached的分布式
正如第1次中介绍的那样, memcached虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。服务器端仅包括 第2次、 第3次 前坂介绍的内存存储功能,其实现非常简单。至于memcached的分布式,则是完全由客户端程序库实现的。这种分布式是memcached的最大特点。
memcached的分布式是什么意思?
这里多次使用了“分布式”这个词,但并未做详细解释。现在开始简单地介绍一下其原理,各个客户端的实现基本相同。
下面假设memcached服务器有node1~node3三台,应用程序要保存键名为“tokyo”“kanagawa”“chiba”“saitama”“gunma” 的数据。

图1 分布式简介:准备
首先向memcached中添加“tokyo”。将“tokyo”传给客户端程序库后,客户端实现的算法就会根据“键”来决定保存数据的memcached服务器。服务器选定后,即命令它保存“tokyo”及其值。

图2 分布式简介:添加时
同样,“kanagawa”“chiba”“saitama”“gunma”都是先选择服务器再保存。
接下来获取保存的数据。获取时也要将要获取的键“tokyo”传递给函数库。函数库通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存
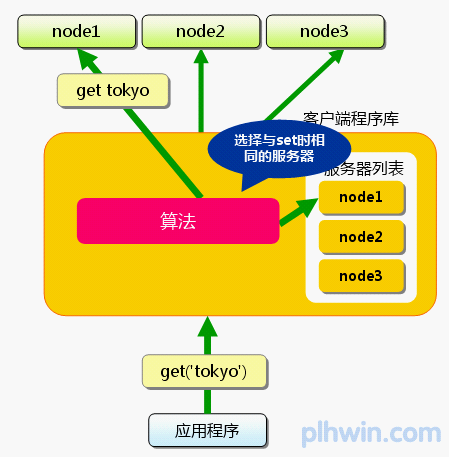
图3 分布式简介:获取时
这样,将不同的键保存到不同的服务器上,就实现了memcached的分布式。 memcached服务器增多后,键就会分散,即使一台memcached服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
接下来介绍第1次中提到的Perl客户端函数库Cache::Memcached实现的分布式方法。
Cache::Memcached的分布式方法
Perl的memcached客户端函数库Cache::Memcached是 memcached的作者Brad Fitzpatrick的作品,可以说是原装的函数库
Cache::Memcached – search.cpan.org
该函数库实现了分布式功能,是memcached标准的分布式方法。
根据余数计算分散
Cache::Memcached的分布式方法简单来说,就是“根据服务器台数的余数进行分散”。求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。
下面将Cache::Memcached简化成以下的Perl脚本来进行说明。
use strict;
use warnings;
use String::CRC32;
my @nodes = ('node1','node2','node3');
my @keys = ('tokyo', 'kanagawa', 'chiba', 'saitama', 'gunma');
foreach my $key (@keys) {
my $crc = crc32($key); # CRC値
my $mod = $crc % ( $#nodes + 1 );
my $server = $nodes[ $mod ]; # 根据余数选择服务器
printf "%s => %sn", $key, $server;
}
Cache::Memcached在求哈希值时使用了CRC。
String::CRC32 – search.cpan.org
首先求得字符串的CRC值,根据该值除以服务器节点数目得到的余数决定服务器。上面的代码执行后输入以下结果:
tokyo => node2
kanagawa => node3
chiba => node2
saitama => node1
gunma => node1
根据该结果,“tokyo”分散到node2,“kanagawa”分散到node3等。多说一句,当选择的服务器无法连接时,Cache::Memcached会将连接次数添加到键之后,再次计算哈希值并尝试连接。这个动作称为rehash。不希望rehash时可以在生成Cache::Memcached对象时指定“rehash => 0”选项。
根据余数计算分散的缺点
余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中率。用Perl写段代码来验证其代价。
use strict;
use warnings;
use String::CRC32;
my @nodes = @ARGV;
my @keys = ('a'..'z');
my %nodes;
foreach my $key ( @keys ) {
my $hash = crc32($key);
my $mod = $hash % ( $#nodes + 1 );
my $server = $nodes[ $mod ];
push @{ $nodes{ $server } }, $key;
}
foreach my $node ( sort keys %nodes ) {
printf "%s: %sn", $node, join ",", @{ $nodes{$node} };
}
这段Perl脚本演示了将“a”到“z”的键保存到memcached并访问的情况。将其保存为mod.pl并执行。
首先,当服务器只有三台时:
$ mod.pl node1 node2 nod3
node1: a,c,d,e,h,j,n,u,w,x
node2: g,i,k,l,p,r,s,y
node3: b,f,m,o,q,t,v,z
结果如上,node1保存a、c、d、e……,node2保存g、i、k……,每台服务器都保存了8个到10个数据。
接下来增加一台memcached服务器。
$ mod.pl node1 node2 node3 node4
node1: d,f,m,o,t,v
node2: b,i,k,p,r,y
node3: e,g,l,n,u,w
node4: a,c,h,j,q,s,x,z
添加了node4。可见,只有d、i、k、p、r、y命中了。像这样,添加节点后键分散到的服务器会发生巨大变化。26个键中只有六个在访问原来的服务器,其他的全都移到了其他服务器。命中率降低到23%。在Web应用程序中使用memcached时,在添加memcached服务器的瞬间缓存效率会大幅度下降,负载会集中到数据库服务器上,有可能会发生无法提供正常服务的情况。
mixi的Web应用程序运用中也有这个问题,导致无法添加memcached服务器。但由于使用了新的分布式方法,现在可以轻而易举地添加memcached服务器了。这种分布式方法称为 Consistent Hashing。
Consistent Hashing
关于Consistent Hashing的思想,mixi株式会社的开发blog等许多地方都介绍过,这里只简单地说明一下。
mixi Engineers’ Blog – スマートな分散で快適キャッシュライフ
ConsistentHashing – コンシステント ハッシュ法
Consistent Hashing的简单说明
Consistent Hashing如下所示:首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。

