一.XXX
1)概念说明
这里不再具体描述内存池的概念和作用,需要了解请看http://baike.baidu.com/view/2659852.htm?fr=ala0_1_1。
2)描述
在开发一个长时间运行的服务器程序时,一般频繁的向操作系统动态申请内存,而采用堆new分配,速度较慢,而且如果一个程序频繁的申请小内存块,很容易产生内存碎片,每次查找相对较慢。
因为堆是向高地址扩展的数据结构,每次内存分配其实都是进行虚拟内存分配,都会建立虚拟内存的到物理内存的映射,而是分配的一种不连续的内存区域,由于系统是用链表来存储的空闲内存地址的,而链表的遍历方向是由低地址向高地址。
这里还有一篇关于关于频繁的内存分配性能分析 ,图文并茂的讲得很详细。
3)实现目标.
而设计内存池的目的是为了保证一个程序长时间高效的运行,而该程序对内存申请频繁,为了减少系统内存碎片的产生,合理分配管理用户内存,从而减少系统中出现有效空间足够,而无法分配大块连续内存的情况。
关于实现一个高效与稳定内存池模块有如下目标:
A.如何实现内存的快速分配
B.如何实现内存的快速释放
C.如何管理内存池的稳定与效率.
注:本文介绍的内存池管理效率相对较高,且可以针对任意大小内存分配....
二.设计
设计前我们假设内存申请很频繁,而且申请小于在5120byte的远远大于5120byte字节。
为了让设计的内存池的使用更具有通用型和高效性,这里大致介绍通过需求不同指定一种基于内存需求策略的方式设计出一种内存池。
及小于5120字节的采用小块内存分配,大于5120的通过操作系统分配,内存池管理.
此内存池包括2中分配方式,介绍分配如下:
1) 个数固定的不定长的静态内存分配(BlockPool)。
A.设计思路
这种主要是根据程序中不同对象的大小而指定的一种策略,对于每一种大小又是通过一个链表链表管理,每个链表的节点的内存大小不同,而为了方便内存的管理,一般在程序初始化的时候针对不同的策略大小分配一块内存块,然后把此内存块划分为多个节点保存到链表中,每一个链表中保存的将是空闲的节点。
B.基本数据结构
 基本数据结构:
基本数据结构:

 /**//// 指定的策略 enum eBuff_Type
/**//// 指定的策略 enum eBuff_Type
 {
{
 eBT_32 =0,
eBT_32 =0,
eBT_64,
eBT_128,
eBT_256,
eBT_512,
eBT_1024,
eBT_2048,
eBT_5120,
eBT_END,
 };
}; /// 定一个双向链表的节点2个指针
/**////
/// file BaseNode.h
/// brief 一个双向链表需要的前后指针节点
///
#pragma once
template < typename T >
class CNode
{
typedef T Node;
public:
Node* next;
Node* prev;
CNode()

 {
{
next = prev = NULL;
 }
}
};
/**//// 节点struct Buffer: CNode<Buffer>
{
eBuff_Type type;
};
/// 不同大小的数据节点.
