这一节关注TC中的hash数据库如何根据一个key查找到该key所在的record,因为后续的删除,插入记录都是以查找为基础的,所以首先描述这部分内容.
从上一节的
概述中,可以看到record结构体中有两个成员left,right:
typedef struct { // type of structure for a record
uint64_t off; // offset of the record
uint32_t rsiz; // size of the whole record
uint8_t magic; // magic number
uint8_t hash; // second hash value
uint64_t left; // offset of the left child record
uint64_t right; // offset of the right child record
uint32_t ksiz; // size of the key
uint32_t vsiz; // size of the value
uint16_t psiz; // size of the padding
const char *kbuf; // pointer to the key
const char *vbuf; // pointer to the value
uint64_t boff; // offset of the body
char *bbuf; // buffer of the body
} TCHREC;
说明,每个record是存放在一个类二叉树的结构中的.
实际上,TC会首先根据一个record的key去算出该key所在的bucket index以及hash index,代码如下:
/* Get the bucket index of a record.
`hdb' specifies the hash database object.
`kbuf' specifies the pointer to the region of the key.
`ksiz' specifies the size of the region of the key.
`hp' specifies the pointer to the variable into which the second hash value is assigned.
The return value is the bucket index. */
static uint64_t tchdbbidx(TCHDB *hdb, const char *kbuf, int ksiz, uint8_t *hp){
assert(hdb && kbuf && ksiz >= 0 && hp);
uint64_t idx = 19780211;
uint32_t hash = 751;
const char *rp = kbuf + ksiz;
while(ksiz--){
idx = idx * 37 + *(uint8_t *)kbuf++;
hash = (hash * 31) ^ *(uint8_t *)--rp;
}
*hp = hash;
return idx % hdb->bnum;
}
需要特别提醒的一点是,上面的算法中,根据key算出所在的bucket index,是经过模TCHDB->bnum之后的结果,也就是说,这个值是有限制的---最大不能超过TCHDB初始化时得到的bucket最大数量;而算出的二级hash值,我是没有看出来有数值上的限制的,为什么?看了后面的内容就明白了.
因此,所有根据记录的key算出bucket index相同的记录全都以二叉树的形式组织起来,而每个bucket array元素存放的整型值就是该bucket树根所在记录的offset.
到此,相关的结构体联系都清楚了,下面的流程图给出了查找一个key的记录是否存在的流程:
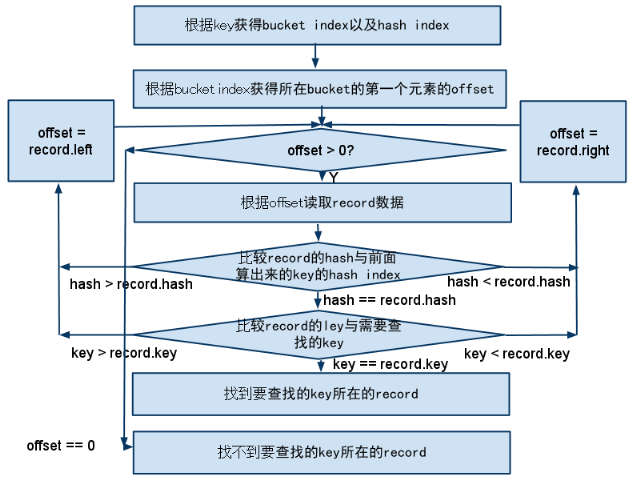
简单的解释一下,这个查找的流程就是首先根据查找的key算出所在的bucket,然后在这个bucket的二叉树中按照条件遍历的过程.
前面提到过,bucket array是整个被mmap映射到共享内存中去的.我们来做一个估计,假设存放bucket array的内存使用了1G,而真正存放record的文件长度有16G,也就是,bucket array的元素与记录大概是1:16的关系,假设所选的hash算法足够的好,以至于每个记录的key可以较为平均的分布在不同的bucket index上,也就是每个bucket array的元素组成的二叉树上平均有16个元素,那么也就最多需要O(4)次读取文件I/O(每次去读取记录的数据都是一次读磁盘操作) + O(1)次内存读操作(因为需要在bucket array中得到树根元素的offset).
但是等等,上面还有一些细节没有交待清楚.
首先,上面的二叉树不是类似AVL,红黑树这样的平衡二叉查找树,也就是说,很可能在极端的情况下演变成一个链表---树的一边没有元素,另一边有全部的元素.
其次,上面的流程图中还有一点就是每次比较首先比较的是hash值,这个值的奥秘就在于解决上面提到的那个问题.既然只是一个普通的二叉树,无法保证平衡,那么就通过算出这个二级的hash值来保证平衡---当然,前提依然是所选择的hash算法足够的好,可以保证key平均的分布.
前面提到过,非平衡的二叉树只会在极端的情况下才会演变为一个极端不平衡的二叉树--链表,而诸如AVL,红黑树之类的平衡二叉树,算法编码都相对复杂,调试起来也麻烦,出错了要跟进更麻烦,另外还别忘了,这些平衡二叉树之所以能保持平衡,在删除/增加元素时做的让树重新平衡的操作,比如旋转等,都是要涉及到读写树结点的,而这些,目前都是存放在磁盘上的---也就是这是相对较费时的操作,所以问题在于:是不是值得为这一个极端的情况去优化?另外,引入二级hash就是为了部分解决这个极端不平衡问题,它的思路简单也容易实现,但是引入的另外一个问题就是每次查找时根据key去算bucket index的时候,还要耗费时间去算hash index了.
平衡点,还是平衡点.时间还是空间,这是一个问题.
所以,经过对TC的hash数据库查找key流程的分析,最大的感受是:它没有使用复杂的算法与数据结构,而是通过一些巧妙的优化如二级hash的引入,达到了系统效率和编码调试复杂度之间一个较好的平衡.学会"平衡"各种因素,是做项目做事情,都要掌握的一个技能,而这个,只有多经历多想才能慢慢积累了.
好了,简单的回顾整个查找key的关键点:
1) 所有的record是以二叉树的形式组织在同一个bucket上面的.
2) 这个二叉树不是平衡的二叉树
3) 为了解决问题二造成的极端不平衡问题,TC引入了二级hash,以保证这个二叉树尽可能的平衡.
以上,就是TC对记录,bucket的组织情况,以及整个查找算法的流程.可以看到,算法,结构体定义等等都不复杂,但是由于巧妙的构思,既可以使用尽可能简单的算法/数据结构,又能规避可能出现的一些隐患,同时还能保证查找的高效率.
查找是key-value形式存储的核心流程,能够将这个流程优化,对整个系统的性能也有很大的影响.