图4 Consistent Hashing:基本原理
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在continuum上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。

图5 Consistent Hashing:添加服务器
因此,Consistent Hashing最大限度地抑制了键的重新分布。而且,有的Consistent Hashing的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
通过下文中介绍的使用Consistent Hashing算法的memcached客户端函数库进行测试的结果是,由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:
(1 – n/(n+m)) * 100
支持Consistent Hashing的函数库
本连载中多次介绍的Cache::Memcached虽然不支持Consistent Hashing,但已有几个客户端函数库支持了这种新的分布式算法。第一个支持Consistent Hashing和虚拟节点的memcached客户端函数库是名为libketama的PHP库,由last.fm开发。
libketama – a consistent hashing algo for memcache clients – RJ ブログ – Users at Last.fm
至于Perl客户端,连载的第1次 中介绍过的Cache::Memcached::Fast和Cache::Memcached::libmemcached支持 Consistent Hashing。
· Cache::Memcached::Fast – search.cpan.org
· Cache::Memcached::libmemcached – search.cpan.org
两者的接口都与Cache::Memcached几乎相同,如果正在使用Cache::Memcached,那么就可以方便地替换过来。Cache::Memcached::Fast重新实现了libketama,使用Consistent Hashing创建对象时可以指定ketama_points选项。
my $memcached = Cache::Memcached::Fast->new({
servers => ["192.168.0.1:11211","192.168.0.2:11211"],
ketama_points => 150
});
另外,Cache::Memcached::libmemcached 是一个使用了Brain Aker开发的C函数库libmemcached的Perl模块。 libmemcached本身支持几种分布式算法,也支持Consistent Hashing,其Perl绑定也支持Consistent Hashing。
· Tangent Software: libmemcached
总结
本次介绍了memcached的分布式算法,主要有memcached的分布式是由客户端函数库实现,以及高效率地分散数据的Consistent Hashing算法。下次将介绍mixi在memcached应用方面的一些经验,和相关的兼容应用程序
memcached完全剖析系列教程–5.memcached的应用和兼容程序
[ 2010-01-07 22:29 by plhwin | 访问:5,189次 |  查看评论
查看评论  发表评论 ]
发表评论 ]
memcached的连载终于要结束了。到上次为止,我们介绍了与memcached直接相关的话题,本次介绍一些mixi的案例和实际应用上的话题,并介绍一些与memcached兼容的程序。
本文目录
mixi案例研究
· 服务器配置和数量
· memcached进程
memcached使用方法和客户端
通过Cache::Memcached::Fast维持连接
公共数据的处理和rehash
· memcached应用经验
· 通过daemontools启动
· 监视
· memcached的性能
兼容应用程序
· Tokyo Tyrant案例
· 总结
mixi案例研究
mixi在提供服务的初期阶段就使用了memcached。随着网站访问量的急剧增加,单纯为数据库添加slave已无法满足需要,因此引入了memcached。此外,我们也从增加可扩展性的方面进行了验证,证明了memcached的速度和稳定性都能满足需要。现在,memcached已成为mixi服务中非常重要的组成部分。