struct Buffer32 : Buffer { char buf[32]; };
struct Buffer64 : Buffer { char buf[64]; };
struct Buffer128 : Buffer { char buf[128]; };
struct Buffer256 : Buffer { char buf[256]; };
struct Buffer512 : Buffer { char buf[512]; };
struct Buffer1024: Buffer { char buf[1024]; };
struct Buffer2048: Buffer { char buf[2048]; };
struct Buffer5120: Buffer { char buf[5120]; };
/**////TlinkedList为一个链表
///这里包括eBT_END数组TlinkedList<Buffer> m_MemPool[eBT_END];
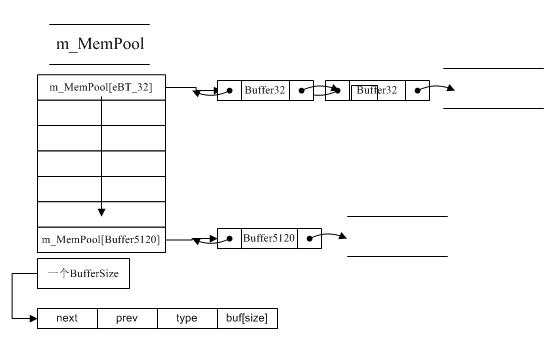
m_MemPool主要结构图如下:
C.性能分析
分配
这里策略只是针对小于eBT_5120Byte的内存进行分配,根据传入的大小直接Hash利用m_MemPool[idx]返回链表头,返回Buffer节点的buf数据块。
释放:根据传入要释放的Mem内存地址
/**//// 获得偏移地址Buffer* buf = (Buffer_Face*)( (char*)Mem - offsetof(Buffer_Face,buf) );
通过偏移地址即可获得buf的地址,buf里面包括type获得m_MemPool的索引,然后把释放的节点重新Push到m_MemPool[type]中。
性能: 插入,分配都是0(1)
2) 完全动态分配内存(HeapPool)。
介绍了上面的静态内存分配,其实是在利用已经分配好了的内存块里面在进行查找,释放也是直接根据传入的直接直接保存到缓存表中。
A.介绍下需要的基本数据结构
struct listNode : CNode<listNode>
{
long size;
/**//// 指向的内存
char* ptr;
};
struct HeapNode
{
/**//// memory request rate
__int64 m_Count;
/**//// all free memory list
TlinkedList<listNode> m_FreeList;
/**//// using memory list
TlinkedList<listNode> m_Used;
HeapNode( )
{
m_Count = 0 ;
m_FreeList.ReleaseList();
m_Used.ReleaseList();
}
};
typedef std::map<unsigned long,HeapNode* > MHEAPLIST; /// 其中map的key是分配的大小。
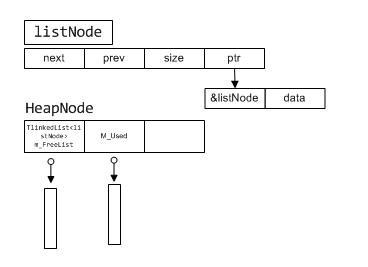
HeapNode的结构图如下:
B.设计思路
根据策略程序一般大于5120Byte字节的相对比较少,而程序请求大小也是相对比较规则,散列不是太大。
HeapNode有2个链表m_FreeList和m_Used,其中链表的节点如图ListNode所示
listNode有一个ptr表示需要配的内存,ptr指向的前8个地址为listnode的地址值(根据Cpu的最大寻址为64位),ptr+8则是分配的内存地址,为什么这么设计呢?
我是这样想的外界使用内存空间为data区域,那么我们释放的时候的只是需要传入data的地址,即可通过求出listnode的地址,
/**//// 根据MemAddr的地址求listnode地址__int64 pAddr = *(__int64*)((char*)MemAddr-8);
listNode* pNode = (listNode*)pAddr;
得到listNode地址后即可进行找到对应的HeapNode,然后进行释放或者放入缓存列表的操作。
关于HeapNode的管理,为了节约内存我们不可能一直申请内存而不释放,所以我们约定m_FreeList只是保存m_Used中一半大小的结点。当m_FreeList过多的节点时需要释放一定空间。(这个约定可以根据不同的需求而制定).
上面介绍了为什么如此的设计这个数据结构,下面介绍分配策略。分配的时候先查找是否有缓存数据,没有则分配一个,否则直接返回m_FreeList的一个listNode(结点)的ptr+8;
C.性能分析
通过上面描述可以确定基于完全动态分配的效率
分配的时候 lg(n);
释放的时候 lg(n);
而map的查找基于AVL树,所以查找基本是常量型的。
三.实现
上面只是介绍了分配方式,下面介绍实现。
通过上面描述可知,对于大于5120byte的内存分配采用HeapPool分配,否则采用BlockPool分配。
为了方便外界使用我们使用一个CMemFactory内存分配工厂,通过使用者申请Size和释放pAddr即可快速进行分配和释放。
代码如下:
http://code.google.com/p/tpgame/source/browse/#svn/trunk/MemPool/MemPool
具体代码打包如下:
/Files/expter/Pool.rar
注:如需了解跟多的内存池是实现可以阅读STL SGI, Loki, Boost内存池的实现...
附带最新内存池,实现和介绍...
http://www.cppblog.com/expter/archive/2011/01/18/138787.html