LingosHook第二十版(v1.2.003)主要围绕HTML结果的单词解析问题添加了新的功能,并为此增加了相应的配置项。这里下载。
此版本的问题可以由下图描述:
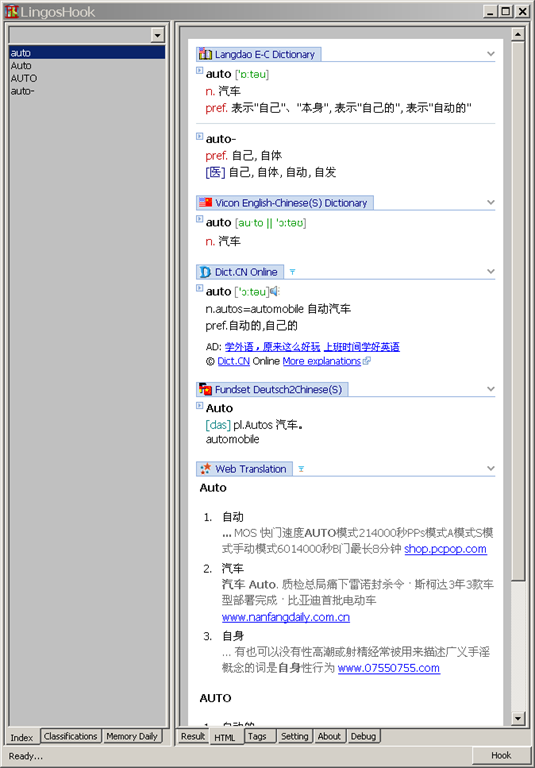
上图是查询单词'auto'的结果,从左侧的Index中可以看到LingosHook提取的结果单词,包括'auto','Auto','AUTO'和'auto-'。此结果展现了LingosHook的一个‘强力’功能--尽可能地提取HTML结果数据中罗列的单词。这样做的好处是能尽量记录结果数据中所返回的和所查询单词相关的单词;但当查询词典过多时,此功能也会造成过多的冗余数据,就像上图所示。
因此有必要提供相应的功能以屏蔽此能力。于是LingosHook在此版本新增如下配置,以实现此需求。
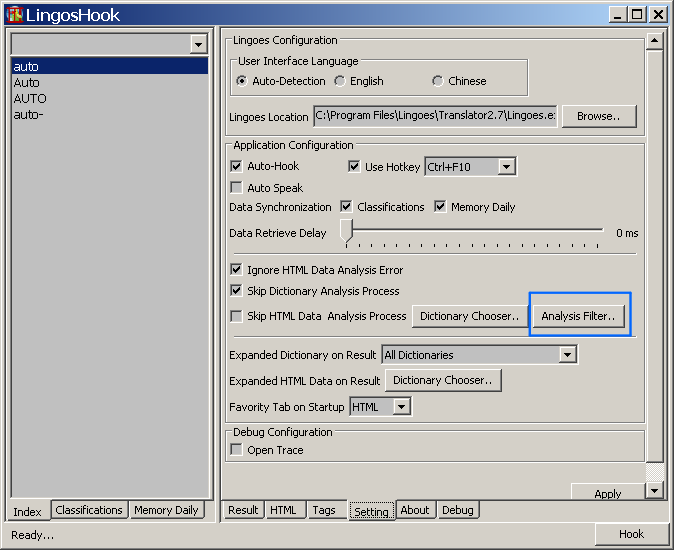
点击如上Setting界面中新增的'Analysis Filter'按钮,将弹出如下对话框,并提供三种单词解析过滤配置;
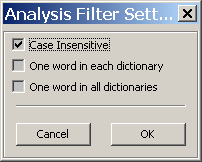
1. 'Case Insensitive': 大小写不敏感;选中此项后,大小写不同的单词将被认为是相同的单词,相同的单词会从列表中被过滤掉;
2. 'One word in each dictionary': 一个词典仅记录一个单词;选中此项后,LingosHook将针对不同的词典结果,仅解析其列举的第一个单词;
3. 'One word in all dictionaries': 所有词典仅记录一个单词;选中此项后,LingosHook将针对不同的词典结果,仅解析全部词典列举的第一个单词;
下图展示了三种不同配置下,显示的查询'auto'时的结果。
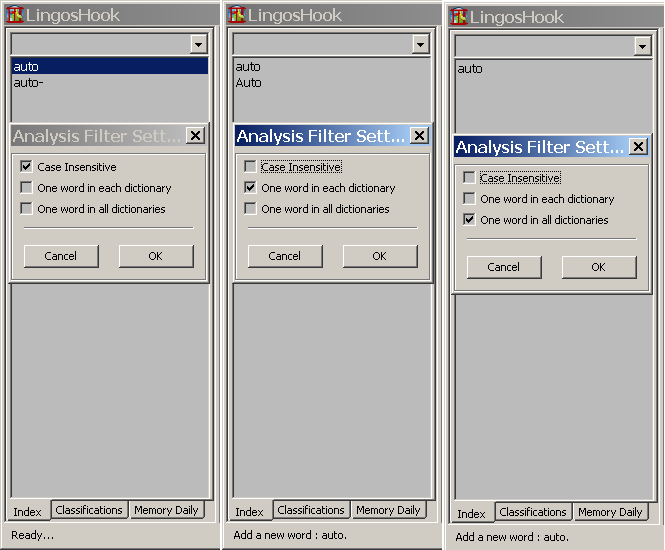
'Analysis Filter'功能就这些了。。。
<---- 疲惫的分割线 ---->
LingosHook就这些了。。。