图1 现在的系统组件
服务器配置和数量
mixi使用了许许多多服务器,如数据库服务器、应用服务器、图片服务器、反向代理服务器等。单单memcached就有将近200台服务器在运行。 memcached服务器的典型配置如下:
· CPU:Intel Pentium 4 2.8GHz
· 内存:4GB
· 硬盘:146GB SCSI
· 操作系统:Linux(x86_64)
这些服务器以前曾用于数据库服务器等。随着CPU性能提升、内存价格下降,我们积极地将数据库服务器、应用服务器等换成了性能更强大、内存更多的服务器。这样,可以抑制mixi整体使用的服务器数量的急剧增加,降低管理成本。由于memcached服务器几乎不占用CPU,就将换下来的服务器用作memcached服务器了。
memcached进程
每台memcached服务器仅启动一个memcached进程。分配给memcached的内存为3GB,启动参数如下:
/usr/bin/memcached -p 11211 -u nobody -m 3000 -c 30720
由于使用了x86_64的操作系统,因此能分配2GB以上的内存。32位操作系统中,每个进程最多只能使用2GB内存。也曾经考虑过启动多个分配2GB以下内存的进程,但这样一台服务器上的TCP连接数就会成倍增加,管理上也变得复杂,所以mixi就统一使用了64位操作系统。
另外,虽然服务器的内存为4GB,却仅分配了3GB,是因为内存分配量超过这个值,就有可能导致内存交换(swap)。连载的第2次中前坂讲解过了memcached的内存存储“slab allocator”,当时说过,memcached启动时指定的内存分配量是memcached用于保存数据的量,没有包括“slab allocator”本身占用的内存、以及为了保存数据而设置的管理空间。因此,memcached进程的实际内存分配量要比指定的容量要大,这一点应当注意。
mixi保存在memcached中的数据大部分都比较小。这样,进程的大小要比指定的容量大很多。因此,我们反复改变内存分配量进行验证,确认了3GB的大小不会引发swap,这就是现在应用的数值。
memcached使用方法和客户端
现在,mixi的服务将200台左右的memcached服务器作为一个pool使用。每台服务器的容量为3GB,那么全体就有了将近600GB的巨大的内存数据库。客户端程序库使用了本连载中多次提到车的Cache::Memcached::Fast,与服务器进行交互。当然,缓存的分布式算法使用的是 第4次介绍过的 Consistent Hashing算法。
· Cache::Memcached::Fast – search.cpan.org
应用层上memcached的使用方法由开发应用程序的工程师自行决定并实现。但是,为了防止车轮再造、防止Cache::Memcached::Fast上的教训再次发生,我们提供了Cache::Memcached::Fast的wrap模块并使用。
通过Cache::Memcached::Fast维持连接
Cache::Memcached的情况下,与memcached的连接(文件句柄)保存在Cache::Memcached包内的类变量中。在mod_perl和FastCGI等环境下,包内的变量不会像CGI那样随时重新启动,而是在进程中一直保持。其结果就是不会断开与memcached的连接,减少了TCP连接建立时的开销,同时也能防止短时间内反复进行TCP连接、断开而导致的TCP端口资源枯竭。
但是,Cache::Memcached::Fast没有这个功能,所以需要在模块之外将Cache::Memcached::Fast对象保持在类变量中,以保证持久连接。
package Gihyo::Memcached;
use strict;
use warnings;
use Cache::Memcached::Fast;
my @server_list = qw/192.168.1.1:11211 192.168.1.1:11211/;
my $fast; ## 用于保持对象
sub new {
my $self = bless {}, shift;
if ( !$fast ) {
$fast = Cache::Memcached::Fast->new({ servers => @server_list });
}
$self->{_fast} = $fast;
return $self;
}
sub get {
my $self = shift;
$self->{_fast}->get(@_);
}
上面的例子中,Cache::Memcached::Fast对象保存到类变量$fast中。
公共数据的处理和rehash
诸如mixi的主页上的新闻这样的所有用户共享的缓存数据、设置信息等数据,会占用许多页,访问次数也非常多。在这种条件下,访问很容易集中到某台memcached服务器上。访问集中本身并不是问题,但是一旦访问集中的那台服务器发生故障导致memcached无法连接,就会产生巨大的问题。
连载的第4次 中提到,Cache::Memcached拥有rehash功能,即在无法连接保存数据的服务器的情况下,会再次计算hash值,连接其他的服务器。
但是,Cache::Memcached::Fast没有这个功能。不过,它能够在连接服务器失败时,短时间内不再连接该服务器的功能。
my $fast = Cache::Memcached::Fast->new({
max_failures => 3,
failure_timeout => 1
});
在failure_timeout秒内发生max_failures以上次连接失败,就不再连接该memcached服务器。我们的设置是1秒钟3次以上。
此外,mixi还为所有用户共享的缓存数据的键名设置命名规则,符合命名规则的数据会自动保存到多台memcached服务器中,取得时从中仅选取一台服务器。创建该函数库后,就可以使memcached服务器故障不再产生其他影响。
memcached应用经验
到此为止介绍了memcached内部构造和函数库,接下来介绍一些其他的应用经验。
通过daemontools启动
通常情况下memcached运行得相当稳定,但mixi现在使用的最新版1.2.5 曾经发生过几次memcached进程死掉的情况。架构上保证了即使有几台memcached故障也不会影响服务,不过对于memcached进程死掉的服务器,只要重新启动memcached,就可以正常运行,所以采用了监视memcached进程并自动启动的方法。于是使用了daemontools。
daemontools是qmail的作者DJB开发的UNIX服务管理工具集,其中名为supervise的程序可用于服务启动、停止的服务重启等。
· daemontools
这里不介绍daemontools的安装了。mixi使用了以下的run脚本来启动memcached。
#!/bin/sh
if [ -f /etc/sysconfig/memcached ];then
./etc/sysconfig/memcached
fi
exec 2>&1
exec /usr/bin/memcached -p $PORT -u $USER -m $CACHESIZE -c $MAXCONN $OPTIONS
监视
mixi使用了名为“nagios”的开源监视软件来监视memcached。
· Nagios: Home
在nagios中可以简单地开发插件,可以详细地监视memcached的get、add等动作。不过mixi仅通过stats命令来确认memcached的运行状态。
define command {
command_name check_memcached
command_line $USER1$/check_tcp -H $HOSTADDRESS$ -p 11211 -t 5 -E -s 'statsrnquitrn' -e 'uptime' -M crit
}
此外,mixi将stats目录的结果通过rrdtool转化成图形,进行性能监视,并将每天的内存使用量做成报表,通过邮件与开发者共享。
memcached的性能
连载中已介绍过,memcached的性能十分优秀。我们来看看mixi的实际案例。这里介绍的图表是服务所使用的访问最为集中的memcached服务器。

