今天工作情况依然~
早上收到Yu同学的反馈--取到空单词。狠狠认真分析了一下其发来的数据,发现其数据跟我处理的有微小的差异,很是奇怪,怀疑是词典版本或者Lingoes版本差异的问题。唉,把基础建立在别人上面就有这样的风险--别人微小的改动,会导致自己全部的垮掉。但,但难不成我也来写个词典?!算了,还是专心写生词本吧。。。
于是重新分析Lingoes的HTML数据,总结其结果的‘共性’,有点成果,明天整理下,希望可以提高取词的成功率~
来,看看修正后的 Yu同学的数据,其是用German的,就简单查了一个'versuchen'(我不认识,麻烦Yu同学解释吧。。)结果,结果多的很可怕。。。
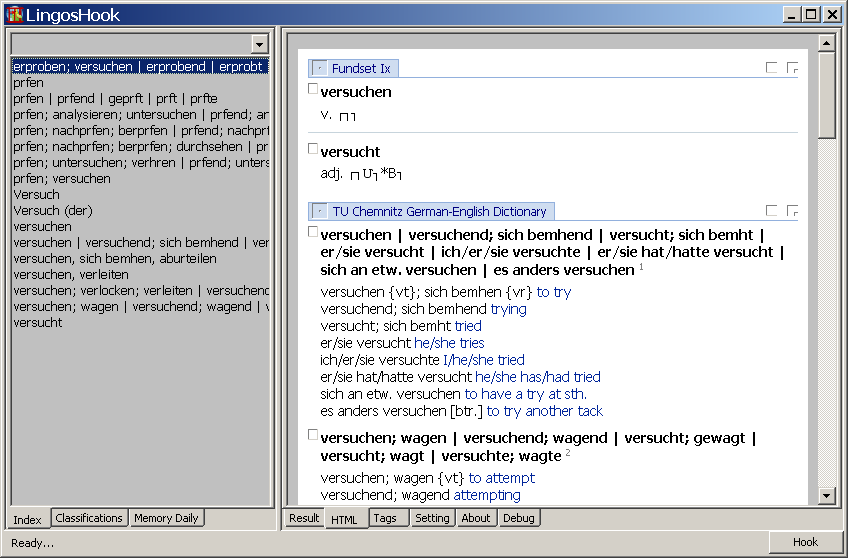
Yu同学很聪明,其只想两个结果--Fundset词典的结果,因此开启‘Skip Html Dictionay ..'选项来禁止其它词典的解析,只使用Fundset词典结果,这招太强了,我都没有想到,所以我才有这么多结果。但杯具的是--Fundset词典解析失败了,Yu同学只得到一个空单词。。。不好意思啊。。。下个版本一定给你改好。。
这个结果也提示了应该快点实现HTML词典解析配置部分了,目前HTML词典在显示上是可以配置的,但在解析上是不能指定解析哪个,不解析哪个的。在设计时,这个配置已经存在了,只是自己想来应该都希望能解析的越多越好,因此一直没有实现,但上图又一次刺激了我--不要自以为是。。。。