图2 请求数

图3 流量

图4 TCP连接数
从上至下依次为请求数、流量和TCP连接数。请求数最大为15000qps,流量达到400Mbps,这时的连接数已超过了10000个。该服务器没有特别的硬件,就是开头介绍的普通的memcached服务器。此时的CPU利用率为:
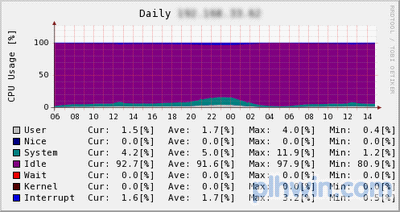
图5 CPU利用率
可见,仍然有idle的部分。因此,memcached的性能非常高,可以作为Web应用程序开发者放心地保存临时数据或缓存数据的地方。
兼容应用程序
memcached的实现和协议都十分简单,因此有很多与memcached兼容的实现。一些功能强大的扩展可以将memcached的内存数据写到磁盘上,实现数据的持久性和冗余。连载第3次 介绍过,以后的memcached的存储层将变成可扩展的(pluggable),逐渐支持这些功能。
这里介绍几个与memcached兼容的应用程序。
repcached:为memcached提供复制(replication)功能的patch。
Flared:存储到QDBM。同时实现了异步复制和fail over等功能。
memcachedb:存储到BerkleyDB。还实现了message queue。
Tokyo Tyrant:将数据存储到Tokyo Cabinet。不仅与memcached协议兼容,还能通过HTTP进行访问。
Tokyo Tyrant案例
mixi使用了上述兼容应用程序中的Tokyo Tyrant。Tokyo Tyrant是平林开发的 Tokyo Cabinet DBM的网络接口。它有自己的协议,但也拥有memcached兼容协议,也可以通过HTTP进行数据交换。Tokyo Cabinet虽然是一种将数据写到磁盘的实现,但速度相当快。
mixi并没有将Tokyo Tyrant作为缓存服务器,而是将它作为保存键值对组合的DBMS来使用。主要作为存储用户上次访问时间的数据库来使用。它与几乎所有的mixi服务都有关,每次用户访问页面时都要更新数据,因此负荷相当高。MySQL的处理十分笨重,单独使用memcached保存数据又有可能会丢失数据,所以引入了Tokyo Tyrant。但无需重新开发客户端,只需原封不动地使用Cache::Memcached::Fast即可,这也是优点之一。
关于Tokyo Tyrant的详细信息,请参考:
· mixi Engineers’ Blog – Tokyo Tyrantによる耐高負荷DBの構築
· mixi Engineers’ Blog – Tokyo (Cabinet|Tyrant)の新機能
总结
到本次为止,“memcached全面剖析”系列就结束了。我们介绍了memcached的基础、内部结构、分散算法和应用等内容。读完后如果您能对memcached产生兴趣,就是我们的荣幸。关于mixi的系统、应用方面的信息,请参考这里。感谢您的阅读。
From:
http://www.plhwin.com/memcached-tutorial-memory-storage-2/